
文章目录
每篇前言一、透视表基础参数说明+实战案例0. 导入Excel数据1. data2. index3. values4. columns5. aggfunc6. fill_value7. dropna8. margins9. margins_name10. observed11. sort 二、书籍推荐1三、书籍推荐2三、书籍推荐3
每篇前言
??作者介绍:Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6 |
一、透视表基础参数说明+实战案例
数据透视表(Pivot Table)是一种交互式的表,可以进行某些计算,如求和与计数等。所进行的计算与数据跟数据透视表中的排列有关。之所以称为数据透视表,是因为可以动态地改变它们的版面布置,以便按照不同方式分析数据,也可以重新安排行号、列标和页字段。每一次改变版面布置时,数据透视表会立即按照新的布置重新计算数据。另外,如果原始数据发生更改,则可以更新数据透视表。语法格式:
pandas.pivot_table( data: DataFrame, # 制作透视表的数据 values=None, # 值 index=None, # 行索引 columns=None, # 列属性 aggfunc: AggFuncType = "mean", # 使用的函数,默认是均值 fill_value=None, # 缺失值填充 margins=False, # 是否显示总计 dropna=True, # 缺失值处理 margins_name="All", # 总计显示为All observed=False, # 显示类别分组的观察值 sort=True, # 排序功能) -> DataFrame参数说明:
0. 导入Excel数据
CSDN下载链接(设置0积分但是好像还是要会员):透视表-篮球赛数据.xlsx
阿里网盘链接:https://www.aliyundrive.com/s/bsqugWGJLVz
import pandas as pdimport numpy as npdf = pd.read_excel(r'E:\Python学习\透视表——篮球赛数据.xlsx')print(df)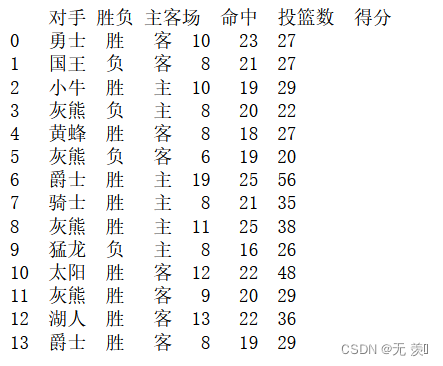
1. data
要创建透视表的DataFrame对象
2. index
接收字符串,列表、分组器、数组或上一个的列表。如果传递了数组,它的长度必须与数据的长度相同。列表可以包含任何其他类型(列表除外)。要根据透视表索引分组的键。如果传递了一个数组,则它的使用方式与列值相同。
(1)接收字符串:
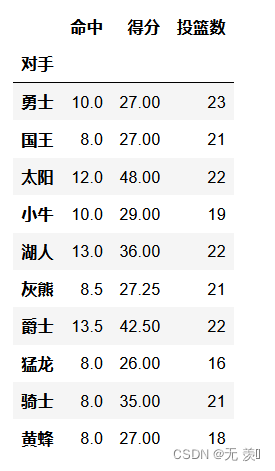
df.pivot_table(index='对手')运行结果:
(2)接收列表:
# 在不同主客场下对阵同一对手的数据,分类条件为对手和主客场df.pivot_table(index=['对手','主客场'])运行结果: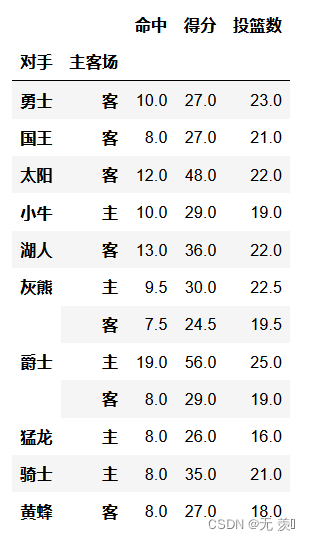
3. values
要聚合的列/筛选需要显示的列,可选。如果不写values显示全部数据,写了只会显示我们指定的数据
在主客场和不同胜负情况下的得分和投篮数:
df.pivot_table(index=['主客场','胜负'],values=['投篮数','得分'])运行结果: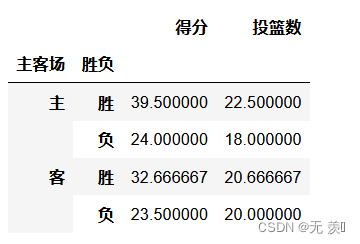
4. columns
列、分组器、数组或上一个的列表。如果传递了数组,它的长度必须与数据的长度相同。列表可以包含任何其他类型(列表除外)。要在透视表列上分组的键。如果传递了一个数组,则它的使用方式与列值相同。
横向显示每队主客场的得数:
df.pivot_table(index=['主客场'],values='得分',columns='对手')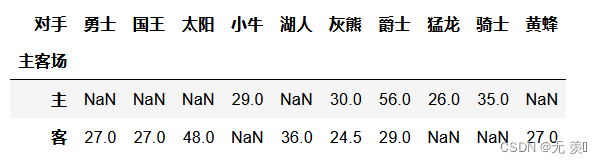
5. aggfunc
函数,函数列表,dict,默认numpy.mean。如果传递了函数列表,则生成的透视表将具有分层列,其顶层是函数名称(从函数对象本身推断)。如果传递了dict,则键是要聚合的列,值是函数或函数列表。
(1)单个函数应用:
# 计算在主客场和不同胜负情况下的总得分、总投篮数df.pivot_table(index=['主客场','胜负'],values=['得分','投篮数'],aggfunc='sum')可以看出投篮数和得数成正比关系: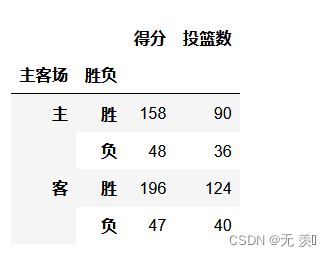
(2)多个函数应用:我们可以在aggfunc函数中指定多个函数,将这些函数放在同一个列表中:
求和:sum
求均值:mean
求个数:size
df.pivot_table(index=['主客场','胜负'],values=['得分','投篮数'],aggfunc=['sum','mean','size'])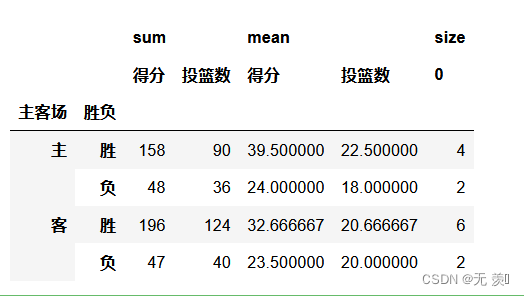
6. fill_value
标量,默认无。值替换缺少的值(在聚合后的结果透视表中)。
横向显示每队主客场的得数,用fill_value=0填充空值:
df.pivot_table(index=['主客场'],values='得分',columns='对手',fill_value=0)运行结果: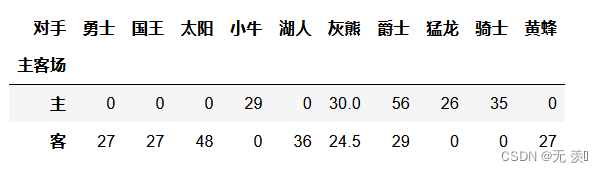
7. dropna
bool,默认为True。不要包含条目均为NaN的列。如果为True,则在计算边距之前,将忽略任何列中具有NaN值的行。简单来说就是数据中有空值的列不会参与计算
8. margins
bool,默认为False。添加所有行/列(例如小计/总计)。作用是对透视表中的分组数据进行汇总显示。
计算在主客场和不同胜负情况下的总得分、总投篮数,并对结果进行汇总:
df.pivot_table(index=['主客场','胜负'],values=['得分','投篮数'],aggfunc='sum',margins=True)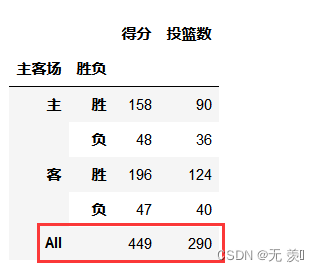
9. margins_name
作用修改margins汇总的行名,接收str,默认为“All”。只有margins=True,参数margins_name的设置才会生效。
计算在主客场和不同胜负情况下的总得分、总投篮数,并对结果进行汇总:
df.pivot_table(index=['主客场','胜负'],values=['得分','投篮数'],aggfunc='sum',margins=True,margins_name='汇总')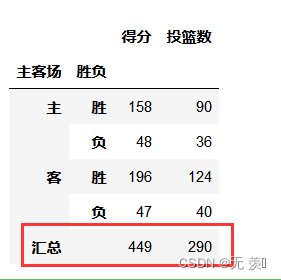
10. observed
bool,默认为False。这只适用于任何一个石斑鱼属于分类的情况。如果为True:仅显示类别分组的观察值。如果为False:显示类别分组的所有值。
11. sort
bool,默认为True。指定是否应对结果进行排序。1.3.0版中的新功能。
计算对手的总得分,并对结果进行排序
(1)排序前:
df.pivot_table(index='对手',values='得分',aggfunc='sum')
(2)排序后:这里由于自带的sort参数没有效果于是用的sort_values函数
df.pivot_table(index='对手',values='得分',aggfunc='sum').sort_values(by=['得分'],ascending=False)
二、书籍推荐1
书籍展示:《人工智能数学基础》
【书籍内容简介】
没有有基础科学的强力支持,应用科学是不可能做出顶尖成绩的。例如,人工智能的深度学习目前存在许多不足,例如大样本依赖,可解释性差,易受欺骗等,但当前没有更好的算法来替代。要解决这些问题,需要对相关数学理论进行深入的研究,了解大数据内在的数学结构和原理。《人工智能数学基础》这本书以零基础讲解为宗旨,面向学习数据科学与人工智能的读者,通俗地讲解每一个知识点,帮助读者快速打下数学基础,适合准备从事数据科学与人工智能相关行业的读者。京东自营:https://item.jd.com/13009168.html当当:http://product.dangdang.com/29145839.html
三、书籍推荐2
书籍展示:《贝叶斯算法与机器学习》
【书籍内容简介】
涵盖了贝叶斯概率、概率估计、贝叶斯分类、随机场、参数估计、机器学习、深度学习、贝叶斯网络、动态贝叶斯网络、贝叶斯深度学习等。本书涉及的应用领域包含机器学习、图像处理、语音识别、语义分析等。本书整体由易到难,逐步深入,内容以算法原理讲解和应用解析为主,每节内容辅以案例进行综合讲解。当当自营:http://product.dangdang.com/29478966.html
三、书籍推荐3
书籍展示:《Excel数据透视表应用大全》
【书籍内容简介】
分别介绍创建数据透视表,整理好 Excel 数据源,改变数据透视表的布局,刷新数据透视表,数据透视表的格式设置,在数据透视表中排序和筛选,数据透视表的切片器,利用 Power Map 创建 3D 地图可视化数据,Power BI Desktop 入门,数 据透视表与 VBA,智能数据分析可视化看板,数据透视表常见问题答疑解惑,数据透视表打印技术,Excel 常用 SQL语句解释等内容当担自营:http://product.dangdang.com/29454856.html