
文章目录
每篇前言一、常用统计方法与案例1. 求和(sum)2. 求平均值(mean)3. 求最小值(min)4. 求最大值(max)5. 求中位数(median)6. 求众数(mode)7. 求方差(var)8. 求标准差(std)9. 求分布情况(describe)10. 求相关系数(corr) 二、书籍推荐
每篇前言
??作者介绍:Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6 |
一、常用统计方法与案例
Pandas 的本质是统计学原理在计算机领域的一种应用实现,通过编程的方式达到分析、描述数据的目的。而统计函数则是统计学中用于计算和分析数据的一种工具。在数据分析的过程中,使用统计函数有助于我们理解和分析数据。本节将学习比如求和、求平均值、求最大值、最小值、中位数、众数、方差、标准差等。除此以外,还可以获取数值的分布情况、相关系数等。
常用的统计描述方法:
| 方法 | 说明 |
|---|---|
| count | 非NA值的数量 |
| min、max | 计算最小值、最大值 |
| argmin、argmax | 计算能够获取到最小值和最大值的索引位置(整数) |
| idxmin、idxmax | 计算能够获取到最小值和最大值的索引值 |
| quantile | 计算样本的分位数(0到1) |
| sum | 值的总和 |
| mean | 值的平均数 |
| median | 值的算术中位数(50%分位数) |
| mode | 值的众数 |
| var | 样本数值的方差 |
| std | 样本值的标准差 |
| skew | 样本值的偏度(三阶矩) |
| kurt | 样本值的峰度(四阶矩) |
| cumsum | 样本值的累计和 |
| cummin、cummax | 样本值的累计最大值和累计最小值 |
| cumprod | 样本值的累计积 |
| diff | 计算一阶差分(对时间序列很有用) |
| pct_ change | 计算百分数变化 |
| describe | 计算数据表中所有数值的分布情况,包括个数、均值、极值、方差、四分位 |
| corr | 计算相关系数 |
1. 求和(sum)
pandas模块的sum()函数可以对每一列数据进行求和,如果值是字符串类型,则是拼接起来
DataFrame.sum(self, axis=None, skipna=None, level=None, numeric_only=None, min_count=0, **kwargs,)参数说明:
axis:axis=0 按列统计,axis=1按行统计,默认值为0skipna:布尔型,表示计算结果是否排除NaN/Null值,默认值为Nonelevel:索引层级,默认为Nonenumeric_only:布尔型,仅数字,默认值为Nonemin_count:int类型,执行操作所需的数目,默认为0import numpy as npimport pandas as pddf_obj = pd.DataFrame(data=[{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}])print(df_obj)print("按列统计:")print(df_obj.sum())print("按行统计:")print(df_obj.sum(axis=1))运行结果: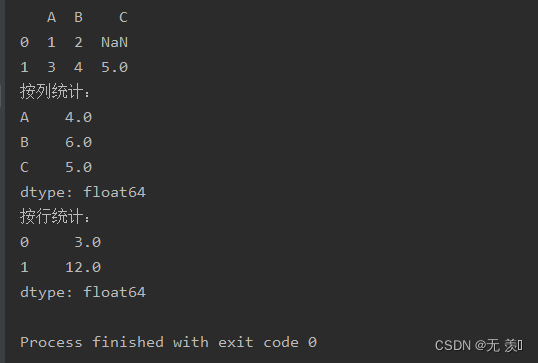
2. 求平均值(mean)
mean(self, axis=None, skipna=None, level=None, numeric_only=None, **kwargs)import numpy as npimport pandas as pddf_obj = pd.DataFrame(data=[{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}])print(df_obj)print("按列统计:")print(df_obj.mean())print("按行统计:")print(df_obj.mean(axis=1))运行结果: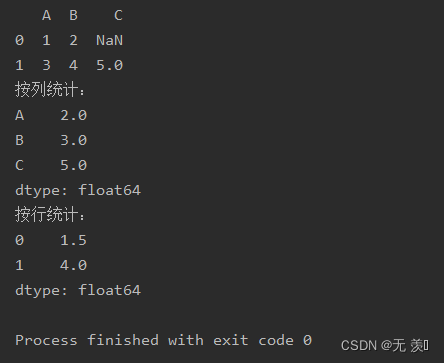
3. 求最小值(min)
min(self, axis=None, skipna=None, level=None, numeric_only=None, **kwargs)import numpy as npimport pandas as pddf_obj = pd.DataFrame(data=[{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}])print(df_obj)print("按列统计:")print(df_obj.min())print("按行统计:")print(df_obj.min(axis=1))运行结果: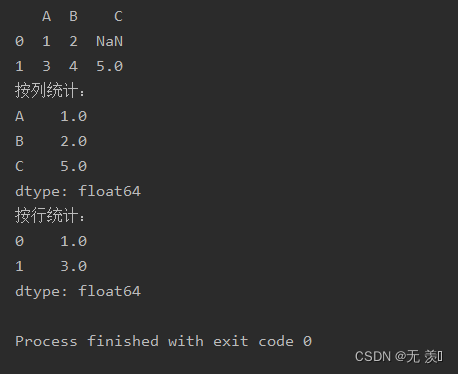
4. 求最大值(max)
max(self, axis=None, skipna=None, level=None, numeric_only=None, **kwargs)import numpy as npimport pandas as pddf_obj = pd.DataFrame(data=[{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}])print(df_obj)print("按列统计:")print(df_obj.max())print("按行统计:")print(df_obj.max(axis=1))运行结果: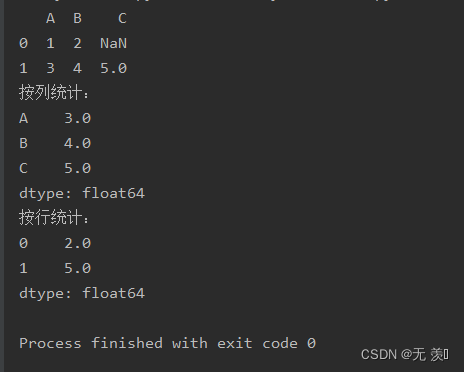
5. 求中位数(median)
median(self, axis=None, skipna=None, level=None, numeric_only=None, **kwargs)import numpy as npimport pandas as pddf_obj = pd.DataFrame(data=[{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}])print(df_obj)print("按列统计:")print(df_obj.median())print("按行统计:")print(df_obj.median(axis=1))运行结果: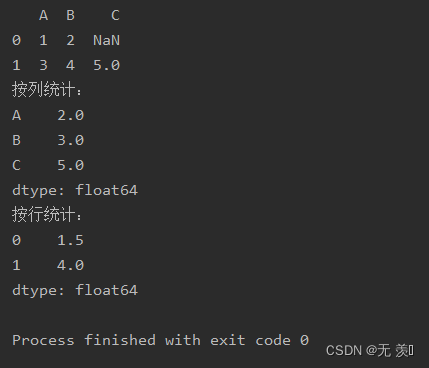
6. 求众数(mode)
mode(self, axis: Axis = 0, numeric_only: bool = False, dropna: bool = True)参数说明:
axis:axis=0 按列统计,axis=1按行统计,默认值为0numeric_only:布尔型,仅数字,默认值为Nonedrop_na:是否删除缺失值,布尔型,默认为Trueimport numpy as npimport pandas as pddf_obj = pd.DataFrame([[1, 1, 1], [2, 2, 3], [3, 4, 5]])print(df_obj)print("按列统计:")print(df_obj.mode())print("按行统计:")print(df_obj.mode(axis=1))运行结果: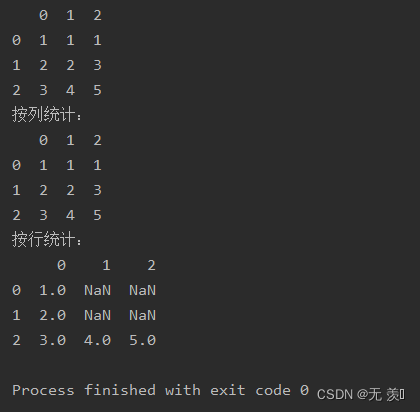
7. 求方差(var)
方差是在概率论和统计方差衡量随机变量或一组数据时离散程度的度量。概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。在许多实际问题中,研究方差即偏离程度有着重要意义。方差越小越稳定。
var(self, axis=None, skipna=None, level=None, ddof=1, numeric_only=None,**kwargs)参数说明:
axis:axis=0 按列统计,axis=1按行统计,默认值为0skipna:布尔型,表示计算结果是否排除NaN/Null值,默认值为Nonelevel:索引层级,默认为Nonenumeric_only:布尔型,仅数字,默认值为Noneddof:int类,计算中使用的除数是N-ddof,其中N表示元素的数量。默认值为1.自由度import numpy as npimport pandas as pddata = [[99, 100, 60, 78, 50], [80, 89, 90, 88, 87]]df_obj = pd.DataFrame(data=data, columns=['语文', '数学', '英语', '历史', '政治'], index=['小明', '小红'])print(df_obj)print("按列统计:")print(df_obj.var())print("按行统计:")print(df_obj.var(axis=1))运行结果:可以看出小红的成绩更加稳定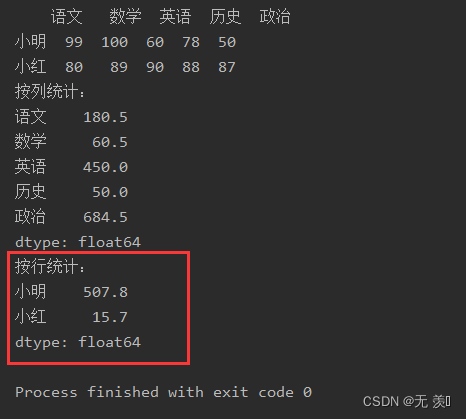
8. 求标准差(std)
标准差(Standard Deviation) ,数学术语,是离均差平方的算术平均数(即:方差)的算术平方根,用σ表示。标准差也被称为标准偏差,或者实验标准差,在概率统计中最常使用作为统计分布程度上的测量依据。
标准差是方差的算术平方根。标准差能反映一个数据集的离散程度。平均数相同的两组数据,标准差未必相同。
参数与var一致:
std(self, axis=None, skipna=None, level=None, ddof=1, numeric_only=None, **kwargs)import numpy as npimport pandas as pddata = [[99, 100, 60, 78, 50], [80, 89, 90, 88, 87]]df_obj = pd.DataFrame(data=data, columns=['语文', '数学', '英语', '历史', '政治'], index=['小明', '小红'])print(df_obj)print("按列统计:")print(df_obj.std())print("按行统计:")print(df_obj.std(axis=1))运行结果: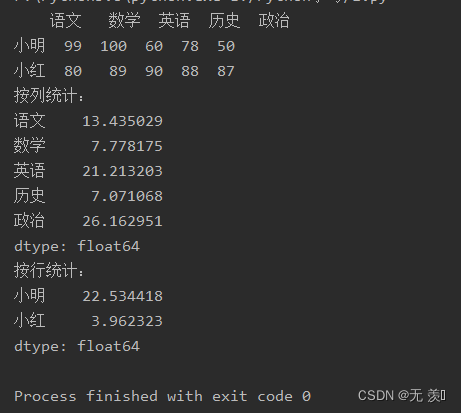
9. 求分布情况(describe)
计算数据表中所有数值的分布情况,包括个数、均值、极值、方差、四分位
describe(self: FrameOrSeries,percentiles=None,include=None,exclude=None,datetime_is_numeric=False,)参数说明:
percentiles:数字列表,可选。要包含在输出中的百分比。所有值都应介于0和1之间。默认值为[.25、.5、.75],返回第25、50和75个百分位。
include:“all”,类似于dtypes或None(默认)的列表,可选。要包含在结果中的数据类型的白色列表。对于系列忽略。以下是选项:
“all”:输入的所有列都将包含在输出中。类似数据类型的列表:将结果限制为所提供的数据类型。要将结果限制为数字类型,请提交numpy.number。要将其限制为对象列,请提交numpy。对象数据类型。字符串也可以以select_dypes的样式使用(例如df.description(include=[‘O’]))。要选择熊猫分类列,请使用“类别”None (默认):结果将包括所有数字列。exclude:列表,如数据类型或无(默认),可选,要从结果中省略的数据类型的黑色列表。对于系列忽略。以下是选项:
数据类型列表:从结果中排除提供的数据类型。要排除数字类型,请提交numpy.number。要排除对象列,请提交数据类型numpy.object。字符串也可以以select_dypes的样式使用(例如df.description(exclude=[‘O’]))。要排除熊猫分类列,请使用“category”
None(默认):结果将不排除任何内容。
datetime_is_numeric:bool,默认为False。是否将日期时间数据类型视为数字。这会影响为列计算的统计信息。对于DataFrame输入,这还控制默认情况下是否包含日期时间列。
import numpy as npimport pandas as pddata = [[99, 100, 60, 78, 50]]df_obj = pd.DataFrame(data=data, columns=['语文', '数学', '英语', '历史', '政治'], index=['小明'])print(df_obj)print(df_obj.describe())运行结果: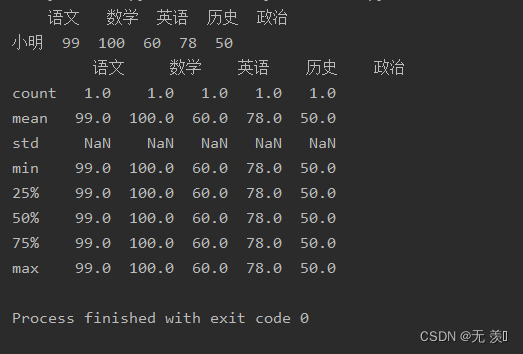
10. 求相关系数(corr)
相关系数通常是用来衡量两个或多个元素之间的相关程度
corr(self,method: str | Callable[[np.ndarray, np.ndarray], float] = "pearson",min_periods: int = 1,)参数说明:
method:可选值为{‘pearson’, ‘kendall’, ‘spearman’} pearson:Pearson相关系数来衡量两个数据集合是否在一条线上面,即针对线性数据的相关系数计算,针对非线性数据便会有误差。kendall:用于反映分类变量相关性的指标,即针对无序序列的相关系数,非正太分布的数据spearman:非线性的,非正太分析的数据的相关系数 min_periods:样本最少的数据量import numpy as npimport pandas as pddf_obj = pd.DataFrame({'age': [10, 15, 20], 'height': [110, 150, 180]},index= ['小红', '小明', '小白'])print(df_obj)print("所有的相关系数:")print(df_obj.corr())print("身高的相关系数:")print(df_obj.corr()['height'])运行结果: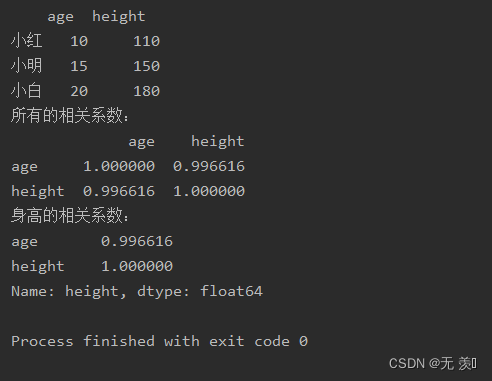
二、书籍推荐
书籍展示:《Web渗透测试新手实操详解》
【书籍内容简介】
渗透测试是检验网络安全的一个重要手段,但渗透测试本身又是一项极具艺术性的工作。它涉及的知识领域很广泛,甚至不限于计算机领域。为了方便读者掌握这一技术,本书全面讲解了渗透测试的相关内容,包括Web渗透测试的本质——冒用身份、Web渗透测试基础知识、常用工具介绍、简单Web渗透测试实验室搭建指南、面向服务器的渗透测试、面向客户端的攻击、面向通信渠道的攻击、防御措施与建议。
京东自营:https://item.jd.com/13401713.html