拼一个自己的操作系统 SnailOS 0.03的实现
拼一个自己的操作系统SnailOS0.03源代码-Linux文档类资源-CSDN下载
操作系统SnailOS学习拼一个自己的操作系统-Linux文档类资源-CSDN下载
SnailOS0.00-SnailOS0.00-其它文档类资源-CSDN下载
内核线程的实现
大家在学习操作系统的时候,对线程和进程可能已经有所耳闻了。而线程或进程的实现是在时钟中断中完成的。所以在实现内核线程之前,我们要先来个小插曲,即是开启时钟中断。前面我们已经开启了实时时钟中断,它的这种工作模式每秒中产生一个中断,对于线程或进程这种飞速运转的东西,实在是跟咱们操作系统的名字一样蜗牛了。所以为了让“蜗牛牌操作系统”,看起来不那么蜗牛,我们务必要开启发生频率更快的时钟中断。当然如果你不愿意坐高铁,而是特别习惯于老爷车,其实用实时时钟当作线程或进程切换的基地也不是不可以,更甚者说,那样的话更适合于人们观察的速度,能够亲眼看到进程或线程切换某些细节。好了,废话已经很多了。还是看代码吧。
【./kernel/system.asm 节选】
(上面省略)
; 时钟中断处理程序的汇编语言部分。
; void timer(void);
global _timer
align 8
_timer:
push 0x20 ; 向量号
jmp _interrupt_entry
【./intr/intr.c 节选】
(上面省略)
i_table[0x20] = (unsigned int)timer_handler;
(中间省略)
create_gate(0x20, (unsigned int)timer, 1 * 8, 0x8e00);
(中间省略)
/*
通过可编程中断控制器,开启外设中断的函数。
*/
void enable_extern_intr(unsigned char intr_vector) {
unsigned char data;
if((intr_vector >= 0x20) && (intr_vector <= 0x2f)) {
if(intr_vector < 0x28) {
/*
复位(清零)的方法是欲复位的某个位和0进行与操作,因此要取得
端口原有的数据信息然后在复位,而要得到需复位的位要进行移位操作
并且按位取反。同样的置位要进行或操作就好了,当然也不用取反。
*/
intr_vector -= 0x20;
data = in(0x21);
data &= ~(1 << intr_vector);
out(0x21, data);
} else {
/*
通过主芯片的第2个端口(从0开始计算),允许从芯片的接收中断。
*/
data = in(0x21);
data &= ~(1 << 2);
out(0x21, data);
intr_vector -= 0x28;
data = in(0xa1);
data &= ~(1 << intr_vector);
out(0xa1, data);
}
} else {
kprintf_("Invalid extern interrupt!...");
}
}
/*
通过可编程中断控制器,关闭外设中断的函数。
*/
void disable_extern_intr(unsigned char intr_vector) {
unsigned char data;
if((intr_vector >= 0x20) && (intr_vector <= 0x2f)) {
if(intr_vector < 0x28) {
intr_vector -= 0x20;
data = in(0x21);
data |= (1 << intr_vector);
out(0x21, data);
} else {
intr_vector -= 0x28;
data = in(0xa1);
data |= (1 << intr_vector);
out(0xa1, data);
}
} else {
kprintf_("Invalid extern interrupt!...");
}
}
/*
时钟中断处理程序的C语言部分。
*/
void timer_handler(void) {
kprintf_(" #TIMER# ");
}
这一次,笔者又杜撰了连个小函数附送给大家。它们分别是通过可编程中断控制器开启和关闭外设中断的函数。在中断那一章大家已经了解了吧,向数据端口0x21和0xa1写入数据可以开启或关闭对应外设的中断。具体的来说就是向量号为0x20至0x2f的中断是外设使用,对应的向中断控制器的主芯片和从芯片数据端口写入的数据第0位至7位,也就是0x20对应主芯片的0位,0x21对应主芯片的1位,依次类推到0x27对那个主芯片的第7位。0x28对应从芯片的第0位,也依次类推。因此通过中断向量号与相应位的对应规律,我们就能轻易的开启和关闭可编程中断控制器对硬件中断的响应。
【./kernel/kernel.c 节选】
(上面省略)
// out(0x21, 0xfb);
// out(0xa1, 0xfe);
enable_extern_intr(0x20);
enable_extern_intr(0x28);
(下面省略)
这次我们不在用直接操作端口的方法让中断控制器接收中断,而是通过对应端口的操作来完成。下面是运行效果。
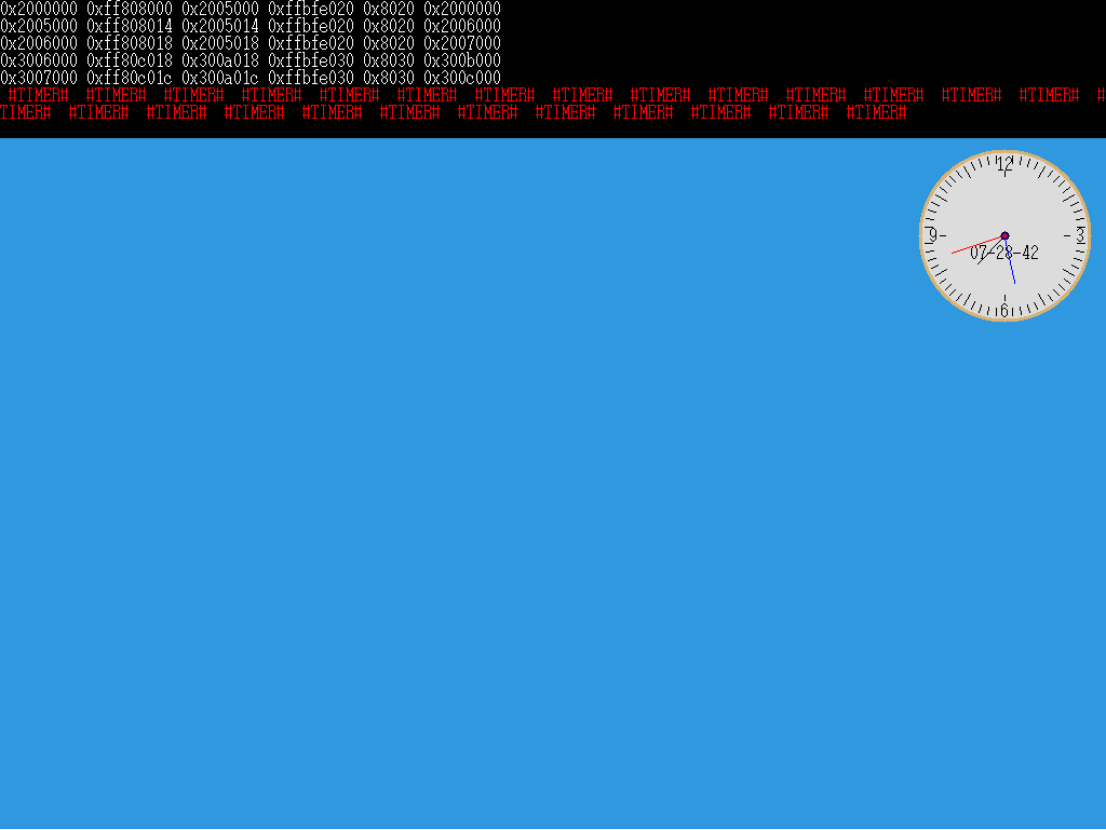
大家看到了吧,瞬间就发生了数次中断(大约18次),可是怎么觉得,还是不够快的样子。不过没关系,这里我们还没有设置时钟中断控制器的中断发生频率。接下来我们设置一下就好了。见代码。
【./intr/intr.c 节选】
(上面省略)
/*
可编程定时器计数器发生频率的初始化函数。
*/
void i8253_init(void) {
#define frequency 1193182
#define temp (frequency / 100)
/*
采用标准的分频方式(工作方式2),即比率发生器方式,就是往控制端口0x43
写入0x34。
*/
out(0x43, 0x34);
/*
向计数端口0x40分两次写入,计数初值,这样便能够使可编程定时器计数器每
10ms发生1次中断,也就是每秒钟产生100次时钟中断。
*/
out(0x40, temp & 0xff);
out(0x40, temp >> 8);
}
上面的注释非常简略,之所以这样主要是因为可编程定时器计数器的工作方式设置还是非常繁琐的,看起来就让人心情不爽,他有好多种工作方式,看了后脑袋就大大的。详细的设置方式在赵炯先生《Linux内核完全剖析》上写的非常之详细,祝你幸运地看完哟,^_^。这一次就没办法用图片来展示效果了,大家可以分别运行之前和现在的,并对比一下,重新设置频率后,大约快乐6倍吧。这里为什么是100次,而不是1000次,10000次,不是越快越好吗?据说专家们推算过,如果频率过快的话,cpu的时间就会有很多浪费在中断切换上,毕竟中断切换也需要cpu时间。如果频率太低,当然就好像cpu大脑迟钝一样的。所以说一百次也不是随意选择的数据哟。
现在万事俱备了,我们真的该说说线程了。现在我们的eip(指令指针)可以指向的地方大致也就这么几处,第一个是./kernel/kernel.c运行到最后有一条语句while(1),它是什么意思大家都明白吧。对了无线循环,也就是说,在没有中断和异常的情况下指令指针只能指向该语句。在这之后呢,我们开启了实时时钟中断和时钟中断,实时时钟中断每秒钟发生一次,时钟中断每秒中100次,也就是说,在这个刚才的无线循环中,偶尔会进入这两种中断中去进行特殊处理(注意我们的中断是不可以重入的,也就是中断中不能再次被中断,这是我们刻意设置的,当然也可以设置成中断可以被中断,不过那样就增加了难度,在这里我们当然要避重就轻了),完成后继续无线循环。之所以讲这些,一是因为要使大家清楚地明白一点,cpu将指令执行到哪里是让指令指针牵着走的。二是中断和异常处理在处理器的角度上看不算做一个单独的执行线索,它们算作为while(1)提供的服务。也就是说现在我们唯一运行的程序如果算作一个线程的话,那就是main函数,而且无论如何,它今后都只能在while(1)中发挥作用了。
目前看来,我们肯定不能陷入while(1)的泥潭中徘徊不前吧。我们要想一个办法让eip从这个main的while(1)中运行到另外一个地方去(其实也是while(1))。而且这个跳转还不能在main的while(1)中用jmp、call等指令跳转过去,我们要做得神不知鬼不觉、无声无息,玩他个月黑杀人夜、风高放火天,玩他个明修栈道、暗度陈仓。说得神乎其神,其实就是改变eip的值,而且不是在main的while(1)中改,而是在时钟中断中改。
那么接下来,几行简单的代码我们就实现了修改eip的功能,从而改变了程序的执行线索。
【./kernel/system.asm 节选】
_interrupt_entry:
; 占位
push 0
pusha
push ds
push es
push fs
push gs
mov al, 0x20
out 0x20, al
out 0xa0, al
mov eax, [esp + 4 * 4 + 8 * 4 + 1 * 4]
push esp
call [_i_table + eax * 4]
add esp, 1 * 4
jmp _exit
这里修改的位置,我们专门的标注了下划线,主要的目标是给timer_handler传递当前栈指针这个参数。
【./intr/intr.c 节选】
void main2(void);
void timer_handler(unsigned int esp) {
unsigned int* eip = (unsigned int*)(esp + 14 * 4);
*eip = (unsigned int)main2;
kprintf_(" #TIMER# ");
}
(中间省略)
void main2(void) {
printf_(" ##MAIN2## ");
while(1);
}
在timer_handler函数中,接收了主调函数timer传递过来的参数esp,通过计算esp + 4 * 14处即是返回地址的所在处,因此,我们在此处做些手脚,即使让执行流发生了改变。下面是运行效果图。

看到了吧,这说明时钟中断不止发生了一次,由于每次进入时钟中断都修改eip,所以即使main2的打印函数不在循环之内,还是随着时钟中断处理程序对eip的修改运行了数次。而且实时时钟中断也运行过了。现在唯一不确定的是kernel_main中是否运行到了while(1)中,因为图中并未显示出运行到哪里。程序运行到这里,如果大家认为没有问题的话,那就大错特错了。其实这只是一张妥妥的截图罢了。虚拟机此时已经over了。原因显然是多方面的,笔者一时半刻也解释不清。不过一个明显的问题是,我们并没有对程序运行的现场采取任何保护措施,而是直接地改变了eip。这样一来宕机也就在所难免了。之所以要进行这个失败的实验,其实是想告诉大家。虽然修改eip的成本很低,几乎没有什么门槛,但是要想实现线程,显然不是那么简单。这里面水还深着呢!
接下来关于线程的实现,虽然是舶来品,还请大家打起精神来,要不然是很难弄懂的。不过在给大家展示我所拿来的线程代码之前,我们还是要简单的啰嗦一下什么是进程,什么又是线程。这样大家才会对为什么产生这些概念有所了解,至于说能不能够深刻理解,那就要看悟性和功力了。
计算机发展到今天这个程度,我想大家对一边听音乐一边浏览网页,或者一边编程一边下载小电影这种事情早就已经司空见惯了吧。这个所说的几种表面的现象其实就是典型的多任务“同时”运行的例子。因此说,有了多任务就有了进程的概念,那些单独运行的任务就可以称之为一个进程。因此上,进程的概念并不难理解,像音乐播放器、网页浏览器、文本编辑器、编译器、视频播放器等运行起来后都可以是单独的进程。可以说可执行程序是静态未被运行起来的代码,而进程是运行起来的程序代码。你可以想象我们可以运行多个音乐播放器,这是完全可以的,只不过让我们同时听多部歌曲,是不是很乱呀!说到这里大家感觉出程序与进程的不同之处了吗?还是拿音乐播放器来说事。因为磁盘上的程序肯定是固定不变的了,所以通过操作系统的骚操作,可以多次被加载进内存,并且看似同时地播放多个不同的歌曲。这里可执行程序和进程的概念就明显的区分开来了。现在,不得不告诉大家一个事实,处理器每个确定的时刻只能运行一段特定的指令,其实并不是同时的播放多部歌曲,只不过即使“同时”运行多段特殊的指令,即分时地运行多段程序,切换以及运行的时间都是比较短暂的,一般的情况下,我们根本分辨不出来罢了。可是有时候用浏览器上网,同时播放歌曲的音乐会卡音。有时候下载大东西,编译软件的速度又会非常的慢。甚至有的时候中了某些病毒的时候,鼠标会在某个界面的不停的打转。凡此种种的现象都是多任务系统不可避免的现象,无论是在你的手机中、还是在电脑中,也无论你用的系统是苹果、微软、安卓、还是什么其他的系统。这样大家就明白了吧,看似无痕的多任务,其实给我们留下了很多讨厌的痕迹,那就是等待和忍耐。不过我们还真的不能没有多任务,即使给了我们这么多不好的体验,我们还得依赖多任务,谁让我们没钱,大多只能买一个处理器的产品呢!其实这只是美好的愿望,太湖之光之类的计算机倒是有多个处理器,即使买来了,对我们个人用户还真的没用,因为我们还真的拿不动了。
好了,真的是跑题了。让我们继续讲进程吧。有了对进程表象的了解后,我们就该说说进程的实现了。现在我们说了,同时播放两个音乐的时候,其实只是分时播放两个音乐。所以,处理器要记住,第一个被加载到内存的音乐播放器的代码运行到哪里了,也要记住音乐到哪里了。第二个当然也一样。这也就是说,处理器此时对自己的各个寄存器都要记住当前值,然后调取另一个播放器的当前值。恢复了这些后,就能够继续播放第二个音乐里,然而没有多久,就要保存第二个,切换到第一个,从而无声无息地让我们听到似乎都是完整的两首甚至更多首音乐播放。这个过程说的简略,也不严谨。但是话糙理不糙。实现进程的本质的问题就给大家摆在这了。意即一定要保护好现场,也就是保护当前程序的上文,当进程再次被调度后,能够继续它的下文。
上面对进程以及进程的实现都有了大概的印象了,接下来我们就说说线程。还是拿音乐播放器说事吧。现在大家用的音乐播放器是不是单独的播放音乐呢?我想不是吧,我们可以一边听音乐,一边下载歌曲,还一边浏览歌单。干这几样事情,谁都不会干扰谁。这样在一个任务中又同时分出来的小任务就是所谓的线程。在windows中具体这些线程是怎么实现的,笔者就不得而知了。不过大概率是用户线程。与用户线程相对应的就是内核线程,内核也需要同时干很多很多的事情,这当然可以通过相互协作的进程来实现,可以既然在用户的进程中能够实现线程,在内核中也是能够实现的。这种在内核中0特权级实现的线程称之为内核线程。它的好处是操作系统的任务调度器完全知道有线程的存在,可以创建和销毁内核线程程,就像创建和销毁进程一样。
讲的再多也不如用实际的代码来的一目了然,来的直截了当,来的豁然开朗,来的酣畅淋漓,下面把代码给大家展示一下。
【system.asm 节选】
(上面省略)
; 时钟中断处理程序的汇编语言部分又改成了老样子。
; void timer(void);
global _timer
align 8
_timer:
push 0x20 ; 向量号
jmp _interrupt_entry
;struct thread_stack
;{
; 0 unsigned int edi;
; 1 unsigned int esi;
; 2 unsigned int ebp;
; 3 unsigned int esp;
; 4 unsigned int ebx;
; 5 unsigned int edx;
; 6 unsigned int ecx;
; 7 unsigned int eax;
; 8 unsigned int kernel_thread; 经由调度进入则这里是返回地址。
; 9 unsigned int retaddr_dummy; 这里是cur。
; 10 unsigned int func; 这里是next。
; 11 unsigned int func_arg;
;};
;strcut task_struct
;{
; unsigned int* self_kstack;
;(下面省略)
;}
; switch_to(cur, next)函数是真正的负责任务切换的汇编函数
; 这个函数的实现其实再过简单不过了。首先他把当前任务的esp
; 保存在当前任务结构的self_kstack中,也就是任务结构首部,
; 然后从上处理器运行的任务结构取得之前(即使任务第一次运行,
; esp也被保存了一个特殊得值)保存得esp,然后返回。
global _switch_to
align 8
_switch_to:
; 之所以要用这条指令,是为了照顾c语言函数调用得约定,
; schedule()在调用switch_to()后,不应产生对schedule()
; 使用得寄存器得任何破环,当然这里我真的了解此函数破坏
; schedule()使用的那个寄存器。
pusha
; 为什么是9 * 4是任务结构cur的指针,我们向大家应该知道了
; 通过函数原型switch_to(cur, next) 可知参数cur后入栈,也就是
; 在next之后入栈,而在返回schedule()的地址之前入栈,
mov eax, [esp + 9 * 4]
mov [eax], esp
mov eax, [esp + 10 * 4]
mov esp, [eax]
; 对返回之前对寄存器予以恢复。看上面的线程结构可以知道,
; 如果线程是第一次上处理器,则esp应该指向线程栈开头。
popa
; 恢复了寄存器之后,透过ret指令返回到调用switch_to()的
; 的函数,一般的是schedule()调用了switch_to(),特殊的第一次是
; 预先修改的返回地址,所以会返回到kernel_thread()函数。
; 这就是线程栈在8个通用寄存器之后预留了一个kernel_thread
; 地址空间的原因,只不过这里只有第一次是kernel_thread的原因
; 问题在于下面还预留了一个返回地址是玩的是什么妖。是这样的
; func(func_arg)被kernel_thread()调用时,会在栈上留下一个返
; 回地址,但该函数将永远不会返回。而kernel_thread(func, func_arg)
; 的原型是这样的,func和func_arg的第一次则分别按顺序被放在栈中。
ret
【intr.c 节选】
(上面省略)
/*
时钟中断处理程序的C语言部分。
*/
void timer_handler(void) {
struct task* cur_thread = running_thread();
/*
校验任务结构是否被覆盖。
*/
ASSERT((cur_thread->stack_magic == 0x19810602));
/*
任务总滴答数(时间片数)自增。
*/
cur_thread->elapsed_ticks++;
/*
系统总滴答数(时间片数)自增。
*/
ticks++;
/*
这种调度算法应该叫做“极简优先级”算法吧。当任务时间片用完,执行调度器,
其他情况中断返回,继续运行当前任务。
*/
if(cur_thread->ticks == 0) {
schedule();
} else {
cur_thread->ticks--;
}
}
(下面省略)
【thread.h】
// thread.h 创建者:至强 创建时间:2022年8月
#ifndef __THREAD_H
#define __THREAD_H
#include "double_linked_list.h"
/*
定义了一个函数类型,他就是实质意义上的线程实体的类型。
*/
typedef void thread_func(void*);
/*
该枚举类型是线程或进程的各种状态,目前我们只知道两种状态
就好了,也就是运行态和就绪态。运行态也就是线程中的代码正
在被处理器执行,就绪态则是程序控制块在就绪队列中。
*/
enum task_status {
RUNNING, READY, BLOCKED, WAITING, HANDING, DIED
};
/*
这里看似多余的列出了中断处理程序中的exit过程,其实是为了
让大家对exit和中断栈中安排的数据结构一一对应,从而明白其
中的道理。
*/
/*
_exit:
pop gs
pop fs
pop es
pop ds
popa
add esp, 2 * 4
iret
*/
/*
现在大家学习到这里也应该明白一个基本的道理了,栈是处理器
原生支持的临时保存数据的内存空间,尤其是函数调用和中断处
理是离不开栈的操作的。中断栈即是在中断发生时,保存寄存器
数据的内存空间。可以想象中断是随时发生的,那么入栈和出栈
的操作也是非常频繁的。拿现在的线程来说,中断来临时可能是
我们的正在运行的线程中发生多次多层函数调用,因此即使初始化线
程时把栈指针指向程序控制块的最高处(某个物理页的最高处),
也是不能够保证该栈指针的值是一个固定的值。由于线程是位于
内核中,所以在入栈时,中断栈结构的最后(最高处)两个四字节
的数据esp和ss是不会被压入到栈中的。原因是现在没有特权级
的变化。另一方面,当正在运行的代码是用户进程时,一定会把
这两个数据压入用户进程的内核栈。在中断发生时,处理器和我们
的中断处理程序又会有不同的分工,我们的中断处理程序根据
处理器的异常发生的特殊性,刻意地将入栈操作区分为有出错码和
无出错码两种情况,从而保证了出入栈的对称性,也就是即使没有
出错码我们在中断处理程序中也会将空数据入栈而占位。之所以压入
向量号,只是为了调用中断处理函数是方便一些,其实这个不是必要
的。原因是,每个中断处理程序都是我们人为认真的编制的,所以我们
完全是知道发生了什么中断,也就完全知道对应的中断处理函数是什么。
而由于当前运行的进程是用户态还是内核态的不同处理压入内核栈的
数据也不一样,也就是上面说的,只有当前是用户进程时,才把数据
结构中的最后(内存中是高处)两个数据压入栈。在线程处是从eflags
开始压入栈的。
*/
struct intr_stack {
// 段寄存器的占位
unsigned int gs, fs, es, ds;
// 通用寄存器的占位
unsigned int edi, esi, ebp, esp_dummy;
unsigned int ebx, edx, ecx, eax;
// 中断向量的占位
unsigned int vector_no_dummy;
// 出错码的占位
unsigned int err_code_dummy;
// 中断发生时必然入栈的数据占位
unsigned int eip, cs, eflags;
// 只有当特权级事件发生时,才会被入栈的数据占位
unsigned int esp, ss;
};
/*
线程栈的作用是根据函数调用的约定保护寄存器的手段,也就是
当c语言的调度程序schedule()调用汇编语言的switch_to过程时,
我们需要在被调用的汇编过程中保护部分寄存器的值,以免破主调
函数的数据。另外一个作用是在真正的线程或进程函数第一次被
调度到处理器时,事先布置一个完全正确的栈环境。这个比较难以
理解,需要对照kernel_thread函数结构才能够讲清楚。
*/
struct thread_stack {
// 为了应对c语言函数对汇编过程的调用,直接将8个通用寄存器入栈
unsigned int edi, esi, ebp, esp_dummy;
unsigned int ebx, edx, ecx, eax;
/*
线程(甲线程)第一次被调用时,一定会从这里开始运行,也可以这样认为,
编译器编译的kernel_thread函数的地址如果是固定的话这个地址
值都将是固定的。而通过这里真正的线程函数被调用。当甲线程被
调度下处理器后,处理器和中断处理程序会把当前甲线程状态保存在甲的中
断栈中,并且先后进入中断处理程序、调度程序schedule()和switch_to()程序,
switch_to()会切换栈到处于运行态的乙线程(这里假设乙线程也不是
第一次运行,第一次也要从kernel_thread开始)的中断栈,这时候乙
线程也是由switch_to()函数上次调度下处理器的,因此,中断栈上会
保存调用switch_to()函数的函数schedule()中的返回地址,这样由
switch_to()返回到schedule()中,而schedule()是由中断处理程序
的汇编过程调用的,所以又返回到该汇编过程。最后在exit过程的
努力下还原所以寄存器的值,恢复本次乙线程的运行。同样的当再次切换
到甲线程的时候,也是按照这样的顺序返回到甲线程的,也就是说
在此种情况下kernel_threan占位处保持保存的是switch_to过程返回到
shhedule()的地址。
*/
unsigned int kernel_thread;
/*
这个是函数调用时,被压入栈的返回地址,也就是function(func_arg)的
返回地址,很明显由于每个线程都将是一个无限循环(目前没有线程的
退出机制)。因此该函数无法也不会返回。这里仅仅是占位罢了。但这里
不能没有因为一个函数调用过程一定会在堆栈中压入一个返回地址。
*/
unsigned int retaddr_dummy;
/*
thread_create()函数会把真正被调用函数的入口地址和参数,复制到
线程栈的对应位置,当线程第一次运行时,供kernel_thread函数调用。
我们看kernel_thread的原型是下面这样:
void kernel_thread(thread_func* function, void* func_arg);
它是把被调用的函数及其参数都作为自己的参数了。这样就不难理解这个
线程栈结构了。
*/
unsigned int func, func_arg;
};
/*
这是任务结构,也就是程序控制块,将开始于某个自然页的最低端。
*/
struct task {
/*
在线程中,通过switch_to()函数,该处用于存放线程切换时的内核栈指针。
因为任务结构开始于自然页的最低端,所以该变量作为任务结构的第一个
成员即是处于自然页的最低端。
*/
unsigned int* self_kstack;
/*
这是任务状态。
*/
enum task_status status;
/*
这是任务名字,最大16字节。
*/
char name[16];
/*
这是任务优先级,数值不会太大,所以字节类型就够了。
*/
unsigned char priority;
/*
同样的,这是任务时间片,初值设置为优先级,每次时钟中断自减1,
时间片用完,则该任务被调度器置为就绪态,换上其他任务运行。
*/
unsigned char ticks;
/*
这是任务在处理器上运行的总的时间片。
*/
unsigned int elapsed_ticks;
/*
任务在就绪队列中的节点,用于把任务从该队列中添加和删除。
*/
struct list_node general_tag;
/*
任务在全部任务队列中的节点,用于把任务从该队列中添加和删除。
*/
struct list_node all_list_tag;
/*
页目录表指针,内核线程没有自己单独的页目录表,该处为NULL。
*/
unsigned int* pgdir;
/*
因为任务结构开始于自然页的最低端,而内核栈指针位于该页的高端
某处,为了防止在某个可能的时刻,内核栈覆盖任务结构,设置了这个
魔数。
*/
unsigned int stack_magic;
};
struct task* running_thread(void);
void kernel_thread(thread_func* function, void* func_arg);
void thread_create(struct task* pthread, thread_func function,
void* func_arg);
void init_thread(struct task* pthread, char* name, int prio);
struct task* thread_start(char* name, int prio, thread_func function,
void * func_arg);
void make_main_thread(void);
void schedule(void);
void thread_init(void);
struct task* main_thread;
struct double_linked_list thread_ready_list;
struct double_linked_list thread_all_list;
struct list_node* thread_tag;
#endif
【thread.c】
// thread.c 创建者:至强 创建时间:2022年8月
#include "double_linked_list.h"
#include "thread.h"
#include "intr.h"
#include "string.h"
#include "debug.h"
#include "global.h"
#include "memory.h"
/*
这个汇编过程用于任务切换,即是切换任务的内核栈。
*/
extern void switch_to(struct task* cur, struct task* next);
/*
系统开启中断后,运行的总的滴答数(时间片数),可以想象,
如果系统连续运行的时间比较长,该值将溢出,当然那是2^32时间片
后才会发生的事情。
*/
unsigned int ticks;
/*
获取当前任务结构的一种暴力的方法,因当前任务结构始终和任务内核栈
指针处于同一自然页中,且位于自然页的最低端,所以将esp值的低12为
清零就得到了任务结构。
*/
struct task* running_thread(void) {
unsigned int esp;
__asm__ __volatile__("movl %%esp, %0":"=a"(esp));
return (struct task*)(esp & 0xfffff000);
}
/*
线程被创建时,在线程栈中会把switch_to()函数的返回地址设置
为该函数,因此,第一次运行线程实际上是执行该函数。
*/
void kernel_thread(thread_func* function, void* func_arg) {
/*
必须要重新打开中断,因为在时钟中断中自动关闭了处理器的中断。
*/
intr_enable();
/*
通过函数调用,真正运行起代表线程的函数。
*/
function(func_arg);
}
void thread_create(struct task* pthread, thread_func function, void* func_arg) {
// pthread->self_kstack -= sizeof(struct intr_stack);
// pthread->self_kstack -= sizeof(struct thread_stack);
/*
在线程开始之前,任务的内核栈指针位于任务结构所处自然页面的最高端,
在这里通过两次自减操作,使该指针指向我们人为设置的线程栈最开始处,
同时通过访问线程栈结构,创建线程。
*/
pthread->self_kstack = (unsigned int*)((int)pthread->self_kstack
- sizeof(struct intr_stack));
pthread->self_kstack = (unsigned int*)((int)pthread->self_kstack
- sizeof(struct thread_stack));
struct thread_stack* kthread_stack =
(struct thread_stack*)pthread->self_kstack;
kthread_stack->kernel_thread = (unsigned int)kernel_thread;
kthread_stack->func = (unsigned int)function;
kthread_stack->func_arg = (unsigned int)func_arg;
kthread_stack->eax = kthread_stack->ecx = kthread_stack->edx =
kthread_stack->ebx = kthread_stack->esp_dummy = kthread_stack->ebp =
kthread_stack->esi = kthread_stack->edi = 0;
}
/*
初始化线程的函数。
*/
void init_thread(struct task* pthread, char* name, int prio) {
/*
为了防范内存残留的数据导致的错误,将线程任务结构清零。
*/
memset_(pthread, 0, sizeof(*pthread));
/*
为线程命名。
*/
strcpy_(pthread->name, name);
/*
主线程已经运行,设置为运行态。其他线程设置为就绪态。
*/
if(pthread == main_thread) {
pthread->status = RUNNING;
} else {
pthread->status = READY;
}
/*
线程开始运行前,将线程栈设置为任务结构所在页面的最高端。
*/
pthread->self_kstack = (unsigned int*)((unsigned int)pthread + 4096);
/*
下面是设置优先级、时间片、总时间片、页目录地址、内核栈魔数的初始值。
*/
pthread->priority = prio;
pthread->ticks = prio;
pthread->elapsed_ticks = 0;
pthread->pgdir = NULL;
pthread->stack_magic = 0x19810602;
}
/*
真正启动线程的函数。
*/
struct task* thread_start(char* name, int prio, thread_func function,
void * func_arg) {
/*
在内核空间,动态分配线程任务结构和线程内核栈所在的一个自然页。
*/
struct task* thread = get_kernel_pages(1);
init_thread(thread, name, prio);
thread_create(thread, function, func_arg);
/*
将线程分别添加到任务的就绪队列和全部队列中。
*/
ASSERT(!double_linked_list_find(&thread_ready_list, &thread->general_tag));
double_linked_list_append(&thread_ready_list, &thread->general_tag);
ASSERT(!double_linked_list_find(&thread_all_list, &thread->all_list_tag));
double_linked_list_append(&thread_all_list, &thread->all_list_tag);
return thread;
}
/*
创建主线程的函数于一般函数略有不同,因为主线程已经处于运行态,
所以只需要将主线程加入到任务全部队列,无需加入到就绪队列中。
*/
void make_main_thread(void) {
main_thread = running_thread();
init_thread(main_thread, "main", 31);
ASSERT(!double_linked_list_find(&thread_all_list, &main_thread->all_list_tag));
double_linked_list_append(&thread_all_list, &main_thread->all_list_tag);
}
/*
所有线程任务的初始化。
*/
void thread_init(void) {
double_linked_list_init(&thread_ready_list);
double_linked_list_init(&thread_all_list);
make_main_thread();
}
/*
内核中极端重要的函数,也就是任务调度的函数,然而它被做的非常简单。
*/
void schedule(void) {
/*
任何使用调度函数的过程,都有责任保障处理器处于禁止中断的状态,
这主要是务必要保证任务切换的原子操作。
*/
ASSERT((get_intr_status() == 0));
struct task* cur = running_thread();
/*
因为时间片用完,只有当前任务处于运行态的情况,才把任务状态置
为就绪态,同时把时间片再次充满。
*/
if(cur->status == RUNNING) {
ASSERT(!double_linked_list_find(&thread_ready_list, &cur->general_tag));
double_linked_list_append(&thread_ready_list, &cur->general_tag);
cur->ticks = cur->priority;
cur->status = READY;
} else {
/*
调度程序不一定是被时钟中断处理程序调用,也可能是任务自己阻塞自己,
当这些情况发生时,调度程序什么也不做。由阻塞函数将任务加入到其他的
等待队列。
*/
}
ASSERT(!double_linked_list_is_empty(&thread_ready_list));
/*
无论何种情况,当前任务都要被换下处理器,从就绪队列的头部取出任务,
设置为运行态,并切换到该任务。
*/
thread_tag = double_linked_list_pop(&thread_ready_list);
struct task* next = node2entry(struct task, general_tag, thread_tag);
next->status = RUNNING;
switch_to(cur, next);
}
当有了线程的系统,大家简单的看一下截图吧。

因为屏幕上各个线程搜搜闪过,在处理器给定的时间片上全力以赴的运行,所以这里根本很少看到它们同时出现在屏幕上。