关于计划的制定
FlowUs计划链接:
点击我进入计划
发现不足:首先,制定计划经验不足,制定计划应该是具体的、有任务量、完成时间。
其次任务应该是可衡量的(比如,我阅读李升波老师的网站文章,应该以读书报告和实验作为衡量标准)。
还有重要的是计划应该是可执行可完成的,本周制定计划时大而无象,强化学习的学习之路尚不明确,应该从教材、博客、论文的阅读起步,不应该因为畏惧而拖延,因完不成感到挫败。
计划也应该和其他计划具有相关性,比如强化学习的原理了解是理解和运用强化学习算法的基础,短期的end target是能够顺利完成毕业设计。
计划也要应该有外束力和Deadline,这是利用心理上的一种局促感提高效率。
tips:如何制定一个好的计划
强化学习原理基础
链接为深度强化学习必读文献
参考教材:Sutton老爷子的经典书目
参考视频 李宏毅 强化学习
李宏毅强化学习课程一共11p
点击进入:清华李升波老师的教学网站

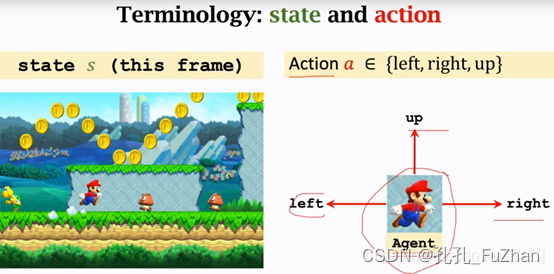
State and action
State可以理解成状态(环境状态),当我们在玩超级玛丽我们可以认为当前的状态就是下图中,超级玛丽游戏的画面,当然这样说不太严谨,我们观测的observation和state未必是相同的东西,为了方便我们理解,我们认为这张图片就是当前的状态,我们玩超级玛丽的时候观测到屏幕上的状态,就可以操纵马里奥做出相应的动作,马里奥做的动作就是action,假设马里奥会做三个动作,向左走、向右走和向上跳,这个例子里面马里奥就是agent,如果在自动驾驶的领域中汽车就是agent,总之在一个应用里面动作是谁做的谁就是agent,agent通常被翻译为智能体。
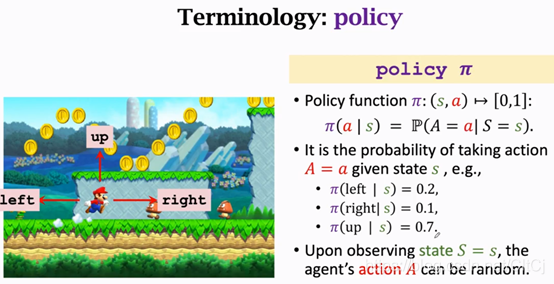
Policy
我们观测到屏幕上这个画面的时候,你该让马里奥做什么样的action呢,是往上还是左还是右,policy的意思就是根据观测到的状态来进行决策,来控制agent运动。
在数学上policy函数π是这样定义的,这个policy函数π是个概率密度函数:
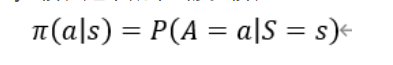 这个公式的意思就是给定状态s做出动作a的概率密度。
这个公式的意思就是给定状态s做出动作a的概率密度。
观测到马里奥这张图片agent(马里奥)会做出三种动作中的一种,把这张图片输入到policy函数π它会告诉我向左的概率为0.2,向右的概率为0.1,向上跳的概率为0.7。如果你让这个policy函数自动操作它就会做一个随机抽样,以0.2的概率向左走,0.1的概率向右走,0.2的概率向上跳,三种动作都有可能发生,但是向上跳的概率最大,向左的概率较小,向右的概率更小,强化学习学什么呢就是学这个policy函数只要有了这个policy函数,就可以让它自动操作马里奥打游戏了。
这个例子里agent的动作是随机的,根据policy函数输出的概率来做动作,当然也有确定的policy,那样的话动作就是确定的,为什么让agent动作随机呢,超级玛丽这个游戏里面马里奥的动作不管是随机还是确定都还没有问题都可以,但如果是和人博弈最好还是要随机,要是你的动作很确定别人就有办法赢,我们来想想剪刀石头布的例子,要是你出拳的策略是固定的那就有规律可循了,你的对手就能猜出你下一步要做什么,你很定会输,只有让你的策略随机,别人无法猜测你的下一步动作,你就会赢,所以很多应用里面policy是一个概率密度,最好是随机抽样得到的要有随机性。
Reward
下一个知识点是奖励reward:
Agent做出一个动作,游戏就会给一个奖励,这个奖励通常需要我们来定义,奖励定义的好坏非常容易影响强化学习的结果,如何定义奖励就见人见智了。
马里奥吃到一个金币奖励R=+1,如果赢了这场游戏奖励R=+10000,我们应该把打赢游戏的奖励定义的大一些,这样才能激励学到的policy打赢游戏而不是一味的吃金币,如果马里奥碰到敌人Goomba,马里奥就会死,游戏结束,这时奖励就设为R=-10000,如果这一步什么也没发生,奖励就是R=0,强化学习的目标就是使获得的奖励总和尽量要高。

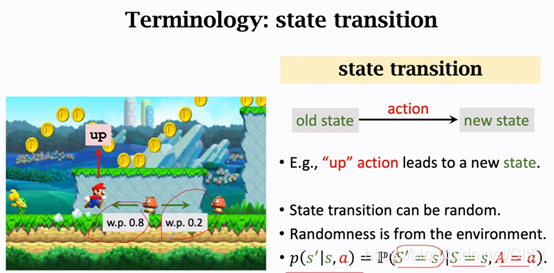
State Transition
当前状态下,马里奥做一个动作,游戏就会给出一个新的状态,比如马里奥跳一下,屏幕上下一个画面就不一样了,也就是状态变了,这个过程就叫做State transition(状态转移)状态转移可以是固定的也可以是随机的,通常我们认为状态转移是随机的,如果学过马尔科夫链状态转移的随机性应该很容易理解,状态转移的随机性是从环境里来的。环境是什么呢?在这里环境就是游戏的程序,游戏程序决定下一个状态是什么,我举个例子来说明状态转移的随机性。
如果马里奥向上跳,马里奥就到上面去了,这个地方是确定的,而敌人Goomba可能往左,也可能往右,Goomba的状态是随机的这也造成下一状态的随机性。可以将状态转移用p函数来表示:
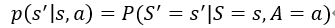
这是一个条件概率密度函数,意思是如果观测到当前的状态s以及动作a,p函数输出s’的概率,我举的这个例子里,马里奥跳到上面,Goomba往左的概率为0.8,往右为0.2,但是我们不知道这个状态转移函数,我知道Goomba可能往左也可能往右,但是我不确定它往左或者往右的概率有多大,这个概率转移函数只有环境自己知道,我们玩家是不知道的。
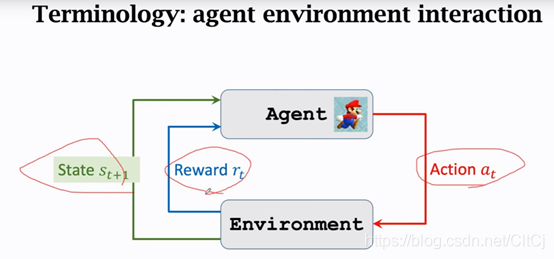
Agent environment interaction
最基本的概念讲的差不多了,我们来看一下agent和环境是怎么进行交互的,agent是马里奥,状态St是环境告诉我们的,在超级玛丽的例子里面,我们可以把当前屏幕上显示的图片看做状态St,agent看到状态St之后要做出一个动作at,动作可以是向左走、向右走和向上跳,agent做出动作at之后环境会更新状态St+1,同时环境还会给agent一个奖励rt,
要是吃到金币奖励是正的,要是赢了游戏奖励就是一个很大的正数,要是马里奥over了奖励就是一个很大的负数。
Return
Return翻译为回报,Return的另一个名字是cumulative future reward(未来的累计奖励),我们把t时刻的return叫做Ut,return这样定义的把t时刻的奖励全都累计加起来,一直加到游戏结束时的最后一个奖励。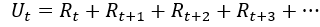
这里,我问一个问题,你们觉得奖励R_t和+R_(t+1)同样重要吗?
假如,我给你两个选项:
1、 我立刻给你100块钱和我一年后我给你100块钱。你会选择哪一个?
理性的人应该都会选择现在立刻得到100块钱,这是因为未来的不确定性很大,即使我现在答应给你明年给你100,你也未必拿得到,大家都明白这个道理,明年得到这100块钱不如现在立刻得到这100块钱。
2、 是我换一个问题,现在我立刻给你80块钱,和我明年给你100块钱,你会选择哪一个,或许大家会做不同的选择,有人选择前者,有人选择后者。
所以呢,未来的奖励100不如现在的100好,未来的100恐怕只值现在的80,因此我该给未来的奖励打一个折扣,比如打一个8折,未来Rt+1的权重要比Rt低才可以,由于未来的奖励不如现在的奖励值钱,所以强化学习中常使用Discounted return(折扣回报),把折扣率记作?,这个值要介于0和1之间,如果未来和现在的权重一样那么γ=1要是未来的奖励不重要γ就比较小,这就是折扣回报的定义:当前的奖励Rt没有折扣,下一时刻Rt+1的折扣率是?,依次类推,折扣率是一个超参数需要我们自己来调,折扣率的设置对强化学习有一定的影响。

理解强化学习如何打游戏
如果我们玩超级玛丽,那么我们的目标是什么呢?我们的目标就是操作马里奥多吃金币,避开敌人,向前走,打赢每一关,我们想写个程序用AI来控制agent,我们应该怎么做呢?
一种办法是学习policy函数π,这在强化学习里面叫做policy-based learning 基于策略的学习,我后面会讲,假如我们有了policy函数π,我们就可以用π函数控制agent做动作了,每观测到一个状态st就将st作为π函数的输入,π函数会输出每一个动作的概率,然后用这些概率做随机抽样得到at,最后agent执行这个动作at,AI就是用这种方式控制agent打游戏的。 另外
另外
一种方法是optimal action-value function(最优动作-价值函数)Q* ,这在强化学习里面称为value-based learning 价值学习。

Python语言基础
参考教材:Python蓝皮书
参考视频:
Python 三剑客学习视频
数据分析之numpy学习
NumPy(Numerical Python) 是科学计算基础库,提供大量科学计算相关功能,比如数据 统计,随机数生成等。其提供最核心类型为多维数组类型(ndarray),支持大量的维度数组 与矩阵运算,Numpy 支持向量处理 ndarray 对象,提高程序运算速度。
数据分析之Pandas库
pandas 是用于数据挖掘的Python库
便捷的数据处理能力
独特的数据结构
读取文件方便
封装了matplotlib的画图和numpy的计算
pandas的数据结构
SeriesSeries 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。由索引(index)和列组成。DataFrame
DataFrame 是一个表格型的数据结构,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典。
matplotlib 可视化工具学习
Matplotlib将数据绘制在Figure对象上,Figure对象应包含一个或多个Axes对象,Axes对象包含一组X-Y坐标或者更多维度坐标的区域
pyplot是matplotlib的绘图接口;对Figure对象进行管理