
欢迎关注博主 Mindtechnist 或加入【Linux C/C++/Python社区】一起探讨和分享Linux C/C++/Python/Shell编程、机器人技术、机器学习、机器视觉、嵌入式AI相关领域的知识和技术。
人工智能与机器学习
?人工智能相关概念☞什么是人工智能、机器学习、深度学习☞人工智能发展必备的三要素☞人工智能主要分支 ?机器学习工作流程☞数据集☞数据基本处理☞特征工程☞机器学习o 监督学习o 无监督学习o 半监督学习o 强化学习 ☞模型评估o 分类模型评估o 回归模型评估o拟合
专栏:《机器学习》
?人工智能相关概念
☞什么是人工智能、机器学习、深度学习
人工智能这个概念诞生于1956年的达特茅斯会议,因此,1956年也是人工智能元年。在《Python深度学习》一书中,人工智能简洁定义为:努力将通常由人类完成的智力任务自动化。
机器学习是人工智能的一个实现途径;深度学习是机器学习的一个方法发展而来;三者的关系如下图所示: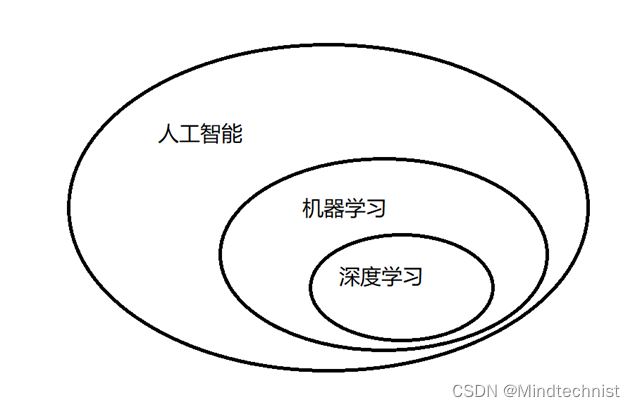
在早期计算机专家认为,只要可以在程序中写出足够多的明确规则来处理知识,就可以实现人工智能,这种方法被称为符号主义人工智能(symbolic AI)。
后来在图灵关于“计算机除了执行我们的命令外,能否自我学习执行特定任务的方法”这一问题之后,又引出了一种新的编程范式。在符号主义人工智能范式中,人们输入规则(程序)以及根据这些规则要处理的数据,系统输出问题的答案。而在机器学习中,人们输入的是数据和从这些数据中预期得到的答案,系统输出的是规则,这些规则可以应用于新的数据并由计算机自动生成答案。这就是机器学习(machine learning),机器学习系统是训练出来的,而不是直接通过程序明确写出来的,所以,机器学习与数理统计密切相关。
深度学习(deep learning)是机器学习的一个分支领域,深度学习强调从连续的层中进行学习,所谓深度是指一系列连续的表示层,数据模型包含的层数称为模型的深度,这些表示层都是通过数据训练自动学习的,通常它们是由神经网络(neural network)模型中学习得到的。我们可以这么理解,深度学习网络中的每一层都像一个过滤器,原始信息经过每一层的过滤器后纯度越来越高。神经网络中每层对输入数据所做的操作保存在当前层的权重(也称为该层的参数)中,权重的本质是一串数字,每一层实现的变换都由权重来参数化。于是,学习的意思就是指为神经网络的所有层找到一组权重值,使得神经网络能够将每个示例输入与其目标一一对应。神经网络的输出值与预期值之间的差距,由损失函数(也叫目标函数)来评价,损失函数的输入为预测值与真实目标值,然后计算出一个距离值,以此来衡量网络在这个示例上的效果好坏。深度学习则是利用这个距离值作为反馈信号来对权重值进行微调,以降低当前示例的损失值。微调的任务由优化器完成,该过程实现了反向传播算法。一开始给神经网络的权重赋予随机值,随着网络处理的示例越来越多,权重值向着正确方向一步步的调整,损失值也将逐渐降低,这个过程就是循环训练的过程。重复这个循环过程来得到使损失函数最小的权重值,而具有最小损失的网络,其输出和目标值尽可能地接近,这就是训练好的网络。(参考《Python深度学习》一书)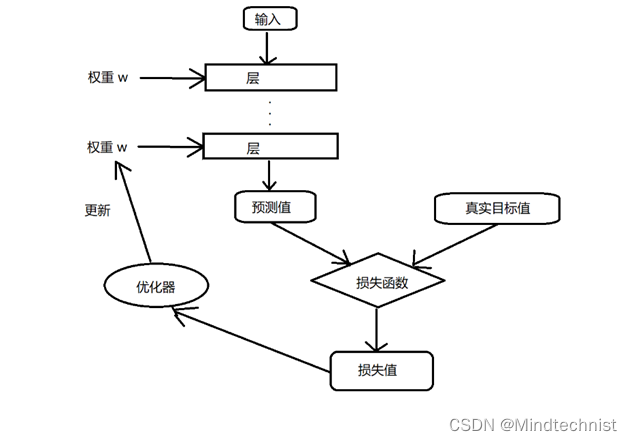
☞人工智能发展必备的三要素
数据算法计算力 CPU:中央处理器GPU:图形处理器TPU:谷歌张量处理器NPU:神经网络处理器我们一般用到的是CPU和GPU,二者的区别在于:
CPU主要适合I\O密集型的任务GPU主要适合计算密集型任务对于CPU和GPU并没有谁好谁坏之分,它们的应用场景不同,如果你需要进行大量的计算一般使用GPU,GPU就是为计算而生的;如果你需要频繁的进行IO操作,比如频繁读写文件等等,就需要使用CPU,使用GPU反而不好。
适合在GPU上运行的程序一般具有如下特征:
所谓计算密集型(Compute-intensive)的程序,就是其大部分运行时间花在了寄存器运算上,寄存器的速度和处理器的速度相当,从寄存器读写数据几乎没有延时。可以做一下对比,读内存的延迟大概是几百个时钟周期;读硬盘的速度就不说了,即便是SSD, 也实在是太慢了。易于并行的程序。
GPU其实是一种SIMD(Single Instruction Multiple Data)架构, 他有成百上千个核,每一个核在同一时间最好能做同样的事情。
☞人工智能主要分支
人工智能的主要技术领域分为计算机视觉CV、自然语言处理NLP(包含文本挖掘/分类、机器翻译和语音识别)、机器人三大领域。
计算机视觉计算机视觉(CV)是指机器感知环境的能力。这一技术类别中的经典任务有图像形成、图像处理、图像提取和图像的三维推理。物体检测和人脸识别是其比较成功的研究领域。语音识别
语音识别是指识别语音(说出的语言)并将其转换成对应文本的技术,文本转语音/TTS也是这一领域内一个类似的研究主题。语音识别现在已经应用很久了,但是类似于鸡尾酒效应、声纹识别等问题还亟待解决。文本挖掘/分类
这里的文本挖掘主要是指文本分类,该技术可用于理解、组织和分类结构化或非结构化文本文档。其涵盖的主要任务有句法分析、情绪分析和垃圾信息检测。机器翻译
机器翻译(MT)是利用机器自动将一种自然语言(源语言)的文本翻译成另一种语言(目标语言)。机器人
机器人学(Robotics)研究的是机器人的设计、制造、运作和应用,以及控制它们的计算机系统、传感反馈和信息处理。机器人可以分成两大类:固定机器人和移动机器人。固定机器人通常被用于工业生产(比如用于装配线)。常见的移动机器人应用有货运机器人、空中机器人和自动载具。机器人需要不同部件和系统的协作才能实现最优的作业。其中在硬件上包含传感器、反应器和控制器;另外还有能够实现感知能力的软件,比如定位、地图测绘和目标识别。
?机器学习工作流程
我们已经知道,机器学习就是从数据中自动分析模型,并利用模型对位置数据进行预测。
机器学习工作流程总结
☞数据集
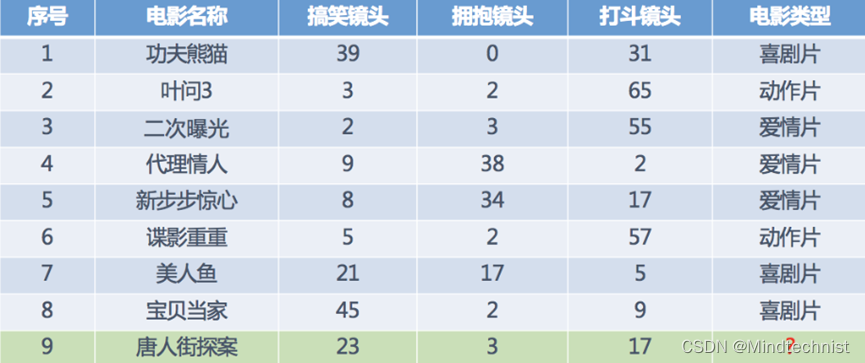

在数据集中:
数据类型构成:
特征值+目标值(目标值是连续的和离散的)。比如上面的电影图标,在电影图表中,目标值即电影类型有喜剧、动作、爱情,每个类型都是一个离散的点,此时称目标值是离散的;如果目标值是房价,房价的数值可以是连续的,从1万-10万每平方米,这就称目标值是连续的。只有特征值,没有目标值。比如上面的人物图表。数据分割:
机器学习一般的数据集会划分为两个部分: 训练数据:用于训练,构建模型。测试数据:在模型检验时使用,用于评估模型是否有效。 常用的划分比例: 训练集:70% 80% 75%测试集:30% 20% 25%☞数据基本处理
处理数据集中的缺失值和异常值。
☞特征工程
特征工程(Feature Engineering)是指使用专业背景知识和技巧去处理数据,使得特征能够在机器学习算法上发挥更好的作用,特征工程直接影响着机器学习的效果。数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
特征工程主要包含三个内容:
将数据(比如文本或图像)转换成可用于机器学习的数字特征(比如二进制数据)。特征预处理
通过一系列函数变换,将特征数据转换成更适合算法模型的特征数据的过程。特征降维
在某些特定条件下,降低随机变量(特征)的个数,得到一组不相关主变量的过程。比如将三维立体的地球转换为二维的地图。
☞机器学习
根据数据集的组成,可以把机器学习算法分为监督学习、无监督学习、半监督学习和强化学习几类。
o 监督学习
监督学习是指输入数据是由输入特征值和目标值所组成的,在监督学习中,根据函数的输出不同可以分为两类:
函数输出连续的值,称为回归;函数输出有限个离散值,称为分类;回归问题
比如说房价预测,我们根据数据样本集可以拟合出一条连续曲线,这就是回归问题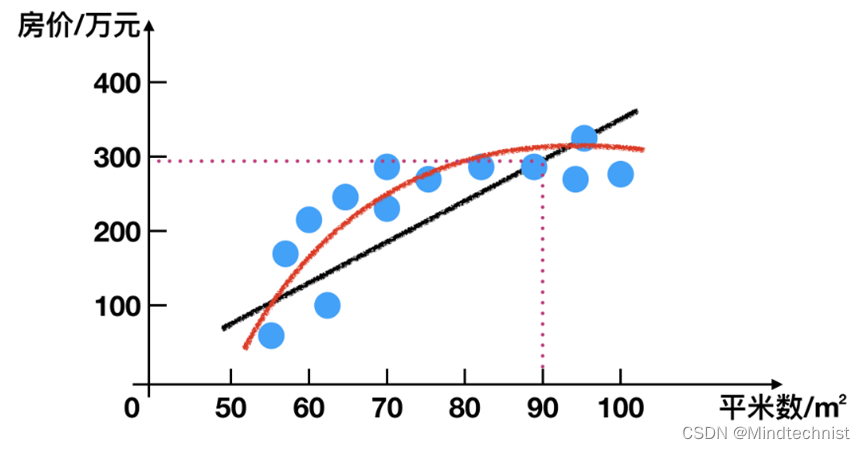
分类问题
比如说我们判断一个形状是矩形还是圆形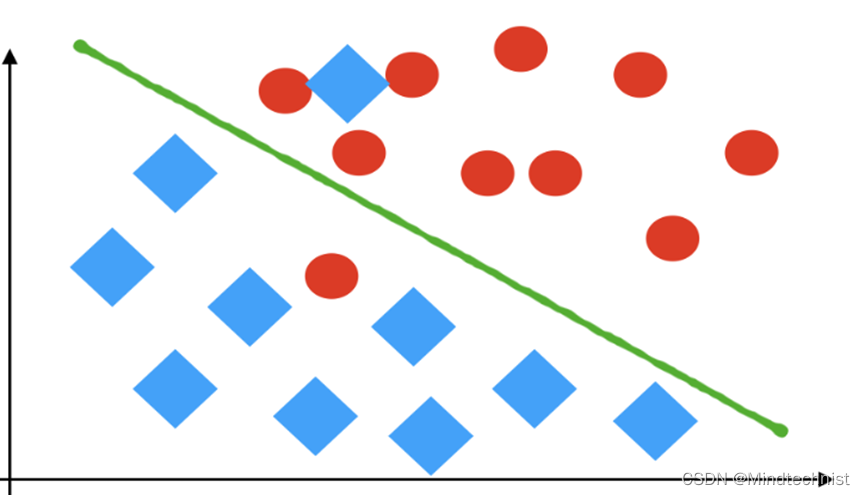
监督学习的方法及特点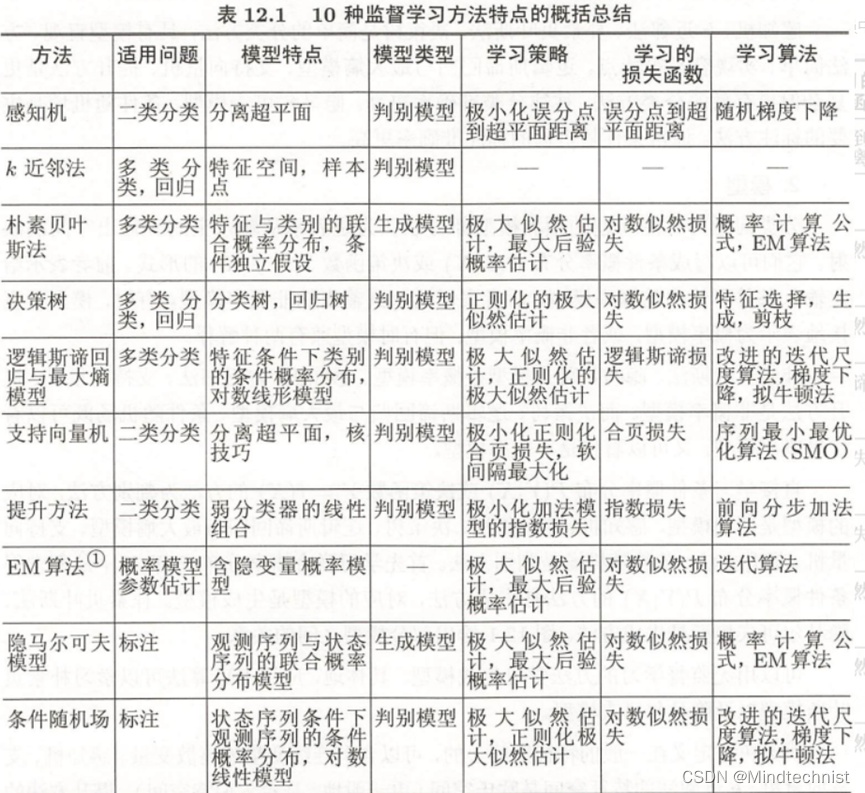
o 无监督学习
无监督学习是指,输入数据是由输入特征值组成,没有目标值。输入数据没有被标记,也没有确定的结果,样本数据类别未知,需要根据样本间的相似性对样本集进行类别划分。比如下图对人物进行分类。
无监督学习方法及特点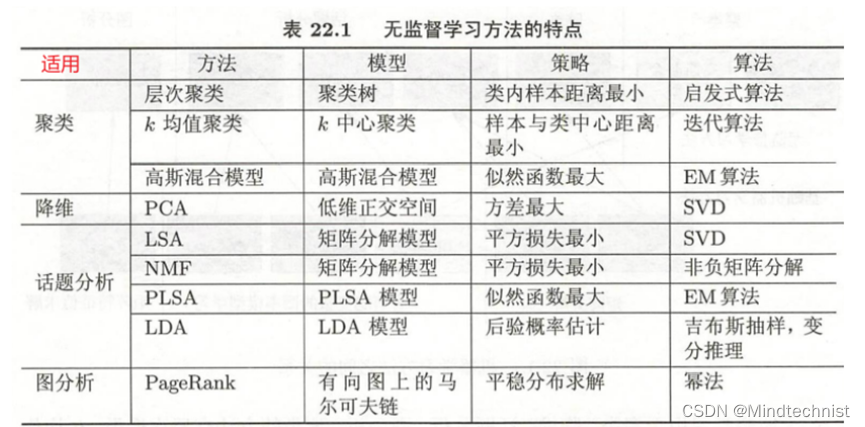
监督学习和无监督学习对比如下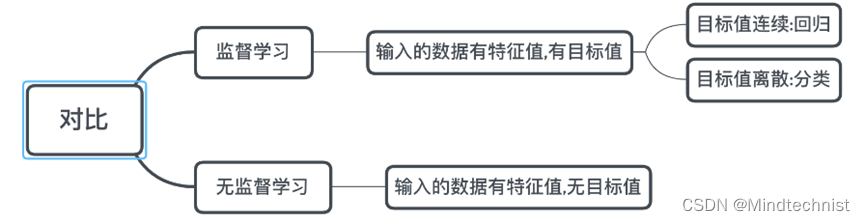
o 半监督学习
半监督学习是指,训练集同时包含有样本数据和未标记样本数据。
o 强化学习
强化学习是指智能系统在与环境的连续交互中学习最佳行为策略的机器学习问题。强化学习主要包含五个元素:agent, action, reward, environment, observation。强化学习的目标就是获得累计最多的奖励。
☞模型评估
模型评估是模型开发过程不可或缺的一部分。它有助于发现表达数据的最佳模型和所选模型将来工作的性能如何。按照数据集的目标值不同,可以把模型评估分为分类模型评估和回归模型评估。
o 分类模型评估
比如前面判断图形是圆形还是矩形(离散的)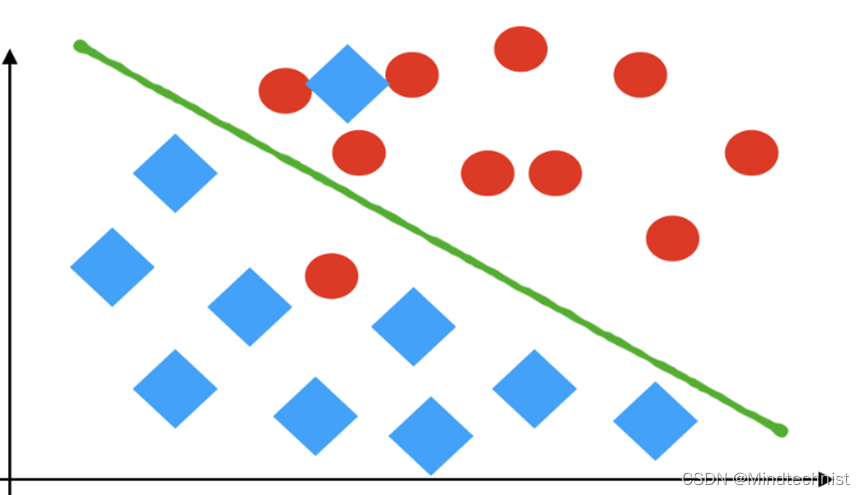
其评价指标包括:准确率、精确率、召回率、F1-score、AUC指标等。
o 回归模型评估
比如前面的房价预测(连续的)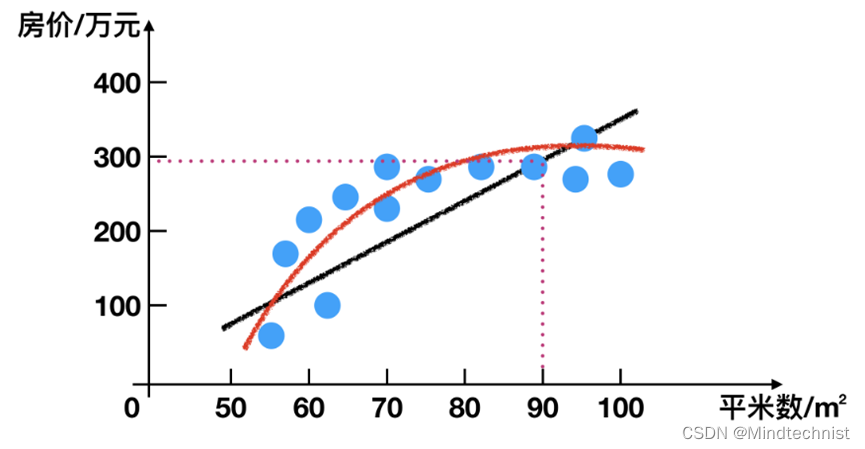
评价指标包括:均方根误差(Root Mean Squared Error,RMSE)、相对平方误差(Relative Squared Error,RSE)、平均绝对误差(Mean Absolute Error,MAE)、相对绝对误差(Relative Absolute Error,RAE)
o拟合
模型评估是用来评价训练好的模型的表现效果的,从表现效果来看,大致可以分为两类:过拟合和欠拟合。
欠拟合(under-fitting):模型学习太过粗糙,连训练集中的样本数据特征关系都没有学出来。比如说,识别猫科动物,机器学习学到的特征包括四条腿、会撒娇,实际上狗也有四条腿,也会撒娇,这就导致机器可能把狗也误认为猫科动物。过拟合(over-fitting):所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在测试数据集中表现不佳。比如说,机器学习时使用的都是黄色的老虎、橘猫、黄色的狮子,这时候机器学习到的特征就包含了一个颜色特征:黄色。但是白色的老虎或者黑猫可能被机器识别为非猫科动物。
