商品系统、搜索系统这类与用户关联不大的系统,效果特别的好。因为在这些系统中,每个人看到的内容都是一样的,也就是说,对后端服务来说,每个人的查询请求和返回的数据都是一样的。这种情况下,Redis缓存的命中率非常高,近乎于全部的请求都可以命中缓存,相对的,几乎没有多少请求能穿透到MySQL。
但用户相关系统,使用缓存效果就没那么好,如订单系统、账户系统、购物车系统等。这些系统每个用户要查询的信息都和用户相关,即使同一功能界面,那每个人看到数据都不一样。
如“我的订单”,用户在这里看到的都是自己订单数据,我打开我的订单缓存的数据,是不能给你打开你的订单来使用。这种情况下,缓存命中率就没那么高,相当一部分查询请求因为命中不了缓存,打到MySQL。
随系统用户数量越来越多,打到MySQL读写请求越来越多,单台MySQL支撑不了这么多的并发请求时,怎么办?
读写分离,提升MySQL并发首选
只能用多MySQL实例承担大量读写请求。MySQL是典型单机数据库,不支持分布式部署。用一个单机数据库的多实例来组成一个集群,提供分布式数据库服务非常困难。
在部署集群的时候,需要做很多额外工作,很难做到对应用透明,那你的应用程序也要为此做较大调。所以,除非系统规模真的大到只有这一条路,不建议你对数据分片,自行构建MySQL集群,代价大。
一个简单而且非常有效的方案是,不对数据分片,而使用多个具有相同数据的MySQL实例分担大量查询请求,即“读写分离”。基于很多系统,特别是面对公众用户的互联网系统,对数据读写比例严重不均。读写比一般几十,平均每发生几十次查询请求,才有一次更新请求。即数据库要应对绝大部分请求都是只读查询。
一个分布式的存储系统,想要做分布式写非常困难,因为很难解决好数据一致性。但实现分布式读简单很多,只需增加一些只读实例,只要能够把数据实时的同步到这些只读实例上,保证这这些只读实例数据随时一样,这些只读实例就可分担大量查询请求。
读写分离的另外一个好处是,它实施起来相对比较简单。把使用单机MySQL的系统升级为读写分离的多实例架构非常容易,一般不需要修改系统的业务逻辑,只需要简单修改DAO代码,把对数据库的读写请求分开,请求不同的MySQL实例就可以了。
通过读写分离这样一个简单的存储架构升级,就可以让数据库支持的并发数量增加几倍到十几倍。所以,当你的系统用户数越来越多,读写分离应该是你首先要考虑的扩容方案。
典型读写分离架构:
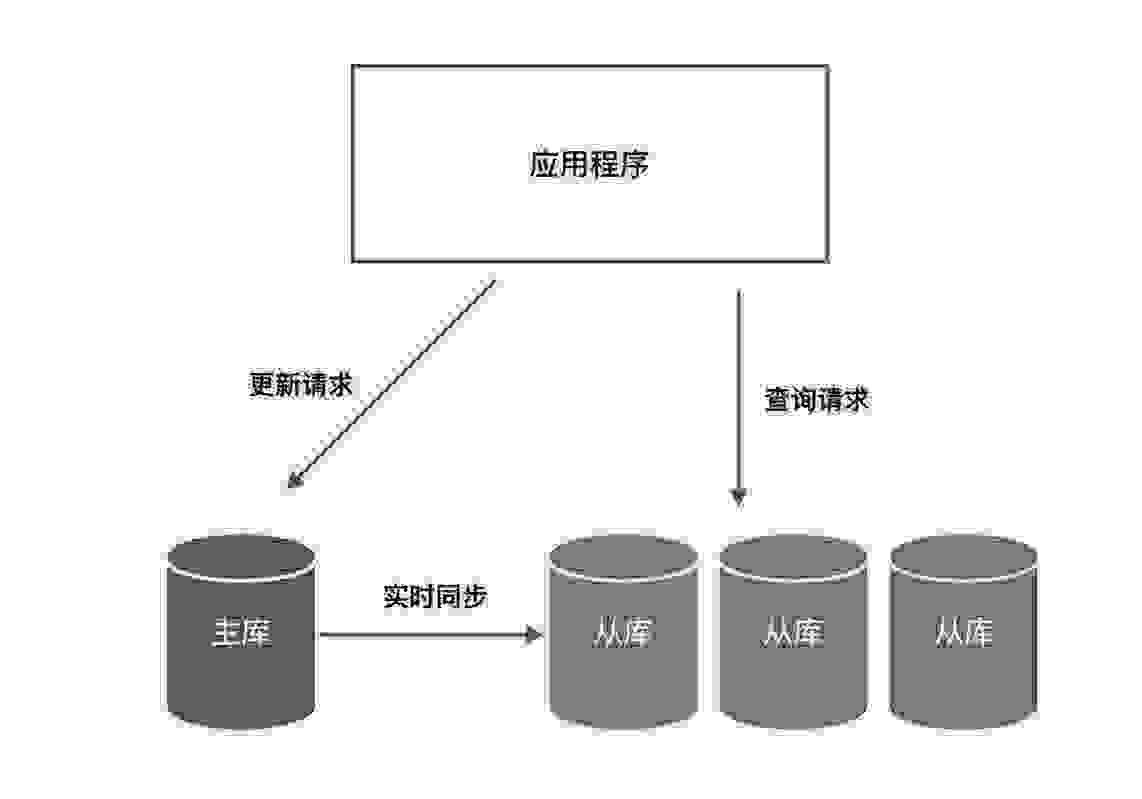
主库负责执行应用程序发来的所有数据更新请求,然后异步将数据变更实时同步到所有的从库中去,这样,主库和所有从库中的数据是完全一样的。多个从库共同分担应用的查询请求。
MySQL读写分离方案
部署一主多从多个MySQL实例,并让它们之间保持数据实时同步分离应用程序对数据库的读写请求,分别发送给从库和主库MySQL自带主从同步功能,配置就可实现一个主库和几个从库间数据同步,部署和配置方法:MySQL的官方文档。
分离应用程序的读写请求方法
纯手工
修改应用程序的DAO层代码,定义读、写两个数据源,指定每个数据库请求的数据源。
如果你的应用程序是一个逻辑非常简单的微服务,简单到只有几个SQL,或者是,你的应用程序使用的编程语言没有合适的读写分离组件,考虑这种。
组件
像Sharding-JDBC这种第三方组件,集成在你的应用程序内,代理应用程序的所有数据库请求,自动把请求路由到对应数据库实例。
推荐使用,代码侵入少,兼顾性能和稳定性。
代理
在应用程序、数据库实例间部署一组数据库代理实例,如Atlas或MaxScale。对应用程序来说,数据库代理把自己伪装成一个单节点的MySQL实例,应用程序的所有数据库请求被发送给代理,代理分离读写请求,然后转发给对应的数据库实例。
一般不推荐,使用代理加长你的系统运行时数据库请求的调用链路,有一定性能损失,并且代理服务本身也可能故障和性能瓶颈。但代理有个好处,它对应用程序完全透明。所以,只有在不方便修改应用程序代码情况,才采用代理。
若你配置多个从库,推荐“HAProxy+Keepalived”,给所有从节点做个高可用负载均衡方案:
避免某个从节点宕机导致业务可用率降低方便你后续随时扩容从库的实例数量因为HAProxy可做L4层代理,即它转发TCP请求。
读写分离带来的数据不一致
读写分离的一个副作用:可能存在数据不一致。DB中的数据在主库完成更新后,是异步复制到每个从库,即主从同步延迟。正常不超过1ms。但也会导致某刻,主、从库数据不一致。
订单系统,一般用户从购物车里发起结算创建订单,进入订单页,打开支付页面支付,支付完成后,应再返回支付之前的订单页。但若此时马上自动返回订单页,可能出现订单状态还显示“未支付”。因为,支付完成后,订单库的主库中,订单状态已被更新,而订单页查询的从库中,这条订单记录的状态有可能还没更新。
这没什么好的技术解决,大电商支付完成后不会自动跳回到订单页,它增加一个“支付完成”页面,这页面没有效信息,就是告诉你支付成功,再放一些广告。你如果想再看刚刚支付完成的订单,要手动点一下,这就很好规避主从同步延迟问题。
特别注意那些数据更新后,立刻查询更新后的数据,然后再更新其他数据这种case。如购物车页面,若用户修改某商品数量,需重新计算优惠和总价。更新购物车数据后,需立即调用计价服务,这时若计价服务读购物车从库,可能读到旧数据而导致计算总价错误。
可把“更新购物车、重新计算总价”这两步合并成一个微服务,然后放在一个数据库事务,同一事务中的查询操作也会被路由到主库,规避了主从不一致。
对这种主从延迟带来的数据不一致的问题,没有什么简单方便而且通用的技术方案,要重新设计业务逻辑,规避更新数据后立即去从库查询刚刚更新的数据。
总结
随着系统的用户增长,当单个MySQL实例快要扛不住大量并发的时候,读写分离是首选的数据库扩容方案。读写分离的方案不需要对系统做太大的改动,就可以让系统支撑的并发提升几倍到十几倍。
推荐你使用集成在应用内的读写分离组件方式来分离数据库读写请求,如果很难修改应用程序,也可以使用代理的方式来分离数据库读写请求。如果你的方案中部署了多个从库,推荐你用“HAProxy+Keepalived”来做这些从库的负载均衡和高可用,这个方案的好处是简单稳定而且足够灵活,不需要增加额外的服务器部署,便于维护并且不增加故障点。
主从同步延迟会导致主库和从库之间出现数据不一致的情况,我们的应用程序应该能兼容主从延迟,避免因为主从延迟而导致的数据错误。规避这个问题最关键的一点是,我们在设计系统的业务流程时,尽量不要在更新数据之后立即去查询更新后的数据。
FAQ
课后请你对照你现在负责开发或者维护的系统来分享一下,你的系统实施读写分离的具体方案是什么样的?比如,如何分离读写数据库请求?如何解决主从延迟带来的数据一致性问题?
使用Cache Aside模式更新缓存会产生脏数据?使用Cache Aside模式来更新缓存,是不是就完全可以避免产生脏数据呢?也不是,如果一个写线程在更新订单数据的时候,恰好赶上这条订单数据缓存过期,又恰好赶上一个读线程正在读这条订单数据,还是有可能会产生读线程将缓存更新成脏数据。但是,这个可能性相比Read/Write Through模式要低很多,并且发生的概率并不会随着并发数量增多而显著增加,所以即使是高并发的场景,这种情况实际发生的概率仍然非常低。
既然不能百分之百的避免缓存的脏数据,那我们可以使用一些方式来进行补偿。比如说,把缓存的过期时间设置的相对短一些,一般在几十秒左右,这样即使产生了脏数据,几十秒之后就会自动恢复了。更复杂一点儿的,可以在请求中带上一个刷新标志位,如果用户在查看订单的时候,手动点击刷新,那就不走缓存直接去读数据库,也可以解决一部分问题。
写订单支付成功之后需要送优惠券的业务,也导致赠送优惠券不成功。测试环境怎么都不出问题,后来才想到主从问题,之后就修改成功,从主库查询并增加优惠券。
原来用mycat,现在我们使用sharding-jdbc,配置简单,对开发透明。而且看官网上未来发展前景不错。sharding可以做到同一个线程内更新后的查询在主库进行,其他的情况也是在交互上做改进。
读写分离后,是否可以满足高并发写呢,比如秒杀系统,能够满足瞬间大量订单创建写数据库吗?
即使做了读写分离,一般也不会用MySQL直接抗秒杀请求,还是需要前置保护机制,避免大量的请求打到MySQL。
同一个事务会路由到主库是什么意思?
比如先后执行一条更新语句,和一条查询语句。默认读写分离的情况下,更新语句会走主库,查询语句会走从库。如果把这两条语句放到同一个事务里面,因为事务的原子性,那查询语句也会走主库。
我们系统现在从库没有ha的配置,在检测到主从延迟大于几秒后或故障后,把数据源自动切换切换到主库,如果检测一段时间延长减少又把数据源切换到从库,这种方式目前还行,如果并发真上来了,然后主从同步延迟加大导致切换到主库,可能把主库也搞挂。
缓存有2层,一层是渠道端,策略是我们有更新了发mq消息通知他们删除,一层是我们系统在有导致数据变更的接口调用后会刷缓存,策略是查主库把数据弄到缓存,另外就是设置缓存失效时间,在回到看数据的页面也要几秒,这种针对活跃的数据有较好的效果,不活跃的数据也没有数据延迟的问题
HAProxy+Keepalived这套架构:挺好挺稳定,业界使用率很高。
现在主流的都是用proxy,主备延迟怎么解决呢?
1、开启半同步方案
2、尽量在主库里面减少大事务、使用不均匀的话开启写后考虑主库读
3、有能力的话 分库分表
4、增加从库性能
5、如果实在无法追平,重新做从库