
文章目录
每篇前言一、Pandas自定义函数1. pipe()2. apply()3. map()4. applymap()5. agg() 二、总结三、书籍推荐1四、书籍推荐1
每篇前言
??作者介绍:Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6 |
一、Pandas自定义函数
自定义函数是指:有时候需要对 pandas 里的值进行一些特殊操作,但是没有内置函数,或者把其他库中的函数应用到 Pandas 对象中,这时候可以自己写的一个函数
1. pipe()
通过给 pipe() 函数传递一个自定义函数和适当数量的参数值,从而操作 DataFrme 中的所有元素
语法格式:
DataFrame.pipe(func: Callable[..., T] | tuple[Callable[..., T], str],*args,**kwargs,)参数说明:
func:自己编写要应用于Series/DataFrame的函数,*args, **kwargs被传递到“func”中args:迭代的参数,可选,可以是元组类型,也可以是列表类型或者其他。kwargs:映射的参数,可选,是一个包含关键字的字典。1. 首先写一个自定义函数(DataFrame中所有数值乘以多少倍):
def ride(num, multiple): return num * multiple2. 应用自定义函数:
import numpy as npimport pandas as pd# 自定义函数def ride(num, multiple): return num * multipledf = pd.DataFrame(np.ones((3, 3)), columns=['a', 'b', 'c'])print("应用前:")print(df)print("应用后:")print(df.pipe(ride, 10)) # 所有数值乘以10倍运行结果: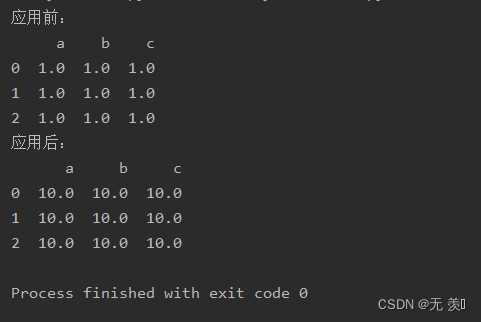
2. apply()
apply()可以对DataFrame按行和列(默认按列)进行函数处理,也支持Series。如果是Series,将逐个传入具体值。使用lambda时,变量是调用对象低一维的值。
语法格式:
DataFrame.apply(func: AggFuncType,axis: Axis = 0,raw: bool = False,result_type=None,args=(),**kwargs,)参数说明:
func:自己编写要应用于Series/DataFrame的函数,*args, **kwargs被传递到“func”中
Axis :应用功能的轴,0 将函数应用于每列,1将函数应用于每一行,默认为0。
raw:bool,默认为False。确定行或列是否作为Series或ndarray对象传递:
False:将每行或每列作为序列传递给作用
True:传递的函数将接收ndarray对象
相反,如果您只是应用NumPy缩减函数,这将实现更好的性能。
result_type:‘expand’,‘reduce’,‘broadcast’,None},默认为None。这些仅在“轴=1”(列)时起作用:
expand:类似列表的结果将变成列。
reduce:如果可能,返回一个序列,而不是展开列表式结果。这与“展开”相反。
broadcast:结果将广播到原始形状在DataFrame中,原始索引和列将是保留。
默认行为(None)取决于应用的函数:类似列表的结果将作为序列返回其中之一。但是,如果apply函数返回Series展开为列。
args:迭代的参数,可选,可以是元组类型,也可以是列表类型或者其他。
kwargs:映射的参数,可选,是一个包含关键字的字典。
可以与lambda结合使用:
import numpy as npimport pandas as pddata = {'A': pd.Series(1, index=list(range(4)), dtype='float32'), 'B': pd.Series(2, index=list(range(4)), dtype='float32'), 'C': pd.Series(3, index=list(range(4)), dtype='float32') }df = pd.DataFrame(data)print("应用前:")print(df)print("对列进行求和:")print(df.apply(lambda x: x.sum(), axis=0))print("对行进行求和:")print(df.apply(lambda x: x.sum(), axis=1))运行结果: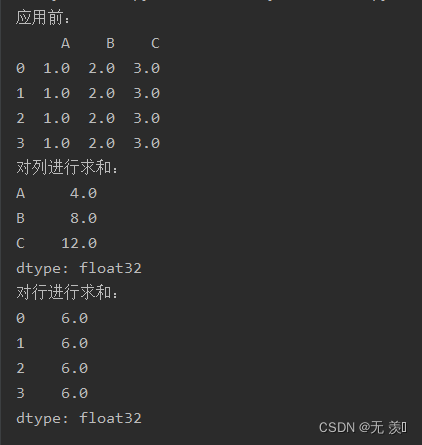
3. map()
map()是Series对象的一个函数,DataFrame中没有map(),map()的功能是将一个自定义函数作用于Series对象的每个元素。
语法格式:
Series.map(arg, na_action=None) -> Series参数说明:
arg:自己编写要应用于Series的函数。映射子类或系列映射对应关系na_action:{None,“ignore”},默认为无,如果“ignore”,则传播NaN值,而不将它们传递给映射对应关系。使用map()函数来将 A 这一列的数据改为保留三位小数显示:
import numpy as npimport pandas as pddata = {'A': pd.Series(1, index=list(range(4)), dtype='float32'), 'B': pd.Series(2, index=list(range(4)), dtype='float32'), 'C': pd.Series(3, index=list(range(4)), dtype='float32') }df = pd.DataFrame(data)print("应用前:")print(df)print("应用后:")print(df['A'].map(lambda x : "%.3f"%x))运行结果: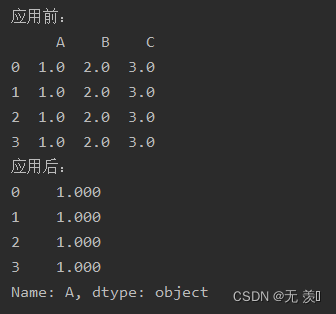
4. applymap()
DataFrame 数据表结构的 applymap() 和 Series 系列结构的 map() 类似,applymap将自定义函数作用于DataFrame的所有元素
语法格式:
DataFrame.applymap(func: PythonFuncType, na_action: str | None = None, **kwargs) -> DataFrame参数说明:
func:Python函数,从单个值返回单个值。
na_action:{None,“ignore”},默认为无,如果“ignore”,则传播NaN值,而不将它们传递给func。
kwargs:映射的参数,可选,是一个包含关键字的字典。
import numpy as npimport pandas as pddata = {'A': pd.Series(1, index=list(range(4)), dtype='float32'), 'B': pd.Series(2, index=list(range(4)), dtype='float32'), 'C': pd.Series(3, index=list(range(4)), dtype='float32') }df = pd.DataFrame(data)print("应用前:")print(df)print("应用后:")print(df.applymap(lambda x: x * 10))运行结果:
5. agg()
聚合函数agg()一般用于使用指定轴上的一项或多项操作进行汇总,可以传入一个函数或函数的字符,还可以用列表的形式传入多个函数。agg()还支持传入函数的位置参数和关键字参数,支持每个列分别用不同的方法聚合,支持指定轴的方向。agg()的用法整体上与apply()极为相似。
语法格式:
DataFrame.agg(func=None, axis: Axis = 0, *args, **kwargs)参数说明:
func:用于聚合数据的函数,如max()、mean()、count()等,函数必须满足传入一个DataFrame能正常使用,或传递到DataFrame.apply()中能正常使用。Axis :应用功能的轴,0 将函数应用于每列,1将函数应用于每一行,默认为0。args:迭代的参数,可选,可以是元组类型,也可以是列表类型或者其他。kwargs:映射的参数,可选,是一个包含关键字的字典。import numpy as npimport pandas as pddata = [[1, 2, 3, 4], [11, 22, 33, 44], [111, 222, 333, 444], [1111, 2222, 3333, 4444] ]df = pd.DataFrame(data)print("应用前:")print(df)print("在列上聚合这些函数:")print(df.agg(['max', 'min', 'mean']))print("在行上聚合这些函数:")print(df.agg(['max', 'min', 'mean'],axis=1))运行结果: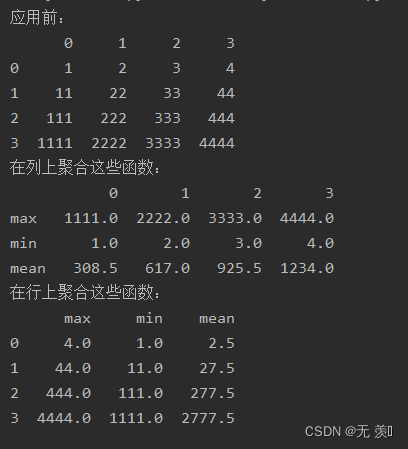
二、总结
1、通过给 pipe() 函数传递一个自定义函数和适当数量的参数值,从而操作 DataFrme 中的所有元素
2、apply()方法使用与Series对象、DataFrame对象、Groupby对象,处理的是行或列数据(本质上处理的是单个Series),用函数类对象来构建映射关系对Series对象进行转换;
3、map()方法适用于Series对象,可以通过字典或函数类对象来构建映射关系对Series对象进行转换;
4、applymap()方法用来处理DataFrame对象的单个元素值,也是使用函数类对象映射转换
5、agg()函数为aggregate的缩写,总数、合计、聚合的意思,是一个功能非常强大的函数,在Pandas中可以利用agg()对Series、DataFrame以及groupby()后的结果进行聚合操作。
三、书籍推荐1
书籍展示:《巧学巧用Excel函数:掌握核心技能,秒变数据分析高手》
【书籍内容简介】
从函数公式入门到了解函数的结构,然后对逻辑判断函数、文本处理函数、信息提取函数、数据统计函数、数学计算函数、日期时间函数、查找引用函数分别进行介绍,建立起对函数的正确认知,最后实现系统级工资表的综合制作。京东自营:https://item.jd.com/13331763.html
四、书籍推荐1
书籍展示:《Python自动化测试实战》
【书籍内容简介】
结合真实案例分别对主流自动化测试工具Selenium、Robot Framework、Postman、Python+Requests、Appium等进行系统讲解。通过学习本书,读者可以快速掌握主流自动化测试技术,丰富测试思维,提高Python编码能力当当:http://product.dangdang.com/28496655.html京东:https://item.jd.com/12609791.html