文章目录
前言基于 CLIP Latents 的条件文本图像生成BLIPHugging Face奇点智源中文-CLIP百度昆仑万维之AI绘画
前言
随着人工智能技术的发展与完善,AIGC(AI generated content)在内容的创作上为人们的工作和生活带来前所未有的帮助,具体表现在能够帮助人类提高内容生产的效率,丰富内容生产的多样性、提供更加动态且可交互的内容。在这两年AIGC在AI作画、AI 作曲、AI 作诗等领域持续大放异彩。
2022,是 AI 绘画逐渐走向舞台中央的一年。
文本生成图像(AI 绘画)是根据文本生成图像的的新型生产方式,相比于人类创作者,文本生成图像展现出了创作成本低、速度快且易于批量化生产的优势。
近一年来,该领域迅猛发展,国际科技巨头和初创企业争相涌入,国内也出现了不少文本生成图像的产品。这些产品背后主要使用基于扩散生成算法的 dall-e-2 和 stable diffusion 等模型。
就在几年前,计算机能否从这样的文本描述中生成图像还是一件难以预测的事情。当下 AI 已经开始能够完成一部分创造性的工作,而非只是机械重复的工作。
最近昆仑万维、百度、美图等着力借助AI技术赋能生态业务的公司也纷纷推出了中文版的文本生成图像算法,整体来看该领域还处于迅猛发展阶段。
本文旨在带领读者一览 当前众多出色的文本引导图像生成模型相关发展以及一些目前广受关注的文本图像生成在线API体验:包括 OpenAI、Hugging Face、百度以及致力于AIGC和游戏业务的昆仑万维等有着雄厚 AI 技术投入和生态发展的公司。
基于 CLIP Latents 的条件文本图像生成
Hierarchical Text-Conditional Image Generation with CLIP Latents像CLIP这样的对比模型已经证明可以很好学习到图像 representations,这些 representations 既能捕捉语义又能捕捉风格。作者提出了一个两阶段模型:先验模型在给定文本标题的情况下生成CLIP图像特征,然后把图像特征送给解码器生成得到图像;文章链接如下
https://cdn.openai.com/papers/dall-e-2.pdf

BLIP
论文基础信息如下
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation论文地址:https://arxiv.org/pdf/2201.12086.pdf代码地址:https://github.com/salesforce/BLIP试玩地址:https://huggingface.co/spaces/akhaliq/BLIP视觉语言理解和生成、试玩流程如下
上传心仪图像点击下方的提交按钮等待几秒,右侧即可生成对应的:图像内容描述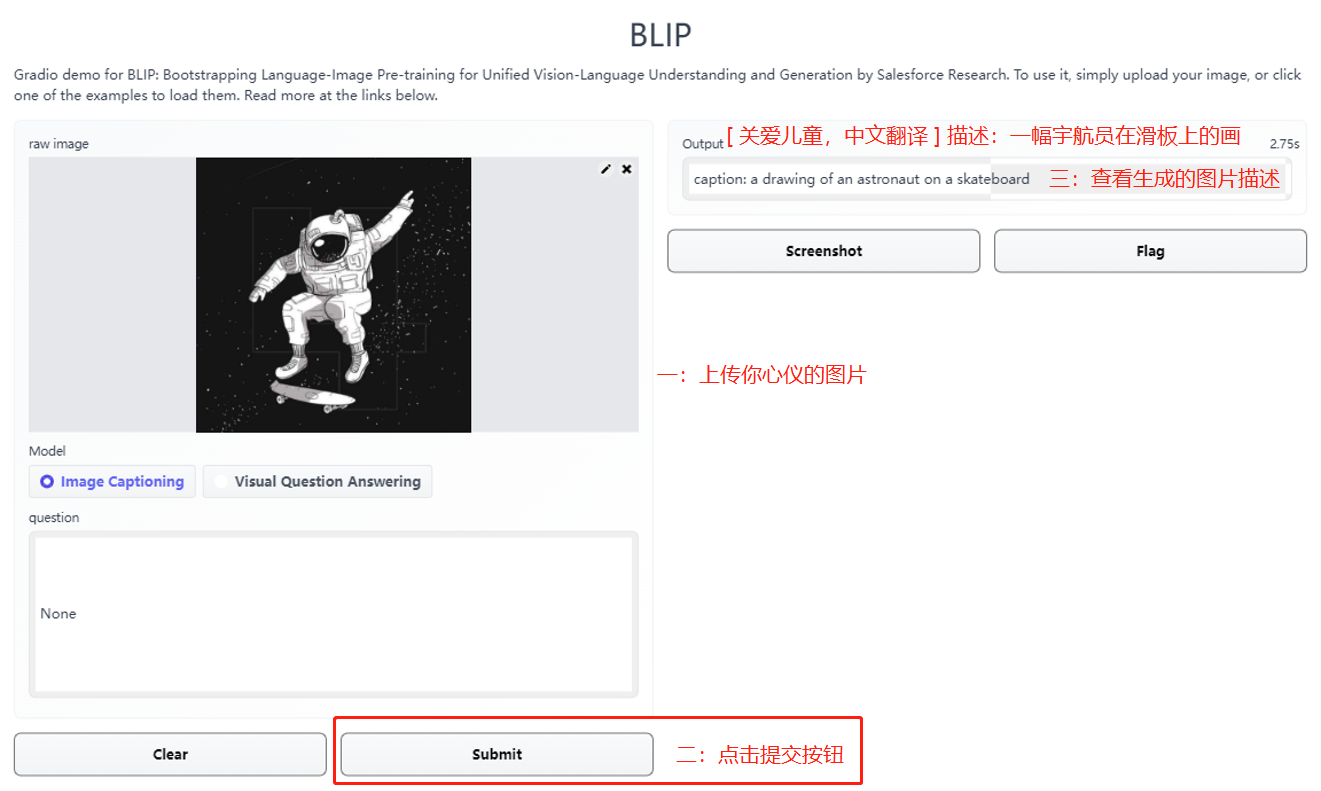
网络结构采用多个编码器-解码器
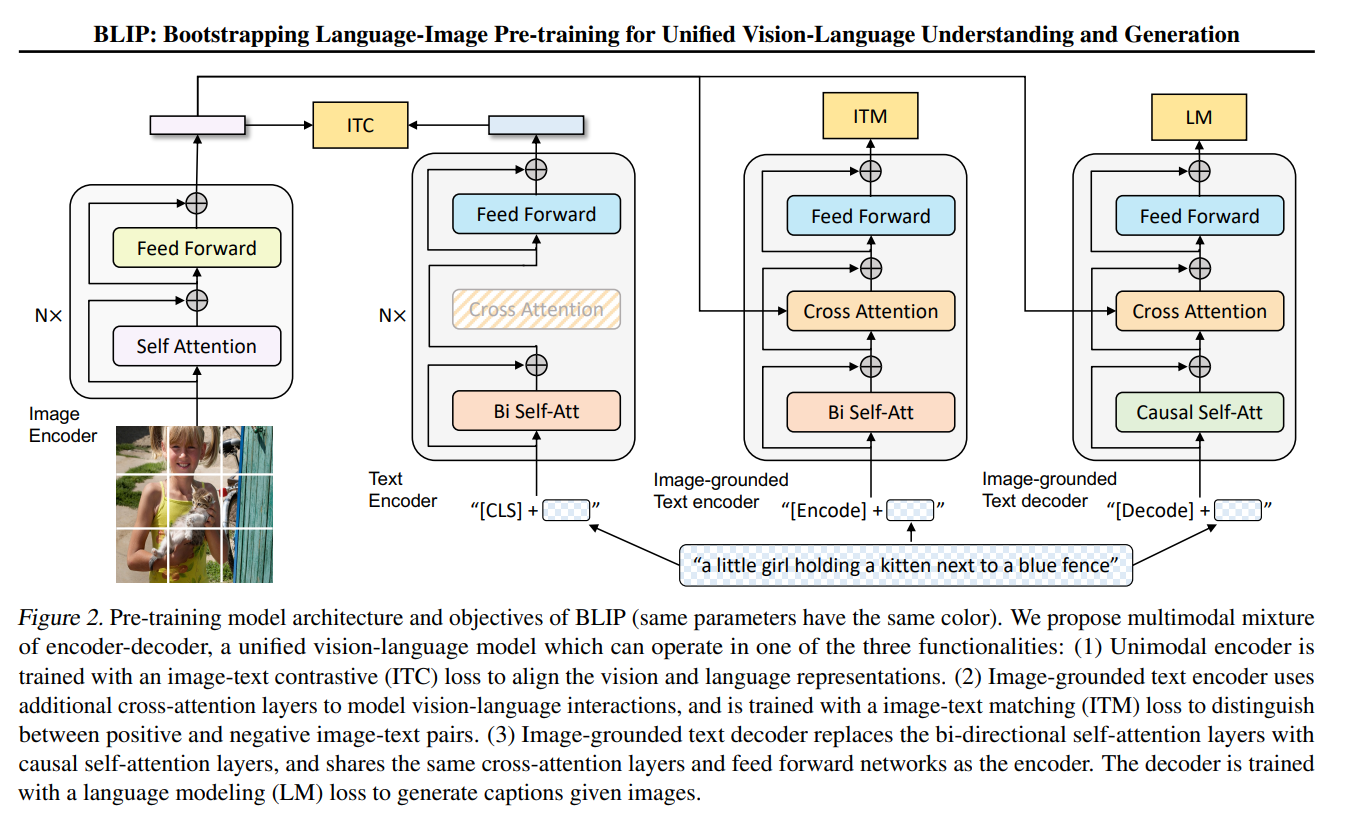
模型架构
研究者将一个视觉 transformer 用作图像编码器,该编码器将输入图像分解为 patch,然后将这些 patch 编码为序列嵌入,并使用一个额外的[CLS] token 表征全局图像特征。相较于将预训练目标检测器用于视觉特征提取的方法,使用 ViT 在计算上更友好,并且已被最近很多方法所采用。
为了预训练一个具备理解和生成能力的统一模型,研究者提出了多任务模型 MED(mixture of encoder-decoder),它可以执行以下三种功能的任意一种:
单峰编码器基于图像的文本编码器基于图像的文本解码器预训练目标
研究者在预训练过程中共同优化了三个目标,分别是两个基于理解的目标和一个基于生成的目标。每个图像文本对只需要一个前向传播通过计算更重(computational-heavier)的视觉 transformer,需要三个前向传播通过文本 transformer,其中激活不同的功能以计算以下 3 个损失,分别是:
图像文本对比损失(image-text contrastive loss, ITC),激活单峰编码器,旨在通过鼓励正图像文本对(而非负对)具有相似的表征来对齐视觉与文本 transformer 的特征空间;
图像文本匹配损失(image-text matching loss, ITM),激活基于图像的文本编码器,旨在学习捕获视觉与语言之间细粒度对齐的图像文本多模态表征;
语言建模损失(language modeling loss, LM),激活基于图像的文本解码器,旨在给定一张图像时生成文本描述。
为了在利用多任务学习的同时实现高效的预训练,文本编码器和解码器必须共享除自注意力(self-attention, SA)层之外的所有参数。具体地,编码器使用双向自注意力为当前输入 token 构建表征,同时解码器使用因果自注意力预测接下来的 token。
另外,嵌入层、交叉注意力(cross attention, CA)层和 FFN 在编码和解码任务之间功能类似,因此共享这些层可以提升训练效率并能从多任务学习中获益。
实验结果
研究者在 PyTorch 中实现模型,并在两个 16-GPU 节点上预训练模型。其中,图像 transformer 源于在 ImageNet 上预训练的 ViT,文本 transformer 源于 BERT_base。
主流数据集:COCO 、 Flickr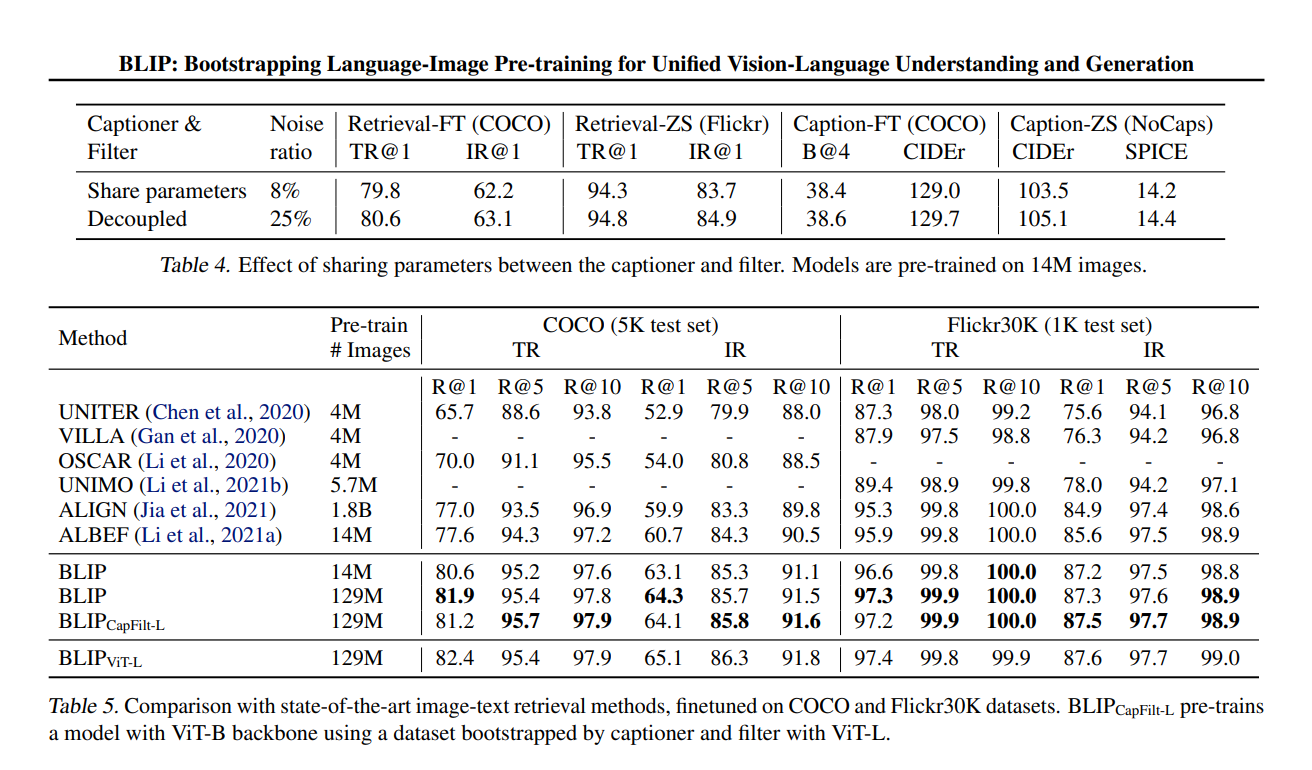
Hugging Face
Hugging 官方提供了很多有趣的基于 自然语言处理和计算机视觉的AI应用在线体验API,还有非常多高star的开源项目收到很多开发者的持续关注
奇点智源
奇点智源 开放了 非常多有趣的 AI 应用 API 接口,大家有兴趣可以去体验试用

中文-CLIP
该项目为CLIP模型的中文版本,使用大规模中文数据进行训练(~2亿图文对),旨在帮助用户快速实现中文领域的图文特征&相似度计算、跨模态检索、零样本图片分类等任务。该项目代码基于open_clip project建设,并针对中文领域数据以及在中文数据上实现更好的效果做了优化。
https://github.com/OFA-Sys/Chinese-CLIP国内也有很多科技公司开放了 AIGC(AI generated content)众多体验或者支持商用的 API 试用接口,接下来主要以全面展现强大AI能力的百度 、 游戏和AIGC业务蓬勃发展的昆仑万维 两家行业内 AI 技术积累深厚的公司 AI 绘画展开介绍和试用体验
百度
前不久百度也上线了 基于文本的风格图像生成技术的文心作画体验链接:
基于文本的图像生成技术体验链接:https://wenxin.baidu.com/ernie-vilg打开链接之后,简单输入目标词汇、选择想要的风格,即可完成别具一格的画作,并且可以看到百度官方提供的在线API体验目前已经支持十多种风格的文本到图像的生成。
示例图像如下,的确强大哇
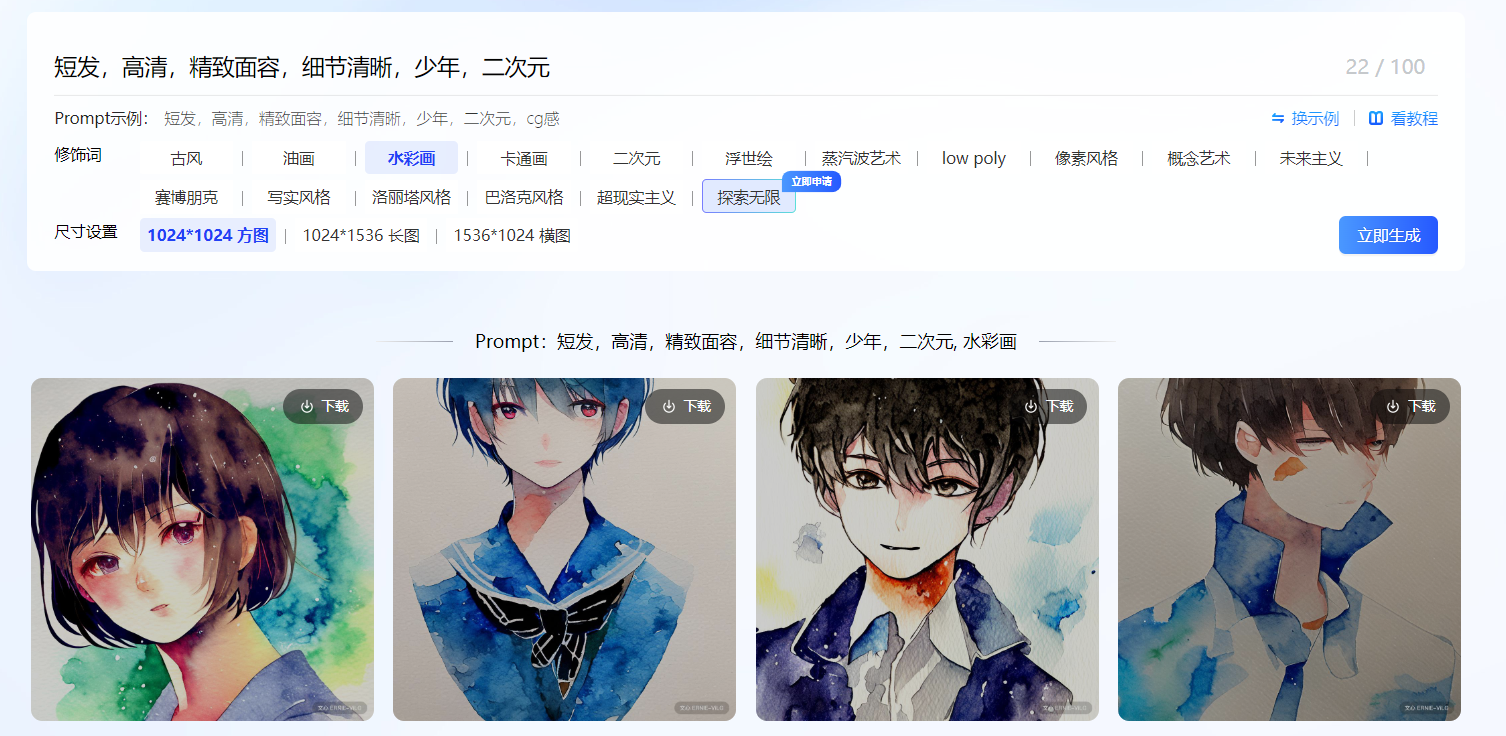
可以看到,百度的API体验生成效果也还是不错的,百度的文本提供是多个关键词的形式,不知道当前提供的模型对长文本语义的理解是否也能很好,小伙伴有兴趣可去体验,另外一个明显的感觉就是目前的算法模型生成耗时还是比较久的;
昆仑万维之AI绘画
随着人工智能技术的发展与完善,AIGC在内容的创作上为人类带来前所未有的帮助,具体表现在能够帮助人类提高内容生产的效率,丰富内容生产的多样性、提供更加动态且可交互的内容。
昆仑万维 AI绘画 继 StarX系列产产品 AI 作曲后 又一次 AIGC 的绘画实践, 标志着昆仑万维在 AI 绘画领域构建方面实现质的突破。
作为一个庞大的概念,虚拟技术横跨AI、游戏、社交等多领域的庞大产业链条。中长期来看,有望带来虚拟世界的创新,推动产业链上的各环节共荣,进而带来新增量。
该技术发展不仅需要技术的推动,更需要内容端的支持。昆仑万维在2021年完成布局及AI技术在社交娱乐、信息分发等领域的应用。随着AIGC的逐步成熟和推进,该技术也将成为昆仑万维取得“幂次增长”的突破口之一。
昆仑万维的AI作画模型研发人员针对中文领域构建了千亿级别的高质量数据集,通过高性能 a100-gpu集群,训练(200张显卡,训练了4周,后续优化合计2周)得到百亿参数量的大生成模型;
昆仑万维AI绘画模型在模型训练过程中主要采取了如下策略
体验昆仑万维之AI绘画小程序,惊艳到我

昆仑万维官网链接如下,感兴趣的小伙伴,去下载他家产品进行体验AIGC强大生产力吧