Hallo,各位小伙伴大家好呀!这两天一直在肝项目,都是关于计算机视觉方面的,所以这两天一直也没有更新(真的不是我懒)!在这个过程中我对Yolov5有了更深刻的理解,在原有的Yolov5框架上增加了图像分割功能,这样在原有的识别基础上可以将目标切割出来,再进行更为精确的识别,调用百度AI的接口,将图片上传再接受返回值,这难道不香吗?所以本篇文章以Yolov5+图像分割+调用百度AI的接口实现车牌实时监测识别的效果,识别效果非常优秀。接下来就一起来看看这篇文章吧,如果小伙伴们感兴趣也欢迎评论区或者私信交流!
目录
一、Yolov5介绍
二、图像分割
三、百度AI
四、Yolov5+图片分割+百度AI车牌实时检测识别系统
4.1流程图
4.2数据集下载
4.3Yolov5模型训练
4.3PyQt5可视化界面
4.4opencv切割图片
4.5调用百度AI进行图片检测
五、总结
一、Yolov5介绍
之前有些一篇文章——《Yolov5:强大到你难以想象──新冠疫情下的口罩检测》,详细链接为 :Yolov5:强大到你难以想象──新冠疫情下的口罩检测,里面有对Yolov5的简介,这两天的学习我对Yolov5的了解更加深入,在知网上查阅了不少资料,总结一下:
YOLOv5 算法整体主要有 3 部分组成: Backbone、 Neck 和 Prediction, 以 YOLOv5s 模型为例整体算法结 构如下所示. Backbone 主要有 Conv, C3 和 SPPF 基 本网络模块组成, 其主要功能就是提取图像特征信息, C3 模块使用残差网络结构, 可以学习到更多的特征信 息, SPPF 模块是空间金字塔池化, 也是 Backbone 网络 的输出端, 主要功能是将提取到的任意大小的特征信 息转换成固定大小的特征向量. Neck 网络采用 FPN+ PAN 的特征金字塔结构网络, 可以实现不同尺寸目标 特征信息的传递, 可以有效解决多尺度问题. Prediction 采用 3 种损失函数分别计算目标分类损失, 目标定位损失和置信度损失, 并通过 NMS 提高网络检测的准确 度. 模型默认输入图像尺寸大小为 640×640的 3 通道图像, 最终输出格式是 3×(5+ncls), ncls 表示目标检测分类 数量。
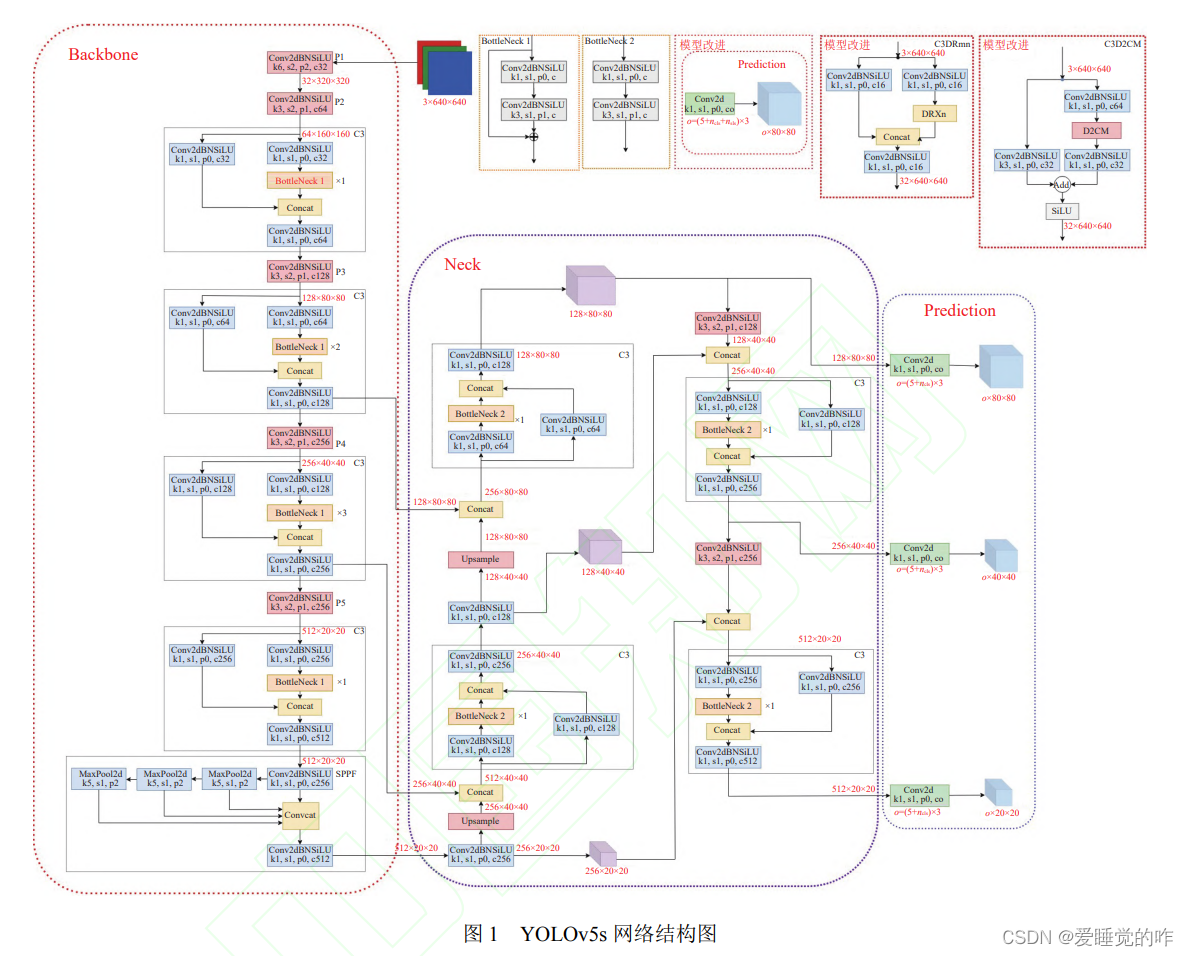
YOLO 算法从总体上看, 是单阶段端到端的基于 anchor-free 的检测算法. 将图片输入网络进行特征提 取与融合后, 得到检测目标的预测框位置以及类概率. 而 YOLOv5 相较前几代 YOLO 算法, 模型更小、部署 灵活且拥有更好的检测精度和速度, 适合实时目标检 测. YOLOv5 根据模型不同深度和不同特征图宽度划 分为 YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x 四个模型. 其中 YOLOv5s 是最小的模型,本文车牌检测既是用YOLOv5s模型。
二、图像分割
图像分割就是把图像分成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术和过程。它是由图像处理到图像分析的关键步骤。现有的图像分割方法主要分以下几类:基于阈值的分割方法、基于区域的分割方法、基于边缘的分割方法以及基于特定理论的分割方法等。从数学角度来看,图像分割是将数字图像划分成互不相交的区域的过程。图像分割的过程也是一个标记过程,即把属于同一区域的像素赋予相同的编号。
主要是用opencv进行矩阵切割,
img = cv2.imread('图片.jpg')dst = img[num1:num2,num3:num4] #裁剪坐标为[y0:y1, x0:x1] 我们看一个demo,还记得我们之前写的人脸识别算法吗?我们进行一下改进,之前的效果是:
 我们将代码优化一下,不仅要在原图上用红框标记出来,而且要切割出来。代码如下:
我们将代码优化一下,不仅要在原图上用红框标记出来,而且要切割出来。代码如下:
import cv2 as cvdef face_detect_demo(img): img = cv.resize(img, dsize=(800, 800)) gary = cv.cvtColor(img, cv.COLOR_BGR2GRAY) face_detect = cv.CascadeClassifier("D:/opencv/sources/data/haarcascades/haarcascade_frontalface_default.xml") face = face_detect.detectMultiScale(gary, 1.004, 28, 0, (40, 40), (50, 50)) count = 1 for x, y, w, h in face: cv.rectangle(img, (x, y), (x + w, y + h), color=(0, 0, 225), thickness=4) dst = img[y:y + h, x:x + w] # cv.imshow("demo",dst) cv.imwrite("temp/face_{0}.jpg".format(count), dst) count += 1 cv.imshow("result", img) # img.save("result.jpg") # 保存图片 cv.imwrite(r"final_result.jpg", img)img = cv.imread("photo.jpg")face_detect_demo(img) # 检测单个图片while True: if ord("q") == cv.waitKey(1): breakcv.destroyAllWindows()检测结果如下,我们就将所有人脸分割出来啦!
三、百度AI
百度智能云AR开放平台提供领先的AR技术能力与一站式平台工具,开放感知跟踪、人机交互等40+技术能力。它提供了很多技术的接口,比如说人脸识别,文字识别,语言识别等等。
 这次我们通过调用文字识别的接口,用来识别我们本地图片上的文字,详细教程可以看这位博主的:百度AI调接口教程。对了,大家记得领一下百度免费送的优惠,要不然程序运行会报错,别问我怎么知道的,问就是搞了两个半小时总结出来的。这个过程可以理解为调用百度文字识别这个函数,传入本地的一张图片,它可以返回本地图片上的文字。只不过这个函数不是内置的,需要你去配置才能够使用。代码如下:
这次我们通过调用文字识别的接口,用来识别我们本地图片上的文字,详细教程可以看这位博主的:百度AI调接口教程。对了,大家记得领一下百度免费送的优惠,要不然程序运行会报错,别问我怎么知道的,问就是搞了两个半小时总结出来的。这个过程可以理解为调用百度文字识别这个函数,传入本地的一张图片,它可以返回本地图片上的文字。只不过这个函数不是内置的,需要你去配置才能够使用。代码如下:
# 测试百度在线图片文本识别包# 导入百度的OCR包from aip import AipOcrif __name__ == "__main__": # 此处填入在百度云控制台处获得的appId, apiKey, secretKey的实际值 appId, apiKey, secretKey = ['28509942', 'HbB3GChFwWENkXEI7uCuNG5V', 'IRnFhizLzlXnYFiNoq3VcyLxRHaj2dZU'] # 创建ocr对象 ocr = AipOcr(appId, apiKey, secretKey) with open('D:/cartarget/result_1.png', 'rb') as fin: img = fin.read() res = ocr.basicGeneral(img) print(res['words_result'][0]['words'])这里的appId, apiKey, secretKey需要更换成自己的,图片检测的位置也要换成自己的。我是要下载SDK运行的,你们也可以试试别的方法。
四、Yolov5+图片分割+百度AI车牌实时检测识别系统
4.1流程图
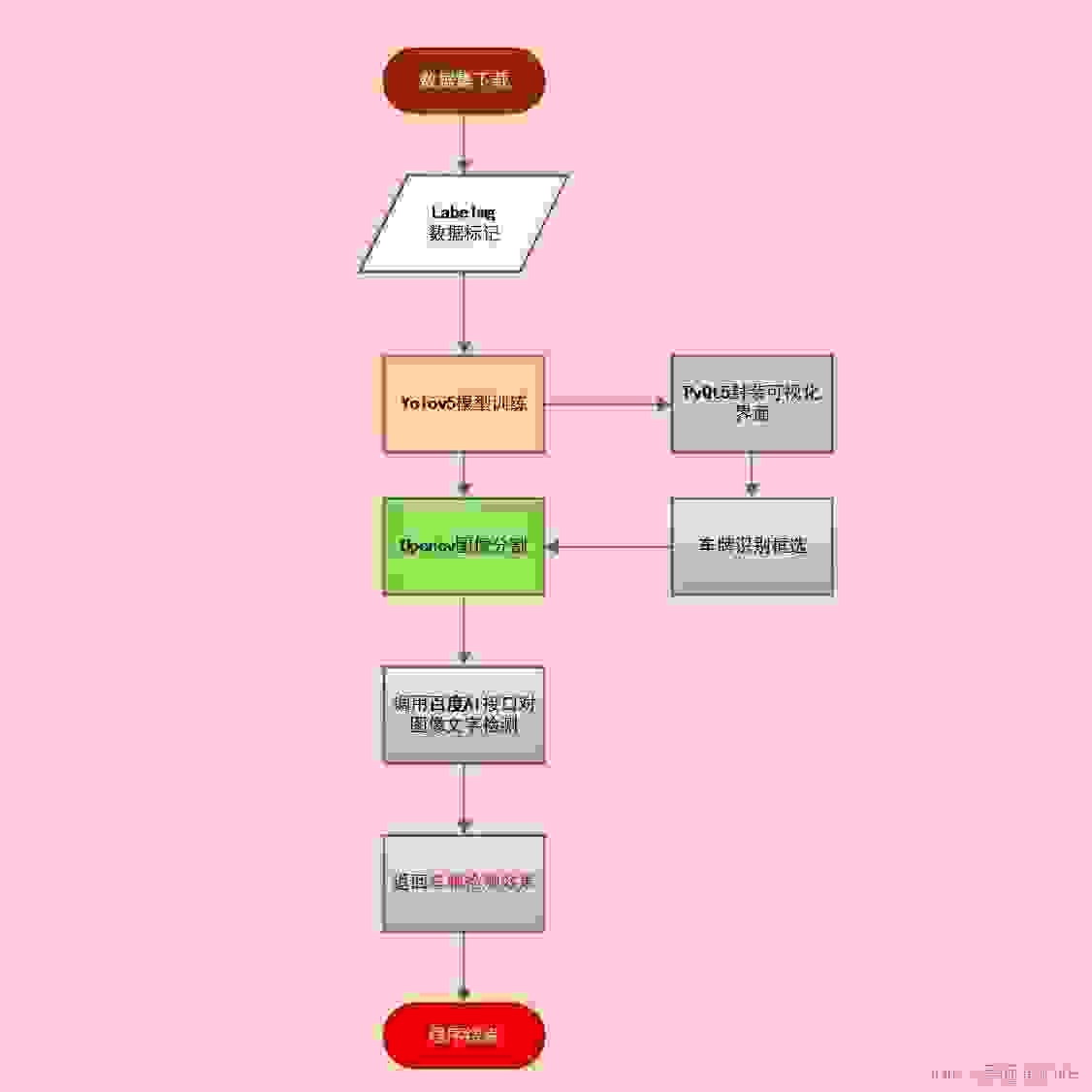
Visio浅浅画了一个流程图,用来表达整个项目的逻辑:
4.2数据集下载
首先是数据集下载,我用的是CCPD2020的数据集,CCPD2020数据集采集方法应该CCPD2019数据集类似。CCPD2020仅仅有新能源车牌图片,包含不同亮度,不同倾斜角度,不同天气环境下的车牌。CCPD2020中的图像被拆分为train/val/test数据集,train/val/test数据集中图片数分别为5769/1001/5006。我用的时候取了100张train,80张val和20张test。CCPD2020数据集(数据大小865.7MB)下载链接我也分享给大家,不用谢!链接:https://pan.baidu.com/s/11IgwwsCjsTRuLOnewx51lw?pwd=5rvf 提取码:5rvf
4.3Yolov5模型训练
然后是Yolov5模型的训练,详细代码还是看之前那篇口罩检测的文章吧,配置文件只要改这几个。
数据集的配置文件:mask_data.yaml: 修改train的路径 注意是 /(反斜杠)修改val的路径修改类别 nc :1、2 names [“标签名称1”、“标签名称2”] 具体几个看你的类别有几个模型配置文件: yolov5s.yaml 修改类别个数 nc:1、2这里贴上检测数据,由于是用CPU跑的,考虑到时间问题,我这里仅训练了20次,用时在40min左右。
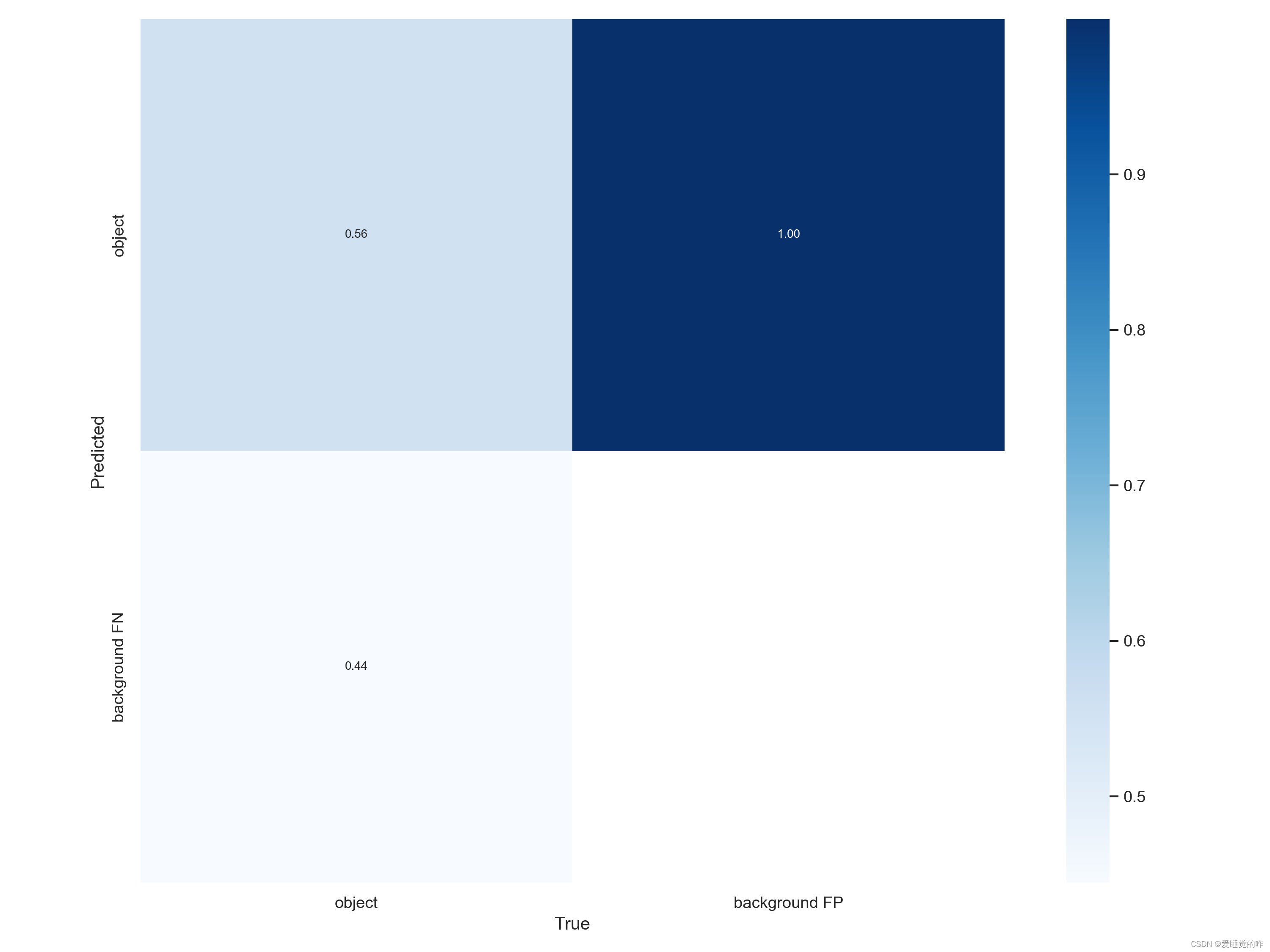
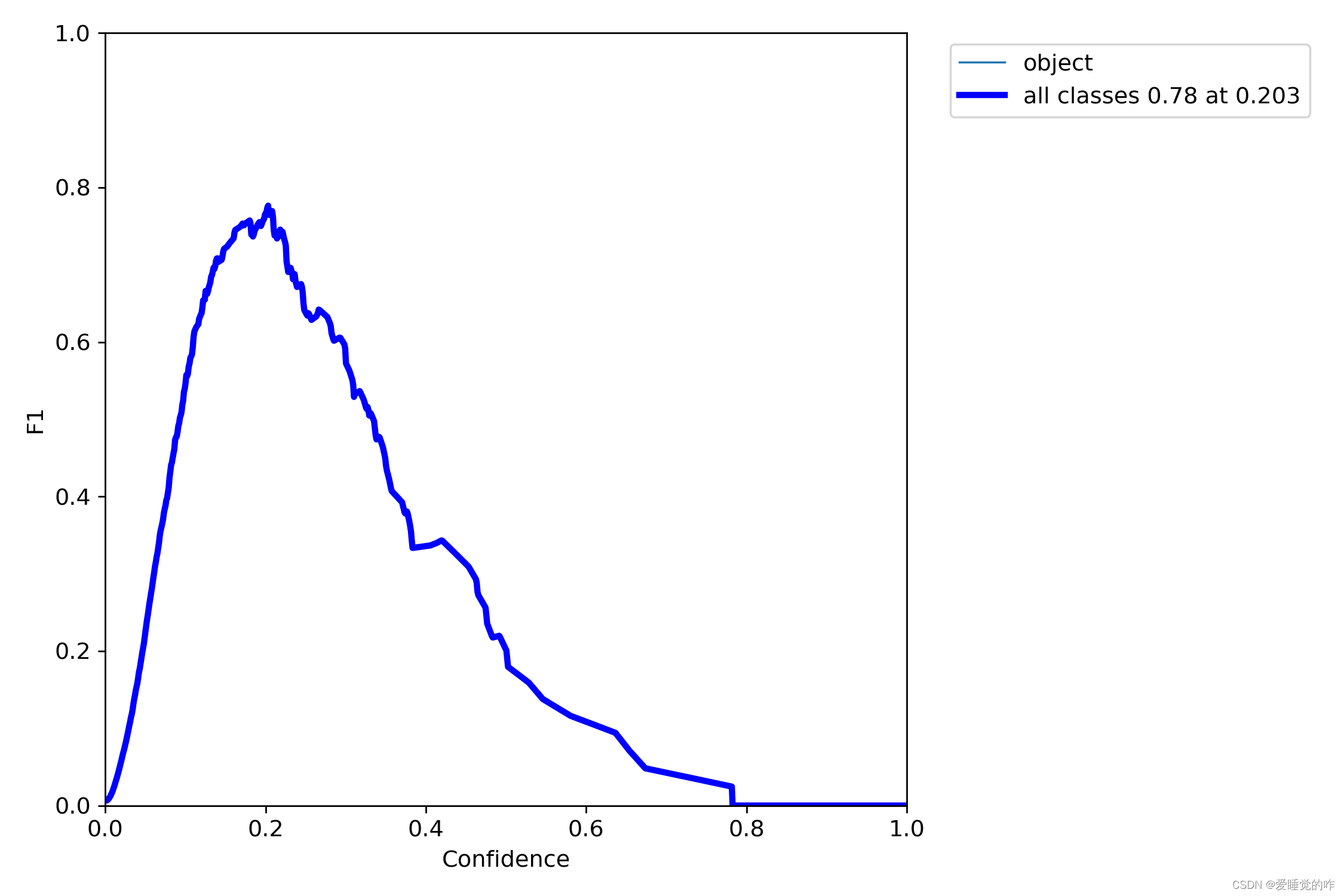
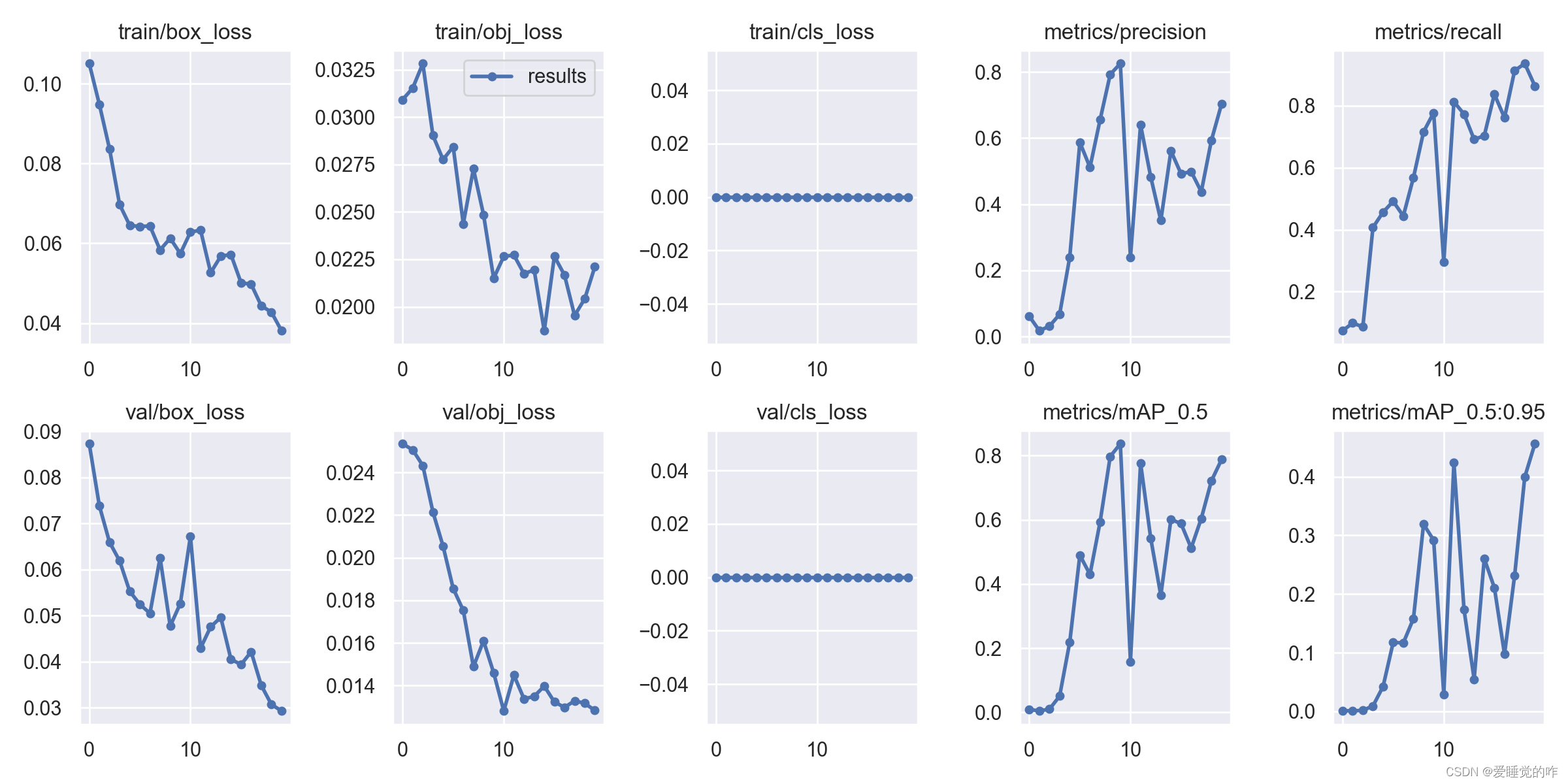
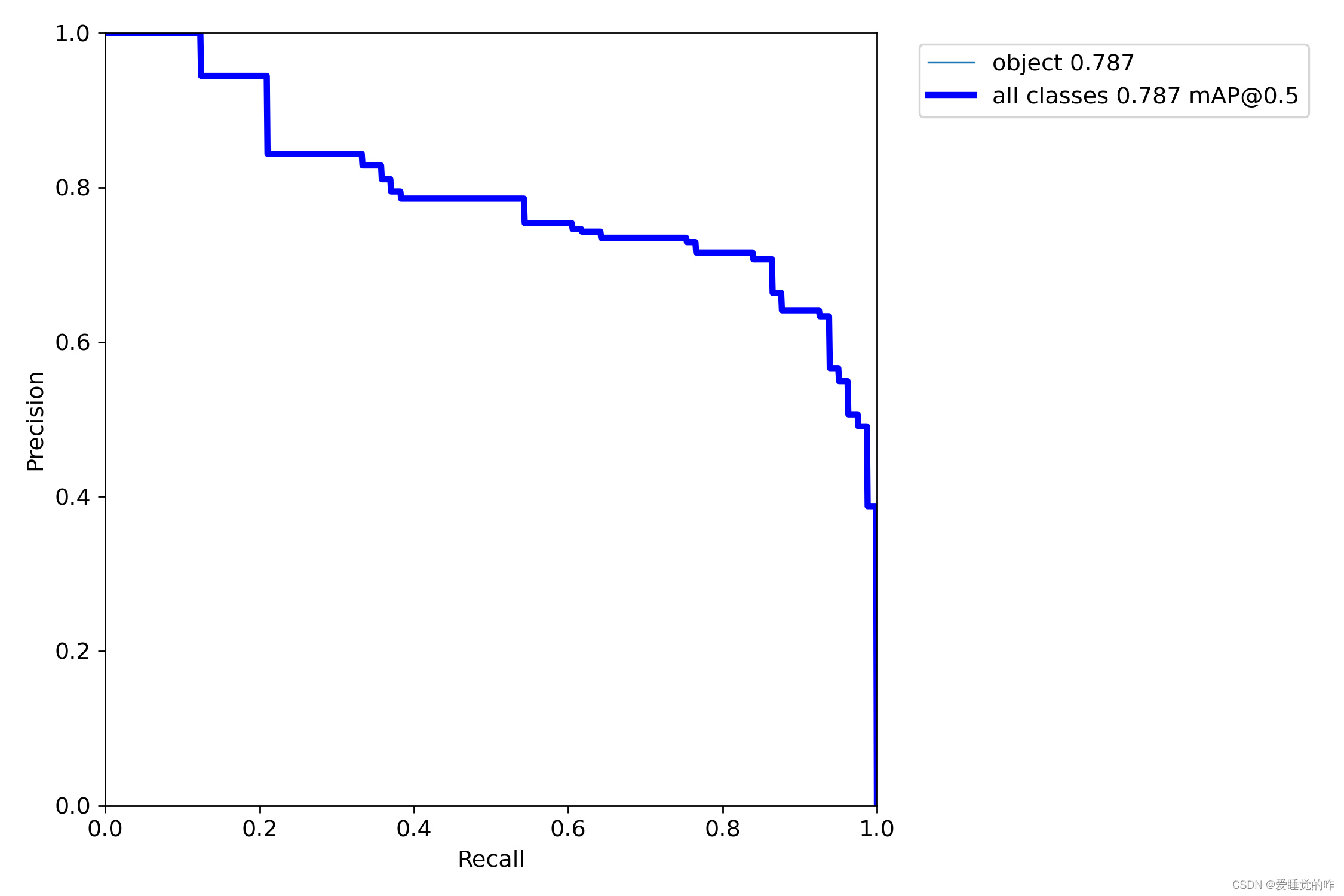
可以看到,识别的精度为80%左右,还是比较可观的,通过增大epoch的值,可以调整成100,识别率达到95%是没有问题的。
4.3PyQt5可视化界面
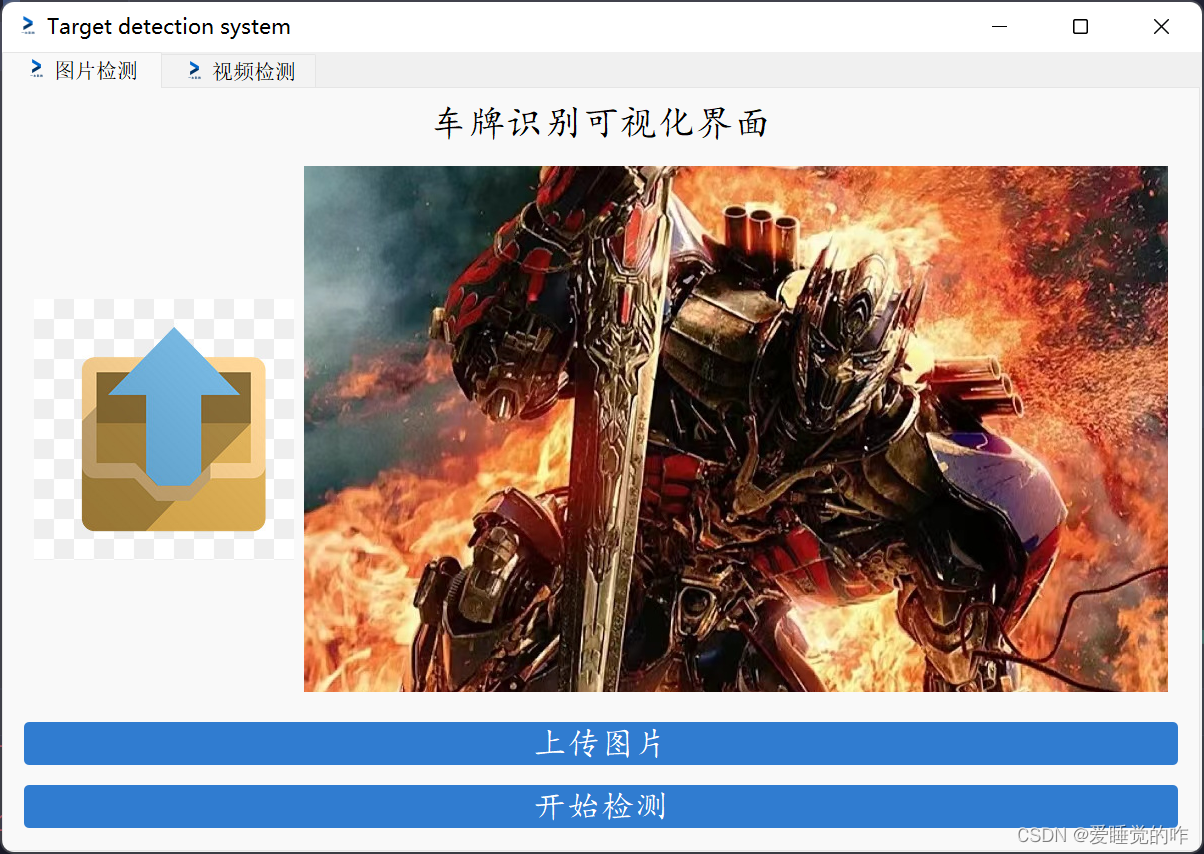
点击上传图片按钮上传图片,从本地选择一张图片。
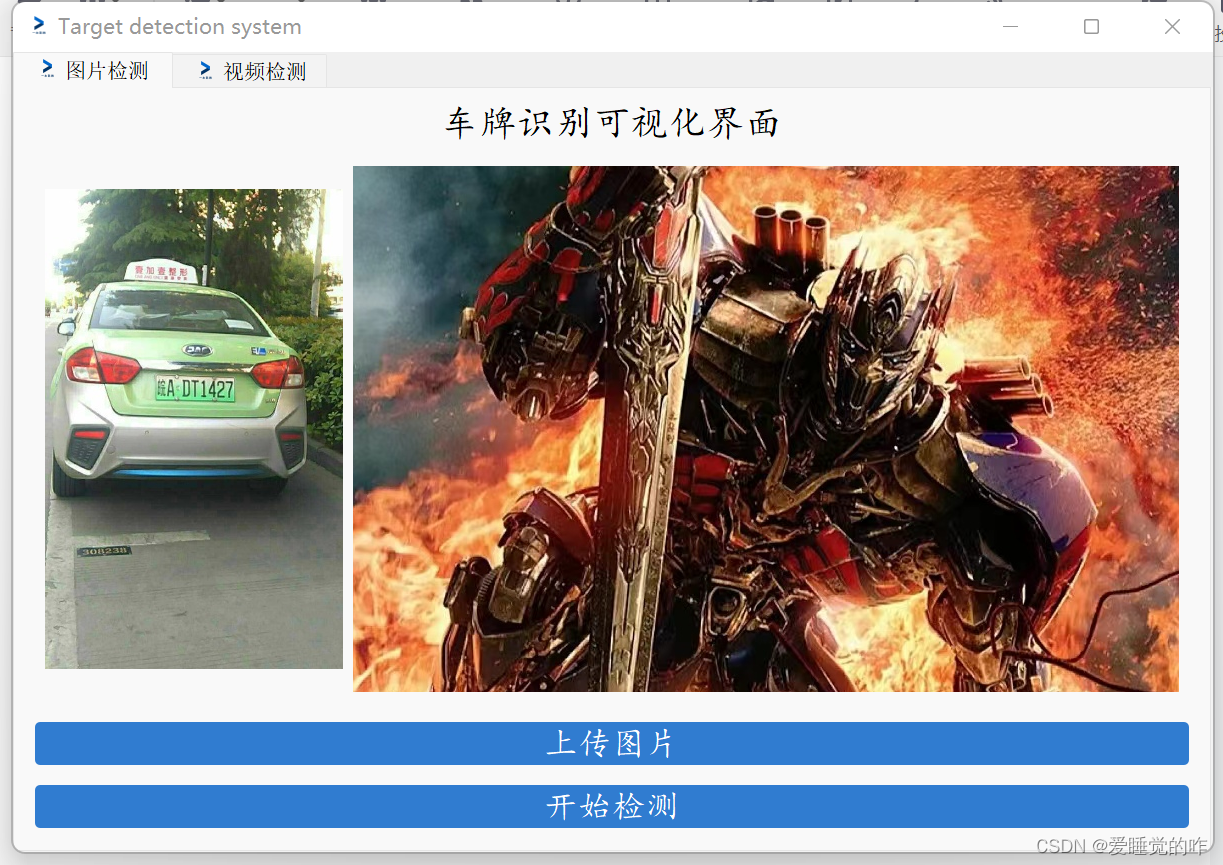 再点击开始检测 ,调用训练好的pt模型进行识别。
再点击开始检测 ,调用训练好的pt模型进行识别。
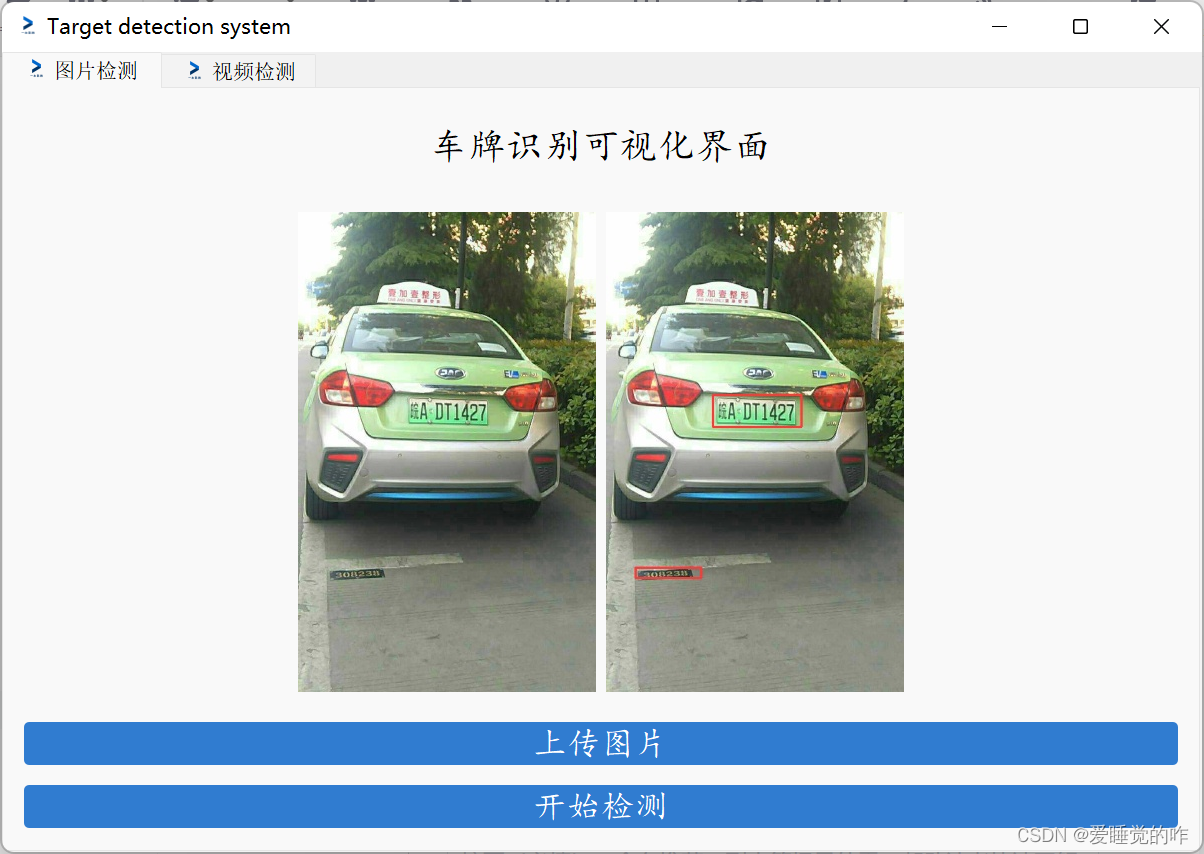
左边为原图,右边为检测之后的图, 可以看到这辆车的车牌已经被框选出来,做了标记。
4.4opencv切割图片
我自定义了一个split.py,里面只有一个split函数,目的就是为了切割图片,这里是运用了封装思想。在windows.py文件中通过import导入,就可以直接运用这个函数了。以下为split.py文件内容。
import cv2 as cvdef split(list_1,img,i): dst = img[int(list_1[1]):int(list_1[3]),int(list_1[0]):int(list_1[2])] # 裁剪坐标为[y0:y1, x0:x1] xyxy cv.imwrite("D:/cartarget/result_{0}.png".format(i+1), dst)# list_1 =[231,1391,586,1518]# img = cv.imread('train_25.jpg')# split(list_1,img,0)接着需要对windows.py进行修改,在检测图片detect_img函数中,添加
tem_list = [] tem_list.append(int(xyxy[0])) tem_list.append(int(xyxy[1])) tem_list.append(int(xyxy[2])) tem_list.append(int(xyxy[3])) print("准备切割!") split.split(tem_list, im0,count_1) count_1 += 1 print("切割完成!")这样,Yolov5检测出几个目标,就会调用几次split方法从而切割出来几张子图片,由于这里图片只有一辆车,所有只有一个检测目标,所以只会得到一个车牌。

4.5调用百度AI进行图片检测
这个逻辑就很好理解啦!只要把上面这个图片丢给百度文字识别去识别内容就好啦!
if __name__ == "__main__": # 此处填入在百度云控制台处获得的appId, apiKey, secretKey的实际值 appId, apiKey, secretKey = ['28509942', 'HbB3GChFwWENkXEI7uCuNG5V', 'IRnFhizLzlXnYFiNoq3VcyLxRHaj2dZU'] # 创建ocr对象 ocr = AipOcr(appId, apiKey, secretKey) with open('name.png', 'rb') as fin: img = fin.read() res = ocr.basicGeneral(img) print(res['words_result'][0]['words'])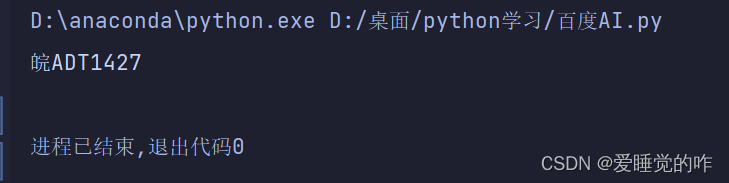
可以看到识别完全正确!大功告成!
五、总结
这个车牌识别系统到这里就算正式结束啦!感觉收获还是蛮多的,对Yolov5的理解更加深刻,Opencv的运用更加熟练,PyQt5也算是熟悉了。目标检测、图片分割、图像搜索、增强和特效、动作识别等等,慢慢觉得这些功能更像是一个个拼图,想要完成一个较大的工程,需要将一个个小功能拼在一起。
机器学习的路程还很漫长,很多知识我都未曾了解,其中的数学原理更是知之甚少。未来的学习还很漫长,人工智能的领域依然辽阔而精彩。车牌检测这个项目只是一个载体,项目本身并不重要,重要的是项目背后学到的知识,定期总结才能更好的接受知识吧!好啦,今天的分享就到这里啦!