yolov5目标检测模型中,对模型结构的描述较多,也容易理解。但对如何获得目标预测方面描述较少,或总感觉云山雾罩搞不清楚。最近查阅一些资料,并加上运行yolov5程序的感受,总结一下对目标特征参数的预测方法,记录如下。
1 yolov5框架结构
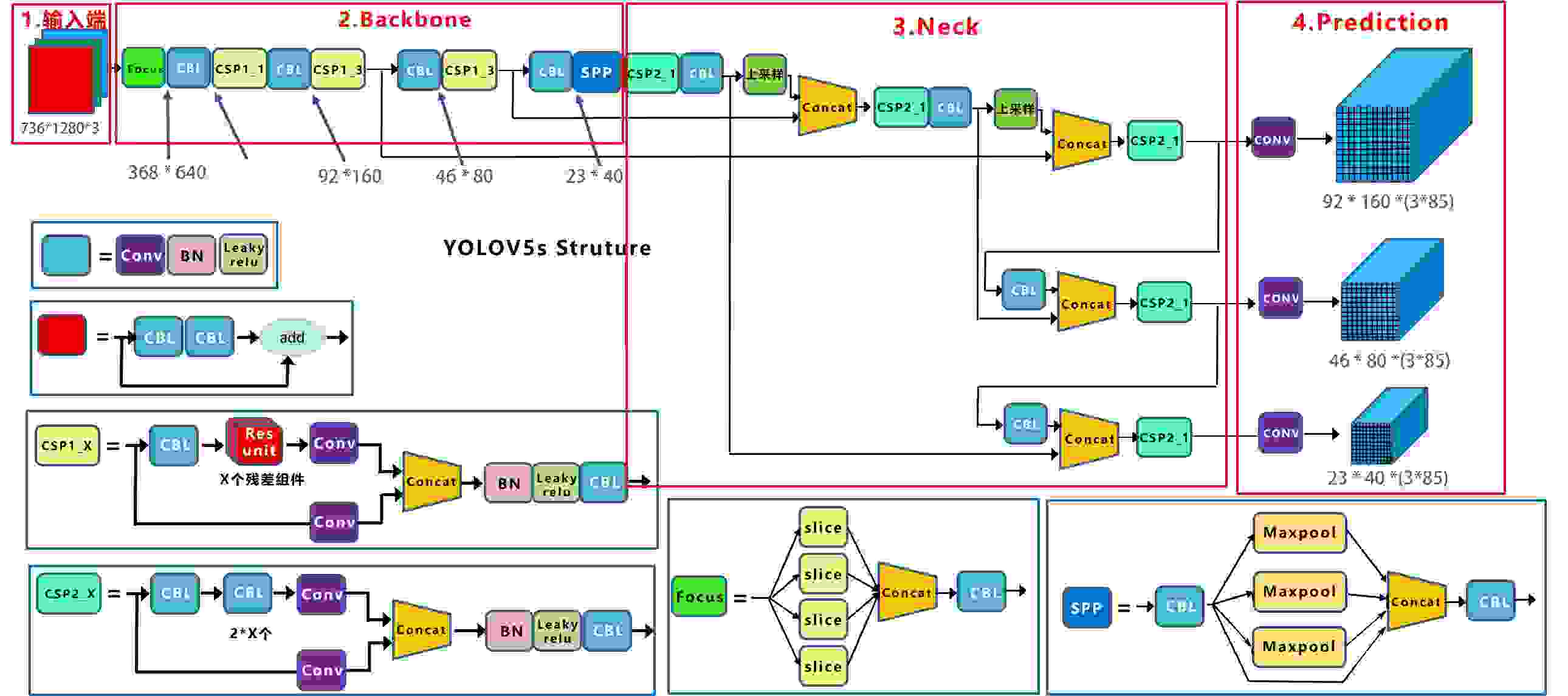
图x-1借用江大白的图,做了少许修改,以适应本博文的描述,其细节请看江大佬的文章。此处说明,输入图像为1280x720,根据边长需被32整除,resize为1280x736,在以下的描述中,对应tensor的顺序,改变行列顺序的写法,将输入图像写成 w x h = 736x1280。
输入图像 736x1280经yolov5模型,产生三个不同目标尺度的特征图,prediction形成92x160x(3x85)特征图,对应于小目标,46x80x(3x85)对应中目标,23x40x(3x85)对应大目标。这三个尺度特征图用来预测图像中的目标,产生目标框参数输出。
2 锚框anchor
锚框是根据先验知识选定的目标预测框初始形状,yolov5选用了三种不同宽高比的锚框。对每个特征图,用锚框anchor来预测目标框。见下图x-2,真实标签GT有行人类框(橙色)和小汽车框(黄色)。锚框预先设定为三种不同宽高比,Anchor box1- Anchor box 3(红色虚线框),显然Anchor box1适合预测行人,Anchor box3适合预测小汽车。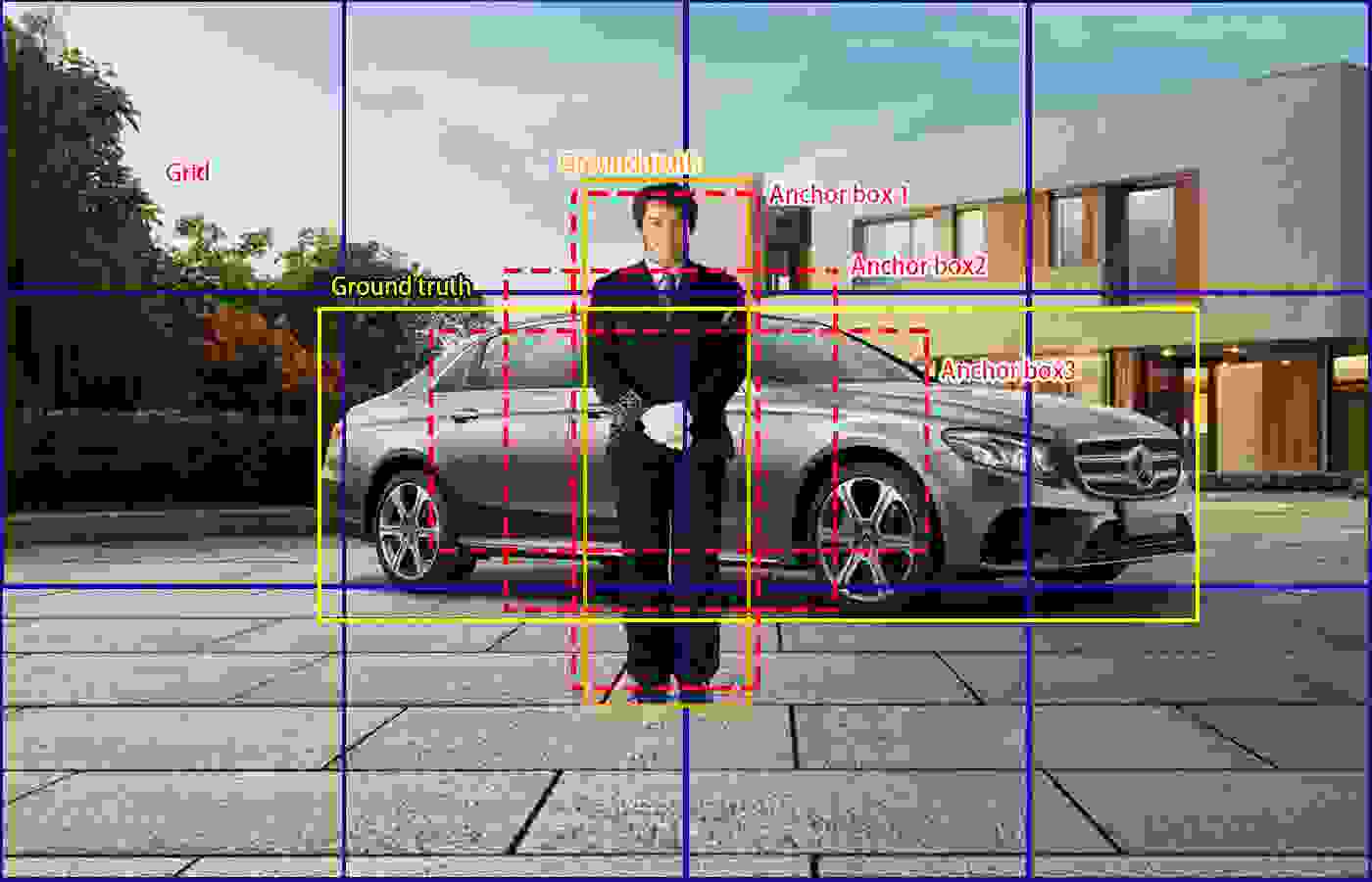
计算IoU,用相交面积和相并面积的比值,来确定两个框的相似程度,比值越大相似度越高。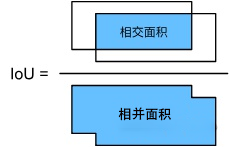
通过IoU,若Anchor box1套用在小汽车目标上,所得到的IoU值小,而套用行人IoU数值大,故对小汽车目标,可通过IoU阈值丢弃Anchor box1。
在yolov5特征图中,每个空间点,对应输入图像的一个网格,对每个网格中的目标,放置三个锚框来预测目标框,见图x-3。Yolov5不同尺度特征图,所采用的锚框尺寸也不同,如大目标,锚框采用116x90,156x198, 373x326三个不同形状的锚框。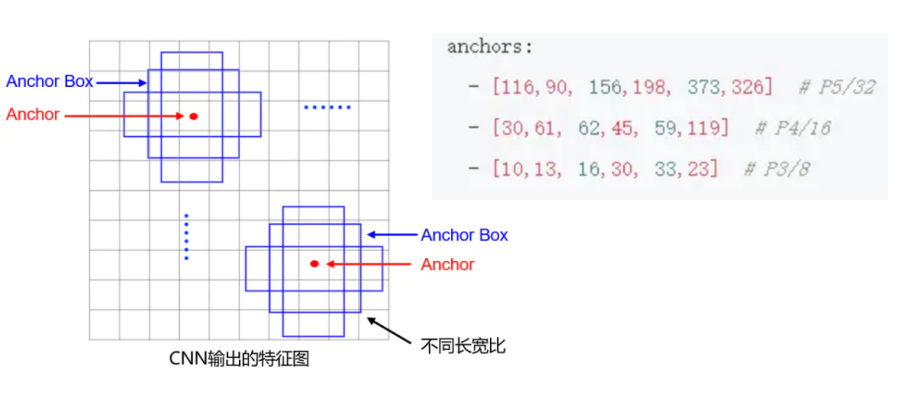
3 yolo目标预测
核心思想:将整张图片作为网络的输入,直接在输出层对目标框的位置和类别进行回归。
实现方法:
将一幅图像分成ShxSw个网格(grid cell),如果某个目标的中心落在这个网格中,则这个网格就负责预测这个目标。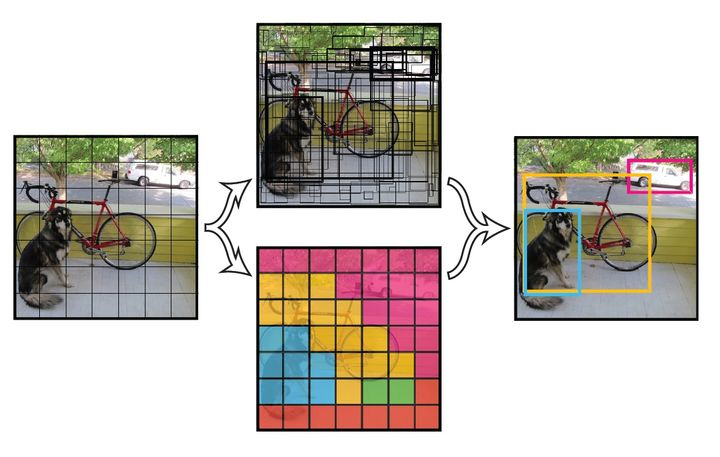
P r ( C l a s s i ∣ O b j e c t ) ∗ P r ( O b j e c t ) ∗ I O U t r u t h p r e d = P r ( C l a s s i ) ∗ I O U t r u t h p r e d Pr(Class_{i}|Object)*Pr(Object)*IOU\frac{truth}{pred}=Pr(Class_{i})*IOU\frac{truth}{pred} Pr(Classi∣Object)∗Pr(Object)∗IOUpredtruth=Pr(Classi)∗IOUpredtruth
其中如果有目标中心落在一个网格里,第一项取1,否则取0。 第二项是预测目标框和实际的groundtruth之间的IoU值。
每个目标框要预测(x, y, w, h)和置信度共5个值,每个网格还要预测一个类别信息,记为C类。把输入图像划分成ShxSw个网格,每个网格要预测B个目标框,还要预测C个类别。输出就是Sh x Sw x (5*B+C)的张量tensor。(注意:类别信息针对每个网格,置信度信息针对每个目标框。)
举例说明: 在COCO数据集中,共有80个类别
目标类别:C=80
图像输入:736x1280,
大尺度特征图,屏幕网格:23x40,Sh=23,Sw=40,
网格像素:32x32,
网格锚框: B=3
特征图输出张量:[1, 3, 23, 40, 85]
4 yolov5目标框预测程序实现
图x-5表示yolov5三个尺度特征图的形成,图中卷积层下方数字是通道数,上方为二维图像尺寸值,输入图像为736x1280,3通道。不同尺度特征图随卷积层加深,在输入图像上的感受野不同,就是特征图对应的输入图像网格大小不同。粗略计,大尺度特征图感受野是38, 中尺度感受野22, 小尺度感受野14。感受野区域中,位于中心的像素比边缘像素对特征图输出的贡献更高,即有效感受野比理论感受野范围小,所以,感受野范围应大于检测网络范围。如此,对应的原始图像网格分别是大尺度32x32, 中尺度16x16, 小尺度8x8。
图x-5中,backbone中卷积层输出的通道数由yolov5s.yaml确定,而从yolov5网站提供的ckpt模型则Backbone和Neck通道数需除以2。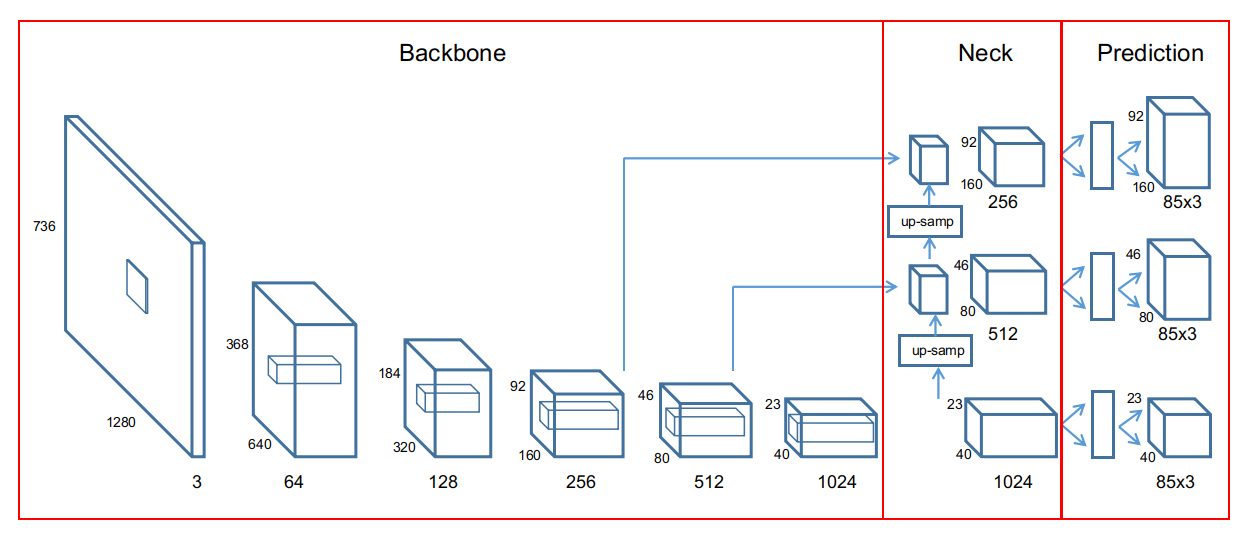
在网络推理时,每个网格预测的类别信息和目标框预测的置信度相乘,就得到每个目标框的类别置信度分class-specific confidence score:
P r ( C l a s s i ∣ O b j e c t ) ∗ P r ( O b j e c t ) ∗ I O U t r u t h p r e d = P r ( C l a s s i ) ∗ I O U t r u t h p r e d Pr(Class_{i}|Object)*Pr(Object)*IOU\frac{truth}{pred}=Pr(Class_{i})*IOU\frac{truth}{pred} Pr(Classi∣Object)∗Pr(Object)∗IOUpredtruth=Pr(Classi)∗IOUpredtruth
等式左边第一项就是每个网格预测的类别概率,第二三项就是每个目标框预测的置信度。这个乘积即为预测的目标框属于某个类别的概率,也有该目标框准确度的概率。
得到每个目标框的类别置信度分class-specific confidence score以后,设置阈值,滤掉得分低的目标框,对保留的目标框进行NMS处理,就得到最终的检测结果。
简单的概括就是:
(1) 给定一个输入图像,首先将图像划分成Sh x Sw的网格
(2) 对于每个网格,我们都预测3个边框(锚框,三种不同宽高比的方框)
(3) 根据上一步可以预测出Sh x Sw x3个目标窗口,然后根据阈值去除可能性比较低的目标窗口,最后NMS去除冗余窗口即可。
图x-6进一步给出三个尺度特征图输出张量包含的信息。每个尺度中,空间点上安排有三个先验框(锚框anchor),每个anchor分配边框坐标四个点(xywh),1个置信度,80个类别置信度,故每个anchor深度为85。图x-6输入图像736x1280,对应得到图中不同尺度的特征维度23x40x85, 46x80x85, 92x160x85。所对应的tensor shape分别是:[1, 3, 23, 40, 85], [1, 3, 46, 80, 85], [1, 3, 92, 160, 85]。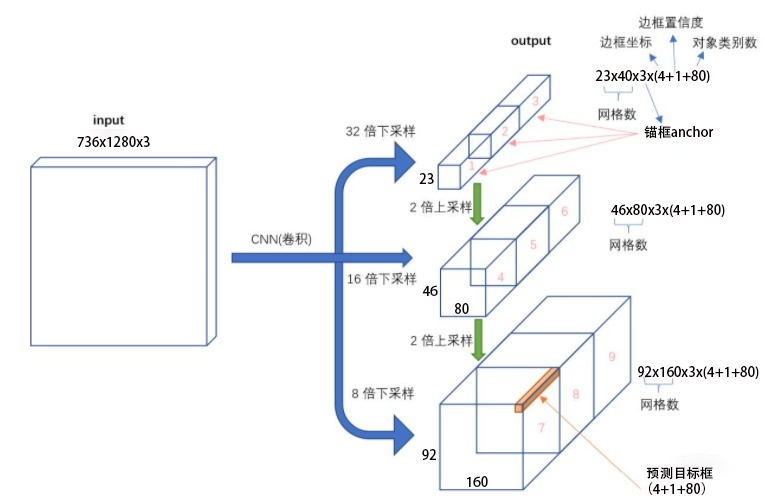
尺度特征图如何能产生目标坐标信息?这是通过训练得到,训练的loss设计使输出特征与目标框真值标签ground truth间差异为最小,特征量从图形几何参数转为目标框参数,见图x-7。
对输入图像,经yolo网络得到尺度特征图,尺度特征图上每个二维点,对应输入图像中的网格,每个网格获得目标预测值为:坐标(tx,ty)和宽高(tw,th),目标置信度pw,ph。按照下式计算该网格的目标坐标和目标框大小:
bx = σ(tx)*2-0.5+Cxby = σ(ty)*2-0.5+Cybw = pw(σ(tw)*2)**2bh = ph(σ(th)*2)**2其中,σ是sigmoid函数
在yolo.py中代码是:
y = x[i].sigmoid()y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xyy[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # whz.append(y.view(bs, -1, self.no))在x[i] (i=0,1,2对应三个尺度特征图)中,最后一个维度是85, 其前四个元素[tx,ty,tw,th]经线性回归计算,得到[bx,by,bw,bh],使锚框接近目标的真实标签GT。此外,Pw,Ph认为是1,表示目标是positive(网格中有目标)。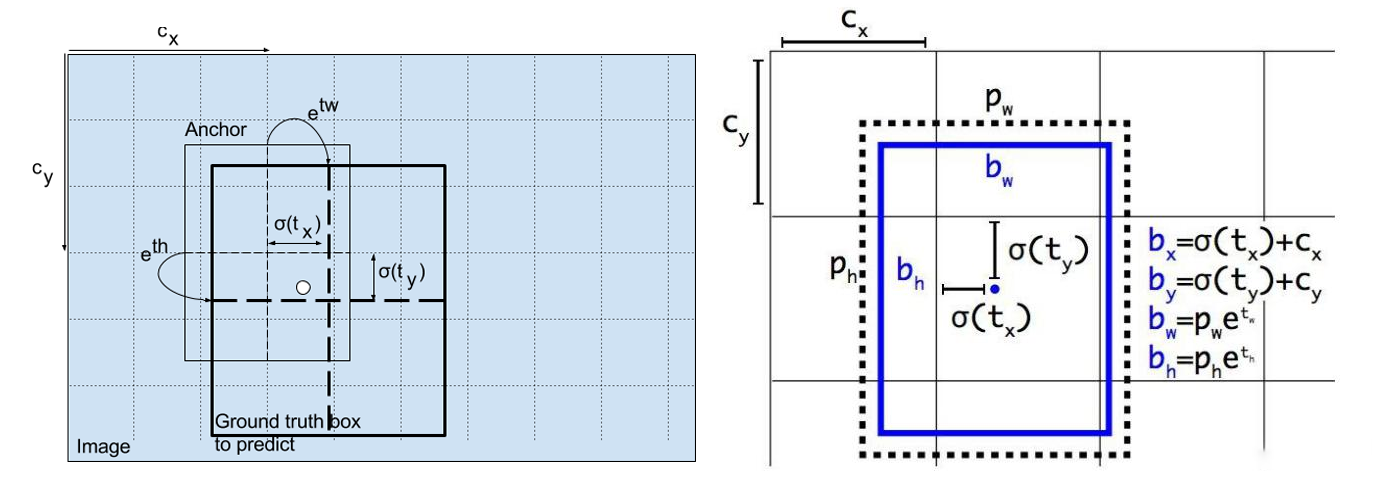
针对输入图像736x1280, 经目标框坐标变换后,得到所有网格中的目标框张量[1, 57960,85]。
57960=(40x23+80x46+160x92)x3 是所有网格的目标框数量。
经过非极大值抑制nms处理,去除小于置信度目标,IoU阈值,类别选择,剩下的就是图像中实际的预测目标参数xywh和置信度conf。
下面图x-9形象表示了网格和目标框参数的对应情况。黑网格表示无目标Pc = 0,下面几个黑网格虽然有目标,但占网格的比例小,IoU值小将被丢弃。绿网格为白车目标中心(绿点)所落入的网格,Pc = 1,所预测的目标框为红框。黄网格中有一个小目标,在此网格中IoU值小,也可能被丢弃,但在另一个小目标尺度的特征图网格中,将提取此目标。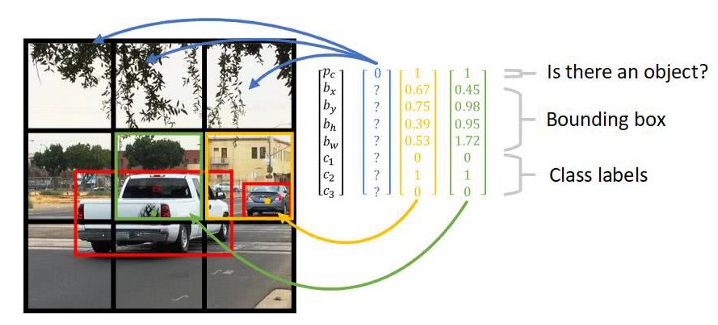
图x-10是目标框的参数张量示意图,一个网格配置三个不同比例的目标框Box1,Box2,Box3,B是锚框数量。