Web应用测试
对Web应用进行渗透测试HTTP对Web程序进行渗透测试所需模块urllib2库的使用urllib2.urlopen()urllib2.Request() 其他模块文件urllib模块httplib2模块requests模块BeautifulSoup模块cookielib模块 处理HTTP头部Cookie捕获HTTP基本认证数据包编写Web服务器扫描程序暴力扫描出目标服务器上所有页面
对Web应用进行渗透测试
HTTP
HTTP是Hyper Text Transfer Protocol(超文本传输协议)的缩写,这也是现在互联网上最为重要的协议。在很多人的心目中,Internet已经等同于HTTP了。
目前互联网上的大部分应用都使用了HTTP,这些应用包括但不限于电子商务、搜索引擎、论坛、博客、社交网络、电子政务等。谷歌甚至推出了一款基于HTTP的操作系统Chrome OS,只需要一个浏览器就可以完成操作系统的功能。如果要将应用程序发布到互联网上供人使用,就可以使用Web服务,这种程序也被称为Web应用,而这种应用使用的就是HTTP。
不过,正是由于HTTP的广泛应用,这个协议也成了网络安全的重灾区。所以进行网络安全渗透测试时,对Web应用的检查是十分重要的一个环节。
HTTP是一个无状态的明文传输协议,这意味着每次的请求都是独立的,它的执行情况和结果与前后的请求都是没有关系的。
这个协议在设计之初主要考虑的因素是便捷,而没有考虑到安全。
HTTP的方法主要有如下几个:
GET:请求资源。HEAD:类似于GET请求,但是只请求页面的首部。POST:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立或已有资源的修改。PUT:创建或者更新资源。DELETE:请求服务器删除指定的页面。CONNECT:HTTP /1.1协议中预留给能够将连接改为管道方式的代理服务器。OPTIONS:列出服务器支持的所有方法、内容类型和编码方式。TRACE:回显服务器收到的请求。整个HTTP中实际起作用的只有客户端(浏览器)和服务端(服务器)两个角色,其中,客户端完成的操作流程如图:
这里的通信使用到了HTTP Request与HTTP Response。
其中,HTTP Request由请求方法URI协议/版本、请求头(Request Header)、请求正文(Request Body)三部分组成。
请求方法URI协议 / 版本 位于HTTP Request的首行,包含HTTP Request Method、URI、Protocol Version三部分。例如,“GET /test.html HTTP/1.1”,其中HTTP Request Method表示为GET方法,URI为/test.html,HTTP版本号为1.1。
请求头部分为Request的头部信息,包含编码信息、请求客户端类型信息。
请求正文包含Request得到主题信息,与HTTP Request Header之间隔开一行。
HTTP Response的数据格式与HTTP Request类似,也包含三部分信息。由状态行、响应头(Response Header)、响应正文(Response Body)组成。
状态行由协议版本、数字形式的状态代码以及相应的状态描述,各元素之间以空格分隔。其中的状态代码由三位数字组成,表示请求是否被理解或被满足。常见的状态代码有如下几种:
200 Successful request:请求已成功,请求所希望的响应头或数据体将随此相应返回。201 Resource was newly c:请求已经被实现,而且有一个新的资源已经依据请求的需要而建立,且其URI已经随Location:头信息返回。加入需要的资源无法及时建立,应当返回“202 Accpeted”。301 Resource moved perm:永久移动。请求的资源已被永久地移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI,今后任何新的请求都应使用新的URI代替。307 Resource moved temp:临时重定向。400 Lnvalid request:客户端请求的语法错误,服务器无法理解。401 thorization required:请求要求用户的身份认证。403 cess denied:服务器理解请求客户端的请求,但是拒绝执行此请求。404 Resource could not be:服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置“您所请求的资源无法找到”的个性页面。405 Method not allowed:客户端请求中的方法被禁止。500 Internal server error:服务器内部错误,无法完成请求。对Web程序进行渗透测试所需模块
在Python中提供了大量用来处理HTTP的模块,例如urllib、urllib2、urllib3、httplib、httplib2、request和BeautifulSoup模块。这些模块的功能之间有重合,所以经常会看到有些相同功能程序却使用了不同的模块文件。
urllib2库的使用
urllib2 是Python2中自带的一个很有用的库,可以利用这个库轻松完成对网页的访问。需要注意的是,这个库在Python3中被分成urllib.request和urllib.error两个类。在urllib2中提供了很多实用的函数。
urllib2.urlopen()
urllib2.urlopen():这是urllib2中最为常用的一个函数,只需要向这个函数提供一个网址或者Request对象,它就可以创建一个表示远程URL的response对象,然后像对本地文件一样对其进行操作。
使用之前需要导入这个库:import urllib2
然后使用urllib2.urlopen函数打开一个链接地址,并将返回的内容保存到response中:response=urllib2.urlopen("http://www.nmap.org")
可以对urlopen()返回的文件对象进行如下操作:
read():这个方法的使用方式和文件对象完全一样,可以用来读取网页的全部HTML代码:response.read() ,返回该页面的全部HTML代码。 info():返回一个httplib.HTTPMessage对象,获取meta-information信息。例如服务器发送的headers信息:
info():返回一个httplib.HTTPMessage对象,获取meta-information信息。例如服务器发送的headers信息: print response.info() 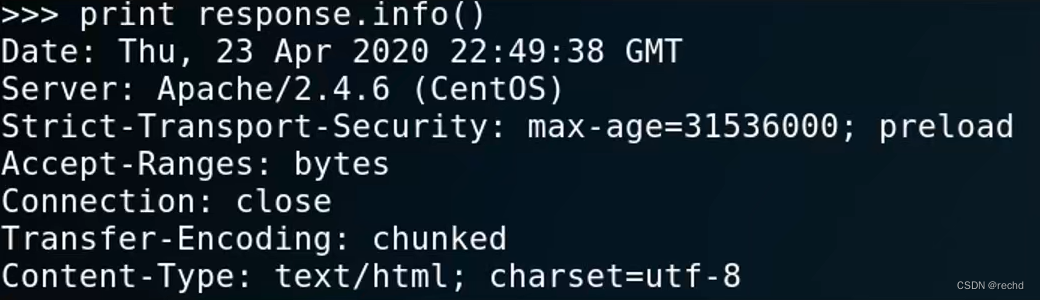 getcode():返回HTTP状态码。如果是HTTP请求,例,200表示请求成功,404表示地址未找到。
getcode():返回HTTP状态码。如果是HTTP请求,例,200表示请求成功,404表示地址未找到。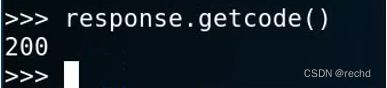 geturl():获取真实打开的地址,通常可以识别网址是否设置跳转。这个urllib2会帮用户完成,最后得到的是真实地址。
geturl():获取真实打开的地址,通常可以识别网址是否设置跳转。这个urllib2会帮用户完成,最后得到的是真实地址。
urllib2.urlopen函数除了使用url作为参数之外,也可以使用request对象。操作步骤如下:
url='http://www.sijitao.net/'request=urllib2.Request(url)response=urllib2.urlopen(request)返回结果的操作方法与上面的response是一样的
urllib2.Request()
urllib2中第二个经常使用的函数就是urllib2.Request()。这个函数完整格式为:urllib2.Request(url[,data][,headers][,originreqhost][,unverifiable])
比较常用的前两个参数如下:
其他模块文件
urllib模块
这个模块的功能较为基础,提供了一些比较原始的基础的方法而urllib2没有这些。例如urlencode。
使用带参数的GET方法取回URL:import urllibparams=urllib.urlencode({'spam':1,'eggs':2,'bacon':0})f=urllib.urlopen("http://www.musi-cal.com/cgi-bin/query?%s" % params)print f.read()
使用POST方法:import urllibparams=urllib.urlencode({'spam':1,'eggs':2,'bacon':0})f=urllib.urlopen("http://www.musi-cal.com/cgi-bin/query",params)print f.read()
httplib2模块
这个模块和urllib2有相似的地方。httplib2中提供对缓存的支持。例如下面例子中就是用“.cache”目录保存了对页面的访问缓存。
import httplib2H=httplib2.Http(".cache")#cache 缓存resp,content=h.request("http://example.org/","GET")requests模块
使用Requests发哦是那个网络请求。
导入requests模块:import requests
尝试获取某个网页:r=requests.get('https://github.com/timeline.json')
现在获得了一个Response对象r。可以从这个对象中获取所有想要的信息。requests简便的API意味着所有HTTP请求类型都是显而易见的。利用这个库发送HTTP请求十分简单,下面给出使用requests模块发送POST、PUT、DELETE、HEAD和OPTIONS的方式。
r=request.post("http://httpbin.org/post")r=request.put("http://httpbin.org/put")r=request.delete("http://httpbin.org/delete")r=request.head("http://httpbin.org/get")r=request.options("http://httpbin.org/get")BeautifulSoup模块
BeautifulSoup提供了一些简单的、Python式的函数,用来处理导航、搜索、修改分析树等功能。
它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
cookielib模块
Python中的cookielib库(Python3中为http.cookiejar)为存储和管理Cookie提供客户端支持。
该模块主要功能是提供可存储Cookie对象。使用此模块捕获Cookie并在后续连接请求时重新发送,还可以用来处理包含Cookie数据的文件。这个模块主要提供了这几个对象:CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
处理HTTP头部
解析HTTP
首先以一个比较简单的程序开始,这个程序利用httplib2模块中的request方法向目标服务器发送了一个GET类型的请求,并将收到的应答显示在屏幕上。
import httplib2client=httplib2.Http()#创建对象header,content=client.request("http://www.baidu.com","GET")#发送请求for field,value in header.items():print field + ":" + value这里使用Http()函数构造了一个httplib2对象,实际完成工作的是这个对象的request函数,这个函数以URL地址和HTTP方法作为参数,返回两个值,一个时字典类型的HTTP头部文件,另一个是请求地址的HTML页面。
这个过程也可以使用urllib2来实现,使用urllib2模块编写相同功能的代码要简单一些,这里面与httplib2的主要区别是urllib的urlopen方法不再返回两个值,而是只有一个response。这个response中既包含头部文件,也包括请页面的代码。
可以使用两个函数进行读取,read()用来读取网页的全部HTML代码,info()用来读取头部文件。
import urllib2url="http://www.baidu.com/"response=urllib2.urlopen(url)print response.info()构造一个HTTP Request头部
利用urllib2还可以十分简单地构造HTTP Request数据包,当在浏览器地址栏中输入URL地址并按下回车键之后,浏览器就会向目标服务器发送一个HTTP Request数据包,这个数据包的内容是浏览器所决定的。
现在使用Python自行设计一个HTTP Request数据包的头部
import urllib2url="http://www.baidu.com"send_header={'HOST':'www.baidu.com','User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:103.0) Gecko/20100101 Firefox/103.0',\'Accept':'text/html,application/xhtml+xml,application/xml;q-0.9,*/*;q-0.8','Connection':'keep-alive'}req=urllib2.Request(url,header=send_headers)response=urllib2.urlopen(req)response_header=response.info()print(response_header)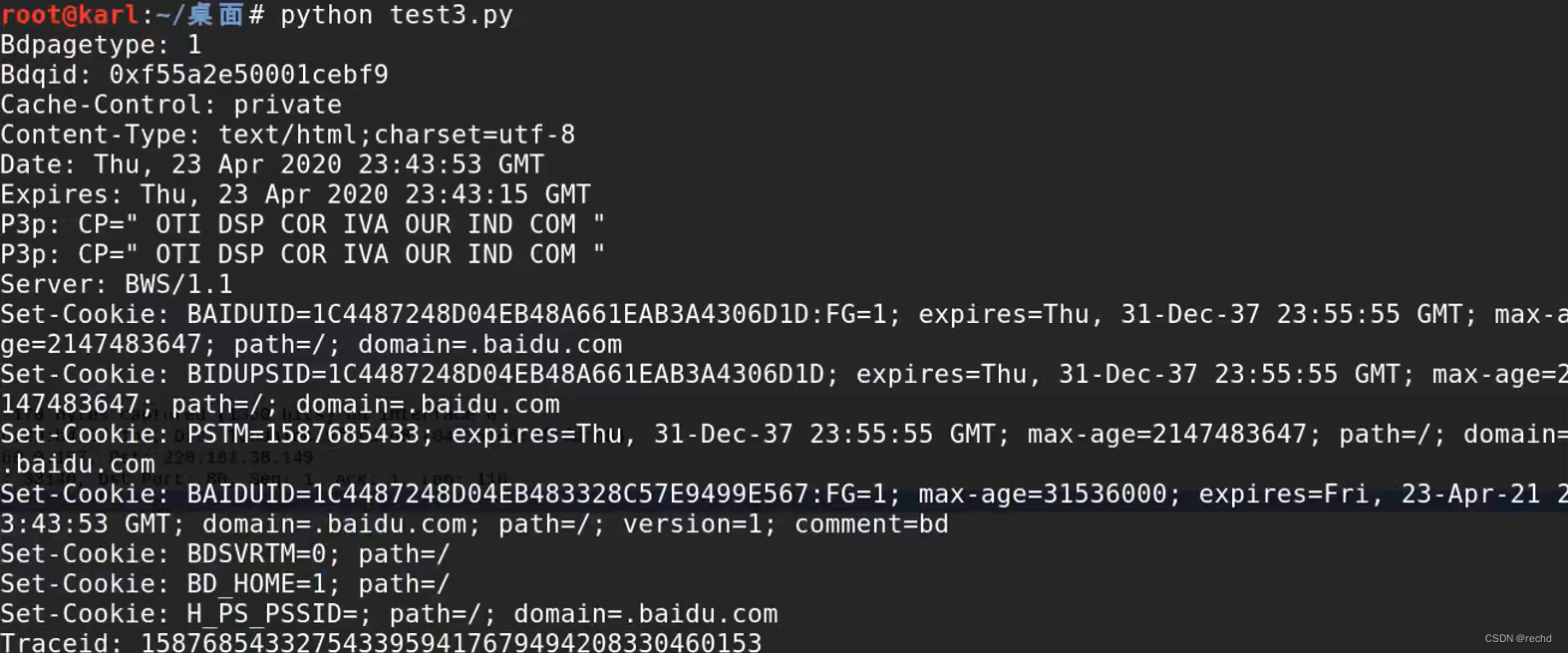
Cookie
Cookie是某些网站为了能够辨别用户的身份而储存在用户本地计算机上的数据(一般经过加密)。简单地说,就是当用户访问网站时,该网站会通过浏览器网站建立自己的Cookie,它负责存储用户在该网站上的一些输入数据与操作记录,当用户再次浏览该网站时,网站就可以通过浏览器查探该Cookie,并以此识别用户身份,从而输出特定的网页内容。
使用cookielib来获取访问www.baidu.com所产生的Cookie。
import cookielibimport urllib2#声明一个CookieJar对象来保存cookiecookie=cookielib.CookieJar()#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器handler=urllib2.HTTPCookieProcessor(cookie)#通过handler来构建openeropener=urllib2.build_opener(handler)opener.open("http://www.baidu.com")print cookie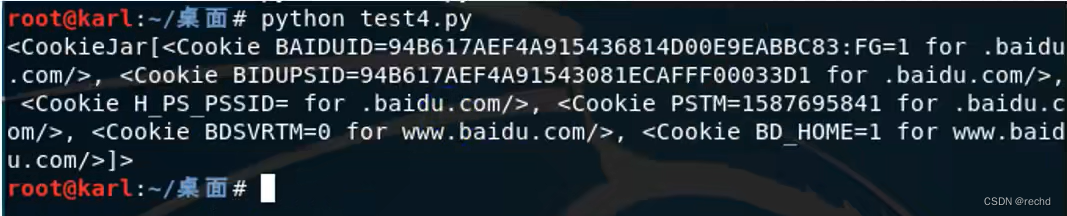
也可以将获取的Cookie保存到本地中,需要注意的是,保存文件的FileCookie-Jar类中有两个子类:MozillaCookieJar和LWPCookieJar
这两个子类提供了不同的保存方式,例如,首先以MozillaCookieJar来保存Cookie。
import cookielibimport urllib2filename="MyBaiduCookie.txt"FileCookieJar=cookielib.MozillaCookieJar(filename)FIleCookieJar.save()opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(FileCookieJar))opener.open("http://www.baidu.com")FileCookieJar.save()print open(filename).read()
将上面程序中的“FileCookieJar=cookielib.MozillaCookieJar(filename)”替换为“FileCookieJar=cookielib.LWPCookieJar(filename)”,然后执行这个程序。
import cookielibimport urllib2filename="MyBaiduCookie.txt"FileCookieJar=cookielib.LWPCookieJar(filename)FIleCookieJar.save()opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(FileCookieJar))opener.open("http://www.baidu.com")FileCookieJar.save()print open(filename).read()
捕获HTTP基本认证数据包
除了浏览器之外,很多应用程序也可以使用HTTP与Web服务器进行交互。这时通常会采用一种叫做HTTP基本认证的方式。
这种方式就是使用 Base64算法1来加密“用户名+冒号+密码”,并将加密后的信息放在HTTP Request中的header Authorization中发送给服务端。例如,用户名是admin,密码是123456,两者使用冒号连接在一起的结果是admin:123456,再用Base64进行编码,得到结果是YWRtaW46MTIzNDU2。将这个结果发送给服务器。
一个具有注脚的文本。
前面已经编写过一段可以在网络中进行监听的程序,现在为这个程序再添加一个功能,就是将HTTP基本认证的数据包过滤出来。 这个程序需要使用到两个模块:re 和 base64 。
re 模块,它的作用是实现对正则表达式的支持。
本例中查找的就是“Authorization:Basic”。
使用两个函数:re.match 与re.search 。
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
re.search匹配整个字符串,直到找到一个匹配。
这里面选择使用 re.search
import retext="Authorization: Basic YWRtaW46MTIzNDU2"m=re.search(r'Authorization: Basic (.+)',text)if m:print m.group(0)print m.group(1)else:print 'not search'
base64中有两个函数:b64encode用来实现编码,而b64decode用来实现解码。
import base64text="admin:123456"auth_str1=base64.b64encode(text)print auth_str1auth_str2=base64.b64decode(auth_str1)print auth_str2
接下来完成一个完整的程序。这个程序中使用sniff函数捕获网络中的数据包,并设置了只捕获端口为80的数据包
import efrom base64 import b64decodefrom scapy.all import sniffdev="eth0"def handl_packet(packet):tcp=packet.getlayer("TCP")match=re.search(r"Authorization:Basic (.+)",str(tcp.payload))if match:auth_str=b64decode(match.group(1))auth=auth_str.split(":")print("User: "+auth[0]+"Pass "+auth[1])sniff(iface=dev,store=0,filter="tcp and port 80",prn=handl_packet)编写Web服务器扫描程序
编写一个程序,用于检测一台主机是否运行HTTP服务。
前面介绍过如何检测一台主机上面的80端口是否开放,但是这种检测不一定能可靠地检测出目标主机是否真的提供Web服务。因为目标主机完全可能开放80端口,但是未必提供Web服务。
但是,如果对目标服务器发起一个HTTP请求,并得到回应,就可以肯定这台服务器提供了Web服务。这个程序也可以使用GET和HEAD方法来完成。
首先以GET方法来完成这个功能:
import urllib2import sysif len(sys.argv)!=2:print "Usage: testURL <IP>\n eg: testURL http://192.168.1.1"sys.exit(1)URL=argv[1]response=urllib2.urlopen(URL)#发送get请求print response.info()#获取返回信息
如果发包失败(主机不存在或不存在服务),会直接报错。 可以使用exceot来捕获这个错误。
import urllib2import sysif len(sys.argv)!=2:print "Usage: testURL <IP>\n eg: testURL http://192.168.1.1"sys.exit(1)URL=sys.argv[1]print("[*] Testing %s " % URL)try:response=urllib2.urlopen(URL)#发送get请求except:print("[-] No web serve at %s" % URL)response=Noneif response!=None:print("[*] Response from %s" % URL)print response.info()#获取返回信息
使用HEAD方法会更快捷,因为HEAD方法无须目标服务器返回整个页面的代码。
现在利用HTTP方法中的HEAD方法来完成对目标的检测,相比起GET方法来说,使用HEAD方法会更加快速。HEAD方法特点如下:
使用HEAD方法来完成这个功能,基本与GET方法相同,只是需要在使用Request时指定使用方法为“HEAD”,修改的代码如下:
import urllib2import sysif len(sys.argv)!=2:print "Usage: testURL <IP>\n eg: testURL http://192.168.1.1"sys.exit(1)URL=sys.argv[1]print("[*] Testing %s " % URL)try:request=urllib2.Request(URL)request.get_method=lambda:"HEAD"response=urllib2.urlopen(request)except:print("[*] Response from %s" % URL)print response.info()if response!=None:print("[*] Response from %s" % URL)print response.info()运行结果与get一样,只是速度不同。
暴力扫描出目标服务器上所有页面
一个网站往往拥有很多个页面,这些页面中最为常见的要数index页面,这就是常说的主页。当在浏览器地址栏中输入“http://192.168.1.1”实际上打开的就是这台服务器上的index页面。网页的其他页面则提供了其他的功能,例如,用来展示内容的页面,用来进行登录的页面等。不过有些页面并不应该展示给用户,这些页面可能包含网站的敏感信息,但是很多程序员往往会没有隐藏这个页面,在大多数时候,这并不会带来什么麻烦,因为很少有用户能够找到这些页面。但是黑客往往会利用这一些工具找到这些页面,从而获得有用的信息。
这些工具原理很简单,应为常见的页面起的名字大致相同,例如index、admin、login等。网上很容易找到收集常见页面的字典文件。然后使用目标服务器的地址和这个字典文件的表项组合,使用get方法进行测试,如果得到回应,说明目标服务器上存在这个页面,否则表示目标服务器上没有这个页面。
下面编写一个用来测试http://192.168.169.133上是否存在名为“link.htm”页面的程序。
import urllib2host="http://192.168.169.133"item="link.htm"target=host+"/"+itemrequest=urllib2.Request(target)request.get_method=lambda:'GET'response=urllib2.urlopen(request)print response.info()
这表示在http://192.168.169.133上存在一个名为“link.htm”页面,同样如果目标上没有这个页面,将会得到一个错误。
Base64是一种任意二进制到文本字符串的编码方法,常用于在URL、Cookie、网页中传输少量二进制数据。 ↩︎