Java文档搜索引擎
项目运行效果一、简述搜索引擎概念二、搜索引擎实现思路2.1倒排索引介绍2.2项目目标2.3获取java文档2.4模块划分2.5创建项目2.6认识分词2.7分词的原理2.8使用第三方分词库 三、实现索引模块-parser类3.1 实现索引模块-递归枚举文件3.2 排除非HTML文件3.3 实现索引模块-解析HTML3.4 实现索引模块-解析标题3.5 实现索引模块-解析url的思路3.6 实现索引模块-解析url代码实现3.7 实现索引模块-解析正文的思路3.8 实现索引模块-解析正文的代码实现3.9 Parser类小结 四、实现索引模块-Index类4.1 实现索引模块 - 实现索引结构4.2 实现索引模块- 实现正排索引4.3 实现索引模块- 实现构建倒排索引4.4 如何改进权重公式4.5实现索引模块- 实现词频统计4.6实现索引模块 -构造倒排索引代码实现4.7实现索引模块-保存加载索引的背景4.8实现索引模块-实现保存索引文件4.9实现索引模块-实现加载索引4.10实现索引模块-给加载保存操作加上时间4.11实现索引模块-在parser中调用index4.12实现索引模块-验证索引制作 五、实现索引模块-优化索引模块篇5.1实现索引模块-关于索引制作速度5.2实现索引模块-实现多线程制作索引5.3实现索引模块-给制作的索引代码加锁5.4实现索引模块-验证多线程的效果5.4实现索引模块-解决进程不退出的问题5.4实现索引模块-首次制作索引比较慢的问题5.5实现索引模块-首次制作索引比较慢的问题5.5实现索引模块-验证索引加载逻辑5.6实现索引模块-索引模块小结 六、实现搜索模块-搜索模块篇6.1实现搜索模块- 创建DocSearcher类6.2实现搜索模块- 实现search方法(1)6.2实现搜索模块- 实现search方法(2)6.3实现搜索模块- 简单验证6.4实现搜索模块- 使用正则表达式6.5实现搜索模块- 替换script标签及其内容6.6实现搜索模块- 搜索模块小结 七、实现Web模块-约定前后端交互接口7.1 实现Web模块-基于Servlet的方式实现后端7.2 实现Web模块-验证后端接口7.3 实现Web模块-实现页面结构7.4 实现Web模块-实现页面样式(CSS)7.5 实现Web模块-通过ajax获取搜索结果7.6 实现Web模块- 实现标红逻辑7.7 实现Web模块- 测试更复杂的查询词7.8 实现Web模块- 处理停用词7.9 实现Web模块- 处理生成描述的BUG7.10 实现Web模块- 加上搜索结果的个数7.11 实现Web模块- 关于重复文档的问题7.12 实现Web模块- 多路归并的思路7.13 实现Web模块- 实现多路归并7.14 实现Web模块-验证权重合并 八、搜索引擎-改为springboot-创建项目8.1 搜索引擎-改为springboot-拷贝代码到新的项目8.2 搜索引擎-改为springboot-实现controller层8.3 搜索引擎-改为springboot-搞个路径切换开关8.4 搜索引擎-改为springboot-部署到服务器
项目运行效果
一、简述搜索引擎概念
我们先来看看搜索引擎是啥?
我们经常使用的百度搜索引擎就是一个这样的,看起来页面很简单,但是里面的代码是十分的复杂的。
我们去搜索其实就发现搜索引擎核心功能就是查找到一组和用户输入的词or一句话
像这个蛋糕两个字,我们称它为查询词,我们搜索到的内容也是要和查询词有相关性。
一般搜索到的内容也差不多是这样的,当然有的显示出来的结果会更加多一点内容。
当我们点击进去会跳转到详细页面(落地页)
二、搜索引擎实现思路
对于搜索引擎来说,首先需要获取很多的网页,然后在根据用户输入的查询词,在这些网页中查找。
但是我们有以下问题:
答:此处主要涉及到“爬虫”这样的程序,其实爬虫也就是Http客户端程序,它也是发送一些请求,响应一些结果,像百度,搜狗每天都有好多这样的程序,去爬互联网的各各网站,把数据收集处理。用户输入了查询词之后,如何让查询词和当前这些网页进行匹配呢?
答:假设我们使用暴力搜索的话,如果我们现在有一亿条数据,那么我们需要把查询词,去在一亿里面找,那这样我们的效率是很低的,我们的搜索引擎肯定是希望一敲回车马上出结果。这样肯定是不行的,所以我们需要一种数据结构,使用倒排索引这样的数据结构,这个数据结构在搜索引擎是十分重要的。
2.1倒排索引介绍
我们先来认识一下专业词:
文档(document):指的是每个待搜索的网页
正排索引:指的是 文档id 到 文档内容,给你一个文档id可以快速的查到对应的内容
倒排索引:指的是词到文档id列表的映射关系,倒排索引正好和正排索引相反,随便给你个词,问你在那个文档里面出现过 ,所以肯定有很多词在内容出现过,所以给的是一个列表。
来个简单的例子:
现在我们有2个文档:
正排索引| 文档ID | 文章 |
|---|---|
| 1 | 雷军发布了小米手机 |
| 2 | 雷军买了两斤小米 |
根据文档ID=1,我们就可以很快找到第一个内容,根据文档ID=2,我们就可以很快找到第二个内容,这样的结构就是正排索引
倒排索引
| 词 | 词出现过的文档ID |
|---|---|
| 雷军 | 1,2 |
| 发布 | 1 |
| 买 | 2 |
| 了 | 1, 2 |
| 小米 | 1,2 |
| 手机 | 1 |
上面这样的,根据词出现在哪个文档中,找出它的ID,这样的过程就构成了倒排索引。
当然上面是这样约定,只不过大家效果这样的形式,你也可以反正来 。 QAQ
其实我们平时打游戏的时候也经常遇到倒排索引这样的专业词。
用王者荣耀举例:里面有个叫做妲己的英雄,她有三个技能
1技能:群体伤害
2技能:眩晕技能
3技能:群体伤害
这样的类似于正排索引,根据 英雄名字 到 英雄技能
现在我们这样问,哪一个英雄的2技能有眩晕效果啊?
有这些英雄:1.妲己,2.小鲁班(靠近敌人)…
这样根据英雄的技能到英雄的名字
2.2项目目标
实现一个针对Java文档的搜索引擎
像百度,bing这样的搜索引擎,都是属于“全站搜索”,搜索整个互联网上所有的网站。
还有一类搜索引擎,称为“站内搜索” 只针对某个网站内部的内容进行搜索,像知乎啊,百度贴吧这样的,也就是我们现在的目标。
我们先来看看java文档网站Java文档地址
但是我们发现这个网站没有 搜索框 太不方便了吧!!!所以我们就来做一个!!!
–
2.3获取java文档
刚刚我们说了,想要搜索到内容,就得有网页,才可以制作倒排索引,搜索出来。
我们有两种方式获取:
通过爬虫获取文档直接从官方网站上下载压缩包我们使用第二种,直接下载即可,不需要通过爬虫来实现了。
网站地址:点击跳转下载
下载好了之后打开
打开里面的一个HTML和官方文档的对比一下,发现是一样的。
官方文档: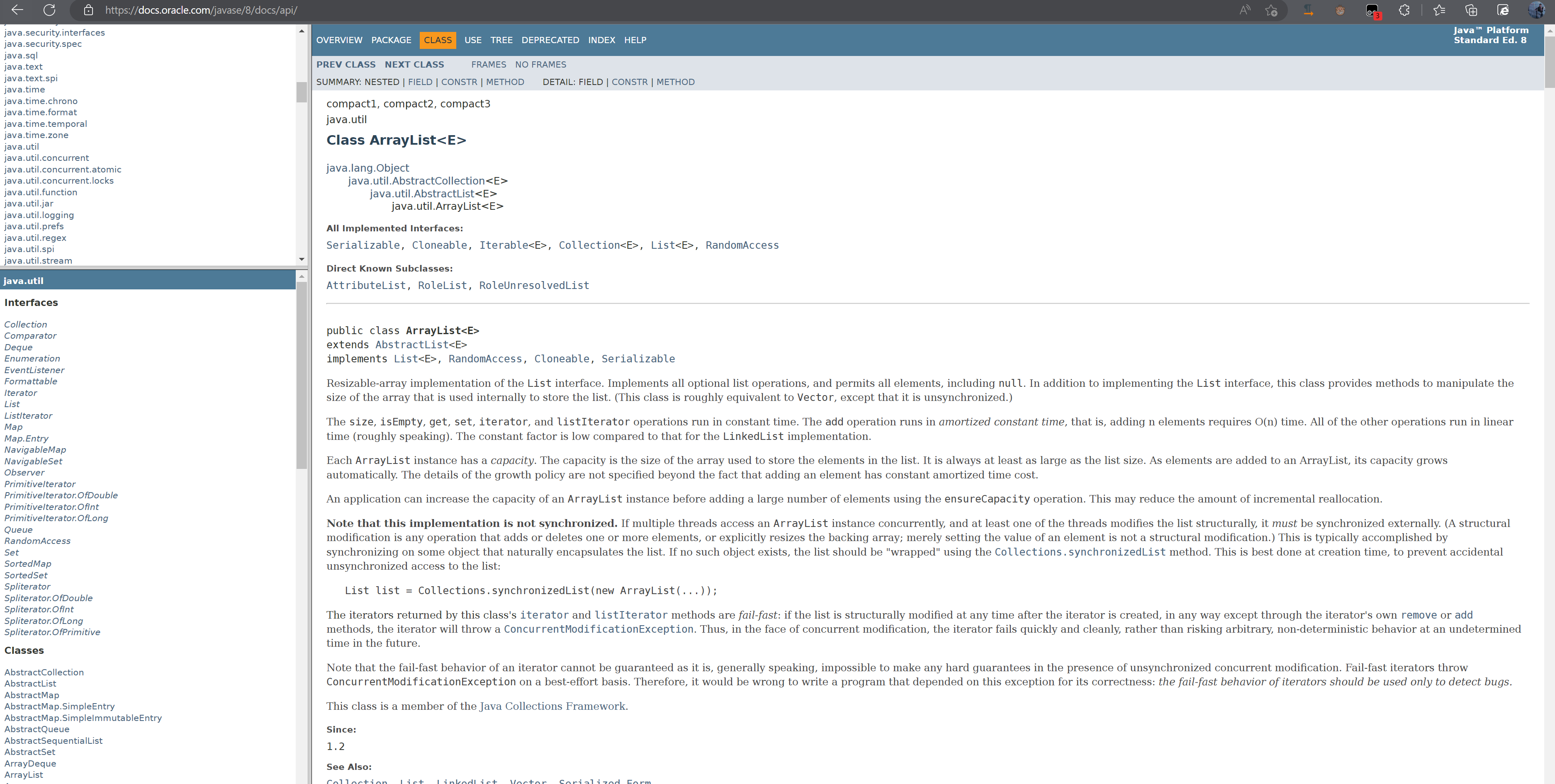
本地文档: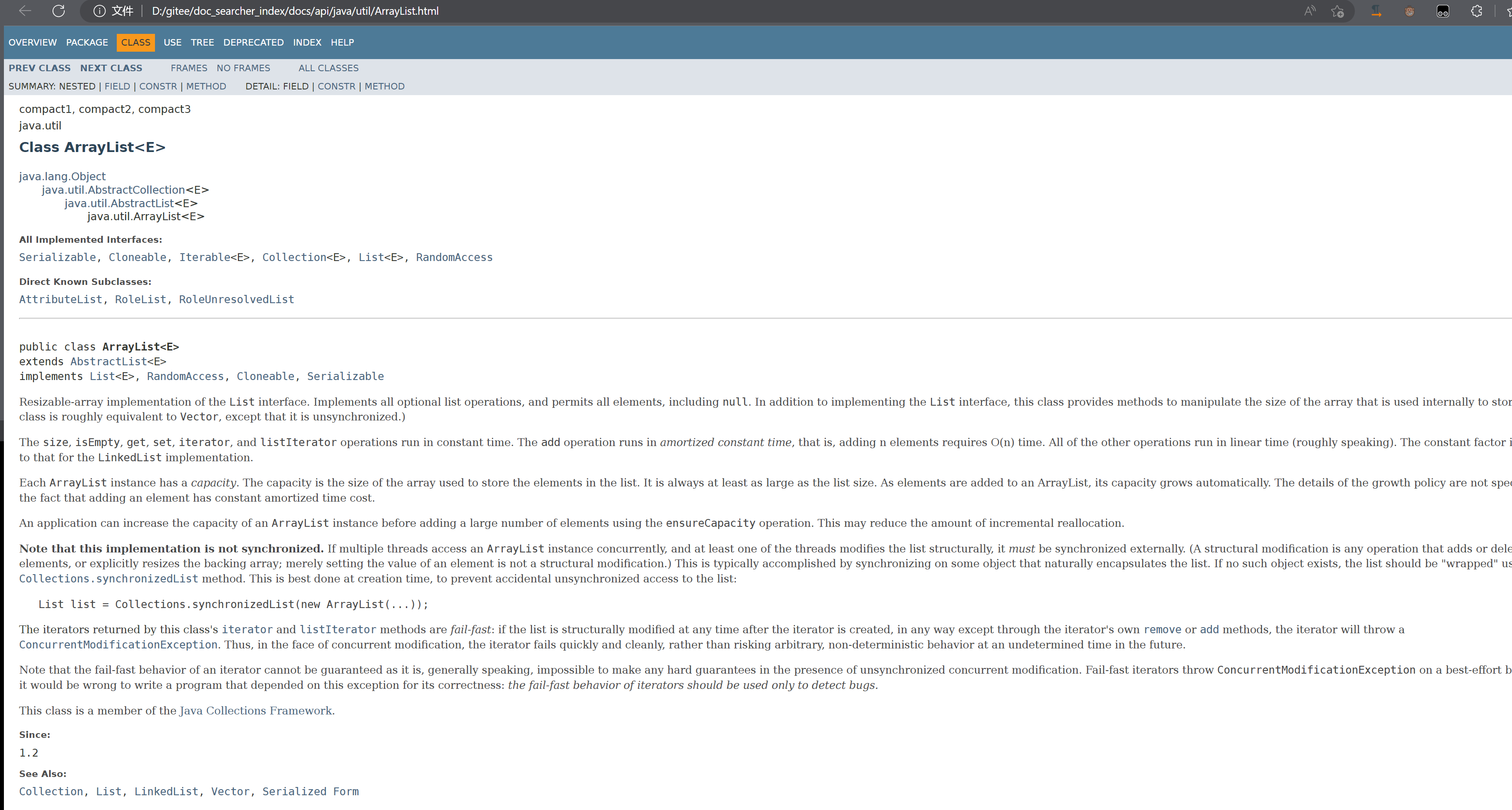
其实重点的是我们对比一下它们路径的关系:右击在新窗口打开链接
我们发现还是存在一定的关联关系,从docs后面都是一样的,只是前面不一样,前面是我们自己创建的路径。
针对于这样的关系,我们可以在本地基于离线文档来制做索引,当用户在搜索结果页点击具体的搜索结果的时候,就自动跳转到在线文档的页面。
2.4模块划分
索引模块1)扫描下载到的文档,分析文档的内容,构建出正排索引+倒排索引,并且把索引内容保存到文件中
2)加载制作好的索引,并提供一些API实现查询正排和查倒排这样的功能
2.搜索模块
调用索引模块,实现一个搜索的完整过程
输入:用户的查询词
输出:完整的搜索结果(包含了很多记录,每个记录就有标题,描述,展示url,并且能够跳转)
3.web模块
需要实现一个web模块程序,能够通过网页的形式来和用户进行交互(包含前端和后端)
2.5创建项目
直接创建Maven项目即可
2.6认识分词
用户在搜索引擎中,输入的查询词不一定就真的是一个词 ,也有可能是一句话。
分词就是把一个完整的句子给切分成多个词
我要买白菜 分成词 我/要/买/白菜/
对于人分词这个操作很简单,对于机器来说,我们要通过代码来分词,会困难很多。
典型的列子:
我一把把车把把住 我也想过过儿过的生活
哈哈哈 这样的是不是很难的。
但是相比之下英文的分词就很简单,因为天然中间有空格。
这样的情况我们使用第三方库来实现。
当然那些百度啥的,别人有团队自己做分词库,比我们开源的要准确不少。
2.7分词的原理
基于词库
尝试把所有的“词” 都进行穷举,把这些穷举的结果放到词典文件中
然后就可以依次的取句子中的内容,每隔一个字,在词典查一下,每隔两个字查一下
当然还是有些词是不准确的,那些网络流行词就不得行。
基于统计
收集到很多很多的“语料库” 相当于人工标准,就知道了那些词在一起的概率比较大。
分词的实现,就是属于“人工智能”典型的应用场景,训练模型。
2.8使用第三方分词库
java第三方的分词库挺多的,我们直接使用 ansj 这个库。
<!-- https://mvnrepository.com/artifact/org.ansj/ansj_seg --><dependency> <groupId>org.ansj</groupId> <artifactId>ansj_seg</artifactId> <version>5.1.6</version></dependency>如果是红色的就点刷新,没有报红也点一下:
我们来写个代码:
import org.ansj.domain.Term;import org.ansj.splitWord.analysis.ToAnalysis;import java.util.List;/** * Created by Lin * Description: * User: Administrator * Date: 2022-12-14 * Time: 19:29 */public class TestAnsj { public static void main(String[] args) { //准备一个比较长的话 用来分词 String str ="小明毕业于清华大学,后来又去蓝翔技校和新东方去深照,擅长使用计算机控制挖掘机来炒菜。"; ToAnalysis analysis = new ToAnalysis(); //Term就表示一个分词结果 List<Term> terms = analysis.parse(str).getTerms(); for (Term term :terms){ System.out.println(term.getName()); } }}我们使用的是ToAnalysis 如果idea爆红自己手动导入一下包。
我们使用的是parse()这个方法,但是这个方法返回的是一个第三方词库自己的Result类型,我们想获取一个类似于List的集合,所以我们使用getTerms()这个方法,返回的是List类型。
然后运行结果就是:
词已经分好了,但是我们看见这个有红色的玩意是啥**,其实是在分词的时候,其实会加载一些词典文件,通过这些词典文件能够加快分词速度,提高准确率,但是没有这些词典文件,ansj也可以快速准确分出词**,
注意英文 大小会变成小写。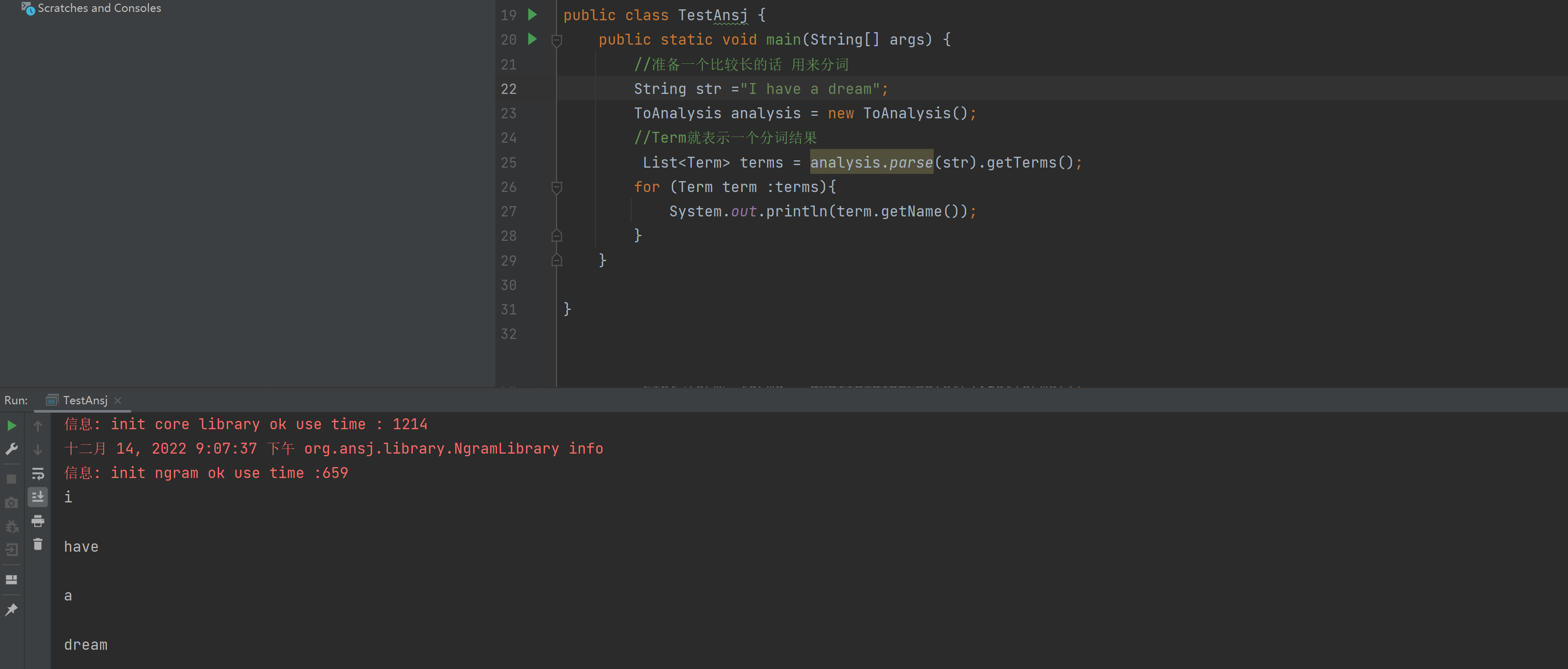
三、实现索引模块-parser类
接下来我们实现索引模块
我们期望这个类,去读取我们之前下载好的文档,并完成索引的制作。
我们首先创建一个Parser类里面实现制作索引数据结构
这个类具体要做的事情就这几点:
1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到 2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引 3.把内存中构造好的索引数据结构,保存到指定的文件中我们来看看第一点是啥意思:
因为官方的文档都是放在api那个文件夹下,所以我们要那个文件夹下的全部内容:
第二点的意思就是:就是那个文件夹
第三点的意思是:把做好的索引放到一个文件中,以后让程序读取索引。
当前阶段代码块:
public class Parser { //先指定一个加载文档的路径 ,由于是固定路径 我们使用 static 类属性 不需要变final private static final String INPUT_PATH ="D:\\gitee\\doc_searcher_index\\docs\\api"; // 只需要api文件夹下的文件 public void run(){ //整个Parser类的入口 //1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到 //2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引 //3.把内存中构造好的索引数据结构,保存到指定的文件中 } public static void main(String[] args) { //通过main方法来实现整个制作索引的过程 Parser parser = new Parser(); parser.run(); }}3.1 实现索引模块-递归枚举文件
枚举全部文件然后放到集合里,先上代码:
import java.io.File;import java.util.ArrayList;/** * Created by Lin * Description: * User: Administrator * Date: 2022-12-15 * Time: 19:15 */public class Parser { //先指定一个加载文档的路径 ,由于是固定路径 我们使用 static 类属性 不需要变final private static final String INPUT_PATH ="D:\\gitee\\doc_searcher_index\\docs\\api"; // 只需要api文件夹下的文件 public void run(){ //整个Parser类的入口 //1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到 ArrayList<File> fileList = new ArrayList<>(); enumFile(INPUT_PATH,fileList); //2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引 //3.把内存中构造好的索引数据结构,保存到指定的文件中 System.out.println(fileList); //看看文件个数 System.out.println(fileList.size()); } //第一个参数表示从那个目录开始进行遍历,第二个目录表示递归得到的结果 private void enumFile(String inputPath, ArrayList<File> fileList) { //我们需要把String类型的路径变成文件类 好操作点 File rootPath = new File(inputPath); //listFiles()类似于Linux的ls把当前目录中包含的文件名获取到 //使用listFiles只可以看见一级目录,想看到子目录需要递归操作 File[] files = rootPath.listFiles(); for (File file : files) { //根据当前的file的类型,觉得是否递归 //如果file是普通文件就把file加入到listFile里面 //如果file是一个目录 就递归调用enumFile这个方法,来进一步获取子目录的内容 if (file.isDirectory()){ //根路径要变 enumFile(file.getAbsolutePath(),fileList); }else { //普通文件 fileList.add(file); } } } public static void main(String[] args) { //通过main方法来实现整个制作索引的过程 Parser parser = new Parser(); parser.run(); }}这里我们是创建了一个enumFile()方法,使用listFile()这个函数可以获取目标路径下的当前目录
获取所有的文件的思路就是:判断是否是目录还是文件,是文件的话就把文件加入到 ArrayList fileList = new ArrayList<>()这个里面; 是目录就继续进函数里面递归,具体看代码注释。
最后看结果:
发现不止只有HTML文件还要其他的文件,我们应该去除它,只有HTML文件
3.2 排除非HTML文件
排除非HTML文件其实思路很简单,只需要判断文件的后缀是什么就可以了,可以使用endWith()这个函数进行识别,
import java.io.File;import java.util.ArrayList;/** * Created by Lin * Description: * User: Administrator * Date: 2022-12-15 * Time: 19:15 */public class Parser { //先指定一个加载文档的路径 ,由于是固定路径 我们使用 static 类属性 不需要变final private static final String INPUT_PATH ="D:\\gitee\\doc_searcher_index\\docs\\api"; // 只需要api文件夹下的文件 public void run(){ //整个Parser类的入口 //1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到 ArrayList<File> fileList = new ArrayList<>(); enumFile(INPUT_PATH,fileList); //2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引 //3.把内存中构造好的索引数据结构,保存到指定的文件中 System.out.println(fileList); System.out.println(fileList.size()); } //第一个参数表示从那个目录开始进行遍历,第二个目录表示递归得到的结果 private void enumFile(String inputPath, ArrayList<File> fileList) { //我们需要把String类型的路径变成文件类 好操作点 File rootPath = new File(inputPath); //listFiles()类似于Linux的ls把当前目录中包含的文件名获取到 //使用listFiles只可以看见一级目录,想看到子目录需要递归操作 File[] files = rootPath.listFiles(); for (File file : files) { //根据当前的file的类型,觉得是否递归 //如果file是普通文件就把file加入到listFile里面 //如果file是一个目录 就递归调用enumFile这个方法,来进一步获取子目录的内容 if (file.isDirectory()){ //根路径要变 enumFile(file.getAbsolutePath(),fileList); }else { //只针对HTML文件 if(file.getAbsolutePath().endsWith(".html")){ //普通HTML文件 fileList.add(file); } } } } public static void main(String[] args) { //通过main方法来实现整个制作索引的过程 Parser parser = new Parser(); parser.run(); }}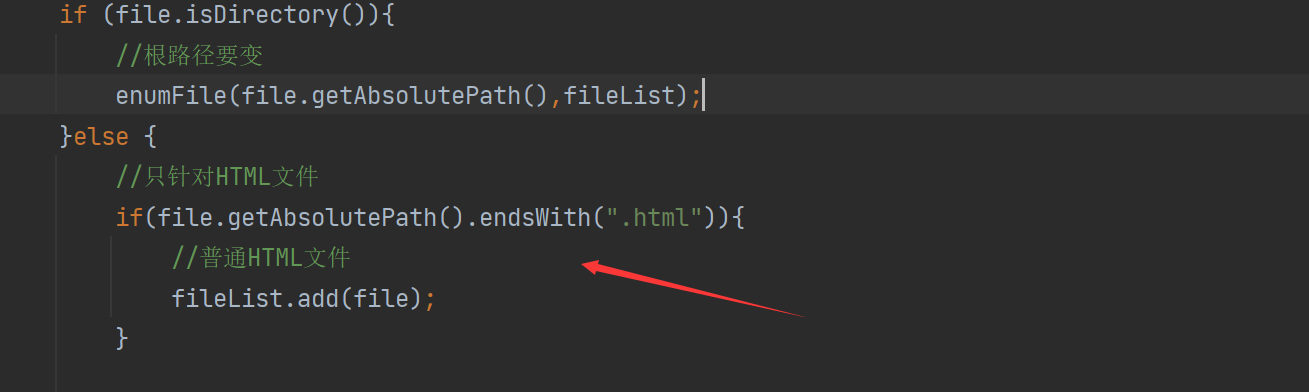
只加了这个的一个判断即可。
3.3 实现索引模块-解析HTML
解析HTML的意思就是:我们一条搜索结果包含了标题,描述,展示URL,这些信息就是来着于要解析的HTML
因此当前的解析HTML操作,就是要把整个HTML文件的标题,描述,URL获取到,其实我们重点要理解这个描述是个啥东西呢?
描述:我们可以视为是正文的一段摘要
因此要想得到描述,就先得到整个正文,所以我们先不管描述,先想办法得到正文。
所以我们的当前任务就是:
解析出HTML标题解析出HTML对应的文章解析出HTML对应的正文(有正文才有后续的描述)import java.io.File;import java.util.ArrayList;/** * Created by Lin * Description: * User: Administrator * Date: 2022-12-15 * Time: 19:15 */public class Parser { //先指定一个加载文档的路径 ,由于是固定路径 我们使用 static 类属性 不需要变final private static final String INPUT_PATH ="D:\\gitee\\doc_searcher_index\\docs\\api"; // 只需要api文件夹下的文件 public void run(){ //整个Parser类的入口 //1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到 ArrayList<File> fileList = new ArrayList<>(); enumFile(INPUT_PATH,fileList); //2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引 for (File f :fileList){ //通过这个方法解析单个HTML文件 System.out.println("开始解析:" + f.getAbsolutePath()); parseHTML(f); } //3.把内存中构造好的索引数据结构,保存到指定的文件中// System.out.println(fileList);// System.out.println(fileList.size()); } //通过这个方法解析单个HTML文件 private void parseHTML(File f) {// 1. 解析出HTML标题 String title = parseTitle(f);// 2. 解析出HTML对应的文章 String url = parseUrl(f);// 3. 解析出HTML对应的正文(有正文才有后续的描述) String content = parseContent(f); } private String parseContent(File f) { } private String parseUrl(File f) { } private String parseTitle(File f) { } //第一个参数表示从那个目录开始进行遍历,第二个目录表示递归得到的结果 private void enumFile(String inputPath, ArrayList<File> fileList) { //我们需要把String类型的路径变成文件类 好操作点 File rootPath = new File(inputPath); //listFiles()类似于Linux的ls把当前目录中包含的文件名获取到 //使用listFiles只可以看见一级目录,想看到子目录需要递归操作 File[] files = rootPath.listFiles(); for (File file : files) { //根据当前的file的类型,觉得是否递归 //如果file是普通文件就把file加入到listFile里面 //如果file是一个目录 就递归调用enumFile这个方法,来进一步获取子目录的内容 if (file.isDirectory()){ //根路径要变 enumFile(file.getAbsolutePath(),fileList); }else { //只针对HTML文件 if(file.getAbsolutePath().endsWith(".html")){ //普通HTML文件 fileList.add(file); } } } } public static void main(String[] args) { //通过main方法来实现整个制作索引的过程 Parser parser = new Parser(); parser.run(); }}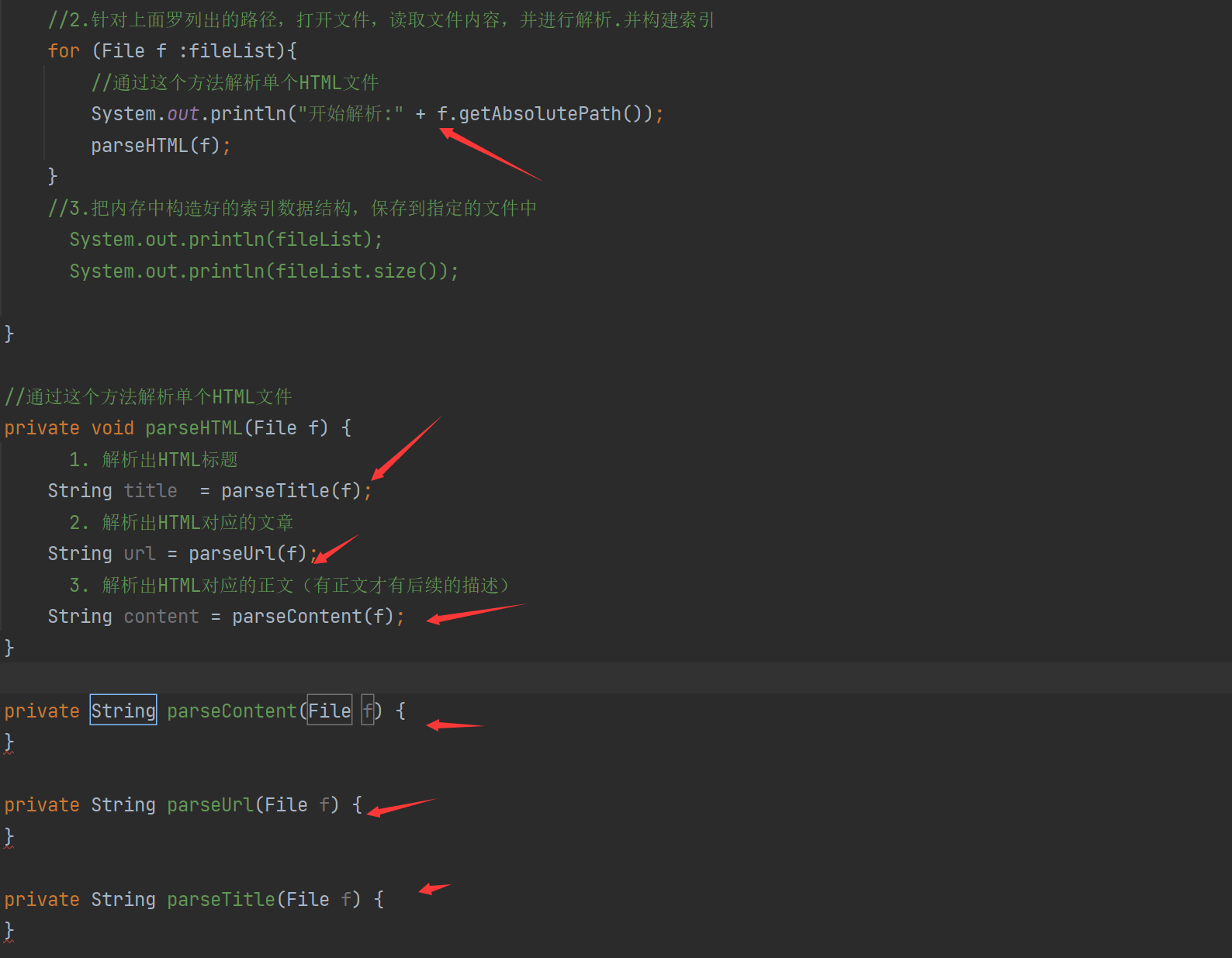
本小节我们增加了解析HTML类,和解析我们需要用到的内容,标题,URL类。
3.4 实现索引模块-解析标题
接下来我们就开始进行解析HTML标题
思路有其二:
找到HTML文件的title标签中的内容就标题 获取文件名获取具体的HTML标题,每个文件名好像和HTML的标题是差不多的。
获取文件名获取具体的HTML标题,每个文件名好像和HTML的标题是差不多的。
所以我们直接选择获取文件名,来获取标题。
这里我们使用的是getName()函数:
输出结果就获取到了HTML文件名
我们需要的搜索结果是标题,不需要带后缀,要去掉
去掉后缀实现思路:使用substring()来实现
这里有个小问题,我们要如何刚刚好把 .html给去掉,这个substring()有个版本是前闭后开,我们只需要找出总长度减去.html的长度即可得到.html的前面部分:
public static void main(String[] args) { File f = new File("D:\\gitee\\doc_searcher_index\\docs\\api\\java\\util\\ArrayList.html"); System.out.println(f.getAbsolutePath()); System.out.println(f.getName().substring(0,f.getName().length()-".html".length())); }.html也是字符串可以使用length();
parseTitle()的实现:
private String parseTitle(File f) { //获取文件名 String name = f.getName(); return name.substring(0,name.length()-".html".length()); }–
3.5 实现索引模块-解析url的思路
其实真正的搜索引擎的展示url和跳转的url是不一样的:有的要先经过搜索引擎的服务器然后在到页面
但是我们这里就不要考虑那么多辣,直接都使用一个url就可以了,既可以展示,也可以跳转。
有人在想为什么要跳到搜索引擎的服务器,因为有如下原因:
如果是广告结果 ,需要根据点击计费自然搜索结果的话,需要根据点击来优化用户体验我们实现url的思路:
因为我们最终期望的效果是:用户点击搜索结果,就能够跳转到对应的线上文档的页面
然后我们发现Java的API文档有两份,线上文档和线下文档然后他们的路径有相同点
https://docs.oracle.com/javase/8/docs/api/java/util/ArrayList.html
D:/gitee/doc_searcher_index/docs/api/java/util/ArrayList.html
可以发现就前面到doc目录不一样其他的一模一样,
我们最终跳转的目的地是官方的:“https://docs.oracle.com/javase/8/docs/api/java/util/ArrayList.html”
所以我们可以使用拼接的方法,先把本地的路径的后半部分路径提前出来保存,在和官网的前面固定的路径一起拼接一下,这样就是实现了他们的关系。
3.6 实现索引模块-解析url代码实现
Test类测试一下:
private static final String INPUT_PATH ="D:\\gitee\\doc_searcher_index\\docs\\api"; // 只需要api文件夹下的文件 public static void main(String[] args) { File f = new File("D:\\gitee\\doc_searcher_index\\docs\\api\\java\\util\\ArrayList.html"); //固定的前缀 String path = "https://docs.oracle.com/javase/8/docs/api/"; //只放一个参数的意思是:前面一段都不需要,取后面的一段 String path2= f.getAbsolutePath().substring(INPUT_PATH.length()); String result = path + path2; System.out.println(result); }其实也就是使用substring的拼接:我们的 INPUT_PATH这个就是前面和官方不一样的路径,我们只需要去掉它拿取后面的就可以了,然后进行拼接。
结果看起来是不是有点变扭,那个斜杠,我们也可以直接使用replaceall替换,也不可以不管,因为把代码复制到浏览器,浏览器会自己解析把整个网址变成正常的那样。主流的浏览器对于这些还是小问题的。
private String parseUrl(File f) { //固定的前缀 String path = "https://docs.oracle.com/javase/8/docs/api/"; //只放一个参数的意思是:前面一段都不需要,取后面的一段 String path2= f.getAbsolutePath().substring(INPUT_PATH.length()); return path + path2; }3.7 实现索引模块-解析正文的思路
实现去除标签可以有很多方式,比如正则表达式,也可以简单粗暴的方式:
我们使用简单粗暴点的,
HTML标签是非常有特点的,我们依次去读取这个HTML中的每个字符,然后针对取出的每个字符进行判定。
看这个结果是否是 < (左尖括号) 那么就从这个位置开始直到遇到 > (右尖括号)为止都不把这些字符放到结果中,换句话说,遇到的 不是 尖括号就直接把当前的字符拷贝到一个结果中(StringBuilder)
演示:
< div> 这个是内容 </ div>
我们读到第一个 < 就把后面的内容不拷贝,如果是 读到的是 > 就把后面的内容开始拷贝,所以我们可以设置一个标志位flag,如果是 < 就为false 关闭拷贝,如果是 > 就为true 打开进行拷贝。
有人会想 万一内容里面有 < or > 字符怎么办呢?其实 htm要求,内容中的 <>使用 &l t;或者&g t;来代替。
3.8 实现索引模块-解析正文的代码实现
public String parseContent(File f) { //先按照一个字符一个字符来读取,以< 和 > 来控制拷贝数据的开关 try(FileReader fileReader = new FileReader(f)) { //加上一个开关 boolean isCopy = true; //还准备一个保存结果的StringBuilder StringBuilder content = new StringBuilder(); while (true){ //read int类型 读到最后返回-1 int ret = fileReader.read(); if (ret == -1){ //表示文件读完了 break; } //不是-1就是合法字符 char c = (char) ret; if (isCopy){ //打开的状态可以拷贝 if (c == '<'){ isCopy =false; continue; } //判断是否是换行 if (c == '\n' || c == '\r'){// 是换行就变成空格 c = ' '; } //其他字符进行拷贝到StringBuilder中 content.append(c); }else{ // if (c=='>'){ isCopy= true; } } } return content.toString(); } catch (IOException e) { e.printStackTrace(); } return ""; }这段代码需要注意的是关闭字符流StringBuilder,不然造成资源泄露,然后就是一下逻辑上的问题,如果是关闭的状态该干嘛,如果打开的状态改干嘛.
3.9 Parser类小结
现在我们解析HTML页面的标题,内容,url以后都是会使用的到的
接下来我们要创建一个索引类然后把解析的信息放进索引,把内存构建好的索引放到指定的文件中。
Parser类代码:
import java.io.File;import java.io.FileNotFoundException;import java.io.FileReader;import java.io.IOException;import java.util.ArrayList;/** * Created by Lin * Description: * User: Administrator * Date: 2022-12-15 * Time: 19:15 */public class Parser { //先指定一个加载文档的路径 ,由于是固定路径 我们使用 static 类属性 不需要变final private static final String INPUT_PATH ="D:\\gitee\\doc_searcher_index\\docs\\api"; // 只需要api文件夹下的文件 public void run(){ //整个Parser类的入口 //1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到 ArrayList<File> fileList = new ArrayList<>(); enumFile(INPUT_PATH,fileList); //2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引 for (File f :fileList){ //通过这个方法解析单个HTML文件 System.out.println("开始解析:" + f.getAbsolutePath()); parseHTML(f); } //3. TODO 把内存中构造好的索引数据结构,保存到指定的文件中 } //通过这个方法解析单个HTML文件 private void parseHTML(File f) {// 1. 解析出HTML标题 String title = parseTitle(f);// 2. 解析出HTML对应的文章 String url = parseUrl(f);// 3. 解析出HTML对应的正文(有正文才有后续的描述) String content = parseContent(f); // 4. TODO 解析的信息加入到索引当中 } public String parseContent(File f) { //先按照一个字符一个字符来读取,以< 和 > 来控制拷贝数据的开关 try(FileReader fileReader = new FileReader(f)) { //加上一个开关 boolean isCopy = true; //还准备一个保存结果的StringBuilder StringBuilder content = new StringBuilder(); while (true){ //read int类型 读到最后返回-1 int ret = fileReader.read(); if (ret == -1){ //表示文件读完了 break; } //不是-1就是合法字符 char c = (char) ret; if (isCopy){ //打开的状态可以拷贝 if (c == '<'){ isCopy =false; continue; } //判断是否是换行 if (c == '\n' || c == '\r'){// 是换行就变成空格 c = ' '; } //其他字符进行拷贝到StringBuilder中 content.append(c); }else{ // if (c=='>'){ isCopy= true; } } } return content.toString(); } catch (IOException e) { e.printStackTrace(); } return ""; } private String parseUrl(File f) { //固定的前缀 String path = "https://docs.oracle.com/javase/8/docs/api/"; //只放一个参数的意思是:前面一段都不需要,取后面的一段 String path2= f.getAbsolutePath().substring(INPUT_PATH.length()); return path + path2; } private String parseTitle(File f) { //获取文件名 String name = f.getName(); return name.substring(0,name.length()-".html".length()); } //第一个参数表示从那个目录开始进行遍历,第二个目录表示递归得到的结果 private void enumFile(String inputPath, ArrayList<File> fileList) { //我们需要把String类型的路径变成文件类 好操作点 File rootPath = new File(inputPath); //listFiles()类似于Linux的ls把当前目录中包含的文件名获取到 //使用listFiles只可以看见一级目录,想看到子目录需要递归操作 File[] files = rootPath.listFiles(); for (File file : files) { //根据当前的file的类型,觉得是否递归 //如果file是普通文件就把file加入到listFile里面 //如果file是一个目录 就递归调用enumFile这个方法,来进一步获取子目录的内容 if (file.isDirectory()){ //根路径要变 enumFile(file.getAbsolutePath(),fileList); }else { //只针对HTML文件 if(file.getAbsolutePath().endsWith(".html")){ //普通HTML文件 fileList.add(file); } } } } public static void main(String[] args) { //通过main方法来实现整个制作索引的过程 Parser parser = new Parser(); parser.run(); }}四、实现索引模块-Index类
我们需要创建一个Index类,这个类主要实现是在内存中来构造出索引结构
//通过这个类在内存中来构造出索引结构public class Index { //这个类需要提供的方法 //1.给定一个docId ,在正排索引中,查询文档的详细信息 public DocInfo getDocInfo(int docId){ //TODO return null; } //2.给定一词,在倒排索引中,查哪些文档和这个文档词关联 public List<Weight> getInverted(String term){ //TODO return null; } //3.往索引中新增一个文档 public void addDoc(String title,String url,String content){ //TODO } //4.把内存中的索引结构保存到磁盘中 public void save(){ //TODO } //5.把磁盘中的索引数据加载到内存中 public void load(){ //TODO }}接下来来一一解释一下各个函数是什么意思:
public DocInfo getDocInfo(int docId) // 给定一个docId ,在正排索引中,查询文档的详细信息这个类其实个正排索引,给个文档ID 获取文档信息内容,所以我们要让返回值表示具体的返回内容,所以我们新创建一个类
public class DocInfo { private int docId; private String title; private String url; private String content; public String getUrl() { return url; } public String getTitle() { return title; } public void setTitle(String title) { this.title = title; } public void setUrl(String url) { this.url = url; } public String getContent() { return content; } public void setContent(String content) { this.content = content; } public int getDocId() { return docId; } public void setDocId(int docId) { this.docId = docId; }}这几个属性也就是我们前面解析出来的,要让他们有一定的关联关系。
–
public List<Weight> getInverted(String term) //给定一个词,在倒排索引中,查哪些文档和这个文档词关联因为文档词可能和很多文档有关联,所以我们就使用List这个集合来接收,参数是 分词的结果,因为用户可能搜索词是一段话,我们不是把一段话去查,而是分词之后,分别去查。 List<Weight> 这个Weight是文章的权重,就是查询词和有的文档相关性强一点,有点相关性弱一点。
//文档ID和文档的相关性 权重进行包裹public class Weight { private int docId; public int getDocId() { return docId; } public void setDocId(int docId) { this.docId = docId; } public int getWeight() { return weight; } public void setWeight(int weight) { this.weight = weight; } //这个weight就表示文档和词的相关性 //这个值越大,就认为相关性越强 private int weight;}这个weight就表示文档和词的相关性,这个值越大,就认为相关性越强
public void addDoc(String title,String url,String content)往索引里面新增一个文档。
public void save()把内存中的索引结构保存到磁盘当中
public void load()把磁盘中的索引数据加载到内存中
4.1 实现索引模块 - 实现索引结构
实现正排索引的具体结构:
使用ArrayList表示正排索引,如果DocID为0那么东西就放在0位置上,如果为100就放在100的位置上,这样通过ArrayList的get方法根据下标找到对应的元素,这个是正排索引的表示。
实现倒排索引的具体结构:
我们使用哈希表来表示倒排索引 key就是搜索词 ,value就是一组和词相关的文章,所以我们使用ArrayList,为什么泛型使用Weight呢,因为这个既包含了DocId又包含了相关性(权重)
代码:
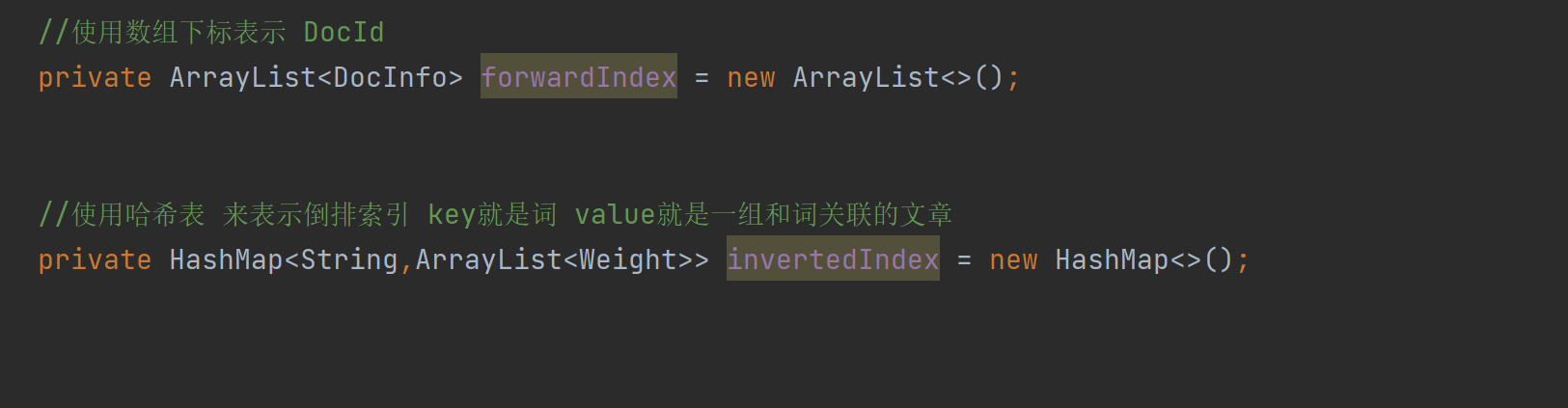
import java.util.ArrayList;import java.util.HashMap;import java.util.List;/** * Created by Lin * Description: * User: Administrator * Date: 2022-12-17 * Time: 13:01 *///通过这个类在内存中来构造出索引结构public class Index { //使用数组下标表示 DocId private ArrayList<DocInfo> forwardIndex = new ArrayList<>(); //使用哈希表 来表示倒排索引 key就是词 value就是一组和词关联的文章 private HashMap<String,ArrayList<Weight>> invertedIndex = new HashMap<>(); //这个类需要提供的方法 //1.给定一个docId ,在正排索引中,查询文档的详细信息 public DocInfo getDocInfo(int docId){ return forwardIndex.get(docId); } //2.给定一词,在倒排索引中,查哪些文档和这个文档词关联 public List<Weight> getInverted(String term){ return invertedIndex.get(term); } //3.往索引中新增一个文档 public void addDoc(String title,String url,String content){ //TODO } //4.把内存中的索引结构保存到磁盘中 public void save(){ //TODO } //5.把磁盘中的索引数据加载到内存中 public void load(){ //TODO }}–
4.2 实现索引模块- 实现正排索引
我们前面已经解析好了那些需要的东西:
现在开始要往索引里面新增文档了,既要往正排索引里面放,也要往倒排索引里面放,先看看正排的这个简单:
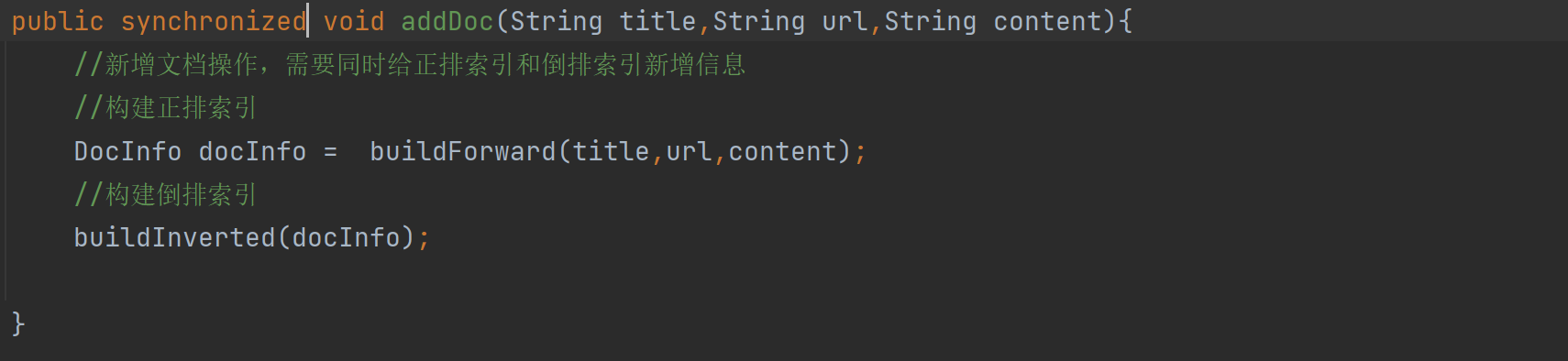
//3.往索引中新增一个文档 public void addDoc(String title,String url,String content){ //新增文档操作,需要同时给正排索引和倒排索引新增信息 //构建正排索引 DocInfo docInfo = buildForward(title,url,content); //构建倒排索引 buildInverted(docInfo); //TODO } private DocInfo buildForward(String title, String url, String content) { DocInfo docInfo =new DocInfo(); docInfo.setDocId(forwardIndex.size()); docInfo.setTitle(title); docInfo.setUrl(url); docInfo.setContent(content); forwardIndex.add(docInfo); return docInfo; }我们主要来看看这些代码:正排索引
private DocInfo buildForward(String title, String url, String content) { DocInfo docInfo =new DocInfo(); docInfo.setDocId(forwardIndex.size()); docInfo.setTitle(title); docInfo.setUrl(url); docInfo.setContent(content); forwardIndex.add(docInfo); return docInfo; }这个代码是因为正排构造其实就是把解析好的三个参数插入到DocInfo里面,重点是DocId,我们如何让他实现从0,1,2,3这样的自增,后面其实发现,如果ArrayList在没有add加入值的时候,那个size()就是0,当我们进行 forwardIndex.add(docInfo); 过后才会变成1。然后在add就变成了2,依次。
4.3 实现索引模块- 实现构建倒排索引
来看看倒排索引的思路:
倒排索引,就是词 到文档id 之间的映射,我们要知道当前的文档都有哪些词。
因此我们要对当前的文档进行分词,分词要针对标题和正文分词,然后结合分词的结果,就知道当前的的文档id应该加入那个倒排索引的key中。
我们要记住倒排索引就是一个键值对结构(Hash Map),key是分词的结果(term) ,value是一组和这个分词结果相当的文档列表
因此就可以先针对当前的文档进行分词,然后根据分词结果,去倒排索引中,找到对应的value,然后把当前的文档id给加入到对应的value列表中即可。
还有一个问题,我们的倒排索引不止是一个哈希表,它的参数还有,ArrayList< Weight >,这个值描述了词和文档之间的相关性。
我们的相关性表示为:词在文章中出现的次数越高,相关性就越高,这个是我们自己简单粗暴的方法,在真实的搜索引擎中,相关性是一个算法团队来做的事情的。
所以我们接下来要做的事情:
针对文档标题进行分词遍历分词结果,统计每个词出现的次数针对正文进行分词遍历分词结果,统计每个词出现的次数把上面的结果汇总到一个HasMap里面最终的文档的权重,设置为标题的出现次数 * 10 + 正文中出现的次数
4.4 如何改进权重公式
我们介绍一下真正的工作环境是怎么样进行实现改进的,要想针对执行公司进行改进,我们得先有办法来评估这个公式的好坏。
真正的搜索引擎,往往是使用“点击率” 这样的概念来进行衡量 :点击率= 点击次数 / (除以) 展示次数
比如搜索的时候,啥都没有做然后关闭浏览器,一个页面就是一次展示。
如果我们搜索了页面,并且点击跳转了一个页面,那么这个搜索结果的点击率就是百分之百,所以一般不会百分之百,可能真实的千分之几。这个也正常,毕竟一个搜索结果几千个内容,不可能每一个都去一下。
我们竟然可以通过点击率这样的策略,那么我们还可以使用其他的多个策略。
对于真实的搜索引擎项目流量比较大,假设每天有一亿访问量,那么我们就可以把这个一亿访问量拆成若干份,30%,30%,40%,我们就可以让第一个 百分之三十使用A公式,第二个百分之三十使用B公式,在百分之四十使用C公式,然后分别统计点击率如何,经过一系列的迭代,公式会越来越复杂,同时点击效果越来越好。最后选最好的公式即可。这样的工作中称为小流量实验,公式行就一点点的放大效果。
4.5实现索引模块- 实现词频统计
我们现在要实现一个词频统计的功能:
private void buildInverted(DocInfo docInfo) { //搞一个内部类避免出现2个哈希表 class WordCnt{ //表示这个词在标题中 出现的次数 public int titleCount ; // 表示这个词在正文出现的次数 public int contentCount; } //统计词频的数据结构 HashMap<String,WordCnt> wordCntHashMap =new HashMap<>(); //1,针对文档标题进行分词 为什么可以直接docInfo取值,是因为上次的正派索引里面已经有内容了 List<Term> terms = ToAnalysis.parse( docInfo.getTitle()).getTerms(); //2. 遍历分词结果,统计每个词出现的比例 for (Term term : terms){ //先判定一个term这个词是否存在,如果不存在,就创建一个新的键值对,插入进去,titleCount 设为1 //gameName()的分词的具体的词 String word = term.getName(); //哈希表的get如果不存在默认返回的是null WordCnt wordCnt = wordCntHashMap.get(word); if (wordCnt == null){ //词不存在 WordCnt newWordCnt = new WordCnt(); newWordCnt.titleCount =1; newWordCnt.contentCount = 0; wordCntHashMap.put(word,newWordCnt); }else{ //存在就找到之前的值,然后加1 wordCnt.titleCount +=1; } //如果存在,就找到之前的值,然后把对应的titleCount +1 } //3. 针对正文进行分词 terms = ToAnalysis.parse(docInfo.getContent()).getTerms(); for (Term term : terms) { String word = term.getName(); WordCnt wordCnt = wordCntHashMap.get(word); if (wordCnt == null){ WordCnt newWordCnt = new WordCnt(); newWordCnt.titleCount = 0; newWordCnt.contentCount = 1; wordCntHashMap.put(word,newWordCnt); }else { wordCnt.contentCount +=1; } } //4. 遍历分词结果,统计每个词出现的次数 //5. 把上面的结果汇总到一个HasMap里面 // 最终的文档的权重,设置为标题的出现次数 * 10 + 正文中出现的次数 //遍历当前的HashMap,依次来更新倒排索引中的结构。 }我们先直接来看一下这个图: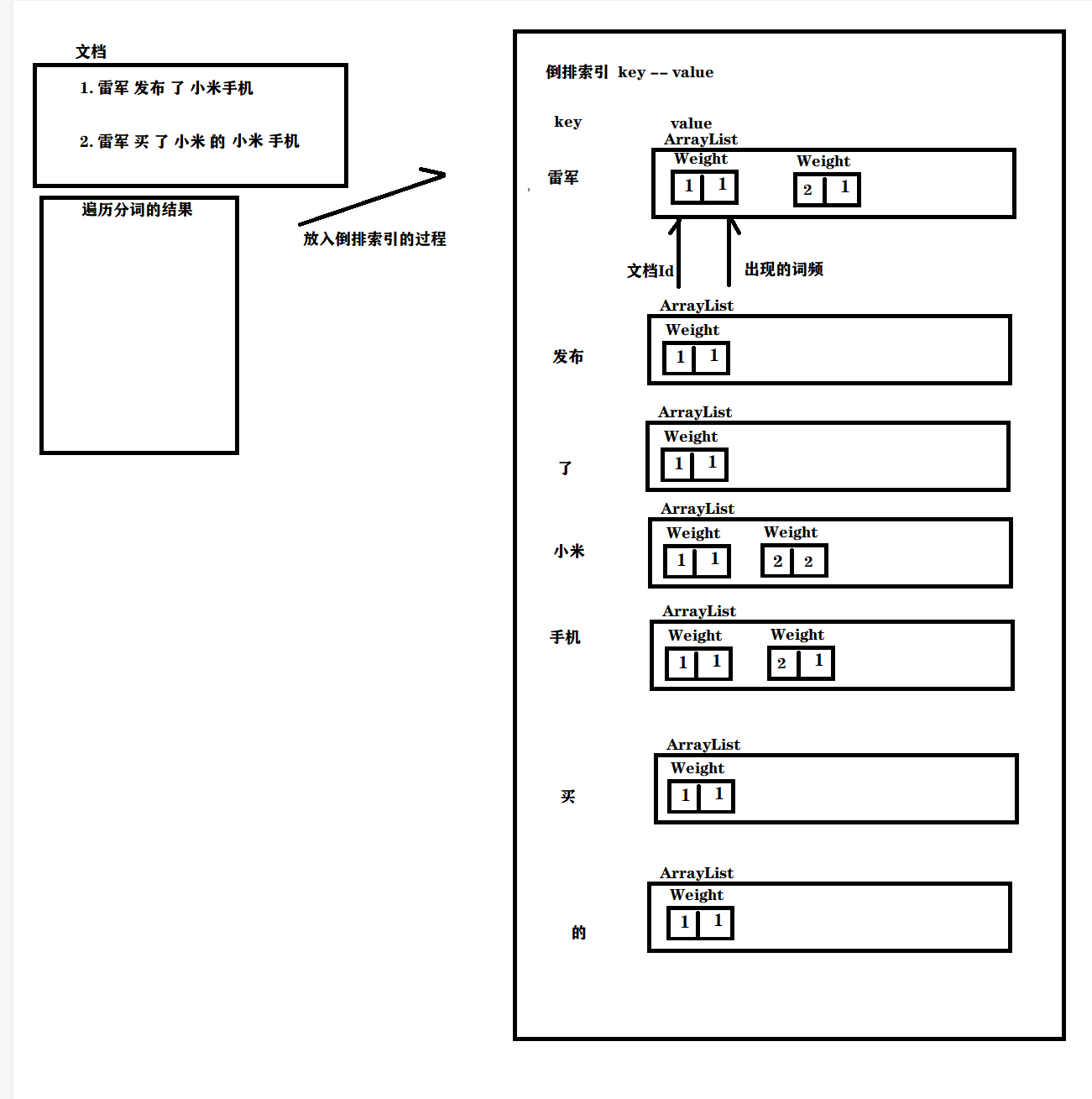
其实就是没有的词就先看看词在倒排索引中存在了没,没有存在就插入,存在就在已有的地方继续存放对应的代码就是:
WordCnt wordCnt = wordCntHashMap.get(word); if (wordCnt == null){ //词不存在 WordCnt newWordCnt = new WordCnt(); newWordCnt.titleCount =1; newWordCnt.contentCount = 0; wordCntHashMap.put(word,newWordCnt); }else{ //存在就找到之前的值,然后加1 wordCnt.titleCount +=1; }再来解释一下Weight那个东西: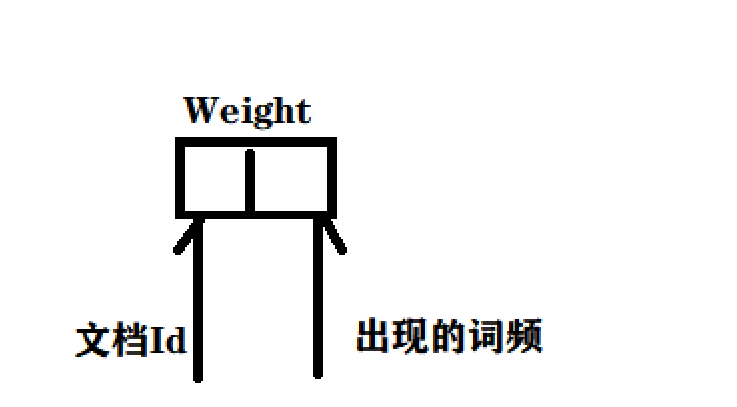
这个其实就是文档id,和出现的词频:
文档id号为2 : 雷军买了小米的小米手机
这个就会得到一个这样的倒排索引部分的图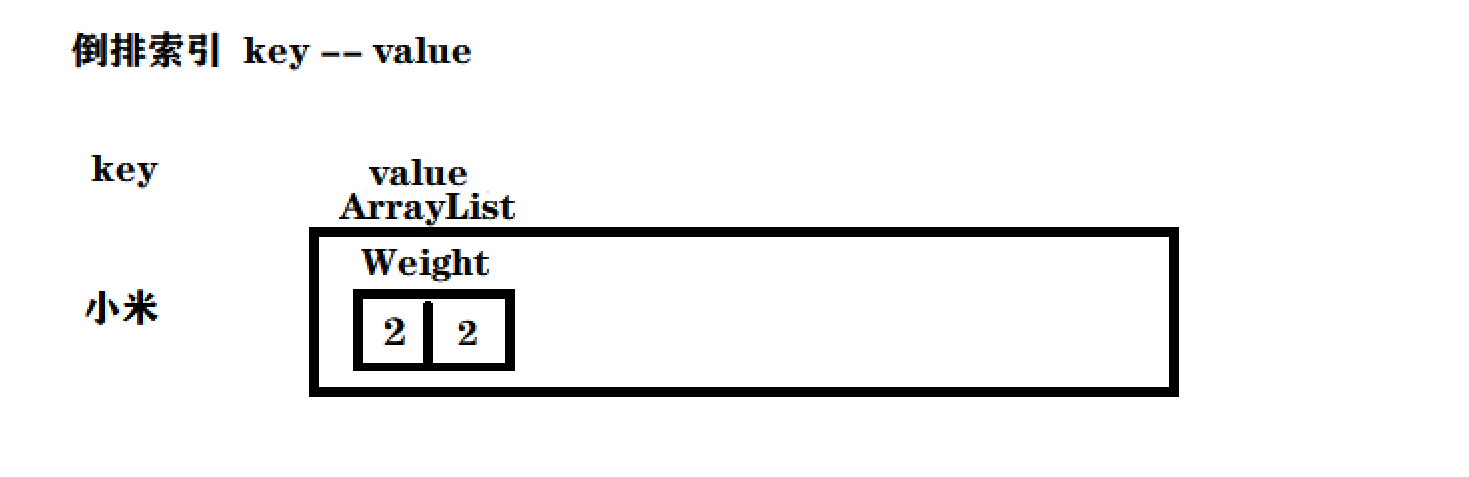
意思就是小米这个字 在2号文章出现过2次,这样就实现了词频的统计了。
4.6实现索引模块 -构造倒排索引代码实现
private void buildInverted(DocInfo docInfo) { //搞一个内部类避免出现2个哈希表 class WordCnt{ //表示这个词在标题中 出现的次数 public int titleCount ; // 表示这个词在正文出现的次数 public int contentCount; } //统计词频的数据结构 HashMap<String,WordCnt> wordCntHashMap =new HashMap<>(); //1,针对文档标题进行分词 List<Term> terms = ToAnalysis.parse( docInfo.getTitle()).getTerms(); //2. 遍历分词结果,统计每个词出现的比例 for (Term term : terms){ //先判定一个term这个词是否存在,如果不存在,就创建一个新的键值对,插入进去,titleCount 设为1 //gameName()的分词的具体的词 String word = term.getName(); //哈希表的get如果不存在默认返回的是null WordCnt wordCnt = wordCntHashMap.get(word); if (wordCnt == null){ //词不存在 WordCnt newWordCnt = new WordCnt(); newWordCnt.titleCount =1; newWordCnt.contentCount = 0; wordCntHashMap.put(word,newWordCnt); }else{ //存在就找到之前的值,然后加1 wordCnt.titleCount +=1; } //如果存在,就找到之前的值,然后把对应的titleCount +1 } //3. 针对正文进行分词 terms = ToAnalysis.parse(docInfo.getContent()).getTerms(); //4. 遍历分词结果,统计每个词出现的次数 for (Term term : terms) { String word = term.getName(); WordCnt wordCnt = wordCntHashMap.get(word); if (wordCnt == null){ WordCnt newWordCnt = new WordCnt(); newWordCnt.titleCount = 0; newWordCnt.contentCount = 1; wordCntHashMap.put(word,newWordCnt); }else { wordCnt.contentCount +=1; } } //5. 把上面的结果汇总到一个HasMap里面 // 最终的文档的权重,设置为标题的出现次数 * 10 + 正文中出现的次数 //6.遍历当前的HashMap,依次来更新倒排索引中的结构。 for(Map.Entry<String,WordCnt> entry:wordCntHashMap.entrySet()){ //先根据这里的词去倒排索引中查一查词 //倒排拉链 List<Weight> invertedList = invertedIndex.get(entry.getKey()); if (invertedList == null){ //如果为空,插入一个新的键值对 ArrayList<Weight> newInvertedList =new ArrayList<>(); Weight weight = new Weight(); weight.setDocId(docInfo.getDocId()); //权重计算公式:标题中出现的次数* 10 +正文出现的次数 weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount); newInvertedList.add(weight); invertedIndex.put(entry.getKey(),newInvertedList); }else{ //如果非空 ,就把当前的文档,构造出一个Weight 对象,插入到倒排拉链的后面 Weight weight = new Weight(); weight.setDocId(docInfo.getDocId()); //权重计算公式:标题中出现的次数* 10 +正文出现的次数 weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount); invertedList.add(weight); } } }
这个部分写的是这里的代码:先搞清楚为什么需要一个Map.Entrt来这个是个什么:
并不是全部代码都是可以for循环的,只有这个对象是”可迭代的“,实现Iterable 接口才可以但是Map并没有实现,Map存在意义,是根据key查找value,但是好在Set实现了实现Iterable,就可以把Map转换为Set本来Map存在的是戒键值对,可以根据key快速找到value,Set这里存的是一个把 键值对 打包在一起的类 称为Entry(条目)转成Set之后,失去了快速根据key快速查找value的只这样的能力,但是换来了可以遍历每一个是一个键值对就变成了一个Entry类: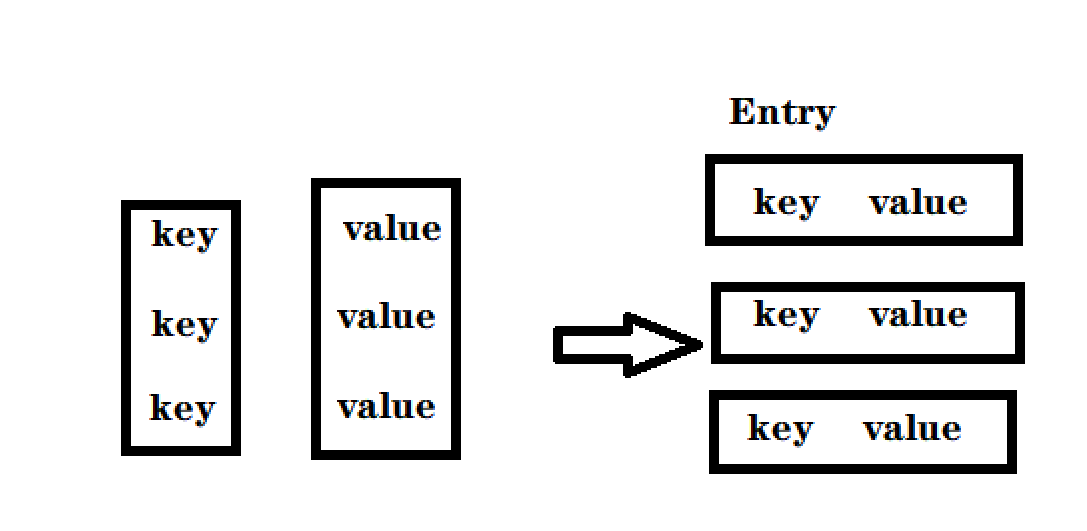
我们知道我们的倒排索引是这样的一个结构:
key是个词,值是一组文档,
我们根据词查找有没有在到索引有这个文章,返回值就是一个一组文章
如果这个为为空,我们就新搞一个键值对:
倒排索引需要的是词和一组文章:
我们发现还没有装文章的容器,使用先搞个容器
然后我们需要搞一个Weight对象,把文章的id和权重放进去这个容器。
这里要注意权重的设置,我们这个Entry的键就是那个String的词,而且词就是上面词频统计的类:所以我们可以直接获取到Entry的value就是词频,然后根据权重公式来设置权重。
最后把构建好的新的键值对放到倒排索引里面即可。

如果词不是非空的话,那么我们就把docId 和权重设置好
最后其实最重要的倒排索引的构建我觉得就是这段代码:
4.7实现索引模块-保存加载索引的背景
我们现在是把索引构建好了,但是现在 还是有个问题啊,我们索引当前是在内存里面的,但是我们要保存在硬盘中,因为我们构建索引的过程比较耗时间的: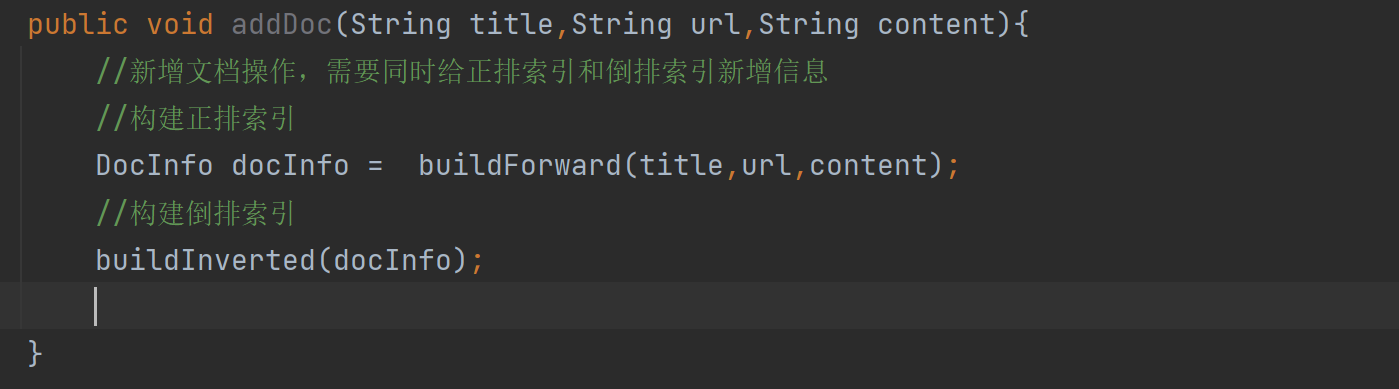
每次我们调它一次就构建一次,但是我们是成千上万了文档,真正的搜索引擎文档可以数以亿记,甚至几十亿。如果这样搞的话会很慢的。
因此我们不应该在服务器启动的时候构建索引(启动服务器可能会被拖慢好多)。
所以我们拆分开这些耗时的操作,单独去进行完成。单独执行完了之后,我们在让线上服务器直接加载这个构造好的索引
具体怎么保存到文件中呢?文件无非就是二进制数据要么就是文本数据,说白了文本数据就是“字符串”,我们把内存中的索引结构,变成一个字符串,然后写文件即可也可以叫做序列化,对应的把特定的结果的字符串,反向解析成一些结构化数据(类、对象,基础数据结构)可叫做反序列化。
序列化和反序列化有很多现成的方法,此处我们就直接使用Json格式来进行序列化/ 反序列化-使用jackson 这个库,很简单的就可以序列化和反序列化。
4.8实现索引模块-实现保存索引文件
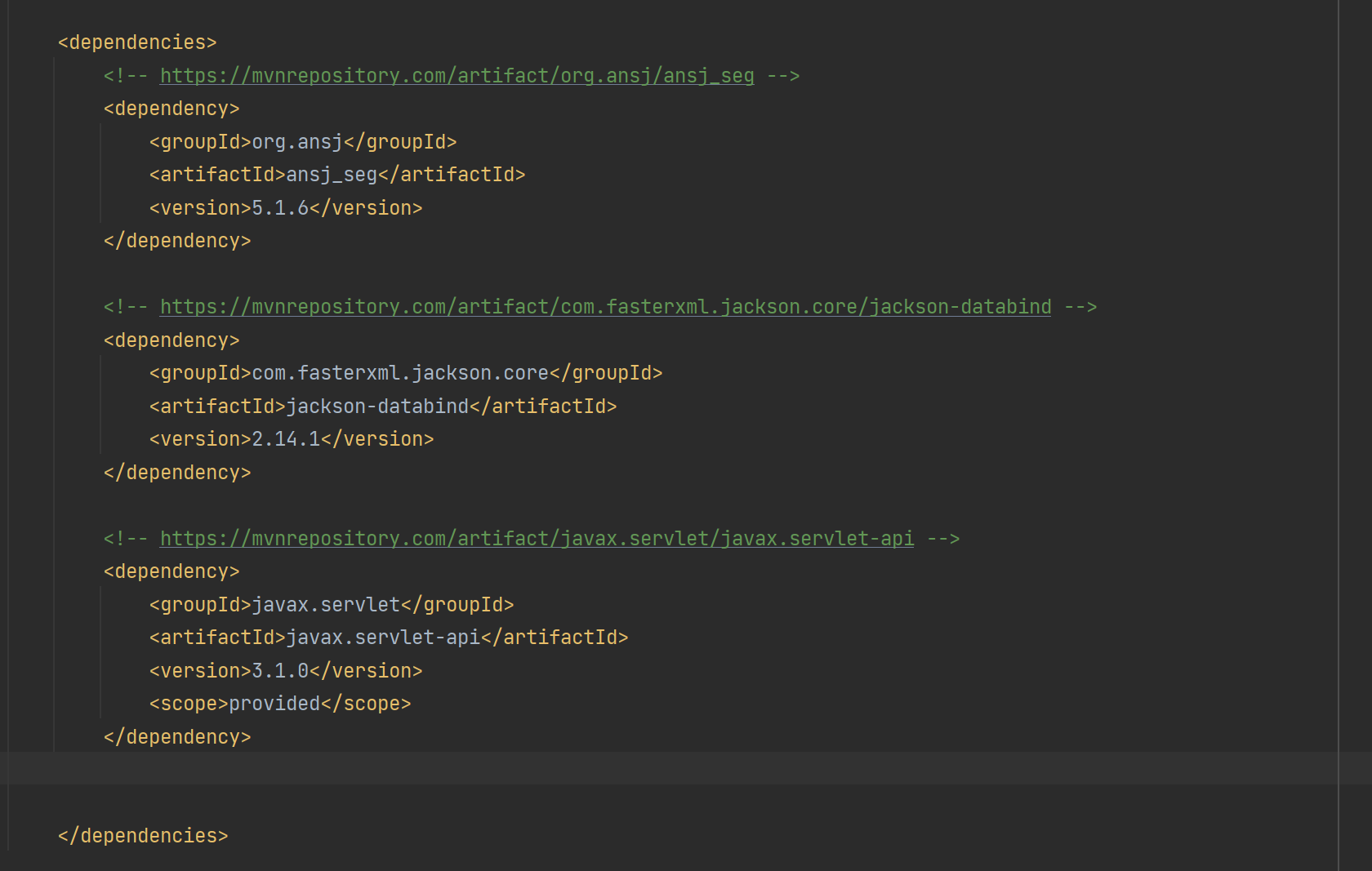
Jackson的maven地址:JacksonMaven地址
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind --><dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.14.1</version></dependency>刷新一下:
先创建一个库的实例:
保存索引文件的路径:(要2个反斜杠,最后也要)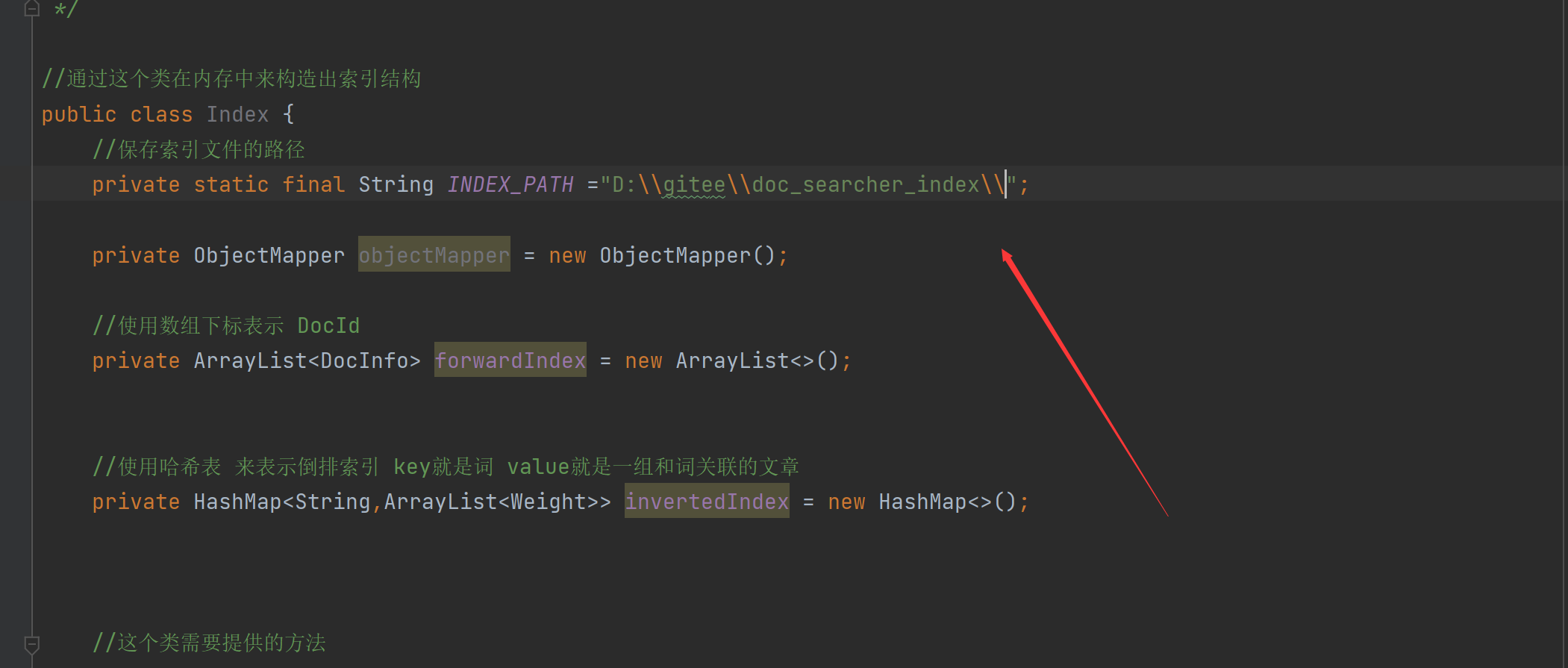
//4.把内存中的索引结构保存到磁盘中 public void save(){ //使用2个文件。分别保存正排和倒排 System.out.println("保存索引开始"); //1.先判断一下索引对应的目录是否存在 File indexPathFile =new File(INDEX_PATH); if (!indexPathFile.exists()){ //如果路径不存在 //mkdirs()可以创建多级目录 indexPathFile.mkdirs(); } //创建正排索引文件 File forwardIndexFile = new File(INDEX_PATH+"forward.txt"); //创建倒排索引文件 File invertedIndexFile = new File(INDEX_PATH+"inverted.txt"); try { //writeValue的有个参数可以把对象写到文件里 objectMapper.writeValue(forwardIndexFile,forwardIndex); objectMapper.writeValue(invertedIndexFile,invertedIndex); }catch (IOException e){ e.printStackTrace(); } System.out.println("保存索引完成"); }4.9实现索引模块-实现加载索引
保存就是把内存的数据写到文件里,加载就是把文件里的数据写回到内存中,制作索引阶段要去保存,服务器程序的使用就需要去加载:
//5.把磁盘中的索引数据加载到内存中 public void load(){ System.out.println("加载索引开始"); //1.设置加载索引路径 //正排索引 File forwardIndexFile = new File(INDEX_PATH+"forward.txt"); //倒排索引 File invertedIndexFile = new File(INDEX_PATH+"inverted.txt"); try{ //readValue()2个参数,从那个文件读,解析是什么数据 forwardIndex = objectMapper.readValue(forwardIndexFile, new TypeReference<ArrayList<DocInfo>>() {}); invertedIndex = objectMapper.readValue(invertedIndexFile, new TypeReference<HashMap<String, ArrayList<Weight>>>() {}); }catch (IOException e){ e.printStackTrace(); } System.out.println("加载索引结束"); }其实我们就是来看看 我们怎么样把文件的内容写回到内存的,这里还是使用的是Jackson的库函数 readValue(),这个是有2个参数,一个是从哪里读取,第二个参数是解析的是什么样的格式,这里这个库函数给了一个 new TypeReference<> ,中括号里面就可以填你要解析的格式。
4.10实现索引模块-给加载保存操作加上时间
//4.把内存中的索引结构保存到磁盘中 public void save(){ long beg = System.currentTimeMillis(); //使用2个文件。分别保存正排和倒排 System.out.println("保存索引开始"); //1.先判断一下索引对应的目录是否存在 File indexPathFile =new File(INDEX_PATH); if (!indexPathFile.exists()){ //如果路径不存在 //mkdirs()可以创建多级目录 indexPathFile.mkdirs(); } //正排索引文件 File forwardIndexFile = new File(INDEX_PATH+"forward.txt"); //倒排索引文件 File invertedIndexFile = new File(INDEX_PATH+"inverted.txt"); try { //writeValue的有个参数可以把对象写到文件里 objectMapper.writeValue(forwardIndexFile,forwardIndex); objectMapper.writeValue(invertedIndexFile,invertedIndex); }catch (IOException e){ e.printStackTrace(); } long end = System.currentTimeMillis(); System.out.println("保存索结束 !消耗时间"+(end - beg)+"ms"); } //5.把磁盘中的索引数据加载到内存中 public void load(){ long beg = System.currentTimeMillis(); System.out.println("加载索引开始"); //1.设置加载索引路径 //正排索引 File forwardIndexFile = new File(INDEX_PATH+"forward.txt"); //倒排索引 File invertedIndexFile = new File(INDEX_PATH+"inverted.txt"); try{ //readValue()2个参数,从那个文件读,解析是什么数据 forwardIndex = objectMapper.readValue(forwardIndexFile, new TypeReference<ArrayList<DocInfo>>() {}); invertedIndex = objectMapper.readValue(invertedIndexFile, new TypeReference<HashMap<String, ArrayList<Weight>>>() {}); }catch (IOException e){ e.printStackTrace(); } long end = System.currentTimeMillis(); System.out.println("加载索引结束 ! 消耗时间"+(end -beg)+"ms"); }我们可以给耗时的部分加上时间,这样能更加直观的对比。
4.11实现索引模块-在parser中调用index
我们把index的核心代码是写的差不多了,我们需要让index类和parser类有关联
他们之间的关系就是:
Parser类相当于制作索引的入口 对应到一个可执行的程序。
index相当于实现了索引的数据结构,并且提供了一些api供上级使用,因此index给parser调用。
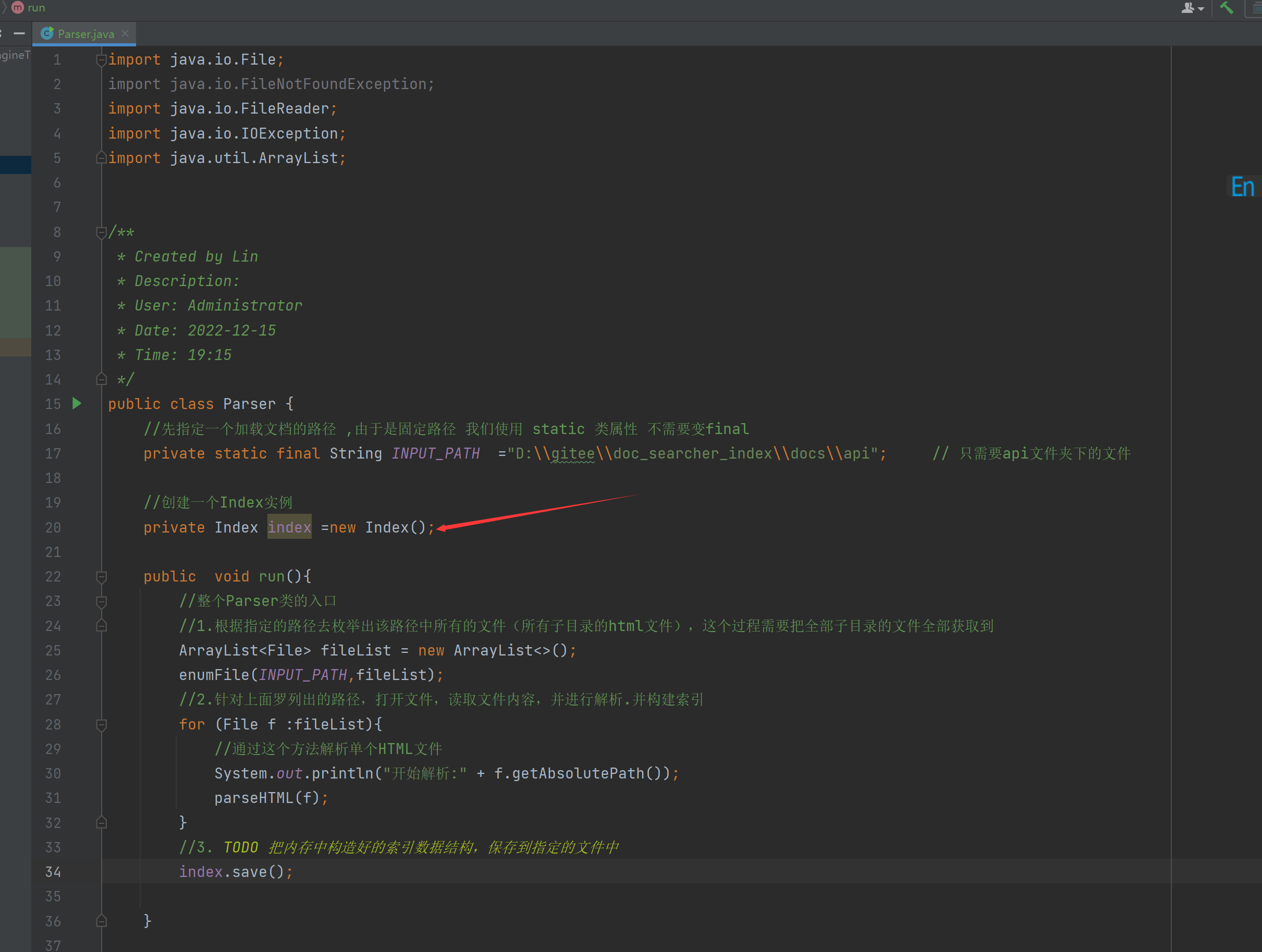
然后在到run方法把构造好的索引,保存到指定文件中,把解析单个HTML文件加到索引中。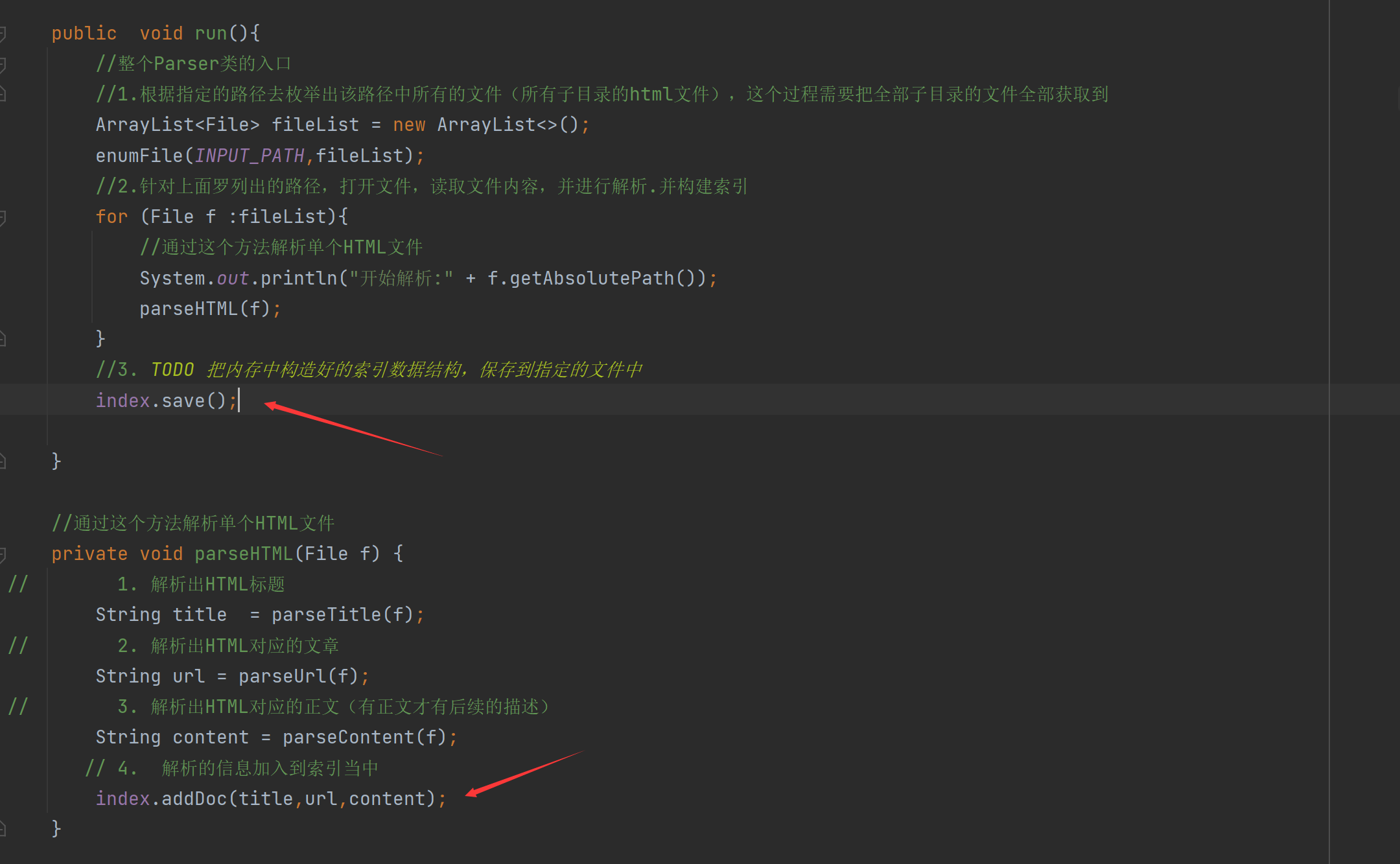
4.12实现索引模块-验证索引制作
我们现在来看看代码是否可以制作索引文件:把2个类的完整代码放出
Parser类:
import java.io.File;import java.io.FileNotFoundException;import java.io.FileReader;import java.io.IOException;import java.util.ArrayList;/** * Created by Lin * Description: * User: Administrator * Date: 2022-12-15 * Time: 19:15 */public class Parser { //先指定一个加载文档的路径 ,由于是固定路径 我们使用 static 类属性 不需要变final private static final String INPUT_PATH ="D:\\gitee\\doc_searcher_index\\docs\\api"; // 只需要api文件夹下的文件 //创建一个Index实例 private Index index =new Index(); public void run(){ //整个Parser类的入口 //1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到 ArrayList<File> fileList = new ArrayList<>(); enumFile(INPUT_PATH,fileList); //2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引 for (File f :fileList){ //通过这个方法解析单个HTML文件 System.out.println("开始解析:" + f.getAbsolutePath()); parseHTML(f); } //3. TODO 把内存中构造好的索引数据结构,保存到指定的文件中 index.save(); } //通过这个方法解析单个HTML文件 private void parseHTML(File f) {// 1. 解析出HTML标题 String title = parseTitle(f);// 2. 解析出HTML对应的文章 String url = parseUrl(f);// 3. 解析出HTML对应的正文(有正文才有后续的描述) String content = parseContent(f); // 4. 解析的信息加入到索引当中 index.addDoc(title,url,content); } public String parseContent(File f) { //先按照一个字符一个字符来读取,以< 和 > 来控制拷贝数据的开关 try(FileReader fileReader = new FileReader(f)) { //加上一个开关 boolean isCopy = true; //还准备一个保存结果的StringBuilder StringBuilder content = new StringBuilder(); while (true){ //read int类型 读到最后返回-1 int ret = fileReader.read(); if (ret == -1){ //表示文件读完了 break; } //不是-1就是合法字符 char c = (char) ret; if (isCopy){ //打开的状态可以拷贝 if (c == '<'){ isCopy =false; continue; } //判断是否是换行 if (c == '\n' || c == '\r'){// 是换行就变成空格 c = ' '; } //其他字符进行拷贝到StringBuilder中 content.append(c); }else{ // if (c=='>'){ isCopy= true; } } } return content.toString(); } catch (IOException e) { e.printStackTrace(); } return ""; } private String parseUrl(File f) { //固定的前缀 String path = "https://docs.oracle.com/javase/8/docs/api/"; //只放一个参数的意思是:前面一段都不需要,取后面的一段 String path2= f.getAbsolutePath().substring(INPUT_PATH.length()); return path + path2; } private String parseTitle(File f) { //获取文件名 String name = f.getName(); return name.substring(0,name.length()-".html".length()); } //第一个参数表示从那个目录开始进行遍历,第二个目录表示递归得到的结果 private void enumFile(String inputPath, ArrayList<File> fileList) { //我们需要把String类型的路径变成文件类 好操作点 File rootPath = new File(inputPath); //listFiles()类似于Linux的ls把当前目录中包含的文件名获取到 //使用listFiles只可以看见一级目录,想看到子目录需要递归操作 File[] files = rootPath.listFiles(); for (File file : files) { //根据当前的file的类型,觉得是否递归 //如果file是普通文件就把file加入到listFile里面 //如果file是一个目录 就递归调用enumFile这个方法,来进一步获取子目录的内容 if (file.isDirectory()){ //根路径要变 enumFile(file.getAbsolutePath(),fileList); }else { //只针对HTML文件 if(file.getAbsolutePath().endsWith(".html")){ //普通HTML文件 fileList.add(file); } } } } public static void main(String[] args) { //通过main方法来实现整个制作索引的过程 Parser parser = new Parser(); parser.run(); }}Index类:
import com.fasterxml.jackson.core.type.TypeReference;import com.fasterxml.jackson.databind.ObjectMapper;import org.ansj.domain.Term;import org.ansj.splitWord.analysis.ToAnalysis;import java.io.File;import java.io.IOException;import java.lang.reflect.Field;import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;/** * Created by Lin * Description: * User: Administrator * Date: 2022-12-17 * Time: 13:01 *///通过这个类在内存中来构造出索引结构public class Index { //保存索引文件的路径 private static final String INDEX_PATH ="D:\\gitee\\doc_searcher_index\\"; private ObjectMapper objectMapper = new ObjectMapper(); //使用数组下标表示 DocId private ArrayList<DocInfo> forwardIndex = new ArrayList<>(); //使用哈希表 来表示倒排索引 key就是词 value就是一组和词关联的文章 private HashMap<String,ArrayList<Weight>> invertedIndex = new HashMap<>(); //这个类需要提供的方法 //1.给定一个docId ,在正排索引中,查询文档的详细信息 public DocInfo getDocInfo(int docId){ return forwardIndex.get(docId); } //2.给定一词,在倒排索引中,查哪些文档和这个文档词关联 public List<Weight> getInverted(String term){ return invertedIndex.get(term); } //3.往索引中新增一个文档 public void addDoc(String title,String url,String content){ //新增文档操作,需要同时给正排索引和倒排索引新增信息 //构建正排索引 DocInfo docInfo = buildForward(title,url,content); //构建倒排索引 buildInverted(docInfo); } private void buildInverted(DocInfo docInfo) { //搞一个内部类避免出现2个哈希表 class WordCnt{ //表示这个词在标题中 出现的次数 public int titleCount ; // 表示这个词在正文出现的次数 public int contentCount; } //统计词频的数据结构 HashMap<String,WordCnt> wordCntHashMap =new HashMap<>(); //1,针对文档标题进行分词 List<Term> terms = ToAnalysis.parse( docInfo.getTitle()).getTerms(); //2. 遍历分词结果,统计每个词出现的比例 for (Term term : terms){ //先判定一个term这个词是否存在,如果不存在,就创建一个新的键值对,插入进去,titleCount 设为1 //gameName()的分词的具体的词 String word = term.getName(); //哈希表的get如果不存在默认返回的是null WordCnt wordCnt = wordCntHashMap.get(word); if (wordCnt == null){ //词不存在 WordCnt newWordCnt = new WordCnt(); newWordCnt.titleCount =1; newWordCnt.contentCount = 0; wordCntHashMap.put(word,newWordCnt); }else{ //存在就找到之前的值,然后加1 wordCnt.titleCount +=1; } //如果存在,就找到之前的值,然后把对应的titleCount +1 } //3. 针对正文进行分词 terms = ToAnalysis.parse(docInfo.getContent()).getTerms(); //4. 遍历分词结果,统计每个词出现的次数 for (Term term : terms) { String word = term.getName(); WordCnt wordCnt = wordCntHashMap.get(word); if (wordCnt == null){ WordCnt newWordCnt = new WordCnt(); newWordCnt.titleCount = 0; newWordCnt.contentCount = 1; wordCntHashMap.put(word,newWordCnt); }else { wordCnt.contentCount +=1; } } //5. 把上面的结果汇总到一个HasMap里面 // 最终的文档的权重,设置为标题的出现次数 * 10 + 正文中出现的次数 //6.遍历当前的HashMap,依次来更新倒排索引中的结构。 //并不是全部代码都是可以for循环的,只有这个对象是”可迭代的“,实现Iterable 接口才可以 // 但是Map并没有实现,Map存在意义,是根据key查找value,但是好在Set实现了实现Iterable,就可以把Map转换为Set //本来Map存在的是戒键值对,可以根据key快速找到value, //Set这里存的是一个把 键值对 打包在一起的类 称为Entry(条目) //转成Set之后,失去了快速根据key快速查找value的只这样的能力,但是换来了可以遍历 for(Map.Entry<String,WordCnt> entry:wordCntHashMap.entrySet()){ //先根据这里的词去倒排索引中查一查词 //倒排拉链 List<Weight> invertedList = invertedIndex.get(entry.getKey()); if (invertedList == null){ //如果为空,插入一个新的键值对 ArrayList<Weight> newInvertedList =new ArrayList<>(); Weight weight = new Weight(); weight.setDocId(docInfo.getDocId()); //权重计算公式:标题中出现的次数* 10 +正文出现的次数 weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount); newInvertedList.add(weight); invertedIndex.put(entry.getKey(),newInvertedList); }else{ //如果非空 ,就把当前的文档,构造出一个Weight 对象,插入到倒排拉链的后面 Weight weight = new Weight(); weight.setDocId(docInfo.getDocId()); //权重计算公式:标题中出现的次数* 10 +正文出现的次数 weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount); invertedList.add(weight); } } } private DocInfo buildForward(String title, String url, String content) { DocInfo docInfo =new DocInfo(); docInfo.setDocId(forwardIndex.size()); docInfo.setTitle(title); docInfo.setUrl(url); docInfo.setContent(content); forwardIndex.add(docInfo); return docInfo; } //4.把内存中的索引结构保存到磁盘中 public void save(){ long beg = System.currentTimeMillis(); //使用2个文件。分别保存正排和倒排 System.out.println("保存索引开始"); //1.先判断一下索引对应的目录是否存在 File indexPathFile =new File(INDEX_PATH); if (!indexPathFile.exists()){ //如果路径不存在 //mkdirs()可以创建多级目录 indexPathFile.mkdirs(); } //正排索引文件 File forwardIndexFile = new File(INDEX_PATH+"forward.txt"); //倒排索引文件 File invertedIndexFile = new File(INDEX_PATH+"inverted.txt"); try { //writeValue的有个参数可以把对象写到文件里 objectMapper.writeValue(forwardIndexFile,forwardIndex); objectMapper.writeValue(invertedIndexFile,invertedIndex); }catch (IOException e){ e.printStackTrace(); } long end = System.currentTimeMillis(); System.out.println("保存索结束 !消耗时间"+(end - beg)+"ms"); } //5.把磁盘中的索引数据加载到内存中 public void load(){ long beg = System.currentTimeMillis(); System.out.println("加载索引开始"); //1.设置加载索引路径 //正排索引 File forwardIndexFile = new File(INDEX_PATH+"forward.txt"); //倒排索引 File invertedIndexFile = new File(INDEX_PATH+"inverted.txt"); try{ //readValue()2个参数,从那个文件读,解析是什么数据 forwardIndex = objectMapper.readValue(forwardIndexFile, new TypeReference<ArrayList<DocInfo>>() {}); invertedIndex = objectMapper.readValue(invertedIndexFile, new TypeReference<HashMap<String, ArrayList<Weight>>>() {}); }catch (IOException e){ e.printStackTrace(); } long end = System.currentTimeMillis(); System.out.println("加载索引结束 ! 消耗时间"+(end -beg)+"ms"); } public static void main(String[] args) { Index index = new Index(); index.load(); System.out.println("索引加载完成"); }}提供Parser的main方法运行:
结果: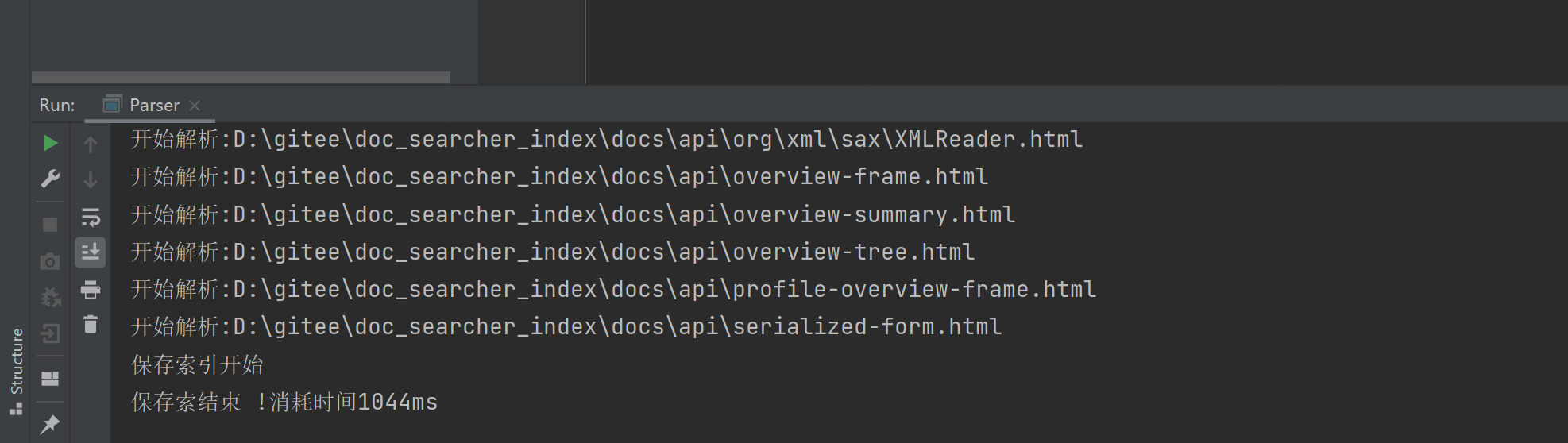
然后去看看做出来的索引文件:文件成功出来了
我们使用vscode打开一下这个文件看看是什么:(记事本打开慢)

其实发现我们的文本里面还是我们想要的文件,该有的都有。倒排文件也是docid 和权重都有
这样我们可以认为我们的索引文件还是完成了的。
五、实现索引模块-优化索引模块篇
5.1实现索引模块-关于索引制作速度
我们刚刚制作索引的时候还是花费了一定的时间,我们可以到parser类的run方法在搞一个时间差这样就可以看清楚了花费多久:然后之后在看看优化后提升了多少速度。
可以发现索引制作完毕差不多花费了30秒: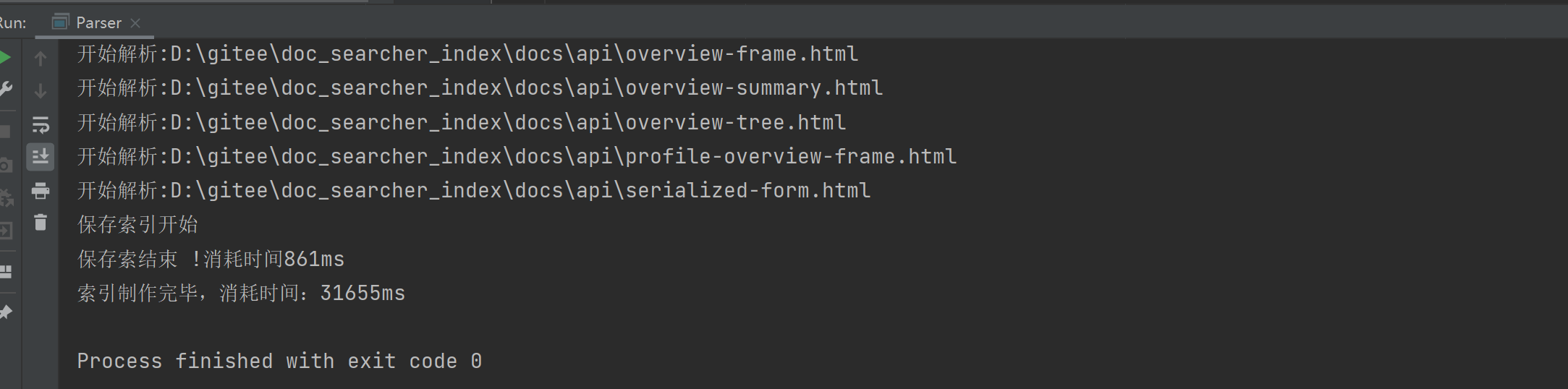
那么我们想一下是哪里在耗时间呢?
在枚举路径吗?其实这里是很快的
保存索引吗?其实也就0.8秒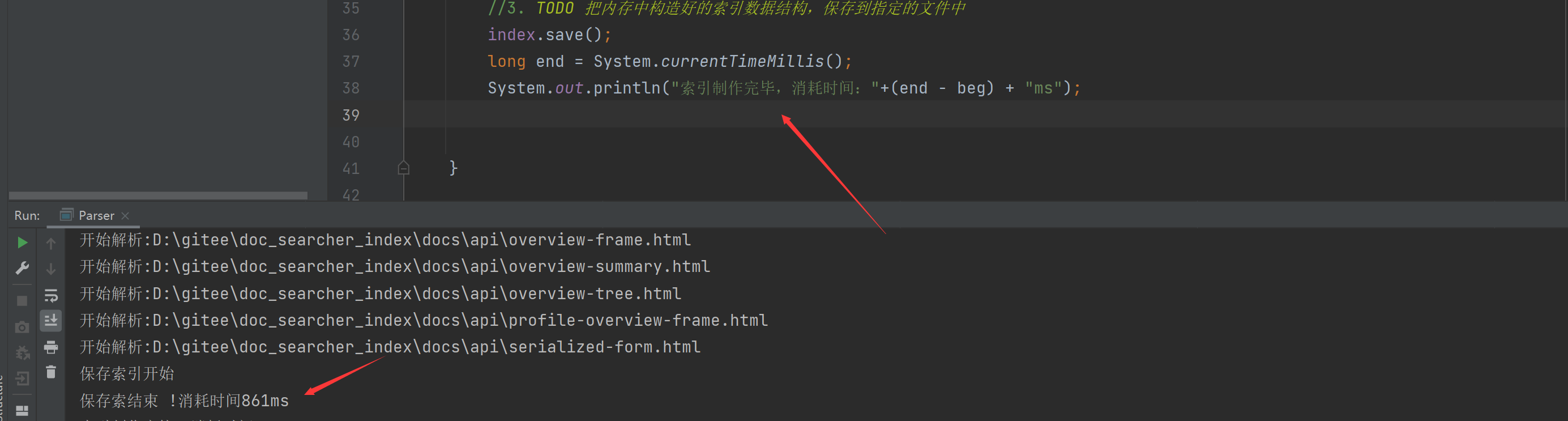
真正的大头还是在循环上:
我们想要提升性能还是得先找到原因:想优化程序的性能,就需要通过测试的手段,找到其中的“性能瓶颈”。像去医院一样,先拍片定位,然后解决问题。怎么测试呢 最简单的就是每个环境加上时间看看谁耗的多:
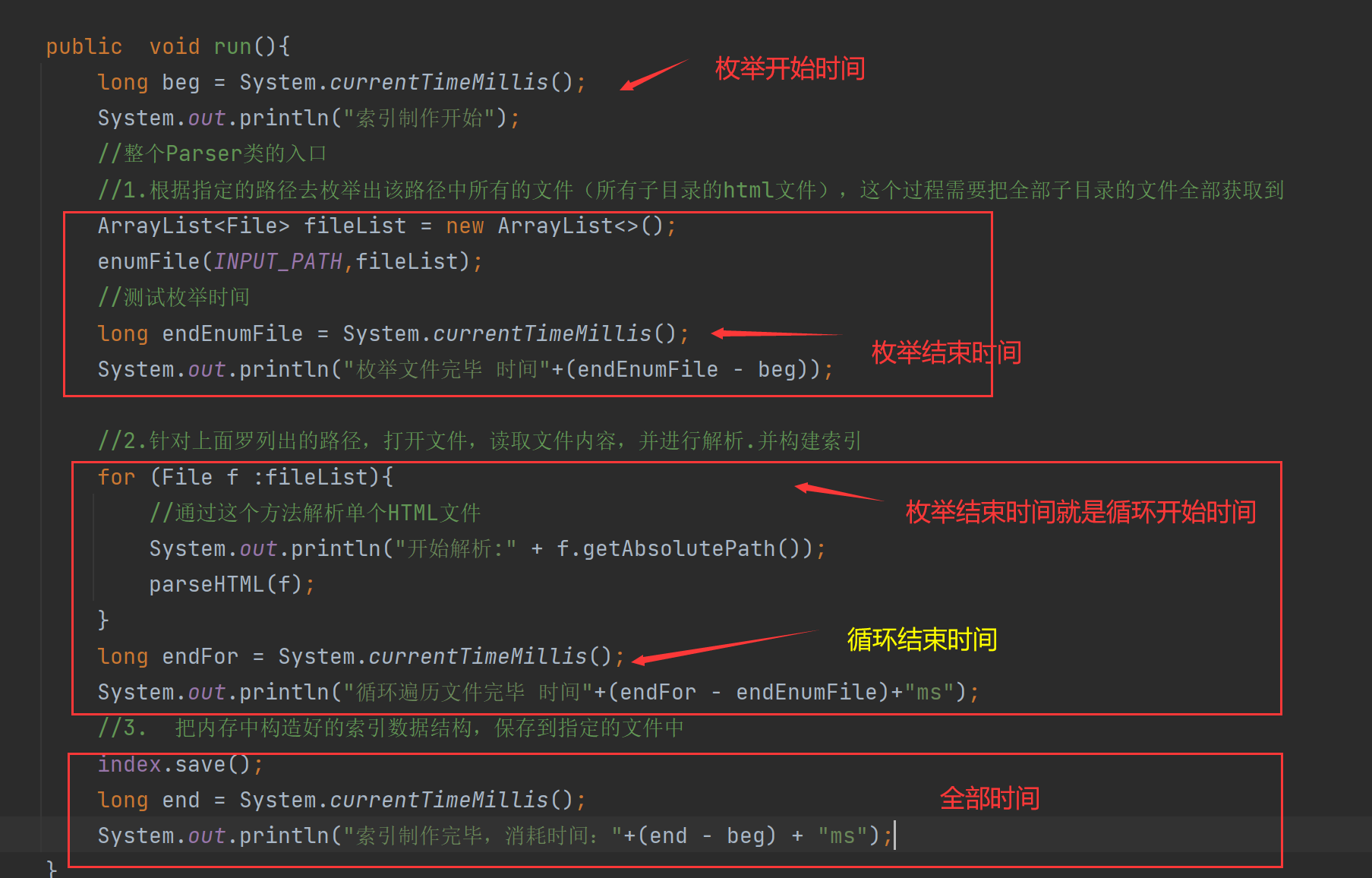
结果:循环时间最多花费时间最多。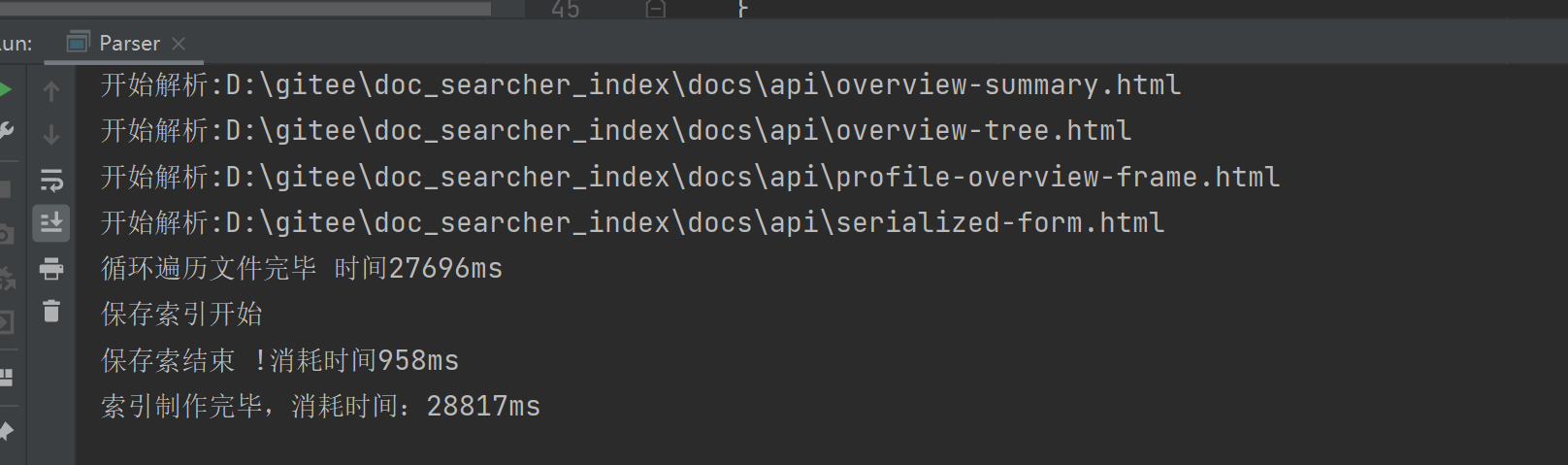
针对这个循环的优化思路也很简单:通过刚才测试发现,主要的性能瓶颈就是在循环遍历文件上,每次循环都要针对一个文件去进行解析:读文件+分词+解析内容(主要还是卡在cpu运算上),单线程的情况下,这些任务是串行的(解析了第一个文件才解析第二个文件),使用多线程提神速度,这样通过多线程制作索引,到达提升速度的目的
5.2实现索引模块-实现多线程制作索引
我们通过一个新的方法实现多线程的制作索引:
//通过这个方法实现多线程制作索引 public void runByThread() throws InterruptedException { long beg =System.currentTimeMillis(); System.out.println("索引制作开始!"); //1.,枚举全部文件 ArrayList<File> files = new ArrayList<>(); enumFile(INPUT_PATH,files); //2.循环遍历文件 此处为了通过多线程制作索引,就直接引入线程池 CountDownLatch latch = new CountDownLatch(files.size()); ExecutorService executorService = Executors.newFixedThreadPool(10); for(File f:files){ //添加任务submit到线程池 executorService.submit(new Runnable() { @Override public void run() { System.out.println("解析"+f.getAbsolutePath()); parseHTML(f); //保证所有的索引制作完再保存索引 latch.countDown(); } }); } //latch.await()等待全部countDown完成,才阻塞结束。 latch.await(); //3.保存索引 ,可能存在还没有执行完的情况 index.save(); long end =System.currentTimeMillis(); System.out.println("索引制作结束!时间"+(end - beg)+"ms"); }这里的基本思路还是和以前的一样,只是变了几个地方需要大家理解:
增加了线程池,ExecutorService 使用newFixedThreadPool(10),使用这个方法创了10个线程,然后重点来了
如果我们索引制作完成了就应该需要调用 index.save(); 方法,但是我们现在是多线程,可能会出现一种情况,就是索引还在制作没有完成,这个时候因为是多线程并发操作,可能就去执行了index.save(); 这样我们就会得到一个不完整的索引文件。
针对这样的情况我们解决的思路是:使用CountDownLatch 这个类的 countDown() 方法,这个方法记录了有多少任务还没有做完,当全部做完的时候,我们使用 await() 唤醒,然后操作下一步。
5.3实现索引模块-给制作的索引代码加锁
我们加入了多线程就可以直接跑了吗?不 不是这样的,因为涉及了线程安全,我们要清楚线程安全产生的,如果涉及到了操作公共对象那么可能就会发生。换句话说(多个线程尝试修改同一个对象)
我们这里调用了parseHTML方法。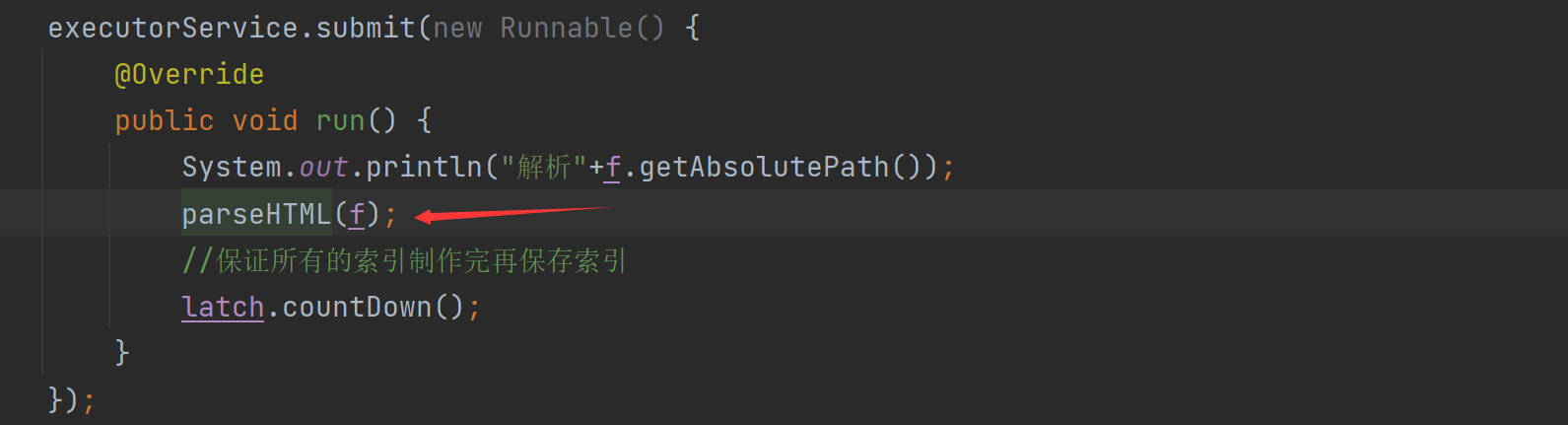
而parserHTML方法还有个其他的操作和addDoc操作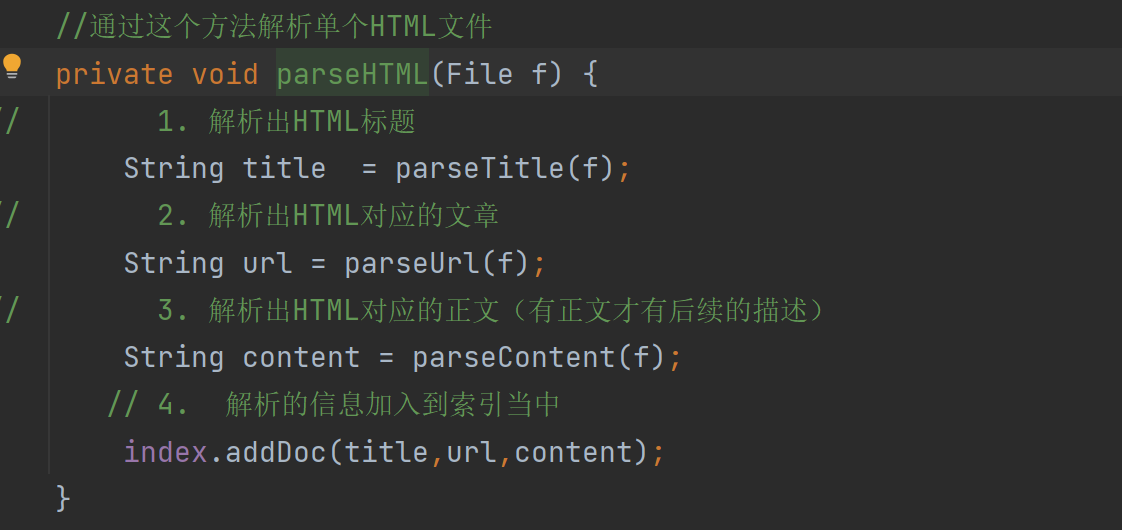
我们发现解析标题,url,和正文都没有涉及操作公共对象,但是addDoc这个方法里面就出问题了:
这里我们发现addDoc发现有构造索引,正排和倒排。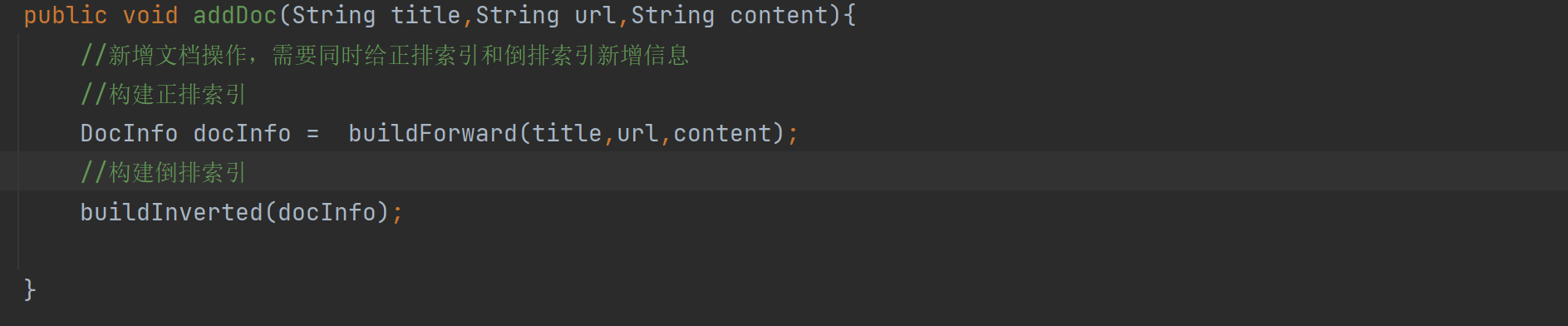
正排索引可发现有2个地方在操作公共的类: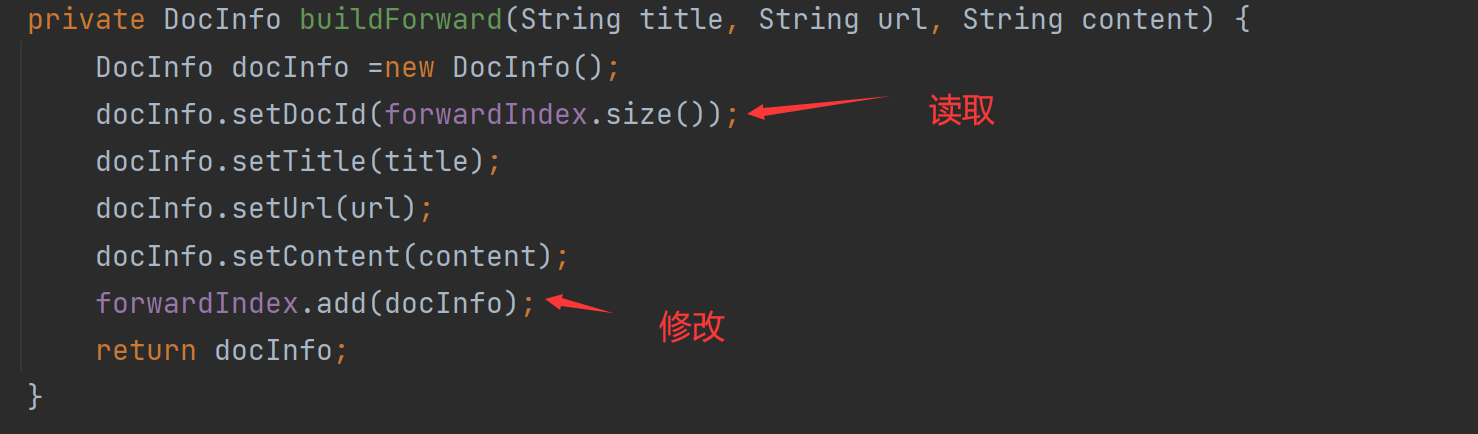
构建倒排索引也有操作公共对象的行为: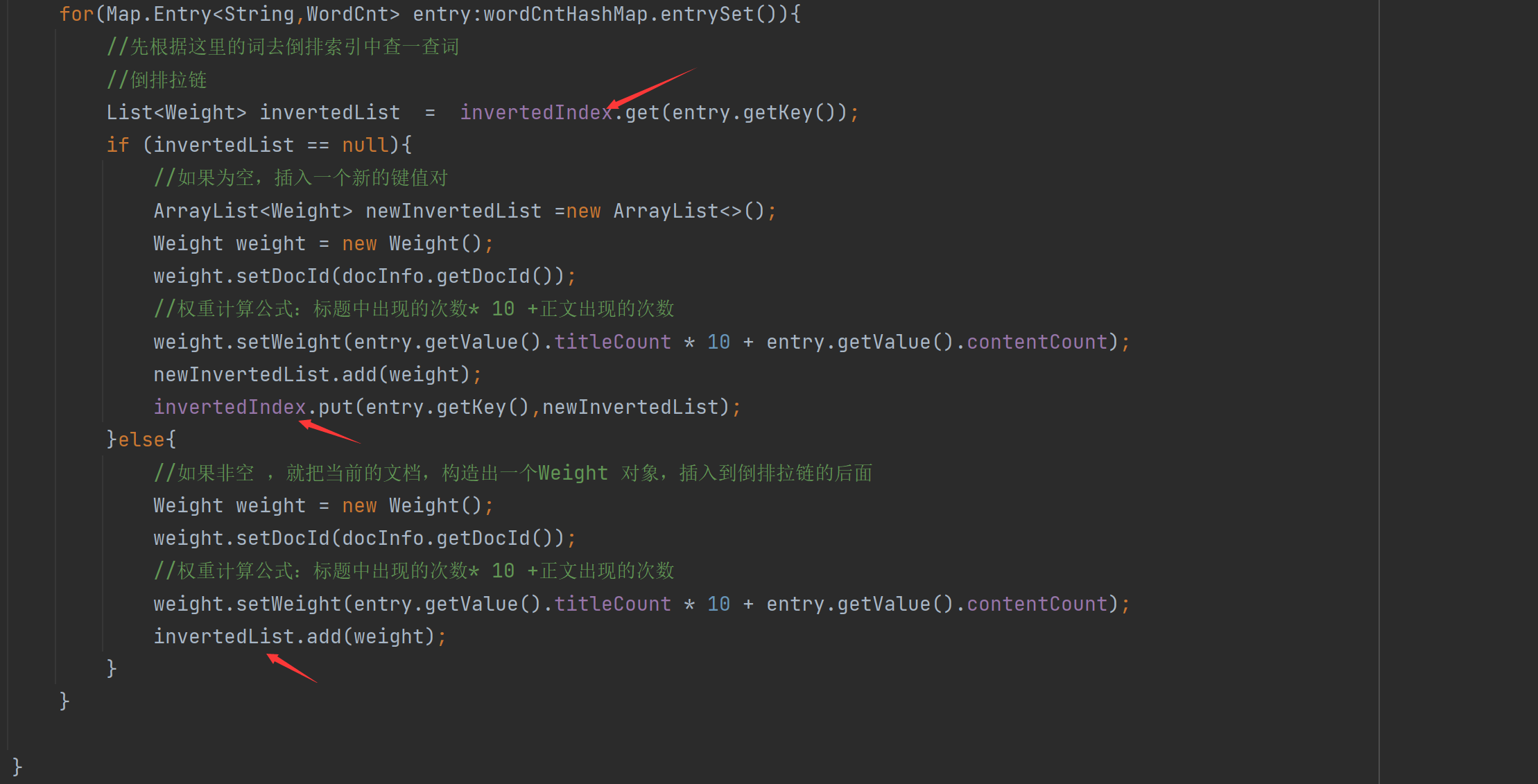
我们画个图来看看大概的执行流程:有4个线程同时修改forwardIndex 和invertedIndex,这样存在线程安全问题,我们就使用线程安全来加锁。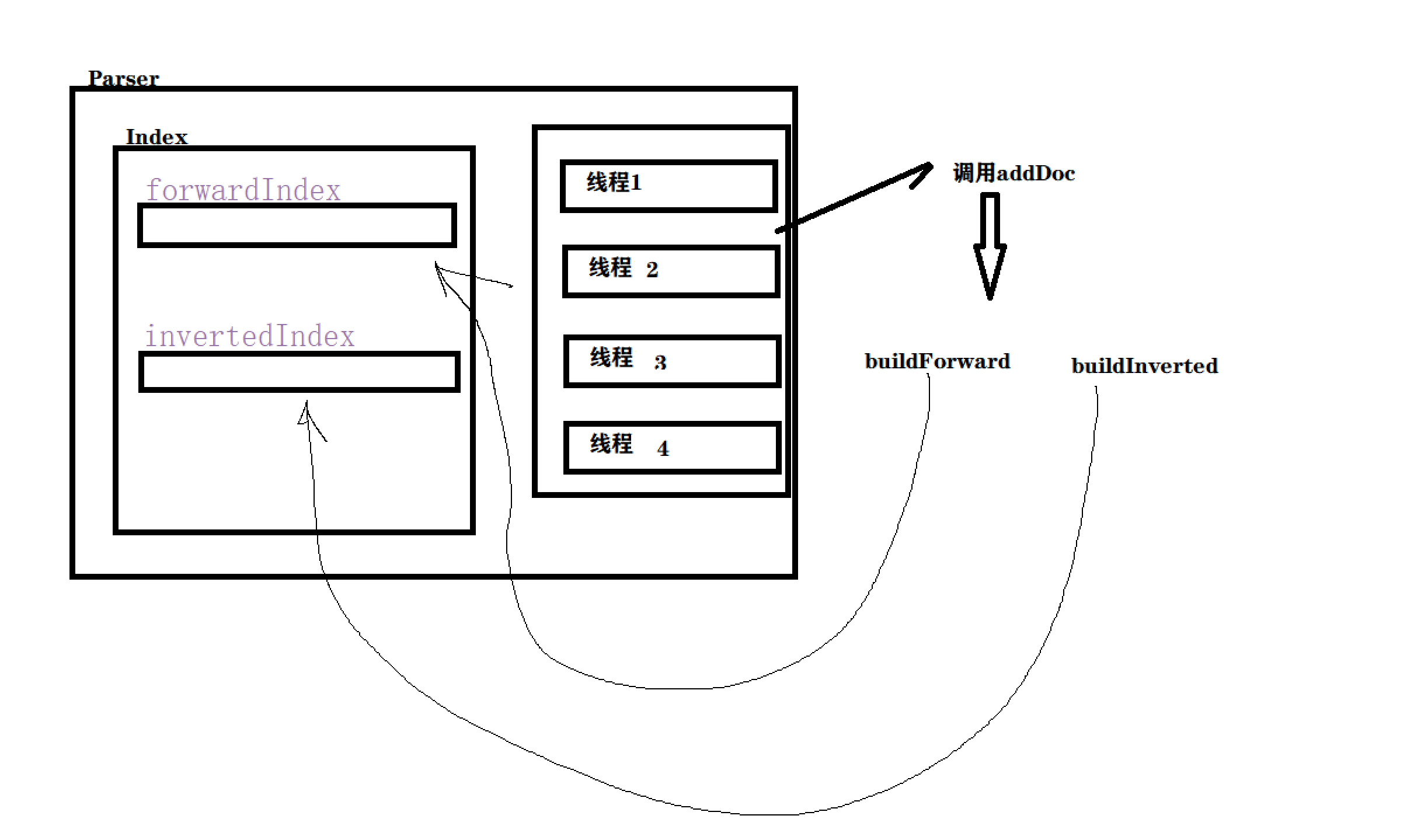
要怎么样加呢? 我们要让能并发的地方尽量并发,不能就地方就串行,加锁的粒度不可以太大。
 给这正排索引2行代码调整顺序加锁
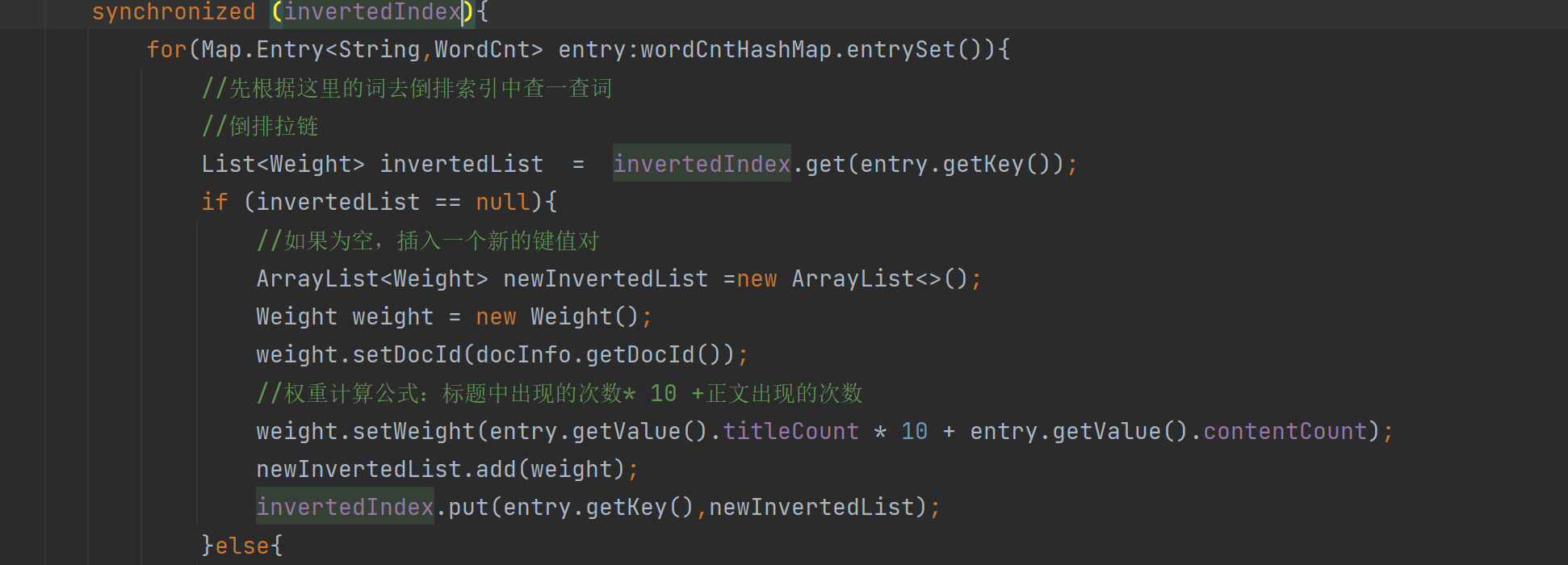
给这正排索引2行代码调整顺序加锁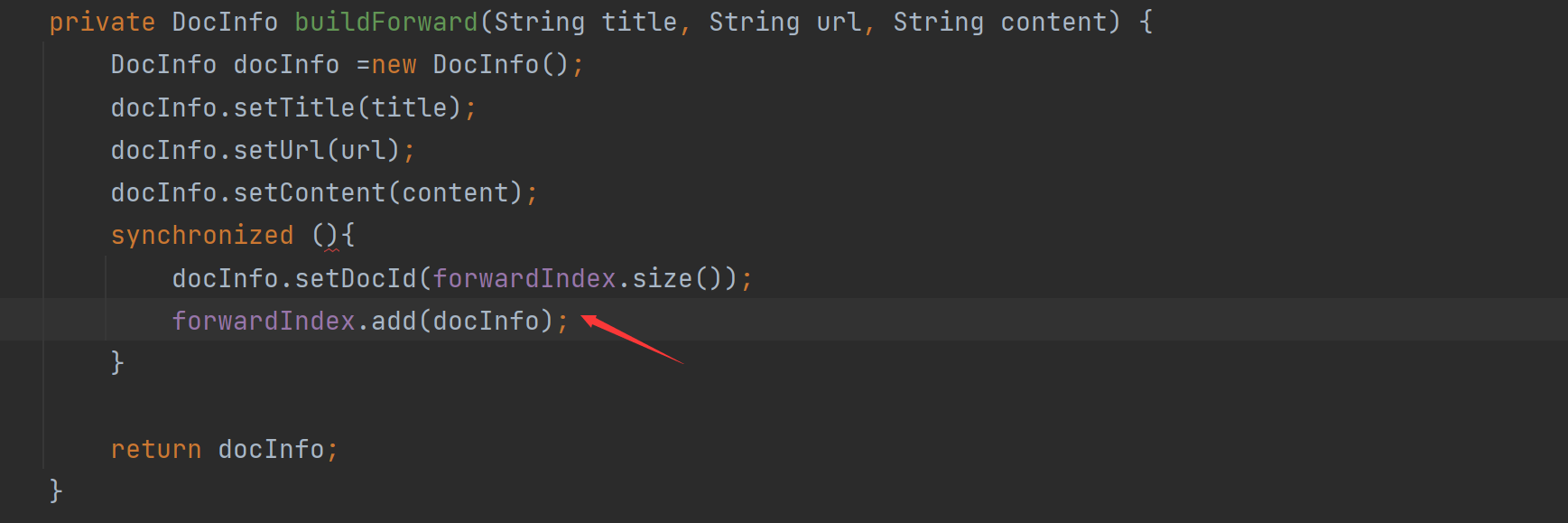 给这倒排索引循环代码调整顺序加锁
给这倒排索引循环代码调整顺序加锁 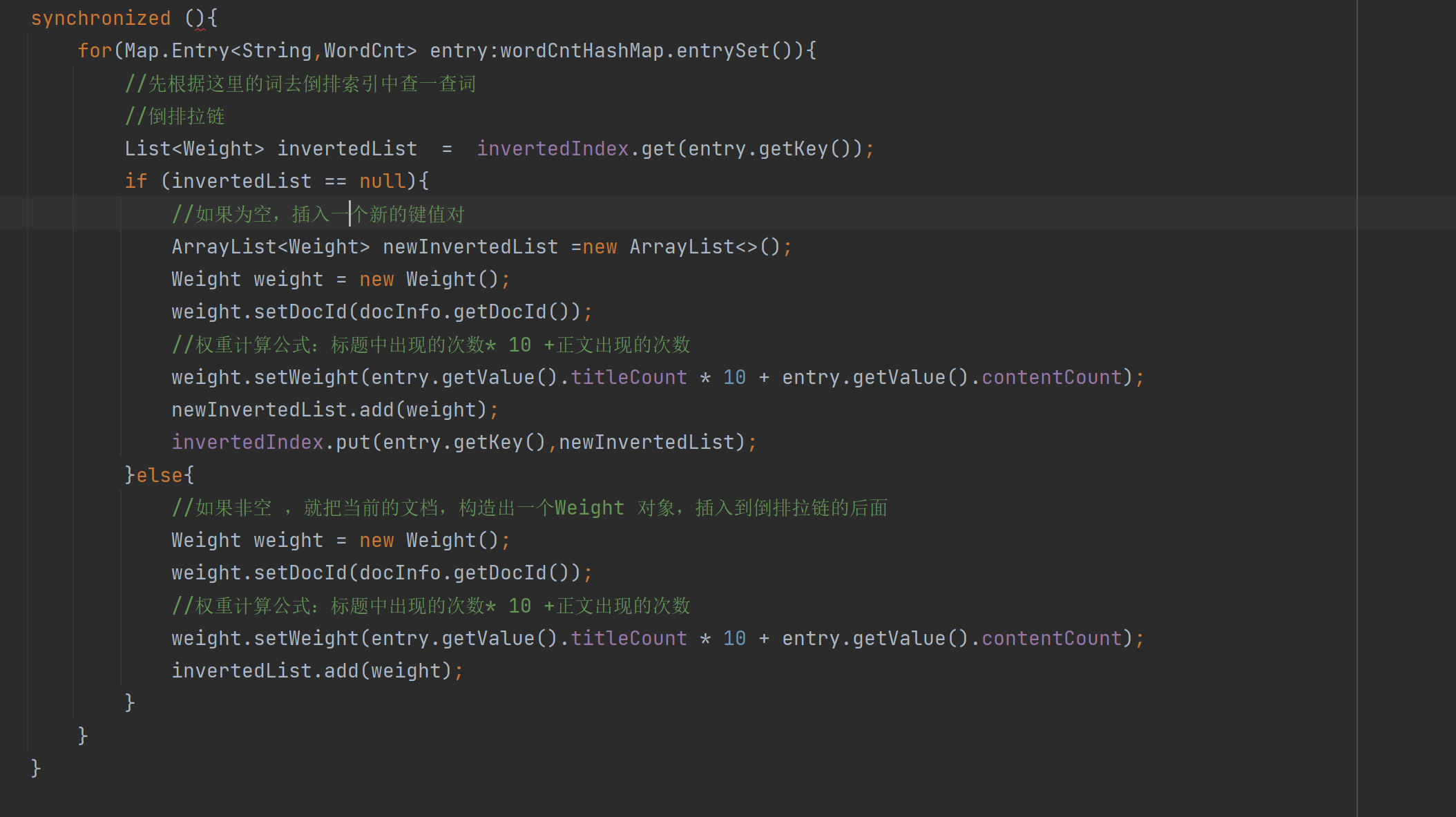
还有个问题:我们需要加锁对象是什么呢?synchronize里面的参数
如果给锁对象给this,就是表示当前的这个Index类,但是如果这样的话,会出现必须先执行完正排索引对象,才可以执行倒排索引对象代码
我们发现我们其实操作的是两个不同的对象(正排索引和倒排索引),所以他们不应该产生锁竞争,就像 A女生和B女生,,都有追求者,然后一个线程男A把A女生约走了,那么其他线程男,就必须要等着A女生吗,他们也可以去找B女生,A和B女生是2给不一样的对象。
所以我们可以针对索引对象加锁,
也可以创建新的2个锁对象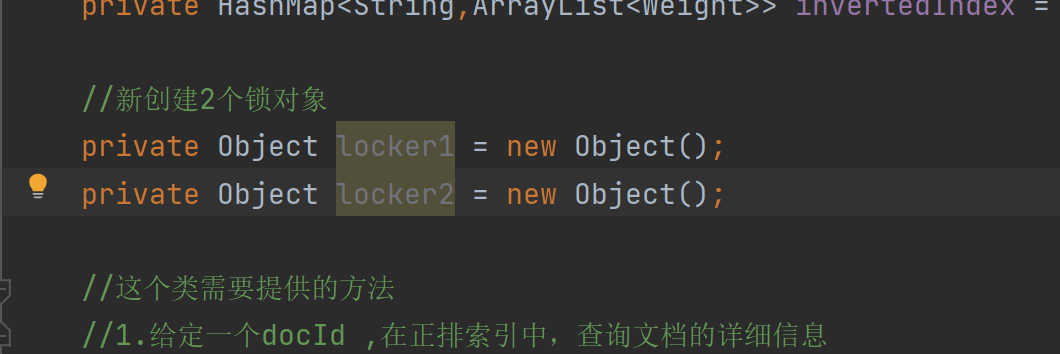
代码也改一下: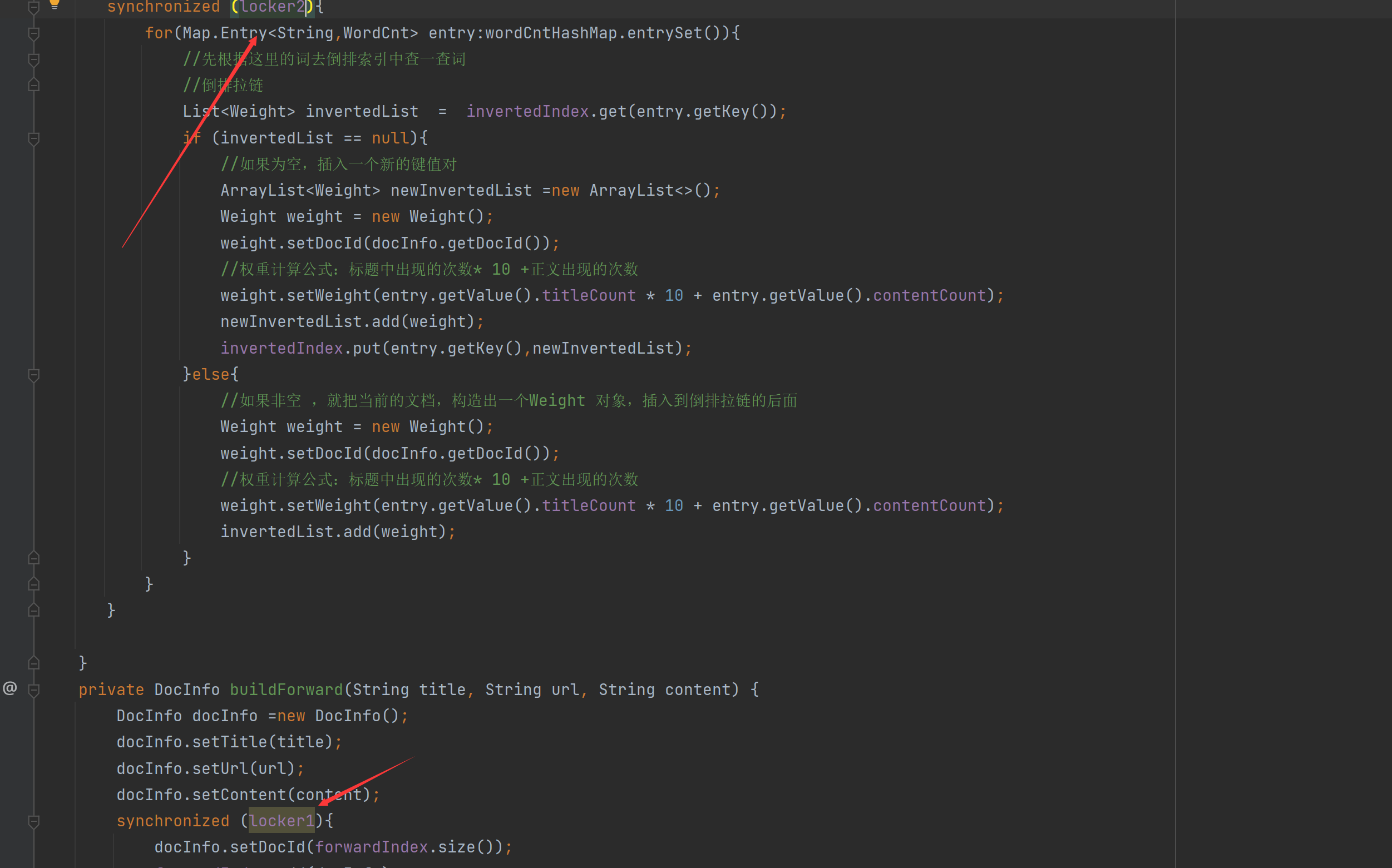
修改后的代码:
import com.fasterxml.jackson.core.type.TypeReference;import com.fasterxml.jackson.databind.ObjectMapper;import org.ansj.domain.Term;import org.ansj.splitWord.analysis.ToAnalysis;import java.io.File;import java.io.IOException;import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;/** * Created by Lin * Description: * User: Administrator * Date: 2022-12-17 * Time: 13:01 *///通过这个类在内存中来构造出索引结构public class Index { //保存索引文件的路径 private static final String INDEX_PATH ="D:\\gitee\\doc_searcher_index\\"; private ObjectMapper objectMapper = new ObjectMapper(); //使用数组下标表示 DocId private ArrayList<DocInfo> forwardIndex = new ArrayList<>(); //使用哈希表 来表示倒排索引 key就是词 value就是一组和词关联的文章 private HashMap<String,ArrayList<Weight>> invertedIndex = new HashMap<>(); //新创建2个锁对象 private Object locker1 = new Object(); private Object locker2 = new Object(); //这个类需要提供的方法 //1.给定一个docId ,在正排索引中,查询文档的详细信息 public DocInfo getDocInfo(int docId){ return forwardIndex.get(docId); } //2.给定一词,在倒排索引中,查哪些文档和这个文档词关联 public List<Weight> getInverted(String term){ return invertedIndex.get(term); } //3.往索引中新增一个文档 public void addDoc(String title,String url,String content){ //新增文档操作,需要同时给正排索引和倒排索引新增信息 //构建正排索引 DocInfo docInfo = buildForward(title,url,content); //构建倒排索引 buildInverted(docInfo); } private void buildInverted(DocInfo docInfo) { //搞一个内部类避免出现2个哈希表 class WordCnt{ //表示这个词在标题中 出现的次数 public int titleCount ; // 表示这个词在正文出现的次数 public int contentCount; } //统计词频的数据结构 HashMap<String,WordCnt> wordCntHashMap =new HashMap<>(); //1,针对文档标题进行分词 List<Term> terms = ToAnalysis.parse( docInfo.getTitle()).getTerms(); //2. 遍历分词结果,统计每个词出现的比例 for (Term term : terms){ //先判定一个term这个词是否存在,如果不存在,就创建一个新的键值对,插入进去,titleCount 设为1 //gameName()的分词的具体的词 String word = term.getName(); //哈希表的get如果不存在默认返回的是null WordCnt wordCnt = wordCntHashMap.get(word); if (wordCnt == null){ //词不存在 WordCnt newWordCnt = new WordCnt(); newWordCnt.titleCount =1; newWordCnt.contentCount = 0; wordCntHashMap.put(word,newWordCnt); }else{ //存在就找到之前的值,然后加1 wordCnt.titleCount +=1; } //如果存在,就找到之前的值,然后把对应的titleCount +1 } //3. 针对正文进行分词 terms = ToAnalysis.parse(docInfo.getContent()).getTerms(); //4. 遍历分词结果,统计每个词出现的次数 for (Term term : terms) { String word = term.getName(); WordCnt wordCnt = wordCntHashMap.get(word); if (wordCnt == null){ WordCnt newWordCnt = new WordCnt(); newWordCnt.titleCount = 0; newWordCnt.contentCount = 1; wordCntHashMap.put(word,newWordCnt); }else { wordCnt.contentCount +=1; } } //5. 把上面的结果汇总到一个HasMap里面 // 最终的文档的权重,设置为标题的出现次数 * 10 + 正文中出现的次数 //6.遍历当前的HashMap,依次来更新倒排索引中的结构。 //并不是全部代码都是可以for循环的,只有这个对象是”可迭代的“,实现Iterable 接口才可以 // 但是Map并没有实现,Map存在意义,是根据key查找value,但是好在Set实现了实现Iterable,就可以把Map转换为Set //本来Map存在的是戒键值对,可以根据key快速找到value, //Set这里存的是一个把 键值对 打包在一起的类 称为Entry(条目) //转成Set之后,失去了快速根据key快速查找value的只这样的能力,但是换来了可以遍历 synchronized (locker2){ for(Map.Entry<String,WordCnt> entry:wordCntHashMap.entrySet()){ //先根据这里的词去倒排索引中查一查词 //倒排拉链 List<Weight> invertedList = invertedIndex.get(entry.getKey()); if (invertedList == null){ //如果为空,插入一个新的键值对 ArrayList<Weight> newInvertedList =new ArrayList<>(); Weight weight = new Weight(); weight.setDocId(docInfo.getDocId()); //权重计算公式:标题中出现的次数* 10 +正文出现的次数 weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount); newInvertedList.add(weight); invertedIndex.put(entry.getKey(),newInvertedList); }else{ //如果非空 ,就把当前的文档,构造出一个Weight 对象,插入到倒排拉链的后面 Weight weight = new Weight(); weight.setDocId(docInfo.getDocId()); //权重计算公式:标题中出现的次数* 10 +正文出现的次数 weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount); invertedList.add(weight); } } } } private DocInfo buildForward(String title, String url, String content) { DocInfo docInfo =new DocInfo(); docInfo.setTitle(title); docInfo.setUrl(url); docInfo.setContent(content); synchronized (locker1){ docInfo.setDocId(forwardIndex.size()); forwardIndex.add(docInfo); } return docInfo; } //4.把内存中的索引结构保存到磁盘中 public void save(){ long beg = System.currentTimeMillis(); //使用2个文件。分别保存正排和倒排 System.out.println("保存索引开始"); //1.先判断一下索引对应的目录是否存在 File indexPathFile =new File(INDEX_PATH); if (!indexPathFile.exists()){ //如果路径不存在 //mkdirs()可以创建多级目录 indexPathFile.mkdirs(); } //正排索引文件 File forwardIndexFile = new File(INDEX_PATH+"forward.txt"); //倒排索引文件 File invertedIndexFile = new File(INDEX_PATH+"inverted.txt"); try { //writeValue的有个参数可以把对象写到文件里 objectMapper.writeValue(forwardIndexFile,forwardIndex); objectMapper.writeValue(invertedIndexFile,invertedIndex); }catch (IOException e){ e.printStackTrace(); } long end = System.currentTimeMillis(); System.out.println("保存索结束 !消耗时间"+(end - beg)+"ms"); } //5.把磁盘中的索引数据加载到内存中 public void load(){ long beg = System.currentTimeMillis(); System.out.println("加载索引开始"); //1.设置加载索引路径 //正排索引 File forwardIndexFile = new File(INDEX_PATH+"forward.txt"); //倒排索引 File invertedIndexFile = new File(INDEX_PATH+"inverted.txt"); try{ //readValue()2个参数,从那个文件读,解析是什么数据 forwardIndex = objectMapper.readValue(forwardIndexFile, new TypeReference<ArrayList<DocInfo>>() {}); invertedIndex = objectMapper.readValue(invertedIndexFile, new TypeReference<HashMap<String, ArrayList<Weight>>>() {}); }catch (IOException e){ e.printStackTrace(); } long end = System.currentTimeMillis(); System.out.println("加载索引结束 ! 消耗时间"+(end -beg)+"ms"); } public static void main(String[] args) { Index index = new Index(); index.load(); System.out.println("索引加载完成"); }}5.4实现索引模块-验证多线程的效果
我们来看看多线程代码速度有多少提升:
多线程前代码速度:
多线程后代码速度:
我们发现还是提升了,当然这里线程并不是说用了几个线程就提高几倍。这里的线程设置几合适,还是得通过实验来判断。因为多线程代码不是完全并发,中间可能涉及锁竞争和读文件io操作,其实并发不会有明显提升,会卡到io的瓶颈上。总之不是线程越多越好
5.4实现索引模块-解决进程不退出的问题
我们发现实验多线程进程还未结束:
这里我们就需要提一下我们的守护线程了:
如果一个线程是守护线程 (后台线程),此时这个线程的运行状态,不会影响到进程结果
如果一个线程不是守护线程,这个线程的运行状态,就会影响到进程结束。
我们上面创建的线程并不是守护线程,当main方法执行完了,这些线程仍然在工作,(等待新任务的到来)

我们可以手动把线程手动干掉。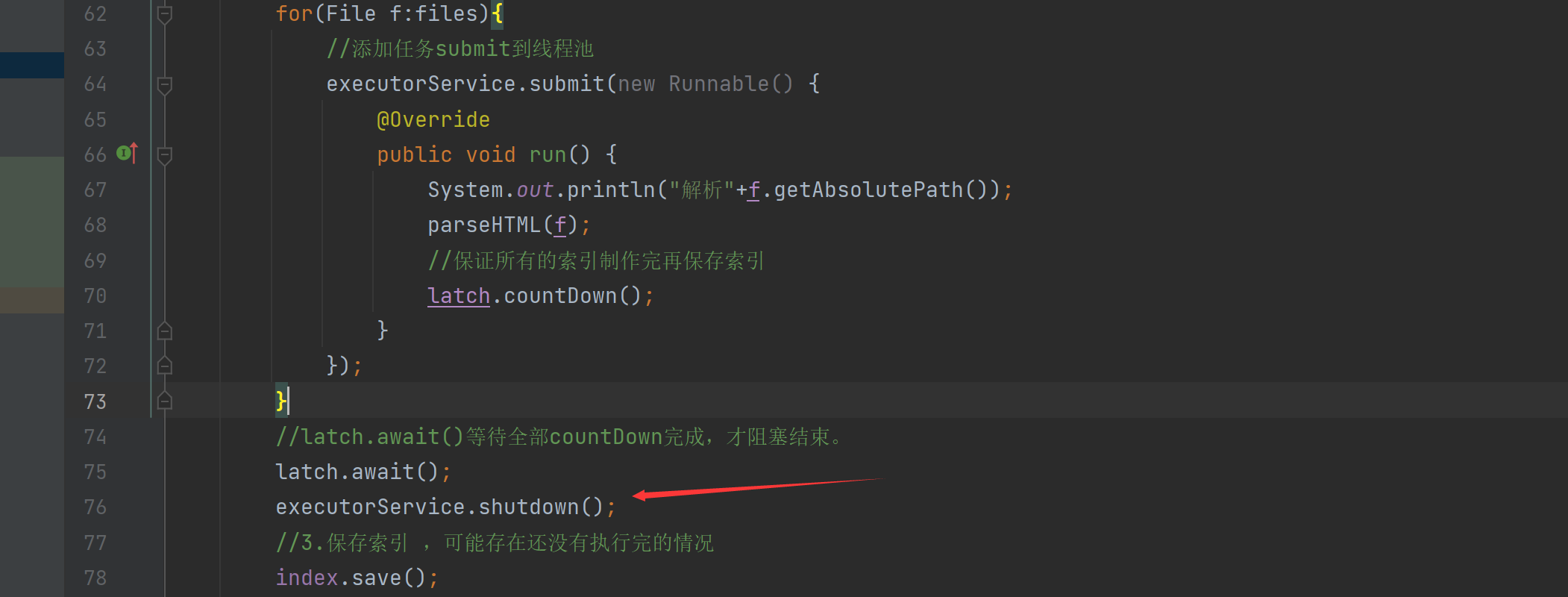
5.4实现索引模块-首次制作索引比较慢的问题
我们可以发现 重新启动机器第一次制作比较慢一点,之后再继续制作速度会快一点,这个是为什么呢?
我们发现addDoc里面解析内容设计到读取文件:计算机读取文件,是一个开销比较大的操作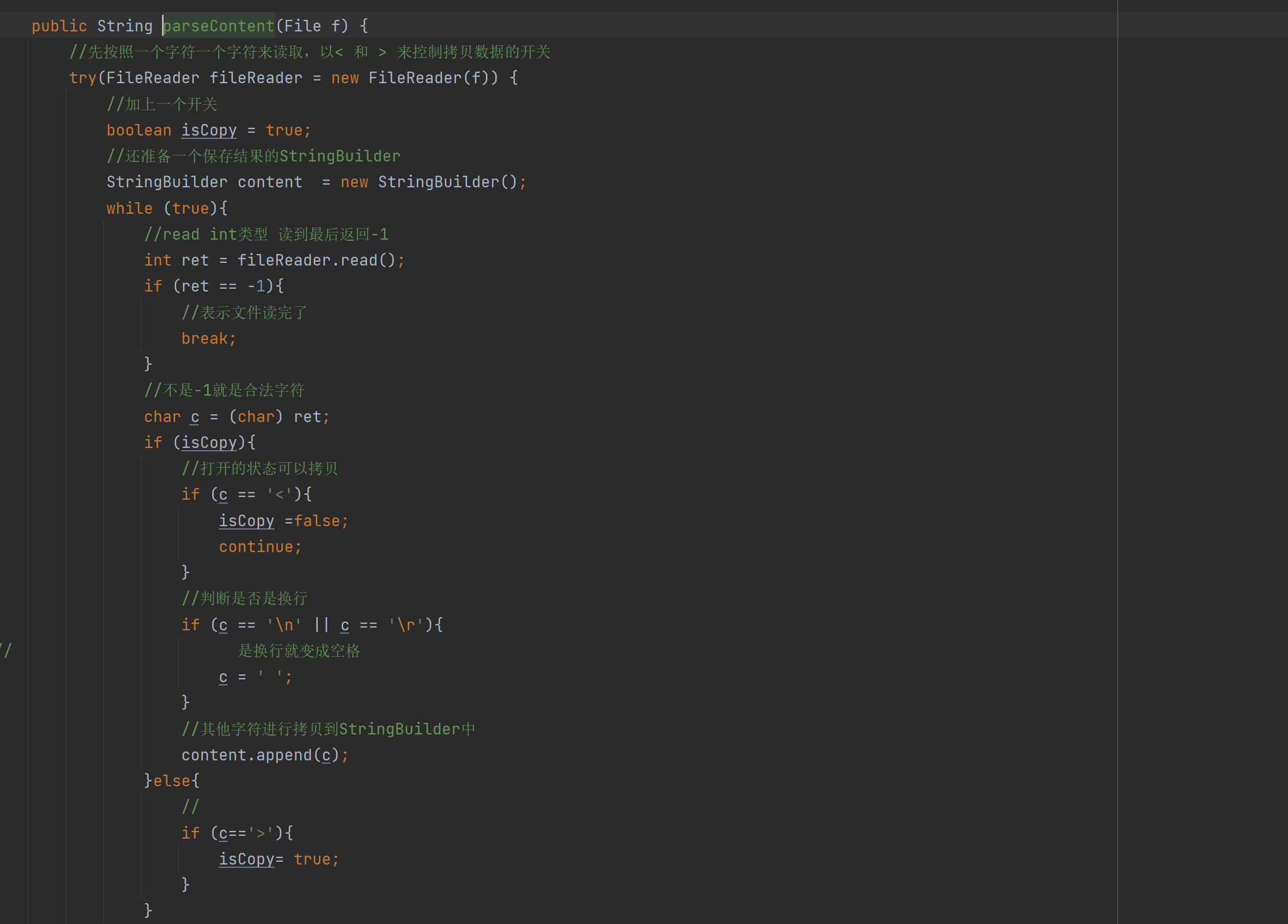
我们考虑可能是这里拖慢了速度,猜想首次运行时读取文件速度特别慢?
我们尝试把解析内容,和加入到索引做一个具体的操作记时,因为解析内容使用到了多线程 所以我们使用AtomicLong避免线程不安全。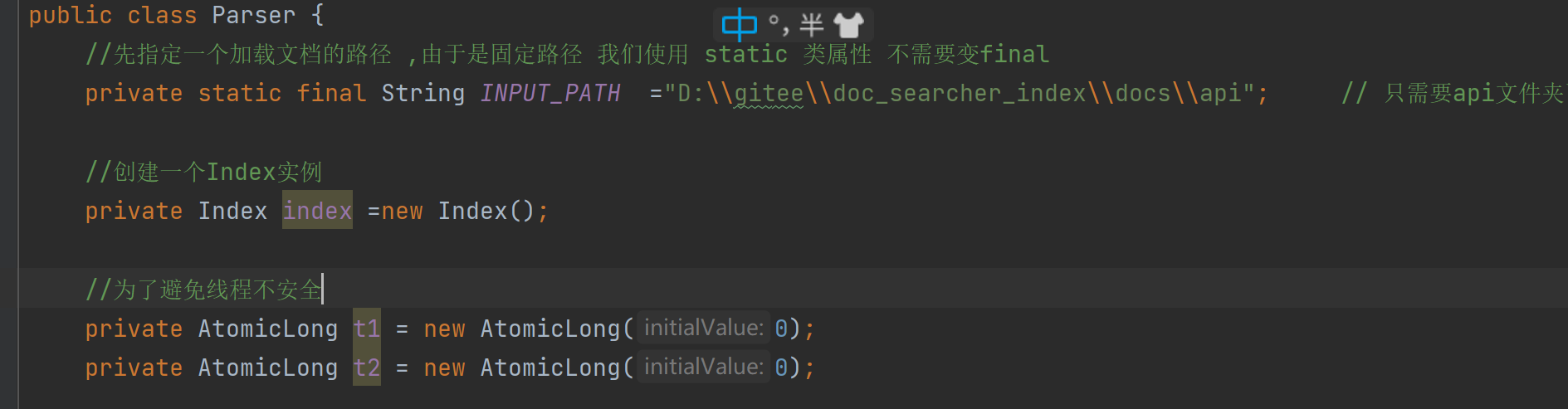
分别计算时间: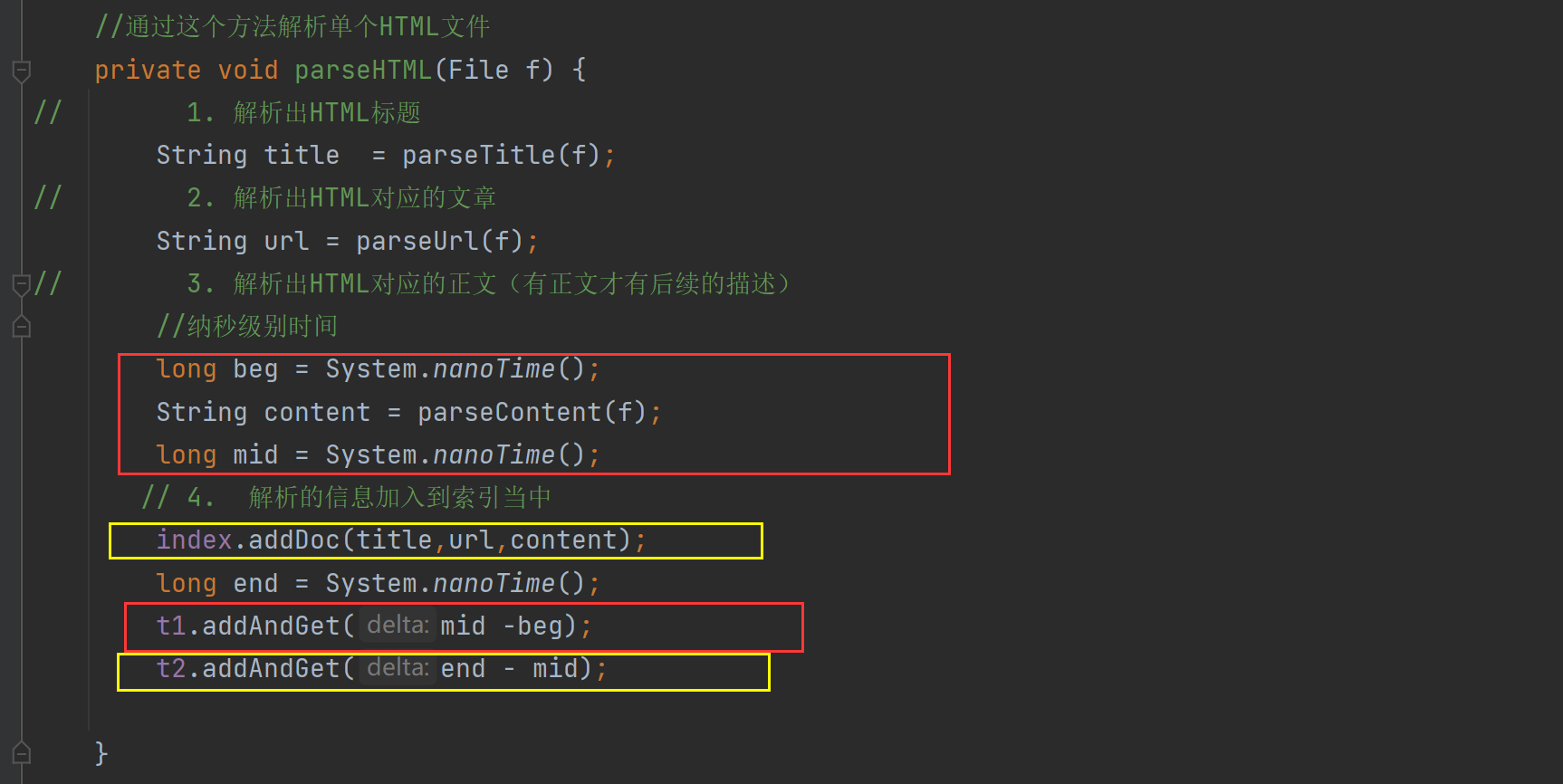
然后在线程结束打印一下时间: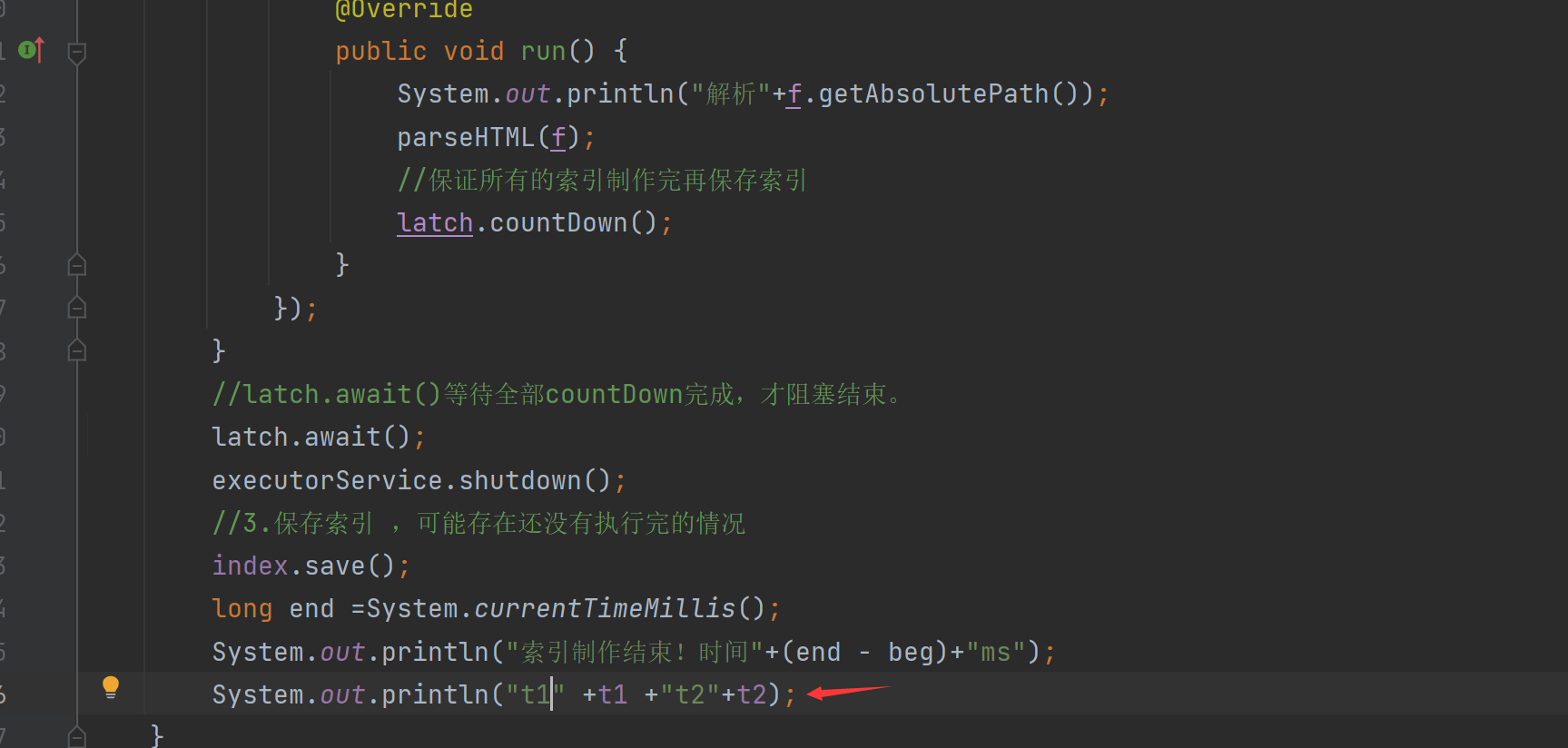
t1是parseContent的时间:
t2是addDoc的时间
电脑重启第一次运行:t1是47秒 t2是87秒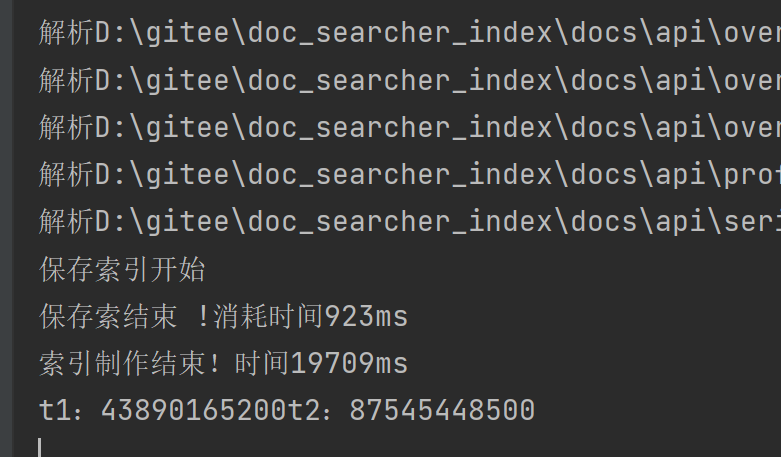
第二次运行就到了:30s 和 58s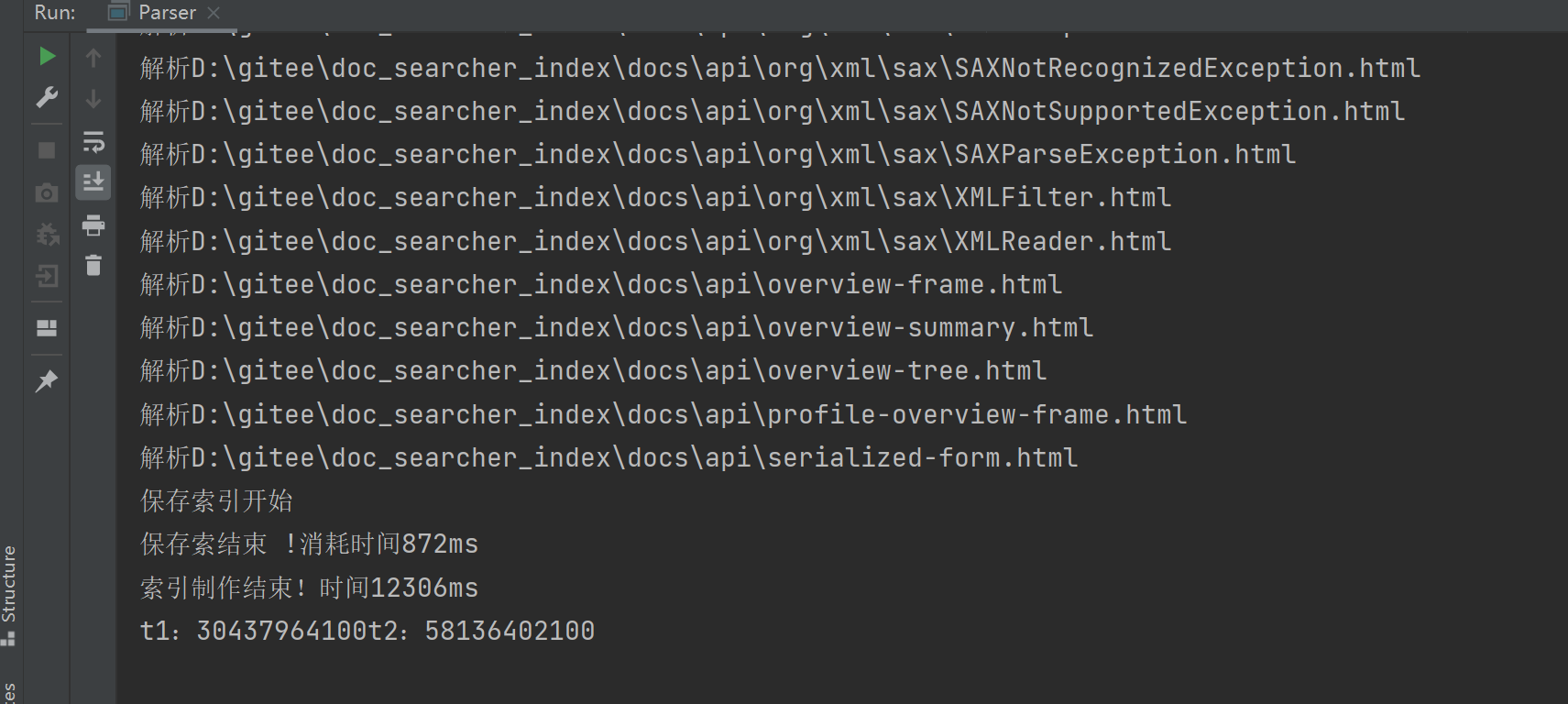
解析内容的核心操作是读取文件,从词盘中进行访问,操作系统会对“经常读取的文件”进行缓存。
首次运行的时候,当前这些Java文档都没有在内存中缓存过,因此读取的时候只能直接从硬盘上读取(就会比较慢)
后面再次运行的时候,由于前面已经读取了这些文档,文档在操作系统中有了一份缓存在内存中,第二次读取不需要直接读硬盘,而是读缓存,那么我们能不能直接使用代码把文档写到缓存呢?答案是可以的。
5.5实现索引模块-首次制作索引比较慢的问题
我们可以发现这里一个个读,是读取到磁盘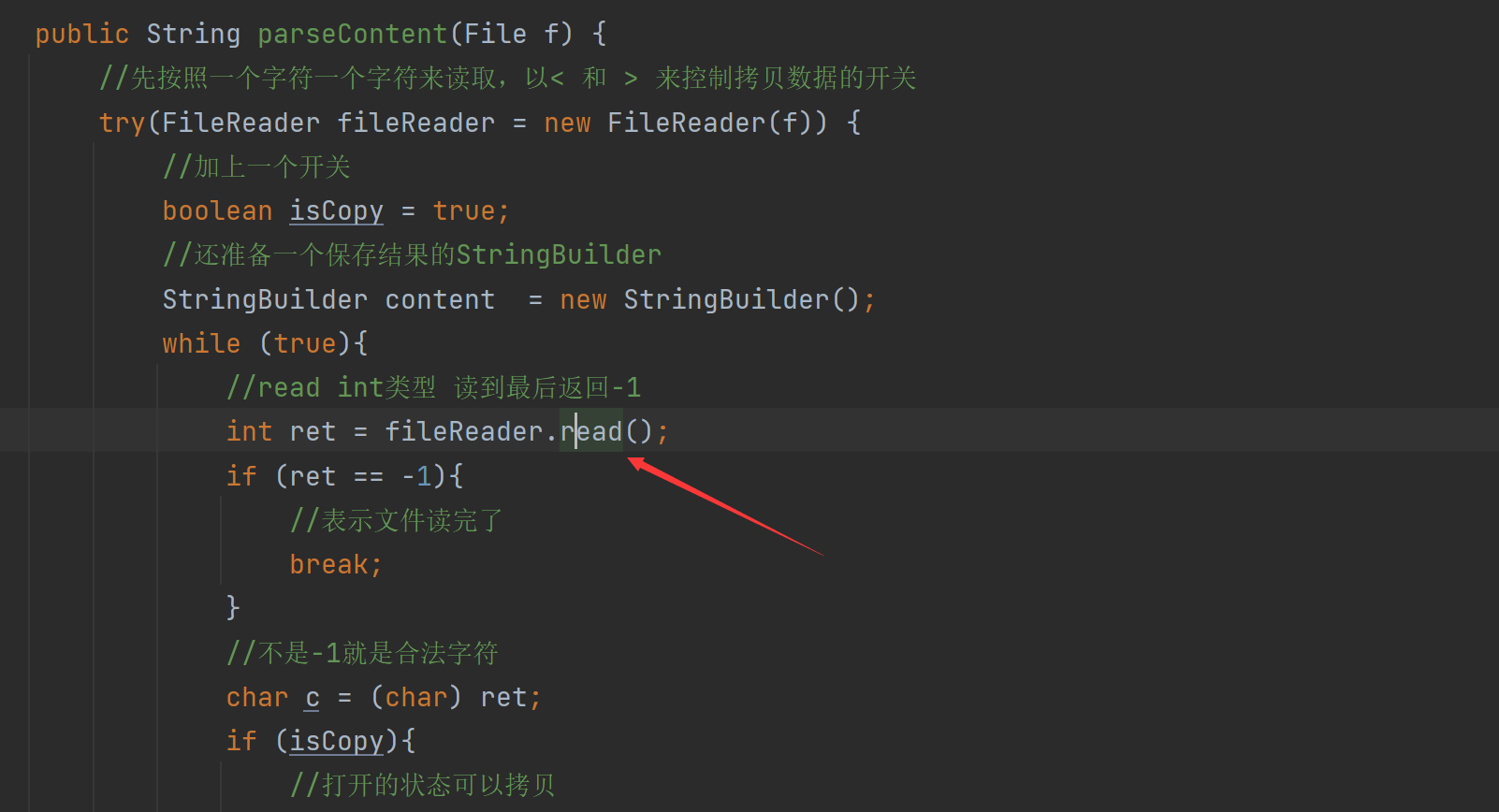
我们可以使用BufferedReader搭配FileReader来使用
BufferedReader 内部就会内置一个缓冲区,能够自动的把FileReader中的一些内容预读到内存中,从而减少直接访问磁盘的次数。
我们可以看到这个缓冲区只有个8k。我们一个html文件都是10几k,我们可以使用它的构造参数让这里大一点
由于操作系统已经对这个读文件做了一定的缓存,我们自己手动设置缓存提升不大,可能操作系统的缓存区出现问题了,会有点帮助,聊胜于无差不多。
5.5实现索引模块-验证索引加载逻辑
我们接下来看看这个load的加载逻辑怎么样,有没有用。
我们到index类里面搞一个main方法使用一下
结果: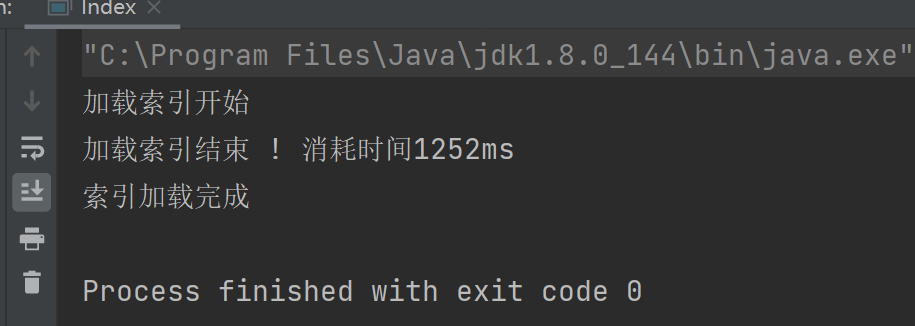
我们通过调试的方式来看看我们加载的索引是什么样的.
这个是正排索引:
这个是倒排索引: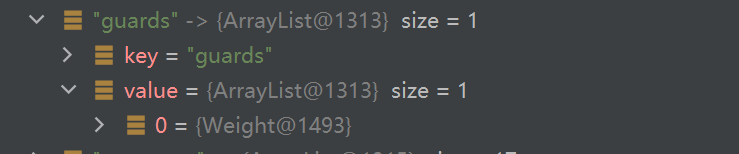
5.6实现索引模块-索引模块小结
我们都是做了啥工作呢,来小结一下
实现了Parser类 通过递归的方式枚举所有的HTML文件针对这里的每个HTML进行解析操作 标题:直接使用HTML文件标题URL:基于文件的路径进行了简单拼接(离线文档和线上文档路径 的关系)正文:去标签,简单粗暴的方式实现了使用 < >判断是否拷贝 把解析的结果放到index类里(addDoc)通过Parser类最主要的事情还是辅助Index类,完成索引制作
我们一开始是单线程制作,后面转换为多线程,多线程也得处理好,只有所有的文档处理完毕才去保存索引
再一个就是读文件的速度,通过实验第一次我们制作索引太慢了,因为是直接访问磁盘,没有到缓存,后面我们换了一个BufferedReader
实现了Parser类
核心属性: 正排索引:ArrayList 每个DocInfo 表示一个文档,在这个文档里面就包含了id,title,url,content倒排索引:HashMap<String,ArrayList> 每个键值对,就表示这个词在哪些文档中出现过 Weight不仅仅是包含了文档id,还包含了权重权重当前是通过词在文档只能出现的频次来进行计算的(标题出现的次数*10 +正文出现的次数)
核心方法:
查正排,直接按照下标来取ArrayList中的元素即可查倒排,直接按照key来取HashMap<String,ArrayList>的value即可添加文档,Parser类在构建索引的调用该方法 构建正排:构造docInfo对象,添加到正排索引的末尾构建倒排:先进行分词,统计词频,遍历分词结果,去更新倒排索引的对应的倒排拉链我们公共对象要考虑到线程安全问题。
保存索引,基于json格式把索引数据给保存到指定文件中加载索引,基于json格式对数据进行解析,把文件中的内容读出来解析到内存中六、实现搜索模块-搜索模块篇
调用索引模块,来完成搜索的核心过程
分词,针对用户输入的查询词进行分词,(用户输入的查询词,可能不是一个词,可能是一句话)触发,拿到分词结果,去倒排索引中查,找到具有相关性的文档~(调用index类查倒排的方法)排序,针对上面触发出来的结果,进行排序(按照相关性,降序排序)包装结果,根据排序后的结果,依次去查正排,获取每个文档的详细信息,包装成一定结构的数据返回出去当然我们这里只是简单的搜索引擎,和真实的搜索引擎没法比的。
6.1实现搜索模块- 创建DocSearcher类
通过这个类完成整个的搜索过程:
import java.util.List;/** * Created by Lin * Description: * User: Administrator * Date: 2022-12-21 * Time: 13:22 */public class DocSearcher { private Index index = new Index(); public DocSearcher(){ //一开始要加载 index.load(); } //完成整个搜索过程的方法 //参数(输入部分)就是用户给出的查询词 //返回值(输出部分)就是搜索结果的集合 public List<Result> search(String query){ //1.[分词]针对query这个查询词进行分词 //2.[触发]针对分词结果来查倒排 //3.[排序]针对触发的结果按照权重降序排序 //4.[包装结果]针对排序的结果,去查正排,构造出要返回的数据 return null; }}我们需要的返回值就是很多的搜索结果:
还需要完成我们的索引加载:直接到构造方法里面使用。
我们在创建一个类表示搜索结果:
/** * Created by Lin * Description: * User: Administrator * Date: 2022-12-21 * Time: 13:24 *///表示搜索结果public class Result { private String title; private String url; //此处是描述 正文的摘要 private String desc; public String getTitle() { return title; } public void setTitle(String title) { this.title = title; } public String getUrl() { return url; } public void setUrl(String url) { this.url = url; } public String getDesc() { return desc; } public void setDesc(String desc) { this.desc = desc; }}注意Result类是标题,url,和摘要,因为我们显示的是正文的一部分。
6.2实现搜索模块- 实现search方法(1)
我们第一部分要实现的有以下的操作:
分词:针对query这个查询词进行分词
触发:针对分词结果来查倒排
排序:针对触发的结果按照权重降序排序
包装结果:针对排序的结果,去查正排,构造出要返回的数据
public List<Result> search(String query) { //1.[分词]针对query这个查询词进行分词 List<Term> terms = ToAnalysis.parse(query).getTerms(); //2.[触发]针对分词结果来查倒排 List<Weight> allTermResult = new ArrayList<>(); for (Term term : terms) { String word = term.getName(); List<Weight> invertedList = index.getInverted(word); if (invertedList == null) { //说明词不存在 continue; } allTermResult.addAll(invertedList); } // 3.[排序]针对触发的结果按照权重降序排序 allTermResult.sort(new Comparator<Weight>() { @Override public int compare(Weight o1, Weight o2) { //降序排序 return o2.getWeight-01.getWeight 升序反之 return o2.getWeight() - o1.getWeight(); } }); //4.[包装结果]针对排序的结果,去查正排,构造出要返回的数据 List<Result> results = new ArrayList<>(); for (Weight weight : allTermResult) { DocInfo docInfo = index.getDocInfo(weight.getDocId()); Result result = new Result(); result.setTitle(docInfo.getTitle()); result.setUrl(docInfo.getUrl()); result.setDesc(GenDesc(docInfo.getContent(),terms)); results.add(result); } return results; }这里要注意我们的第四步:因为我们的倒排得到的只是一些权重和文档ID,并不知道我们详细的内容,详细的内容还是得去正排索引里面。
还有就是我们的摘要,我们现在查出来的是全部的文章,构造最后的结果我们需要的是一段描述,这个描述源于正文,同时也是要包含查询词的一部分。
所以接下来我们要去生成一个描述:
6.2实现搜索模块- 实现search方法(2)
上文说到描述的生成,我们的思路先写出来:
可以获取到所有的分词结果遍历分词结果看看哪个结果在正文中出现,当前的文档不一定会全部包含所有的分词结果针对这个被包含的结果去正文中查询,找到当前查询词的对应位置生成描述 就可以往当前位置往前60个字符,作为描述的开始,在往开始的后面截取160个作为整个描述
private String GenDesc(String content, List<Term> terms) { //先遍历结果,看看哪个结果是在content中存在 int firstPos = -1; for (Term term : terms) { String word = term.getName(); //因为分词结果是会把正文转成小写,所以我们要把查询词也转成小写 //为了搜索结果独立成词 所以加" " firstPos =content.toLowerCase().indexOf(" " + word + " "); if (firstPos >= 0){ break; } if(firstPos ==-1){ //所有的分词结果都不在正文中存在 极端情况 return content.substring(0,160)+"..."; } } //从firstPos 作为基准,往前找60个字符,作为描述的起始位置 String desc =""; //如果当前位置少于60个字符开始位置就是第一个 否则开始位置 在查询词前60个 int descBeg = firstPos < 60 ? 0 : firstPos -60; if (descBeg+160 > content.length()){ //判断是否超过正文长度 //从开始位置到最后 desc = content.substring(descBeg); }else { desc =content.substring(descBeg,descBeg + 160)+"..."; } return desc; }本段生成描述的代码核心思想就是:
找到文档词所在的文章的位置,根据查询词的前60个字符,和查询词后的160个字符,截取当文档描述;
6.3实现搜索模块- 简单验证
我们先到Reslut结果里面加个toString看看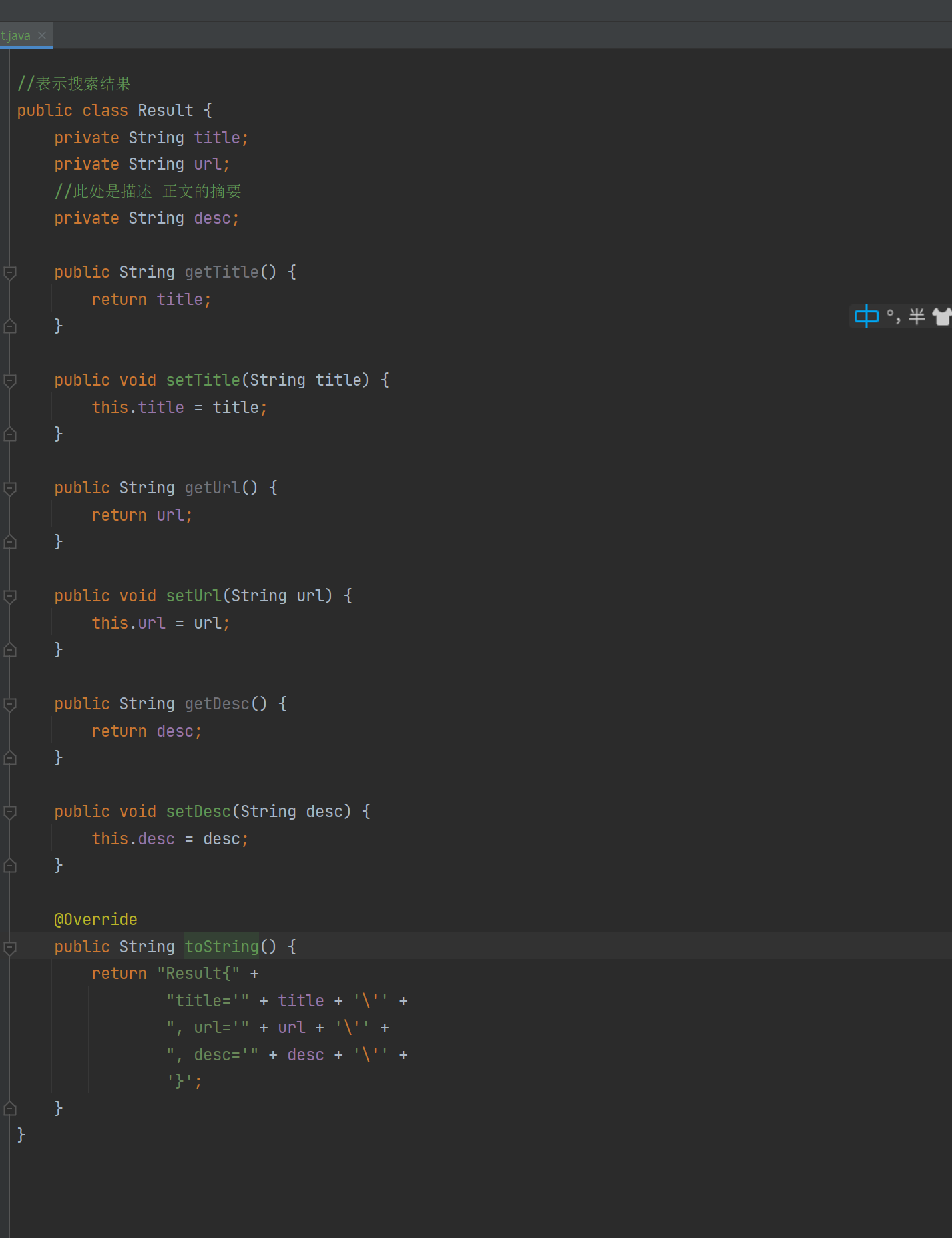
目前搜索类所有的代码
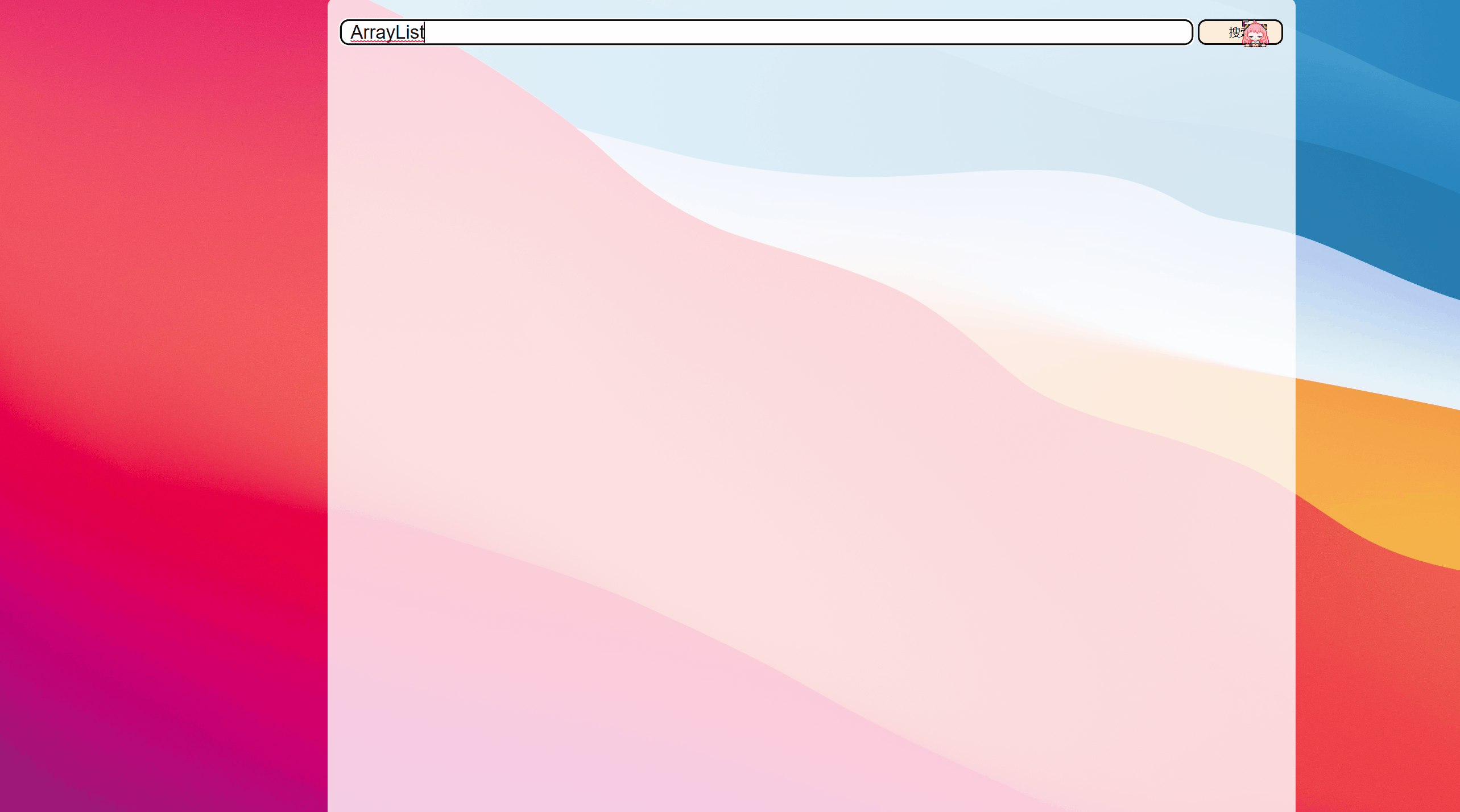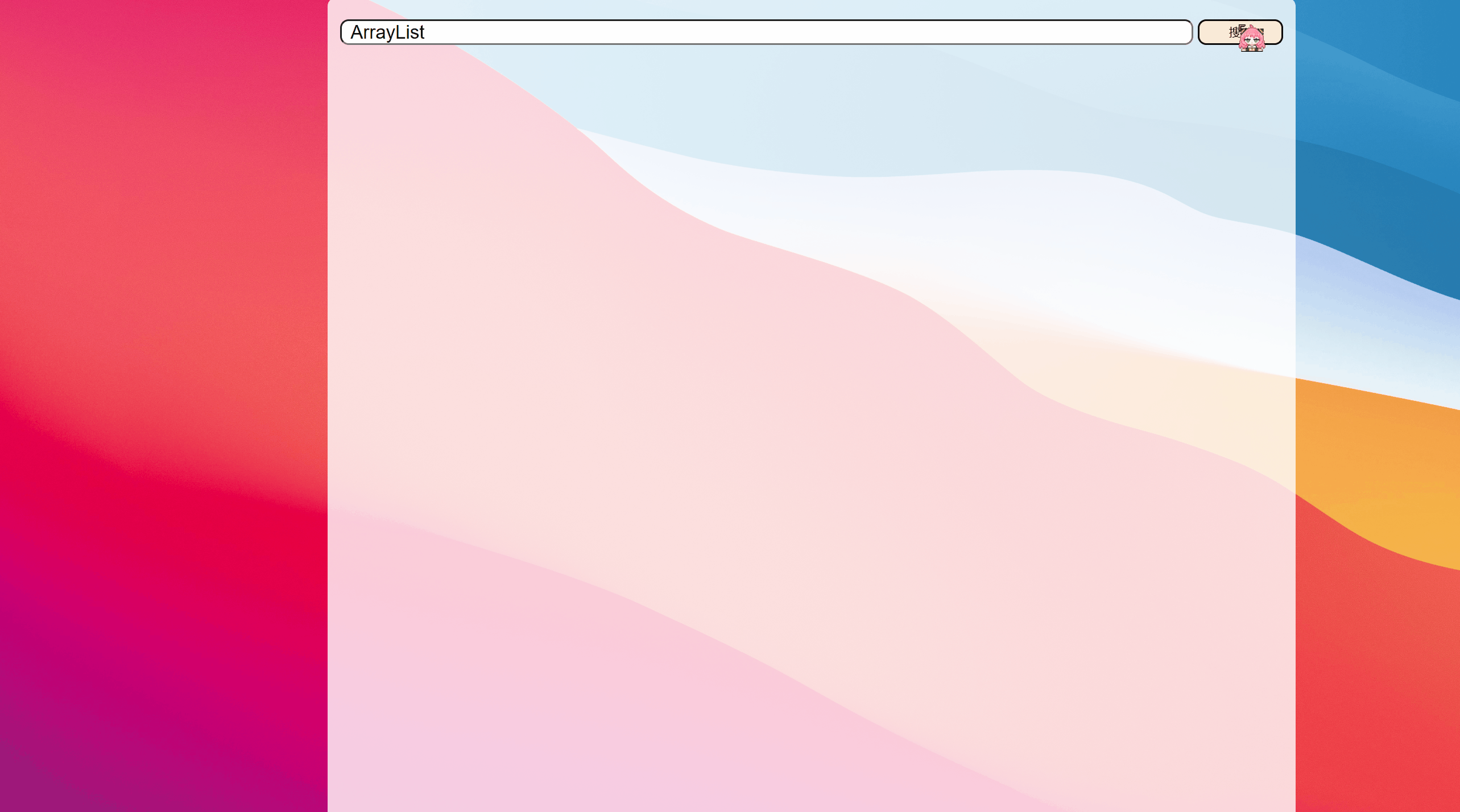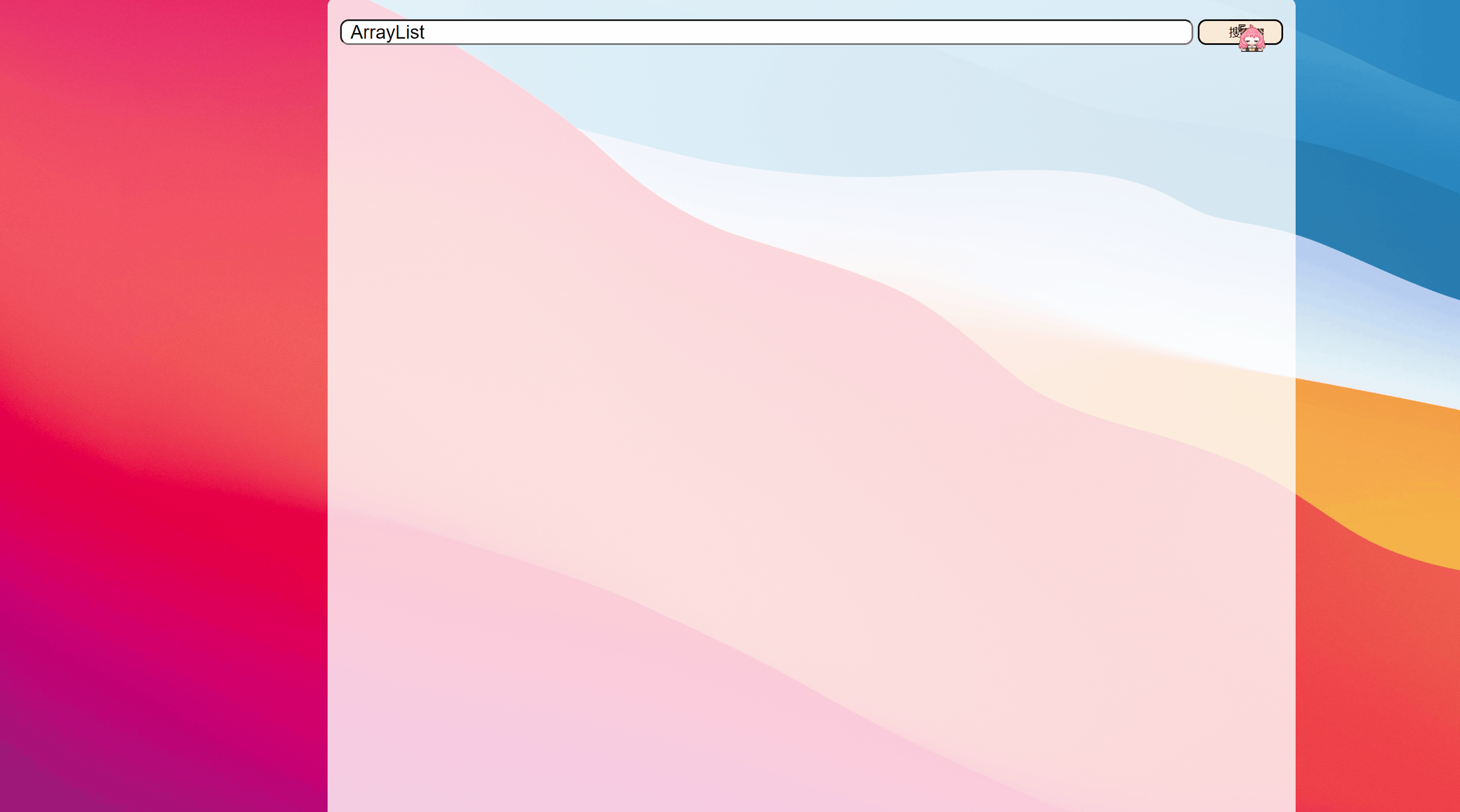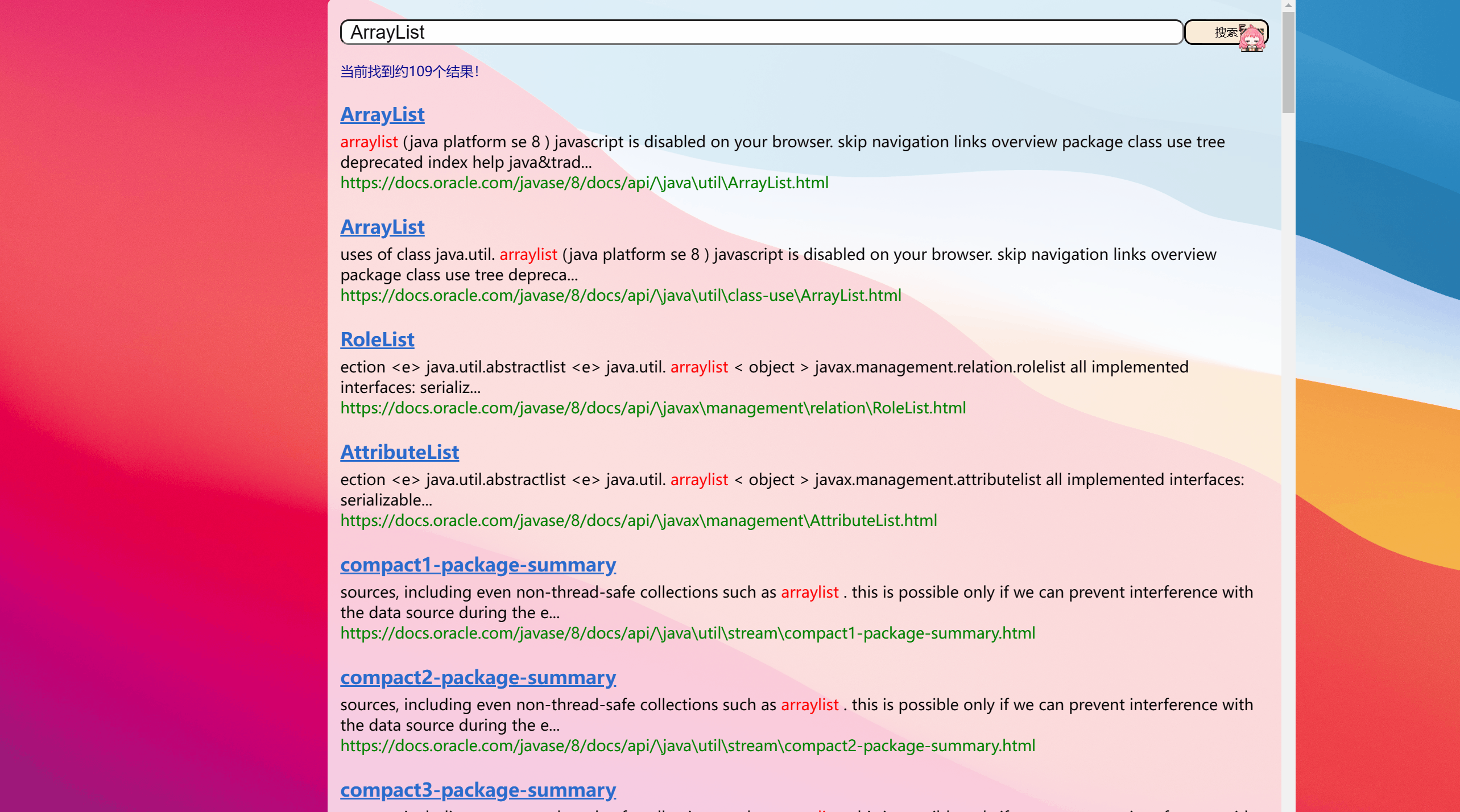
import org.ansj.domain.Term;import org.ansj.splitWord.analysis.ToAnalysis;import java.util.*;/** * Created by Lin * Description: * User: Administrator * Date: 2022-12-21 * Time: 13:22 */public class DocSearcher { private Index index = new Index(); public DocSearcher() { //一开始要加载 index.load(); } //完成整个搜索过程的方法 //参数(输入部分)就是用户给出的查询词 //返回值(输出部分)就是搜索结果的集合 public List<Result> search(String query) { //1.[分词]针对query这个查询词进行分词 List<Term> terms = ToAnalysis.parse(query).getTerms(); //2.[触发]针对分词结果来查倒排 List<Weight> allTermResult = new ArrayList<>(); for (Term term : terms) { String word = term.getName(); List<Weight> invertedList = index.getInverted(word); if (invertedList == null) { //说明词不存在 continue; } allTermResult.addAll(invertedList); } // 3.[排序]针对触发的结果按照权重降序排序 allTermResult.sort(new Comparator<Weight>() { @Override public int compare(Weight o1, Weight o2) { //降序排序 return o2.getWeight-01.getWeight 升序反之 return o2.getWeight() - o1.getWeight(); } }); //4.[包装结果]针对排序的结果,去查正排,构造出要返回的数据 List<Result> results = new ArrayList<>(); for (Weight weight : allTermResult) { DocInfo docInfo = index.getDocInfo(weight.getDocId()); Result result = new Result(); result.setTitle(docInfo.getTitle()); result.setUrl(docInfo.getUrl()); result.setDesc(GenDesc(docInfo.getContent(),terms)); results.add(result); } return results; } private String GenDesc(String content, List<Term> terms) { //先遍历结果,看看哪个结果是在content中存在 int firstPos = -1; for (Term term : terms) { String word = term.getName(); //因为分词结果是会把正文转成小写,所以我们要把查询词也转成小写 //为了搜索结果独立成词 所以加" " firstPos =content.toLowerCase().indexOf(" " + word + " "); if (firstPos >= 0){ break; } if(firstPos ==-1){ //所有的分词结果都不在正文中存在 极端情况 return content.substring(0,160)+"..."; } } //从firstPos 作为基准,往前找60个字符,作为描述的起始位置 String desc =""; //如果当前位置少于60个字符开始位置就是第一个 否则开始位置 在查询词前60个 int descBeg = firstPos < 60 ? 0 : firstPos -60; if (descBeg+160 > content.length()){ //判断是否超过正文长度 //从开始位置到最后 desc = content.substring(descBeg); }else { desc =content.substring(descBeg,descBeg + 160)+"..."; } return desc; } public static void main(String[] args) { DocSearcher docSearcher = new DocSearcher(); Scanner scanner = new Scanner(System.in); while (true) { System.out.print("->"); String query = scanner.next(); List<Result> results = docSearcher.search(query); for (Result result : results) { System.out.println("======================================"); System.out.println(result); } } }}结果:我们搜索一个ArrayList,可以发现排序和我们需要的都有,但是出现了黄色框标注的东西,其实仔细发现他是js代码

为什么会出现呢?因为我们只是在HTML页面去除了标签,但是有些HTML里面包含了< script>标签,就导致了去了标签也出现js代码。 这个问题我们后面在依次解决。
6.4实现搜索模块- 使用正则表达式
对于上面的script标签我们既得去掉标签也得去掉内容,这里我们使用正则表达式
java的String里有许多方法都是支持正则的 indexOf,replace,replaceAll,split…
我们来简单介绍一下我们正则部分符号规则:
. 表示匹配一个不是换行字符(不是\n or \r)
*表示前面的字符可以出现若干次
.* 匹配非换行字符出现若干次
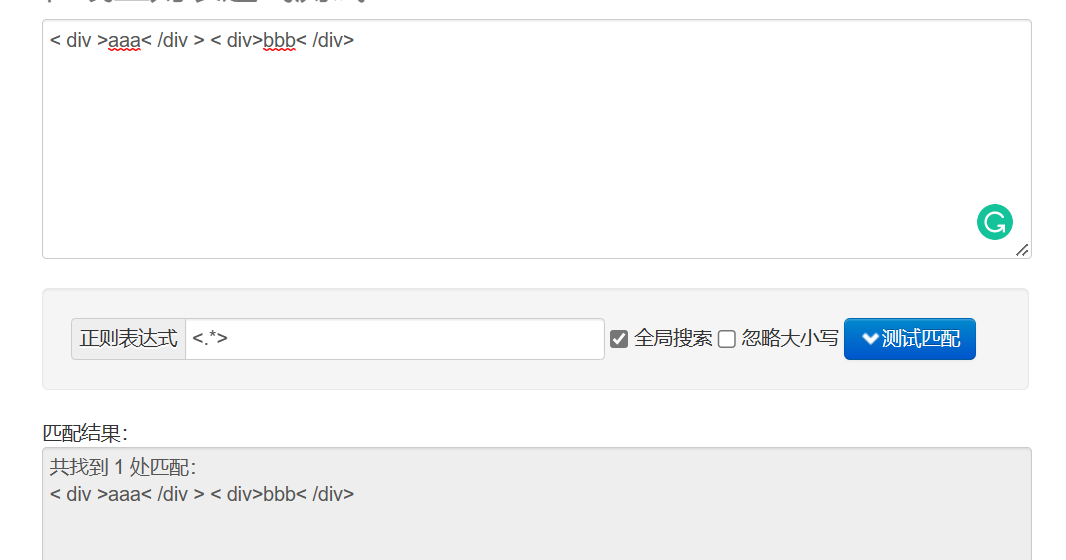
? 表示非贪婪匹配,匹配到一个符合条件的最短结果(贪婪:尽量长的去匹配,匹配到一个符合条件最长的结果)
假设现在有个<.*>的规则,我们文档是< div >aaa< /div > < div>bbb< /div> ,如果是贪婪匹配就会把蓝色的地方全部匹配上。

我们也可以去测试网站去看一下:
如果加上非贪婪匹配 <.*?>: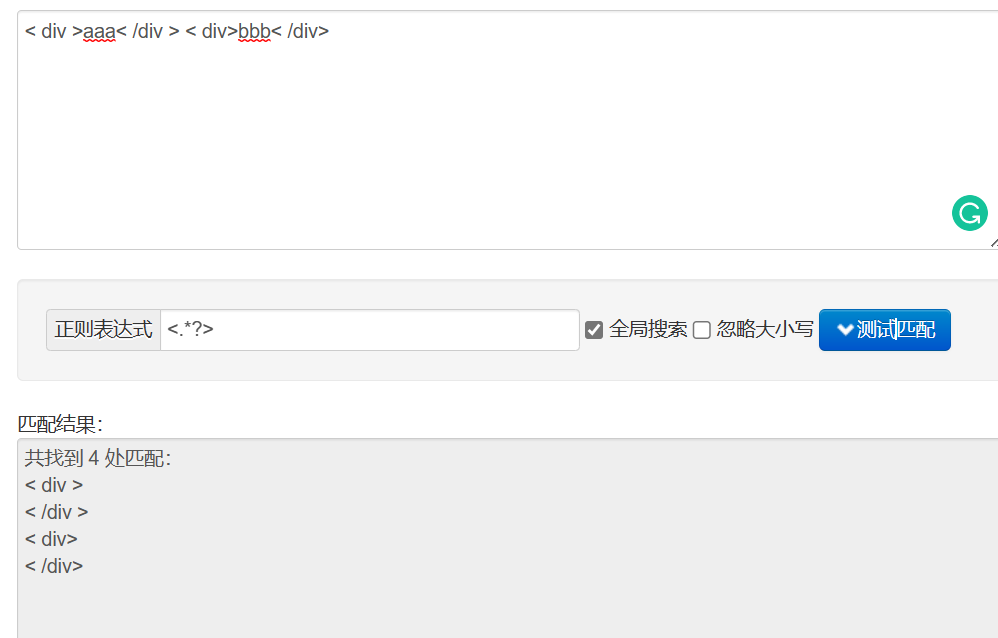
替换为空格的效果: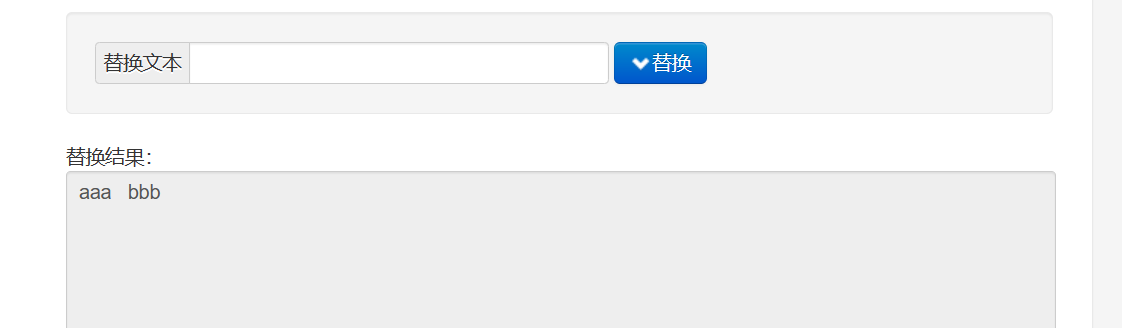
想去掉script标签和内容 正则 就可以写变这样
< script.>(.)< /script> 把属性和内容看成是字符匹配
去掉普通的标签不去掉内容
<.* > 既可以匹配开始标签也可以匹配结束标签
6.5实现搜索模块- 替换script标签及其内容
我们开替换:
private String readFile(File f){ try(BufferedReader bufferedReader = new BufferedReader(new FileReader(f))){ StringBuilder content = new StringBuilder(); while(true){ int ret = bufferedReader.read(); if (ret==-1){ break; } char c = (char) ret; if (c=='\n' || c == '\r'){ c= ' '; } content.append(c); } return content.toString(); }catch (IOException e){ e.printStackTrace(); }return ""; } public String parseContentRegex(File f){ //1.先把整个文件都读取到String里面 String content = readFile(f); //2.替换script标签 content = content.replaceAll("<script.*?>(.*?)</script>"," "); //3.替换普通的HTML标签 content = content.replaceAll("<.*?>"," "); //4.使用正则把多个空格,合并成一个空格 content = content.replaceAll("\\s+"," "); return content; }这里要注意的是替换的顺序,要先script标签在html标签,不然就出问题了,最后我们测试一下对比效果:
可以发现js代码是没了,这个的空格太多,也被我们调整了,/s+ 就是至少查询一次的意思。
然后我们替换一下,重新制作索引。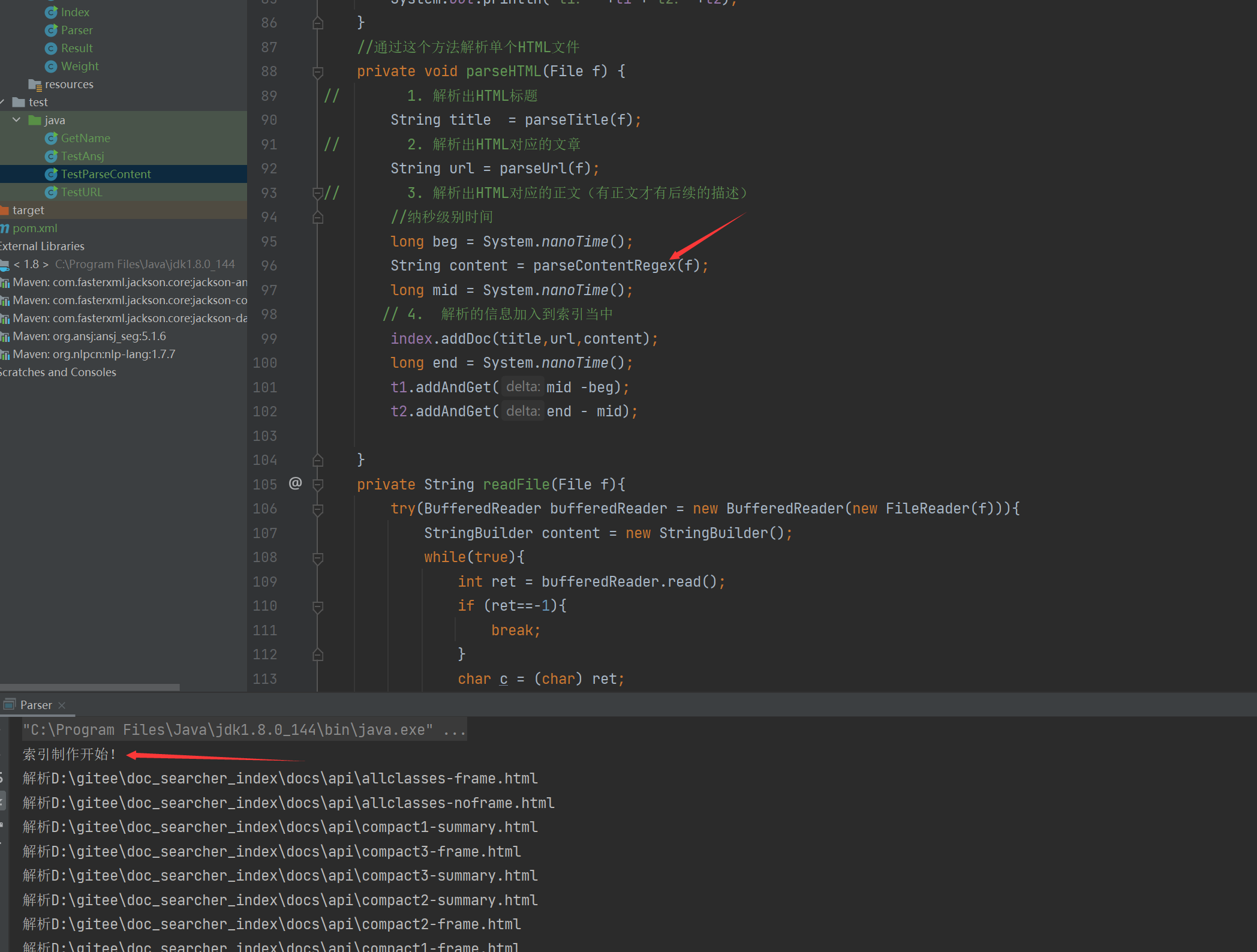
Parser类全部代码:
import com.sun.org.apache.regexp.internal.RE;import java.io.*;import java.util.ArrayList;import java.util.concurrent.CountDownLatch;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.atomic.AtomicLong;/** * Created by Lin * Description: * User: Administrator * Date: 2022-12-15 * Time: 19:15 */public class Parser { //先指定一个加载文档的路径 ,由于是固定路径 我们使用 static 类属性 不需要变final private static final String INPUT_PATH ="D:\\gitee\\doc_searcher_index\\docs\\api"; // 只需要api文件夹下的文件 //创建一个Index实例 private Index index =new Index(); //为了避免线程不安全 private AtomicLong t1 = new AtomicLong(0); private AtomicLong t2 = new AtomicLong(0); //通过这个方法实现单线程制作索引 public void run(){ long beg = System.currentTimeMillis(); System.out.println("索引制作开始"); //整个Parser类的入口 //1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到 ArrayList<File> fileList = new ArrayList<>(); enumFile(INPUT_PATH,fileList); //测试枚举时间 long endEnumFile = System.currentTimeMillis(); System.out.println("枚举文件完毕 时间"+(endEnumFile - beg)); //2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引 for (File f :fileList){ //通过这个方法解析单个HTML文件 System.out.println("开始解析:" + f.getAbsolutePath()); parseHTML(f); } long endFor = System.currentTimeMillis(); System.out.println("循环遍历文件完毕 时间"+(endFor - endEnumFile)+"ms"); //3. 把内存中构造好的索引数据结构,保存到指定的文件中 index.save(); long end = System.currentTimeMillis(); System.out.println("索引制作完毕,消耗时间:"+(end - beg) + "ms"); } //通过这个方法实现多线程制作索引 public void runByThread() throws InterruptedException { long beg =System.currentTimeMillis(); System.out.println("索引制作开始!"); //1.,枚举全部文件 ArrayList<File> files = new ArrayList<>(); enumFile(INPUT_PATH,files); //2.循环遍历文件 此处为了通过多线程制作索引,就直接引入线程池 CountDownLatch latch = new CountDownLatch(files.size()); ExecutorService executorService = Executors.newFixedThreadPool(8); for(File f:files){ //添加任务submit到线程池 executorService.submit(new Runnable() { @Override public void run() { System.out.println("解析"+f.getAbsolutePath()); parseHTML(f); //保证所有的索引制作完再保存索引 latch.countDown(); } }); } //latch.await()等待全部countDown完成,才阻塞结束。 latch.await(); executorService.shutdown(); //3.保存索引 ,可能存在还没有执行完的情况 index.save(); long end =System.currentTimeMillis(); System.out.println("索引制作结束!时间"+(end - beg)+"ms"); System.out.println("t1:" +t1 +"t2:"+t2); } //通过这个方法解析单个HTML文件 private void parseHTML(File f) {// 1. 解析出HTML标题 String title = parseTitle(f);// 2. 解析出HTML对应的文章 String url = parseUrl(f);// 3. 解析出HTML对应的正文(有正文才有后续的描述) //纳秒级别时间 long beg = System.nanoTime(); String content = parseContentRegex(f); long mid = System.nanoTime(); // 4. 解析的信息加入到索引当中 index.addDoc(title,url,content); long end = System.nanoTime(); t1.addAndGet(mid -beg); t2.addAndGet(end - mid); } private String readFile(File f){ try(BufferedReader bufferedReader = new BufferedReader(new FileReader(f))){ StringBuilder content = new StringBuilder(); while(true){ int ret = bufferedReader.read(); if (ret==-1){ break; } char c = (char) ret; if (c=='\n' || c == '\r'){ c= ' '; } content.append(c); } return content.toString(); }catch (IOException e){ e.printStackTrace(); }return ""; } public String parseContentRegex(File f){ //1.先把整个文件都读取到String里面 String content = readFile(f); //2.替换script标签 content = content.replaceAll("<script.*?>(.*?)</script>"," "); //3.替换普通的HTML标签 content = content.replaceAll("<.*?>"," "); //4.使用正则把多个空格,合并成一个空格 content = content.replaceAll("\\s+"," "); return content; } public String parseContent(File f) { //先按照一个字符一个字符来读取,以< 和 > 来控制拷贝数据的开关 try(BufferedReader bufferedReader = new BufferedReader(new FileReader(f),1024 *1024)) { //加上一个开关 boolean isCopy = true; //还准备一个保存结果的StringBuilder StringBuilder content = new StringBuilder(); while (true){ //read int类型 读到最后返回-1 int ret = bufferedReader.read(); if (ret == -1){ //表示文件读完了 break; } //不是-1就是合法字符 char c = (char) ret; if (isCopy){ //打开的状态可以拷贝 if (c == '<'){ isCopy =false; continue; } //判断是否是换行 if (c == '\n' || c == '\r'){// 是换行就变成空格 c = ' '; } //其他字符进行拷贝到StringBuilder中 content.append(c); }else{ // if (c=='>'){ isCopy= true; } } } return content.toString(); } catch (IOException e) { e.printStackTrace(); } return ""; } private String parseUrl(File f) { //固定的前缀 String path = "https://docs.oracle.com/javase/8/docs/api/"; //只放一个参数的意思是:前面一段都不需要,取后面的一段 String path2= f.getAbsolutePath().substring(INPUT_PATH.length()); return path + path2; } private String parseTitle(File f) { //获取文件名 String name = f.getName(); return name.substring(0,name.length()-".html".length()); } //第一个参数表示从那个目录开始进行遍历,第二个目录表示递归得到的结果 private void enumFile(String inputPath, ArrayList<File> fileList) { //我们需要把String类型的路径变成文件类 好操作点 File rootPath = new File(inputPath); //listFiles()类似于Linux的ls把当前目录中包含的文件名获取到 //使用listFiles只可以看见一级目录,想看到子目录需要递归操作 File[] files = rootPath.listFiles(); for (File file : files) { //根据当前的file的类型,觉得是否递归 //如果file是普通文件就把file加入到listFile里面 //如果file是一个目录 就递归调用enumFile这个方法,来进一步获取子目录的内容 if (file.isDirectory()){ //根路径要变 enumFile(file.getAbsolutePath(),fileList); }else { //只针对HTML文件 if(file.getAbsolutePath().endsWith(".html")){ //普通HTML文件 fileList.add(file); } } } } public static void main(String[] args) throws InterruptedException { //通过main方法来实现整个制作索引的过程 Parser parser = new Parser(); parser.runByThread(); }}重新到搜索类去看看:
完美解决。
6.6实现搜索模块- 搜索模块小结
我们搜索模块主要是实现看 Searcher类 search方法:
1.分词 2.触发 3.排序 4.包装结果 我们是把之前实现的准备好的工作串起来了。
我们现在怎么简单是因为还没有上业务逻辑:
别人这里还展示图片,地区等等,各种用户体验拉满,
以后我们实际开发技术,还是得为了业务服务。接下来我们开始实现web模块。
七、实现Web模块-约定前后端交互接口
我们接下来要实现web模块,提供web接口,把程序呈现给用户看。
前端(HTML+css+js)+后端(java、servlet / Spring):
此处我们只需要实现一个接口,搜索接口即可

7.1 实现Web模块-基于Servlet的方式实现后端
我们先使用servlet实现,后面换变Spring boot
我的Tomcat是8.5.x 所以使用的是 servlet 3.1版:
package api;import com.fasterxml.jackson.databind.ObjectMapper;import searcher.DocSearcher;import searcher.Result;import javax.servlet.ServletException;import javax.servlet.annotation.WebServlet;import javax.servlet.http.HttpServlet;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import java.io.IOException;import java.util.List;/** * Created by Lin * Description: * User: Administrator * Date: 2022-12-23 * Time: 15:15 */@WebServlet("/search")public class DocSearcherServlet extends HttpServlet { //此处的DocSearcher 对象应该是全局唯一的,所以给static修饰 private static DocSearcher docSearcher = new DocSearcher(); private ObjectMapper objectMapper = new ObjectMapper(); @Override protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { //1.先解析请求,拿到用户提交的查询词 String query = req.getParameter("query"); if(query == null || query.equals("")){ String msg = "你的参数非法!没有获取到query的值"; resp.sendError(404,msg); return; } //2. 打印记录一下query的值 System.out.println("query="+query); //3.调用搜索模块,来进行搜索 List<Result> results = docSearcher.search(query); //4.把当前的搜索结果进行打包 resp.setContentType("application/json;charset=utf-8"); objectMapper.writeValue(resp.getWriter(),results); }}我们的目录结构也更改了一下:
7.2 实现Web模块-验证后端接口
这里我们是社区版的然后就使用smartTomcat配置运行一下
网址输入这个:
当前初步阶段我们服务器是可以返回数据的
7.3 实现Web模块-实现页面结构
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Java文档搜索</title></head><body> <!-- 1.搜索框 和搜索按钮 --> <!-- 2.显示搜索结果 --> <!-- 通过.container来表示整个页面的元素的容器 --> <div class="container"> <!-- 搜索框加搜索按钮 --> <div class="header"> <input type="text"> <button id="search-btn">搜索</button> </div> <!-- 显示搜索结果 --> <div class="result"> <!-- 包含了很多记录 --> <!-- 通过访问服务器的方式获取搜索结果 --> <div class="item"> <a href="#">我是标题</a> <div class="class">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div> <div class="url">http://www.baidu.com</div> </div> <div class="item"> <a href="#">我是标题</a> <div class="class">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div> <div class="url">http://www.baidu.com</div> </div> <div class="item"> <a href="#">我是标题</a> <div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div> <div class="url">http://www.baidu.com</div> </div> <div class="item"> <a href="#">我是标题</a> <div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div> <div class="url">http://www.baidu.com</div> </div> <div class="item"> <a href="#">我是标题</a> <div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div> <div class="url">http://www.baidu.com</div> </div> </div> </div></body></html>我们最基础的页面有了:

7.4 实现Web模块-实现页面样式(CSS)
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Java文档搜索</title></head><body> <!-- 1.搜索框 和搜索按钮 --> <!-- 2.显示搜索结果 --> <!-- 通过.container来表示整个页面的元素的容器 --> <div class="container"> <!-- 搜索框加搜索按钮 --> <div class="header"> <input type="text"> <button id="search-btn">搜索</button> </div> <!-- 显示搜索结果 --> <div class="result"> <!-- 包含了很多记录 --> <!-- 通过访问服务器的方式获取搜索结果 --> <div class="item"> <a href="#">我是标题</a> <div class="class">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div> <div class="url">http://www.baidu.com</div> </div> <div class="item"> <a href="#">我是标题</a> <div class="class">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div> <div class="url">http://www.baidu.com</div> </div> <div class="item"> <a href="#">我是标题</a> <div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div> <div class="url">http://www.baidu.com</div> </div> <div class="item"> <a href="#">我是标题</a> <div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div> <div class="url">http://www.baidu.com</div> </div> <div class="item"> <a href="#">我是标题</a> <div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div> <div class="url">http://www.baidu.com</div> </div> </div> </div> <style > /* 这部分代码来写样式 */ /* 先去掉浏览器默认的样式 */ *{ margin: 0; padding: 0; box-sizing: border-box; } /* 给整体的页面指定一个高度(和浏览器窗口一样高) */ html,body{ height: 100%; /* 设置背景图 */ background-image: url(image/bjt.jpg); /* 设置背景图不平铺 */ background-repeat: no-repeat; /* 设置背景图的大小 */ background-size: cover; /* 设置背景图的位置 */ background-position: center center; } /* 针对.container 也设置样式,实现版心效果 */ .container{ width: 1135px; height: 100%; /* 设置水平居中 */ margin: 0 auto; /* 设置背景色,让版心和背景图能够区分开 */ background-color:rgba(255, 255, 255, 0.8); /* 设置圆角矩形 */ border-radius: 10px; /* 设置内边距 避免文章内容紧填边界 */ padding: 15px; /* 超出元素的部分,自动生成一个滚动条 */ overflow: auto; } .header{ width: 100%; height: 50px; display: flex; justify-content: space-between; align-items: center; } .header> input{ height: 30px; width: 1000px; font-size: 22px; line-height: 50px; padding-left: 10px; border-radius: 10px; } .header>button{ height: 30px; width: 100px; background-color: antiquewhite; color: black; border-radius: 10px; } .result .count{ color: darkblue; margin-top: 10px; } .header>button:active{ background: gray; } .item{ width:100%; margin-top: 20px; } .item a{ display: block; height: 40px; font-size: 22px; line-height: 40px; font-weight: 700; color: rgb(42, 107, 205); } .item .desc{ font-size: 18px; } .item .url{ font-size: 18px; color: rgb(0, 130, 0); } .item>.desc>i { color: red; /* 去掉斜体 */ font-style: normal; } </style></body></html>
7.5 实现Web模块-通过ajax获取搜索结果
上面我们看到的数据其实是死的,真实的数据还是得通过服务器返回数据,我们使用ajax发生:
当用户点击搜索按钮的时候,浏览器会获取搜索框的内容,基于ajax构造请求,然后发送给搜索服务器,浏览器获取到搜索结果的时候 ,再根据结果的json数据,把页面给生成出来,我们使用jquery。
<script src="http://libs.baidu.com/jquery/2.0.0/jquery.min.js"></script>复制这个就可以使用了。
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Java文档搜索</title></head><body> <!-- 1.搜索框 和搜索按钮 --> <!-- 2.显示搜索结果 --> <!-- 通过.container来表示整个页面的元素的容器 --> <div class="container"> <!-- 搜索框加搜索按钮 --> <div class="header"> <input type="text"> <button id="search-btn">搜索</button> </div> <!-- 显示搜索结果 --> <div class="result"> <!-- 包含了很多记录 --> <!-- 通过访问服务器的方式获取搜索结果 --><!-- <div class="item">--><!-- <a href="#">我是标题</a>--><!-- <div class="class">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>--><!-- <div class="url">http://www.baidu.com</div>--><!-- </div>--><!-- <div class="item">--><!-- <a href="#">我是标题</a>--><!-- <div class="class">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>--><!-- <div class="url">http://www.baidu.com</div>--><!-- </div>--><!-- --><!-- <div class="item">--><!-- <a href="#">我是标题</a>--><!-- <div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>--><!-- <div class="url">http://www.baidu.com</div>--><!-- </div>--><!-- <div class="item">--><!-- <a href="#">我是标题</a>--><!-- <div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>--><!-- <div class="url">http://www.baidu.com</div>--><!-- </div>--><!-- <div class="item">--><!-- <a href="#">我是标题</a>--><!-- <div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>--><!-- <div class="url">http://www.baidu.com</div>--><!-- </div>--> </div> </div> <style > /* 这部分代码来写样式 */ /* 先去掉浏览器默认的样式 */ *{ margin: 0; padding: 0; box-sizing: border-box; } /* 给整体的页面指定一个高度(和浏览器窗口一样高) */ html,body{ height: 100%; /* 设置背景图 */ background-image: url(image/bjt.jpg); /* 设置背景图不平铺 */ background-repeat: no-repeat; /* 设置背景图的大小 */ background-size: cover; /* 设置背景图的位置 */ background-position: center center; } /* 针对.container 也设置样式,实现版心效果 */ .container{ width: 1135px; height: 100%; /* 设置水平居中 */ margin: 0 auto; /* 设置背景色,让版心和背景图能够区分开 */ background-color:rgba(255, 255, 255, 0.8); /* 设置圆角矩形 */ border-radius: 10px; /* 设置内边距 避免文章内容紧填边界 */ padding: 15px; /* 超出元素的部分,自动生成一个滚动条 */ overflow: auto; } .header{ width: 100%; height: 50px; display: flex; justify-content: space-between; align-items: center; } .header> input{ height: 30px; width: 1000px; font-size: 22px; line-height: 50px; padding-left: 10px; border-radius: 10px; } .header>button{ height: 30px; width: 100px; background-color: antiquewhite; color: black; border-radius: 10px; } .result .count{ color: darkblue; margin-top: 10px; } .header>button:active{ background: gray; } .item{ width:100%; margin-top: 20px; } .item a{ display: block; height: 40px; font-size: 22px; line-height: 40px; font-weight: 700; color: rgb(42, 107, 205); } .item .desc{ font-size: 18px; } .item .url{ font-size: 18px; color: rgb(0, 130, 0); } .item>.desc>i { color: red; /* 去掉斜体 */ font-style: normal; } </style><script src="http://libs.baidu.com/jquery/2.0.0/jquery.min.js"></script><script> //放置用户自己写的js代码 let button = document.querySelector("#search-btn"); button.onclick =function(){ // 先获取输入框的内容 let input =document.querySelector(".header input"); let query = input.value; //然后构造ajax的请求 $.ajax({ type:"GET", url:"search?query="+query, success:function(data,status){ // success会在请求成功后调用 //data参数就是表示拿到的结果数据 //status参数就表示的HTTP状态码 //根据收到的数据结果,构造出页面内容 //console.log(data); buildResult(data); } }) } function buildResult(data) { //通过这个函数,来把响应数据给构造成页面内容 //遍历data中的元素,针对每个元素都创建一个div.item,然后把标题,url,描述构造好 //再把这个div.item 给加入到div.result中 //这些操作都是基于DOM API来展开 //获取到.result这个标签 let result = document.querySelector('.result'); //清空上次结果 result.innerHTML=' '; //先构造一个div用来显示结果的个数 let countDiv = document.createElement("div"); countDiv.innerHTML = '当前找到约' + data.length + '个结果!'; countDiv.className = 'count'; result.appendChild(countDiv); //此处得到的item分别代表data的每个元素 for(let item of data){ let itemDiv = document.createElement('div'); itemDiv.className = 'item'; //构造一个标题 let title = document.createElement('a'); title.href=item.url; title.innerHTML = item.title; title.target='_blank'; itemDiv.appendChild(title); //构造一个描述 let desc = document.createElement('div'); desc.className='desc'; desc.innerHTML=item.desc; itemDiv.appendChild(desc); //构造一个url let url = document.createElement('div'); url.className = 'url'; url.innerHTML = item.url; itemDiv.appendChild(url); // 把itemDiv加入到result里面 result.appendChild(itemDiv); } }</script></body></html>7.6 实现Web模块- 实现标红逻辑
我们想要实现一个类似这样的效果:
思路:
private String GenDesc(String content, List<Term> terms) { //先遍历结果,看看哪个结果是在content中存在 int firstPos = -1; for (Term term : terms) { String word = term.getName(); //因为分词结果是会把正文转成小写,所以我们要把查询词也转成小写 //为了搜索结果独立成词 所以加" " firstPos =content.toLowerCase().indexOf(" " + word + " "); if (firstPos >= 0){ break; } if(firstPos ==-1){ //所有的分词结果都不在正文中存在 极端情况 return content.substring(0,160)+"..."; } } //从firstPos 作为基准,往前找60个字符,作为描述的起始位置 String desc =""; //如果当前位置少于60个字符开始位置就是第一个 否则开始位置 在查询词前60个 int descBeg = firstPos < 60 ? 0 : firstPos -60; if (descBeg+160 > content.length()){ //判断是否超过正文长度 //从开始位置到最后 desc = content.substring(descBeg); }else { desc =content.substring(descBeg,descBeg + 160)+"..."; } //在此处加上一个替换操作,把描述中的分词结果相同的部分,给加上一层<i>标签,就可以通过replace的方式实现 for (Term term : terms){ String word = term.getName(); //只有是全部是一个查询词 才加上 i 标签 正则规则(?i)大小写全部匹配 desc = desc.replaceAll("(?i)"+word+" ","<i> " + word + " </i>"); } return desc; }最后代码部分: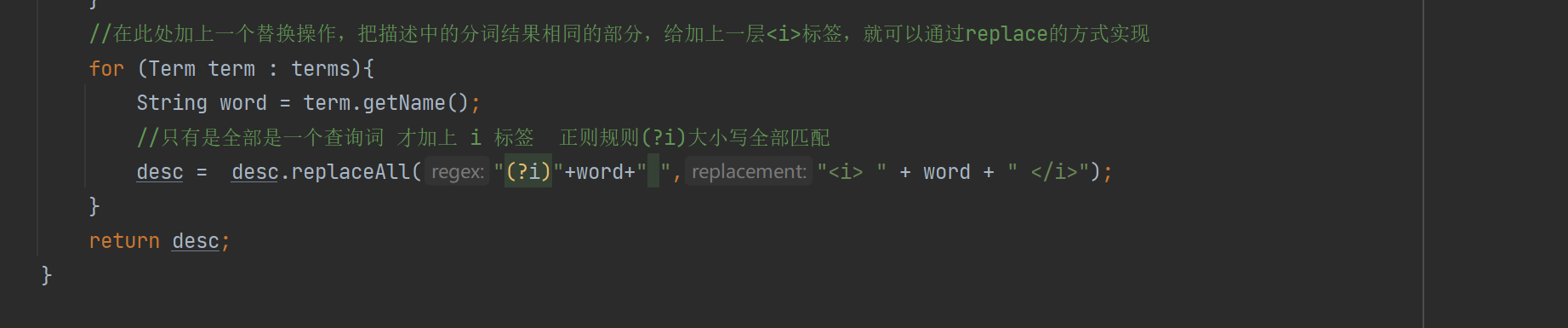
最后的效果:

7.7 实现Web模块- 测试更复杂的查询词
我们在搜索框尝试把单词分开,服务器那边就报500错误,这个是为什么呢?
详细信息:
原来是我们的极端路线:总长度都没有160,我们还截取160个字符所以报错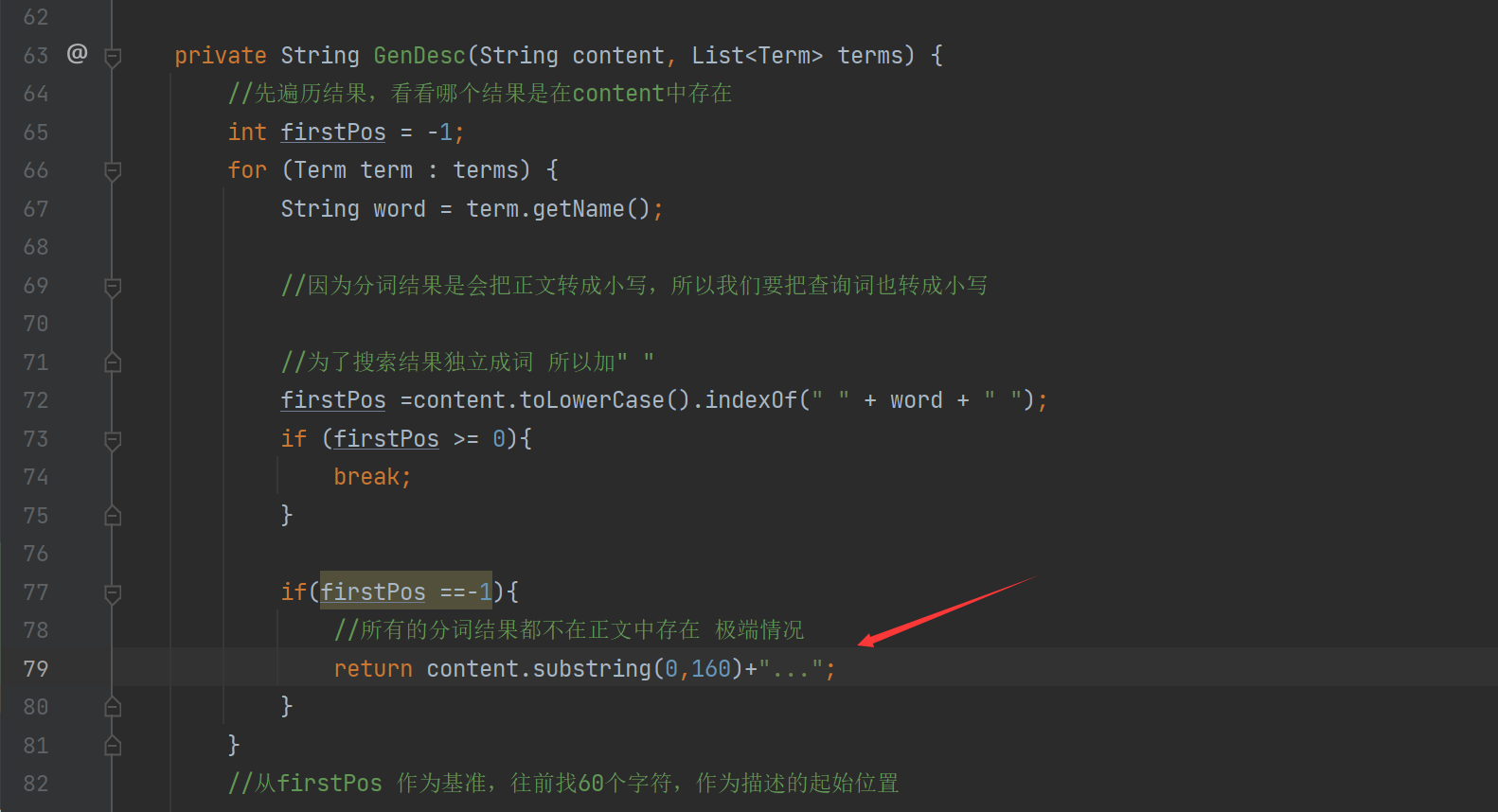
我们把代码改一下: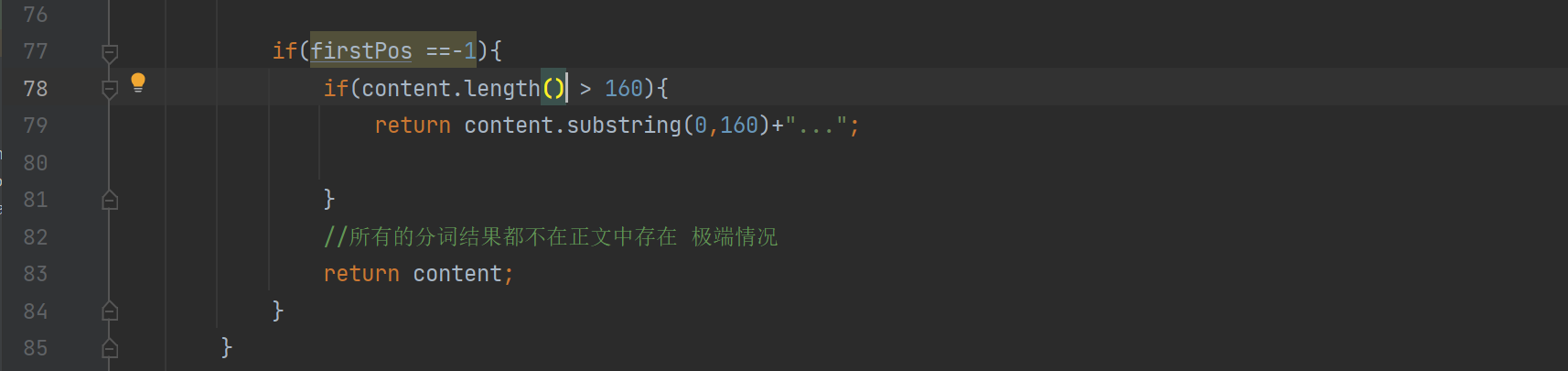
已经可以了:
但是我们又发现一个问题:出现好多和查询词没有关系的词目

这个是为什么呢?
因为我们刚刚的查询词不仅仅是 Array List,而是 Array,空格,List 三个部分,代码会拿空格来查询倒排索引!,所以我们要去掉空格,这里我们引入一个特别的东西。
暂停词:有些东西,属于高频,但是没有啥意义的内容
像: a is have 一 的 是 有,我们要让这类不触发代码查询。
7.8 实现Web模块- 处理停用词
我们可以去网上找到现成的停用词表即可。注意此处的暂停词表中第一个是一个空格:
接下来就可以让搜索程序加载这个停用词表到内存中,使用一个hashSet把这些词都存起来,再针对分词结果,在停用词表中进行筛选,如果其中结果在词表中存在,就直接干掉。
这里我们就放在txt文本中:
package searcher;import org.ansj.domain.Term;import org.ansj.splitWord.analysis.ToAnalysis;import java.io.BufferedReader;import java.io.FileReader;import java.io.IOException;import java.util.*;/** * Created by Lin * Description: * User: Administrator * Date: 2022-12-21 * Time: 13:22 */public class DocSearcher { private static final String STOP_WORD_PATH ="D:\\gitee\\doc_searcher_index\\stop_word.txt"; //使用这个HashSet 来保存停用词 private HashSet<String> stopWords = new HashSet<>(); private Index index = new Index(); public DocSearcher() { //一开始要加载 index.load(); loadStopWords(); } //完成整个搜索过程的方法 //参数(输入部分)就是用户给出的查询词 //返回值(输出部分)就是搜索结果的集合 public List<Result> search(String query) { //1.[分词]针对query这个查询词进行分词 List<Term> oldTerms = ToAnalysis.parse(query).getTerms(); List<Term> terms = new ArrayList<>(); //针对分词结果,使用暂停词表 for (Term term : oldTerms){ if (stopWords.contains(term.getName())){ //是暂停词就不拷贝 continue; } terms.add(term); } //2.[触发]针对分词结果来查倒排 List<Weight> allTermResult = new ArrayList<>(); for (Term term : terms) { String word = term.getName(); List<Weight> invertedList = index.getInverted(word); if (invertedList == null) { //说明词不存在 continue; } allTermResult.addAll(invertedList); } // 3.[排序]针对触发的结果按照权重降序排序 allTermResult.sort(new Comparator<Weight>() { @Override public int compare(Weight o1, Weight o2) { //降序排序 return o2.getWeight-01.getWeight 升序反之 return o2.getWeight() - o1.getWeight(); } }); //4.[包装结果]针对排序的结果,去查正排,构造出要返回的数据 List<Result> results = new ArrayList<>(); for (Weight weight : allTermResult) { DocInfo docInfo = index.getDocInfo(weight.getDocId()); Result result = new Result(); result.setTitle(docInfo.getTitle()); result.setUrl(docInfo.getUrl()); result.setDesc(GenDesc(docInfo.getContent(),terms)); results.add(result); } return results; } private String GenDesc(String content, List<Term> terms) { //先遍历结果,看看哪个结果是在content中存在 int firstPos = -1; for (Term term : terms) { String word = term.getName(); //因为分词结果是会把正文转成小写,所以我们要把查询词也转成小写 //为了搜索结果独立成词 所以加" " firstPos =content.toLowerCase().indexOf(" " + word + " "); if (firstPos >= 0){ break; } if(firstPos ==-1){ if(content.length() > 160){ return content.substring(0,160)+"..."; } //所有的分词结果都不在正文中存在 极端情况 return content; } } //从firstPos 作为基准,往前找60个字符,作为描述的起始位置 String desc =""; //如果当前位置少于60个字符开始位置就是第一个 否则开始位置 在查询词前60个 int descBeg = firstPos < 60 ? 0 : firstPos -60; if (descBeg+160 > content.length()){ //判断是否超过正文长度 //从开始位置到最后 desc = content.substring(descBeg); }else { desc =content.substring(descBeg,descBeg + 160)+"..."; } //在此处加上一个替换操作,把描述中的分词结果相同的部分,给加上一层<i>标签,就可以通过replace的方式实现 for (Term term : terms){ String word = term.getName(); //只有是全部是一个查询词 才加上 i 标签 正则规则(?i)大小写全部匹配 desc = desc.replaceAll("(?i)"+word+" ","<i> " + word + " </i>"); } return desc; } public void loadStopWords (){ System.out.println("加载暂停词表"); try(BufferedReader bufferedReader = new BufferedReader(new FileReader(STOP_WORD_PATH))){ while (true){ String line = bufferedReader.readLine(); if (line == null){ //读取文件完毕 break; } stopWords.add(line); } }catch (IOException e){ e.printStackTrace(); } } public static void main(String[] args) { DocSearcher docSearcher = new DocSearcher(); Scanner scanner = new Scanner(System.in); while (true) { System.out.print("->"); String query = scanner.next(); List<Result> results = docSearcher.search(query); for (Result result : results) { System.out.println("======================================"); System.out.println(result); } } }}暂停词的加载到HashSet: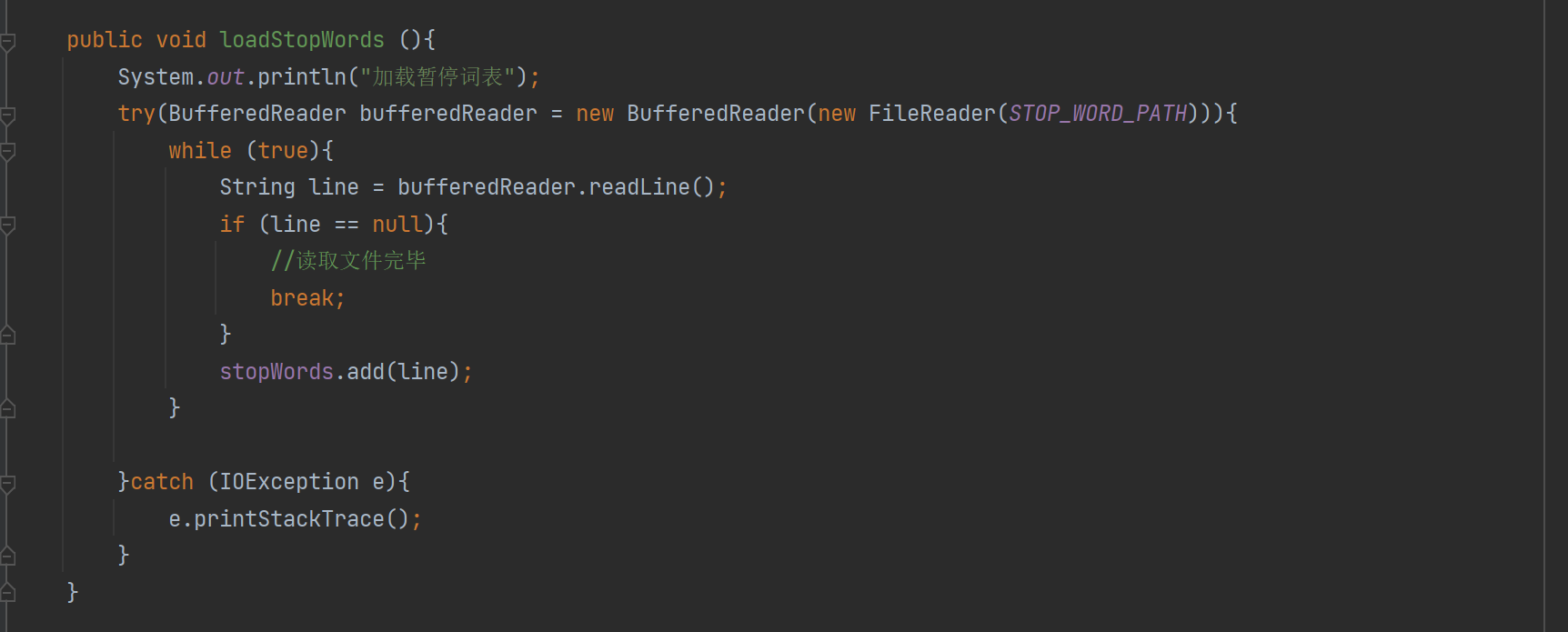
在search方法中也更改一下: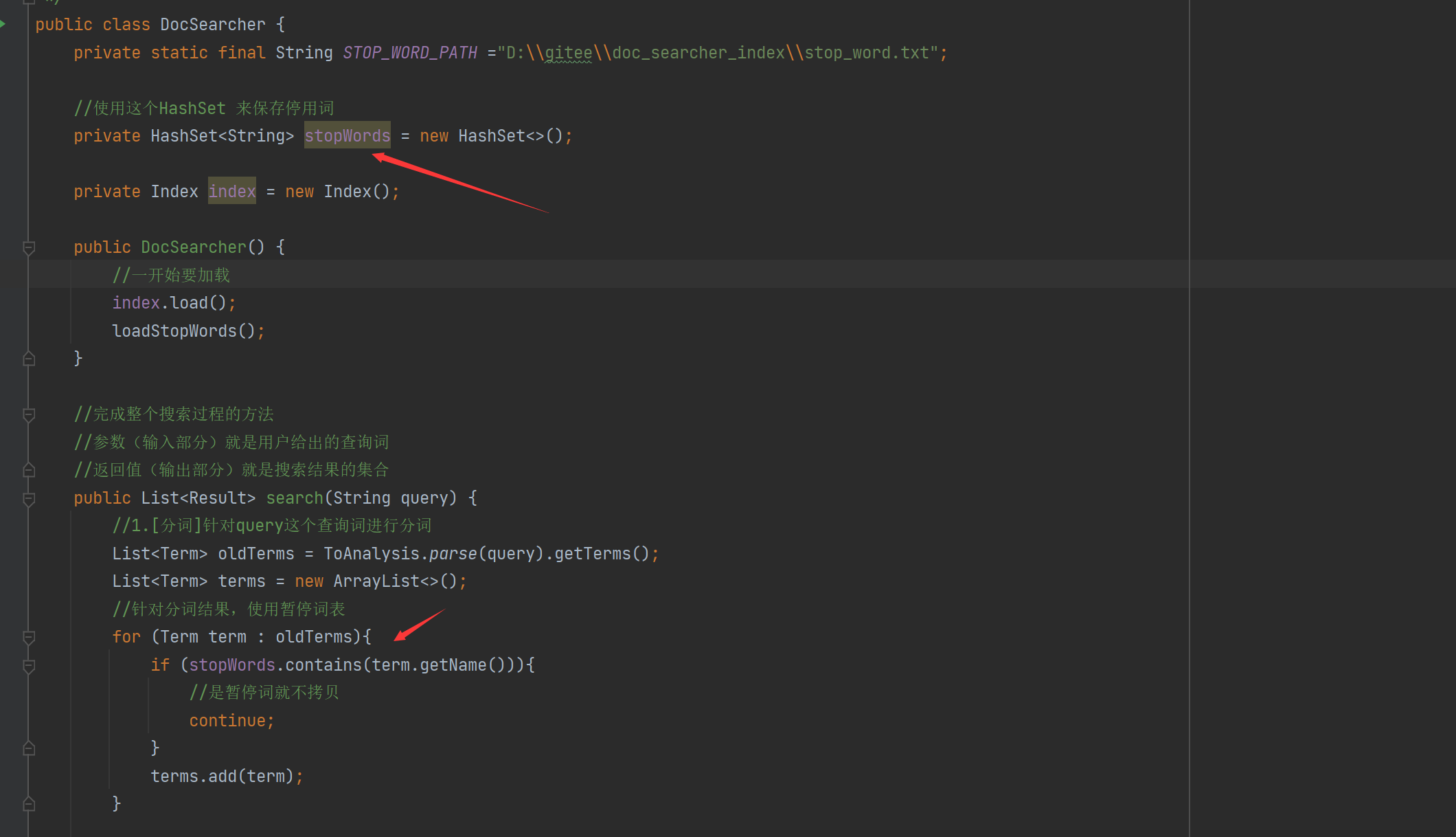
如果暂停词包含就不添加到集合里
7.9 实现Web模块- 处理生成描述的BUG
这里的描述生成是从最开始生成的,并不是按照我们的规则来进行的
像这种我们没有看见他们的描述词但是也出现了,是个什么问题呢?
难道里面也是包含的有吗?所以我们去看看页面:
可以发现这里果然是有的,但是生成的描述是有问题的:我们前面是把一个单词单独找出来:
正文有个词是List 我们不应该把List 和ArrayList的一部分进行匹配,我们可以匹配到独立的单词(a List b)这样是可以的,但是我们还是会存在一些问题,比如出现(a List.),后面出现了个标点符号。这样就会不准确了,
解决这个问题,我们的办法还是正则表达式。
\b:匹配一个单词的边界,包括符号标点
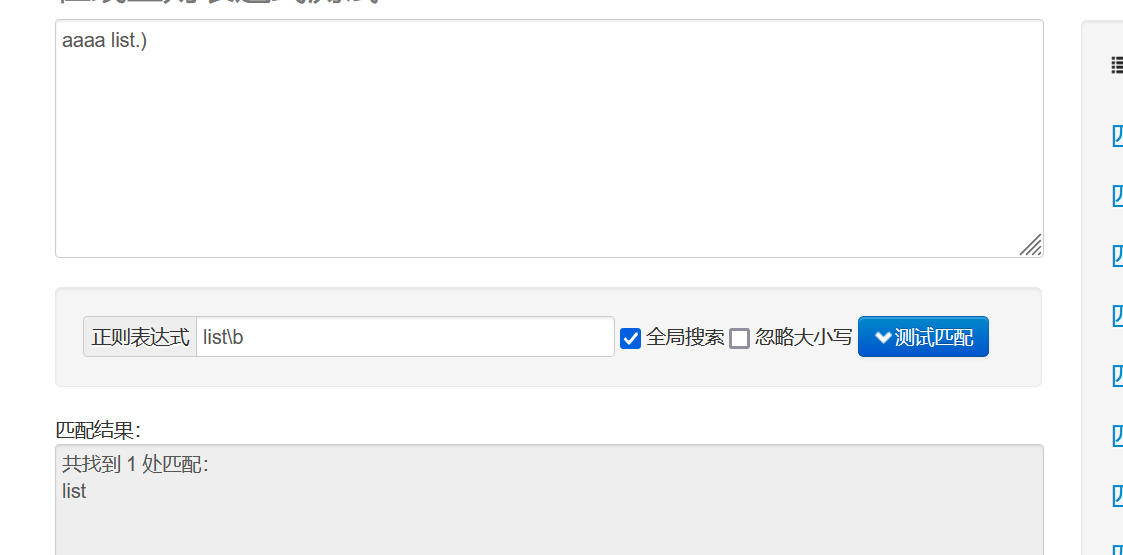
但是我们要怎么实现这个正则呢?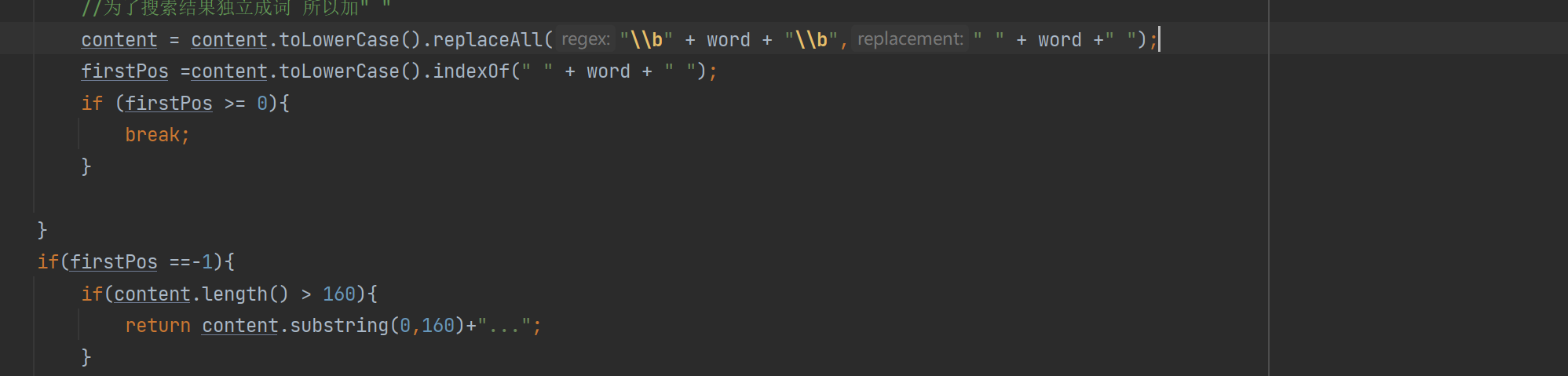
原理就是把带有边界的单词,先转加空格的,然后对空格的单词进行操作。

是不是这里的描述也成功。
7.10 实现Web模块- 加上搜索结果的个数
我们要实现一个类似这样的效果:
我们有2个方法:
我们选择第二种: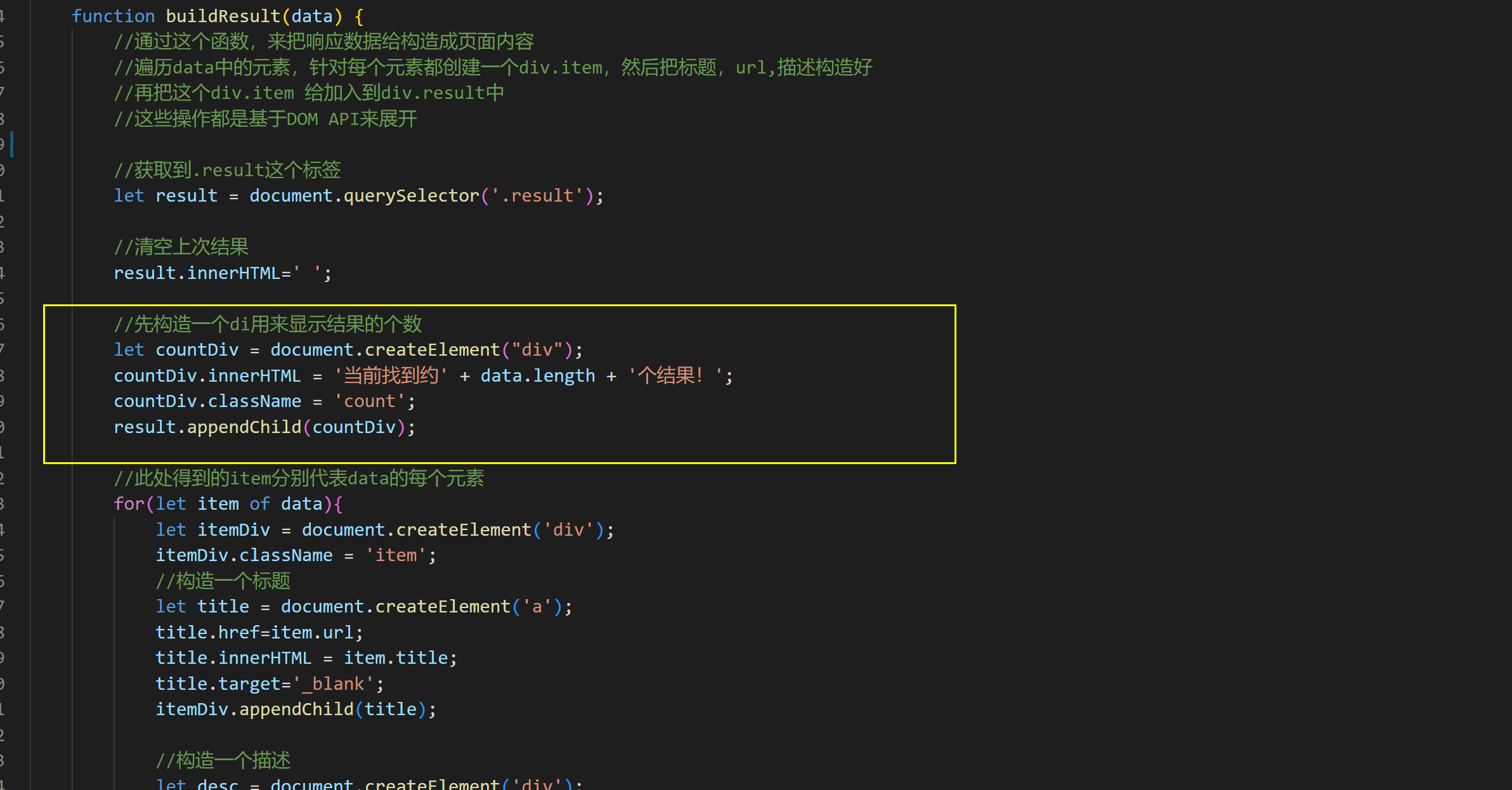
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Java文档搜索</title></head><body> <!-- 1.搜索框 和搜索按钮 --> <!-- 2.显示搜索结果 --> <!-- 通过.container来表示整个页面的元素的容器 --> <div class="container"> <!-- 搜索框加搜索按钮 --> <div class="header"> <input type="text"> <button id="search-btn">搜索</button> </div> <!-- 显示搜索结果 --> <div class="result"> <!-- 包含了很多记录 --> <!-- 通过访问服务器的方式获取搜索结果 --><!-- <div class="item">--><!-- <a href="#">我是标题</a>--><!-- <div class="class">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>--><!-- <div class="url">http://www.baidu.com</div>--><!-- </div>--><!-- <div class="item">--><!-- <a href="#">我是标题</a>--><!-- <div class="class">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>--><!-- <div class="url">http://www.baidu.com</div>--><!-- </div>--><!-- --><!-- <div class="item">--><!-- <a href="#">我是标题</a>--><!-- <div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>--><!-- <div class="url">http://www.baidu.com</div>--><!-- </div>--><!-- <div class="item">--><!-- <a href="#">我是标题</a>--><!-- <div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>--><!-- <div class="url">http://www.baidu.com</div>--><!-- </div>--><!-- <div class="item">--><!-- <a href="#">我是标题</a>--><!-- <div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>--><!-- <div class="url">http://www.baidu.com</div>--><!-- </div>--> </div> </div> <style > /* 这部分代码来写样式 */ /* 先去掉浏览器默认的样式 */ *{ margin: 0; padding: 0; box-sizing: border-box; } /* 给整体的页面指定一个高度(和浏览器窗口一样高) */ html,body{ height: 100%; /* 设置背景图 */ background-image: url(image/bjt.jpg); /* 设置背景图不平铺 */ background-repeat: no-repeat; /* 设置背景图的大小 */ background-size: cover; /* 设置背景图的位置 */ background-position: center center; } /* 针对.container 也设置样式,实现版心效果 */ .container{ width: 1135px; height: 100%; /* 设置水平居中 */ margin: 0 auto; /* 设置背景色,让版心和背景图能够区分开 */ background-color:rgba(255, 255, 255, 0.8); /* 设置圆角矩形 */ border-radius: 10px; /* 设置内边距 避免文章内容紧填边界 */ padding: 15px; /* 超出元素的部分,自动生成一个滚动条 */ overflow: auto; } .header{ width: 100%; height: 50px; display: flex; justify-content: space-between; align-items: center; } .header> input{ height: 30px; width: 1000px; font-size: 22px; line-height: 50px; padding-left: 10px; border-radius: 10px; } .header>button{ height: 30px; width: 100px; background-color: antiquewhite; color: black; border-radius: 10px; } .result .count{ color: darkblue; margin-top: 10px; } .header>button:active{ background: gray; } .item{ width:100%; margin-top: 20px; } .item a{ display: block; height: 40px; font-size: 22px; line-height: 40px; font-weight: 700; color: rgb(42, 107, 205); } .item .desc{ font-size: 18px; } .item .url{ font-size: 18px; color: rgb(0, 130, 0); } .item>.desc>i { color: red; /* 去掉斜体 */ font-style: normal; } </style><script src="http://libs.baidu.com/jquery/2.0.0/jquery.min.js"></script><script> //放置用户自己写的js代码 let button = document.querySelector("#search-btn"); button.onclick =function(){ // 先获取输入框的内容 let input =document.querySelector(".header input"); let query = input.value; //然后构造ajax的请求 $.ajax({ type:"GET", url:"search?query="+query, success:function(data,status){ // success会在请求成功后调用 //data参数就是表示拿到的结果数据 //status参数就表示的HTTP状态码 //根据收到的数据结果,构造出页面内容 //console.log(data); buildResult(data); } }) } function buildResult(data) { //通过这个函数,来把响应数据给构造成页面内容 //遍历data中的元素,针对每个元素都创建一个div.item,然后把标题,url,描述构造好 //再把这个div.item 给加入到div.result中 //这些操作都是基于DOM API来展开 //获取到.result这个标签 let result = document.querySelector('.result'); //清空上次结果 result.innerHTML=' '; //先构造一个di用来显示结果的个数 let countDiv = document.createElement("div"); countDiv.innerHTML = '当前找到约' + data.length + '个结果!'; countDiv.className = 'count'; result.appendChild(countDiv); //此处得到的item分别代表data的每个元素 for(let item of data){ let itemDiv = document.createElement('div'); itemDiv.className = 'item'; //构造一个标题 let title = document.createElement('a'); title.href=item.url; title.innerHTML = item.title; title.target='_blank'; itemDiv.appendChild(title); //构造一个描述 let desc = document.createElement('div'); desc.className='desc'; desc.innerHTML=item.desc; itemDiv.appendChild(desc); //构造一个url let url = document.createElement('div'); url.className = 'url'; url.innerHTML = item.url; itemDiv.appendChild(url); // 把itemDiv加入到result里面 result.appendChild(itemDiv); } }</script></body></html>7.11 实现Web模块- 关于重复文档的问题
Array:1598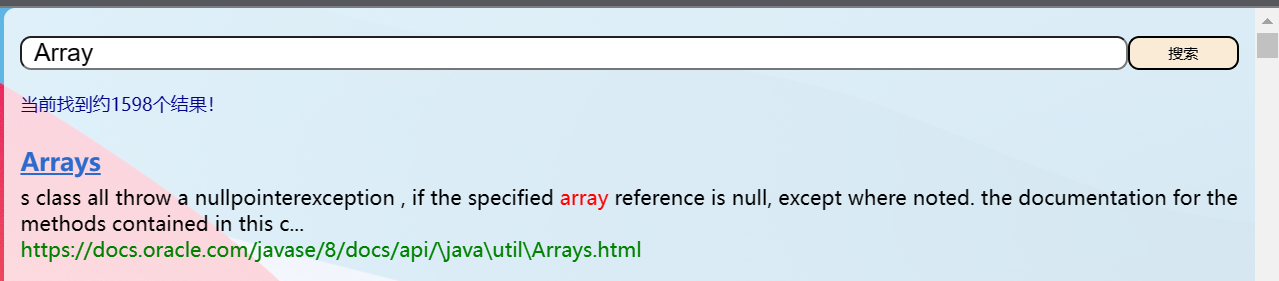
List:1381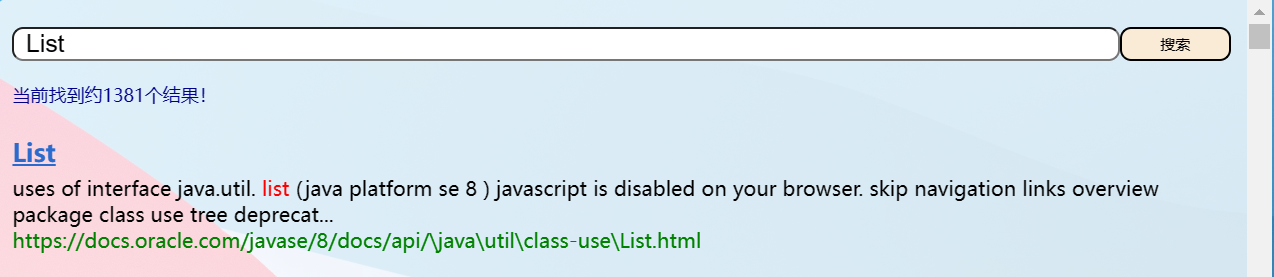
ArrayList:2979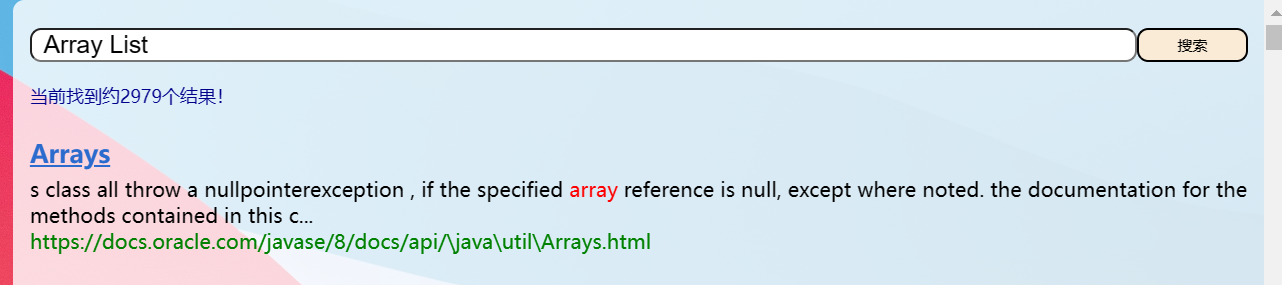
最后发现Array List的数量 就是前面2个结果相加的数量结果,然后还有一个问题出现了重复的文档:
比如这个Collections 就出现了两次
第一次出现位置:
第二次出现的位置:
我们不应该让他们出现两次,而且我们还需要让这个出现两次的权重应该更加靠前
这个是啥问题产生的呢?
我们算权重针对分词结果依次触发
array 触发一组docId
list 触发一组docId
现在Collections这个被array 和 list 都触发了一次
我们解决的办法:
想办法把权重相加 比如第一组权重是10 第二组触发是5,那么就10+5 权重,
要想实现这样的效果,我们需要把触发的结果进行合并。
我们考虑到2组触发结果可能会存在一样的docId,这样合并还是结果数很多,所以我们需要去重,在同时进行权重的合并。
那么怎么样进行去重呢?
去重核心思路:
在我们学过的数据结构有个链表,链表有个经典的问题就是合并两个有序链表。 我们可以按照类似的思路来合并我们两个数组。
合并两个有序链表:两个链表,分别拿两个指针指向各自的头部,然后比较指向的节点,看看谁的值更小,就插入到新的里面。
我们的总体思路就是:
先把分词结果进行一个排序处理(按照docId升序排序)这样就是一个有序的了,然后开始进行合并,合并的时候就可以根据docId值相同的情况,进行相加,插入的同时看看id是不是上次插入的id一样,如果一样就说明重复了,重复了就权重相加。
这里还有一个问题,用户的查询词分词结果不一定就2个部分,可能是多个分词结果,就变成N个数组合并。
7.12 实现Web模块- 多路归并的思路
对于两路数组归并:核心就是对比指向的两个元素大小关系,找到小的插入到结果中
对于多路数组归并:核心就是对比指向多个元素大小关系,找到小的插入到结果中
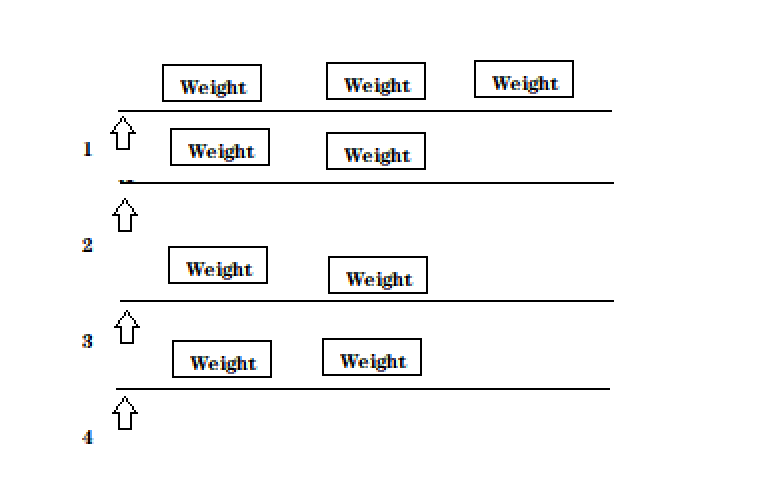
二维数组:
我们需要在上面的图找到谁对应的值最小,把最小的值取出来,插入到结果数组中,同时进行下标++ 。这里找最小的的值,我们采用堆 或者优先队列。
上面的图表示的是每一个docid,和Weight 对象,我们可以把他们当做 第一行下标是1,把1行的每一个Weight当做是列,涉及到行和列,我们就需要考虑到二维数组了。
还是看代码吧
7.13 实现Web模块- 实现多路归并
DocSearcher
package searcher;import org.ansj.domain.Term;import org.ansj.splitWord.analysis.ToAnalysis;import org.omg.CORBA.INTERNAL;import java.io.BufferedReader;import java.io.FileReader;import java.io.IOException;import java.util.*;/** * Created by Lin * Description: * User: Administrator * Date: 2022-12-21 * Time: 13:22 */public class DocSearcher { private static final String STOP_WORD_PATH ="D:\\gitee\\doc_searcher_index\\stop_word.txt"; //使用这个HashSet 来保存停用词 private HashSet<String> stopWords = new HashSet<>(); private Index index = new Index(); public DocSearcher() { //一开始要加载 index.load(); loadStopWords(); } //完成整个搜索过程的方法 //参数(输入部分)就是用户给出的查询词 //返回值(输出部分)就是搜索结果的集合 public List<Result> search(String query) { //1.[分词]针对query这个查询词进行分词 List<Term> oldTerms = ToAnalysis.parse(query).getTerms(); List<Term> terms = new ArrayList<>(); //针对分词结果,使用暂停词表 for (Term term : oldTerms){ if (stopWords.contains(term.getName())){ //是暂停词就不拷贝 continue; } terms.add(term); } //2.[触发]针对分词结果来查倒排 //二维数组 List<List<Weight>> termResult = new ArrayList<>(); for (Term term : terms) { String word = term.getName(); List<Weight> invertedList = index.getInverted(word); if (invertedList == null) { //说明词不存在 continue; } termResult.add(invertedList); } //3.[合并]针对多个分词结果触发出的相同文档进行权重合并 去重 List<Weight> allTermResult = mergeResult(termResult); // 4.[排序]针对触发的结果按照权重降序排序 allTermResult.sort(new Comparator<Weight>() { @Override public int compare(Weight o1, Weight o2) { //降序排序 return o2.getWeight-01.getWeight 升序反之 return o2.getWeight() - o1.getWeight(); } }); //5.[包装结果]针对排序的结果,去查正排,构造出要返回的数据 List<Result> results = new ArrayList<>(); for (Weight weight : allTermResult) { DocInfo docInfo = index.getDocInfo(weight.getDocId()); Result result = new Result(); result.setTitle(docInfo.getTitle()); result.setUrl(docInfo.getUrl()); result.setDesc(GenDesc(docInfo.getContent(),terms)); results.add(result); } return results; } //进行合并的时候把多个行合并成为一行, //合并过程要操作二维数组的每个元素 所以我们把行和列创建好 static class Pos{ public int row; public int col; public Pos(int row, int col) { this.row = row; this.col = col; } } private List<Weight> mergeResult(List<List<Weight>> source) { //1.先针对每一行进行排序(按照id进行升序)不然没办法合并 for(List<Weight> curRow :source){ curRow.sort(new Comparator<Weight>() { @Override public int compare(Weight o1, Weight o2) { return o1.getDocId() - o2.getDocId(); } }); } //2.借助优先队列,针对这些进行合并 // target 表示合并的结果 List<Weight> target = new ArrayList<>(); // 搞一个优先队列 要找到对应的Weight对象位置// 优先队列存在的意义就是:为了能够找出每一行对应的最小的docid对象,把最小的对象插入到target里面,同时把对应的下标给往后移动 PriorityQueue<Pos> queue = new PriorityQueue<>(new Comparator<Pos>() { @Override public int compare(Pos o1, Pos o2) { // 找到Weight对象 然后再根据Weight 的docId来排序// 第一个对象 Weight w1 = source.get(o1.row).get(o1.col); Weight w2 = source.get(o2.row).get(o2.col); return w1.getDocId() - w2.getDocId(); } }); // 初始化队列,把每一行的第一个元素放到队列中 for (int row = 0; row<source.size();row++){ queue.offer(new Pos(row,0)); //把每一行的第一个元素放到队列中 } // 循环取队首元素 (当前若干行最小的元素) while (!queue.isEmpty()){ Pos minPos = queue.poll(); //获取最小weight对象 Weight curWeight = source.get(minPos.row).get(minPos.col); //判断当前取到的对象,是否和前一个插入到target中的结果是相同的 docId // 如果是就合并 if (target.size() >0){ //取出上次插入的元素 Weight lastWeight = target.get(target.size()-1); if (lastWeight.getDocId() == curWeight.getDocId()){ //遇到了相同的文档 lastWeight.setWeight(lastWeight.getWeight()+curWeight.getWeight()); }else{ //如果不相同的话 target.add(curWeight); } }else { // 如果当前是空着的 直接插入即可 target.add(curWeight); } // 把当前的元素处理完了之后,要把对应这个元素的光标往后移动 取下一个元素 Pos newPos = new Pos(minPos.row, minPos.col+1); if (newPos.col >= source.get(newPos.row).size()){ //如果移动光标之后,超过了这一行的列数,就说明到达了末尾 处理完毕 continue; }// 优先队列 自己放到合适的地方 queue.offer(newPos); } return target; } private String GenDesc(String content, List<Term> terms) { //先遍历结果,看看哪个结果是在content中存在 int firstPos = -1; for (Term term : terms) { String word = term.getName(); //因为分词结果是会把正文转成小写,所以我们要把查询词也转成小写 //为了搜索结果独立成词 所以加" " content = content.toLowerCase().replaceAll("\\b" + word + "\\b"," " + word +" "); firstPos =content.toLowerCase().indexOf(" " + word + " "); if (firstPos >= 0){ break; } } if(firstPos ==-1){ if(content.length() > 160){ return content.substring(0,160)+"..."; } //所有的分词结果都不在正文中存在 极端情况 return content; } //从firstPos 作为基准,往前找60个字符,作为描述的起始位置 String desc =""; //如果当前位置少于60个字符开始位置就是第一个 否则开始位置 在查询词前60个 int descBeg = firstPos < 60 ? 0 : firstPos -60; if (descBeg+160 > content.length()){ //判断是否超过正文长度 //从开始位置到最后 desc = content.substring(descBeg); }else { desc =content.substring(descBeg,descBeg + 160)+"..."; } //在此处加上一个替换操作,把描述中的分词结果相同的部分,给加上一层<i>标签,就可以通过replace的方式实现 for (Term term : terms){ String word = term.getName(); //只有是全部是一个查询词 才加上 i 标签 正则规则(?i)大小写全部匹配 desc = desc.replaceAll("(?i)"+word+" ","<i> " + word + " </i>"); } return desc; } public void loadStopWords (){ System.out.println("加载暂停词表"); try(BufferedReader bufferedReader = new BufferedReader(new FileReader(STOP_WORD_PATH))){ while (true){ String line = bufferedReader.readLine(); if (line == null){ //读取文件完毕 break; } stopWords.add(line); } }catch (IOException e){ e.printStackTrace(); } } public static void main(String[] args) { DocSearcher docSearcher = new DocSearcher(); Scanner scanner = new Scanner(System.in); while (true) { System.out.print("->"); String query = scanner.next(); List<Result> results = docSearcher.search(query); for (Result result : results) { System.out.println("======================================"); System.out.println(result); } } }}代码的改动就在search方法 和mergeResult方法
我们就解释一下重要的代码部分吧,
这里是换变了二维数组 因为我们要操作一行的一个Weight对象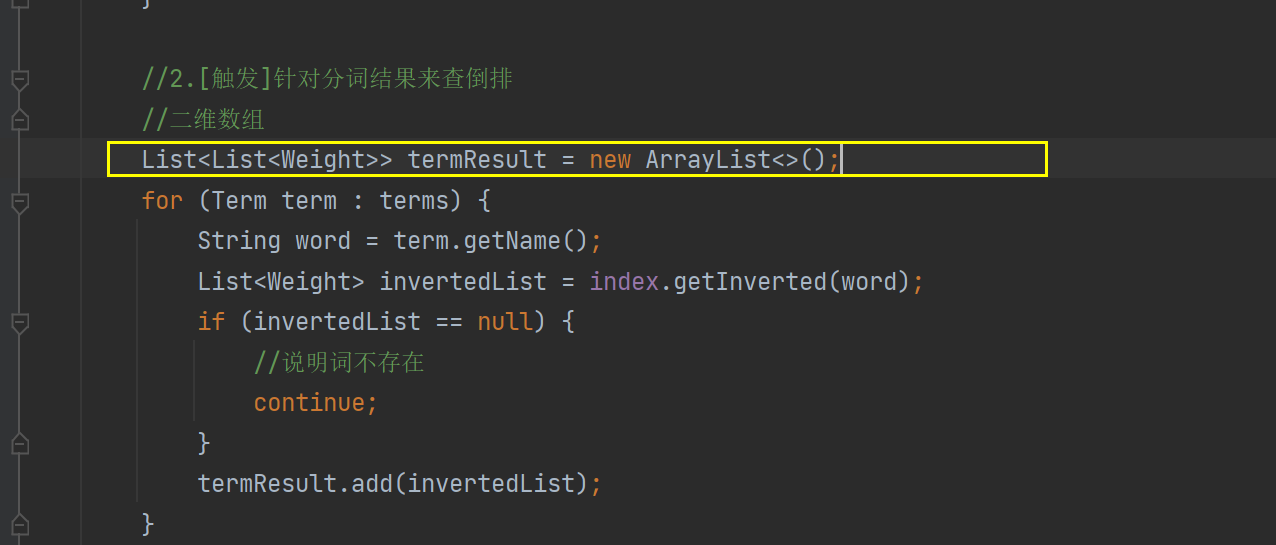
这是已经经过去重排序后的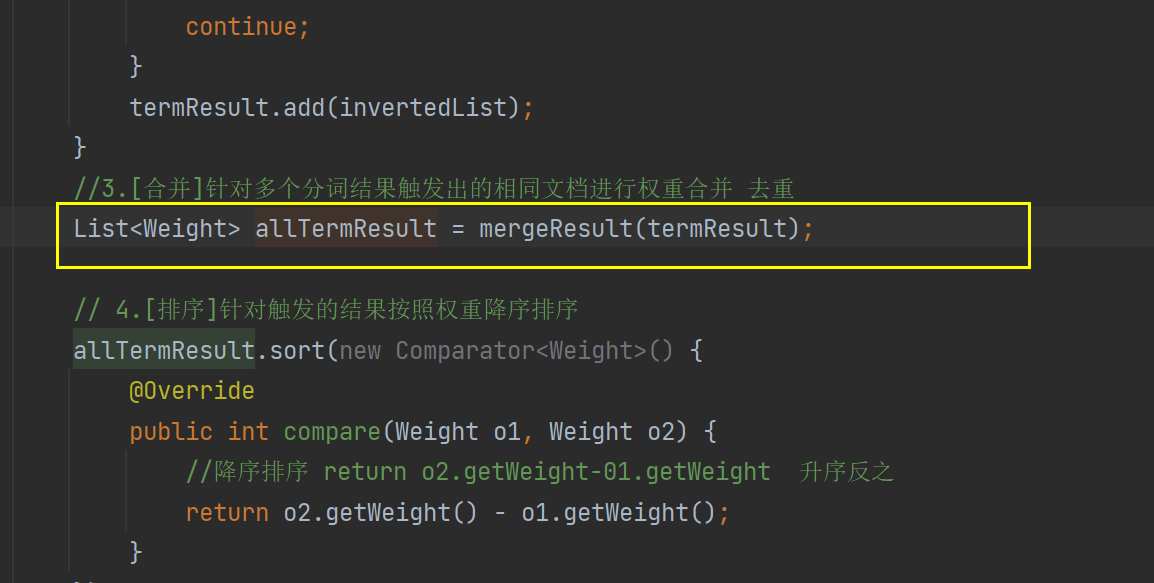
mergeResult讲解:
因为我们使用二维数组肯定操作对象需要行和列的所以这里搞了个内部类Pos:
这里我们采用的是和并两个有序链表的操作,要有序必须先排序,按照docId来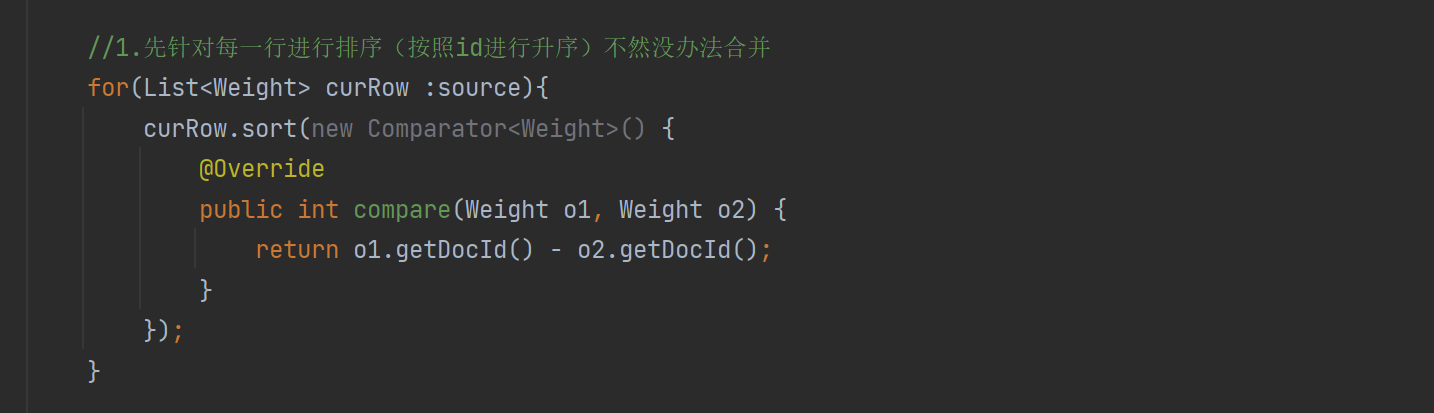
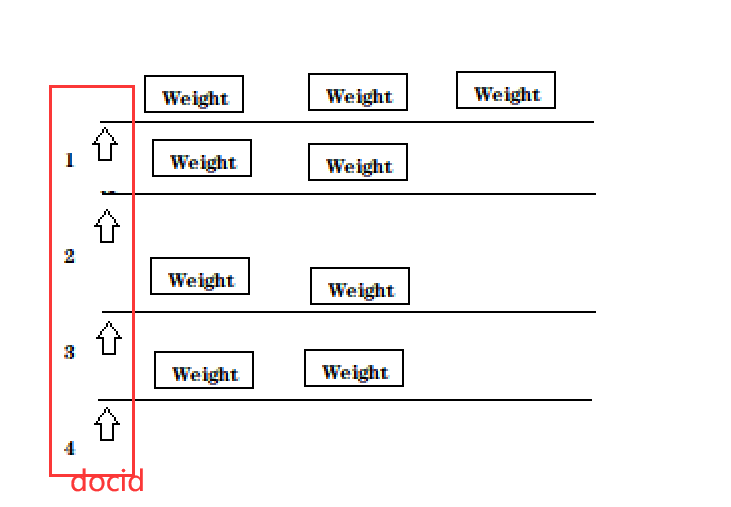
target 就是一个新的集合,我们完成后得返回去,这里我们是优先队列,找到Pos对象的哪一行是最小的,加到我们的结果里面去。优先队列存在的意义就是:为了能够找出每一行对应的最小的docid对象,把最小的对象插入到target里面,同时把对应的下标给往后移动
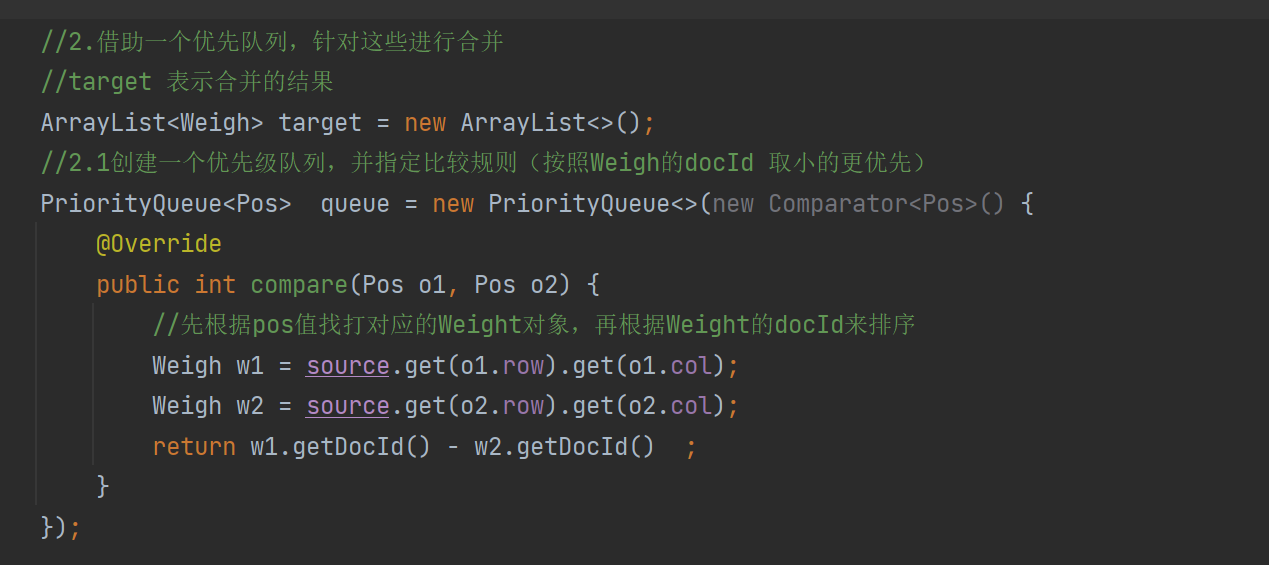
每行第一个:

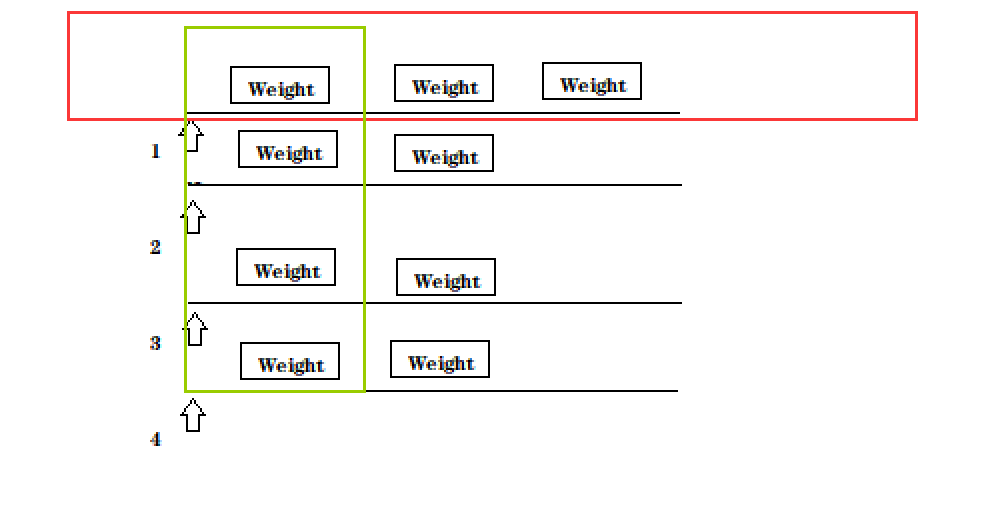
循环取队首元素 (当前若干行最小的元素),poll操作是取出元素,然后获取当地id的Weight对象,如果是空就直接把Weight对象加,加入到数组里,然后找出上次插入的元素 和这次比较,如果id一样就权重相加
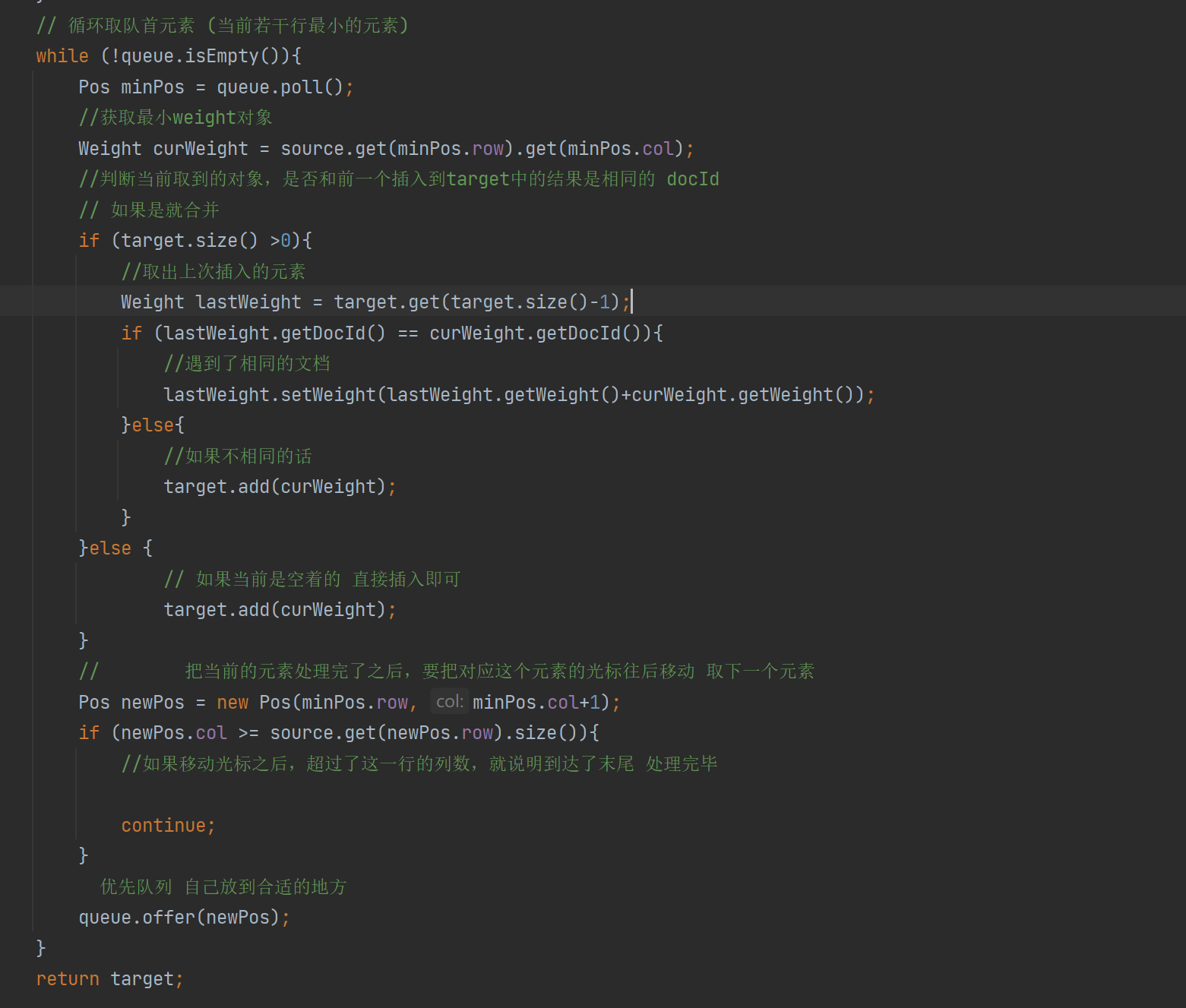
这里光标的移动就是 当前行的,下一列加1就可以了,然后到了最后一列 就跳过,最后return 回去 target。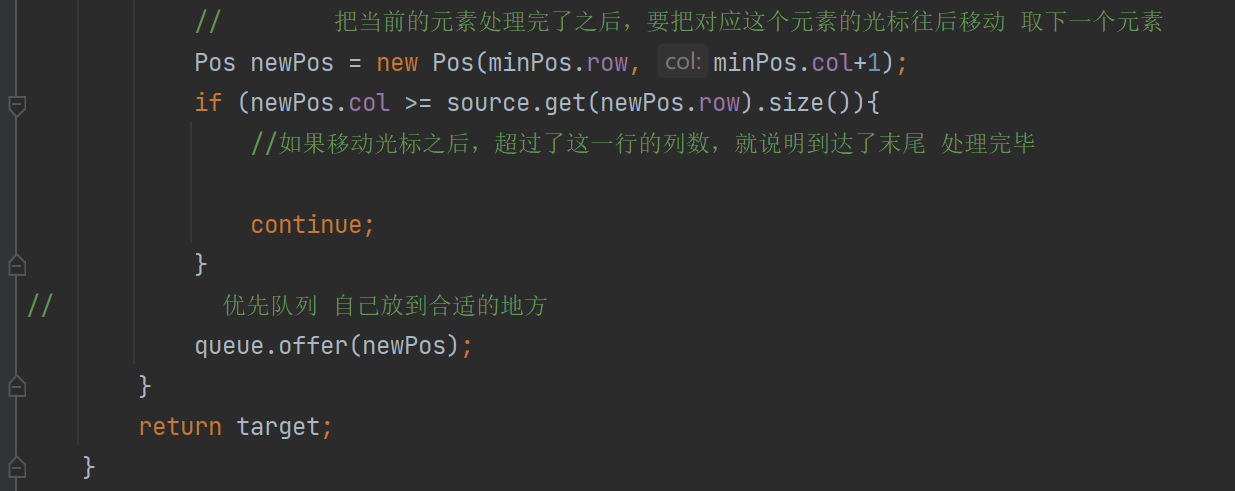
7.14 实现Web模块-验证权重合并
我们第一次搜索结果:既重复,又多余。
我们修改代码后的结果:消除了重复,和多余的结果,权重都变了:是不是发现权重还低了,因为可能其他的文档权重也提高了,所以Collections会降低,不过最终还是没有太大问题的。
八、搜索引擎-改为springboot-创建项目
把当前的Servlet版本变成Spring版本:
使用在线网站创建一个springboot 项目:网站地址
8.1 搜索引擎-改为springboot-拷贝代码到新的项目
拷贝pom.xml文件内容只需要拷贝ansj 和jackson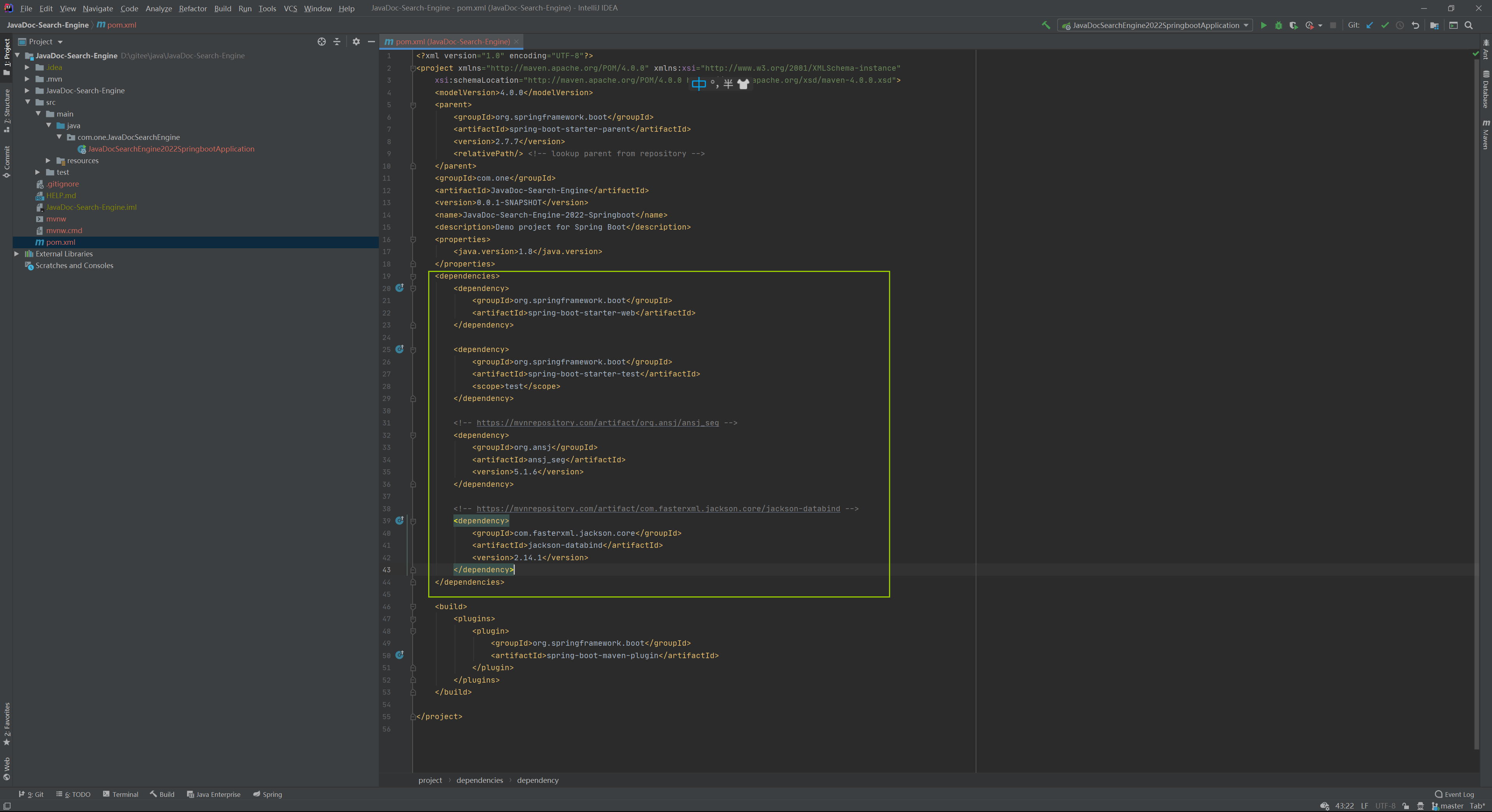
直接拷贝searcher包下的全部代码
 拷贝前端静态资源
拷贝前端静态资源 注意放到resources的static目录下:
8.2 搜索引擎-改为springboot-实现controller层
package com.one.JavaDocSearchEngine.controller;import com.fasterxml.jackson.core.JsonProcessingException;import com.fasterxml.jackson.databind.ObjectMapper;import com.one.JavaDocSearchEngine.searcher.DocSearcher;import com.one.JavaDocSearchEngine.searcher.Result;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;import java.util.List;@RestControllerpublic class DocSearcherController { private static DocSearcher searcher = new DocSearcher(); private ObjectMapper objectMapper = new ObjectMapper(); @RequestMapping(value = "/search",produces = "application/json;charset=utf-8") public String search(@RequestParam("query") String query) throws JsonProcessingException { //参数是查询词,返回是响应内容 //参数的query 来自请求的url,querystring的query的值 List<Result> results = searcher.search(query); return objectMapper.writeValueAsString(results); }}直接运行即可:
8.3 搜索引擎-改为springboot-搞个路径切换开关
我们这个项目是会部署到服务器上面去的,但是我们的索引,暂停词这些东西都是在本地的路径,我们代码的路径也是本地的,但是服务器上面没有这些索引文件,所以我们把文件放到创建好的服务器路径上:
服务器的路径:
我们可以搞一个路径切换的开关 当程序想到哪里跑就打开关闭开关就可以了。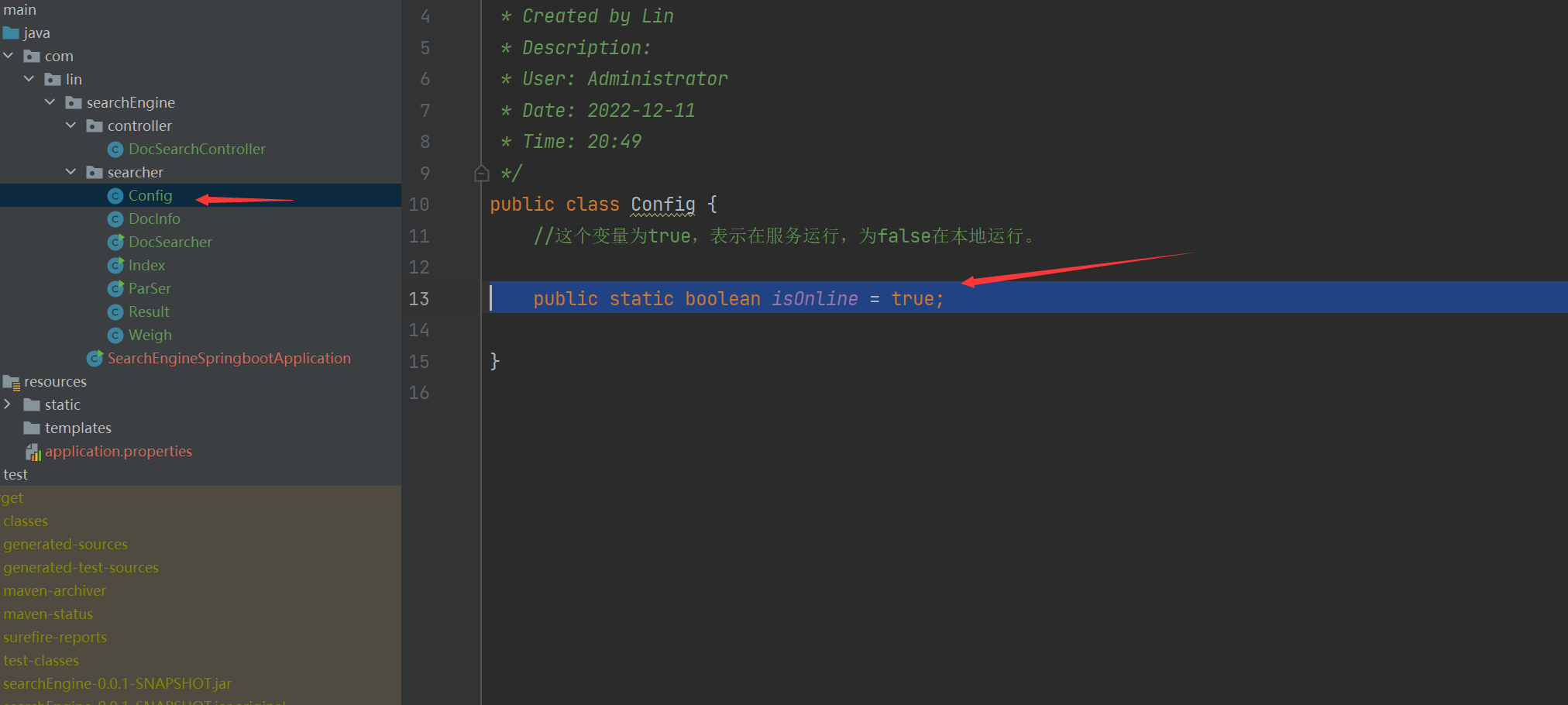
索引的文件路径开关: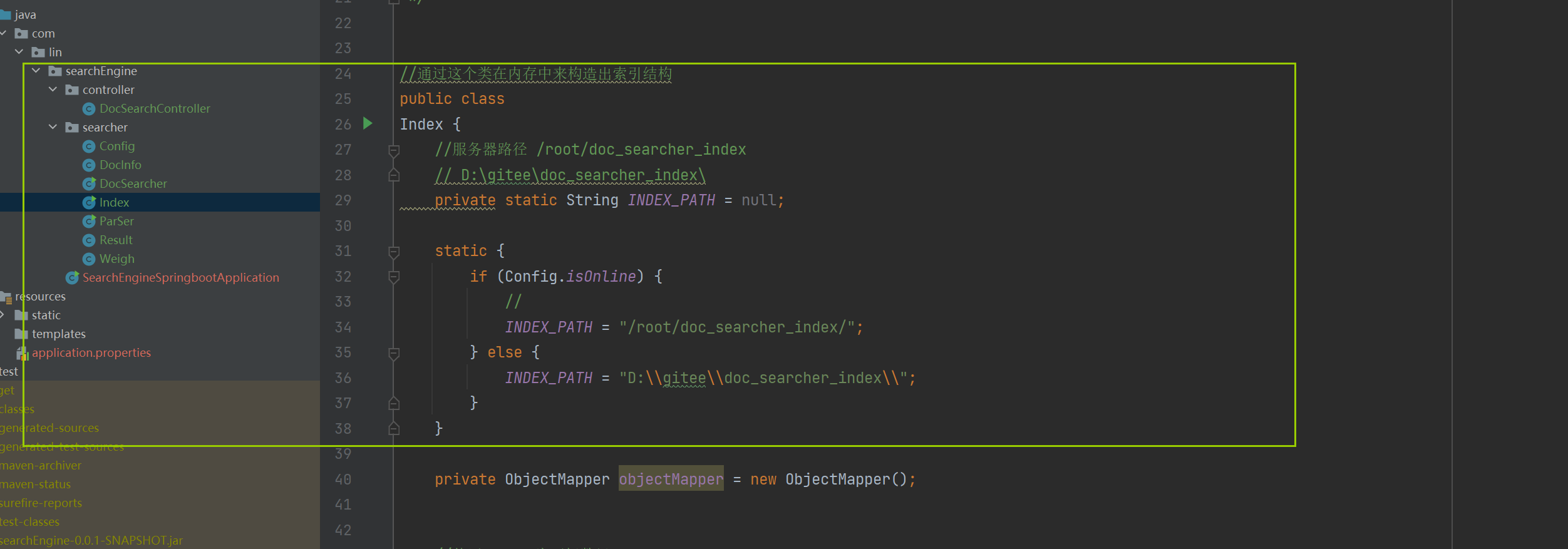
暂停词文件路径开关:
原理也十分简单 就是判断标志位根据标志位来切换。
8.4 搜索引擎-改为springboot-部署到服务器
首先你得有个服务器:华为云,腾讯云都可以。
服务器要注意的点:添加服务器系统防火墙的端口,和服务器的入口规则
如果不熟悉可以安装一个宝塔方便一点:
然后就是:
我的是8084:如果端口有冲突可以改的
然后打包成jar包:
运行:把projectName变成自己的项目名
nohup java -jar projectName.jar &
这个命令是一直保持运行不关闭。
以上你就可以通过你的弹性ip和端口访问你的项目了。