文章目录
前言sleep题目分析与代码 pingpong题目分析与代码 primes题目分析与代码 find题目分析与代码 xargs题目分析与代码
前言
在这个lab中我们会先学习操作系统中的系统调用是如何运用的,并实际运用这些系统调用来编写一些程序
sleep
题目
Implement the UNIX program sleep for xv6; your sleep should pause for a user-specified number of ticks. A tick is a notion of time defined by the xv6 kernel, namely the time between two interrupts from the timer chip. Your solution should be in the file user/sleep.c.
Some hints:
Before you start coding, read Chapter 1 of the xv6 book.Look at some of the other programs inuser/ (e.g., user/echo.c, user/grep.c, and user/rm.c) to see how you can obtain the command-line arguments passed to a program.If the user forgets to pass an argument, sleep should print an error message.The command-line argument is passed as a string; you can convert it to an integer using atoi (see user/ulib.c).Use the system call sleep.See kernel/sysproc.c for the xv6 kernel code that implements the sleep system call (look for sys_sleep), user/user.h for the C definition of sleep callable from a user program, and user/usys.S for the assembler code that jumps from user code into the kernel for sleep.main should call exit(0) when it is done.Add your sleep program to UPROGS in Makefile; once you’ve done that, make qemu will compile your program and you’ll be able to run it from the xv6 shell.Look at Kernighan and Ritchie’s book The C programming language (second edition) (K&R) to learn about C. Run the program from the xv6 shell:
$ make qemu ... init: starting sh $ sleep 10 (nothing happens for a little while) $Your solution is correct if your program pauses when run as shown above. Run make grade to see if you indeed pass the sleep tests.
Note that make grade runs all tests, including the ones for the assignments below. If you want to run the grade tests for one assignment, type:
$ ./grade-lab-util sleepThis will run the grade tests that match “sleep”. Or, you can type:
$ make GRADEFLAGS=sleep grade
which does the same.
分析与代码
我们需要使用运用sleep系统调用来使程序休眠
atoi将字符串转化成数字 ls -asleep 10程序名后面就是我们在程序里面需要是使用到的一些参数
sleep 10
int main(int argc,char* argv[]){int num=aoti(argv[1]);}在argv里面就是用户传入的命令行参数
把我们的sleep程序添加到makefile里面去UPROGS=\...$U/_sleep\#include "user/user.h"#include"kernel/types.h"int main(int argc, char *argv[]){ if (argc != 2) { fprintf(2, "sleep error\n"); exit(0); } else { // int time = atoi(argv[1]); sleep(atoi(argv[1])); } exit(0);}pingpong
题目
Write a program that uses UNIX system calls to ‘‘ping-pong’’ a byte between two processes over a pair of pipes, one for each direction. The parent should send a byte to the child; the child should print “: received ping”, where is its process ID, write the byte on the pipe to the parent, and exit; the parent should read the byte from the child, print “: received pong”, and exit. Your solution should be in the file user/pingpong.c.
Some hints:
Use pipe to create a pipe.Use fork to create a child.Use read to read from a pipe, and write to write to a pipe.Use getpid to find the process ID of the calling process.Add the program to UPROGS in Makefile.User programs on xv6 have a limited set of library functions available to them. You can see the list in user/user.h; the source (other than for system calls) is in * user/ulib.c, user/printf.c, and user/umalloc.c.Run the program from the xv6 shell and it should produce the following output:
$ make qemu...init: starting sh$ pingpong4: received ping3: received pong$Your solution is correct if your program exchanges a byte between two processes and produces output as shown above.
分析与代码
我们需要使用管道来实现进程间通信,父进程给子进程发送ping,子进程给父进程发送pong
管道是单向通信的,所以只能一端发送,一端接受,无法实现全双工我们可以使用pipe系统调用来创建管道,使用fork来创建子进程使用read来从管道里面读取数据,write可以向管道里面写数据使用getpid来获取进程的pid将pingpong程序添加到makefile里面 UPROGS=\...$U/_pingpong\...#include "user/user.h"int main(int argc, char *argv[]){ //用两个管道来连接父子进程 int fd1[2];//给子进程读 int fd2[2];//给父进程 pipe(fd1); pipe(fd2); if (fork() == 0) { // child char buf[5]; int n = read(fd1[0], buf, sizeof(buf) - 1); if (n <= 0) { exit(1); } else { int pid = getpid(); buf[n] = 0; printf("%d: received %s\n", pid,buf); write(fd2[1], "pong", 5); } // 4 receive ping } else { // father write(fd1[1], "ping", 5); char buf[5]; int n = read(fd2[0], buf, sizeof(buf) - 1); wait(0);//我们需要子进程先输出,后wait等待他退出,再进行输出父进程 if (n <= 0) { exit(1); } else { int pid = getpid(); buf[n] = 0; // printf("buf=%s\n",buf); printf("%d: received %s\n", pid,buf); } } exit(0);}primes
题目
Write a concurrent version of prime sieve using pipes. This idea is due to Doug McIlroy, inventor of Unix pipes. The picture halfway down this page and the surrounding text explain how to do it. Your solution should be in the file user/primes.c.
Your goal is to use pipe and fork to set up the pipeline. The first process feeds the numbers 2 through 35 into the pipeline. For each prime number, you will arrange to create one process that reads from its left neighbor over a pipe and writes to its right neighbor over another pipe. Since xv6 has limited number of file descriptors and processes, the first process can stop at 35.
Some hints:
Be careful to close file descriptors that a process doesn’t need, because otherwise your program will run xv6 out of resources before the first process reaches 35.Once the first process reaches 35, it should wait until the entire pipeline terminates, including all children, grandchildren, &c. Thus the main primes process should only exit after all the output has been printed, and after all the other primes processes have exited.Hint: read returns zero when the write-side of a pipe is closed.It’s simplest to directly write 32-bit (4-byte) ints to the pipes, rather than using formatted ASCII I/O.You should create the processes in the pipeline only as they are needed.Add the program to UPROGS in Makefile.Your solution is correct if it implements a pipe-based sieve and produces the following output:
$ make qemu...init: starting sh$ primesprime 2prime 3prime 5prime 7prime 11prime 13prime 17prime 19prime 23prime 29prime 31$分析与代码
这个题就是让我们使用管道多进程来进行素数的筛选,每一个进程中可以使用管道接受其父进程给他发送来的数据,其中第一个元素一定是一个素数,每个管道把他们接收到的第一个数打印出来,我们只需要赛选出2-35间的素数就行了
类似于欧式素数赛选法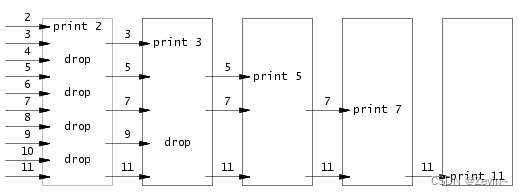
int大小,子进程进行循环读取管道数据我们只有当这一轮的素数都赛选完之后,再创建一个进程我们在发送的时候需要把管道对应的读端关闭,同样在读取的时候也是需要把写端关闭我们需要注意,如果是最后一个进程,就需要返回我们需要判断,如果是最后一个进程(后面循环读取0次),就需要给管道里面发送一个数据(比如0(因为数字里面没有0,所以可以作为结束的标志),关闭管道的所有东西,返回),同时执行close(fd)的操作,避免内存泄漏我们把读取的第一个数字打印出来,后面记录又读取了多少次,就发送多少数据给管道,在每次递归里面创建管道,给下一个管道发数据,从上一个管道里面读数据 #include "user/user.h"void pipecmd(int *inpipe){ int pipefd[2]; pipe(pipefd); int firstprime; int n = read(inpipe[0], &firstprime, sizeof(int)); if(firstprime==0) { close(pipefd[0]); close(pipefd[1]); // exit(0); return; } printf("prime %d\n", firstprime); if (fork() == 0) { close(pipefd[1]); pipecmd(pipefd); // exit(0); } int innum; int runtime = 0; while (n = read(inpipe[0], &innum, sizeof(int))) { // printf("%d ", innum); if (innum % firstprime) { int x = innum; close(pipefd[0]); write(pipefd[1], &x, sizeof(int)); } runtime++; } close(pipefd[1]); if (runtime == 0) { close(pipefd[0]); int x=0; write(pipefd[1],&x,sizeof(int)); // exit(0); } // printf("\n"); wait(0);}int main(){ int rpipe[2]; pipe(rpipe); if (fork() == 0) { close(rpipe[1]); pipecmd(rpipe); // exit(0); } else { printf("prime %d\n", 2); close(rpipe[0]); for (int i = 3; i < 36; i++) { if (i % 2) { int x = i; // printf("%d\n",i); write(rpipe[1], &x, sizeof(int)); } } close(rpipe[1]); wait(0); exit(0); }}find
题目
Write a simple version of the UNIX find program: find all the files in a directory tree with a specific name. Your solution should be in the file user/find.c.
Some hints:
Look at user/ls.c to see how to read directories.Use recursion to allow find to descend into sub-directories.Don’t recurse into “.” and “…”.Changes to the file system persist across runs of qemu; to get a clean file system run make clean and then make qemu.You’ll need to use C strings. Have a look at K&R (the C book), for example Section 5.5.Note that == does not compare strings like in Python. Use strcmp() instead.Add the program to UPROGS in Makefile.Your solution is correct if produces the following output (when the file system contains the files b, a/b and a/aa/b):
$ make qemu...init: starting sh$ echo > b$ mkdir a$ echo > a/b$ mkdir a/aa$ echo > a/aa/b$ find . b./b./a/b./a/aa/b$分析与代码
这个题就是和ls -R | grep “xxxxxxx”一样,递归的遍历一个目录下的所有文件,查找所有名字包含xxxxxx的文件
我们可以查看user/ls.c里面看xv6是如何实现ls的使用递归来遍历目录下的所有文件忽视掉"."和“…”这两个目录,避免循环调用使用strcmp来比较两个字符串如果是目录就需要进入,如果不是一个目录,就直接可以跳过了,我们还需要实现字符串的拼接使用一个目录之前需要先open使用struct dirent 可以获得这个目录的所有数据使用struct stat 可以获得这个文件的所有数据我们在每次遍历目录下文件的时候,进行参数匹配如果是我们需要的文件,就打印出来 #include "kernel/types.h"#include "kernel/stat.h"#include "user/user.h"#include "kernel/fs.h"//单一个目录下什么东西都没有时候,就返回void display_R(char *dir, char *cmpfile);char *fmtname(char *path) //获得文件名{ static char buf[DIRSIZ]; char *p; // Find first character after last slash. //在最后一个/后面找到第一个字符 // ls hello/sad 找到sad这个文件名 for (p = path + strlen(path); p >= path && *p != '/'; p--) ; p++; // p指向/后面的字符 // Return blank-padded name. if (strlen(p) >= DIRSIZ) // p后面太大了,直接返回 return p; memmove(buf, p, strlen(p)); //把p的内容拷贝到buf里面sad memset(buf + strlen(p), '\0', DIRSIZ - strlen(p)); //后面全部给空,14个字符 return buf;}void isfile(char *dirpath, char *cmpfile){ char buf[128], *p; int fd; struct dirent de; struct stat st; if ((fd = open(dirpath, 0)) < 0) { fprintf(2, "ls: cannot open %s\n", dirpath); return; } if (fstat(fd, &st) < 0) { fprintf(2, "ls: cannot stat %s\n", dirpath); close(fd); return; } //打开的获得的东西 if (st.type == T_DEVICE || st.type == T_FILE) //设备 { //文件,直接就是一个文件名 close(fd); return; } else if (st.type == T_DIR) { if (strlen(dirpath) + 1 + DIRSIZ + 1 > sizeof buf) { //目录的路径名太长了 printf("ls: path too long\n"); } else { strcpy(buf, dirpath); //把路径拷贝到buf里面 p = buf + strlen(buf); // *p++ = '/'; //一个目录名后面加上 int time = 0; while (read(fd, &de, sizeof(de)) == sizeof(de)) { //读取目录 if (de.inum == 0) continue; if (strcmp(de.name, ".") == 0 || strcmp(de.name, "..") == 0 || de.name[0] == '.') { continue; } // printf("pbuf=%s\n",buf); memmove(p, de.name, DIRSIZ); //把目录下的文件名输出 p[DIRSIZ] = 0; //用p来保存 if (strcmp(fmtname(buf), cmpfile) == 0) { printf("%s\n", buf); //./as获得文件名,1代表的就是目录 } time++; //已经能打印当前目录了 //现在就是要去实现递归的打印下面的所有目录 } if (time) { display_R(dirpath, cmpfile); //这里的buf就是 } } //把他下面的所有东西都打印完了 //因为他是目录,所以要考虑他下面还有目录,所以我们要进入他里面 close(fd); }}//因为是目录,所以才会走到这里void display_R(char *dir, char *cmpfile){ char buf[128], *p; int fd; struct dirent de; if ((fd = open(dir, 0)) < 0) //把这个目录打开 { fprintf(2, "ls: cannot open %s\n", dir); return; } strcpy(buf, dir); //把路径拷贝到buf里面 p = buf + strlen(buf); // *p++ = '/'; //一个目录名后面加上 while (read(fd, &de, sizeof(de)) == sizeof(de)) { //读取目录 if (de.inum == 0) continue; if (strcmp(de.name, ".") == 0 || strcmp(de.name, "..") == 0 || de.name[0] == '.') { continue; } memmove(p, de.name, DIRSIZ); //把目录下的文件名输出 p[DIRSIZ] = 0; //用p来保存 // p[strlen(buf)] = 0; //用p来保存 isfile(buf, cmpfile); //这里的buf就已经组合上了后面的文件名 } close(fd); return;}int main(int argc, char *argv[]){ if (argc != 3) { printf("ls [directory] [filename]\n"); exit(1); } char dstdir[32]; char cmpfile[32]; strcpy(dstdir, argv[1]); strcpy(cmpfile, argv[2]); isfile(argv[1], argv[2]); //用来打印文件 exit(0);}xargs
题目
Write a simple version of the UNIX xargs program: its arguments describe a command to run, it reads lines from the standard input, and it runs the command for each line, appending the line to the command’s arguments. Your solution should be in the file user/xargs.c.
The following example illustrates xarg’s behavior:
$ echo hello too | xargs echo bye
bye hello too
$
Note that the command here is “echo bye” and the additional arguments are “hello too”, making the command “echo bye hello too”, which outputs “bye hello too”.
Please note that xargs on UNIX makes an optimization where it will feed more than argument to the command at a time. We don’t expect you to make this optimization. To make xargs on UNIX behave the way we want it to for this lab, please run it with the -n option set to 1. For instance
$ (echo 1 ; echo 2) | xargs -n 1 echo12$Some hints:
Use fork and exec to invoke the command on each line of input. Use wait in the parent to wait for the child to complete the command.To read individual lines of input, read a character at a time until a newline (‘\n’) appears.kernel/param.h declares MAXARG, which may be useful if you need to declare an argv array.Add the program to UPROGS in Makefile.Changes to the file system persist across runs of qemu; to get a clean file system run make clean and then make qemu.xargs, find, and grep combine well:
$ find . b | xargs grep hello
will run “grep hello” on each file named b in the directories below “.”.
To test your solution for xargs, run the shell script xargstest.sh. Your solution is correct if it produces the following output:
$ make qemu
…
init: starting sh
$ sh < xargstest.sh
$ $ $ $ $ $ hello
hello
hello
$ $
You may have to go back and fix bugs in your find program. The output has many $ because the xv6 shell doesn’t realize it is processing commands from a file instead of from the console, and prints a $ for each command in the file.
分析与代码
当我们执行xargs的时候,管道前的数据都是xv6帮我们执行好,我们在程序里面只需要使用read(0),从标准输入读取即可,而我们在程序里面需要执行的是xargs后面的程序
在xv6里面输入 echo hello too | xargs echo bye,我们实际main里面argv[0]=“xargs”,不包含前面的那些我们需要把前面执行的结果通过标准输入进行读取,拼接到一个字符串里面,加入到exec数组的后面一次子读取一个字节,当读取到\n说明这一行数据已经读取完了,我们就可以执行exec了如果最后read=0,说明全部读取完了,程序就结束了,退出#include "kernel/param.h"#include "user/user.h"#include "kernel/types.h"#include "kernel/fcntl.h"// MAXARGS,用来声明argv数组// echo 1 | xargs echo bye//这里的xargs就是把管道前面的输出东西添加到了xargs后面的命令去int main(int argc, char *argv[]){ char *parm[MAXARG]; int i; for (i = 1; i < argc; i++) { parm[i - 1] = argv[i]; } parm[i - 1] = 0; char readchar; int n = 0; int flag = 1; while (1) { char buf[128]; memset(buf, 0, sizeof(buf)); char *p = buf; while (n = read(0, (char*)&readchar, 1)) { if (readchar == '\n') { parm[i - 1] = buf; parm[i] = 0; //这里执行完了 break; } else { *p = readchar; p++; } } if (fork() == 0) { exec(parm[0], parm); } else { wait(0); } if (n == 0) { break; } } exit(0);}