文章目录
前言一、需求二、分析三、处理四、总结
前言
为了更好的掌握数据处理的能力,因而开启Python网络爬虫系列小项目文章。
小项目小需求驱动总结各种方式 页面源代码返回数据(Xpath、Bs4、PyQuery、正则)接口返回数据一、需求
获取一品威客任务数据获取码市需求任务获取软件项目交易网需求任务获取YesPMP平台需求任务二、分析
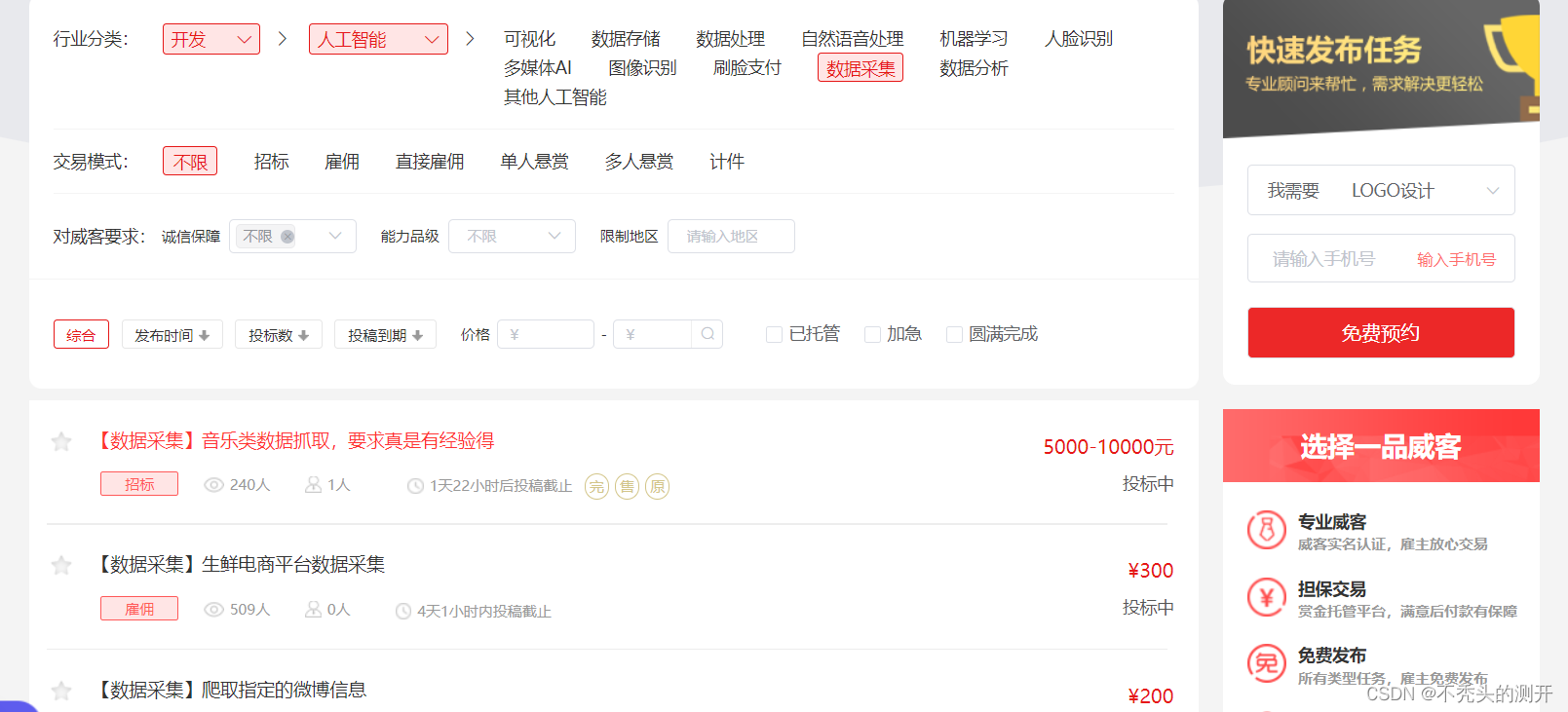
一品威客
1、查看网页源代码
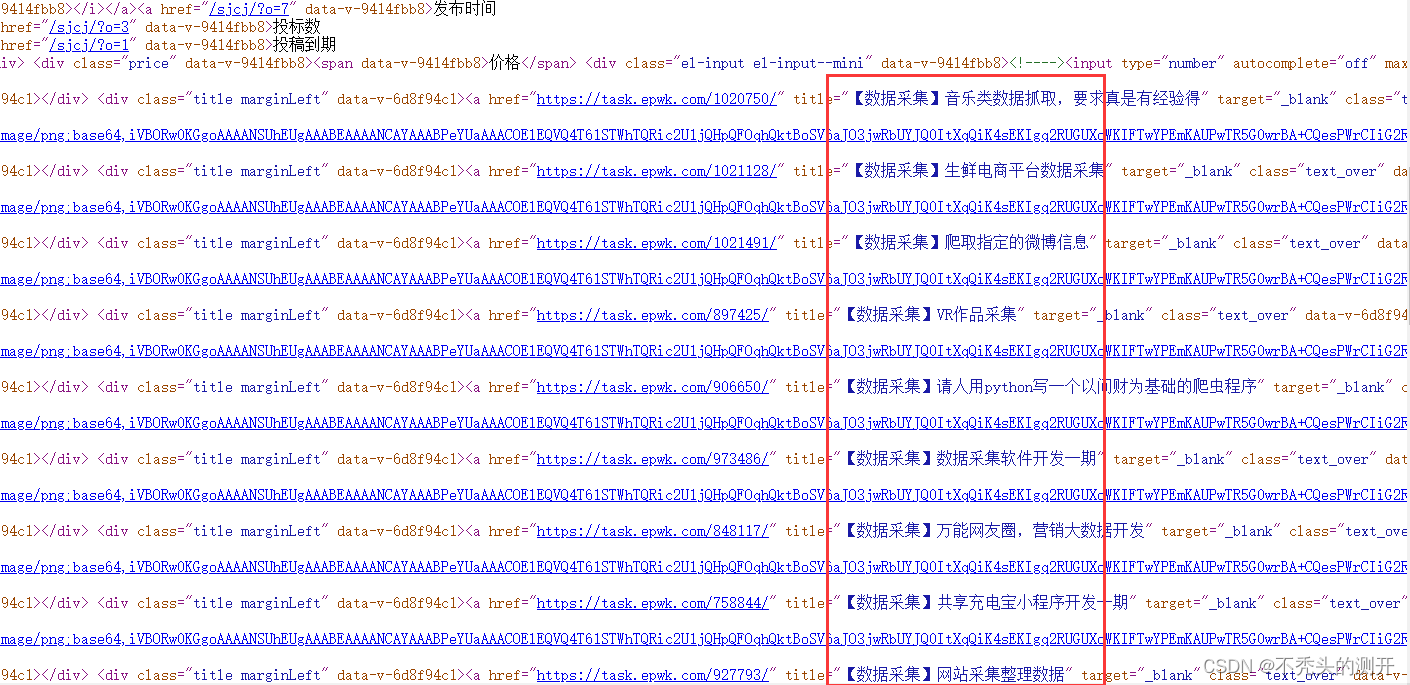
2、查找数据
3、获取详情页(赏金、任务要求、需求、状态)
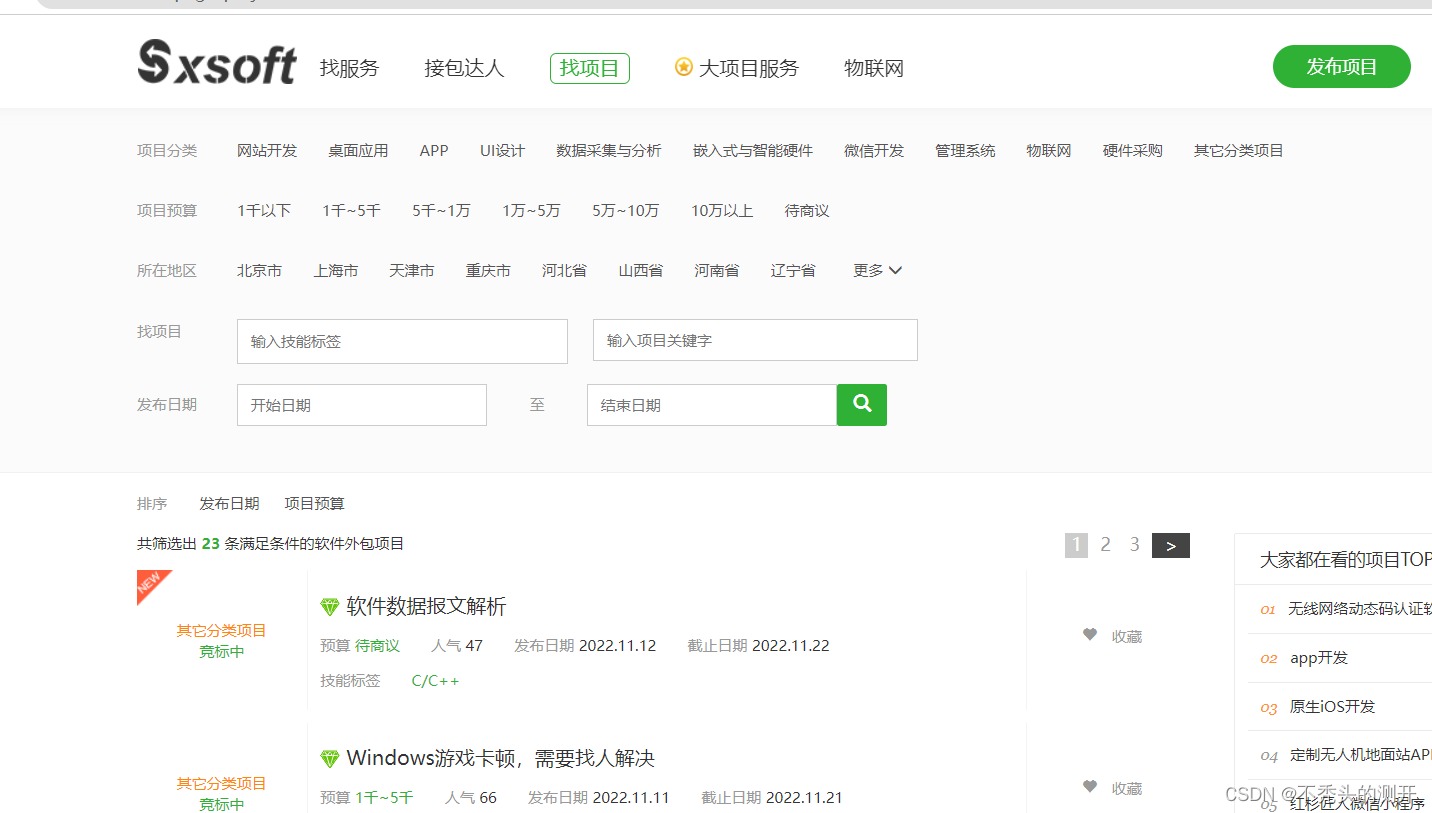
软件项目交易网
1、查看网页源码
2、全局搜索数据

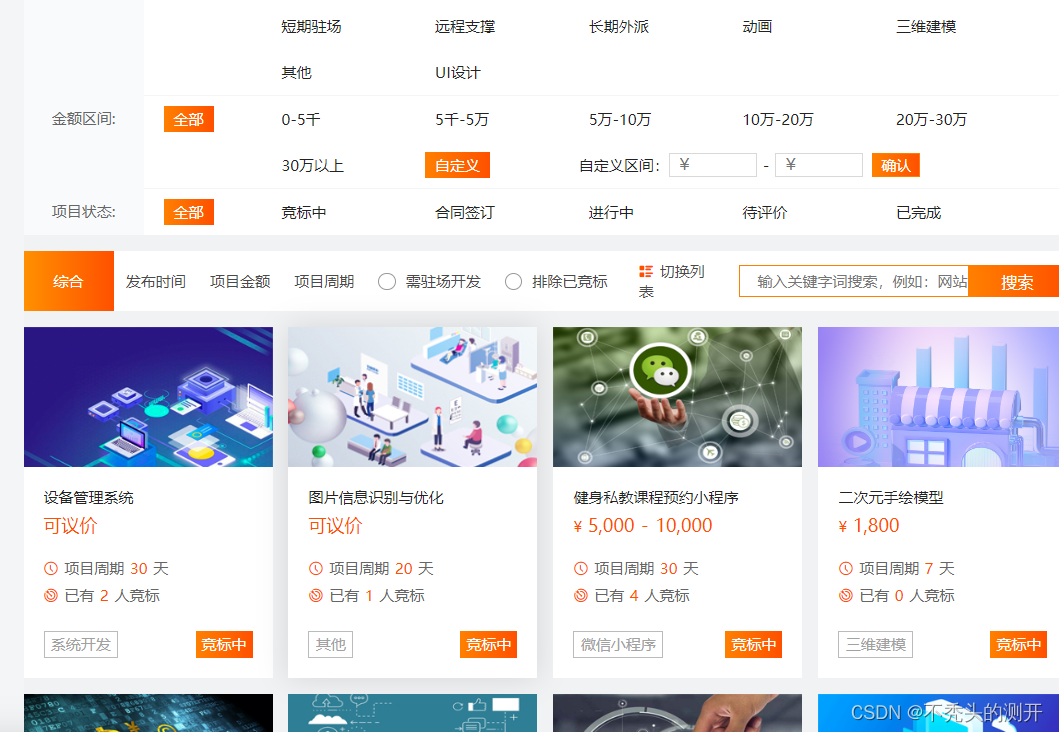
获取YesPMP平台需求任务
1、查看网页源代码
2、全局搜索数据

码市
1、F12抓包即可获取数据
2、构造请求即可获取数据
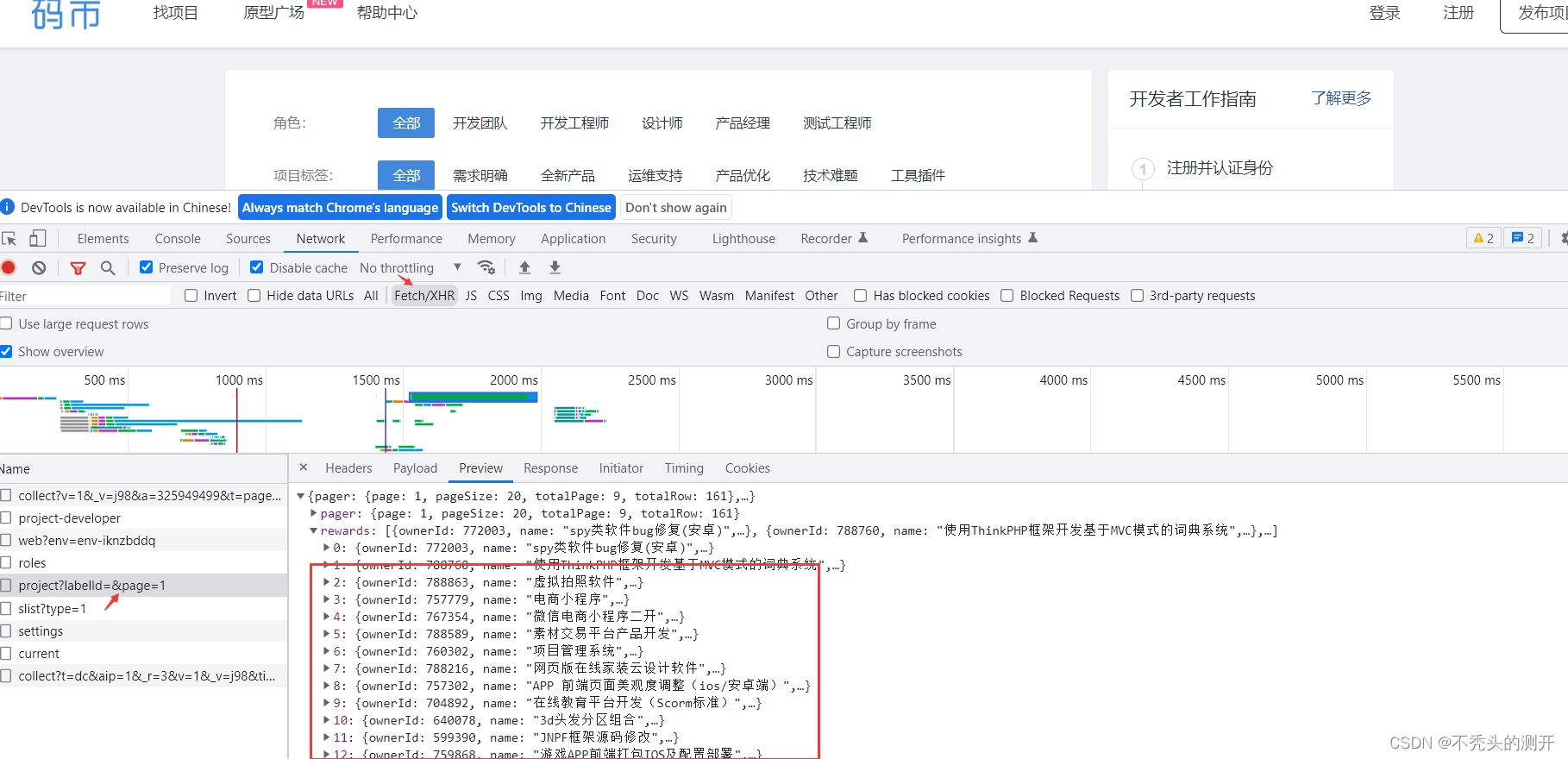
三、处理
一品威客
1、任务页任务
2、详情页(处理直接雇佣)
3、获取赏金、任务要求、时间
# -*- encoding:utf-8 -*-__author__ = "Nick"__created_date__ = "2022/11/12"import requestsfrom bs4 import BeautifulSoupimport reHEADERS = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36", "Content-Type": "text/html; charset=utf-8"}def get_index_source(url): res = requests.request("GET",url=url,headers=HEADERS) res.encoding = "utf-8" return res.text# 实例化bs4def method_bs4(html): page = BeautifulSoup(html, "html.parser") return page# 直接雇佣任务def method_zz(code): deal = re.compile(r'<meta name="description" content="(?P<is_direct>.*?)" />',re.S) result = deal.finditer(code) for i in result: check = i.group("is_direct") if "直接雇佣任务" in check: return Truedef get_task_url(html): page = method_bs4(html) # 通过class属性获取页面的任务div div = page.select(".title.marginLeft") # url_list = {} for _div in div: # 获取url content_url = _div.find("a")["href"] content = _div.text task = content.split("【数据采集】")[1] url_list[task] = content_url return url_listdef get_task_content(url_dict): with open("一品威客任务.txt",mode="a+", encoding="utf-8") as f: for name, url in url_dict.items(): # print(name,url) code_source = get_index_source(url) page = method_bs4(code_source) # 获取赏金 money = page.select(".nummoney.f_l span") for _money in money: task_money = _money.text.strip("\n").strip(" ") print(task_money) # 直接雇佣任务无法查看详情,进行处理 result = method_zz(code_source) if result: f.write(f"直接雇佣-{name}{task_money}\n") # 获取开始、结束时间 time = page.select("#TimeCountdown") for _time in time: start_time = _time["starttime"] end_time = _time["endtime"] print(start_time,end_time) # 获取需求任务 content = page.select(".task-info-content p") for _content in content: content_data = _content.text print(content_data) f.write(f"{name}---{content_data},{task_money},{start_time},{end_time}\n")if __name__ == '__main__': url = "https://task.epwk.com/sjcj/" html = get_index_source(url) url_dict = get_task_url(html) get_task_content(url_dict)软件项目交易网
通过Xpath即可获取对应数据
# -*- encoding:utf-8 -*-__author__ = "Nick"__created_date__ = "2022/11/12"import requestsfrom lxml import etreeHEADERS = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36", "Content-Type": "text/html; charset=utf-8"}def get_index_source(url): res = requests.request("GET",url=url,headers=HEADERS) res.encoding = "utf-8" return res.text# 实例化etreedef method_xpath(html): parse = etree.HTML(html) return parsedef get_task_info(html): with open("软件交易网站需求.txt",mode="w",encoding="utf-8") as f: # 实例化xpath parse = method_xpath(html) # 通过xpath定位 result = parse.xpath('//*[@id="projectLists"]/div/ul/li') for li in result: # 获取任务状态 status = li.xpath('./div[@class="left_2"]/span/text()')[1] # 剔除空格,其它符号 status = status.strip() # 获取任务 task = li.xpath('./div[@class="left_8"]/h4/a/text()') task_content = task[-1].strip() # 获取预算 bond = li.xpath('./div[@class="left_8"]/span[1]/em/text()')[0] # 获取人气 hot = li.xpath('./div[@class="left_8"]/span[2]/em/text()')[0] # 发布日期 start_time = li.xpath('./div[@class="left_8"]/span[3]/em/text()')[0] # 截止日期 end_time = li.xpath('./div[@class="left_8"]/span[4]/em/text()')[0] f.write(f"{status},{task_content},{bond},{hot},{start_time},{end_time}\n")if __name__ == '__main__': url = "https://www.sxsoft.com/page/project" html = get_index_source(url) get_task_info(html)获取YesPMP平台需求任务
通过PQuery即可获取数据
# -*- encoding:utf-8 -*-__author__ = "Nick"__created_date__ = "2022/11/12"import requestsfrom pyquery import PyQuery as pqHEADERS = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36", "Content-Type": "text/html; charset=utf-8"}def get_index_source(url): res = requests.request("GET",url=url,headers=HEADERS) res.encoding = "utf-8" return res.text# 实例化pqdef method_pq(html): parse = pq(html) return parsedef get_task_info(html): with open("yespmp网站需求.txt",mode="a",encoding="utf-8") as f: parse = method_pq(html) # 通过class属性进行定位 result =parse.find(".promain") # print(result) for _ in result.items(): # 任务名称 task_name = _.find(".name").text() # 赏金 price = _.find(".price").text() # 项目周期 date = _.find(".date").text() # 竞标人数 bid_num = _.find(".num").text() f.write(f"{task_name},{price},{date},{bid_num}\n")if __name__ == '__main__': for i in range(2,10): url = f"https://www.yespmp.com/project/index_i{i}.html" html = get_index_source(url) get_task_info(html)码市
基本request请求操作(请求头、参数)
# -*- encoding:utf-8 -*-__author__ = "Nick"__created_date__ = "2022/11/12"import requestsimport jsonheaders = { 'cookie': 'mid=6c15e915-d258-41fc-93d9-939a767006da; JSESSIONID=1hfpjvpxsef73sbjoak5g5ehi; _gid=GA1.2.846977299.1668222244; _hjSessionUser_2257705=eyJpZCI6ImI3YzVkMTc5LWM3ZDktNTVmNS04NGZkLTY0YzUxNGY3Mzk5YyIsImNyZWF0ZWQiOjE2NjgyMjIyNDM0NzgsImV4aXN0aW5nIjp0cnVlfQ==; _ga_991F75Z0FG=GS1.1.1668245580.3.1.1668245580.0.0.0; _ga=GA1.2.157466615.1668222243; _gat=1', 'referer': 'https://codemart.com/projects?labelId=&page=1', 'accept': 'application/json', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36' }def get_data(): url = "https://codemart.com/api/project?labelId=&page=1" payload = {} response = requests.request("GET", url, headers=headers, data=payload) print(json.loads(response.text))if __name__ == '__main__': get_data()四、总结
Xpath 适用于要获取的信息在某个标签下,且各标签层次明显,通过路径找到位置,for循环遍历即可 Bs4 适用于要获取的信息比较分散,且通过选择器可以定位(class唯一、id唯一) PyQuery 适用于要获取的信息比较分散,且通过选择器可以定位(class唯一、id唯一) 正则 通过(.*?)就可以处理元素失效或者定位少量信息不适用网页代码有很多其它符号,定位失效 接口返回数据 对于接口没有进行加密,通过requests构造请求即可获取数据关注点在请求头中的参数欢迎加入免费的知识星球内!
我正在「Print(“Hello Python”)」和朋友们讨论有趣的话题,你⼀起来吧?
https://t.zsxq.com/076uG3kOn