代码里的注释一定要看!!!里面包括了一些基本知识和原因
可以依次把下面的代码段合在一起运行,也可以通过jupyter notebook分次运行
第一步:一些库的导入
import torch#深度学习的pytoch平台import torch.nn as nnimport numpy as npimport randomimport time#可以用来简单地记录时间import matplotlib.pyplot as plt#画图#随机种子random.seed(1234)np.random.seed(1234)torch.manual_seed(1234)torch.cuda.manual_seed(1234)torch.cuda.manual_seed_all(1234)第二步:构建简单的数据集,这里利用sinx函数作为例子
x = np.linspace(-np.pi,np.pi).astype(np.float32)y = np.sin(x)#随机取25个点x_train = random.sample(x.tolist(),25) #x_train 就相当于网络的输入y_train = np.sin(x_train) #y_train 就相当于输入对应的标签,每一个输入都会对应一个标签plt.scatter(x_train,y_train,c="r")plt.plot(x,y)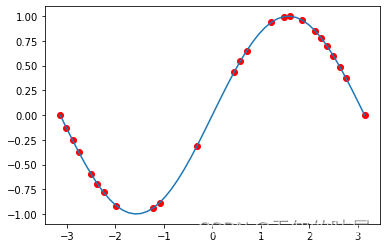
红色的点就是我在sinx函数上取的已知点作为网络的训练点。
第三步:用pytorch搭建简单的全连接网络
class DNN(nn.Module): def __init__(self): super().__init__() layers = [1,20,1] #网络每一层的神经元个数,[1,10,1]说明只有一个隐含层,输入的变量是一个,也对应一个输出。如果是两个变量对应一个输出,那就是[2,10,1] self.layer1 = nn.Linear(layers[0],layers[1]) #用torh.nn.Linear构建线性层,本质上相当于构建了一个维度为[layers[0],layers[1]]的矩阵,这里面所有的元素都是权重 self.layer2 = nn.Linear(layers[1],layers[2]) self.elu = nn.ELU() #非线性的激活函数。如果只有线性层,那么相当于输出只是输入做了了线性变换的结果,对于线性回归没有问题。但是非线性回归我们需要加入激活函数使输出的结果具有非线性的特征 def forward(self,d):#d就是整个网络的输入 d1 = self.layer1(d) d1 = self.elu(d1)#每一个线性层之后都需要加入一个激活函数使其非线性化。 d2 = self.layer2(d1)#但是在网络的最后一层可以不用激活函数,因为有些激活函数会使得输出结果限定在一定的值域里。 return d2第四步:一些基本参数变量的确定以及数据格式的转换
device = torch.device("cuda") #在跑深度学习的时候最好使用GPU,这样速度会很快。不要的话默认用cpu跑epochs = 10000 #这是迭代次数,把所有的训练数据输入到网络里去就叫完成了一次epoch。learningrate = 1e-4 #学习率,相当于优化算法里的步长,学习率越大,网络参数更新地更加激进。学习率越小,网络学习地更加稳定。net = DNN().to(device=device) #网络的初始化optimizer = torch.optim.Adam(net.parameters(), lr=learningrate)#优化器,不同的优化器选择的优化方式不同,这里用的是随机梯度下降SGD的一种类型,Adam自适应优化器。需要输入网络的参数以及学习率,当然还可以设置其他的参数mseloss = nn.MSELoss() #损失函数,这里选用的是MSE。损失函数也就是用来计算网络输出的结果与对应的标签之间的差距,差距越大,说明网络训练不够好,还需要继续迭代。MinTrainLoss = 1e10 train_loss =[] #用一个空列表来存储训练时的损失,便于画图pt_x_train = torch.from_numpy(np.array(x_train)).to(device=device,dtype = torch.float32).reshape(-1,1) #这里需要把我们的训练数据转换为pytorch tensor的类型,并且把它变成gpu能运算的形式。pt_y_train = torch.from_numpy(np.array(y_train)).to(device=device,dtype = torch.float32).reshape(-1,1) #reshap的目的是把维度变成(25,1),这样25相当于是batch,我们就可以一次性把所有的点都输入到网络里去,最后网络输出的结果也不是(1,1)而是(25,1),我们就能直接计算所有点的损失print(pt_x_train.dtype)print(pt_x_train.shape)第五步:网络训练过程
start = time.time()start0=time.time()for epoch in range(1,epochs+1): net.train() #net.train():在这个模式下,网络的参数会得到更新。对应的还有net.eval(),这就是在验证集上的时候,我们只评价模型,并不对网络参数进行更新。 pt_y_pred = net(pt_x_train) #将tensor放入网络中得到预测值 loss = mseloss(pt_y_pred,pt_y_train) #用mseloss计算预测值和对应标签的差别 optimizer.zero_grad() #在每一次迭代梯度反传更新网络参数时,需要把之前的梯度清0,不然上一次的梯度会累积到这一次。 loss.backward() # 反向传播 optimizer.step() #优化器进行下一次迭代 if epoch % 10 == 0:#每10个epoch保存一次loss end = time.time() print("epoch:[%5d/%5d] time:%.2fs current_loss:%.5f" %(epoch,epochs,(end-start),loss.item())) start = time.time() train_loss.append(loss.item()) if train_loss[-1] < MinTrainLoss: torch.save(net.state_dict(),"model.pth") #保存每一次loss下降的模型 MinTrainLoss = train_loss[-1]end0 = time.time()print("训练总用时: %.2fmin"%((end0-start0)/60)) 
训练过程如上,时间我这里设置的比较简单,除了分钟,之后的时间没有按照60进制规定。
第六步:查看loss下降情况
plt.plot(range(epochs),train_loss)plt.xlabel("epoch")plt.ylabel("loss")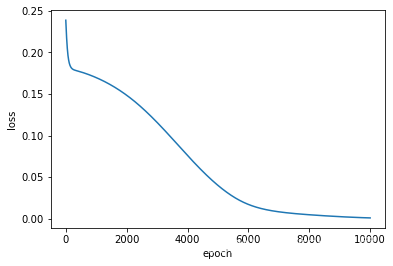
可以看到收敛的还是比较好的。
第七步:导入网络模型,输入验证数据,预测结果
x_test = np.linspace(-np.pi,np.pi).astype(np.float32)pt_x_test = torch.from_numpy(x_test).to(device=device,dtype=torch.float32).reshape(-1,1)Dnn = DNN().to(device)Dnn.load_state_dict(torch.load("model.pth",map_location=device))#pytoch 导入模型Dnn.eval()#这里指评价模型,不反传,所以用eval模式pt_y_test = Dnn(pt_x_test) y_test = pt_y_test.detach().cpu().numpy()#输出结果torch tensor,需要转化为numpy类型来进行可视化plt.scatter(x_train,y_train,c="r")plt.plot(x_test,y_test)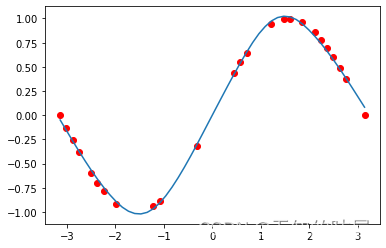
这里红色的点为训练用的数据,蓝色为我们的预测曲线,可以看到整体上拟合的是比较好的。
以上就是用pytorch搭建的简单全连接网络的基本步骤,希望可以给到初学者一些帮助!