Jmeter简介
1. Jmeter的基本概念
Apache JMeter是Apache组织开发的基于Java的压力测试工具。
2.Jmeter的作用
接口测试性能测试压力测试接口自动化测试数据库测试JAVA程序测试3.Windows下Jmeter下载安装
登录 http://jmeter.apache.org/download_jmeter.cgi ,根据自己平台,下载对应文件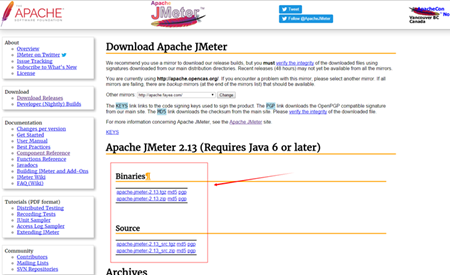
4.安装JAVA环境
安装JDK,配置环境变量(具体步骤不做介绍)
将下载Jmeter文件解压,打开/bin/jmeter.bat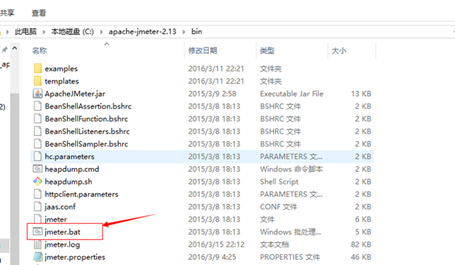
5.Jmeter的目录结构

/bin 目录(常用文件介绍)
examples:目录下包含Jmeter使用实例
ApacheJMeter.jar:JMeter源码包
jmeter.bat:windows下启动文件
jmeter.sh:Linux下启动文件
jmeter.log:Jmeter运行日志文件
jmeter.properties:Jmeter配置文件
jmeter-server.bat:windows下启动负载生成器服务文件
jmeter-server:Linux下启动负载生成器文件
/docs目录——Jmeter帮助文档
/extras目录——提供了对Ant的支持文件,可也用于持续集成
/lib目录——存放Jmeter依赖的jar包,同时安装插件也放于此目录
/licenses目录——软件许可文件,不用管
/printable_docs目录——Jmeter用户手册
Jmeter线程组基本操作
1. 线程组是什么
进程: 一个正在执行的程序对应一个进程
线程: 一个进程有多个执行线程
线程组: 按照线程性质对线程分组
三者关系: 一个进程有多个线程组,一个线程组有多个线程
测试计划—线程组—线程组属性中的线程数
并发执行:多个线程同时执行,特点:执行结束的顺序与开始的顺序不一致
顺序执行:按照线程的启动顺序挨个执行
默认情况下,线程组中的线程是并发执行
每一个线程都要执行组内的http请求
设置线程组顺序执行:勾选测试计划中的(独立运行每个线程组)
线程组用来模拟用户的并发访问
2.创建线程组
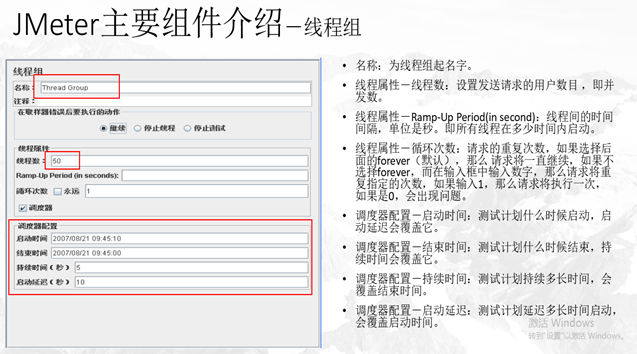
线程组主要包含三个参数:线程数、准备时长(Ramp-Up Period(in seconds))、循环次数。
线程数:虚拟用户数。一个虚拟用户占用一个进程或线程。设置多少虚拟用户数在这里也就是设置多少个线程数。
准备时长(秒):设置的虚拟用户数需要多长时间全部启动。如果线程数为20 ,准备时长为10 ,那么需要10秒钟启动20个线程。也就是每秒钟启动2个线程。
循环次数:每个线程发送请求的次数。如果线程数为20 ,循环次数为100 ,那么每个线程发送100次请求。总请求数为20*100=2000 。如果勾选了“永远”,那么所有线程会一直发送请求,一到选择停止运行脚本。
调度器:设置线程组启动的开始时间和结束时间(配置调度器时,需要勾选循环次数为永远)
持续时间(秒):测试持续时间,会覆盖结束时间
启动延迟(秒):测试延迟启动时间,会覆盖启动时间
启动时间:测试启动时间,启动延迟会覆盖它。当启动时间已过,手动只需测试时当前时间也会覆盖它。
结束时间:测试结束时间,持续时间会覆盖它。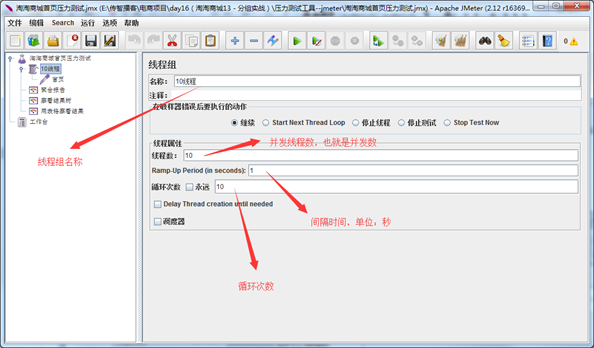
3.创建http请求
4.指定请求域名,请求路径
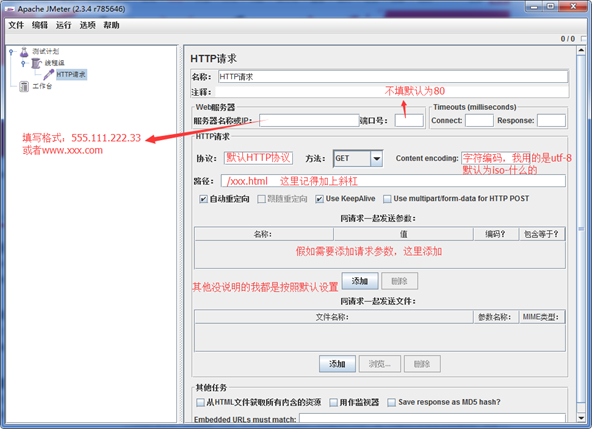
一个HTTP请求有着许多的配置参数,下面将详细介绍:
名称:本属性用于标识一个取样器,建议使用一个有意义的名称。
注释:对于测试没有任何作用,仅用户记录用户可读的注释信息。
服务器名称或IP :HTTP请求发送的目标服务器名称或IP地址。
端口号:目标服务器的端口号。
方法:发送HTTP请求的方法,可用方法包括GET、POST、HEAD、PUT、OPTIONS、TRACE、DELETE等。
Content encoding :内容的编码方式,默认值为iso8859
路径:目标URL路径(不包括服务器地址和端口)
5. 设置对应的查看内容
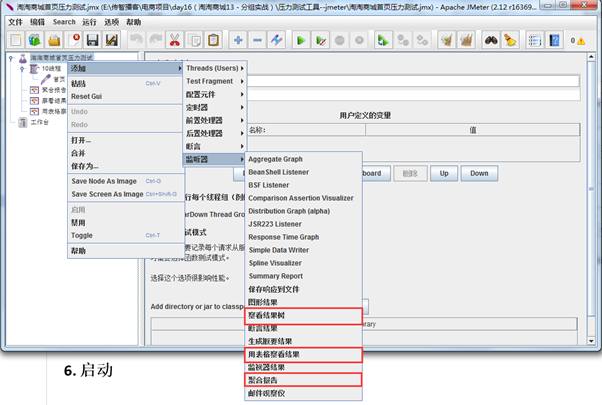
6.查看表格信息
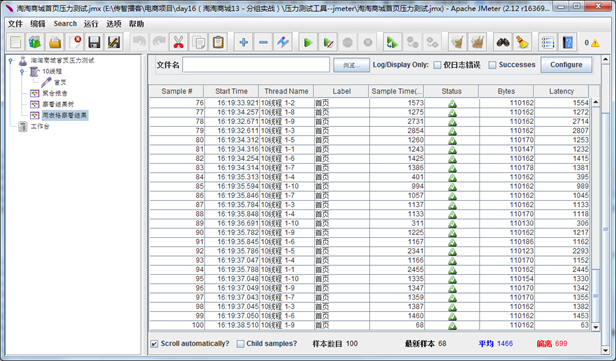
Sample:每个请求的序号
Start Time:每个请求开始时间
Thread Name:每个线程的名称
Label:Http请求名称
Sample Time:每个请求所花时间,单位毫秒
Status:请求状态,如果为勾则表示成功,如果为叉表示失败。
Bytes:请求的字节数
样本数目:也就是上面所说的请求个数,成功的情况下等于你设定的并发数目乘以循环次数
平均:每个线程请求的平均时间
最新样本:表示服务器响应最后一个请求的时间
偏离:服务器响应时间变化、离散程度测量值的大小,或者,换句话说,就是数据的分布。
7. 查看结果树
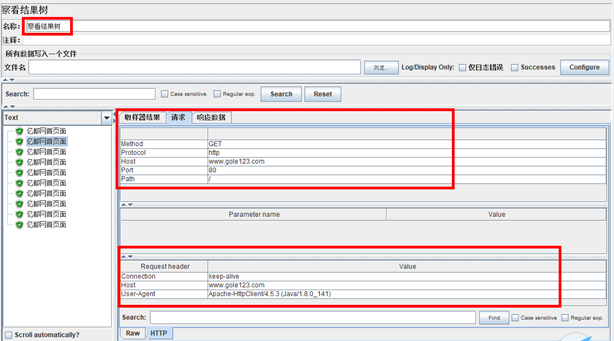
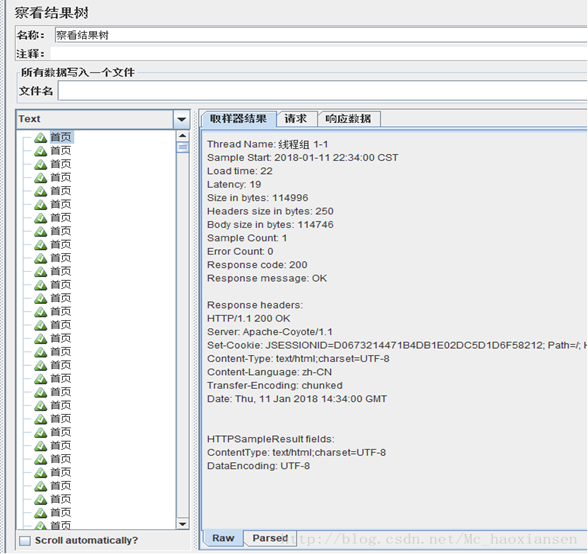
通过察看结果树,我们可以看到每个请求的结果,其中红色的是出错的请求,绿色的为通过。
Thread Name:线程组名称
Sample Start: 启动开始时间
Load time:加载时长
Latency:等待时长
Size in bytes:发送的数据总大小
Headers size in bytes:发送数据的其余部分大小
Sample Count:发送统计
Error Count:交互错误统计
Response code:返回码
Response message:返回信息
Response headers:返回的头部信息
8.聚合报告参数说明
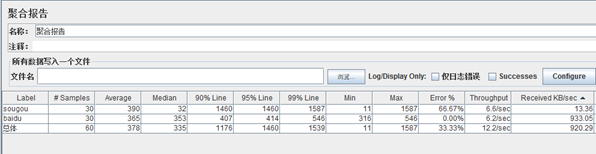
lable:对应每一个http请求,显示的是http请求的Name,如百度http请求name为baidu
#Samples:表示这一次的测试中一共发出了多少请求,如上图所示,sougou和baidu的http请求每个都发出30个请求
Average:平均响应时间,指的是所有的请求的平均响应时间,如上图的30个请求的总的响应时间除以30得出的平均响应时间,默认的情况下是单个请求的平均响应时间,但当使用了“事务控制器”时,则以事物为单位显示平均响应时间
Median:中位数,也就是50%用户的响应时间
90%Line:90%用户的响应时间
Min:最小响应时间
Max:最大的响应时间
Error%:本次测试中出现错误的请求的数量/请求的总数,如上图所示,本次的测试中,sougou的http请求66.6%的请求出错,而baidu的请求则没有出错的请求
Throughput:吞吐量,默认情况下表示每秒完成的请求数,如上图所示,每秒完成的请求数分别为6.6个每秒,6.2个每秒
Recived KB/Sec:每秒从服务器端接收到的数据量,以kb为计算的单位
9.图形结果
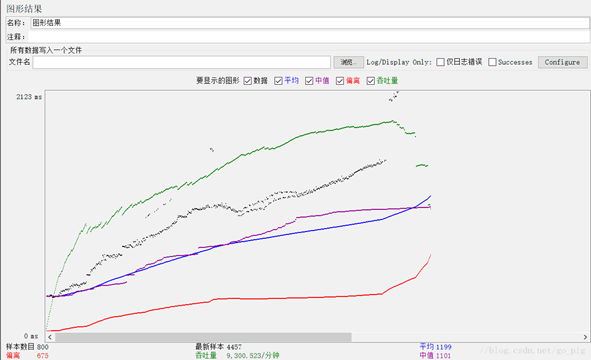
样本数目:总共发送到服务器的请求数。
最新样本:代表时间的数字,是服务器响应最后一个请求的时间。
吞吐量:服务器每分钟处理的请求数。
平均值:总运行时间除以发送到服务器的请求数。
中间值:有一半的服务器响应时间低于改值而另一半高于该值。
偏离:表示服务器响应时间变化、离散程度测量值的大小。
Jmeter主要组件介绍
1、测试计划是使用 JMeter 进行测试的起点,它是其它 JMeter 测试元件的容器。
2、线程组:代表一定数量的并发用户,它可以用来模拟并发用户发送请求。实际的请求内容在Sampler中定义,它被线程组包含。可以在“测试计划->添加->线程组”来建立它,然后在线程组面板里有几个输入栏:线程数、Ramp-Up Period(in seconds)、循环次数,其中Ramp-Up Period(in seconds)表示在这时间内创建完所有的线程。如有8个线程,Ramp-Up = 200秒,那么线程的启动时间间隔为200/8=25秒,这样的好处是:一开始不会对服务器有太大的负载。线程组是为模拟并发负载而设计。
3、取样器(Sampler):模拟各种请求。所有实际的测试任务都由取样器承担,存在很多种请求。如:HTTP 、ftp请求等等。
4、监听器:负责收集测试结果,同时也被告知了结果显示的方式。功能是对取样器的请求结果显示、统计一些数据(吞吐量、KB/S……)等。
5、逻辑控制器:允许自定义JMeter发送请求的行为逻辑,它与Sampler结合使用可以模拟复杂的请求序列。
6、断言:用于来判断请求响应的结果是否如用户所期望,是否正确。它可以用来隔离问题域,即在确保功能正确的前提下执行压力测试。这个限制对于有效的测试是非常有用的。
7、定时器:负责定义请求(线程)之间的延迟间隔,模拟对服务器的连续请求。
8、 配置元件维护Sampler需要的配置信息,并根据实际的需要会修改请求的内容。
9、前置处理器和后置处理器负责在生成请求之前和之后完成工作。前置处理器常常用来修改请求的设置,后置处理器则常常用来处理响应的数据。
1.测试计划

2.线程组
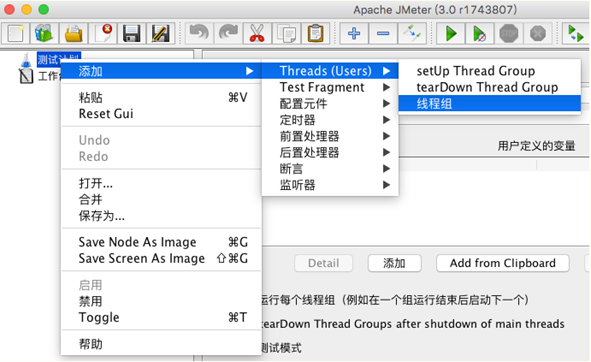
(1)、thread group(线程组)
这个就是我们通常添加运行的线程。通俗的讲一个线程组,可以看做一个虚拟用户组,线程组中的每个线程都可以理解为一个虚拟用户。
(2)、setup thread group
一种特殊类型的ThreadGroup的,可用于执行预测试操作。这些线程的行为完全像一个正常的线程组元件。不同的是,这些类型的线程执行测试前进行定期线程组的执行;类似LoadRunner的init,测试开始时进行初始化的工作。
(3)、teardown thread group
一种特殊类型的ThreadGroup的,可用于执行测试后动作。这些线程的行为完全像一个正常的线程组元件。不同的是,这些类型的线程执行测试结束后执行定期的线程组;类似LoadRunnner的end,测试结束时进行回收工作。
3. 取样器(Http请求)
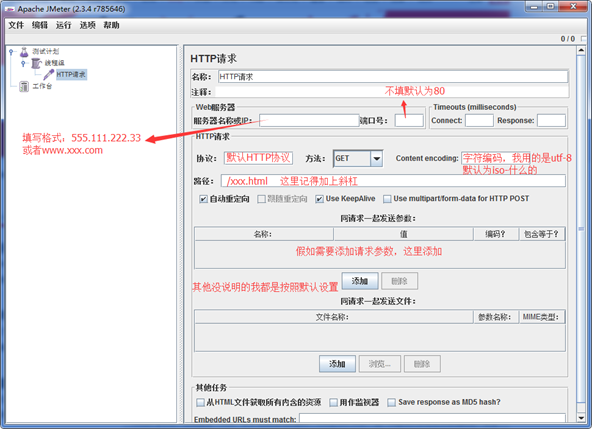
关于http请求的的属性参数说明:
1)名称:用于标识一个sample。建议使用一个有意义的名称
2)注释:对于测试没任何影响,仅用来记录用户可读的注释信息
3)服务器名称或IP:http请求发送的目标服务器名称或者IP地址,比如http://www.baidu.com
4)端口号:目标服务器的端口号,默认值为80,可不填
5)协议:向目标服务器发送http请求时的协议,http/https,大小写不敏感,默认http
6)方法:发送http请求的方法(链接:http://www.cnblogs.com/imyalost/p/5630940.html)
7)Content encoding:内容的编码方式(Content-Type=application/json;charset=utf-8)
8)路径:目标的URL路径(不包括服务器地址和端口)
9)自动重定向:如果选中该项,发出的http请求得到响应是301/302,jmeter会重定向到新的界面
10)Use keep Alive:jmeter 和目标服务器之间使用 Keep-Alive方式进行HTTP通信(默认选中)
11)Use multipart/from-data for HTTP POST :当发送HTTP POST 请求时,使用
12)Parameters、Body Data以及Files Upload的区别:
parameter是指函数定义中参数,而argument指的是函数调用时的实际参数
简略描述为:parameter=形参(formal parameter), argument=实参(actual parameter)
3.在不很严格的情况下,现在二者可以混用,一般用argument,而parameter则比较少用
While defining method, variables passed in the method are called parameters.
当定义方法时,传递到方法中的变量称为参数.
While using those methods, values passed to those variables are called arguments.
当调用方法时,传给变量的值称为引数.(有时argument被翻译为“引数“)
4、Body Data指的是实体数据,就是请求报文里面主体实体的内容,一般我们向服务器发送请求,携带的实体主体参数,可以写入这里
5、Files Upload指的是:从HTML文件获取所有有内含的资源:被选中时,发出HTTP请求并获得响应的HTML文件内容后还对该HTML
进行Parse 并获取HTML中包含的所有资源(图片、flash等):(默认不选中) 如果用户只希望获取特定资源,可以在下方的Embedded URLs must match 文本框中填入需要下载的特定资源表达式,只有能匹配指定正则表达式的URL指向资源会被下载4.监听器
监听器(Listener)负责收集测试结果,同时也被告知了结果显示的方式。我们常用的包括:聚合报告、查看结果树、用表格查看结果,都支持将结果数据写入文件。其他的添加上去看看就行。聚合报告前面我们介绍过,后面是查看结果树和用表格查看结果的截图。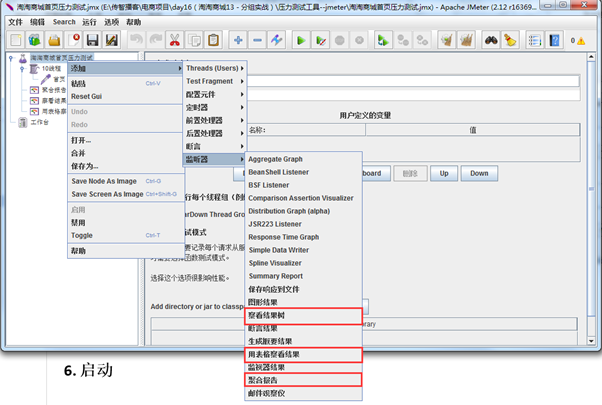
5. 逻辑控制器
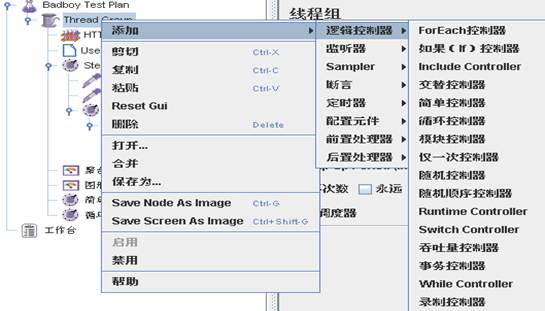
6.循环控制器、事务控制器

6.1循环控制器
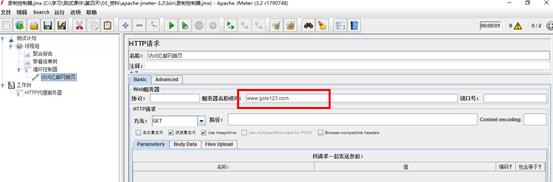
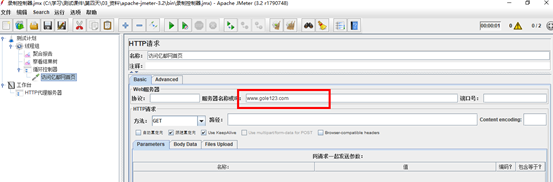
6.2. 事务控制器
作用: 事务控制器会生产一个额外的采样器,用来统计该控制器子结点的所有时间。
在线程组下创建事务控制器
参数:
• Generate parent sample:(选中这个参数结果展示如下图红框,否则显示为下图蓝框)
• Include duration of timer and pre-post processors in generated sample:选中这一项会统计定时器(timer)的时间,否则只统计采样器(sample)的时间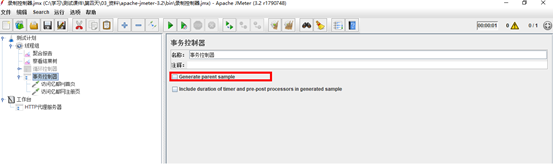
创建sample 访问首页和注册页面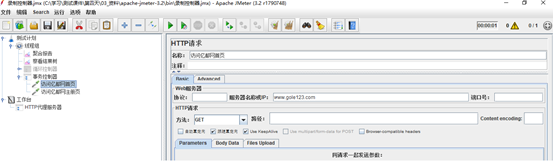
生成聚合报告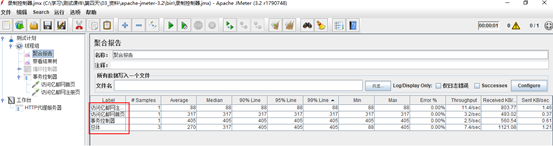
勾选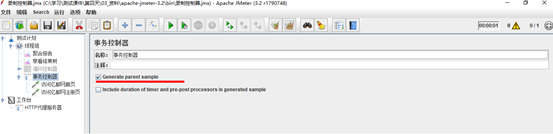
聚合报告中只有一项事务报告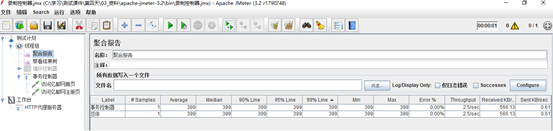
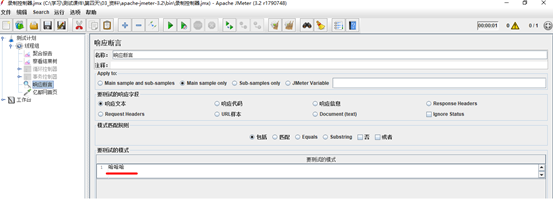
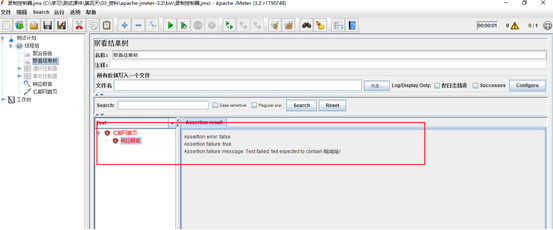
7.断言—检查点
断言(Assertions)可以用来判断请求响应的结果是否如用户所期望的。它可以用来隔离问题域,即在确保功能正确的前提下执行压力测试。这个限制对于有效的测试是非常有用的。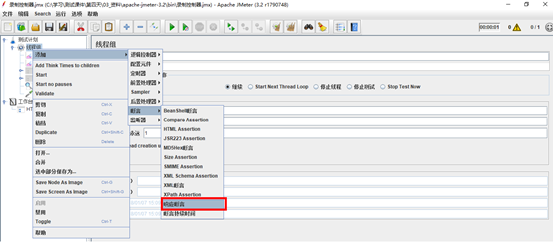
8.前置处理器和后置处理器
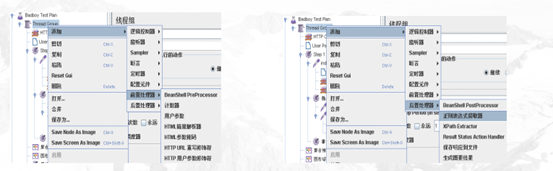
前置处理器(Pre Processors)和后置处理器(Post Processors)负责在生成请求之前和之后完成工作。前置处理器常常用来修改请求的设置,后置处理器则常常用来处理响应的数据。我们主要在动态关联中用到后置处理器的正则表达式提取器。
https://www.cnblogs.com/fengpingfan/p/4755411.html
9.定时器
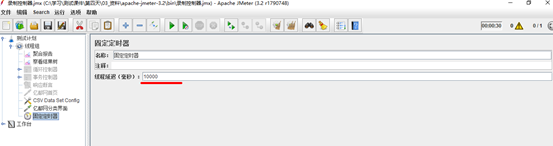
定时器(Timer)负责定义请求之间的延迟间隔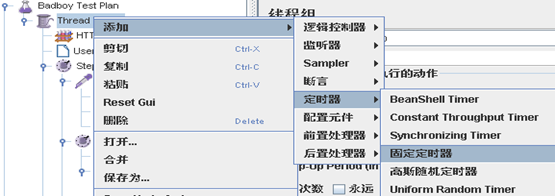
Jmeter组件参数化
1.参数化是什么
动态的获取并设置数据
2. 为什么使用参数化
执行批量操作,批量添加批量删除,人工效率太低
运用程序代替人工获取并设置数据,安全高效
比如:对被测系统的用户名和密码进行参数化,来模拟多个用户同时登录系统
3. 参数化实现之CSV Data Set Config
通过这个组件可以动态获取并设置数据,实现批量添加操作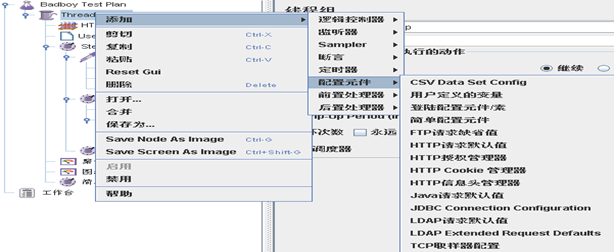
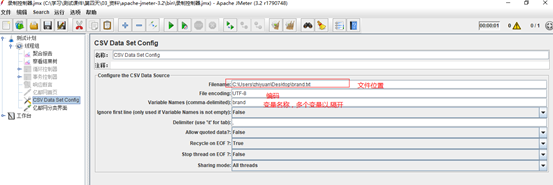
Filename:所需数据文件的路径。如和脚本同一路径,可直接填写文件名
File encoding:编码和文件保持一致即可,默认为ANSI。如有中文,建议为UTF-8
Variable Names:引用变量时的变量名,对应数据文件中的每一列,以逗号分隔。如不填写,文件的第一行数据将被读取为变量名
Delimiter:在.txt、.dat文件中,可以用逗号(,)或者Tab键(\t)来区分列与列
Allow quote data:选项选为“true”的时候对全角字符的处理出现乱码
Recycle on EOF:到数据文件结尾时是否循环读取。设置为True时,线程数过多,数据文件读取到最后一行时,会再次从第一行开始读取。设置为False,到达文件结尾时如继续读取,则值会默认为,可通过设置jmeter属性csvdataset.eofstring来改变该值。
Stop thread on EOF:Recycle on EOF设置为False,Stop thread on EOF设置为True,则读取数据文件最后一行后,停止测试,不管还有多少线程组未执行。
Sharing mode:共享模式。默认在所有线程组中使用,可选择每个线程组单独打开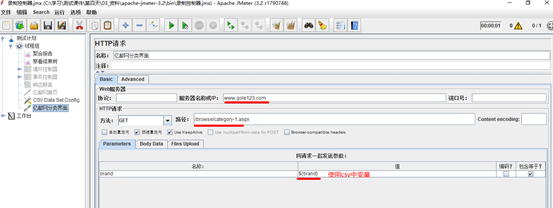
查看结果树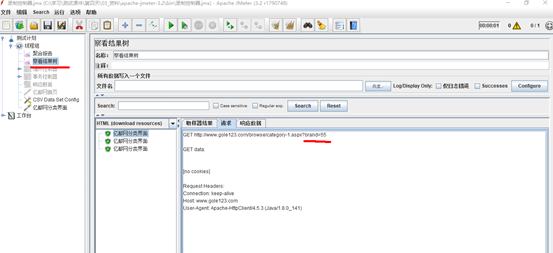
4.使用Jmeter函数助手
1、点击 选项-->函数助手 调出函数助手对话框2、选择 _CSVRead 函数(下图第一个框)
3、函数参数:
1)第一个参数:填写文件路径。
2)第二个参数:文件列号是从0开始的,第一列0、第二列1、第三列2、依次类推,然后点击【生成】按钮,则会自动生成我们需要的参数化函数。
3) 复制生成的参数化函数, copy过程需要使用的地方即可。
4) _Random函数是从某数据段随机读取数据替换参数,当需要添加多条数据记录且某些字段需要唯一性时使用。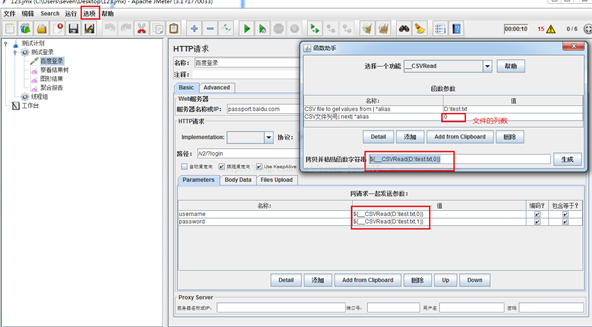
Jmeter脚本录制
1.什么是脚本录制
在进行测试的时候,可能有好多脚本或者界面需要操作测试,并且有些测试链接需要重复多线程高并发进行测试,我们一般会针对这一些操作,进行一个脚本录制,录制好之后,之后测试就可以在这个基础上进行测试。
2.Jemeter脚本录制方式
BadBoy脚本录制
使用Jmeter自带的代理服务器进行脚本录制
使用Jmeter自带的代理服务器进行脚本录制
1.在测试计划上创建线程组
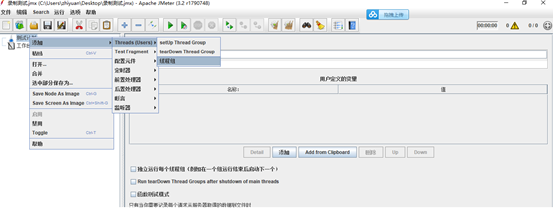
2.添加录制控制器
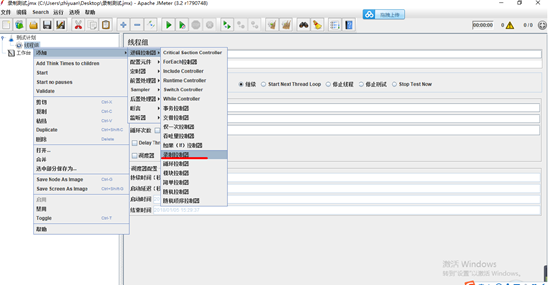
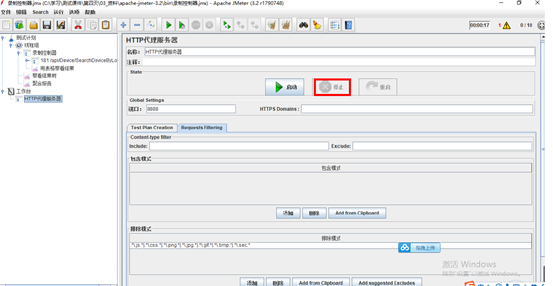
3.在工作台上添加http代理服务器
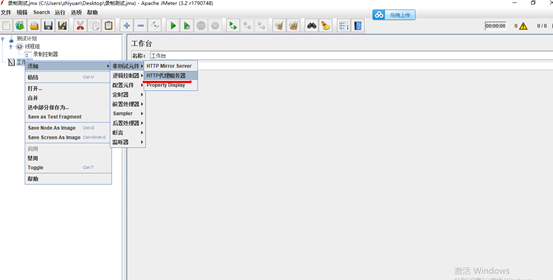
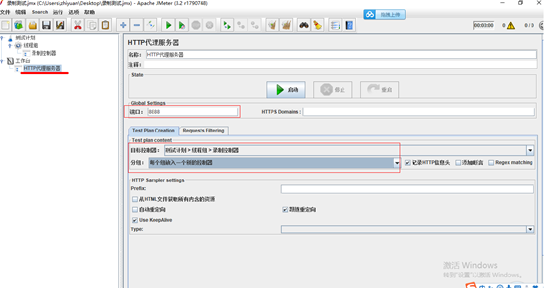
4.配置Http代理服务器
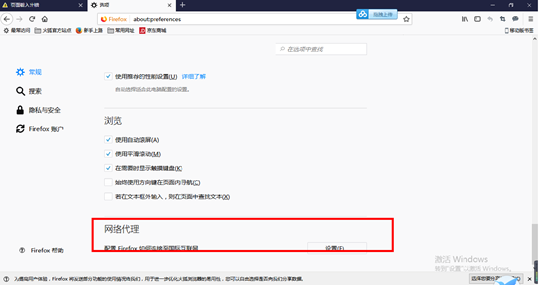
5.配置浏览器
5.1Google浏览器
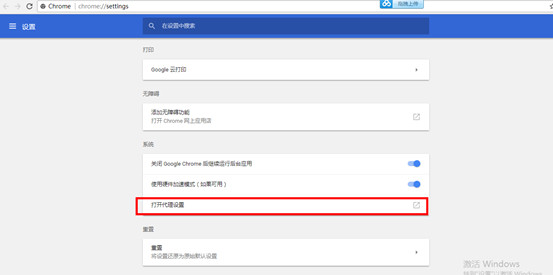
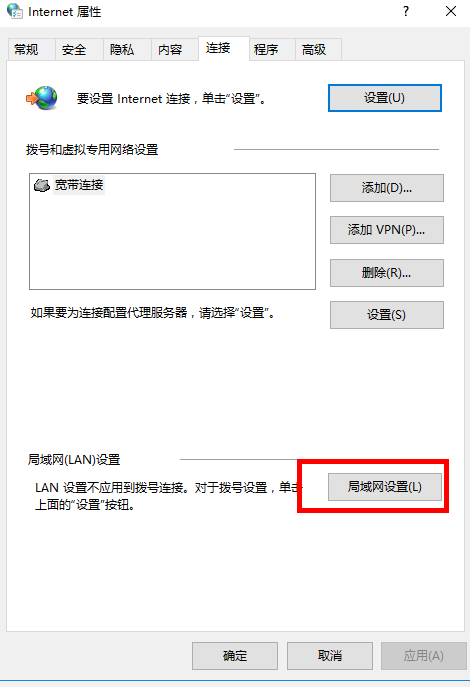
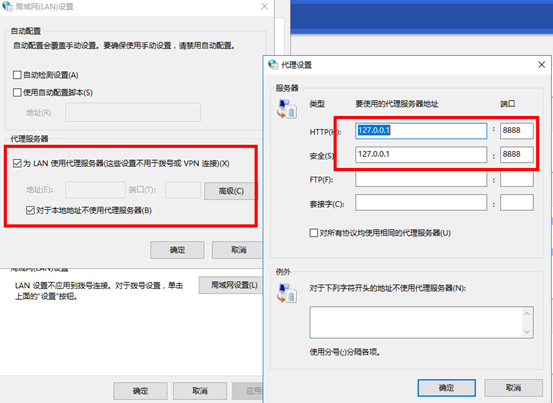
5.2火狐浏览器
6.浏览器请求测试
7.过滤信息
添加如下内容
..js.|..css.|..png.|..jpg.|..gif.|..bmp.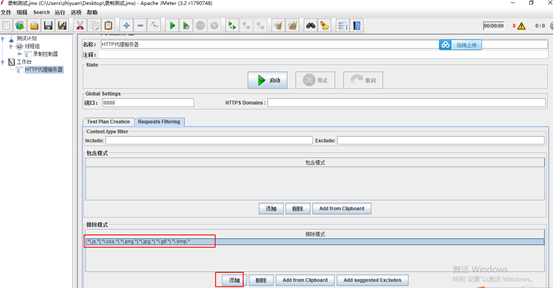
Android手机端脚本录制
1.查看电脑IP
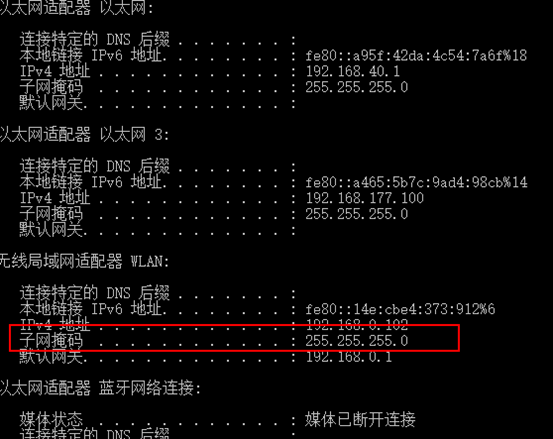
2.配置手机网路连接
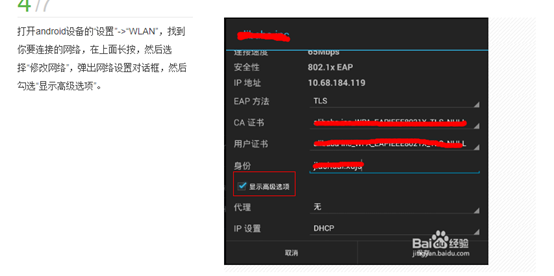
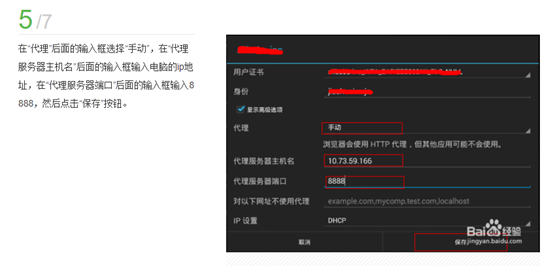
3.手机访问app
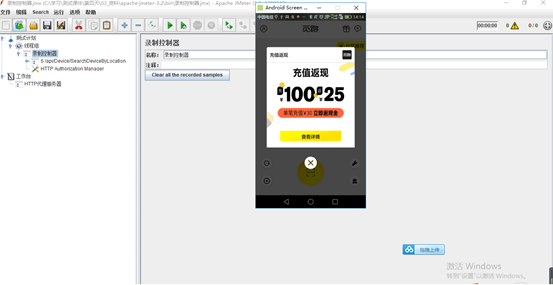
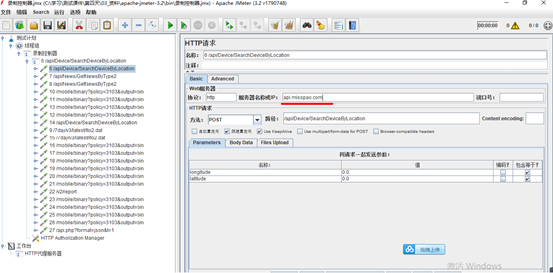
4.模拟登陆操作

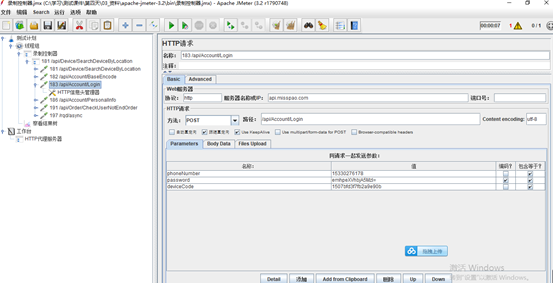
5.执行结束之后,停止脚本录制
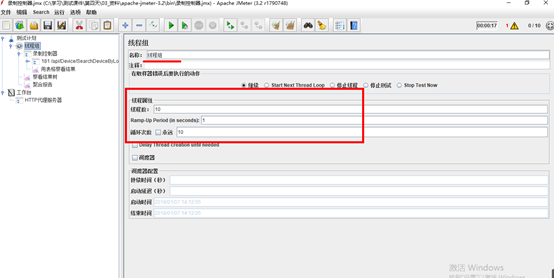
6.脚本测试-线程组设置10个线程分别请求10次
7.查看结果树
BadBoy脚本录制
1.安装badboy脚本软件
傻瓜式安装即可
2.打开badboy软件
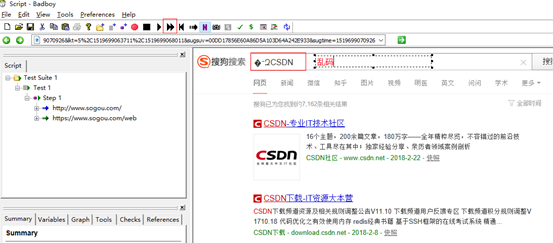
3.badboy脚本录制
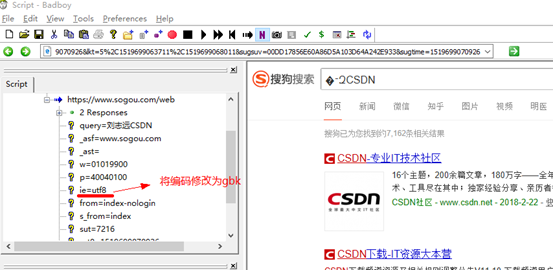
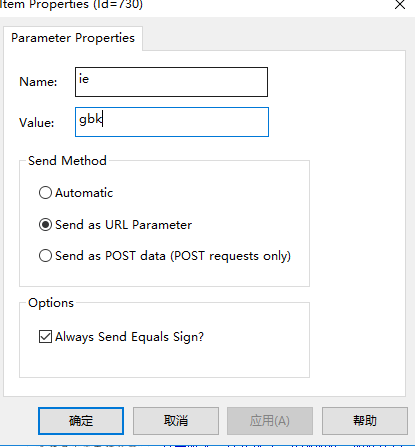
点击录制按钮进行脚本录制,完成打开搜狗搜索,搜索测试岗位薪资操作,然后停止,回放,(回放的时候,会因为编码原因导致乱码,需要手动调乱码问题)
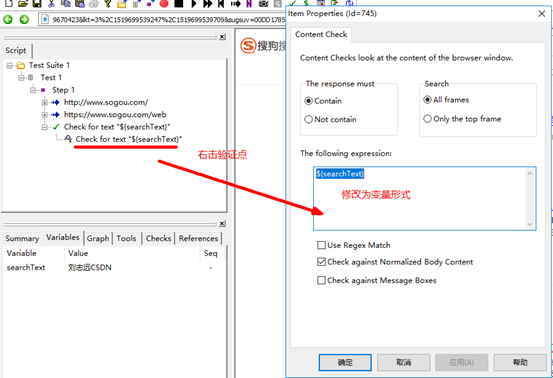
4.添加验证点
验证点的作用就是验证脚本是否按照我们测试的思路执行,判断脚本执行过程中是否存现问题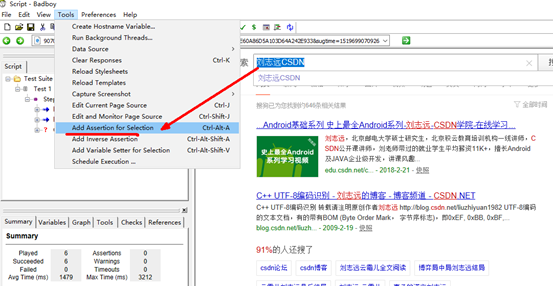
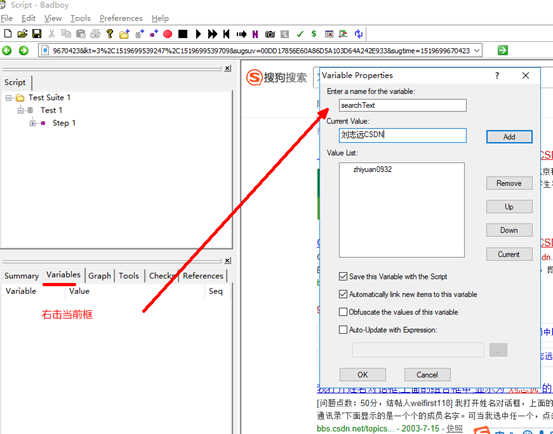
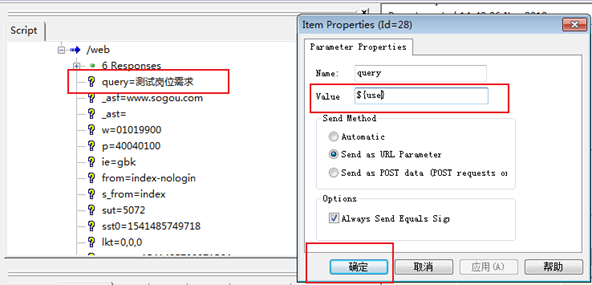
5.badboy参数化
所谓参数化,是指请求的某个参数提前设定多个值,在具体请求的时候,去获取提前设定的值,不同的业务场景设置的参数不一致。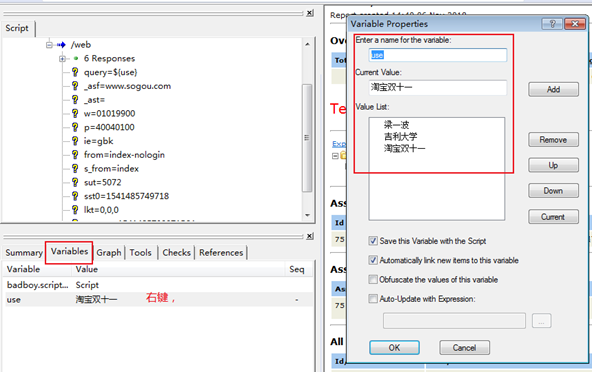
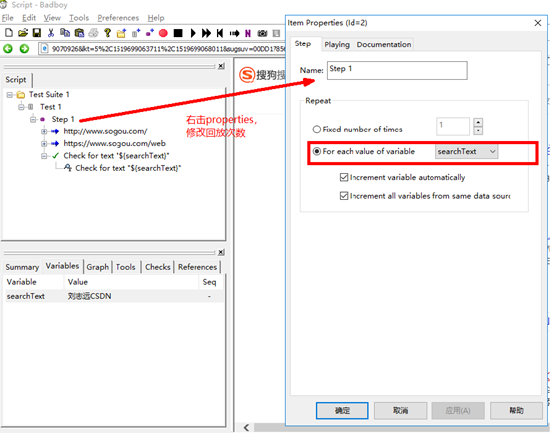
6.导出Jmeter脚本
7.在Jmeter中导入badboy生成的脚本,验证测试
8.badboy并发测试
选择tools run background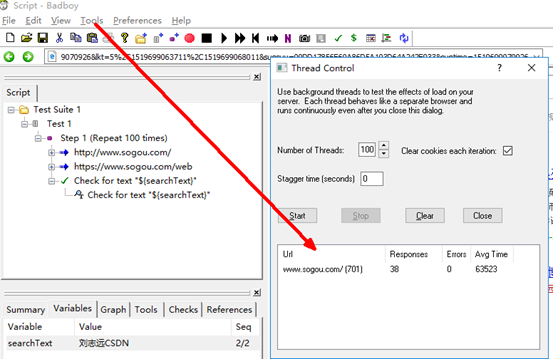
9.badboy测试报告
在badboy–>view—>report下可以看到测试报告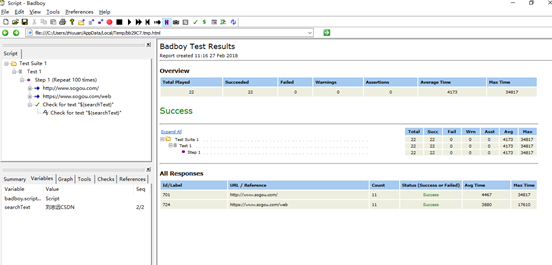
Jmeter扩展插件-显示内存效果图
Jmeter本身是不能够展示内存,cpu和吞吐量的,但是可以通过添加插件的方式来对jmeter添加这些功能
https://www.cnblogs.com/imyalost/p/7751981.html
JMeter之ServerAgent监控资源
1.对linux服务器的服务进行压测
1.1资源准备
可通过该网址下载jmeter所有插件http://jmeter-plugins.org/downloads/all/
本次所需插件:
JMeterPlugins-Extras.jar
JMeterPlugins-Standard.jar
ServerAgent-2.2.1
将JMeterPlugins-Extras.jar和JMeterPlugins-Standard.jar放到apache-jmeter-3.0\lib\ext目录下
将ServerAgent-2.2.1放到linux服务器opt目录下
1.2环境准备
ServerAgent服务端口号默认为4444,需要设置防火墙对此端口不拦截:vi /etc/sysconfig/iptables,在端口22下面添加 iptables -I INPUT -p tcp --dport 4444 -j ACCEPT //允许4444端口访问
然后在服务器中启动监控服务: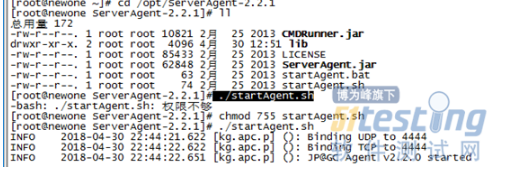
使用以下命令可以改变默认的4444端口
java -jar ./CMDRunner.jar --tool PerfMonAgent --udp-port 7777 --tcp-port 7777
同样的,7777端口也要设置防火墙规则以及使用telnet本地测试下是否可以访问
2.windows本机进行监听

先在服务器上开启server的监听
开始演示效果
jp@gc - Bytes Throughput Over Time:不同时间吞吐量(字节Bytes)展示(图表)
聚合报告里,Throughput是按请求个数来展示的,比如说1.9/sec,就是每s发送1.9个请求;而这里的展示是按字节Bytes来展示的图表,表示每秒发送多少字节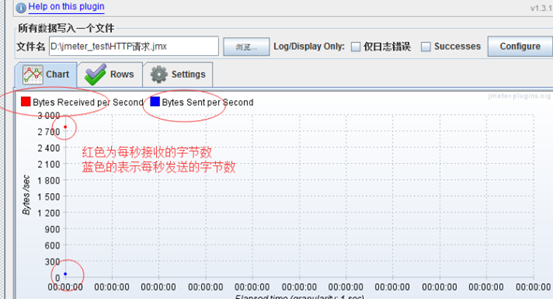
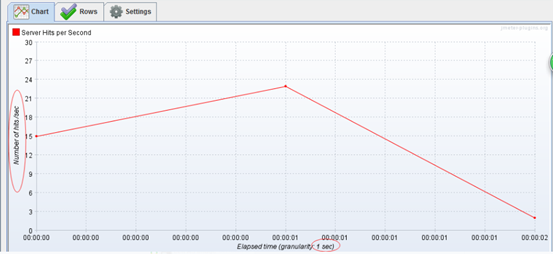
jp@gc - Hits per Second:每秒点击量

jp@gc - PerfMon Metrics Collector:服务器性能监测控件,包括CPU,Memory,Network,I/O等等(此功能用到在需监听的服务器上启动startAgent)
根据需要选择CPU,Memory,Network I/O等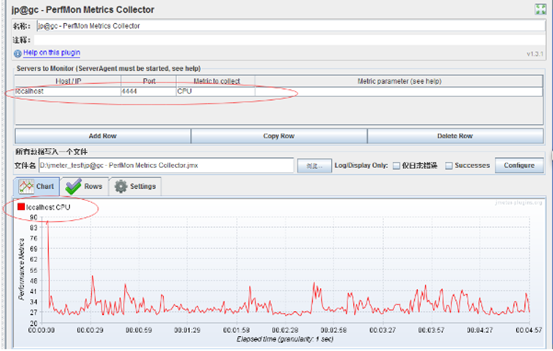
Jmeter数据库压力测试
1.启动jmeter,打开界面工具,添加一个线程组,添加驱动
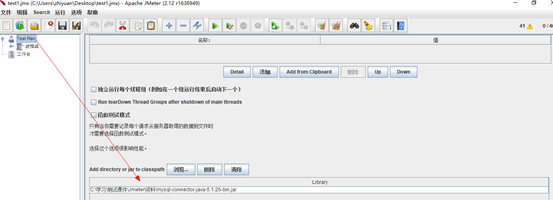
2.添加一个JDBC Connection Configuration,连接池配置文件。右键线程组【添加】–【配置元件】–【JDBC Connection Configuration】
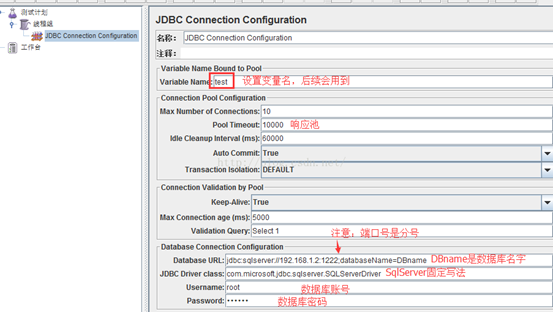
Variable Name:连接池名称。JDBC Request会通过此名称来获取连接池的配置,名称可以随意填写,但是最好具体实际的业务意义,方便理解和记忆。
其他的可以默认,可以根据实际情况来调节优化性能。
Database URL:数据链接url,格式:jdbc:mysql://localhost:3306/host
注释:数据库的ip地址+端口/数据库名(查询数据库端口号show global variables like ‘port’)
JDBC Driver Class:驱动器名称。固定:com.mysql.jdbc.Driver
Username:用户名
Passowrd:密码
添加一个JDBC Request。
3.右键线程组【添加】-【Sampler】-【JDBC Request】
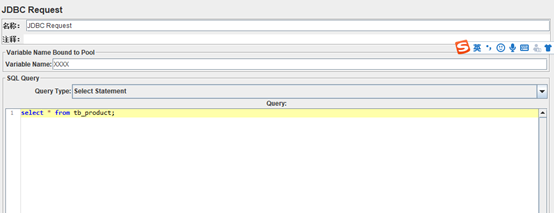
Select Statement:查询语句
Updata Statement:更新语句
Prepared Select Statement:预编译查询语句。(长时间执行效率更高,支持占位符)
Prepared Update Statement:预编译更新语句。(同上)
Commit (立即提交)Rollback(回滚)
Parameter values:参数值。参数化sql语句中的值。故输入:localhost,root
Paramter types:参数类型。数据库的参数你可以去查看一下。这里是两个CHAR,CHAR类型。
Variable names:变量名字,也就是将筛选出来的值放在变量里面。例如这三列数据分为放在变量:A,B,C中(实际操作中命名一定要有实际意义)。
Result variable name:存储变量名。将整个结果存储在变量中。取名:rs
Query timeouts :超时时间。
Jmeter正则表达式提取
1.badboy录制脚本
2.将脚本导出到jmeter
3.回放时候失败-session过期
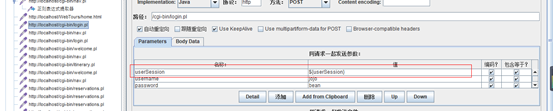
4.查看返回信息,查找userSession
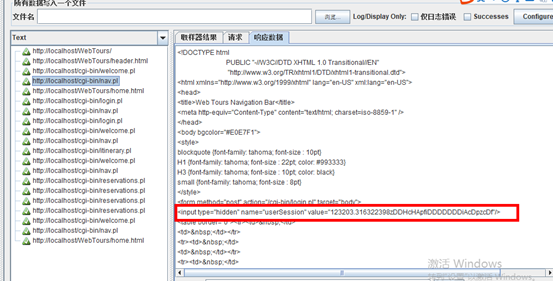
5.使用正则提取
运用Jmeter正则提取器,可以从请求的响应结果中取到需要的内容,从而实现关联。关联是请求与请求之间存在数据依赖关系,需要从上一个请求获取下一个请求需要回传回去的数据
位置1:名称及注释
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?” 可以匹配 “do” 、 “does” 中的 “does” 、 “doxy” 中的 “do” 。? 等价于 {0,1}。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \ . 。 |
构造正则表达式的方法和创建数学表达式的方法一样。也就是用多种元字符与运算符可以将小的表达式结合在一起来创建更大的表达式。正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
位置2:正则表达式提取的相关设置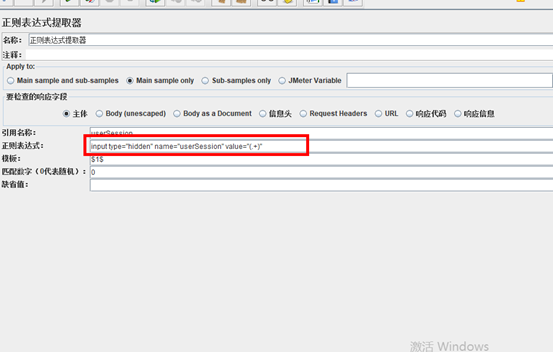
说明:
(1)引用名称:下一个请求要引用的参数名称,如填写title,则可用 t i t l e 引 用 它 。 ( 2 ) 正 则 表 达 式 : ( ) : 括 起 来 的 部 分 就 是 要 提 取 的 。 . : 匹 配 任 何 字 符 串 。 + : 一 次 或 多 次 。 ? : 不 要 太 贪 婪 , 在 找 到 第 一 个 匹 配 项 后 停 止 。 ( 3 ) 模 板 : 用 {title}引用它。 (2)正则表达式: ():括起来的部分就是要提取的。 .:匹配任何字符串。 +:一次或多次。 ?:不要太贪婪,在找到第一个匹配项后停止。 (3)模板:用 title引用它。(2)正则表达式:():括起来的部分就是要提取的。.:匹配任何字符串。+:一次或多次。?:不要太贪婪,在找到第一个匹配项后停止。(3)模板:用$引用起来,如果在正则表达式中有多个正则表达式,则可以是 2 2 2 3 3 3等等,表示解析到的第几个值给title。如: 1 1 1表示解析到的第1个值
(4)匹配数字:0代表随机取值,1代表全部取值,通常情况下填0
(5)缺省值:如果参数没有取得到值,那默认给一个值让它取。
6.使用参数化