?大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流?
?个人主页-Sonhhxg_柒的博客_CSDN博客 ?
?欢迎各位→点赞? + 收藏⭐️ + 留言?
?系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】

?foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟?
文章目录
技术要求
创建马尔可夫链
怎么做...
这个怎么运作...
还有更多...
创建 MDP
怎么做...
这个怎么运作...
还有更多...
也可以看看
执行政策评估
这个怎么运作...
还有更多...
模拟 FrozenLake 环境
做好准备
怎么做...
这个怎么运作...
还有更多...
使用值迭代算法求解 MDP
怎么做...
这个怎么运作...
还有更多...
使用策略迭代算法解决 MDP
怎么做...
这个怎么运作...
还有更多...
还有更多...
也可以看看
解决抛硬币赌博问题
怎么做...
这个怎么运作...
还有更多...
在本章中,我们将通过查看马尔可夫决策过程( MDP ) 和动态规划,继续我们使用 PyTorch 的实际强化学习之旅。本章将从创建马尔可夫链和 MDP 开始,这是大多数强化学习算法的核心。通过实践政策评估,您还将更加熟悉贝尔曼方程。然后,我们将继续并应用两种方法来解决 MDP:价值迭代和策略迭代。我们将使用 FrozenLake 环境作为示例。在本章的最后,我们将逐步演示如何用动态规划解决有趣的抛硬币赌博问题。
本章将介绍以下食谱:
创建马尔可夫链创建 MDP执行政策评估模拟 FrozenLake 环境使用值迭代算法求解 MDP使用策略迭代算法解决 MDP解决抛硬币赌博问题技术要求
您需要在系统上安装以下程序才能成功执行本章中的食谱:
Python 3.6, 3.7, or aboveAnacondaPyTorch 1.0 or aboveOpenAI Gym创建马尔可夫链
让我们从创建马尔可夫链开始,MDP 就是在该链上开发的。
马尔可夫链描述了一系列符合马尔可夫属性的事件。它由一组可能的状态S = {s0, s1, ... , sm}和转换矩阵T(s, s')定义,该矩阵由状态s转换到状态 s'的概率组成。根据马尔可夫性质,给定当前状态,过程的未来状态有条件地独立于过去状态。换句话说,进程在t+1时的状态仅取决于t时的状态。这里,我们以一个学习和睡眠的过程为例,创建一个基于两个状态s0(study)和s1的马尔可夫链(睡觉)。假设我们有以下转换矩阵:
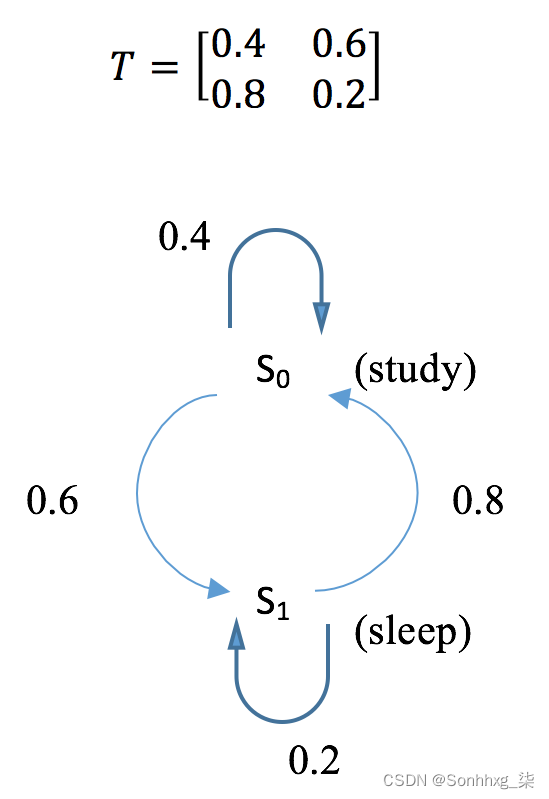
在下一节中,我们将计算 k 步骤后的转移矩阵,以及在给定状态初始分布(例如[0.7, 0.3] )的情况下处于每个状态的概率,这意味着该过程有 70% 的可能性从学习,并且有 30% 的机会从睡眠开始。
怎么做...
要为学习和睡眠过程创建马尔可夫链并对其进行一些分析,请执行以下步骤:
1.导入库并定义转换矩阵:
>>> import torch>>> T = torch.tensor([[0.4, 0.6],... [0.8, 0.2]])2.计算 k 步后的转移概率。这里,我们使用 k = 2, 5, 10, 15, 和20作为例子:
>>> T_2 = torch.matrix_power(T, 2) >>> T_5 = torch.matrix_power(T, 5) >>> T_10 = torch.matrix_power(T, 10) >>> T_15 = torch.matrix_power(T, 15) >>> T_20 = torch.matrix_power(T, 20)3.定义两个状态的初始分布:
>>> v = torch.tensor([[0.7, 0.3]])4.计算 k = 1, 2, 5, 10, 15, 和20步骤后的状态分布:
>>> v_1 = torch.mm(v, T) >>> v_2 = torch.mm(v, T_2) >>> v_5 = torch.mm(v, T_5) >>> v_10 = torch.mm(v, T_10) >>> v_15 = torch.mm(v, T_15) >>> v_20 = torch.mm(v, T_20)这个怎么运作...
在步骤2中,我们计算了k步后的转移概率,即转移矩阵的k次方。您将看到以下输出:
>>> print("Transition probability after 2 steps:\n{}".format(T_2))Transition probability after 2 steps:tensor([[0.6400, 0.3600], [0.4800, 0.5200]])>>> print("Transition probability after 5 steps:\n{}".format(T_5))Transition probability after 5 steps:tensor([[0.5670, 0.4330], [0.5773, 0.4227]])>>> print("Transition probability after 10 steps:\n{}".format(T_10))Transition probability after 10 steps:tensor([[0.5715, 0.4285], [0.5714, 0.4286]])>>> print("Transition probability after 15 steps:\n{}".format(T_15))Transition probability after 15 steps:tensor([[0.5714, 0.4286], [0.5714, 0.4286]])>>> print("Transition probability after 20 steps:\n{}".format(T_20))Transition probability after 20 steps:tensor([[0.5714, 0.4286], [0.5714, 0.4286]])我们可以看到,在 10 到 15 步之后,转移概率收敛。这意味着,无论进程处于什么状态,它都有相同的概率转换到 s0 (57.14%) 和 s1 (42.86%)。
在第4步中,我们计算了k = 1, 2, 5, 10, 15, 和20步骤之后的状态分布,它是初始状态分布和转移概率的乘积。你可以在这里看到结果:
>>> print("Transition probability after 2 steps:\n{}".format(T_2))Transition probability after 2 steps:tensor([[0.6400, 0.3600], [0.4800, 0.5200]])>>> print("Transition probability after 5 steps:\n{}".format(T_5))Transition probability after 5 steps:tensor([[0.5670, 0.4330], [0.5773, 0.4227]])>>> print("Transition probability after 10 steps:\n{}".format(T_10))Transition probability after 10 steps:tensor([[0.5715, 0.4285], [0.5714, 0.4286]])>>> print("Transition probability after 15 steps:\n{}".format(T_15))Transition probability after 15 steps:tensor([[0.5714, 0.4286], [0.5714, 0.4286]])>>> print("Transition probability after 20 steps:\n{}".format(T_20))Transition probability after 20 steps:tensor([[0.5714, 0.4286], [0.5714, 0.4286]])我们可以看到,在 10 步之后,状态分布收敛了。处于s0的概率(57.14%)和处于s1的概率(42.86%)长期保持不变。
从 [0.7, 0.3] 开始,一次迭代后的状态分布变为 [0.52, 0.48]。其计算详情如下图所示:

在另一次迭代后,状态分布变为 [0.592, 0.408],如下图所示:
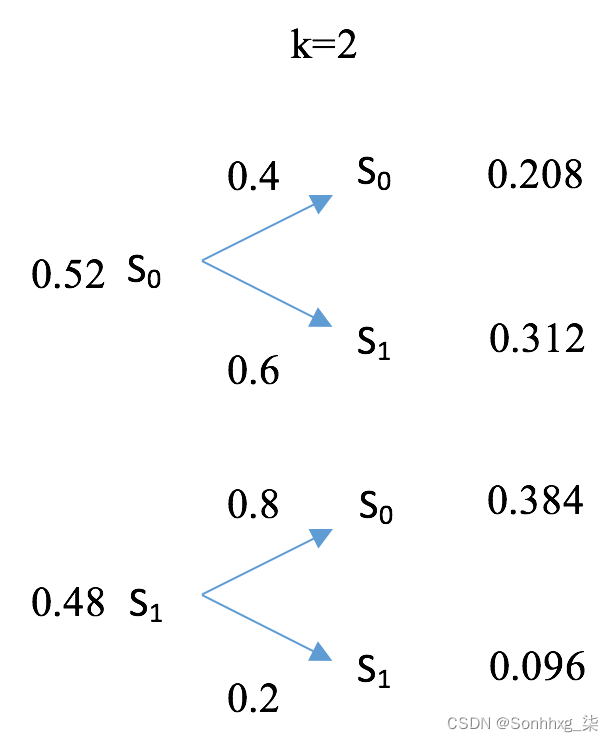
随着时间的推移,状态分布达到平衡。
还有更多...
事实上,无论过程处于何种初始状态,状态分布都将始终收敛于 [0.5714, 0.4286]。您可以使用其他初始分布进行测试,例如 [0.2, 0.8] 和 [1, 0]。10 步后分布将保持 [0.5714, 0.4286]。
马尔可夫链不一定会收敛,尤其是当它包含瞬态或当前状态时。但如果它确实收敛,无论起始分布如何,它都会达到相同的平衡。
如果你想阅读更多关于马尔可夫链的信息,以下是全球范围内具有漂亮可视化效果的两篇很棒的博客文章:
创建 MDP
MDP 是在马尔可夫链上发展起来的,包括一个代理人和一个决策过程。让我们继续开发 MDP 并计算最优策略下的价值函数。
除了一组可能的状态S = {s0, s1, ... , sm}之外,MDP 由一组动作定义,A = {a0, a1, ... , an};过渡模型,T(s, a, s');奖励函数,R(s);和折扣系数 ?。转移矩阵T(s, a, s')包含从状态 s 采取行动 a 然后到达 s' 的概率。折扣因子 ? 控制未来奖励和即时奖励之间的权衡。
为了使我们的 MDP 稍微复杂一些,我们将学习和睡眠过程扩展到一个状态,即s2 play游戏。假设我们有两个动作,a0 work 和a1 slack。3 * 2 * 3的转移矩阵T(s, a, s')如下:

这意味着,例如,当从状态 s0 study 采取 a1 松弛动作时,有 60% 的几率会变成 s1 睡眠(可能是累了),有 30% 的几率会变成 s2 玩游戏(可能是想要放松),并且有 10% 的机会继续学习(可能是一个真正的工作狂)。我们将三个状态的奖励函数定义为 [+1, 0, -1],以补偿辛苦的工作。显然,在这种情况下,最优策略是为每一步选择 a0 工作(继续学习——一分耕耘一分收获,对吧?)。此外,我们首先选择 0.5 作为折扣因子。在下一节中,我们将计算状态值函数(也称为值函数,简称值,或期望效用) 在最优策略下。
怎么做...
可以通过以下步骤创建 MDP:
1.导入 PyTorch 并定义转换矩阵:
>>> import torch >>> T = torch.tensor([[[0.8, 0.1, 0.1], ... [0.1, 0.6, 0.3]], ... [[0.7, 0.2, 0.1], ... [0.1, 0.8, 0.1]], ... [[0.6, 0.2, 0.2], ... [0.1, 0.4, 0.5]]] ... )2.定义奖励函数和折扣因子:
>>> R = torch.tensor([1., 0, -1.]) >>> gamma = 0.53.在这种情况下,最优策略是a0在所有情况下选择行动:
>>> action = 04.我们使用以下函数中的矩阵求逆V方法计算最优策略的值 :
>>> def cal_value_matrix_inversion(gamma, trans_matrix, rewards): ... inv = torch.inverse(torch.eye(rewards.shape[0]) - gamma * trans_matrix) ... V = torch.mm(inv, rewards.reshape(-1, 1)) ... return V我们将在下一节中演示如何得出该值。
5.我们将所有变量提供给函数,包括与 action 相关的转换概率a0:
>>> trans_matrix = T[:, action] >>> V = cal_value_matrix_inversion(gamma, trans_matrix, R) >>> print("The value function under the optimal policy is:\n{}".format(V)) The value function under the optimal policy is: tensor([[ 1.6787], [ 0.6260], [-0.4820]])这个怎么运作...
在这个过于简化的 study-sleep-game 过程中,最优策略,即获得最高总奖励的策略,在所有步骤中都选择动作 a0。然而,在大多数情况下它不会那么简单。此外,各个步骤中采取的操作不一定相同。它们通常依赖于状态。因此,我们将不得不通过在真实案例中找到最优策略来解决 MDP。
给定所遵循的策略,策略的价值函数衡量代理人在每个状态下的好坏程度。值越大,状态越好。
在第 4 步中,我们使用矩阵求逆V计算了最优策略的值。根据贝尔曼方程,第t+1步的值与第t步的值之间的关系可以表示为:
![]()
当值收敛时,即Vt+1 = Vt,我们可以导出值 ,V如下所示:
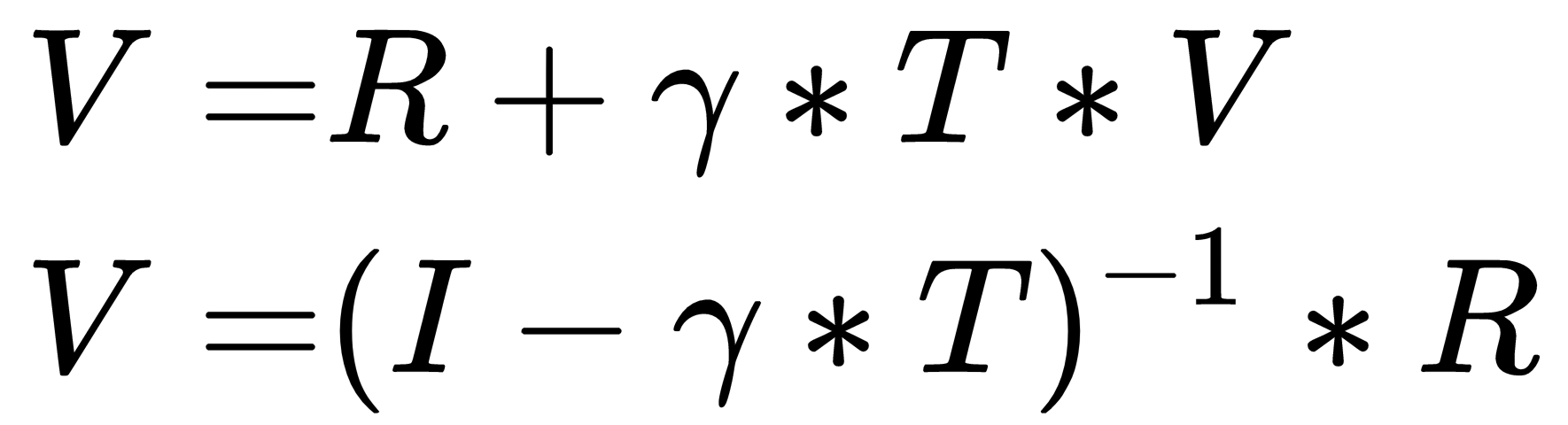
这里,I是主对角线上为 1 的单位矩阵。
使用矩阵求逆求解 MDP 的一个优点是您总能得到准确的答案。但缺点是它的可扩展性。由于我们需要计算 m * m 矩阵的求逆(其中m是可能状态的数量),因此如果存在大量状态,计算将变得昂贵。
还有更多...
我们决定尝试使用不同的折扣因子值。让我们从 0 开始,这意味着我们只关心即时奖励:
>>> gamma = 0 >>> V = cal_value_matrix_inversion(gamma, trans_matrix, R) >>> print("The value function under the optimal policy is:\n{}".format(V)) The value function under the optimal policy is: tensor([[ 1.], [ 0.], [-1.]])这与奖励函数一致,因为我们只看下一步行动中收到的奖励。
随着折扣因子向 1 增加,未来的奖励被考虑在内。让我们来看看?=0.99:
>>> gamma = 0.99 >>> V = cal_value_matrix_inversion(gamma, trans_matrix, R) >>> print("The value function under the optimal policy is:\n{}".format(V)) The value function under the optimal policy is: tensor([[65.8293], [64.7194], [63.4876]])也可以看看
此备忘单Markov Decision Process — Computer Scientists' Cheatsheet documentation可作为 MDP 的快速参考。
执行政策评估
我们刚刚开发了一个 MDP,并使用矩阵求逆计算了最优策略的价值函数。我们还提到了反转具有较大 m 值(例如 1,000、10,000 或 100,000)的 m * m 矩阵的局限性。在这个秘籍中,我们将讨论一种更简单的方法,称为策略评估。
政策评估是一种迭代算法。它从任意策略值开始,然后根据贝尔曼期望方程迭代更新这些值,直到它们收敛。在每次迭代中,状态s的策略值π更新如下:
这里,π(s, a)表示在策略π下在状态s中采取动作a的概率。T(s, a, s')是通过采取行动a从状态s到状态s'的转移概率,而R(s, a)是通过采取行动a在状态s收到的奖励。
有两种方法可以终止迭代更新过程。一种是设置固定的迭代次数,比如1000、10000,有时可能很难控制。另一个涉及指定一个阈值(通常是 0.0001、0.00001 或类似的东西),并且仅当所有状态的值变化到低于指定阈值的程度时才终止该过程。
在下一节中,我们将在最优策略和随机策略下对学习-睡眠-游戏过程进行策略评估。
让我们开发一个策略评估算法并将其应用于我们的学习-睡眠-游戏过程,如下所示:
1.导入 PyTorch 并定义转换矩阵:
>>> import torch >>> T = torch.tensor([[[0.8, 0.1, 0.1], ... [0.1, 0.6, 0.3]], ... [[0.7, 0.2, 0.1], ... [0.1, 0.8, 0.1]], ... [[0.6, 0.2, 0.2], ... [0.1, 0.4, 0.5]]] ... )2.定义奖励函数和折扣因子(让我们0.5现在使用):
>>> R = torch.tensor([1., 0, -1.]) >>> gamma = 0.53.定义用于确定何时停止评估过程的阈值:
>>> threshold = 0.00014.定义在所有情况下都选择动作 a0 的最优策略:
>>> policy_optimal = torch.tensor([[1.0, 0.0], ... [1.0, 0.0], ... [1.0, 0.0]])5.开发一个策略评估函数,该函数接受策略、转换矩阵、奖励、折扣因子和阈值并计算该value函数:
>>> def policy_evaluation( policy, trans_matrix, rewards, gamma, threshold):... """... Perform policy evaluation... @param policy: policy matrix containing actions and their probability in each state... @param trans_matrix: transformation matrix... @param rewards: rewards for each state... @param gamma: discount factor... @param threshold: the evaluation will stop once values for all states are less than the threshold... @return: values of the given policy for all possible states... """... n_state = policy.shape[0]... V = torch.zeros(n_state)... while True:... V_temp = torch.zeros(n_state)... for state, actions in enumerate(policy):... for action, action_prob in enumerate(actions):... V_temp[state] += action_prob * (R[state] + gamma * torch.dot( trans_matrix[state, action], V))... max_delta = torch.max(torch.abs(V - V_temp))... V = V_temp.clone()... if max_delta <= threshold:... break... return V6.现在让我们插入最优策略和所有其他变量:
>>> V = policy_evaluation(policy_optimal, T, R, gamma, threshold)>>> print( "The value function under the optimal policy is:\n{}".format(V))The value function under the optimal policy is:tensor([ 1.6786, 0.6260, -0.4821])这与我们使用矩阵求逆得到的结果几乎相同。
7.我们现在尝试另一种策略,一种随机策略,其中以相同的概率选择动作:
>>> policy_random = torch.tensor([[0.5, 0.5],... [0.5, 0.5],... [0.5, 0.5]])8.插入随机策略和所有其他变量:
>>> V = policy_evaluation(policy_random, T, R, gamma, threshold)>>> print( "The value function under the random policy is:\n{}".format(V))The value function under the random policy is:tensor([ 1.2348, 0.2691, -0.9013])这个怎么运作...
我们刚刚看到使用策略评估来计算策略的价值是多么有效。它是动态规划系列中的一种简单的收敛迭代方法,或者更具体地说,是近似动态规划。它从对值的随机猜测开始,然后根据 Bellman 期望方程迭代更新它们,直到它们收敛。
在第 5 步中,政策评估功能执行以下任务:
将策略值初始化为全零。根据 Bellman 期望方程更新值。计算所有状态下值的最大变化。如果最大变化大于阈值,它会不断更新值。否则,它终止评估过程并返回最新值。由于策略评估使用迭代逼近,其结果可能与使用精确计算的矩阵求逆方法的结果不完全相同。事实上,我们真的不需要那么精确的价值函数。此外,它还可以解决维 数灾难问题,从而将计算扩展到数亿个状态。因此,我们通常更喜欢政策评估。
要记住的另一件事是,政策评估用于预测我们将从给定政策中获得多大的收益;它不用于控制问题。
还有更多...
为了更仔细地观察,我们还绘制了整个评估过程中的策略值。
我们首先需要在policy_evaluation函数中记录每次迭代的值:
>>> def policy_evaluation_history( policy, trans_matrix, rewards, gamma, threshold):... n_state = policy.shape[0]... V = torch.zeros(n_state)... V_his = [V]... i = 0... while True:... V_temp = torch.zeros(n_state)... i += 1... for state, actions in enumerate(policy):... for action, action_prob in enumerate(actions):... V_temp[state] += action_prob * (R[state] + gamma * torch.dot(trans_matrix[state, action], V))... max_delta = torch.max(torch.abs(V - V_temp))... V = V_temp.clone()... V_his.append(V)... if max_delta <= threshold:... break... return V, V_his现在我们为policy_evaluation_history函数提供最优策略、折扣因子0.5和其他变量:
>>> V, V_history = policy_evaluation_history( policy_optimal, T, R, gamma, threshold)然后,我们使用以下代码行绘制生成的值历史记录:
>>> import matplotlib.pyplot as plt>>> s0, = plt.plot([v[0] for v in V_history])>>> s1, = plt.plot([v[1] for v in V_history])>>> s2, = plt.plot([v[2] for v in V_history])>>> plt.title('Optimal policy with gamma = {}'.format(str(gamma)))>>> plt.xlabel('Iteration')>>> plt.ylabel('Policy values')>>> plt.legend([s0, s1, s2],... ["State s0",... "State s1",... "State s2"], loc="upper left")>>> plt.show()我们看到以下结果:
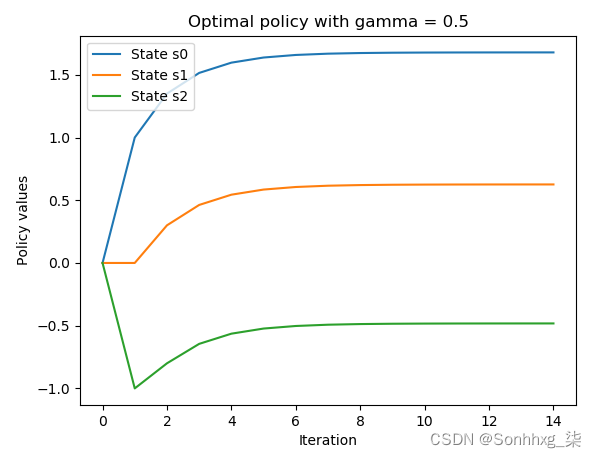
有趣的是,在收敛期间看到迭代 10 到 14 之间的稳定性。
接下来,我们运行相同的代码,但使用两个不同的折扣因子 0.2 和 0.99。我们得到以下贴现因子为 0.2 的图: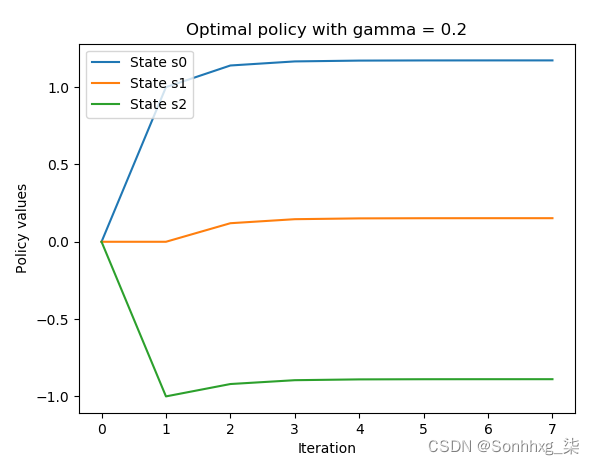
将贴现因子为 0.5 的图与这幅图进行比较,我们可以看到因子越小,策略值收敛得越快。
我们还得到以下贴现系数为 0.99 的图:

通过比较贴现因子为 0.5 的图和贴现因子为 0.99 的图,我们可以看到因子越大,策略值收敛所需的时间越长。折扣因子是现在奖励和未来奖励之间的权衡。
模拟 FrozenLake 环境
到目前为止,我们处理的 MDP 的最优策略非常直观。然而,在大多数情况下并不会那么简单,例如 FrozenLake 环境。在这个秘籍中,让我们尝试一下 FrozenLake 环境,并为即将到来的秘籍做好准备,我们将在其中找到其最优策略。
FrozenLake 是一个典型的具有离散状态空间的 Gym 环境。它是关于在网格世界中将代理从起始位置移动到目标位置,同时避免陷阱。网格是四乘四 ( https://gym.openai.com/envs/FrozenLake-v0/ ) 或八乘八。
t ( https://gym.openai.com/envs/FrozenLake8x8-v0/ )。网格由以下四种类型的图块组成:
S : 起始位置G:目标位置,终止一个情节F : 冻结的瓷砖,这是一个可步行的位置H : 洞的位置,结束一集显然有四个动作:向左移动 (0)、向下移动 (1)、向右移动 (2) 和向上移动 (3)。如果智能体成功到达目标位置,则奖励为 +1,否则为 0。此外,观察空间以 16 维整数数组表示,并且有 4 种可能的操作(这是有道理的)。
这种环境中的棘手之处在于,由于冰面很滑,智能体不会总是朝着它想要的方向移动。例如,当它打算向下移动时,它可能会向左或向右移动。
做好准备
要运行 FrozenLake 环境,让我们首先在此处的环境表中搜索它:https ://github.com/openai/gym/wiki/Table-of-environments 。搜索给了我们FrozenLake-v0。
怎么做...
让我们按照以下步骤模拟 4×4 FrozenLake 环境:
1.我们导入gym库并创建 FrozenLake 环境的实例:
>>> import gym>>> import torch>>> env = gym.make("FrozenLake-v0")>>> n_state = env.observation_space.n>>> print(n_state)16>>> n_action = env.action_space.n>>> print(n_action)42.重置环境:
>>> env.reset() 0代理从 state 开始0。
3.渲染环境:
>>> env.render()4.让我们做一个向下的运动,因为它是可步行的:
>>> new_state,reward,is_done,info = env.step(1) >>> env.render()5.打印出所有返回信息,确认agent登陆状态4的概率为33.33%:
>>> print(new_state) 4 >>> print(reward) 0.0 >>> print(is_done) False >>> print(info) {'prob': 0.3333333333333333}你会得到0奖励,因为它还没有达到目标,而且剧集还没有完成。同样,您可能会看到智能体以状态 1 着陆,或者由于光滑的表面而停留在状态 0。
6.为了演示在结冰的湖面上行走有多困难,实施随机策略并计算超过 1,000 集的平均总奖励。首先,定义一个函数,在给定策略的情况下模拟 FrozenLake 情节并返回总奖励(我们知道它是 0 或 1):
>>> def run_episode(env, policy):... state = env.reset()... total_reward = 0... is_done = False... while not is_done:... action = policy[state].item()... state, reward, is_done, info = env.step(action)... total_reward += reward... if is_done:... break... return total_reward7.现在运行1000episode,将随机生成一个策略并将在每个 episode 中使用:
>>> n_episode = 1000>>> total_rewards = []>>> for episode in range(n_episode):... random_policy = torch.randint( high=n_action, size=(n_state,))... total_reward = run_episode(env, random_policy)... total_rewards.append(total_reward)...>>> print('Average total reward under random policy: {}'.format( sum(total_rewards) / n_episode))Average total reward under random policy: 0.014这基本上意味着,如果我们随机化操作,智能体平均只有 1.4% 的机会可以达到目标。
8.接下来,我们试验随机搜索策略。在训练阶段,我们随机生成一堆策略并记录第一个达到目标的策略:
>>> while True:... random_policy = torch.randint( high=n_action, size=(n_state,))... total_reward = run_episode(env, random_policy)... if total_reward == 1:... best_policy = random_policy... break9.看看最好的政策:
>>> print(best_policy)tensor([0, 3, 2, 2, 0, 2, 1, 1, 3, 1, 3, 0, 0, 1, 1, 1])10.现在使用我们刚刚挑选的策略运行 1,000 集:
>>> total_rewards = []>>> for episode in range(n_episode):... total_reward = run_episode(env, best_policy)... total_rewards.append(total_reward)...>>> print('Average total reward under random search policy: {}'.format(sum(total_rewards) / n_episode))Average total reward under random search policy: 0.208使用随机搜索算法,平均有 20.8% 的时间会达到目标。
请注意,此结果可能会有很大差异,因为我们选择的策略可能会因为光滑的冰面而恰好达到目标,并且可能不是最佳策略。这个怎么运作...
在这个秘籍中,我们随机生成了一个由 16 个状态的 16 个动作组成的策略。请记住,在 FrozenLake 中,移动方向仅部分取决于所选动作。这增加了控制的不确定性。
运行第 4 步中的代码后,您将看到一个 4 * 4 的矩阵,如下所示,代表冰冻的湖面和代理所在的瓦片(状态 0):
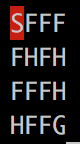
运行第 5 步中的代码行后,您将看到生成的网格如下,其中代理向下移动到状态 4:

如果满足以下两个条件之一,情节将终止:
移动到 H 瓦片(状态 5、7、11、12)。这将产生 0 的总奖励。移动到 G 磁贴(状态 15)。这将产生 +1 的总奖励。
还有更多...
我们可以使用 P 属性查看 FrozenLake 环境的细节,包括转换矩阵和每个状态和动作的奖励。例如,对于状态 6,我们可以执行以下操作:
>>> print(env.env.P[6]){0: [(0.3333333333333333, 2, 0.0, False), (0.3333333333333333, 5, 0.0, True), (0.3333333333333333, 10, 0.0, False)], 1: [(0.3333333333333333, 5, 0.0, True), (0.3333333333333333, 10, 0.0, False), (0.3333333333333333, 7, 0.0, True)], 2: [(0.3333333333333333, 10, 0.0, False), (0.3333333333333333, 7, 0.0, True), (0.3333333333333333, 2, 0.0, False)], 3: [(0.3333333333333333, 7, 0.0, True), (0.3333333333333333, 2, 0.0, False), (0.3333333333333333, 5, 0.0, True)]}这将返回一个包含键 0、1、2 和 3 的字典,代表四种可能的操作。该值是采取行动后的运动列表。移动列表采用以下格式:(转换概率,新状态,收到的奖励,完成)。例如,如果智能体位于状态 6 并打算采取行动 1(向下),则它有 33.33% 的机会进入状态 5,获得奖励 0 并终止情节;它有 33.33% 的机会进入状态 10 并获得 0 的奖励;并且它有 33.33% 的几率会进入状态 7,获得奖励 0 并终止情节。
对于状态 11,我们可以执行以下操作:
>>> print(env.env.P[11]){0: [(1.0, 11, 0, True)], 1: [(1.0, 11, 0, True)], 2: [(1.0, 11, 0, True)], 3: [(1.0, 11, 0, True)]}由于踩到一个洞会终止一集,因此之后它不会有任何动作。
随时查看其他州。
使用值迭代算法求解 MDP
如果找到最优策略,则认为 MDP 已解决。在这个秘籍中,我们将使用值迭代算法找出 FrozenLake 环境的最优策略。
价值迭代背后的思想与政策评估非常相似。它也是一种迭代算法。它从任意策略值开始,然后根据贝尔曼最优方程迭代更新这些值,直到它们收敛。因此,在每次迭代中,它不会选择所有动作的期望值(平均值),而是选择实现最大策略值的动作:
这里,V*(s)表示最优值,即最优策略的值;T(s, a, s') 是采取动作 a 从状态 s 到状态 s' 的转移概率;R(s, a) 是在状态 s 采取行动 a 时获得的奖励。
一旦计算出最优值,我们就可以很容易地得到相应的最优策略:
![]()
怎么做...
让我们使用值迭代算法解决 FrozenLake 环境,如下所示:
1.我们导入必要的库并创建 FrozenLake 环境的实例:
>>> import torch>>> import gym>>> env = gym.make('FrozenLake-v0')2.现在设置0.99为折扣因子,并设置0.0001为收敛阈值:
>>> gamma = 0.99>>> threshold = 0.00013.现在定义根据值迭代算法计算最优值的函数:
>>> def value_iteration(env, gamma, threshold):... """... 用值迭代算法求解给定环境... @param env: OpenAI Gym 环境... @param gamma: 折扣因子... @param threshold:一旦所有状态的值都小于阈值,评估将停止 ... @return:给定环境的最佳策略值... """... n_state = env.observation_space.n... n_action = env.action_space.n... V = torch.zeros(n_state)... while True:... V_temp = torch.empty(n_state)... for state in range(n_state):... v_actions = torch.zeros(n_action)... for action in range(n_action):... for trans_prob, new_state, reward, _ in env.env.P[state][action]:... v_actions[action] += trans_prob * (reward + gamma * V[new_state])... V_temp[state] = torch.max(v_actions)... max_delta = torch.max(torch.abs(V - V_temp))... V = V_temp.clone()... if max_delta <= threshold:... break... return V4.插入环境、折扣因子和收敛阈值,然后打印最优值:
>>> V_optimal = value_iteration(env, gamma, threshold)>>> print('Optimal values:\n{}'.format(V_optimal))Optimal values:tensor([0.5404, 0.4966, 0.4681, 0.4541, 0.5569, 0.0000, 0.3572, 0.0000, 0.5905, 0.6421, 0.6144, 0.0000, 0.0000, 0.7410, 0.8625, 0.0000])5.现在我们有了最优值,我们开发了从中提取最优策略的函数:
>>> def extract_optimal_policy(env, V_optimal, gamma):... """... 根据最优值获取最优策略... @param env: OpenAI Gym 环境... @param V_optimal: 最优值... @param gamma: 折扣因子... @return: 最优策略... """... n_state = env.observation_space.n... n_action = env.action_space.n... optimal_policy = torch.zeros(n_state)... for state in range(n_state):... v_actions = torch.zeros(n_action)... for action in range(n_action):... for trans_prob, new_state, reward, _ in env.env.P[state][action]:... v_actions[action] += trans_prob * (reward + gamma * V_optimal[new_state])... optimal_policy[state] = torch.argmax(v_actions)... return optimal_policy6.插入环境、折扣因子和最优值,然后打印最优策略:
>>> optimal_policy = extract_optimal_policy(env, V_optimal, gamma)>>> print('Optimal policy:\n{}'.format(optimal_policy))Optimal policy:tensor([0., 3., 3., 3., 0., 3., 2., 3., 3., 1., 0., 3., 3., 2., 1., 3.])7.我们想衡量最优策略的好坏。因此,让我们使用最优策略运行 1,000 集并检查平均奖励。在这里,我们将重用run_episode我们在上一节中定义的函数:
>>> n_episode = 1000>>> total_rewards = []>>> for episode in range(n_episode):... total_reward = run_episode(env, optimal_policy)... total_rewards.append(total_reward)>>> print('Average total reward under the optimal policy: {}'.format(sum(total_rewards) / n_episode))Average total reward under the optimal policy: 0.75在最优策略下,智能体平均有 75% 的时间达到目标。这是我们能得到的最好的,因为冰很滑。
这个怎么运作...
在价值迭代算法中,我们通过迭代应用贝尔曼最优方程得到最优价值函数。
以下是贝尔曼最优方程的另一个版本,它可以处理奖励部分依赖于新状态的环境:
这里,R(s, a, s') 是通过采取行动 a 从状态 s 移动到状态 s' 所获得的奖励。由于这个版本的兼容性比较好,所以我们value_iteration根据它开发了我们的功能。正如您在步骤 3中看到的,我们执行以下任务:
将策略值初始化为全零。根据 Bellman 最优方程更新值。计算所有状态下值的最大变化。如果最大变化大于阈值,我们会不断更新这些值。否则,我们终止评估过程并将最新值作为最优值返回。还有更多...
我们以 0.99 的折扣系数获得了 75% 的成功率。折扣因子如何影响性能?让我们用不同的因素做一些实验,包括0、0.2、0.4、0.6、0.8、0.99和1.:
>>> gammas = [0, 0.2, 0.4, 0.6, 0.8, .99, 1.]对于每个折扣因子,我们计算超过 10,000 集的平均成功率:
>>> avg_reward_gamma = []>>> for gamma in gammas:... V_optimal = value_iteration(env, gamma, threshold)... optimal_policy = extract_optimal_policy(env, V_optimal, gamma)... total_rewards = []... for episode in range(n_episode):... total_reward = run_episode(env, optimal_policy)... total_rewards.append(total_reward)... avg_reward_gamma.append(sum(total_rewards) / n_episode)我们绘制了平均成功率与折扣因子的关系图:
>>> import matplotlib.pyplot as plt>>> plt.plot(gammas, avg_reward_gamma)>>> plt.title('Success rate vs discount factor')>>> plt.xlabel('Discount factor')>>> plt.ylabel('Average success rate')>>> plt.show()我们得到以下情节:
结果表明,当折扣因子增加时,性能会提高。这验证了一个事实,即小的折扣因子重视现在的奖励,大的折扣因子重视未来更好的奖励。
使用策略迭代算法解决 MDP
解决 MDP 的另一种方法是使用策略迭代算法,我们将在本节中讨论。
策略迭代算法可以细分为两个部分:策略评估和策略改进。它从一个任意的政策开始。在每次迭代中,它首先根据贝尔曼期望方程计算给定最新策略的策略值;然后,它根据贝尔曼最优方程从生成的策略值中提取改进的策略。它迭代地评估策略并生成改进版本,直到策略不再更改为止。
让我们开发一个策略迭代算法并用它来解决 FrozenLake 环境。之后,我们将解释它是如何工作的。
怎么做...
让我们使用策略迭代算法解决 FrozenLake 环境,如下所示:
1.我们导入必要的库并创建 FrozenLake 环境的实例:
>>> import torch>>> import gym>>> env = gym.make('FrozenLake-v0')2.现在设置0.99为折扣因子,并设置0.0001为收敛阈值:
>>> gamma = 0.99>>> threshold = 0.00013.现在我们定义policy_evaluation函数来计算给定策略的值:
>>> def policy_evaluation(env, policy, gamma, threshold):... """... 执行策略评估... @param env: OpenAI Gym 环境... @param policy: 包含动作及其动作的策略矩阵每个状态的概率... @param gamma:折扣因子... @param threshold:一旦所有状态的值都小于阈值,评估将停止... @return:给定策略的值... """... n_state = policy.shape[0]... V = torch.zeros(n_state)... while True:... V_temp = torch.zeros(n_state)... for state in range(n_state):... action = policy[state].item()... for trans_prob, new_state, reward, _ in env.env.P[state][action]:... V_temp[state] += trans_prob * (reward + gamma * V[new_state])... max_delta = torch.max(torch.abs(V - V_temp))... V = V_temp.clone()... if max_delta <= threshold:... break... return V这与我们在执行策略评估秘籍中所做的类似,但使用 Gym 环境作为输入。
4.接下来,我们开发策略迭代算法的第二个主要组成部分,即策略改进部分:
>>> def policy_improvement(env, V, gamma):... """... 根据值获取改进的策略... @param env: OpenAI Gym 环境... @param V: 策略值... @param gamma: 折扣因子... @return: 政策... """... n_state = env.observation_space.n... n_action = env.action_space.n... policy = torch.zeros(n_state)... for state in range(n_state):... v_actions = torch.zeros(n_action)... for action in range(n_action):... for trans_prob, new_state, reward, _ in env.env.P[state][action]:... v_actions[action] += trans_prob * (reward + gamma * V[new_state])... policy[state] = torch.argmax(v_actions)... return policy这会根据 Bellman 最优方程从给定的策略值中提取改进的策略。
5.现在我们已经准备好两个组件,我们开发策略迭代算法如下:
>>> def policy_iteration(env, gamma, threshold):... """... 使用策略迭代算法解决给定环境... @param env: OpenAI Gym environment ... @param gamma: discount factor ... @param threshold:一旦所有状态的值都小于阈值,评估将停止... @return:给定环境的最佳值和最佳策略... """... n_state = env.observation_space.n... n_action = env.action_space.n... policy = torch.randint(high=n_action, size=(n_state,)).float()... while True:... V = policy_evaluation(env, policy, gamma, threshold)... policy_improved = policy_improvement(env, V, gamma)... if torch.equal(policy_improved, policy):... return V, policy_improved... policy = policy_improved6.插入环境、折扣因子和收敛阈值:
>>> V_optimal, optimal_policy = policy_iteration(env, gamma, threshold)7.我们已经获得了最优值和最优策略。让我们来看看它们:
>>> print('Optimal values:\n{}'.format(V_optimal))Optimal values:tensor([0.5404, 0.4966, 0.4681, 0.4541, 0.5569, 0.0000, 0.3572, 0.0000, 0.5905, 0.6421, 0.6144, 0.0000, 0.0000, 0.7410, 0.8625, 0.0000])>>> print('Optimal policy:\n{}'.format(optimal_policy))Optimal policy:tensor([0., 3., 3., 3., 0., 3., 2., 3., 3., 1., 0., 3., 3., 2., 1., 3.])它们与我们使用值迭代算法得到的完全相同。
这个怎么运作...
策略迭代在每次迭代中结合了策略评估和策略改进。在策略评估中,给定策略(不是最优策略)的值是根据贝尔曼期望方程计算的,直到它们收敛:

这里,a = π(s),这是在状态 s 下在策略 π 下采取的动作。
在策略改进中,根据贝尔曼最优方程,使用生成的收敛策略值 V(s) 更新策略:
这将重复政策评估和政策改进步骤,直到政策收敛。在收敛时,最新的策略及其价值函数是最优策略和最优价值函数。因此,在第 5 步中,该policy_iteration函数执行以下任务:
初始化随机策略。使用策略评估算法计算策略的值。根据策略值获得改进的策略。如果新策略与旧策略不同,它会更新策略并运行另一次迭代。否则,它终止迭代过程并返回策略值和策略。还有更多...
我们刚刚使用策略迭代算法解决了 FrozenLake 环境。因此,您可能想知道什么时候使用策略迭代比值迭代更好,反之亦然。基本上在三种情况下,一种情况比另一种情况具有优势:
如果有大量的动作,使用策略迭代,因为它可以更快地收敛。如果动作数量少,就用值迭代。如果已经存在可行的策略(通过直觉或领域知识获得),请使用策略迭代。在这些场景之外,策略迭代和价值迭代通常是可比较的。
在下一个秘籍中,我们将应用每种算法来解决抛硬币赌博问题。我们将看到哪种算法收敛得更快。
还有更多...
我们刚刚使用策略迭代算法解决了 FrozenLake 环境。因此,您可能想知道什么时候使用策略迭代比值迭代更好,反之亦然。基本上在三种情况下,一种情况比另一种情况具有优势:
如果有大量的动作,使用策略迭代,因为它可以更快地收敛。如果动作数量少,就用值迭代。如果已经存在可行的策略(通过直觉或领域知识获得),请使用策略迭代。在这些场景之外,策略迭代和价值迭代通常是可比较的。
在下一个秘籍中,我们将应用每种算法来解决抛硬币赌博问题。我们将看到哪种算法收敛得更快。
也可以看看
随意使用我们在这两个食谱中学到的知识来解决更大的冰网格FrozenLake8x8-v0环境(https://gym.openai.com/envs/FrozenLake8x8-v0/)。
解决抛硬币赌博问题
掷硬币赌博对每个人来说都应该很熟悉。在每一轮游戏中,赌徒都可以押注抛硬币是否会出现正面。如果结果是正面朝上,则赌徒将赢得与他们下注相同的金额;否则,他们将损失这笔钱。游戏一直持续到赌徒输了(一无所获)或赢了(比方说赢了 100 多美元)。假设硬币是不公平的,正面朝上的概率为 40%。为了使获胜的机会最大化,赌徒在每一轮中根据自己的现有本金应该下注多少?这绝对是一个需要解决的有趣问题。
如果硬币正面朝上的概率超过 50%,则没有什么可讨论的。赌徒可以每轮继续下注 1 美元,大多数时候应该会赢。如果它是一枚公平的硬币,赌徒可以每轮下注一美元,最终赢钱的概率大约为 50%。当正面朝上的概率低于 50% 时,它会变得棘手;安全投注策略将不再有效。随机策略也不会。我们需要借助我们在本章中学到的强化学习技术来做出明智的选择。
让我们开始将抛硬币赌博问题表述为 MDP。它基本上是一个无折扣的、偶发的、有限的 MDP,具有以下属性:
国家是赌徒的美元资本。有 101 种状态:0、1、2、...、98、99 和 100+。达到状态100+则奖励为1;否则,奖励为 0。行动是赌徒在一轮中可能下注的金额。给定状态 s,可能的操作包括 1、2、... 和 min(s, 100 - s)。例如,当赌徒有 60 美元时,他们可以下注 1 到 40 之间的任何金额。任何超过 40 的金额都没有任何意义,因为它会增加损失并且不会增加获胜的机会。采取行动后的下一个状态取决于硬币正面朝上的概率。假设它是 40%。所以,状态s在采取action a之后的下一个状态就是s+a 40%,sa 60%。该过程在状态 0 和状态 100+ 处终止。怎么做...
我们首先通过使用值迭代算法并执行以下步骤来解决抛硬币赌博问题:
1.导入 PyTorch:
>>> import torch2.指定折扣因子和收敛阈值:
>>> gamma = 1>>> threshold = 1e-10在这里,我们将 1 作为折扣因子,因为 MDP 是一个未折扣的过程;我们设置了一个小的阈值,因为我们期望小的策略值,因为除了最后一个状态之外所有的奖励都是 0。
3.定义以下环境变量。
一共有101个州:
>>> capital_max = 100>>> n_state = capital_max + 1相应奖励显示如下:
>>> rewards = torch.zeros(n_state)>>> rewards[-1] = 1>>> print(rewards)tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.])假设正面朝上的概率是 40%:
>>> head_prob = 0.4将这些变量放入字典中:
>>> env = {'capital_max': capital_max,... 'head_prob': head_prob,... 'rewards': rewards,... 'n_state': n_state}4.现在我们开发一个基于值迭代算法计算最优值的函数:
>>> def value_iteration(env, gamma, threshold):... """... Solve the coin flipping gamble problem with value iteration algorithm... @param env: the coin flipping gamble environment... @param gamma: discount factor... @param threshold: the evaluation will stop once values for all states are less than the threshold... @return: values of the optimal policy for the given environment... """... head_prob = env['head_prob']... n_state = env['n_state']... capital_max = env['capital_max']... V = torch.zeros(n_state)... while True:... V_temp = torch.zeros(n_state)... for state in range(1, capital_max):... v_actions = torch.zeros( min(state, capital_max - state) + 1)... for action in range( 1, min(state, capital_max - state) + 1):... v_actions[action] += head_prob * ( rewards[state + action] + gamma * V[state + action])... v_actions[action] += (1 - head_prob) * ( rewards[state - action] + gamma * V[state - action])... V_temp[state] = torch.max(v_actions)... max_delta = torch.max(torch.abs(V - V_temp))... V = V_temp.clone()... if max_delta <= threshold:... break... return V我们只需要计算状态 1 到 99 的值,因为状态 0 和状态 100+ 的值都是 0。并且给定状态s,可能的操作可以是从 1 到min(s, 100 - s) 的任何值。在计算贝尔曼最优方程时,我们应该牢记这一点。
5.接下来,我们开发一个函数,根据最优值提取最优策略:
>>> def extract_optimal_policy(env, V_optimal, gamma):... """... Obtain the optimal policy based on the optimal values... @param env: the coin flipping gamble environment... @param V_optimal: optimal values... @param gamma: discount factor... @return: optimal policy... """... head_prob = env['head_prob']... n_state = env['n_state']... capital_max = env['capital_max']... optimal_policy = torch.zeros(capital_max).int()... for state in range(1, capital_max):... v_actions = torch.zeros(n_state)... for action in range(1, min(state, capital_max - state) + 1):... v_actions[action] += head_prob * ( rewards[state + action] + gamma * V_optimal[state + action])... v_actions[action] += (1 - head_prob) * ( rewards[state - action] + gamma * V_optimal[state - action])... optimal_policy[state] = torch.argmax(v_actions)... return optimal_policy6.最后,我们可以插入环境、折扣因子和收敛阈值来计算 之后的最优值和最优策略。此外,我们计算用价值迭代解决赌博 MDP 需要多长时间;我们将把它与策略迭代完成所需的时间进行比较:
>>> import time>>> start_time = time.time()>>> V_optimal = value_iteration(env, gamma, threshold)>>> optimal_policy = extract_optimal_policy(env, V_optimal, gamma)>>> print("It takes {:.3f}s to solve with value iteration".format(time.time() - start_time))It takes 4.717s to solve with value iteration4.717我们在几秒钟内解决了价值迭代的赌博问题。
7.看一下最优策略值和我们得到的最优策略:
>>> print('Optimal values:\n{}'.format(V_optimal))>>> print('Optimal policy:\n{}'.format(optimal_policy))8.我们可以绘制政策价值与状态如下:
>>> import matplotlib.pyplot as plt>>> plt.plot(V_optimal[:100].numpy())>>> plt.title('Optimal policy values')>>> plt.xlabel('Capital')>>> plt.ylabel('Policy value')>>> plt.show()既然我们已经用价值迭代解决了赌博问题,那么策略迭代呢?让我们来看看。
9.我们首先开发policy_evaluation计算给定策略值的函数:
>>> def policy_evaluation(env, policy, gamma, threshold):... """... Perform policy evaluation... @param env: the coin flipping gamble environment... @param policy: policy tensor containing actions taken for individual state... @param gamma: discount factor... @param threshold: the evaluation will stop once values for all states are less than the threshold... @return: values of the given policy... """... head_prob = env['head_prob']... n_state = env['n_state']... capital_max = env['capital_max']... V = torch.zeros(n_state)... while True:... V_temp = torch.zeros(n_state)... for state in range(1, capital_max):... action = policy[state].item()... V_temp[state] += head_prob * ( rewards[state + action] + gamma * V[state + action])... V_temp[state] += (1 - head_prob) * ( rewards[state - action] + gamma * V[state - action])... max_delta = torch.max(torch.abs(V - V_temp))... V = V_temp.clone()... if max_delta <= threshold:... break... return V10.接下来,我们开发策略迭代算法的另一个主要组成部分,即策略改进部分:
>>> def policy_improvement(env, V, gamma):... """... Obtain an improved policy based on the values... @param env: the coin flipping gamble environment... @param V: policy values... @param gamma: discount factor... @return: the policy... """... head_prob = env['head_prob']... n_state = env['n_state']... capital_max = env['capital_max']... policy = torch.zeros(n_state).int()... for state in range(1, capital_max):... v_actions = torch.zeros( min(state, capital_max - state) + 1)... for action in range( 1, min(state, capital_max - state) + 1):... v_actions[action] += head_prob * ( rewards[state + action] + gamma * V[state + action])... v_actions[action] += (1 - head_prob) * ( rewards[state - action] + gamma * V[state - action])... policy[state] = torch.argmax(v_actions)... return policy11.准备好两个组件后,我们可以开发策略迭代算法的主要入口,如下所示:
>>> def policy_iteration(env, gamma, threshold):... """... Solve the coin flipping gamble problem with policy iteration algorithm... @param env: the coin flipping gamble environment... @param gamma: discount factor... @param threshold: the evaluation will stop once values for all states are less than the threshold... @return: optimal values and the optimal policy for the given environment... """... n_state = env['n_state']... policy = torch.zeros(n_state).int()... while True:... V = policy_evaluation(env, policy, gamma, threshold)... policy_improved = policy_improvement(env, V, gamma)... if torch.equal(policy_improved, policy):... return V, policy_improved... policy = policy_improved12.最后,我们插入环境、折扣因子和收敛阈值来计算最优值和最优策略。我们还记录了解决 MDP 所花费的时间:
>>> start_time = time.time()>>> V_optimal, optimal_policy = policy_iteration(env, gamma, threshold)>>> print("It takes {:.3f}s to solve with policy iteration".format(time.time() - start_time))It takes 2.002s to solve with policy iteration13.查看我们刚刚获得的最优值和最优策略:
>>> print('Optimal values:\n{}'.format(V_optimal))>>> print('Optimal policy:\n{}'.format(optimal_policy))这个怎么运作...
执行第 7 步中的代码行后,您将看到最优策略值:
Optimal values: tensor([0.0000, 0.0021, 0.0052, 0.0092, 0.0129, 0.0174, 0.0231, 0.0278, 0.0323, 0.0377, 0.0435, 0.0504, 0.0577, 0.0652, 0.0695, 0.0744, 0.0807, 0.0866, 0.0942, 0.1031, 0.1087, 0.1160, 0.1259,0.1336,0.1441,0.1600,0.1631,0.1677,0.1738,0.1794,0.1794,0.1861,0.1946,0.1946,0.2017,0.2084,0.2165,0.2165 _ _ _ 0.3488, 0.3604, 0.3762, 0.4000, 0.4031, 0.4077, 0.4138, 0.4194, 0.4261, 0.4346, 0.4417, 0.4484, 0.4565, 0.4652, 0.4755, 0.4865, 0.4979, 0.5043, 0.5116, 0.5210 , 0.5299, 0.5413, 0.5547, 0.5630, 0.5740, 0.5888, 0.6004, 0.6162, 0.6400, 0.6446, 0.6516, 0.6608, 0.6690, 0.6791, 0.6919, 0.7026, 0.7126, 0.7248, 0.7378, 0.7533, 0.7697, 0.7868, 0.7965, 0.8075, 0.8215, 0.8349, 0.8520, 0.8721, 0.8845, 0.9009, 0.9232, 0.9406, 0.9643, 0.0000])您还将看到最优策略:
Optimal policy:tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 22, 29, 30, 31, 32, 33, 9, 35, 36, 37, 38, 11, 40, 9, 42, 43, 44, 5, 4, 3, 2, 1, 50, 1, 2, 47, 4, 5, 44, 7, 8, 9, 10, 11, 38, 12, 36, 35, 34, 17, 32, 19, 30, 4, 3, 2, 26, 25, 24, 23, 22, 21, 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1], dtype=torch.int32)第 8 步为最优策略值生成以下图:
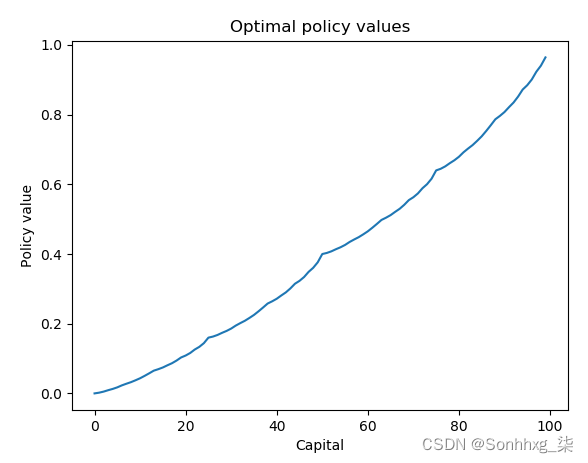
我们可以看到,随着资本(状态)的增加,估计的奖励(政策价值)也会增加,这是有道理的。
我们在第 9 步中所做的与我们在使用策略迭代算法解决 MDP配方中所做的非常相似,但这次是针对抛硬币赌博环境。
在步骤 10中,策略改进函数根据贝尔曼最优方程从给定的策略值中提取改进的策略。
正如您在第 12 步中看到的那样,我们在几秒钟内解决了策略迭代的赌博问题2.002,这比值迭代所用时间的一半还少。
我们从步骤 13得到的结果包括以下最优值:
Optimal values: tensor([0.0000, 0.0021, 0.0052, 0.0092, 0.0129, 0.0174, 0.0231, 0.0278, 0.0323, 0.0377, 0.0435, 0.0504, 0.0577, 0.0652, 0.0695, 0.0744, 0.0807, 0.0866, 0.0942, 0.1031, 0.1087, 0.1160, 0.1259,0.1336,0.1441,0.1600,0.1631,0.1677,0.1738,0.1794,0.1794,0.1861,0.1946,0.1946,0.2017,0.2084,0.2165,0.2165 _ _ _ 0.3488, 0.3604, 0.3762, 0.4000, 0.4031, 0.4077, 0.4138, 0.4194, 0.4261, 0.4346, 0.4417, 0.4484, 0.4565, 0.4652, 0.4755, 0.4865, 0.4979, 0.5043, 0.5116, 0.5210 , 0.5299, 0.5413, 0.5547, 0.5630, 0.5740, 0.5888, 0.6004, 0.6162, 0.6400, 0.6446, 0.6516, 0.6608, 0.6690, 0.6791, 0.6919, 0.7026, 0.7126, 0.7248, 0.7378, 0.7533, 0.7697, 0.7868, 0.7965, 0.8075, 0.8215, 0.8349, 0.8520, 0.8721, 0.8845, 0.9009, 0.9232, 0.9406, 0.9643, 0.0000])它们还包括最优策略:
Optimal policy:tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 22, 29, 30, 31, 32, 33, 9, 35, 36, 37, 38, 11, 40, 9, 42, 43, 44, 5, 4, 3, 2, 1, 50, 1, 2, 47, 4, 5, 44, 7, 8, 9, 10, 11, 38, 12, 36, 35, 34, 17, 32, 19, 30, 4, 3, 2, 26, 25, 24, 23, 22, 21, 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0], dtype=torch.int32)值迭代和策略迭代这两种方法的结果是一致的。
我们通过使用值迭代和策略迭代解决了赌博问题。要处理强化学习问题,最棘手的任务之一是将过程制定为 MDP。在我们的例子中,通过下注某些赌注(行动),政策从当前资本(状态)转变为新资本(新状态)。最优策略最大化赢得比赛的概率(+1奖励),评估最优策略下获胜的概率。
另一个需要注意的有趣的事情是,在我们的例子中,变换概率和新状态是如何在贝尔曼方程中确定的。在状态 s 采取行动 a(拥有资本 s 并下注 1 美元)将有两种可能的结果:
如果硬币正面朝上,则移动到新状态 s+a。因此,变换概率等于正面的概率。如果硬币反面着地,则移动到新状态 sa。因此,变换概率等于尾部概率。这与 FrozenLake 环境非常相似,在 FrozenLake 环境中,代理仅以一定的概率降落在预期的图块上。
我们还验证了在这种情况下策略迭代比值迭代收敛得更快。这是因为最多有 50 个可能的动作,这比 FrozenLake 中的 4 个动作要多。对于具有大量动作的 MDP,使用策略迭代求解比使用值迭代求解效率更高。
还有更多...
您可能想知道最优策略是否真的有效。让我们像聪明的赌徒一样,玩 10,000 集游戏。我们将把最优策略与其他两种策略进行比较:保守(每轮下注一美元)和随机(下注随机金额):
1.我们首先定义上述三种投注策略。
我们首先定义最优策略:
>>> def optimal_strategy(capital):... return optimal_policy[capital].item()然后我们定义保守策略:
>>> def conservative_strategy(capital):... return 1最后,我们定义随机策略:
>>> def random_strategy(capital):... return torch.randint(1, capital + 1, (1,)).item()2.定义一个包装函数,该函数使用策略运行一集并返回游戏是否获胜:
>>> def run_episode(head_prob, capital, policy):... while capital > 0:... bet = policy(capital)... if torch.rand(1).item() < head_prob:... capital += bet... if capital >= 100:... return 1... else:... capital -= bet... return 03.指定起始资金(比方说50美元)和剧集数 ( 10000):
>>> capital = 50>>> n_episode = 100004.行 10,000 集并跟踪获胜次数:
>>> n_win_random = 0>>> n_win_conservative = 0>>> n_win_optimal = 0>>> for episode in range(n_episode):... n_win_random += run_episode( head_prob, capital, random_strategy)... n_win_conservative += run_episode( head_prob, capital, conservative_strategy)... n_win_optimal += run_episode( head_prob, capital, optimal_strategy)5.打印出三种策略的获胜概率:
>>> print('Average winning probability under the random policy: {}'.format(n_win_random/n_episode))Average winning probability under the random policy: 0.2251>>> print('Average winning probability under the conservative policy: {}'.format(n_win_conservative/n_episode))Average winning probability under the conservative policy: 0.0>>> print('Average winning probability under the optimal policy: {}'.format(n_win_optimal/n_episode))Average winning probability under the optimal policy: 0.3947我们的最优策略显然是赢家!