1. ExDark
第一个 公开 特定的提供 natural low-light images for object的数据集
7363张 low-light images,
12 classes
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VK2Wz60U-1670641306011)(:/bbcf37f6b5974f919c036fd4eee77238)]](http://zhangshiyu.com/zb_users/upload/2022/12/20221215100910167107015087423.png)
Low-light image enhancement:
IVC database. general image enhancement而非特指low-light. 黑夜是人工合成的,可以找到原图像See-in-the-Dark dataset (SID): 5094个短曝光(low-light)图像对应到424张长曝光图像(bright)LOw light paired dataset (LOL): 500对图像都含有一对图!!!
但是 SID和LOL都不能展示真实的夜晚灯光环境.
为了保证图像能对应上,使用特定相机并且不含有动态目标(例如cars,people等).
Low-light denoising
是low-light enhancement的一个子集, 但是这些图都是人工合成的,加入Poisson或者Gaussian噪声到合成的黑夜图像中.
Low-light surveillance
热相机和红外相机一般在夜晚监控中使用. 主要集中在人脸识别、行人检测。
数据集有OTCVBS,LSI和LDHF.
ExDark数据集
对low-light condition进行细划分, 例如一天中的黄昏(twilight)还是夜晚(nighttime),位置(indoor,outdoor)、光源可见度、光源类型(太阳、人造光).
12类别: Bicycle, Boat, Bottle, Bus, Car, Cat, Chair, Cup, Dog, Motorbike, People, and Table.
数据收集:网上下载,关键词(dark, low-light,nighttime); 公开数据集(PADCAL VOC, ImageNet和COCO);电影中提取;手动拍摄
标注: 手动标注![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H5f7eTZ3-1670641306012)(:/313977abd4c0435f9edab51919a1b6ee)]](http://zhangshiyu.com/zb_users/upload/2022/12/20221215100910167107015045314.png)
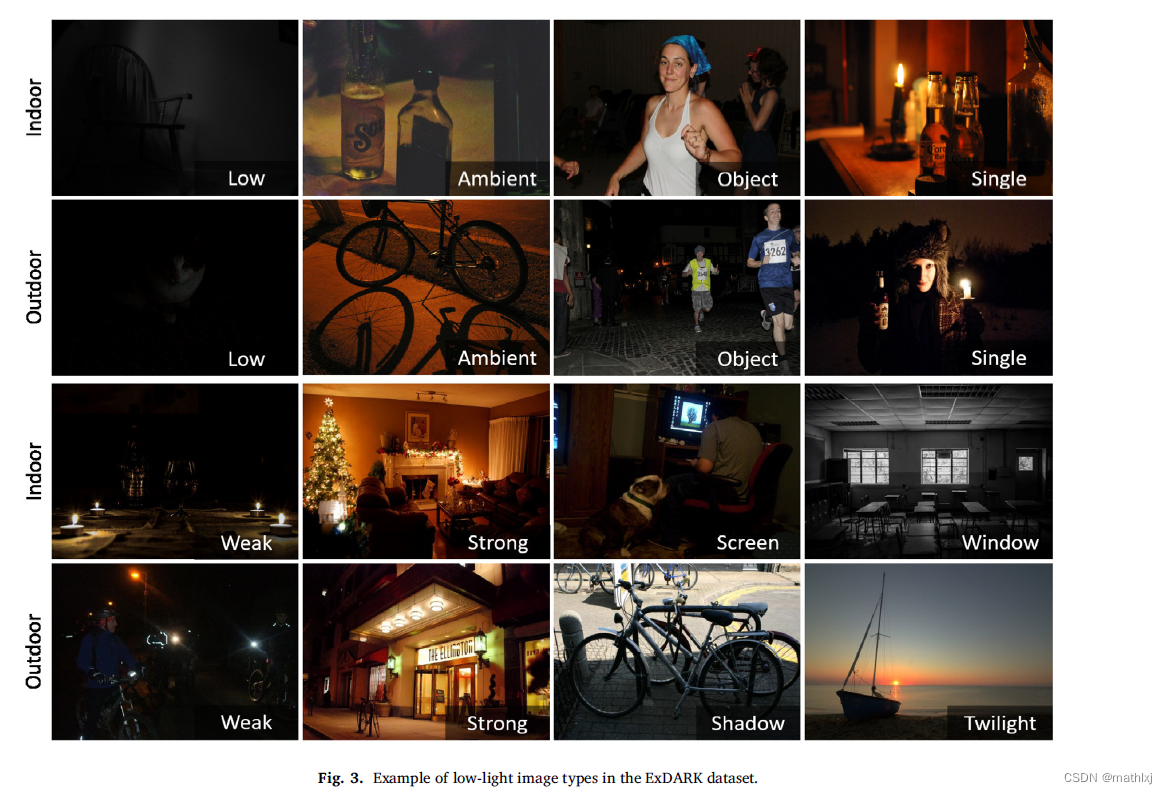
十种灯光类型:
Low: 光线最暗,几乎看不清细节Ambient: 灯光weak, 光源没有捕捉进来Object: 目标较亮但是周围环境很暗,光源没有捕捉进来Single: 只能看到一个光源Weak: multiple visible但是weak光源Strong:multiple visible但是相对亮的光源Screen: 户内图像,可见亮的屏幕Window: 户内图像,以窗户为亮光源.Shadow:户外图像,户外光源,目标在阴影处Twilight:户外,黄昏. 黎明到太阳升起; 微暗到太阳落下.
2. 增强 Survey
传统方法:
Histogram Equalization-based methodsRetinex model-based methods: 例如将一张图解耦为一个reflection部分和一个illumination部分, reflection部分即为增强的结果.缺点: 多光源时会丢失细节和颜色;噪声被忽略了;找到这样一个prior或regularization比较困难;运行时间长.
DL方法:更高精度、更加鲁棒、速度更好
方法包括:监督学习、强化学习、无监督学习、Zero-shot learning和半监督学习.
学习策略
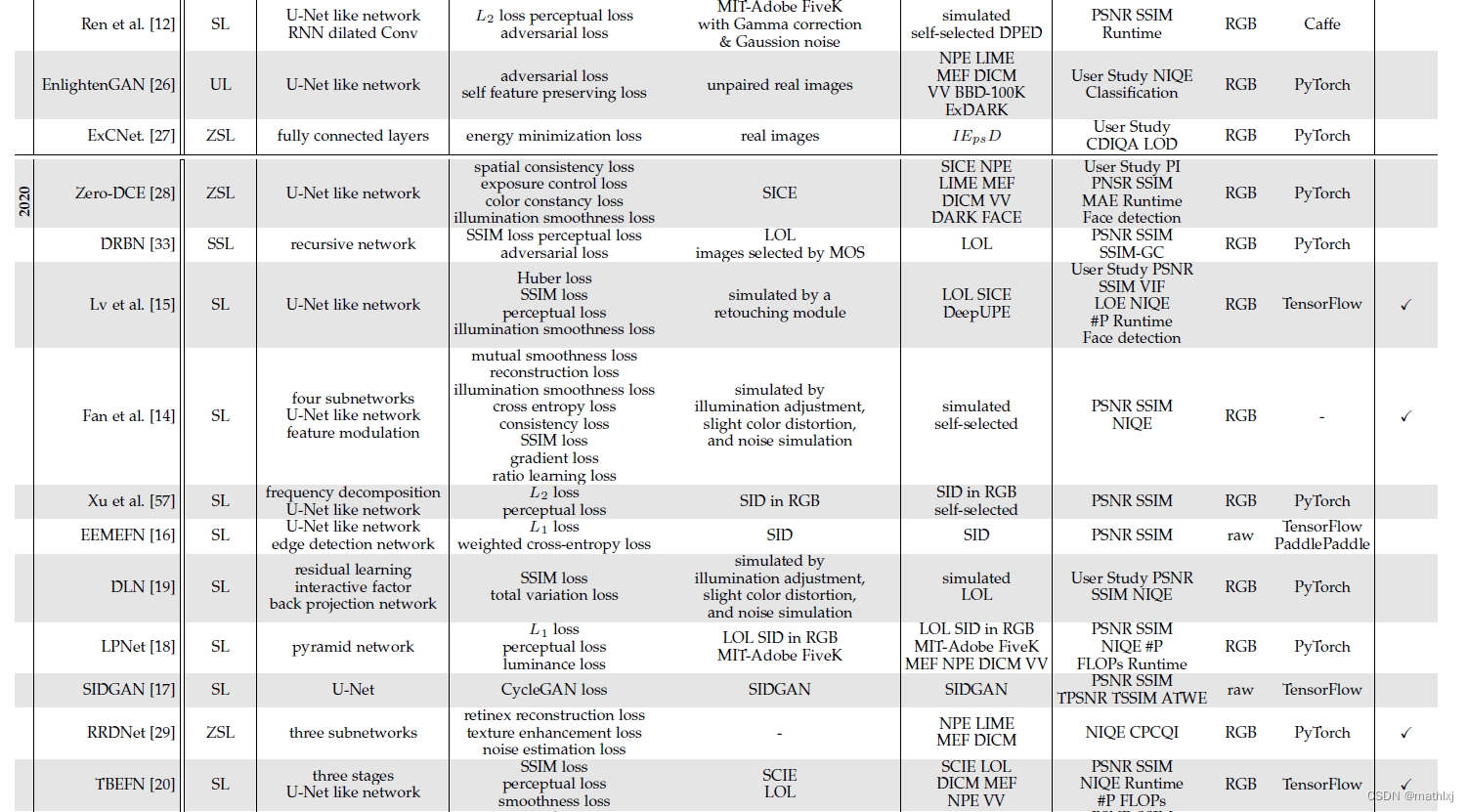
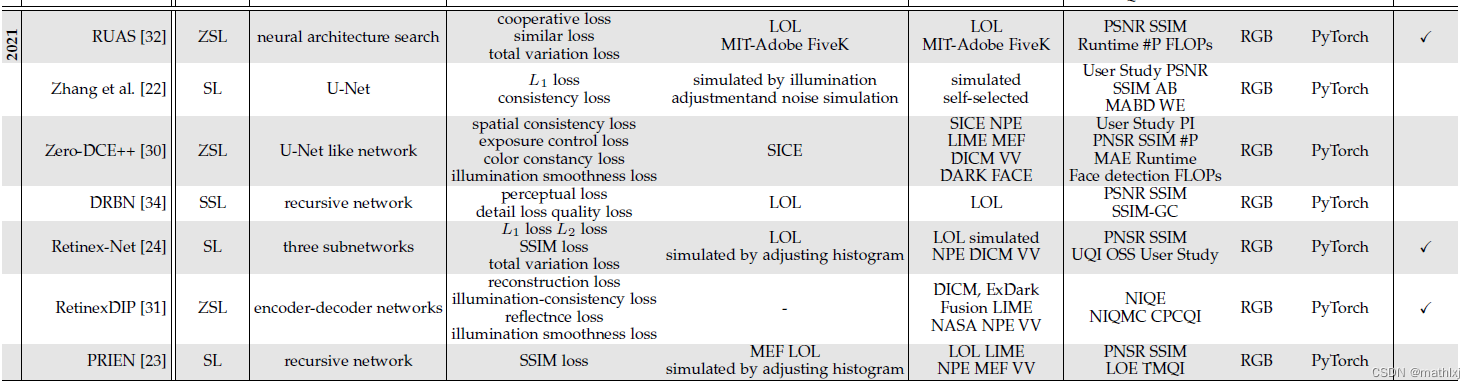
监督学习:分为end-to-end, deepRetinex-based 和realistic data-driven methods.
end-to-end: LLNet, MBLLEN,EEMEFN,LPNet,DSLR,
Retinex-based: 利用物理可解释的Retinex理论.
将illuminance部分和reflectance部分分开增强. 例如Retinex-Net,lightweight LightenNet,而DeepUPE学习从Image到illumination的映射;KinD,KinD++
数据集: SID, DIV(视频),SMOID(视频),SIDGAN(视频)
强化学习:DeepExposure,即首先根据曝光切分为sub-image, 局部曝光是强化学习学到的,奖惩函数类似于对抗学习. 再将局部曝光修整图像,获取不同曝光下的图像.无监督学习: 有监督的学习受限于泛化能力. 无监督学习EnligthenGAN,采用一个attention-guided U-Net作为生成器,使用global-local discriminators来使得增强结果跟自然光线相似.Zero-Shot Learning:直接从test data中学习增强,例如ExCNet, 首先拟合测试集一个最优的S曲线,然后根据S曲线,使用Guided filter划分为base layer和datail layer, 根据S曲线调整base layer,最后使用Weber contrast来融合detailed layer和调整后的base layer.;还有RRDNet,将图像分为illumination, reflectance和noise; RetinexDIP使用NN进行Retinex分解,然后增强low-light image; Zero-DCE/zero-DCE++将光线增强视为一个image-specific curve estimation,输入一个low-light图像输出一个伪high-order曲线.Semi-Supervised Learning:DRBN,首先恢复一个linear band representation,以监督的方式,然后通过无监督学习到的linear transformation进行增强.网络技巧
网络结构: 常见U-Net, pyramid network和multi-stage network.Deep Model和Retinex Theory结合.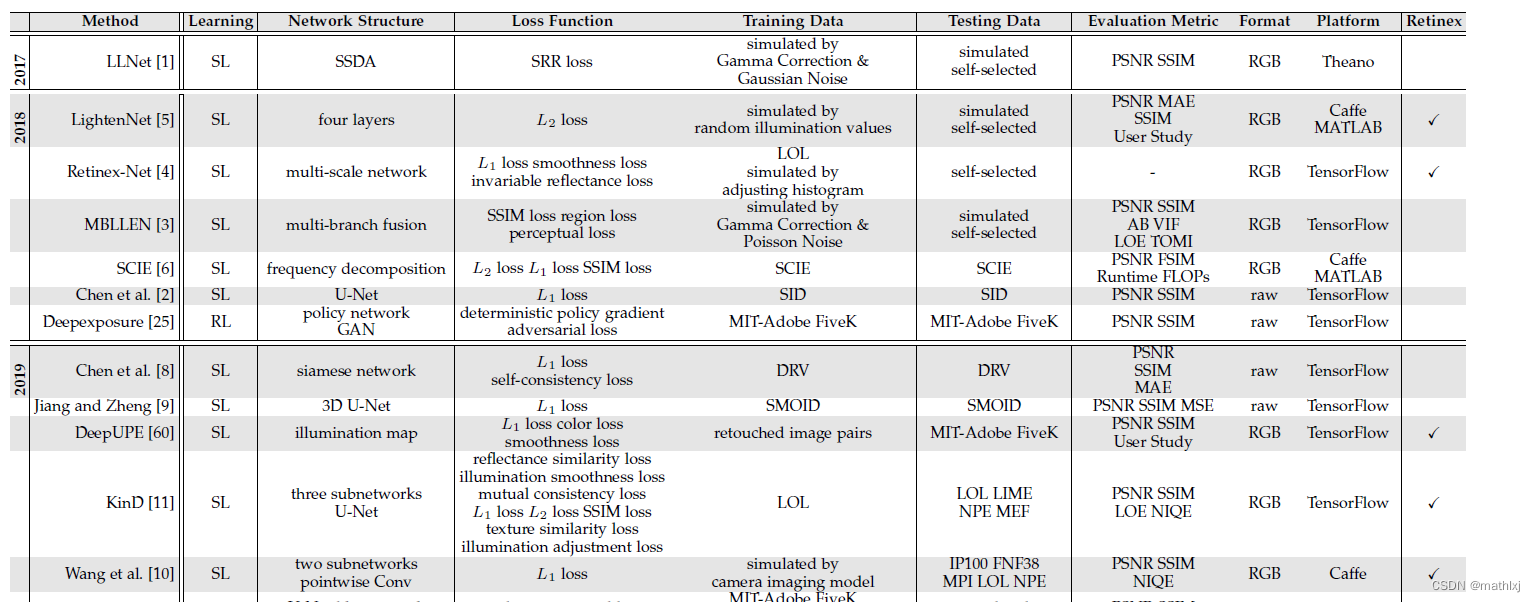
损失函数:
Reconstruction Loss(重构损失): L2倾向于乘法较大的错误,但是对较小错误容忍度高;L1损失保留颜色和luminance较好但是忽略了局部结构;SSIM保留了结构和纹理Perceptual Loss: 和gt在feature map空间中的相似度. 特征提取网络为从一个在ImageNet训练的VGG16.Smoothness Loss:移除结果中的噪音或保留相邻像素点的关系对抗损失:生成的图被辨别的损失Exposure Loss: 不需要匹配的图,直接衡量曝光度的损失训练集:
LOL: 500对 低光照和正常光照的图
SCIE: 589个户内/户外的场景,每个场景有3-18个不同曝光的图,因此有4413个多曝光的图. 选取589张高质量的图.分辨率在3000x2000和6000x4000
MIT-Adobe FiveK: 5000张图
SID:5094张短曝光的图,每个有个对应的长曝光的图
VE-LOL:2500对,1000对是合成的,1500对是真实的
DRV:202个原始的视频,每个对应一段长曝光的gt. 16-18fps/ 3672x5496
SMOID:179对序列,每个200帧
BBD-100K:视频,10000个视频,使用在晚上拍的用来做测试集
ExDARK:
DARK FACE: 6,000张晚上拍的人脸
作者提出新的数据集: LLIV-Phone,120视频,45,148个图像,18张手机类型,
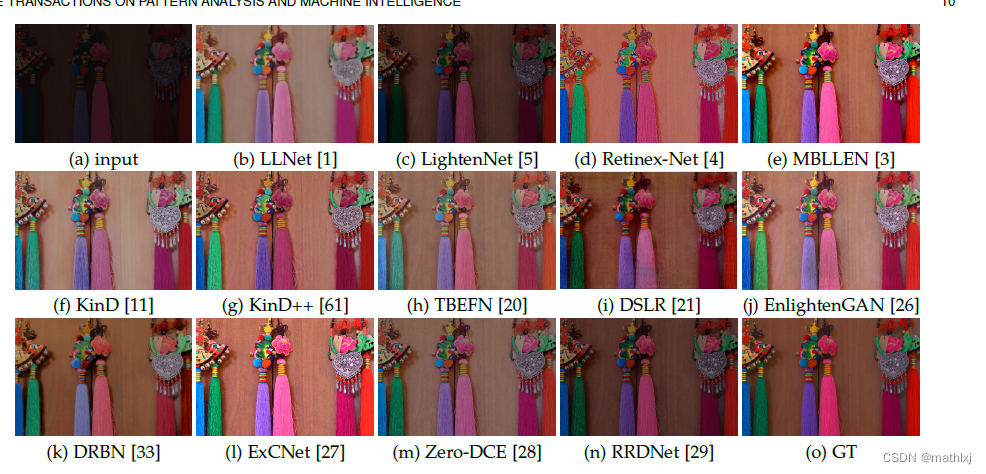

结果展示
方法对比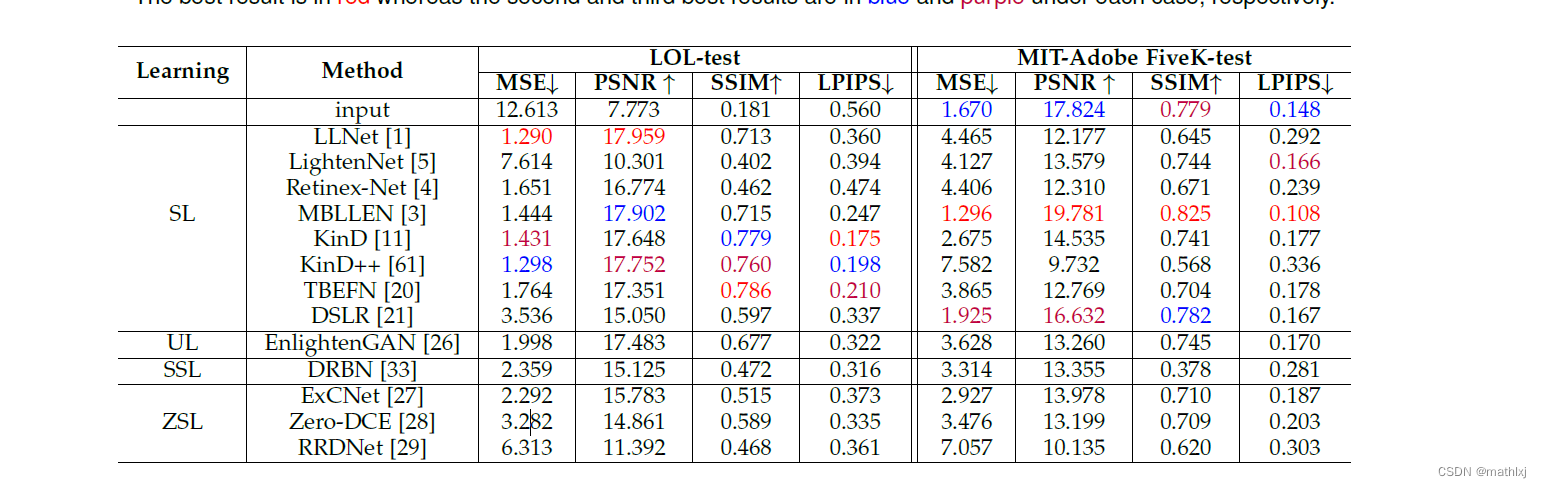
在1080ti上测速,输入1200x900x3,32张求平均![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6lRd3DNk-1670641306018)(:/d7085b61dec34013978b36ba3901ac3c)]](http://zhangshiyu.com/zb_users/upload/2022/12/20221215100912167107015261358.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QIwAr9Gl-1670641306019)(:/caa512055ab945799c41474832a3724e)]](http://zhangshiyu.com/zb_users/upload/2022/12/20221215100913167107015388308.png)