文章目录
1.场景引入2.NoSQL数据库2.1NoSQL简介2.2NoSQL的适用场景2.3NoSQL不适用的场景2.4NoSQL数据库的意义 3.SQL与NoSQL的区别4.Redis简介5.Redis的应用场景5.1配合关系型数据库做高速缓存5.2多样的数据结构存储持久化数据 6.Redis的安装、启动服务、关闭服务6.1Redis的安装6.1.1虚拟机环境搭建6.1.2解压安装包 6.2后台启动Redis服务6.3.redis客户端连接到redis服务6.4关闭Redis服务 7.单线程+IO多路复用机制8.Redis的常用操作(基于key)9.key的层级结构10.常用数据类型10.1String字符串10.1.1String说明10.1.2String的常用命令10.1.3String的数据结构 10.2List列表10.2.1List列表说明10.2.2List列表的常用命令10.2.3List列表的数据结构 10.3Set集合10.3.1Set集合说明10.3.2Set集合的常用命令10.3.3Set集合的数据结构 10.4Hash哈希10.4.1Hash哈希说明10.4.2Hash哈希的常用命令10.4.3Hash哈希的数据结构 10.5有序集合Zset10.5.1有序集合Zset说明10.5.2有序集合Zset的常用命令10.5.3有序集合Zset的数据结构 11.Redis的java客户端Jedis11.1Jedis简介11.2Jedis快速入门11.3Jedis连接池 12.Redis的java客户端SpringDataRedis12.1SpringDataRedis简介12.2SpringDataRedis的特点12.3SpringBoot集成SpringDataRedis12.3.1引入相应依赖12.3.2在配置文件中添加配置信息12.3.3测试RedisTemplate12.3.4RedisTemplate的序列化方式12.3.5更改RedisTemplate的序列化方式12.3.6StringRedisTemplate12.3.7StringRedisTemplate操作字符串类型12.3.8StringRedisTemplate操作Hash类型 13.Redis缓存13.1什么是缓存13.2缓存的作用和成本13.3缓存业务流程13.4缓存的更新策略13.4.1缓存更新策略的三种方式13.4.2主动更新策略实现更新的三种方式13.4.3缓存更新的最佳方案 13.5缓存穿透13.5.1缓存穿透的定义13.5.2缓存穿透的解决方案 13.6缓存雪崩13.6.1缓存雪崩的定义13.6.2缓存雪崩的解决方案 13.7缓存击穿13.7.1缓存击穿的定义13.7.2缓存击穿的解决方案 13.8缓存工具封装13.8.1解决缓存穿透方法封装13.8.2解决缓存击穿方法封装 14.分布式锁14.1分布式锁的概念14.2分布式锁的实现方式的比较14.3Redis分布式锁实现思路14.4Redis实现分布式锁初级版本14.5Redis分布式锁误删问题14.6解决分布式锁的误删问题14.7分布式锁的原子性问题14.8Lua脚本语言 15.Redisson框架15.2Redisson引入15.2Redisson框架简介15.3Redisson配置15.4Redisson可重入锁原理15.5Redisson锁重试和WatchDog机制15.6Redisson分布式锁主从一致性问题 16.消息队列16.2消息队列的概念16.3消息队列-list结构16.4消息队列-PubSub16.5消息队列-Stream 15.Redis企业实战项目15.1项目主要业务功能15.2项目架构15.3项目初始化15.4基于Session短信登录15.4.1发送短信验证码15.4.2验证码登录和注册15.4.3拦截器实现登陆验证15.4.4隐藏用户敏感信息15.4.5集群的session的共享问题 15.5基于Redis实现短信登录15.5.1为什么要使用redis代替session15.5.1Redis代替session的业务流程15.5.2 Redis实现短信登录 15.6商户查询缓存15.6.1添加商户缓存15.6.2采用缓存更新策略优化商户缓存15.6.3解决查询商户不存在时出现的缓存穿透问题15.6.4基于互斥锁的方式解决缓存击穿问题15.6.5基于逻辑过期的方式解决缓存击穿问题 15.7优惠券秒杀15.7.1全局ID生成器15.7.2添加优惠券15.7.3实现秒杀下单15.7.4库存超卖问题(多线程并发问题)分析15.7.5悲观锁和乐观锁15.7.6使用乐观锁解决库存超卖(多线程并发安全)15.7.7使用悲观锁实现一人一单功能15.7.8集群下线程并发安全问题15.7.9使用分布式锁优化一人一单问题15.7.10分布式锁误删优化15.7.11使用Lua脚本实现分布式锁的原子性15.7.12使用Redisson实现分布式锁15.7.13秒杀优化(异步秒杀) 15.8达人探店15.8.1发布探店博客15.8.2查看探店博客15.8.3点赞博客(限制点赞次数)15.8.4点赞排行榜15.8.5关注和取关15.8.6共同关注15.8.7关注推送(Feed流)15.8.9Feed的分页问题15.8.8基于Timeline模式的推方式实现关注推送15.8.9实现关注页面的分页查询 15.9附近商户15.9.1GEO数据结构概念15.9.2GEO数据结构练习15.9.3将商户按照类型分组并存入缓存15.9.4搜索附近商户 15.10用户签到15.10.1BitMap的用法15.10.2实现签到功能15.10.3统计连续签到 15.11UV统计15.11.1HyperLogLog用法 15.11.2实现UV统计 16.分布式缓存16.1采用分布式缓存的原因16.2Redis持久化16.2.1RDB持久化16.2.2AOF持久化16.2.3RDB持久化和AOF持久化比较 16.3Redis主从16.3.1主从复制简介16.3.2主从集群搭建16.3.3开启主从关系16.3.4测试主从读写16.3.5主从数据同步原理16.3.5.1全量同步16.3.5.2增量同步16.3.5.3从主优化16.3.5.4全量同步和增量同步的区别 16.4Redis哨兵16.4.1哨兵的作用16.4.2哨兵的工作原理16.4.3主节点的选取方式16.4.4故障转移16.4.5搭建哨兵集群16.4.6RedisTemplate连接哨兵集群16.4.7测试lettuce的节点感知和自动切换 16.5Redis分片集群16.5.1搭建分片集群16.5.2散列插槽16.5.3集群伸缩16.5.4故障转移16.5.5数据迁移16.5.6RedisTemplate连接分片集群 17.多级缓存
1.场景引入
Web1.0的时代,数据访问量很有限,用一夫当关的高性能的单点服务器可以解决大部分问题。

随着Web2.0的时代的到来,用户访问量大幅度提升,同时产生了大量的用户数据所有的互联网平台都面临了巨大的性能挑战。
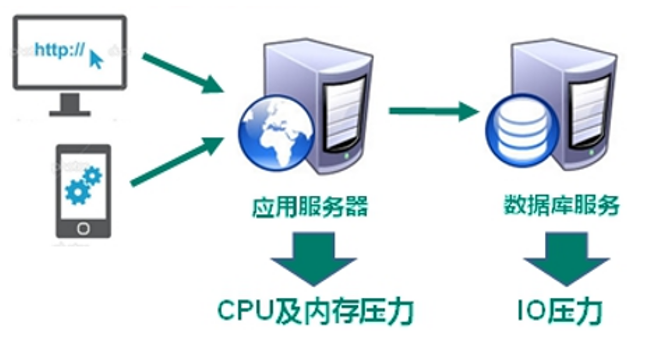
解决CPU和内存压力的方案:
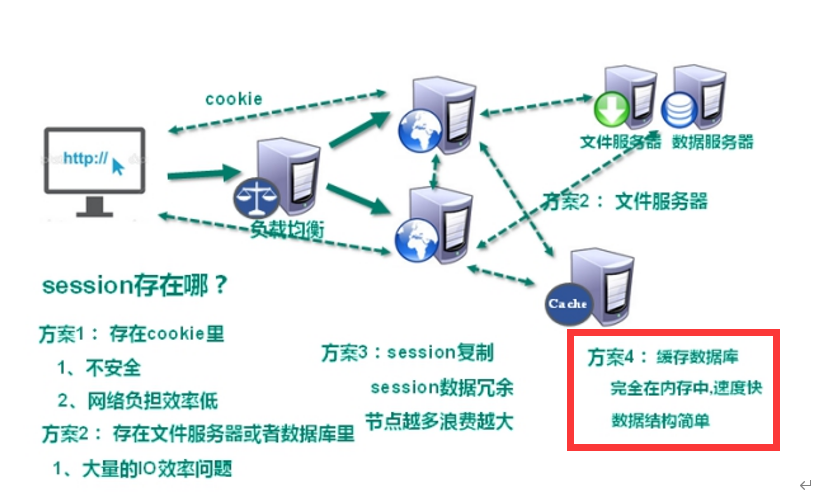
解决IO压力:减少IO操作
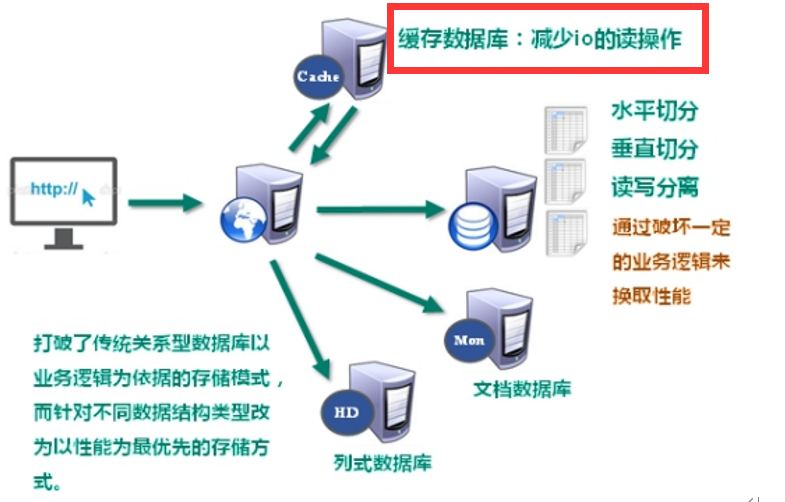
2.NoSQL数据库
2.1NoSQL简介
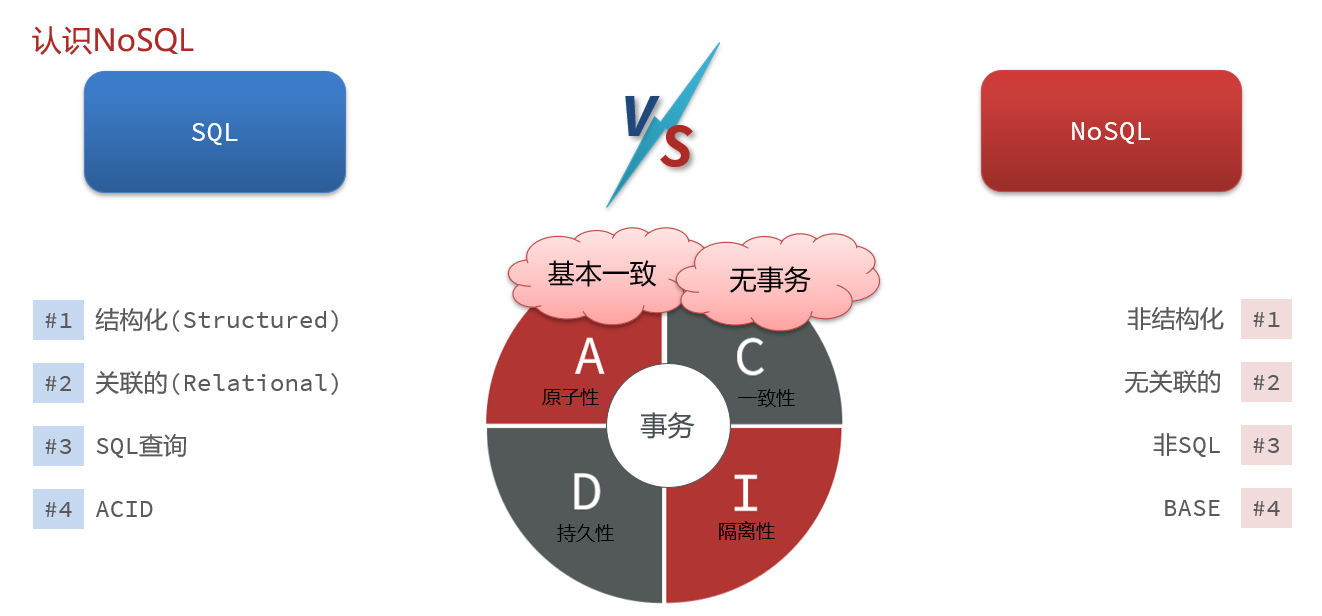
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,泛指非关系型的数据库。
NoSQL 不依赖业务逻辑方式存储,而以简单的key-value模式存储。因此大大的增加了数据库的扩展能力。
特点:
不遵循SQL标准不支持ACID(事务的四大特性:原子性、一致性、隔离性、持久性)远超于SQL性能2.2NoSQL的适用场景
对数据高并发的读写海量数据的读写对数据具有高扩展性2.3NoSQL不适用的场景
需要事务支持基于SQL的结构化查询存储,处理复杂的关系需要即席查询2.4NoSQL数据库的意义
NoSQL数据库打破了传统关系型数据库以业务逻辑为依据的存储模式,而是针对不同数据结构的类型、以性能为优先的存储方式。
3.SQL与NoSQL的区别
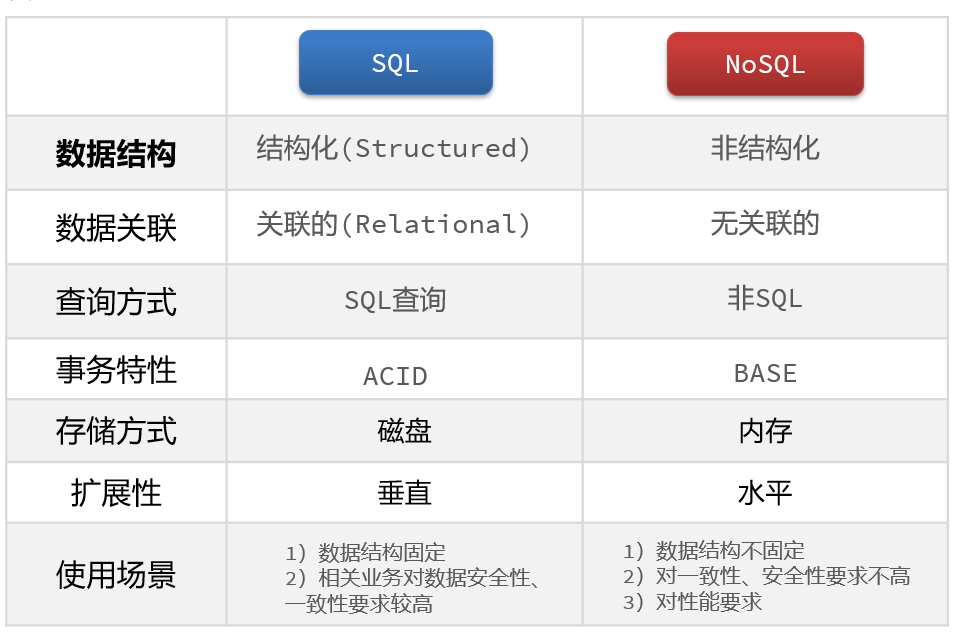
4.Redis简介
Redis是一个NoSQL数据库,其数据都在内存中,支持持久化,主要用作备份恢复。除了支持简单的key-value模式,还支持多种数据结构的存储,比如 list、set、hash、zset等。一般是作为缓存数据库辅助持久化的数据库

redis诞生小故事:
说起我的诞生,跟关系数据库MySQL还挺有渊源的。
在我还没来到这个世界上的时候,MySQL过的很辛苦,互联网发展的越来越快,它容纳的数据也越来越多,用户请求也随之暴涨,而每一个用户请求都变成了对它的一个又一个读写操作,MySQL是苦不堪言。尤其是到“双11”、“618“这种全民购物狂欢的日子,都是MySQL受苦受难的日子。
据后来MySQL告诉我说,其实有一大半的用户请求都是读操作,而且经常都是重复查询一个东西,浪费它很多时间去进行磁盘I/O。
后来有人就琢磨,是不是可以学学CPU,给数据库也加一个缓存呢?于是我就诞生了!
出生不久,我就和MySQL成为了好朋友,我们俩常常携手出现在后端服务器中。
应用程序们从MySQL查询到的数据,在我这里登记一下,后面再需要用到的时候,就先找我要,我这里没有再找MySQL要。
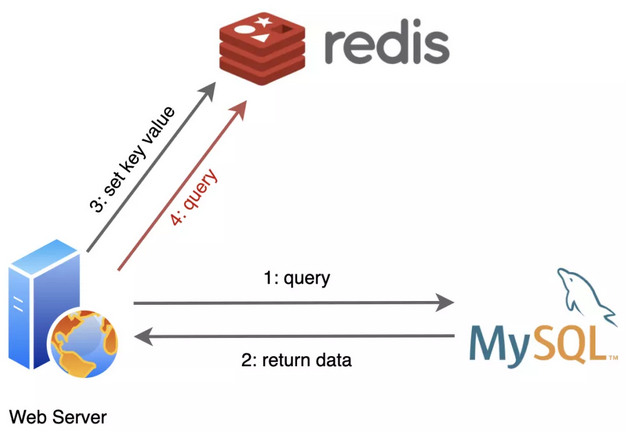
5.Redis的应用场景
5.1配合关系型数据库做高速缓存
高频次,热门访问的数据,降低数据库IO
分布式架构,做session共享
5.2多样的数据结构存储持久化数据
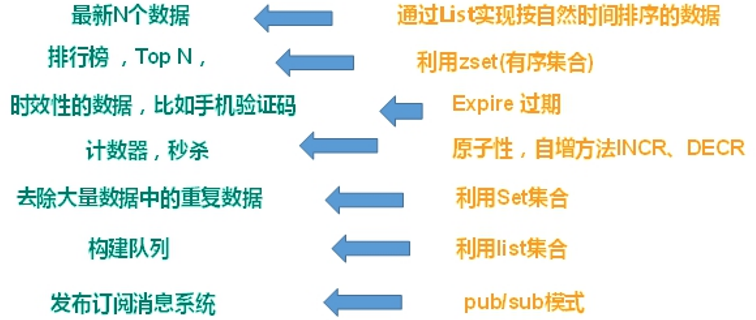
6.Redis的安装、启动服务、关闭服务
6.1Redis的安装
6.1.1虚拟机环境搭建
Redis官网
下载可以发现是Linux版本

原因是因为Redis官方并不推荐在Windows系统下使用Redis。不用考虑在windows环境下对Redis的支持
一:创建Redis环境测试虚拟机
二:用Xshell连接虚拟机,首先在虚拟机中安装C语言的编译环境gcc
yum install gcc
查看gcc版本信息

6.1.2解压安装包
解压到/opt目录下
注意:opt目录对于所有用户没有写权限,所以在此目录下传输文件时需要更改权限
chmod 777 文件名r w x 分别表示读权限、写权限、执行权限 用数字表示为 4 2 1

解压压缩文件:

进入解压好的文件中进行编译安装:
编译
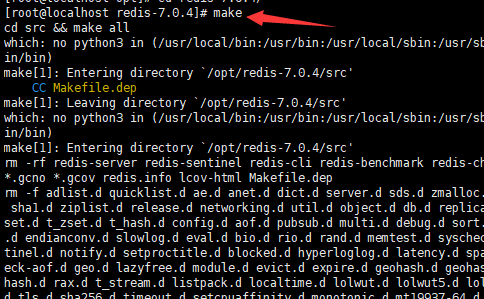
安装:
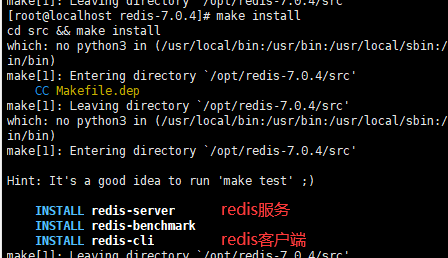
redis的默认安装目录为:/usr/local/bin/
该目录下有redis服务端和redis客户端

6.2后台启动Redis服务
切换到root用户下进入到redis文件目录下

复制redis.conf文件到etc目录下

一:修改redis.conf(128行)文件将里面的daemonize no 改成 yes,让服务在后台启动
采用vim编辑器中的搜索模式进行搜索(正斜线进行搜索模式)

二:修改监听地址:默认是127.0.0.1,只有在本机才能访问,现在测试环境修改为0.0.0.0,即任何ip都能够访问,生产环境下不能修改
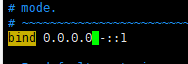
三:设置redis密码
命令:config set requirepass 密码
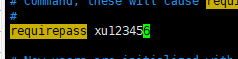
启动redis服务
redis-server /etc/redis.conf查看redis服务
ps -ef | grep redis
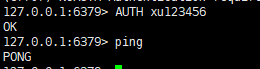
6.3.redis客户端连接到redis服务
redis-cli
可以看到已经连接到了redis服务,redis服务在虚拟机的6379端口运行
6.4关闭Redis服务
一:单实例关闭
redis-cli shutdown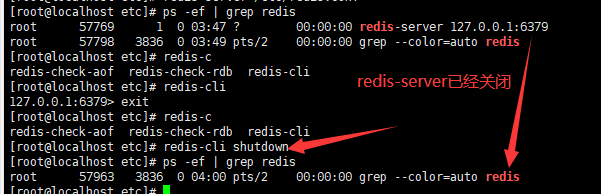
二:客户端连接后进行关闭

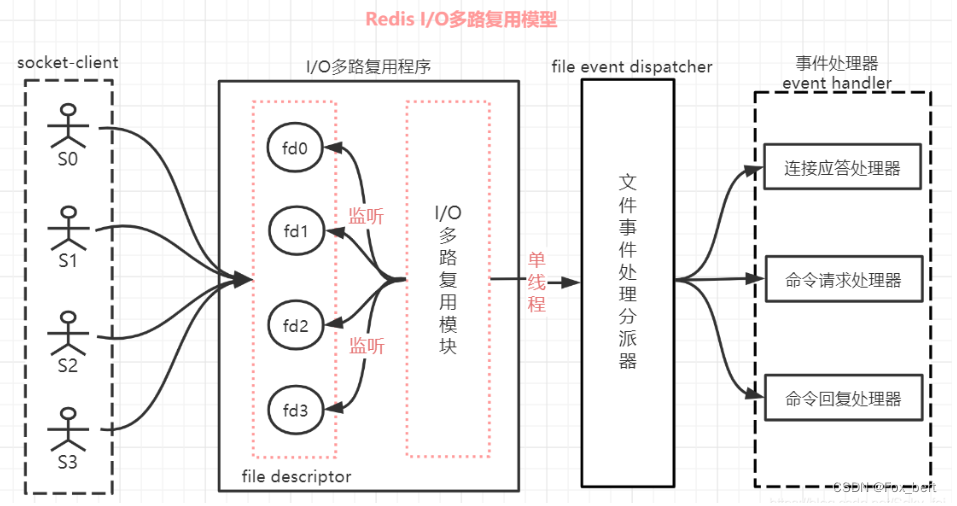
7.单线程+IO多路复用机制
「为了让单线的服务端应用同时处理多个客户端的事件,Redis 采用了 IO 多路复用机制。」
多路【指的是多个网络连接客户端】
复用【指的是复用同一个线程】
多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)
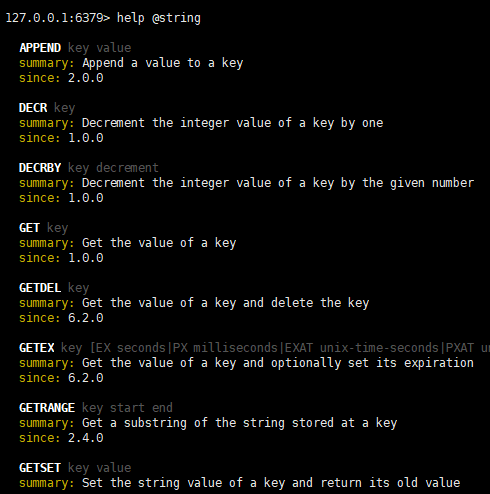
8.Redis的常用操作(基于key)
| 命令 | 说明 |
|---|---|
| keys * | 查看当前库所有key |
| exists key | 判断某个key是否存在 |
| type key | 查看你的key是什么类型 |
| del key | 删除指定的key数据 |
| unlink key | 根据value选择非阻塞删除(提示已经删除,但其实并没有删除,在后续会删除) |
| expire key 数字 | 数字的单位为正整数,表示秒,为给定的key设置过期时间 |
| ttl key | 查看还有多少秒过期,-1表示永不过期,-2表示已过期 |
| select [0-15] | 切换数据库,一共有16个 |
| dbsize | 查看当前数据库的key的数量 |
| flushdb | 清空当前库 |
| flushall | 通杀全部库 |
可以采用help命令查看相关命令的使用方式:
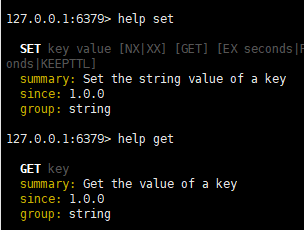
一:查看当前库中的所有key
语法:
keys *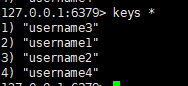
二:判断某个key是否存在
语法:
exists key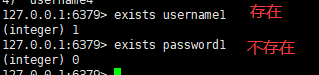
三:查看key的类型
语法:
type key
四:删除指定的key数据
语法:
del key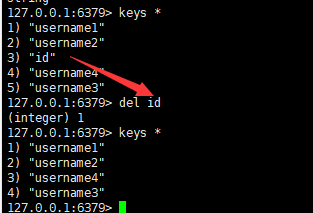
五:设置key的过期时间,查看还有多少秒过期
语法:
设置过期时间
empire key 数字查看还有多少秒过期
ttl key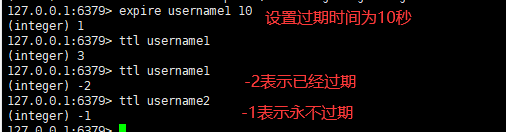
六:切换不同的数据库
语法:
select [0-15]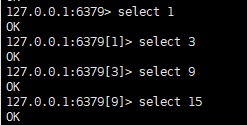
七:查看当前数据库的key的数量
语法:
dbsize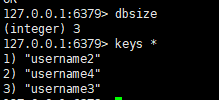
9.key的层级结构
Redis的key允许有多个单词形成层级结构,多个单词之间用’:'隔开,格式如下:

这个格式并非固定,也可以根据自己的需求来删除或添加词条。
如果Value是一个Java对象,例如一个User对象,则可以将对象序列化为JSON字符串后存储:


10.常用数据类型
10.1String字符串
10.1.1String说明
String是Redis最基本的类型,一个key对应一个value。
String类型是二进制安全的。意味着Redis的string可以包含任何数据。比如jpg图片或者序列化的对象。
String类型是Redis最基本的数据类型,一个Redis中字符串value最多可以是512M
10.1.2String的常用命令
| set key value | 添加键值对 |
| get key | 根据key获取到value |
| append key value | 将给定的value追加到key原值的末尾 |
| strlen key | 获得值的长度 |
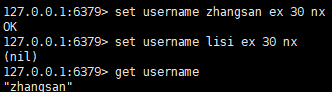
| setnx key value | 只有在 key 不存在时 设置 key 的值 |
| incr/decr key | 让数字类型加1/减1 |
| incrby/decrby key step | 指定步长,让数字类型加步长/减步长 |
| mset key1 value1 key2 value2 … | 同时设置一个或多个 key-value对 |
| mget key1 key2 … | 同时获取一个或多个 value |
| msetnx key1 value1 key2 value2 … | 同时设置一个或多个 key-value对(具有原子性,如果有一个已经存在则全部都会失败) |
| getrange key start end | 获取从start开始,到end结束的字符串片段 |
| setrange key start value | 用 value 参数覆写给定 key 所储存的字符串值,从偏移量 start开始。 |
| setex key 过期时间 value | 设置值的同时设置过期时间 |
| getset key value | 获取旧值的同时设置新值 |
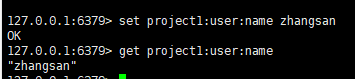
一:添加键值对
语法:
set key value二:根据键来获取值
语法:
get key三:将给定的value追加到key原值的末尾
语法:
append key value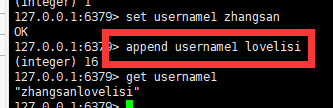
四:获得值的长度
语法:
strlen key 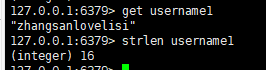
五:只有在 key 不存在时 设置 key 的值
语法:
setnx key value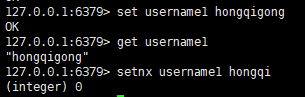
六:让数字类型加1/减1
语法:
incr/decr key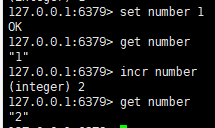
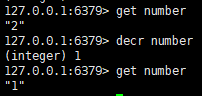
七:让数字类型按照步长加/减
语法:
incrby/decrby key 步长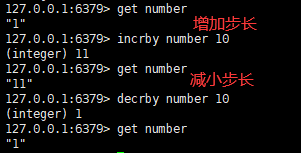
其中数字类型的增加或减小是原子操作,即原子性
原子性就是不会被进程调度所影响的操作

八:同时设置一个或多个 key-value对
语法:
mset key1 value1 key2 value2 ...
九:同时获取一个或多个 value
语法:
mget key1 key2 ...
十:获取到字符串片段
语法:
getrange key start end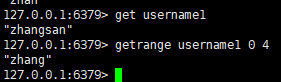
十一:替换掉指定的字符串片段
语法:
setrange key start value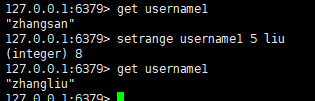
十二:设置值的同时设置过期时间
语法:
setex key 过期时间 value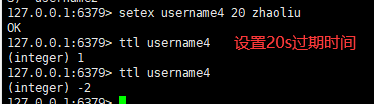
十三:获取旧值的同时设置新值
语法:
getset key value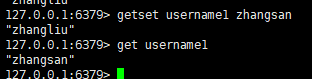
10.1.3String的数据结构
String的数据结构为简单动态字符串(Sample Dynamic Sting)。是可以修改的字符串,内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配.

如图中所示,内部为当前字符串实际分配的空间capacity一般要高于实际字符串长度len。当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。需要注意的是字符串最大长度为512M。
10.2List列表
10.2.1List列表说明
List的数据存储形式为:单键多值
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。

10.2.2List列表的常用命令
| 命令 | 说明 |
|---|---|
| lpush/rpush key value1 value2 value3 … | 从左边/右边插入一个或多个值 |
| lpop/rpop key | 从左边/右边移除一个值 |
| rpoplpush key1 key2 | 从key1列表右边移出一个值,插到key2列表左边 |
| lrange key start end | 按照start开始,end结束的索引下标获得元素(从左到右) |
| lrange key 0 -1 | 0左边第一个,-1右边第一个,(0-1表示获取所有) |
| lindex key index | 按照索引下标获得元素(从左到右) |
| llen key | 获得列表长度 |
| linsert key before/after value newvalue | 在value的前面/后面插入newvalue |
| lrem key n value | 从左边删除n个value(从左到右) |
| lset key index value | 将列表key下标为index的值替换成value |
一:从左边/右边插入一个或多个值
语法:
lpush/rpush key value1 value2 value3 ....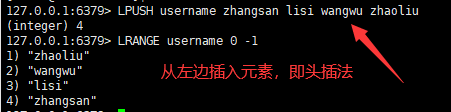
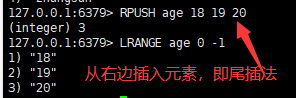
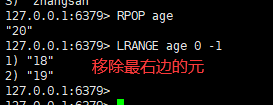
二:从左边/右边移除一个值
语法:
lpop/rpop key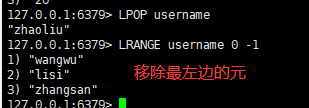
三:从key1列表右边移出一个值,插到key2列表左边
语法:
rpoplpush key1 key2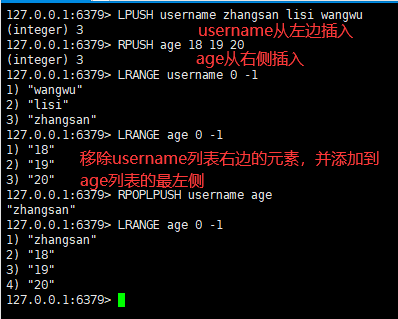
四:按照start开始,end结束的索引下标获得元素(从左到右)
语法:
lrange key start end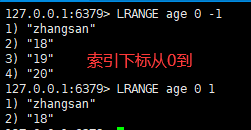
五:按照索引下标获得元素
语法:
lindex key index
六:获取到列表长度
语法:
llen key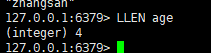
七:在value的前面/后面插入newvalue
语法:
linsert key before/after value newvalue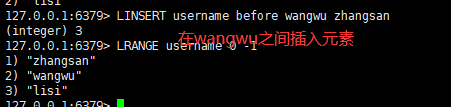
八:从左边删除n个值
语法:
lrem key n value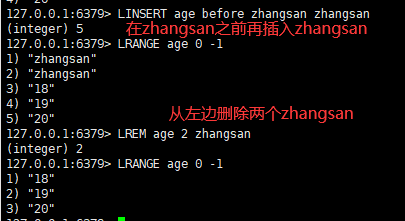
九:将列表key下标为index的值替换成value
语法:
lset key index value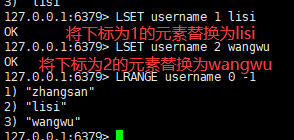
10.2.3List列表的数据结构
List的数据结构为快速链表quickList。
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。
当数据量比较多的时候才会改成quicklist。
因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。

Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
10.3Set集合
10.3.1Set集合说明
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set中的元素是可以自动排重,且无序,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
Redis的Set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是O(1)。
一个算法,随着数据的增加,执行时间的长短,如果是O(1),数据增加,查找数据的时间不变
10.3.2Set集合的常用命令
| 命令 | 说明 |
|---|---|
| sadd key value1 value2 | 将一个或多个 元素加入到集合 key 中,已经存在的元素将被忽略 |
| smembers key | 取出该集合的所有值 |
| sismember key value | 判断集合key是否为含有该value值,有1,没有0 |
| scard key | 返回该集合的元素个数 |
| srem key value1 value2 | 删除集合中的一个或多个元素 |
| spop key | 随机移除集合中的某个元素 |
| srandmember key n | 随机从该集合中取出n个值。不会从集合中删除 |
| smove key1 key2 value | 把集合中一个值从一个集合移动到另一个集合 |
| sinter key1 key2 | 返回两个集合的交集元素 |
| sunion key1 key2 | 返回两个集合的并集元素 |
| sdiff key1 key2 | 返回两个集合的差集元素(key1中的,不包含key2中的) |
一:将一个元素或者多个元素添加到集合中
语法:
sadd username value1 value2...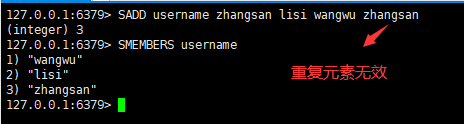
二:取出该集合的所有值
语法:
smembers key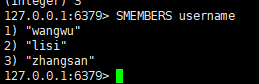
三:判断集合key是否为含有该value值,有1,没有0
语法:
sismember key valus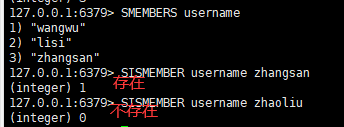
四:返回该集合的元素个数
语法:
scard key
五:删除集合中的一个或多个元素
语法:
scrm key value1 value2...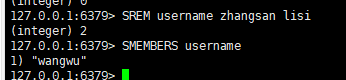
六:随机移除集合中的某个元素
语法:
spop key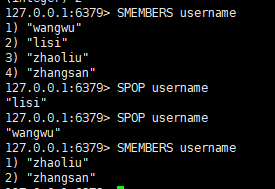
七:随机从该集合中取出n个值。不会从集合中删除
语法:
srandmember key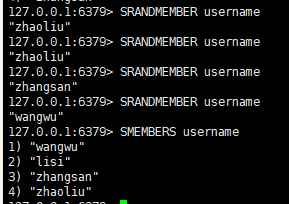
八:把集合中一个值从一个集合移动到另一个集合
语法:
smove key1 key2 value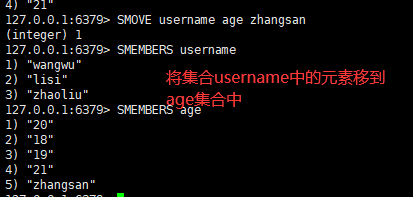
九:返回两个集合的交集元素
语法:
sinter key1 key2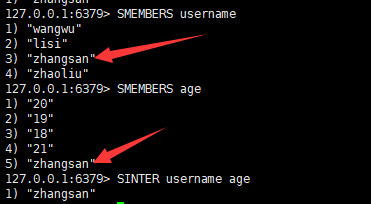
十:返回两个集合的并集元素
语法:
sunion key1 key2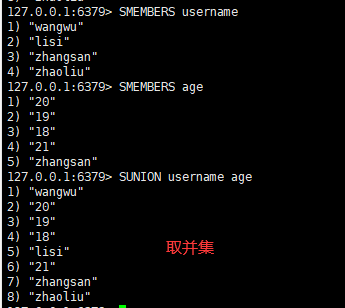
十一:返回两个集合的差集元素
语法:
sdiff key1 key2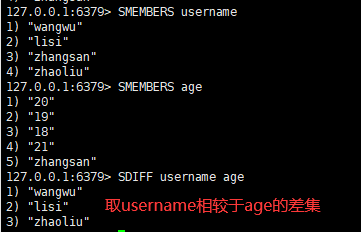
10.3.3Set集合的数据结构
Set数据结构是dict字典,字典是用哈希表实现的。
Java中HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
10.4Hash哈希
10.4.1Hash哈希说明
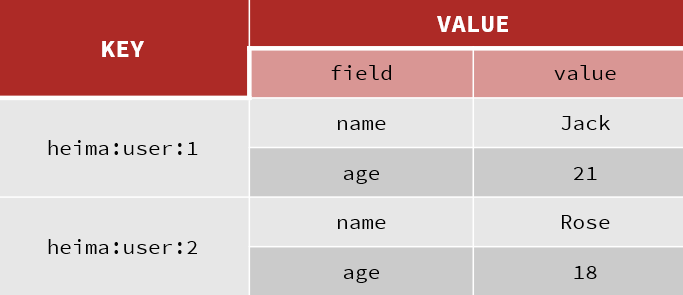
Redis hash 是一个键值对集合。
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
类似Java里面的Map<String,Object>
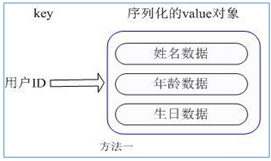
用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息,如果用普通的key/value结构来存储
主要有以下2种存储方式:
方式1:
每次修改用户的某个属性需要先反序列化改好后再序列化回去。开销较大。
方式2:
用户ID数据冗余
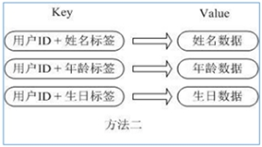
采用Hash的方式进行实现:
通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题
10.4.2Hash哈希的常用命令
| 命令 | 说明 |
|---|---|
| hset | 给集合中的 键赋值 |
| hget | 从集合取出 value |
| hmset … | 批量设置hash的值 |
| hexists | 查看哈希表 key 中,给定域 field 是否存在 |
| hkeys | 列出该hash集合的所有field |
| hvals | 列出该hash集合的所有value |
| hincrby | 为哈希表 key 中的域 field 的值加上增量 1 -1 |
| hsetnx | 将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在 |
一:给集合中的 键赋值
语法:
hset <key> <field> <value>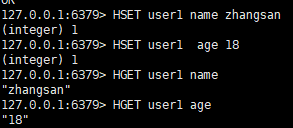
二:从集合取出 value
语法:
hget <key> <field>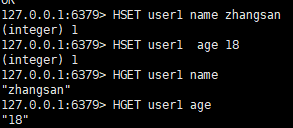
三:批量设置hash的值
语法:
hmset <key1><field1><value1><field2><value2>...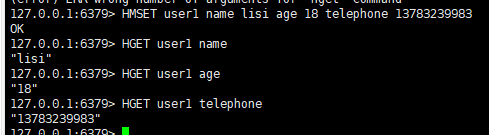
四:查看哈希表 key 中,给定域 field 是否存在
语法:
hexists <key1> <field>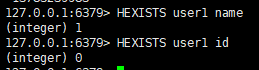
五: 列出该hash集合的所有field
语法:
hkeys <key>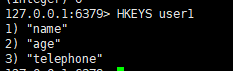
六:列出该hash集合的所有value
语法:
hvals <key>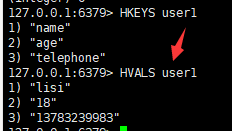
七:为哈希表 key 中的域 field 的值加上增量increment
语法:
hincrby <key><field><increment>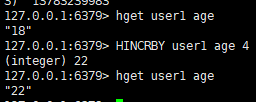
八:将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在
语法:
hsetnx <key><field><value>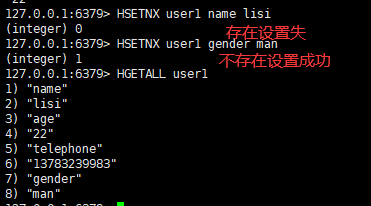
10.4.3Hash哈希的数据结构
Hash类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable。
10.5有序集合Zset
10.5.1有序集合Zset说明
Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。
不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。
因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
10.5.2有序集合Zset的常用命令
| 命令 | 说明 |
|---|---|
| zadd … | 将一个或多个 member 元素及其 score 值加入到有序集 key 当中 |
| zrange [WITHSCORES] | 返回有序集 key 中,下标在 之间的元素, 带WITHSCORES,可以让分数一起和值返回到结果集 |
| zrangebyscore key min max [withscores] [limit offset count] | 返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列 |
| zrevrangebyscore key max min [withscores] [limit offset count] | 取得从大到小从max开始到min结束的数据 |
| zincrby | 为元素的score加上增量 |
| zrem | 删除该集合下,指定值的元素 |
| zcount | 统计该集合,分数区间内的元素个数 |
| zrank | 返回该值在集合中的排名,从0开始 |
一:将一个或多个 member 元素及其 score 值加入到有序集 key 当中
语法:
zadd <key><score1><value1><score2><value2>…
二:返回有序集 key 中,下标在 之间的元素, 带WITHSCORES,可以让分数一起和值返回到结果集
语法:
zrange <key><start><stop>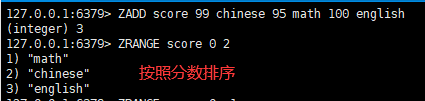
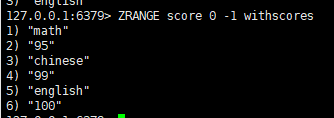
三:返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列
语法:
zrangebyscore key minmax [withscores] [limit offset count]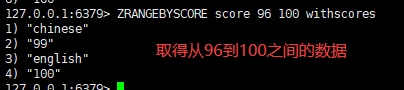
四:取得从大到小从max开始到min结束的数据
语法:
zrevrangebyscore key max min [withscores] [limit offset count]hexists <key1> <field>
五: 为元素的score加上增量
语法:
zincrby <key><increment><value> 
六:删除该集合下,指定值的元素
语法:
zrem <key><value>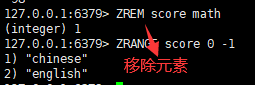
七:统计该集合,分数区间内的元素个数
语法:
zcount <key><min><max>
八:返回该值在集合中的排名,从0开始
语法:
zrank <key><value>10.5.3有序集合Zset的数据结构
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map<String, Double>,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
zset底层使用了两个数据结构
(1)hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
(2)跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
什么是跳跃表
有序集合在生活中比较常见,例如根据成绩对学生排名,根据得分对玩家排名等。对于有序集合的底层实现,可以用数组、平衡树、链表等。数组不便元素的插入、删除;平衡树或红黑树虽然效率高但结构复杂;链表查询需要遍历所有效率低。Redis采用的是跳跃表。跳跃表效率堪比红黑树,实现远比红黑树简单。
2、实例
对比有序链表和跳跃表,从链表中查询出51
(1) 有序链表

要查找值为51的元素,需要从第一个元素开始依次查找、比较才能找到。共需要6次比较。
(2) 跳跃表
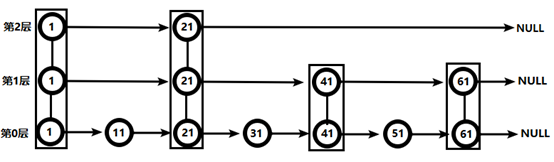
从第2层开始,1节点比51节点小,向后比较。21节点比51节点小,继续向后比较,后面就是NULL了,所以从21节点向下到第1层
在第1层,41节点比51节点小,继续向后,61节点比51节点大,所以从41向下
在第0层,51节点为要查找的节点,节点被找到,共查找4次。
从此可以看出跳跃表比有序链表效率要高
11.Redis的java客户端Jedis
11.1Jedis简介
以 Redis 命令作为方法名称,学习成本低,简单实用。但是 Jedis 实例是线程不安全的,多线程环境下需要基于连接池来使用
11.2Jedis快速入门
Jedis的官网地址: https://github.com/redis/jedis
一:在虚拟机中关闭防火墙
systemctl stop firewall.service二:创建maven项目,引入Jedis的相关依赖
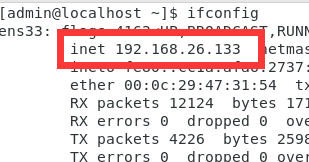
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>4.2.0</version></dependency>
三:创建测试类
private Jedis jedis; @BeforeEach public void initJedis(){// 建立连接 jedis = new Jedis("192.168.26.133",6379);// 设置密码 jedis.auth("xu123456");// 选择库 jedis.select(0); } @Test public void jedisConnect(){ String result = jedis.set("name", "张三"); System.out.println(result); String name = jedis.get("name"); System.out.println(name); } @AfterEach public void releaseJedis(){ if (jedis != null){ jedis.close(); } }控制台打印情况

查看redis可视化工具中的情况
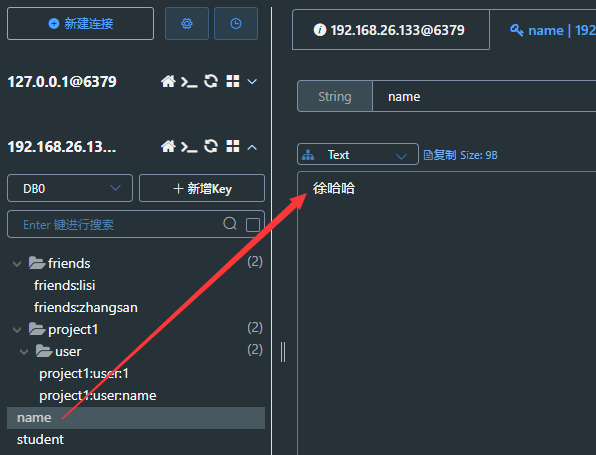
11.3Jedis连接池
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此我们推荐大家使用Jedis连接池代替Jedis的直连方式
一:创建Jedis连接池配置类
public class JedisConnectFactory { private static final JedisPool jedisPool; static {// 配置连接池 JedisPoolConfig poolConfig = new JedisPoolConfig();// 设置最大连接数 poolConfig.setMaxIdle(8);// 设置最大空闲连接 poolConfig.setMaxIdle(8);// 设置最小空闲连接 poolConfig.setMinIdle(0);// 创建连接池对象 jedisPool = new JedisPool( poolConfig, "192.168.26.133", 6379, 1000, "xu123456"); }// 创建方法,用于返回jedis线程池连接 public static Jedis getJedis(){ return jedisPool.getResource(); }}二:测试类测试Jedis数据库连接池
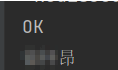
private Jedis jedis; @BeforeEach public void initJedis(){// 建立连接 jedis = JedisConnectFactory.getJedis();// 选择库 jedis.select(0); } @Test public void jedisConnect(){ String result = jedis.set("name", "张三"); System.out.println(result); String name = jedis.get("name"); System.out.println(name); } @AfterEach public void releaseJedis(){ if (jedis != null){ jedis.close(); } }控制台打印:
12.Redis的java客户端SpringDataRedis
12.1SpringDataRedis简介
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis,官网地址:https://spring.io/projects/spring-data-redis
12.2SpringDataRedis的特点
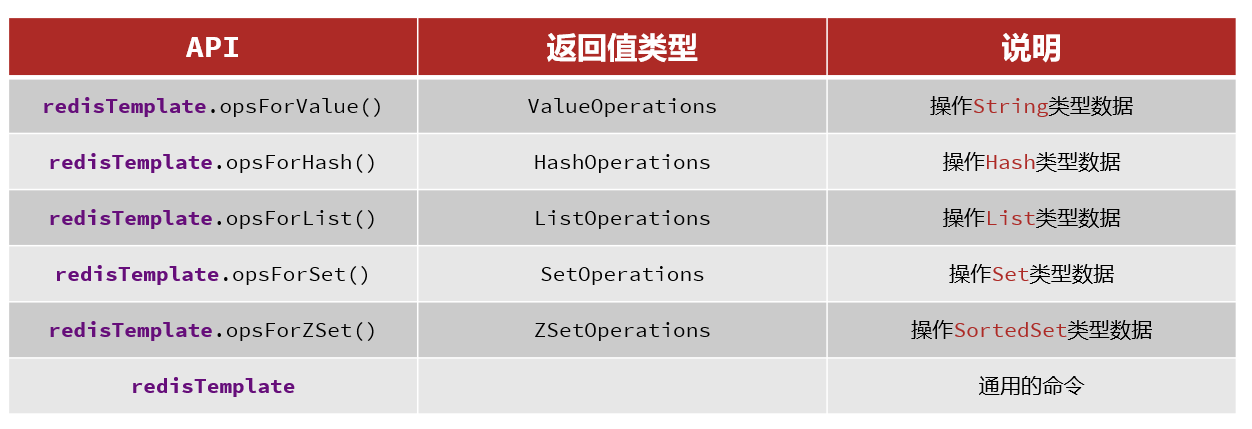
提供了对不同Redis客户端的整合(Jedis和Lettuce)提供了RedisTemplate统一API来操作Redis支持Redis的发布订阅模型支持Redis哨兵和Redis集群支持Lettuce的响应式编程支持基于JDK、JSON、字符串、Spring对象的数据序列化及反序列化支持基于Redis的JDKCollection实现SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中
12.3SpringBoot集成SpringDataRedis
12.3.1引入相应依赖
使用项目初始化工具创建SpringBoot项目
引入Spring对Redis的依赖:
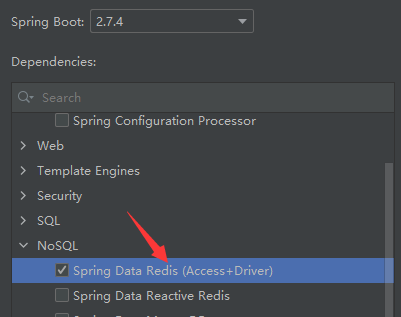
<!-- Spring对redis的整合--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency><!-- 连接池依赖--> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> </dependency>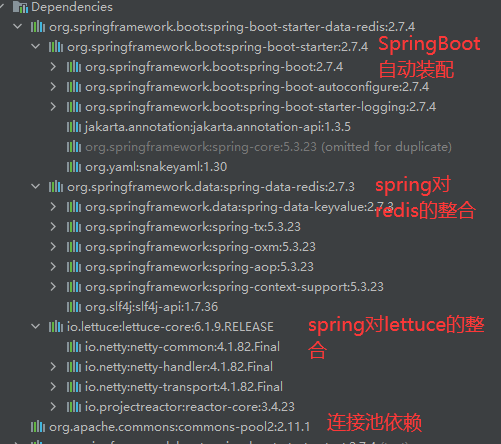
12.3.2在配置文件中添加配置信息
spring: redis: host: "192.168.26.133" port: 6379 password: "xu123456" lettuce: pool: max-active: 8 #最大连接数 max-idle: 8 #最大空闲连接数 min-idle: 0 #最小空闲连接数 max-wait: 100ms #等待连接时间12.3.3测试RedisTemplate
Spring对Redis的封装的各种API
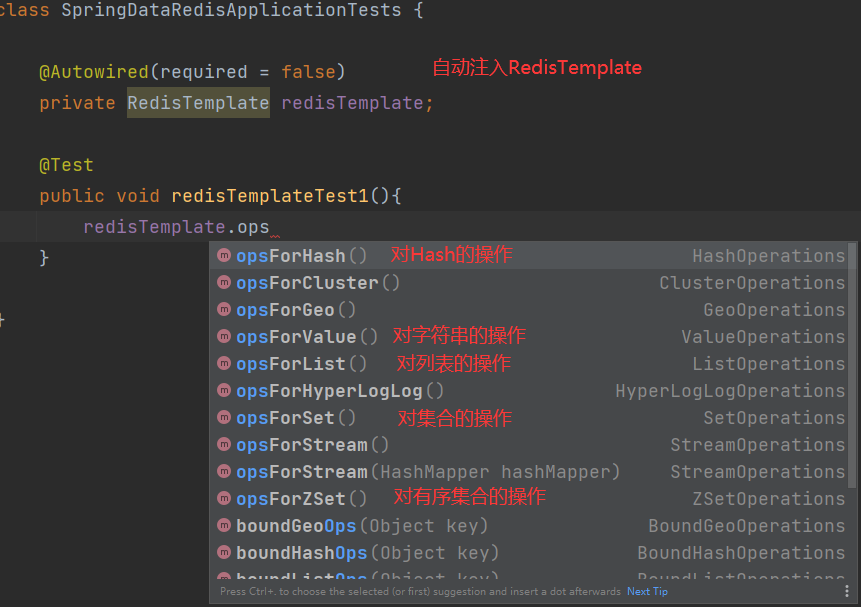
每种API对应了redis所有操作数据的方法
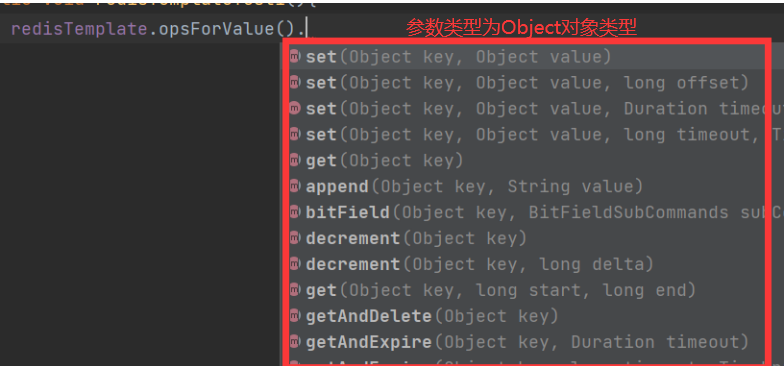
@Autowired(required = false)private RedisTemplate redisTemplate;@Testpublic void redisTemplateTest1(){ redisTemplate.opsForValue().set("username","徐哈哈"); Object username = redisTemplate.opsForValue().get("username"); System.out.println("用户名为:"+username);}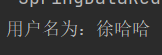
12.3.4RedisTemplate的序列化方式
前面已经看到Spring对Redis的集成的各种Api的各种方法的参数类型为Object类型,而Redis底层对Object对象的处理方式就是使用jdk的序列化工具ObjectOutputStream(对象操作流)进行序列化的。
进入RedisTemplate
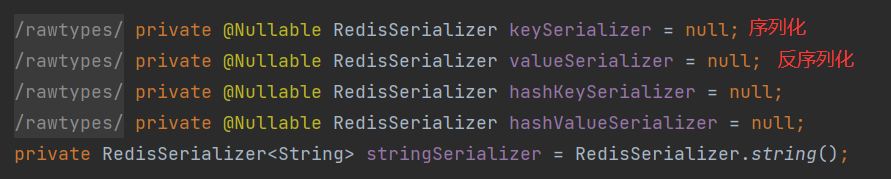
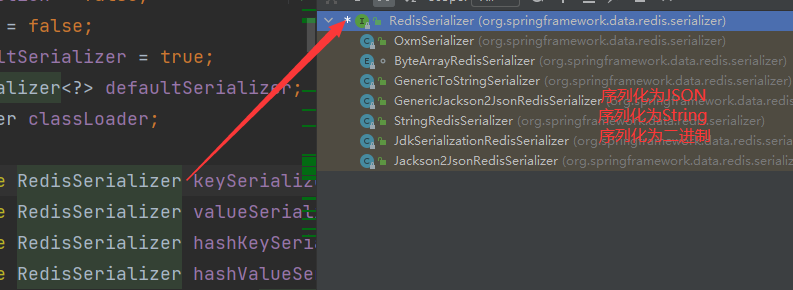
采用ObjectOutputStream序列化得到的结果为:
12.3.5更改RedisTemplate的序列化方式
一:导入相应依赖
导入json解析库的坐标(JSON解析库有:jackson(SpringMVC),fastjson(阿里),gson(Google))
<!-- json解析库--> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> </dependency>二:创建配置类,更改序列化规则
@Configurationpublic class RedisConfig { @Bean public RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory redisConnectionFactory){// 创建Template RedisTemplate<String,Object> redisTemplate = new RedisTemplate<>();// 设置连接工厂 redisTemplate.setConnectionFactory(redisConnectionFactory);// 设置序列化工具 GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();// key和HashKey采用String序列化方式 redisTemplate.setKeySerializer(RedisSerializer.string()); redisTemplate.setHashKeySerializer(RedisSerializer.string());// value和Hashvalue采用JSON序列化方式 redisTemplate.setValueSerializer(RedisSerializer.json()); redisTemplate.setHashValueSerializer(RedisSerializer.json()); return redisTemplate; }}三:再次进行测试,查看序列化情况
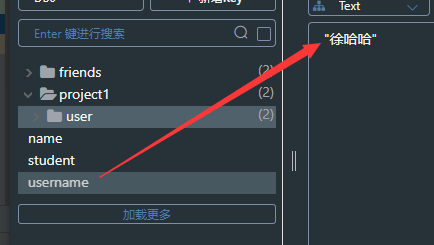
四:创建javaBean,测试对象类型
可以看到当存入缓存的时候对象类型序列化为了JSON类型,读取的时候由JSON类型反序列化为了对象类型。
@Testpublic void redisTemplateTest2(){ redisTemplate.opsForValue().set("user:001",new User(001,"张三",20)); User user001 = (User) redisTemplate.opsForValue().get("user:001"); System.out.println(user001);}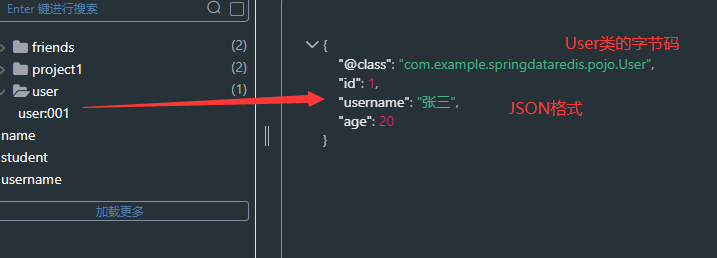
12.3.6StringRedisTemplate
尽管JSON的序列化方式可以满足我们的需求,但依然存在一些问题,如图:
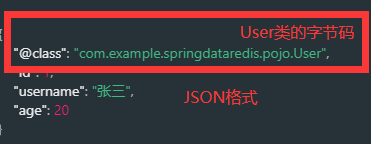
为了在反序列化时知道对象的类型,JSON序列化器会将类的class类型写入json结果中,存入Redis,会带来额外的内存开销。
为了节省内存空间,我们并不会使用JSON序列化器来处理value,而是统一使用String序列化器,要求只能存储String类型的key和value。当需要存储Java对象时,手动完成对象的序列化和反序列化。

Spring默认提供了一个StringRedisTemplate类,它的key和value的序列化方式默认就是String方式。省去了我们自定义RedisTemplate的过程
12.3.7StringRedisTemplate操作字符串类型
ObjectMapper类是Jackson的主要类,它可以帮助我们快速的进行各个类型和Json类型的相互转换。它使用JsonParser和JsonGenerator的实例实现JSON实际的读/写。
测试
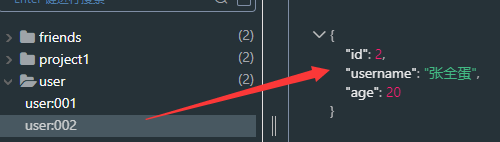
@Autowired(required = false) private StringRedisTemplate stringRedisTemplate; @Test public void StringRedisTemplateTest1() throws JsonProcessingException { ObjectMapper objectMapper = new ObjectMapper();// 创建对象 User user = new User(002,"张全蛋",20);// 手动序列化 String userString = objectMapper.writeValueAsString(user); stringRedisTemplate.opsForValue().set("user:002",userString); String user002String = stringRedisTemplate.opsForValue().get("user:002");// 手动反序列化 User user002 = objectMapper.readValue(user002String, User.class); System.out.println(user002); }JSON字符串

12.3.8StringRedisTemplate操作Hash类型

@Testpublic void StringRedisTemplateTest2() throws JsonProcessingException { stringRedisTemplate.opsForHash().put("user:003", "name", "李四"); stringRedisTemplate.opsForHash().put("user:003", "age", "21"); Map<Object, Object> user = stringRedisTemplate.opsForHash().entries("user:003"); System.out.println(user);}
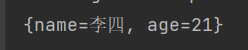
13.Redis缓存
13.1什么是缓存
缓存就是数据交换的缓冲区,是存贮数据的临时地方,一般读写性能较高。
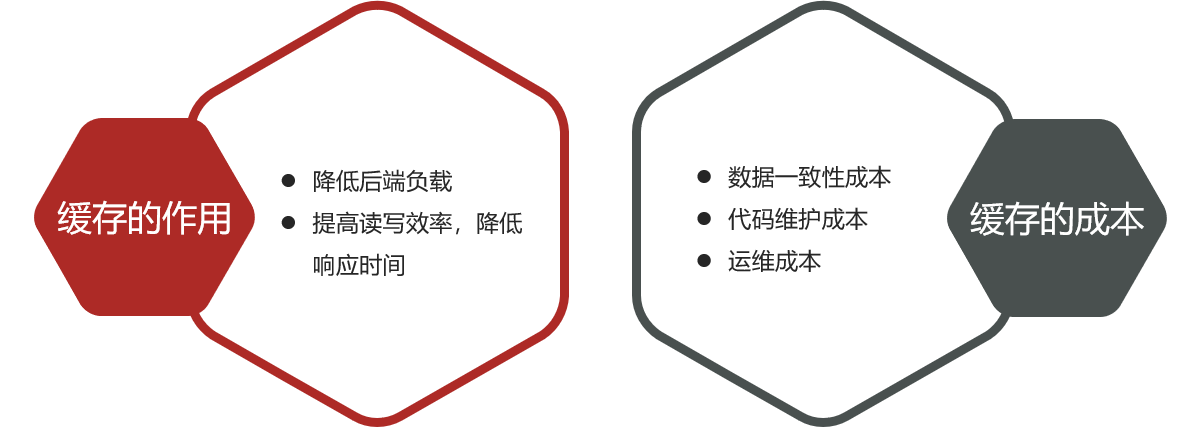
13.2缓存的作用和成本
13.3缓存业务流程
当不使用缓存的时候,当客户端向服务器端发送请求,服务器端每次都会调用DAO层查询数据库,数据库中的数据是写在磁盘当中的,读写效率很慢。
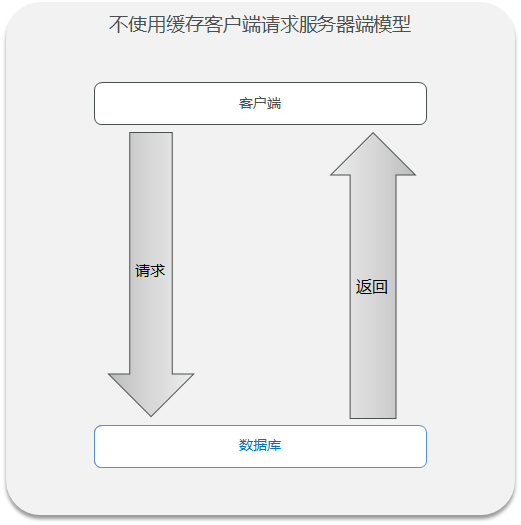
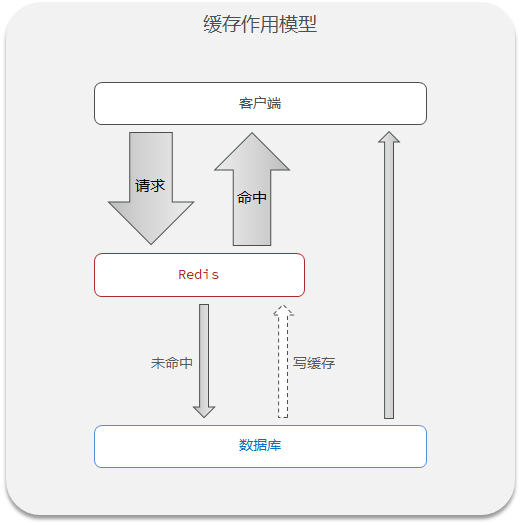
redis缓存的作用就是充当中间件,当客户端前服务器端请求数据的时候,首先会到缓存中查询数据,如果请求命中,redis缓存就返回数据,若请求未命中,则在关系型数据库进行查询,将查询到的数据写入缓存并返回给客户端。
13.4缓存的更新策略
13.4.1缓存更新策略的三种方式
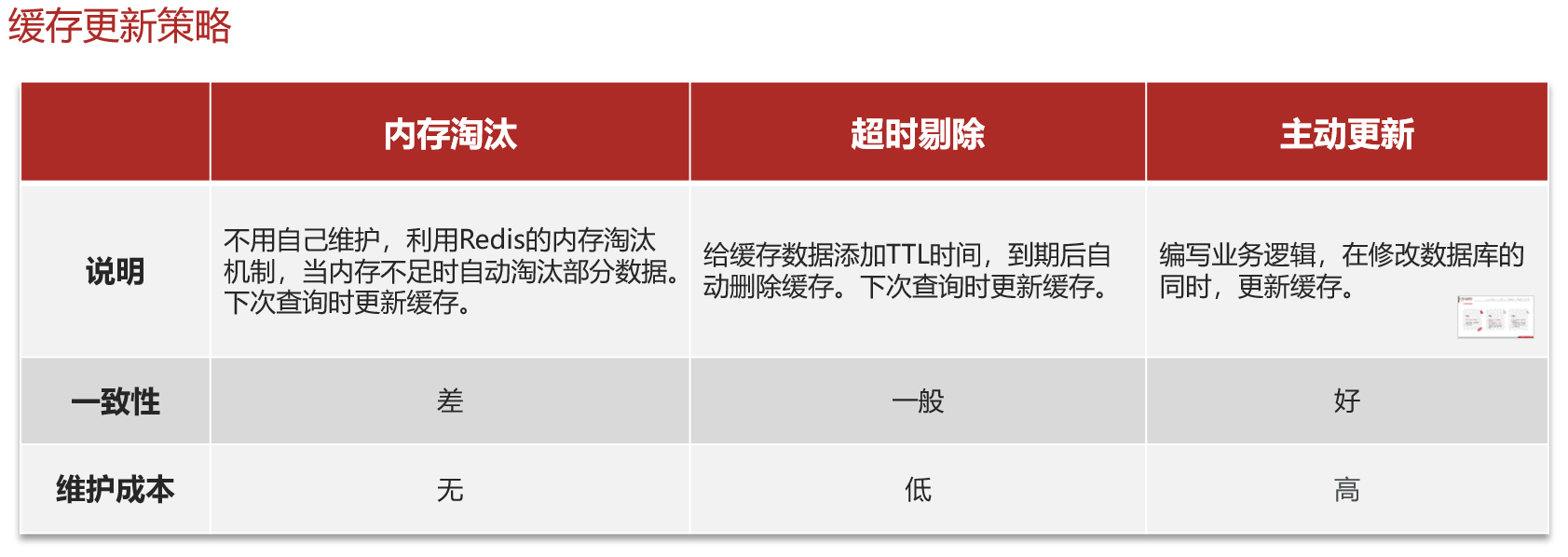
业务场景:
低一致性需求:使用内存淘汰机制。例如不需要经常更新的数据—店铺类型的查询缓存。高一致性需求:主动更新,并以超时剔除作为最后方案。例如店铺详情查询的缓存。13.4.2主动更新策略实现更新的三种方式

操作缓存和数据库的时候有三个问题需要考虑:
删除缓存还是更新缓存
更新缓存:每次更新数据库都更新缓存,无效写操作较多 ✘
删除缓存:更新数据库时让缓存失效,查询时再更新缓存 ✔
如何保证缓存和数据库之间的操作同时成功同时失败
单体系统:将缓存与数据库操作放在一个事务里
分布式系统:利用TCC等分布式事务方案
先操作缓存还是先操作数据库
先删除缓存,再操作数据库
先操作数据库,再删除缓存
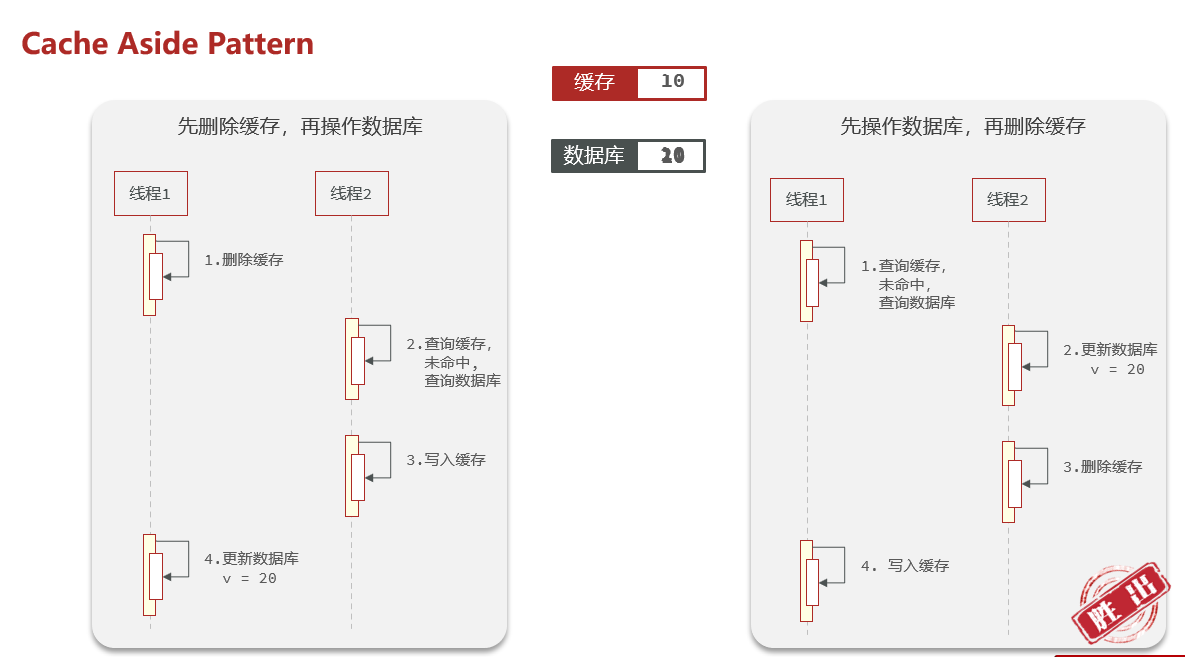
13.4.3缓存更新的最佳方案

13.5缓存穿透
13.5.1缓存穿透的定义
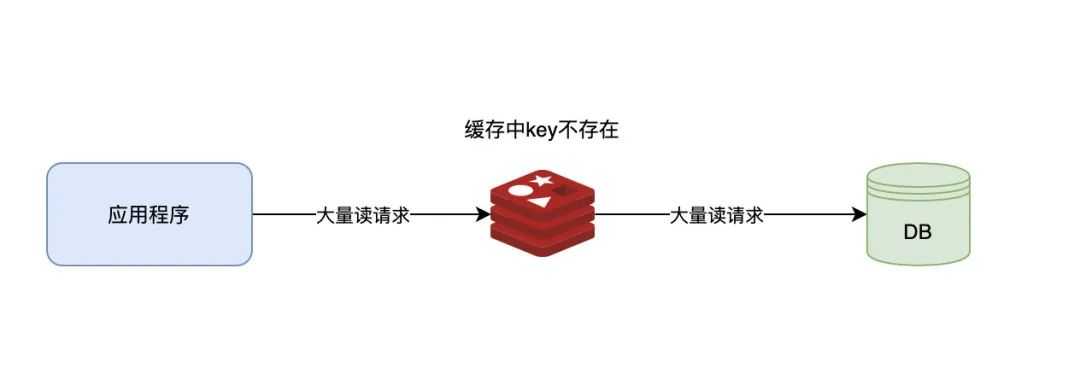
缓存穿透是客户端请求的数据既不在缓存当中,也不在数据库中。出于容错的考虑,如果从底层数据库查询不到数据,则不写入缓存。这就导致每次请求都会到底层数据库进行查询,缓存也失去了意义。当高并发或有人利用不存在的Key频繁攻击时,数据库的压力骤增,甚至崩溃,这就是缓存穿透问题。
13.5.2缓存穿透的解决方案
缓存空值就是当缓存中和数据库中都不存在客户端请求的数据时,就设置一个空值作为缓存,并为缓存设置过期时间(一般很短),当客户端再次发送同样的请求时就会命中缓存,不会请求数据库,从而减小数据库压力。
布隆过滤
13.6缓存雪崩
13.6.1缓存雪崩的定义
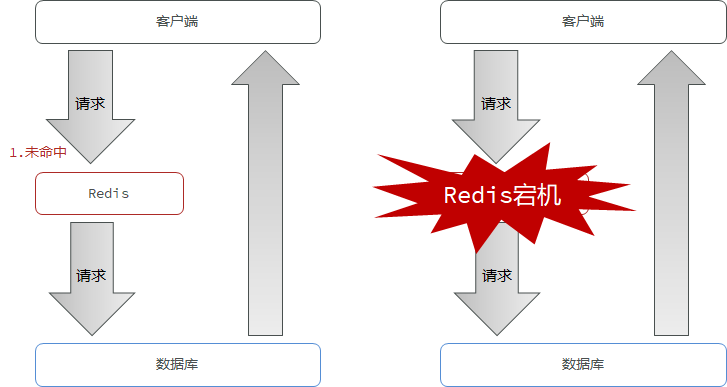
缓存雪崩是指在一段时间内大量的缓存key同时失效或者Redis服务故障,使大量请求到达数据库,从而导致数据库崩溃。
13.6.2缓存雪崩的解决方案
给不同的Key的TTL添加随机值(应对大量key失效的问题)
利用Redis集群提高服务的可用性
给缓存业务添加降级限流策略
给业务添加多级缓存
13.7缓存击穿
13.7.1缓存击穿的定义
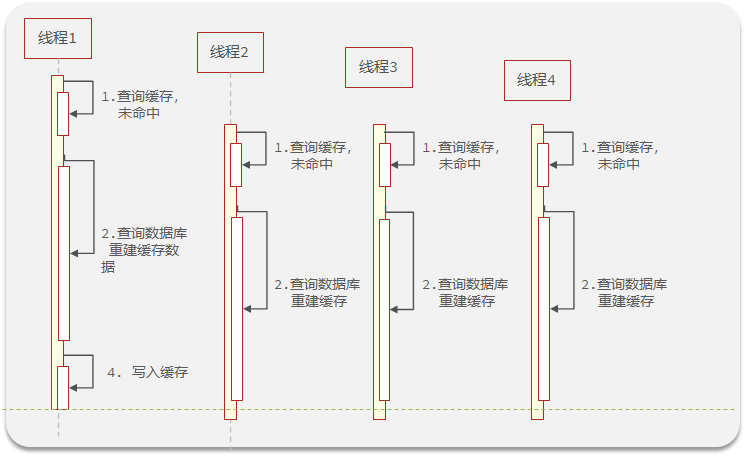
缓存击穿问题也叫热点Key问题,就是一个被==高并发访问并且缓存重建业务较复杂==的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
13.7.2缓存击穿的解决方案
一:互斥锁
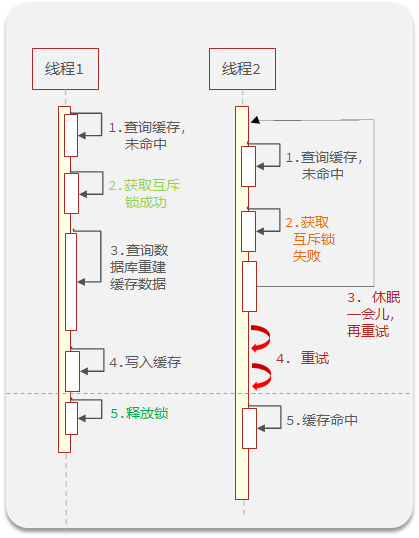
当同个业务不同线程访问redis未命中时,先获取一把互斥锁,然后进行数据库操作,此时另外一个线程未命中时,拿不到锁,等待一段时间后重新查询缓存,此时之前的线程已经重新把数据加载到redis之中了,线程二就直接缓存命中。这样就不会使得大量访问进入数据库
互斥锁的实现方式:
使用setnx实现互斥锁
setnx要求只有当key不存在的时候才能设置key,所以可以采用setnx模拟互斥锁,当一个进程未命中缓存,要查询数据库的时候就添加setnx,并设置过期时间(为了防止忘记释放锁,出现死锁问题)。当其它线程请求时就会等待,等互斥锁时间过期就能获取到缓存中的数据。
二:逻辑过期
给缓存设置一个逻辑过期时间,什么意思呢?缓存本来在redis之中,正常情况下除了主动更新它是不会变的,为了防止缓存击穿,我们以一种预判或者说保守的方式,主动设置一个过期时间,当然这个时间过期了,缓存里面的数据是不会消失的,但是我们只需要根据这个假设的过期时间。来进行经常的动态的缓存数据的更新。可以对缓存击穿起一定的预防作用。
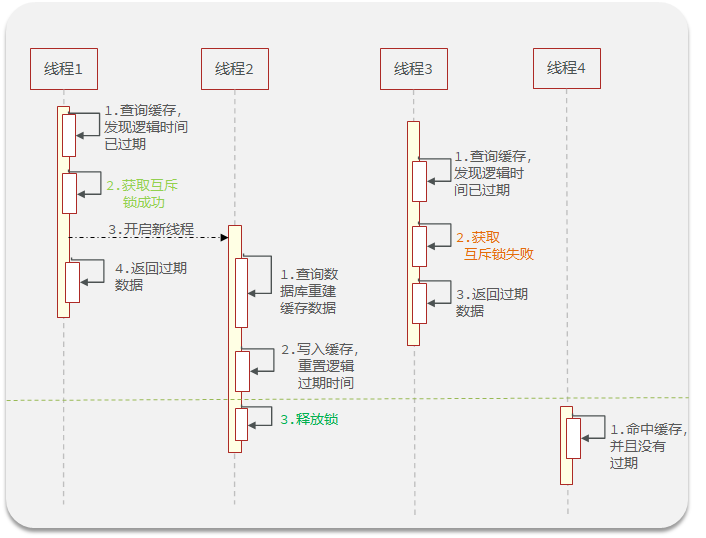
三:互斥锁和逻辑过期的优缺点比较

13.8缓存工具封装
13.8.1解决缓存穿透方法封装
步骤1:将任意Java对象序列化为json并存储在string类型的key中,并且可以设置TTL过期时间(为了在解决缓存穿透时向缓存中添加有效缓存的数据的方法)
步骤2:根据指定的key查询缓存,并反序列化为指定类型,利用缓存空值的方式解决缓存穿透问题
封装的方法:
// 将任意Java对象序列化为json并存储在string类型的key中,并且可以设置TTL过期时间 public void setCacheByThroughPass(String key, Object object, Long time, TimeUnit timeUnit) {// 将对象序列化为Json stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(object), time, timeUnit); } // 根据指定的key查询缓存,并反序列化为指定类型,利用缓存空值的方式解决缓存穿透问题 public <T,ID> T cachePassThrough(String keyPrefix, //key的前缀 ID id, //id类型不确定 Class<T> type, //操作的对象类型,由此对象类型来决定返回值类型T Function<ID,T> dbResult,//函数式编程(数据库查询的逻辑),ID为参数类型,T为返回值类型 Long time, //缓存过期时间 TimeUnit timeUnit) { //时间单位 // 从redis查询用户缓存 String jsonStr = stringRedisTemplate.opsForValue().get(keyPrefix + id);// 判断缓存中是否存在 if (StrUtil.isNotBlank(jsonStr)) {// 存在对象字符串,直接返回 return JSONUtil.toBean(jsonStr, type); }// 判断命中的是否为空字符串 if (jsonStr != null) {// 不为空就是空字符串,就是解决缓存穿透时设置的空值 return null; }// 缓存中不存在,且不为空字符串就去查数据 T obj = dbResult.apply(id);// 数据库中不存在就缓存空值 if (obj == null) { stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, "", CACHE_NULL_TTL, TimeUnit.MINUTES); return null; }// 存在就写入缓存,并设置缓存超时时间 setCacheByThroughPass(keyPrefix + id,obj,time,timeUnit);// 返回商户信息 return obj; }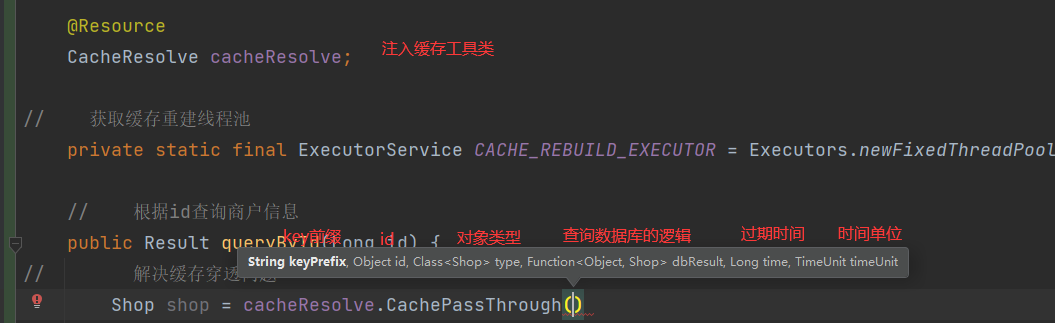
调用封装的方法:font>
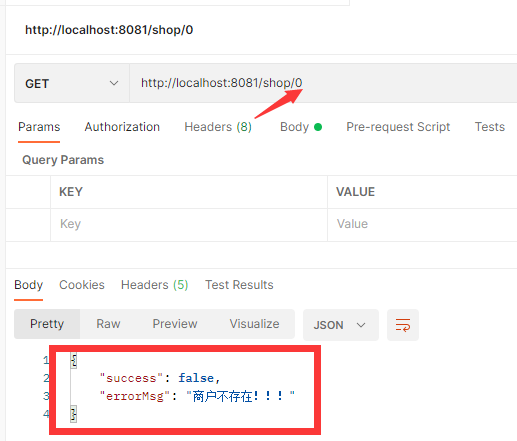
// 根据id查询商户信息 public Result queryById(Long id) {// 利用设置空值解决缓存穿透问题 Shop shop = cacheResolve.cachePassThroughByNull( CACHE_SHOP_KEY, id,Shop.class,// this表示当前对象即IService接口,将方法中的参数id作为数据库查询的参数 this::getById, CACHE_NULL_TTL, TimeUnit.MINUTES); if (shop == null){ return Result.fail("商户不存在!!!"); }// 返回 return Result.ok(shop); }测试:查询缓存和数据库中都不存在的数据:成功向缓存中存入空值
13.8.2解决缓存击穿方法封装
步骤1:将任意Java对象序列化为json并存储在string类型的key中,并且可以设置逻辑过期时间,用于处理缓存击穿问题
步骤2:根据指定的key查询缓存,并反序列化为指定类型,需要利用逻辑过期解决缓存击穿问题
// 获取缓存重建线程池 private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);// 将任意Java对象序列化为json并存储在string类型的key中,并且可以设置逻辑过期时间 public void setCacheByAttackPass(String key, Object object, Long time, TimeUnit timeUnit) {// 设置逻辑过期 RedisData redisData = new RedisData(); redisData.setData(object); redisData.setExpireTime(LocalDateTime.now().plusSeconds(timeUnit.toSeconds(time))); stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(redisData)); } // 利用逻辑过期的方式解决缓存击穿的问题 public <T,ID> T cacheAttackThroughByLogicExpire( String keyPrefix, ID id, Class<T> type, Function<ID,T> dbResult, Long time, TimeUnit timeUnit){// 查询缓存 String jsonStr = stringRedisTemplate.opsForValue().get(keyPrefix + id); if (StrUtil.isBlank(jsonStr)){ return null; }// 缓存命中,将Json字符串反序列化为对象,判断逻辑过期时间 RedisData redisData = JSONUtil.toBean(jsonStr, RedisData.class); T cacheObj = JSONUtil.toBean((JSONObject) redisData.getData(), type); LocalDateTime expireTime = redisData.getExpireTime();// 判断逻辑过期时间是否在当前时间之后 if (expireTime.isAfter(LocalDateTime.now())){// 未过期返回对象信息 return cacheObj; }// 过期,缓存重建,获取互斥锁 String lockKey = SHOP_LOCK_KEY + id; boolean flag = tryLock(lockKey);// 获取互斥锁成功,利用线程池开启独立线程,实现缓存重建 if (flag){ CACHE_REBUILD_EXECUTOR.submit(() -> { try {// 查询数据库重建缓存 T obj = dbResult.apply(id); setCacheByAttackPass(keyPrefix + id,obj,time,timeUnit); } catch (Exception e) { throw new RuntimeException(); } finally { releaseLock(lockKey); } }); }// 获取互斥锁失败,返回过期商铺信息系 return cacheObj; } // 获取锁 private boolean tryLock(String key) { Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "互斥锁", 10, TimeUnit.SECONDS);// 为了防止自动拆箱的过程中出现空指针的现象采用手动拆箱 return BooleanUtil.isTrue(flag); } // 释放锁 private void releaseLock(String key) { stringRedisTemplate.delete(key); }调用封装的方法:
// 利用逻辑过期解决缓存击穿问题 Shop shop = cacheResolve.cacheAttackThroughByLogicExpire( CACHE_SHOP_KEY, id, Shop.class, this::getById, CACHE_EXPIRE_TTL, TimeUnit.MINUTES); if (shop == null){ return Result.fail("商户不存在!!!"); }// 返回 return Result.ok(shop);测试,修改数据库数据,采用JMeter模拟高并发场景
控制台打印一条数据库查询信息

14.分布式锁
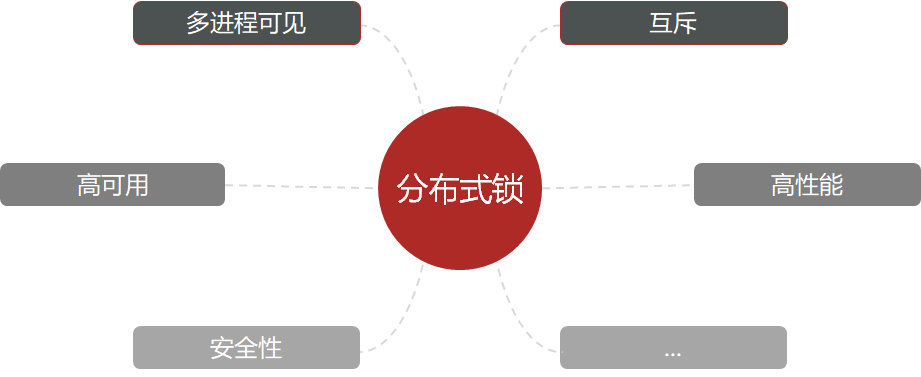
14.1分布式锁的概念
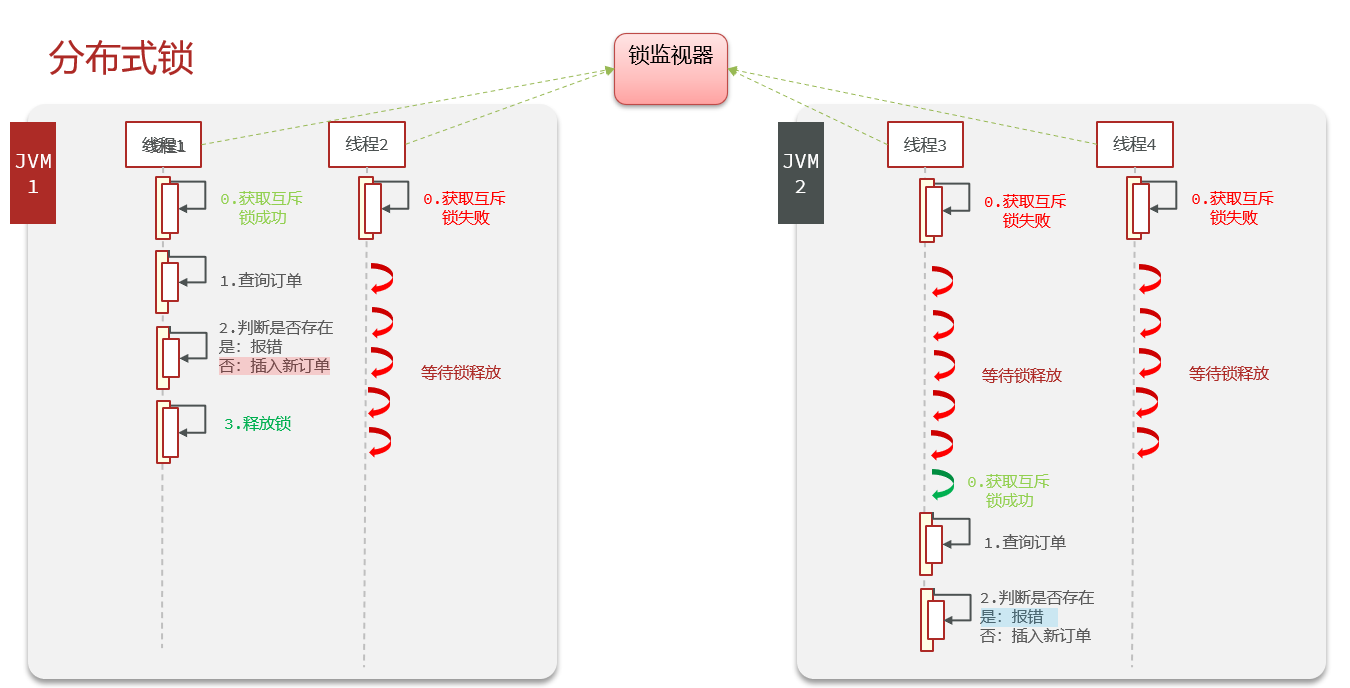
为了解决集群部署模式下多线程并发安全问题,引入分布式锁的概念。
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁
多个服务器使用同一个锁监视器。
14.2分布式锁的实现方式的比较
分布式锁的核心是实现多进程之间互斥,而满足这一点的方式有很多,常见的有三种:
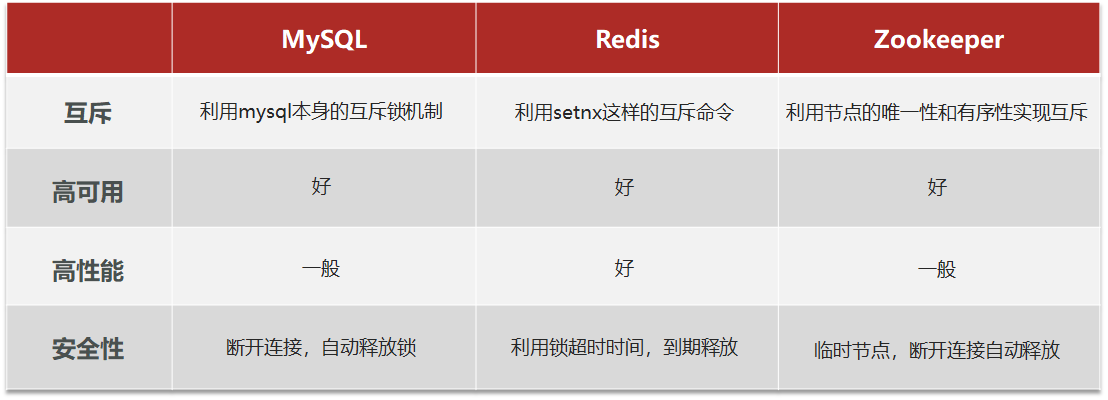
在15.7.7章节使用悲观锁(synchronized)来实现一人一单功能,但是在集群部署模式下,因为synchronized锁只能局限于当前服务器的线程,所以在多个服务器之间不能实现锁共享。
因为由于Redis缓存中的数据在多个服务器之间是共享的,所以可以采用Redis的setnx来实现共享锁监视器
14.3Redis分布式锁实现思路
Redis实现分布式锁时需要实现两个基本方法:
获取锁
互斥:确保只有一个线程获取锁非阻塞:尝试一次,成功返回True,失败返回false
释放锁
手动释放
超时释放:获取锁时添加一个过期时间

setnx原子操作:设置过期时间并设置其原子性
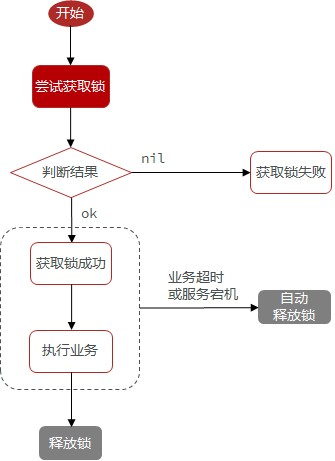
14.4Redis实现分布式锁初级版本
需求:定义一个类,实现下面接口,利用Redis实现分布式锁功能。

public class ILockService implements ILock { @Resource private StringRedisTemplate stringRedisTemplate; @Resource private String keyName; @Override public boolean tryLock(Long timeOutSec) {// 获取线程id long id = Thread.currentThread().getId();// 获取锁,以当前线程的id作为value Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(DISTRI_LOCK_KEY + keyName, id+"", timeOutSec, TimeUnit.SECONDS); return BooleanUtil.isFalse(flag); } @Override public void releseLock() {// 释放锁 stringRedisTemplate.delete(DISTRI_LOCK_KEY + keyName); }}测试单元见 15.7.9
14.5Redis分布式锁误删问题
场景描述:线程1首先获取到分布式锁,但是线程1执行过程中出现业务阻塞,导致分布式锁没有被主动释放,超时之后才被释放。释放后,线程2开始获取到分布式锁,并开始执行业务,在此期间,线程1的业务完成,并释放分布式锁(释放的锁是线程2的锁)。分布式锁被释放,其他线程就能获取到分布式锁。
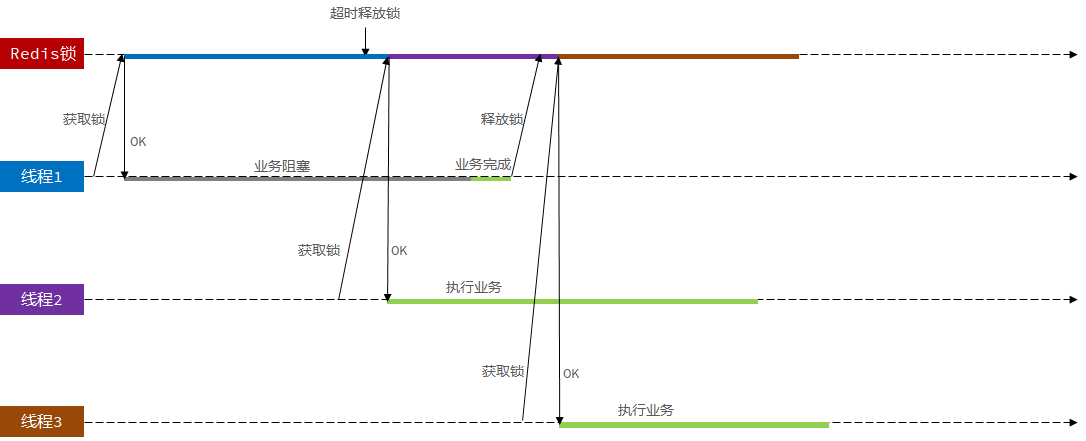
解决分布式锁误删的方案:在释放锁之前判断Redis缓存当中线程号是否和当前线程的线程号相同,相同就是放,不同就不释放。
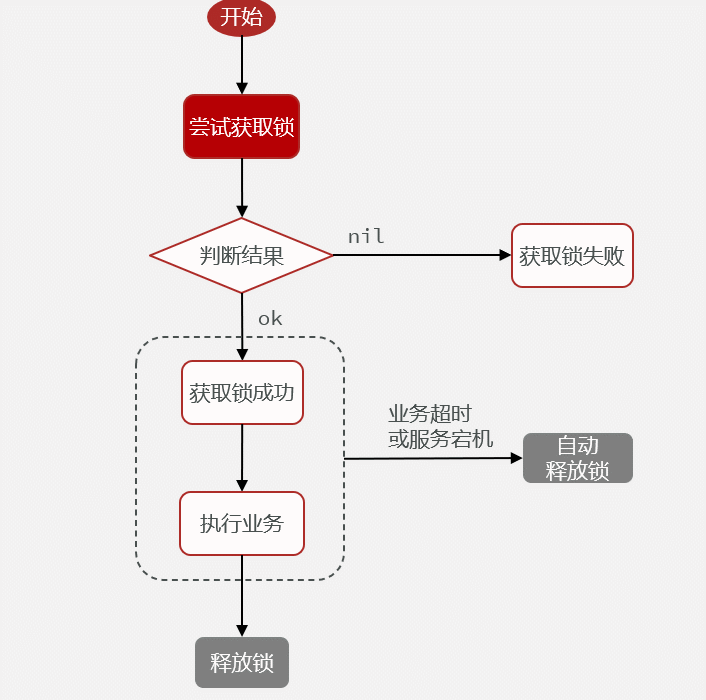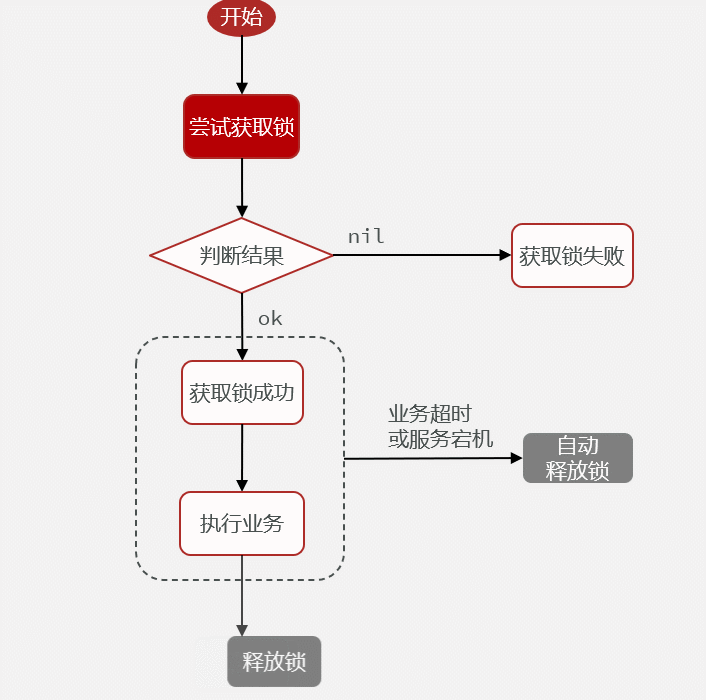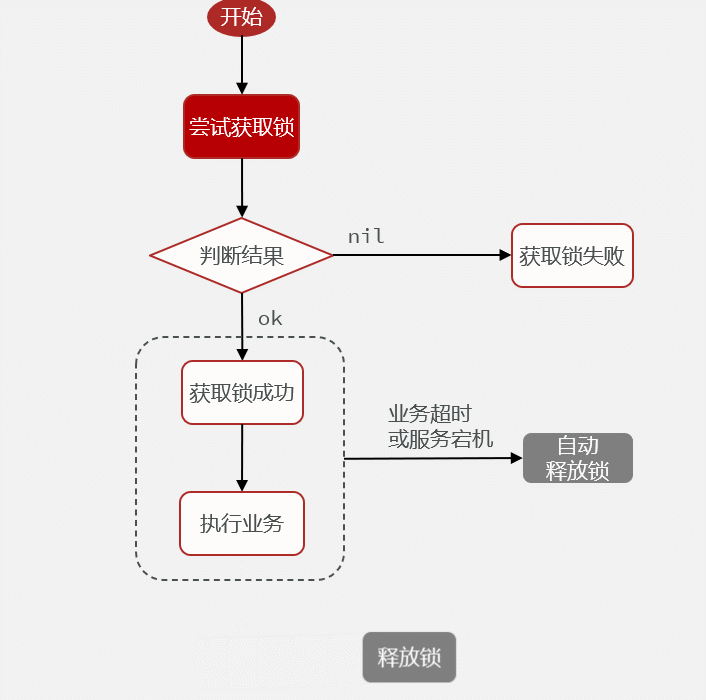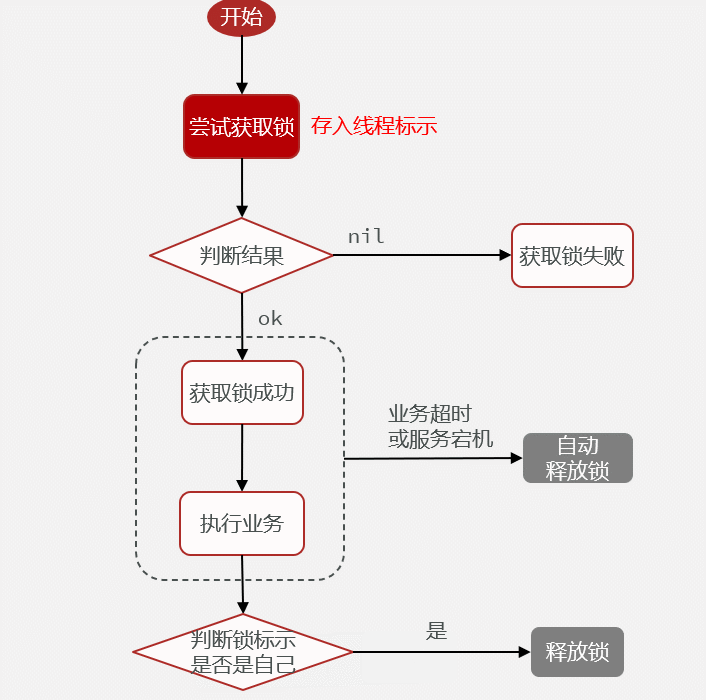
14.6解决分布式锁的误删问题
需求:修改之前的分布式锁实现,满足:
1.在获取锁时存入线程标示(可以用UUID表示)
2.在释放锁时先获取锁中的线程标示,判断是否与当前线程标示一致
如果一致则释放锁
如果不一致则不释放锁
之前采用的锁标识方案为采用线程id(线程id是自增的),但是在集群模式下,多个JVM有可能会产生相同的线程id,所以要加上UUID。
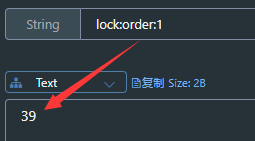
测试单元见15.7.10
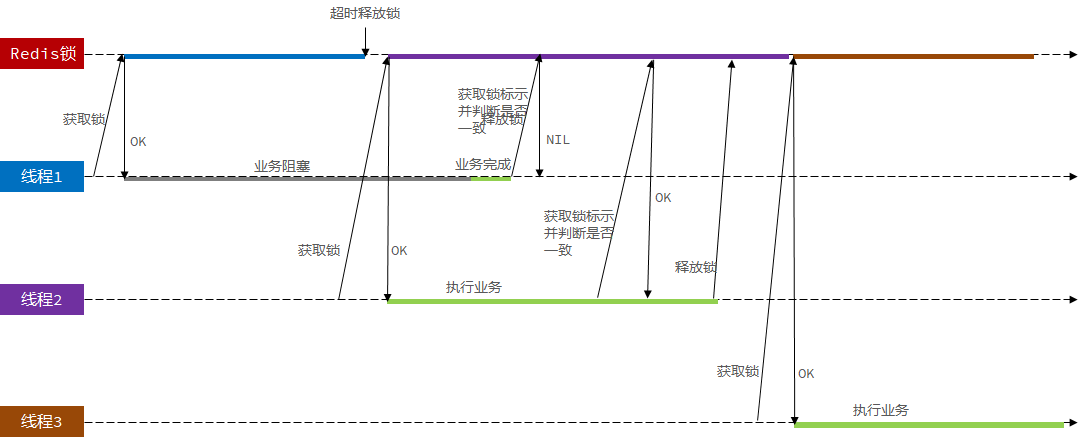
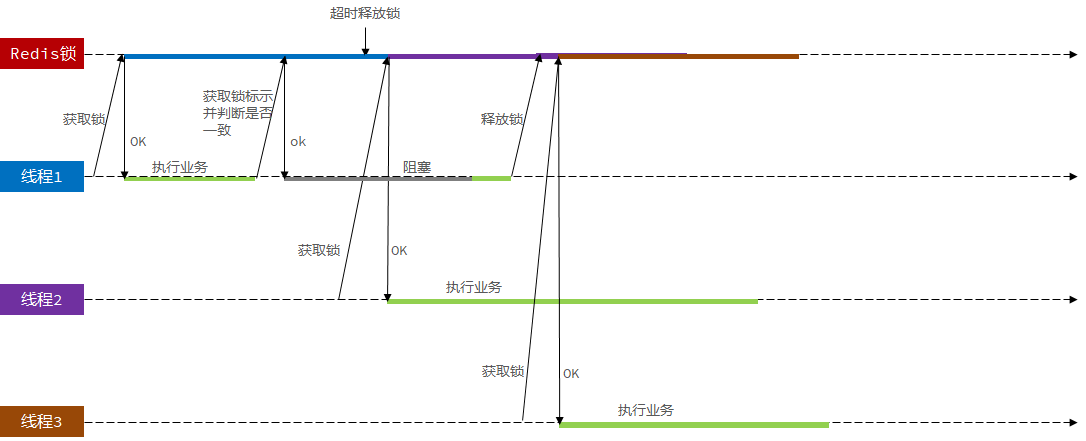
14.7分布式锁的原子性问题
场景描述:线程1获取到分布式锁,当线程完成业务查询分布式锁标识和自己的相符后,准备释放锁时,线程阻塞 ,随后超时释放。另一个线程开始获得分布式锁,执行自己的业务。但是线程1这事从阻塞状态转为就绪状态,因为已经判断过了分布式锁标识,随后就直接释放线程2的分布式锁。
使用Lua脚本实现“判断分布式锁标识”和“释放锁”两个业务的原子性
Redis提供了Lua脚本功能,在一个脚本中编写多条Redis命令,确保多条命令执行时的原子性。Lua是一种编程语言,它的基本语法大家可以参考网站:https://www.runoob.com/lua/lua-tutorial.html
14.8Lua脚本语言
Lua是一种轻量小巧的脚本语言,可以很方便的和其他程序进行集成和扩展(C#,Java…),其设计目的是为了嵌入应用程序中,为应用程序提供灵活的扩展和定制功能。
在使用redis的过程中,发现有些时候需要原子性去操作redis命令,而redis的lua脚本正好可以实现这一功能。比如: 扣减库存操作、限流操作等等。
Redis提供的Lua脚本调用函数语法如下:
redis.call('命令名称','key','其他参数',....)写好脚本以后,需要用Redis命令来调用脚本,调用脚本的常见命令如下:
例如,我们要执行==redis.call(‘set’, ‘name’, ‘jack’)==这个脚本,语法如下:

如果脚本中的key、value不想写死,可以作为参数传递。key类型参数会放入KEYS数组,其它参数会放入ARGV数组,在脚本中可以从KEYS和ARGV数组获取这些参数:

在idea中安装Lua脚本的相关插件
使用Lua脚本实现分布式锁的原执行操作,测试单元见15.7.11
15.Redisson框架
15.2Redisson引入
基于setnx实现的分布式锁会出现以下问题:
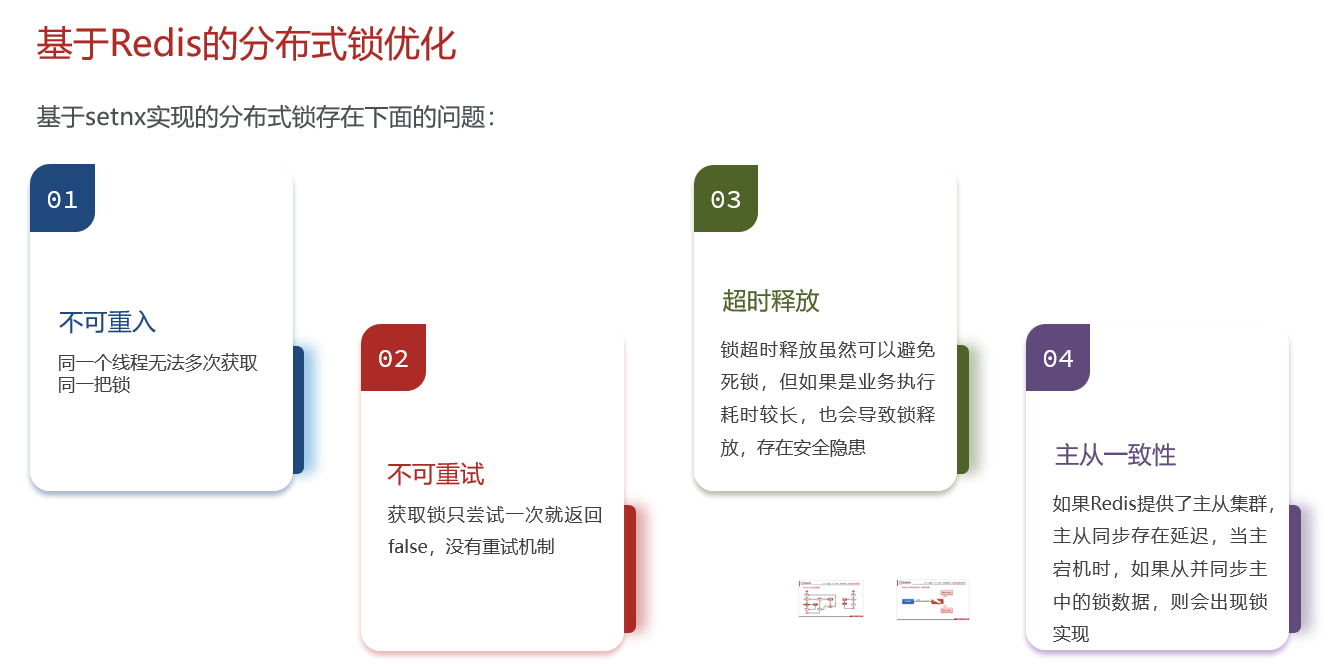
15.2Redisson框架简介
之前用的Redis,都是用的原生的RedisTempale或者是StringRedisTemplate,各种API非常的难易记忆,每次用的时候还得去网上查询API文档。
Redisson是一个在Redis的基础上实现的Java驻内存数据网格。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。其中就包含了各种分布式锁的实现。Redisson是Java的Redis客户端之一,提供了一些API方便操作Redis。

15.3Redisson配置
一:引入Redisson依赖
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.13.6</version></dependency>二:创建配置对象
@Configurationpublic class RedissonConfig { @Bean// RedissonClient是Redisson的工厂类 public RedissonClient redissonClient(){// 创建配置对象 Config config = new Config();// 设置redis地址和密码 config.useSingleServer().setAddress("redis://43.143.117.57").setPassword("xu123456");// 创建RedissonClient对象 return Redisson.create(config); }}三:在使用的类中注入RedissonClient,获取锁,释放锁
测试单元在15.7.12
15.4Redisson可重入锁原理
一个线程连续两次获取锁就是锁的重入。
以下方式是采用setnx自定义锁的方式,当一个线程获取到锁后,调用另一个方法再次获取到锁,但是由于是因为基于setnx实现的,再次获取所就会失败。
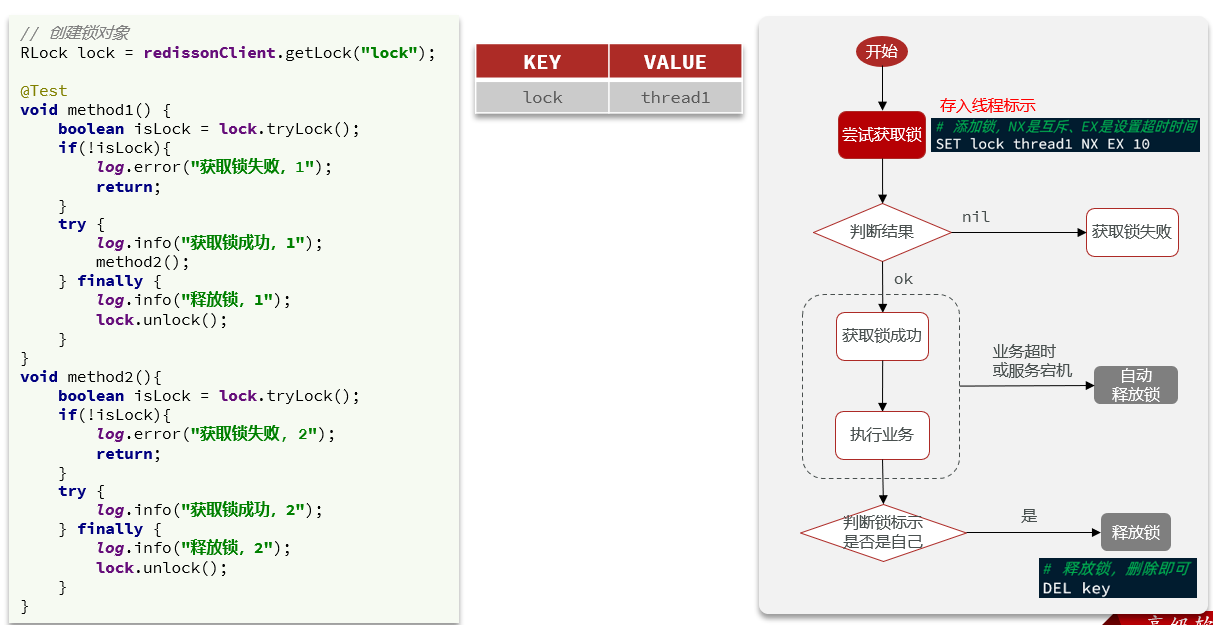
而Redisson实现重入锁的原理就是判断获取分布式锁的线程是否是当前线程,并且记录线程获取锁的次数。当当前线程再次获取分布式锁的时候获取锁的次数就会增加,释放锁后再释放。
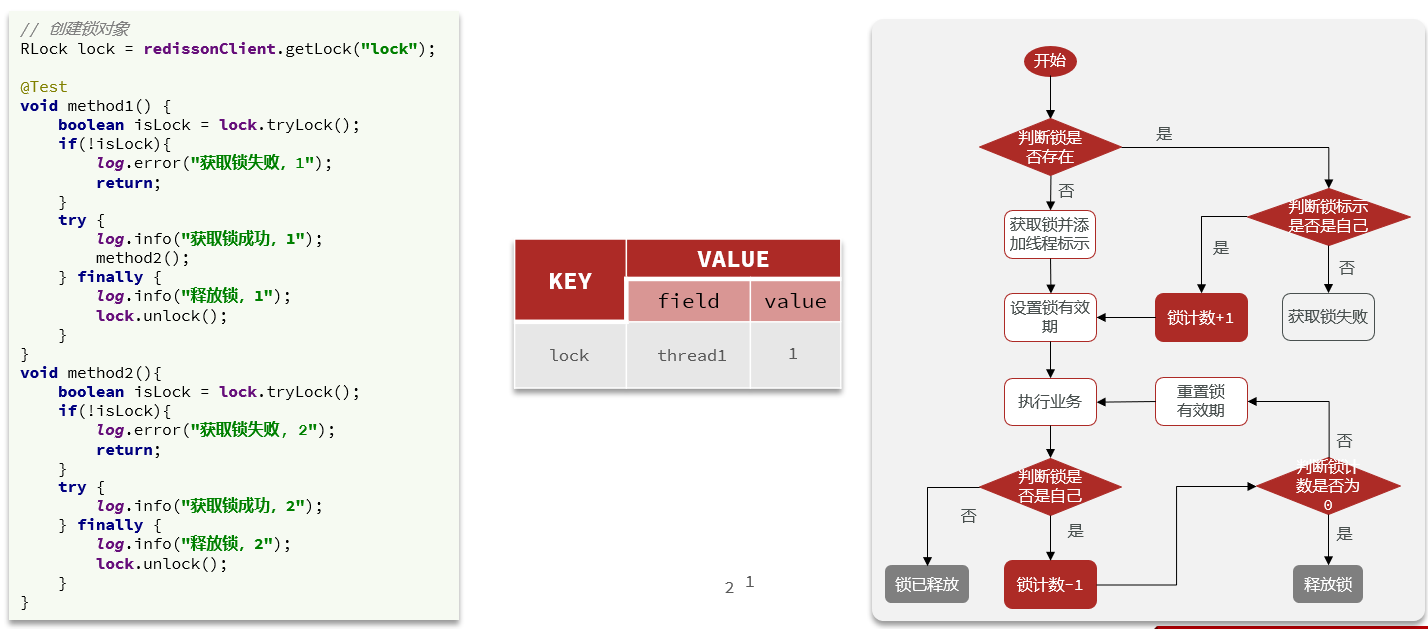
Redisson的分布式锁的创建过程:
查看RedissionClient接口的实现类,实现类是Redisson

getLock方法中调用了RedissonLock类中的构造器
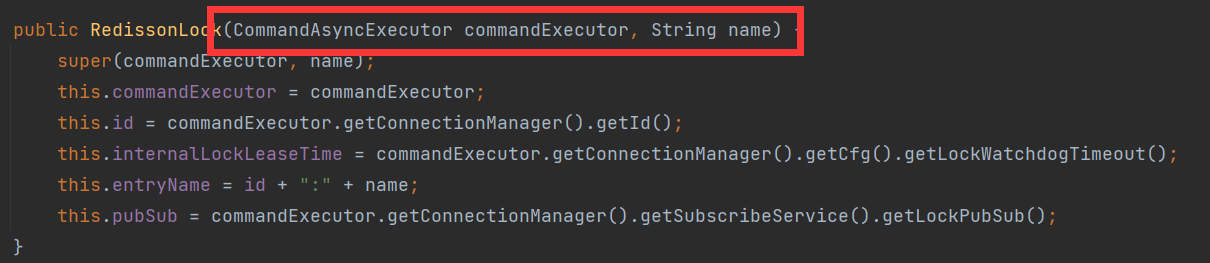
找到创建锁的lua脚本
<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) { internalLockLeaseTime = unit.toMillis(leaseTime); return evalWriteAsync(getName(), LongCodec.INSTANCE, command, //若锁不存在,就创建锁 "if (redis.call('exists', KEYS[1]) == 0) then " + //redis中hash的value加1 "redis.call('hincrby', KEYS[1], ARGV[2], 1); " + //设置过期时间 "redis.call('pexpire', KEYS[1], ARGV[1]); " + "return nil; " + "end; " + //若锁存在 "if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " + //hash的value加1 "redis.call('hincrby', KEYS[1], ARGV[2], 1); " + //重设过期时间 "redis.call('pexpire', KEYS[1], ARGV[1]); " + "return nil; " + "end; " + "return redis.call('pttl', KEYS[1]);", Collections.singletonList(getName()), internalLockLeaseTime, getLockName(threadId));}测试:
@Slf4j@SpringBootTestpublic class ThreadRedissonTest { @Resource private RedissonClient redissonClient; private RLock lock; // 创建锁对象 @BeforeEach void createLock() { lock = redissonClient.getLock(DISTRI_LOCK_KEY); } @Test void method1() {// 获取到锁 boolean flag = lock.tryLock(); if (!flag) {// 获取锁失败 log.error("Method1 acquire lock fail"); } try {// 获取锁成功 log.info("Method1 acquire lock success"); method2(); log.info("Method1 Begin execute work"); } finally {// 释放锁 log.info("Method1 begin release lock"); lock.unlock(); } } void method2() {// 获取到锁 boolean flag = lock.tryLock(); if (!flag) { log.error("Method2 acquire lock fail"); } try { log.info("Method2 acquire lock success"); log.info("Method2 Begin execute work"); } finally { // 释放锁 log.info("Method2 begin release lock"); lock.unlock(); } }}执行方法1,获取锁成功,在缓存中存入锁的标识和获取重入次数,当前次数为1
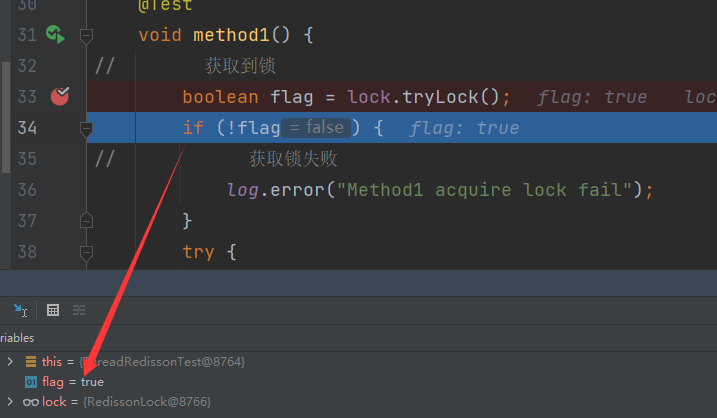
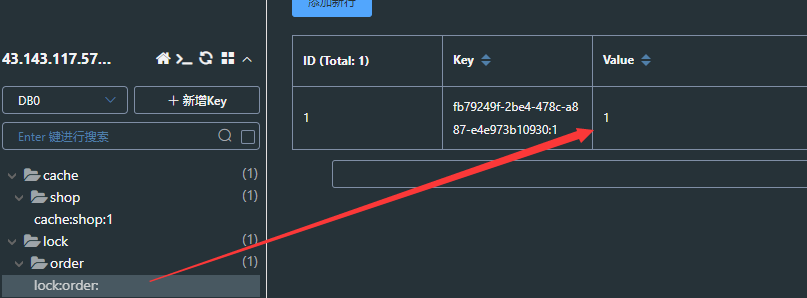
执行到方法2,获取锁成功,重入次数变为2
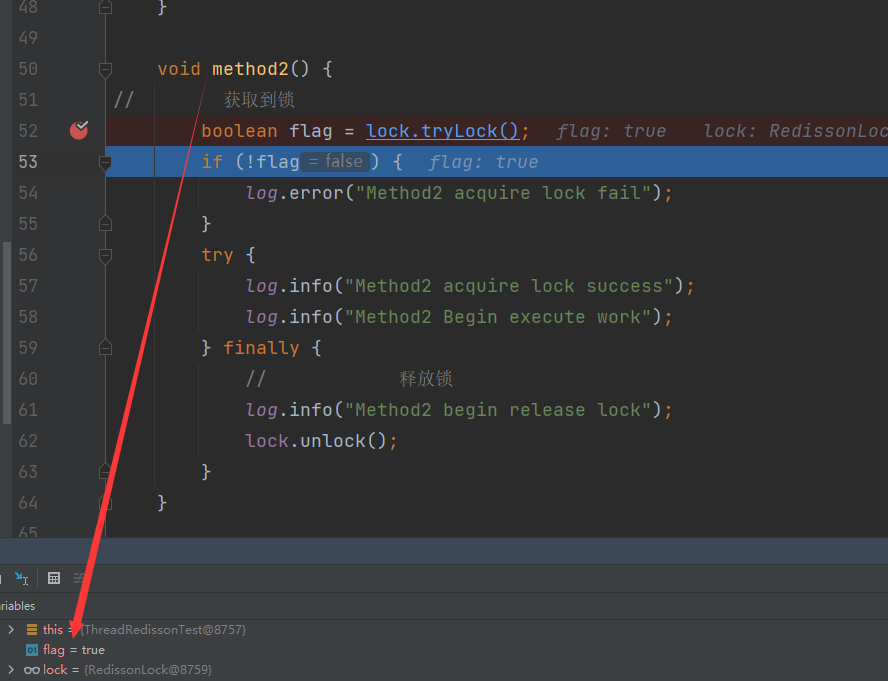
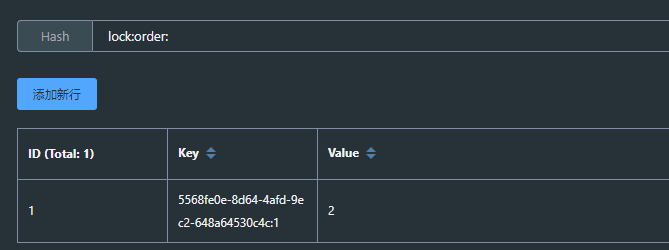
方法2执行后释放锁,重入次数变为1,再执行方法1,重入次数变为0
控制台业务流程:

15.5Redisson锁重试和WatchDog机制
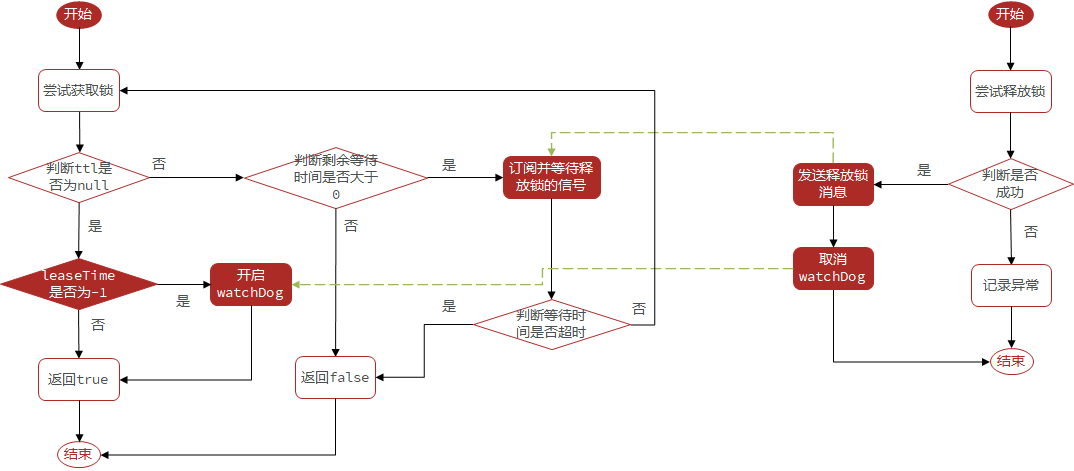
Redisson分布式锁原理:
•可重入:利用hash结构记录线程id和重入次数
•可重试:利用信号量和PubSub功能实现等待、唤醒,获取锁失败的重试机制
•超时续约:==利用watchDog,每隔一段时间(releaseTime / 3),重置超时时间=
15.6Redisson分布式锁主从一致性问题
主从一致性就是一个主节点连有两个从节点,主节点和从节点之间存在主从同步,当一个线程获取锁的时候,主节点存入分布式锁标识。但是在未完成主从同步的时候主节点发生宕机。发生宕机后哨兵会在剩下的从节点中选出一个作为主节点,但是此主节点中并没有分布式锁标识。这就是导致主从一致性的问题。

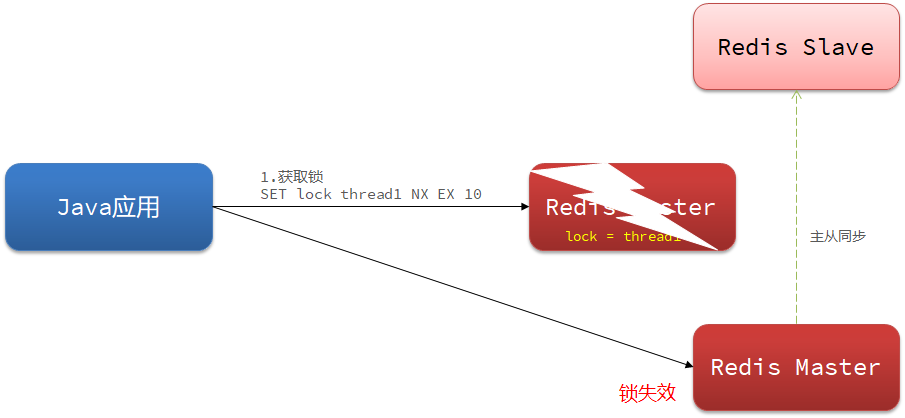
解决主从一致性问题的方法:
只要有任意节点存活,其他线程就获取不到锁,不会出现锁失效问题。

16.消息队列
16.2消息队列的概念
消息队列(Message Queue)一般简称为MQ。是指利用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成,是在消息的传输过程中保存消息的容器。消息队列本质上是一个队列,而队列中存放的是一个个消息。
最简单的消息队列模型包括3个角色:
生产者:发送消息到消息队列
消息队列:存储和管理消息,也被称为消息代理(Message Broker)
消费者:从消息队列获取消息并处理消息
消息队列让生产者和消费者之间解耦合

可以采用市面上提供的消息队列,如Kafka、RabbitMQ、RocketMQ等等,但是Redis也提供了三种不同的方式来实现消息队列:
list结构:基于List结构模拟消息队列
PubSub:基本的点对点消息模型
Stream:比较完善的消息队列模型
16.3消息队列-list结构
队列底层的实现是双向链表,是入口和出口不在一边,因此我们可以利用:LPUSH 结合 RPOP、或者 RPUSH 结合 LPOP来实现。
不过要注意的是,当队列中没有消息时RPOP或LPOP操作会返回null,并不像JVM的阻塞队列那样会阻塞并等待消息。因此这里应该使用BRPOP或者BLPOP来实现阻塞效果。
Redis brpop命令移出并获取列表最右侧的元素。如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
blpop是相反方向。
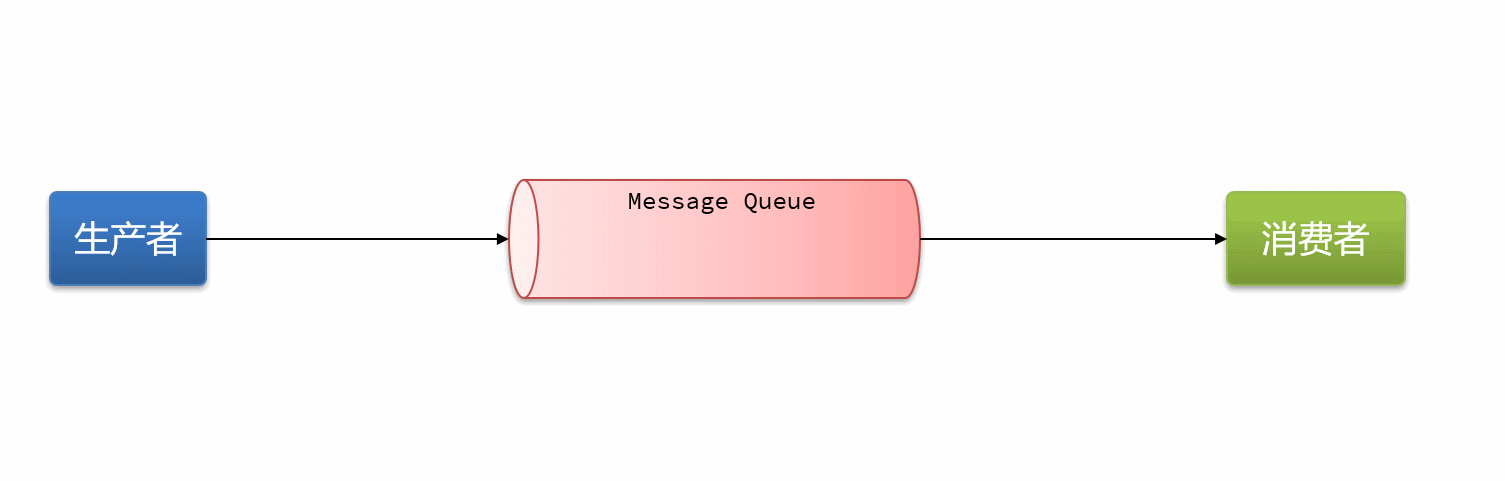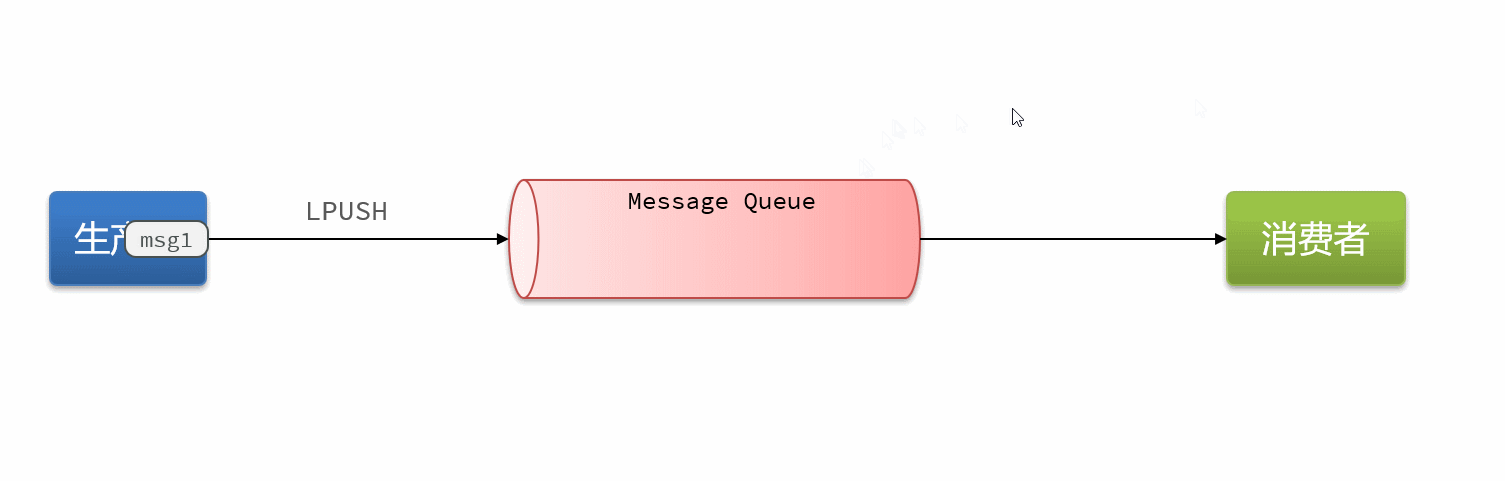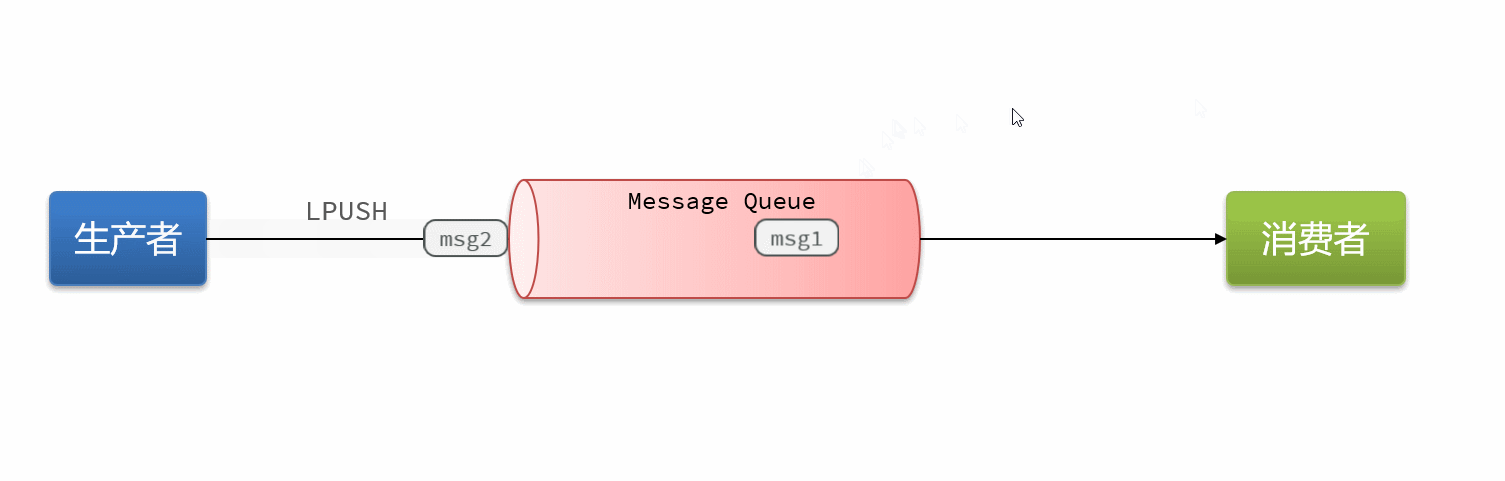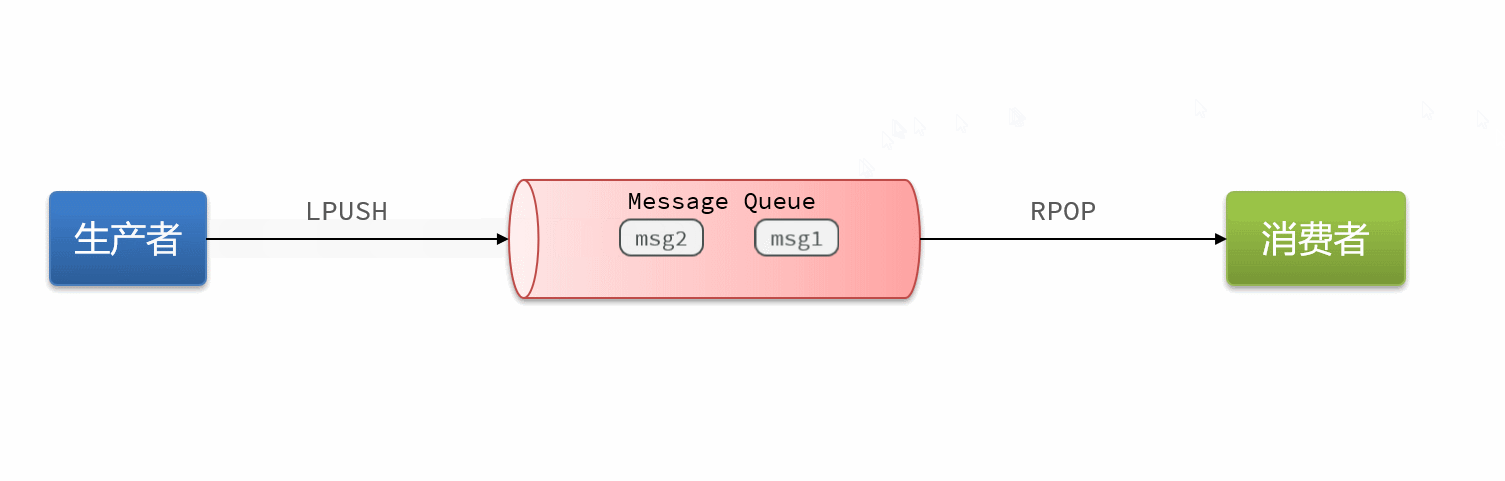
基于List的消息队列有哪些优缺点?
优点:
利用Redis存储,不受限于JVM内存上限
基于Redis的持久化机制,数据安全性有保证
可以满足消息有序性
缺点:
无法避免消息丢失
只支持单消费者
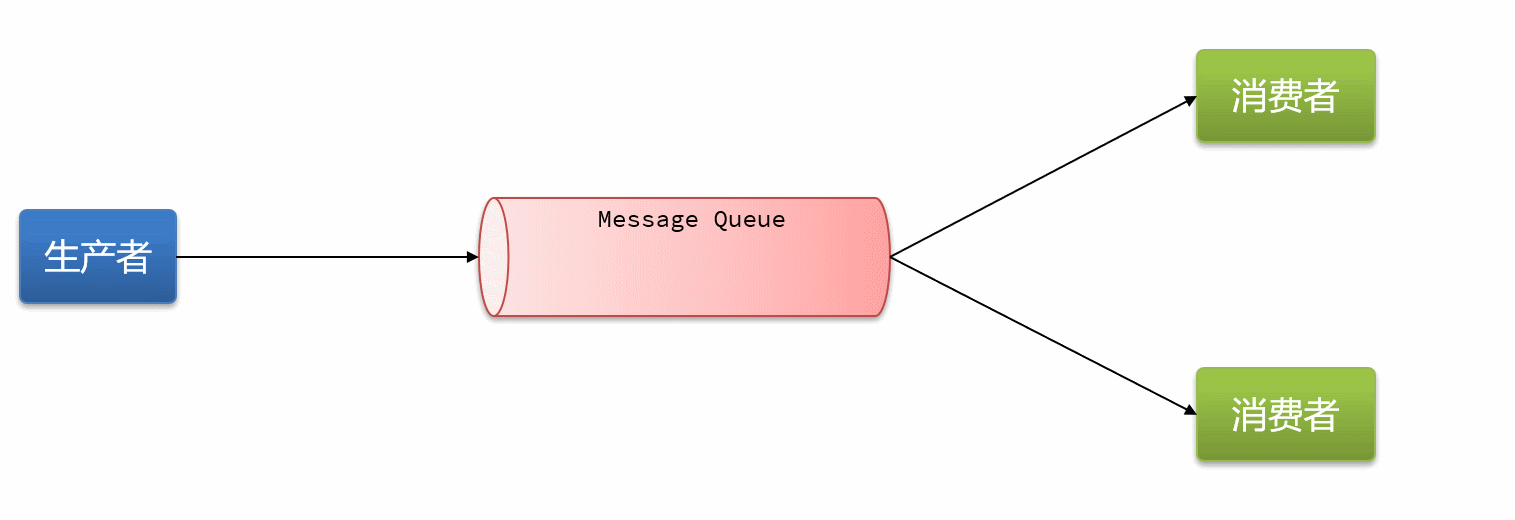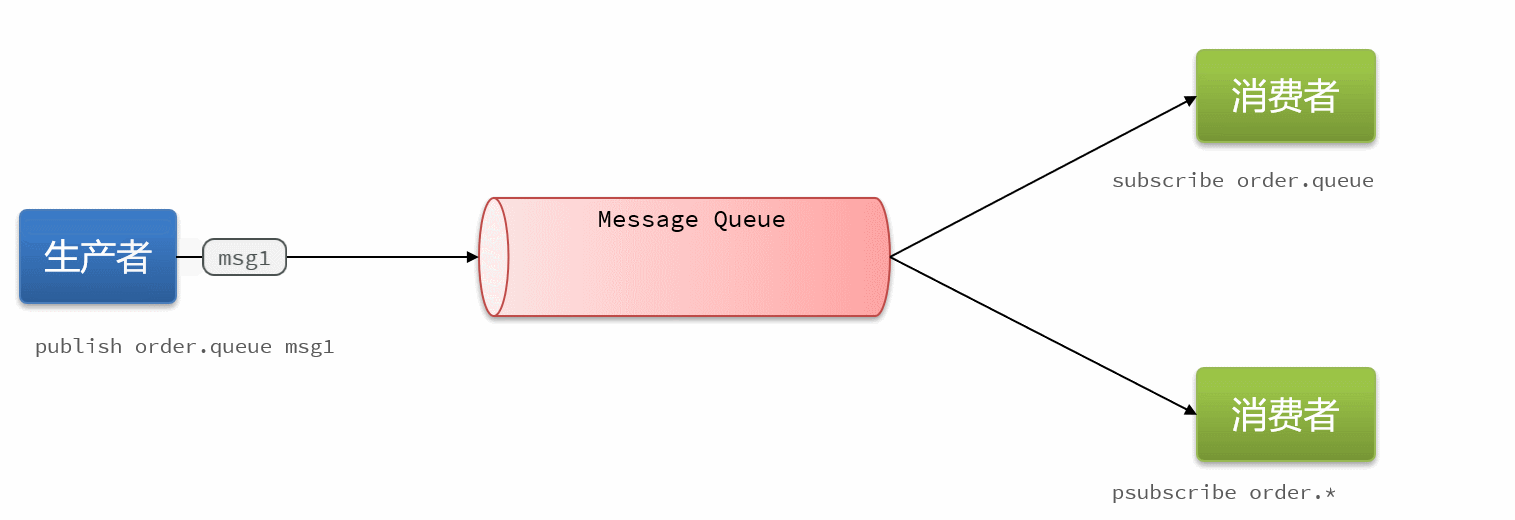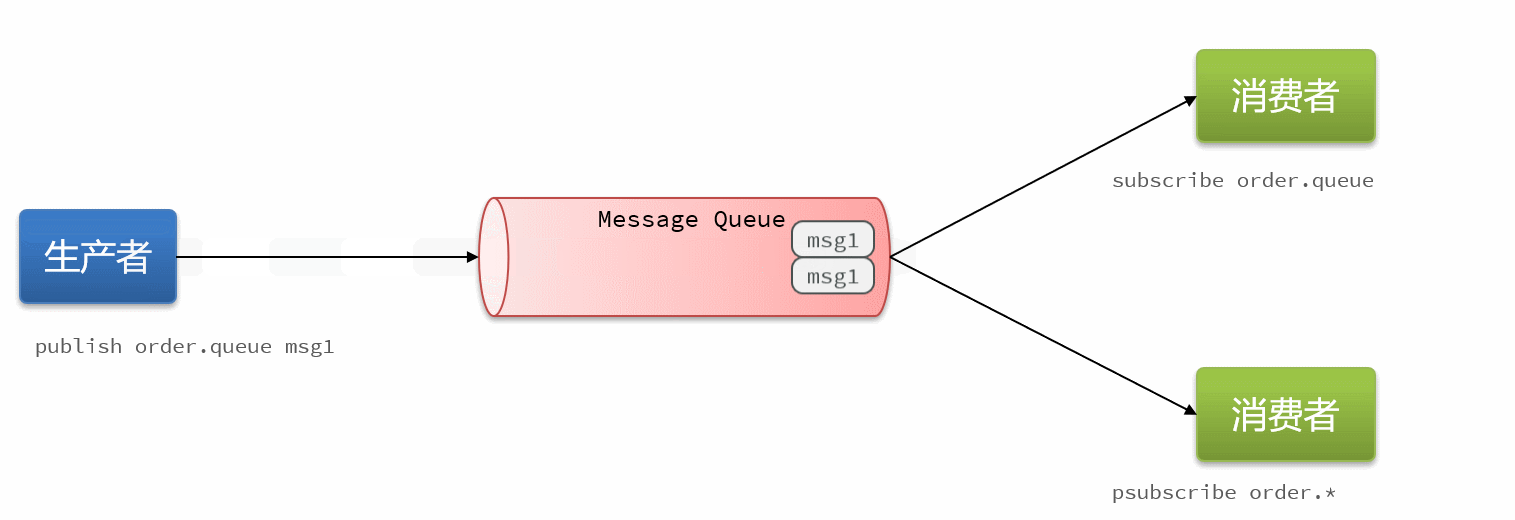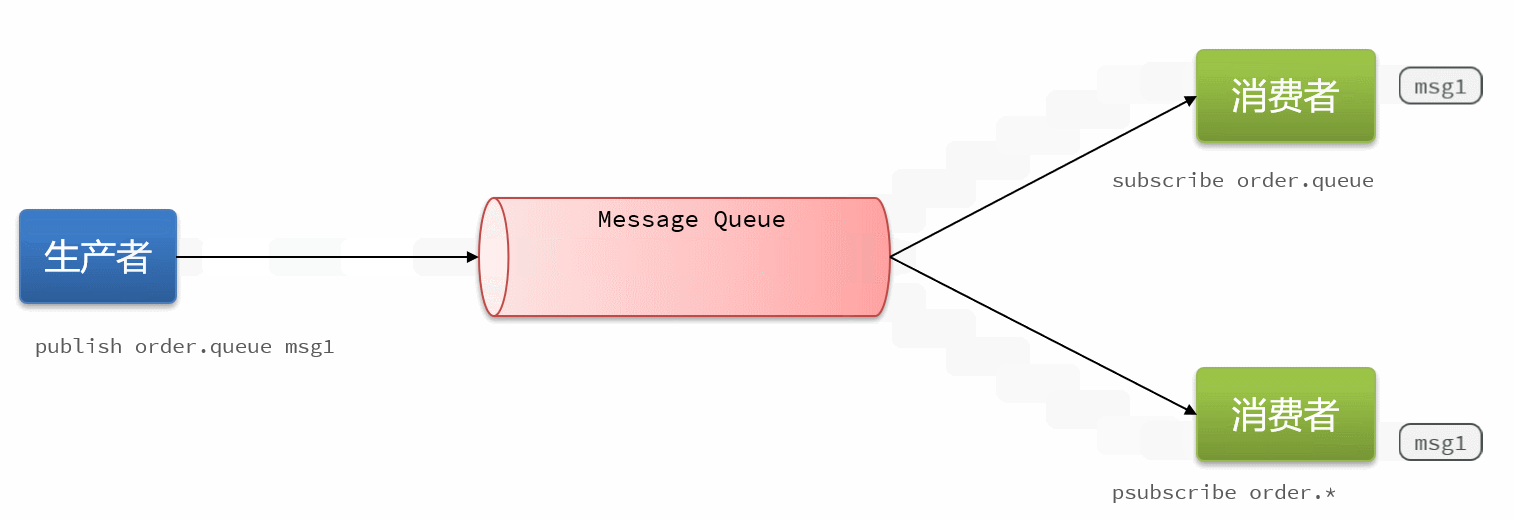
16.4消息队列-PubSub
PubSub(发布订阅)是Redis2.0版本引入的消息传递模型。顾名思义,消费者可以订阅一个或多个channel,生产者向对应channel发送消息后,所有订阅者都能收到相关消息。
SUBSCRIBE channel [channel] :订阅一个或多个频道
PUBLISH channel msg :向一个频道发布消息
PSUBSCRIBE pattern[pattern] :订阅与pattern格式匹配的所有频道
基于PubSub的消息队列有哪些优缺点?
优点:
采用发布订阅模型,支持多生产、多消费缺点:
不支持数据持久化
无法避免消息丢失
消息堆积有上限,超出时数据丢失
16.5消息队列-Stream
Stream 是 Redis 5.0 引入的一种新数据类型,可以实现一个功能非常完善的消息队列。
发送消息的命令:

例如:


读取消息的方式1:XREAD

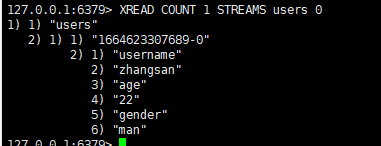
XREAD阻塞方式,阻塞读取最新的消息:

在业务开发中,我们可以循环的调用XREAD阻塞方式来查询最新消息,从而实现持续监听队列的效果,伪代码如下
阻塞读取消息队列中的最新的一条消息,最多等待2s
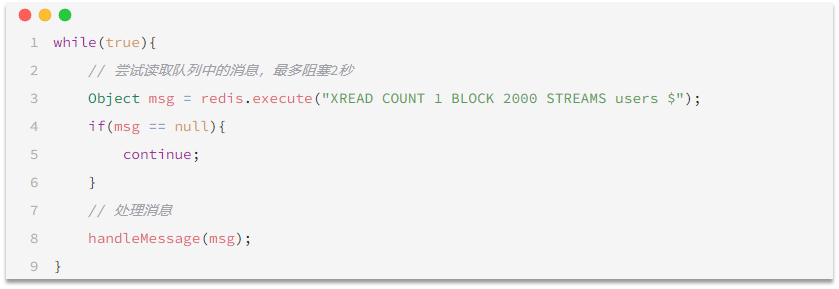

STREAM类型消息队列的XREAD的优缺点:
优点:
消息可回溯
一个消息可以被多个消费者读取
可以阻塞读取
缺点:
有消息漏读的风险15.Redis企业实战项目
15.1项目主要业务功能
15.2项目架构
该项目是一个前后端分离项目,前端部署在Nginx动态代理服务器上。后端部署在Tomcat上面。
客户端向Nginx发送请求获取到静态资源,页面通过Nginx向服务端发送请求查询数据,数据可能来自于MySQL集群,也有可能来自Redis集群。
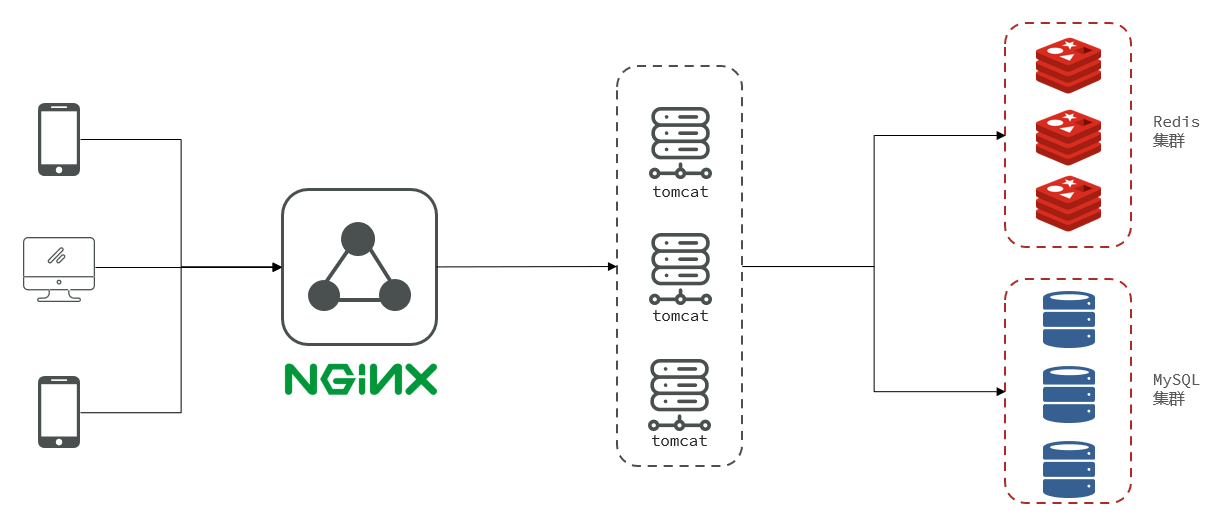
15.3项目初始化
一:创建数据库,导入SQL文件
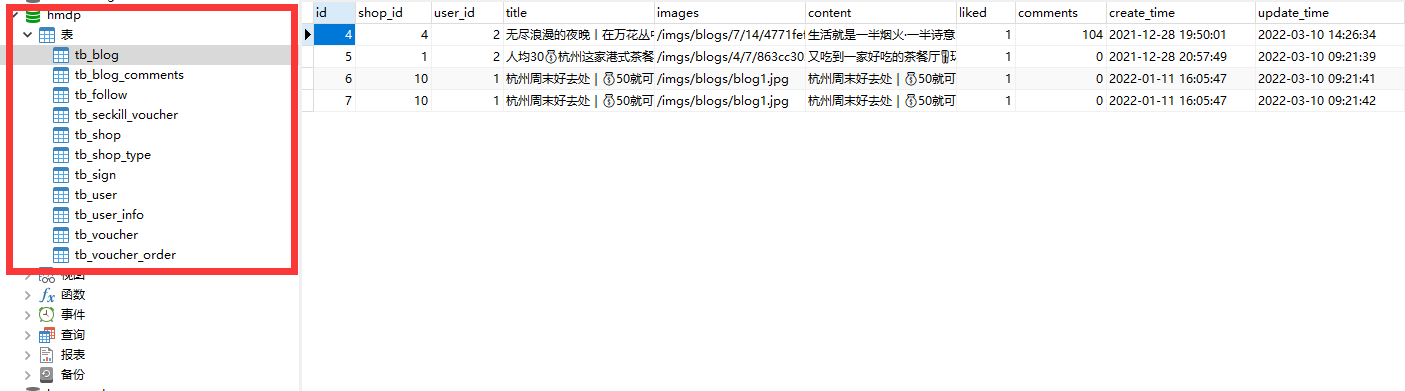
其中的表有:
ltb_user:用户表
ltb_user_info:用户详情表
ltb_shop:商户信息表
ltb_shop_type:商户类型表
ltb_blog:用户日记表(达人探店日记)
ltb_follow:用户关注表
ltb_voucher:优惠券表
ltb_voucher_order:优惠券的订单表
二:导入后端项目
在Gitee中获取到远程仓库的地址
idea克隆项目
初始为master分支,切换分支为init分支
三:pom文件内容
<dependencies><!-- redis的相关依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency><!-- 连接池--> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> </dependency><!-- Web场景启动器--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency><!-- 数据库驱动--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency><!-- lombok插件--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency><!-- 单元测试--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency><!-- mybatis-plus相关依赖--> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.4.3</version> </dependency> <!--hutool--> <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.17</version> </dependency> </dependencies>Hutool是一个小而全的Java工具类库,通过静态方法封装,降低相关API的学习成本,提高工作效率,使Java拥有函数式语言般的优雅;
提供了Java基础工具类,对文件、流、加密解密、转码、正则、线程、XML等JDK方法进行封装,组成各种Util工具类,同时提供以下组件
如随机工具:
四:SpringBoot配置文件
# 项目运行端口server: port: 8081spring: application: name: hmdp# MySQL的相关配置 datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/hmdp?useSSL=false&serverTimezone=UTC username: root password: xu123456# redis的相关配置 redis: host: 192.168.26.133 port: 6379 password: xu123456# lettuce连接池配置 lettuce: pool: max-active: 10 max-idle: 10 min-idle: 1 time-between-eviction-runs: 10s jackson: default-property-inclusion: non_null # JSON处理时忽略非空字段mybatis-plus: type-aliases-package: com.hmdp.entity # 别名扫描包logging: level: com.hmdp: debug五:启动项目,进行测试
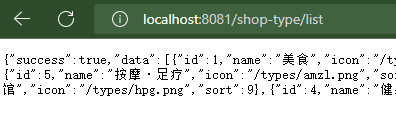
六:导入前端项目
将已经准备好的Nginx文件夹放到目录下:
该文件夹内已经准备好了前端项目
七:启动前端项目
在nginx所在目录下打开一个CMD窗口,输入命令:

打开浏览器,打开设备工具栏,输入前端运行端口8080
15.4基于Session短信登录
15.4.1发送短信验证码
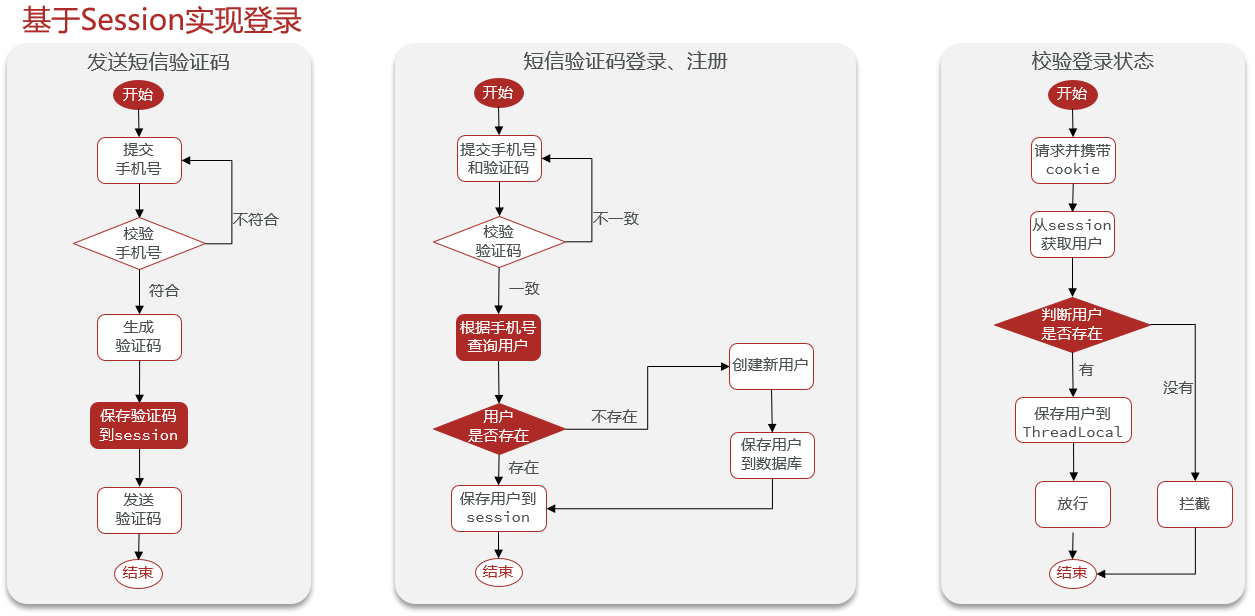
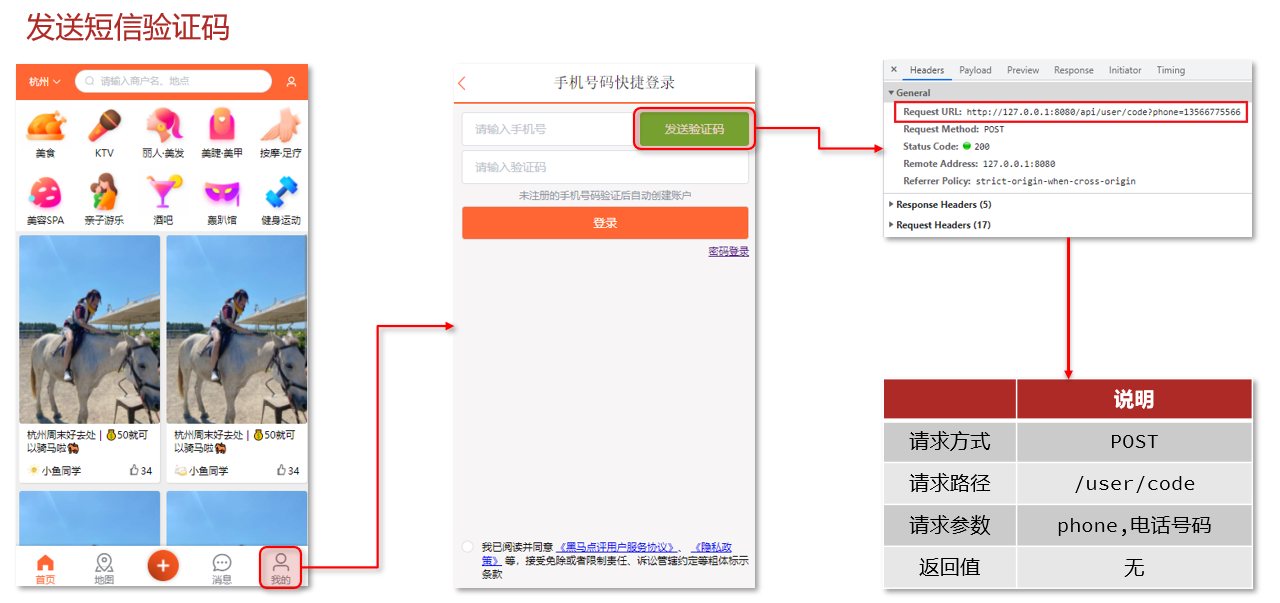
找到对应的控制器方法,调用Service层接口,传递参数phone和session
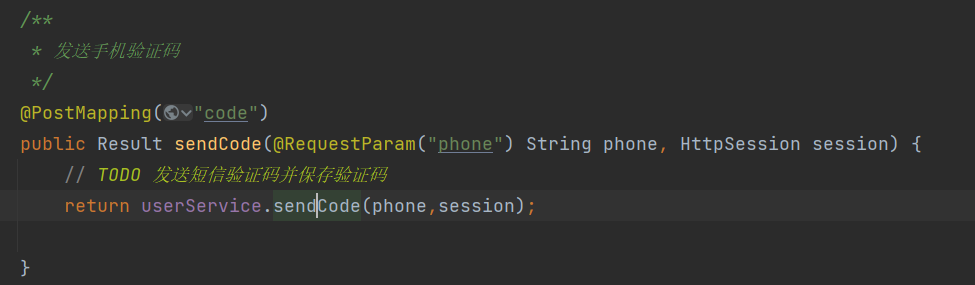
在Service层实现类中编写相应的业务流程
业务流程实现过程:用户输入手机号点击发送验证码后,首先检验手机号是否合法,如果合法就随机生成验证码,并将验证码存入session
public Result sendCode(String phone, HttpSession session) {// 校验手机号 if (RegexUtils.isPhoneInvalid(phone)){ // 不符合,返回错误信息 return Result.fail("手机号格式错误!"); }// 符合,随机生成6位验证码 String code = RandomUtil.randomNumbers(6);// 保存验证码到session session.setAttribute("code",code);// 发送验证码(打印日志信息) log.debug("发送验证码成功,验证码为:"+code);// 返回OK return Result.ok(); }运行项目,再次测试。
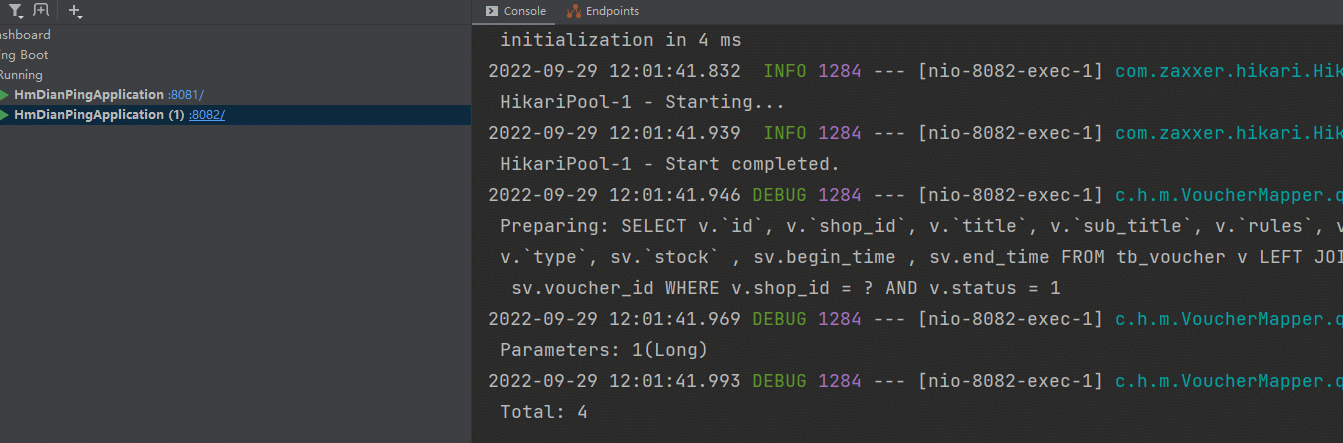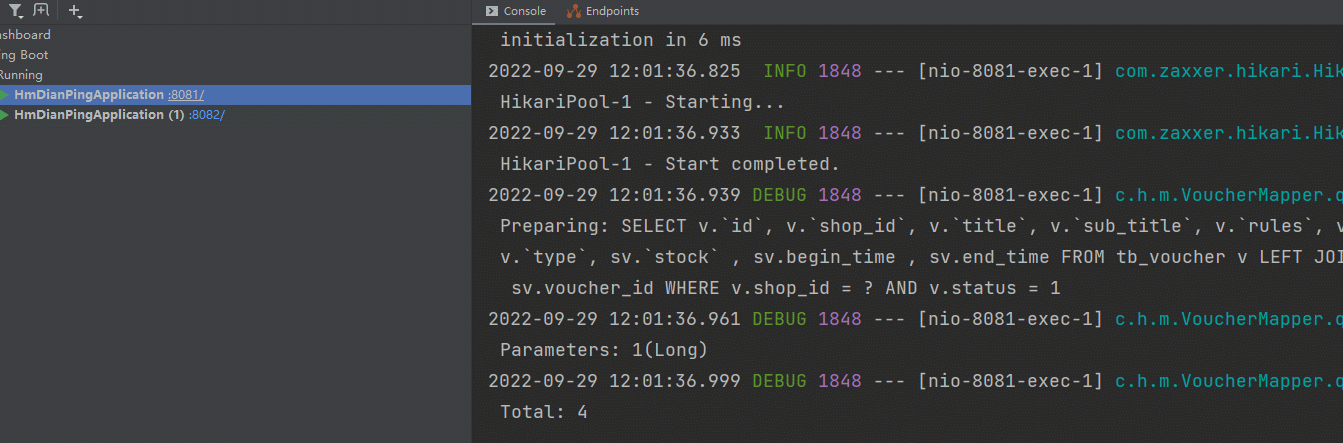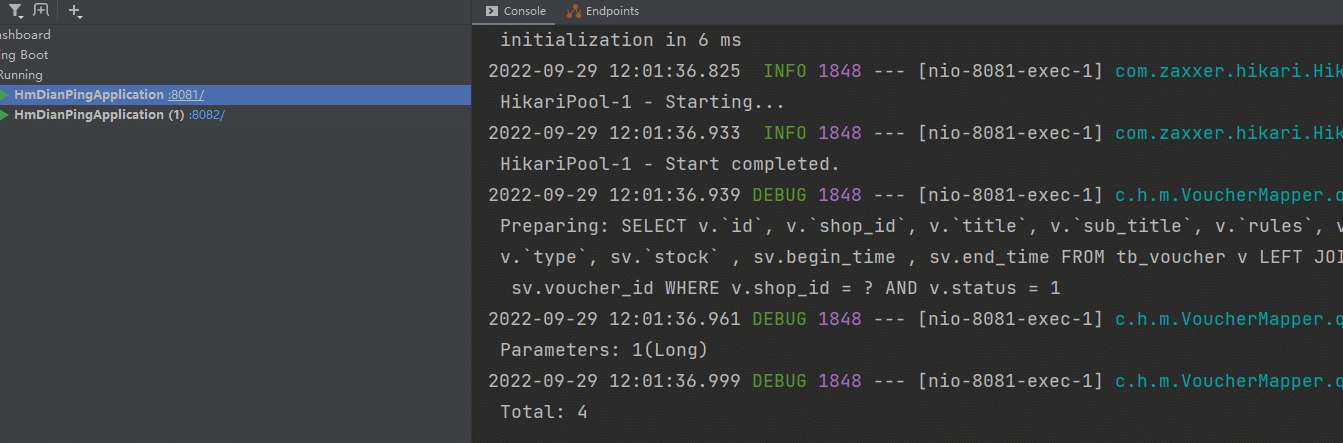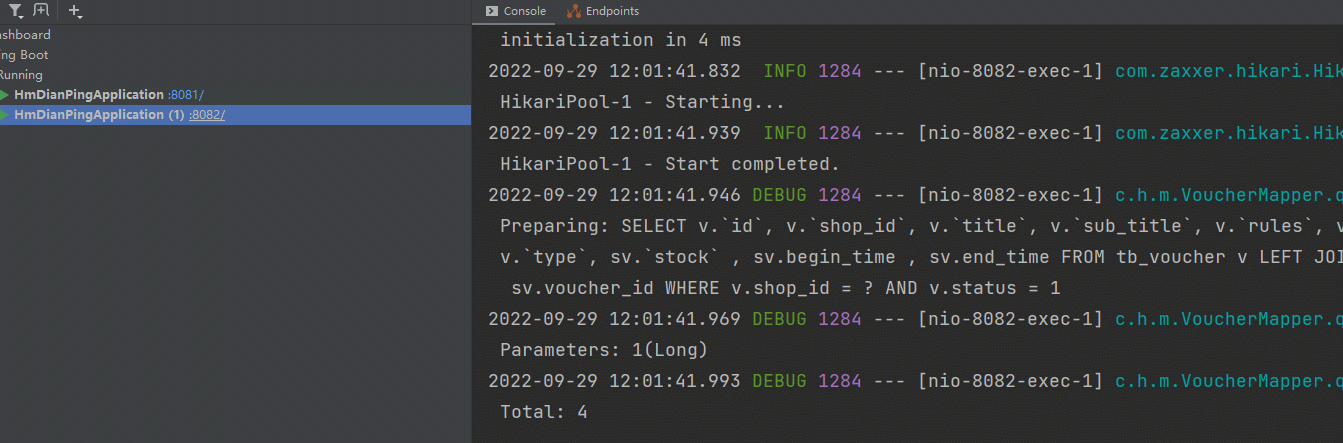
返回成功信息
控制台打印日志信息
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cWDfF0IG-1667304780209)(Redis.assets/image-20220924135440309.png)]
15.4.2验证码登录和注册
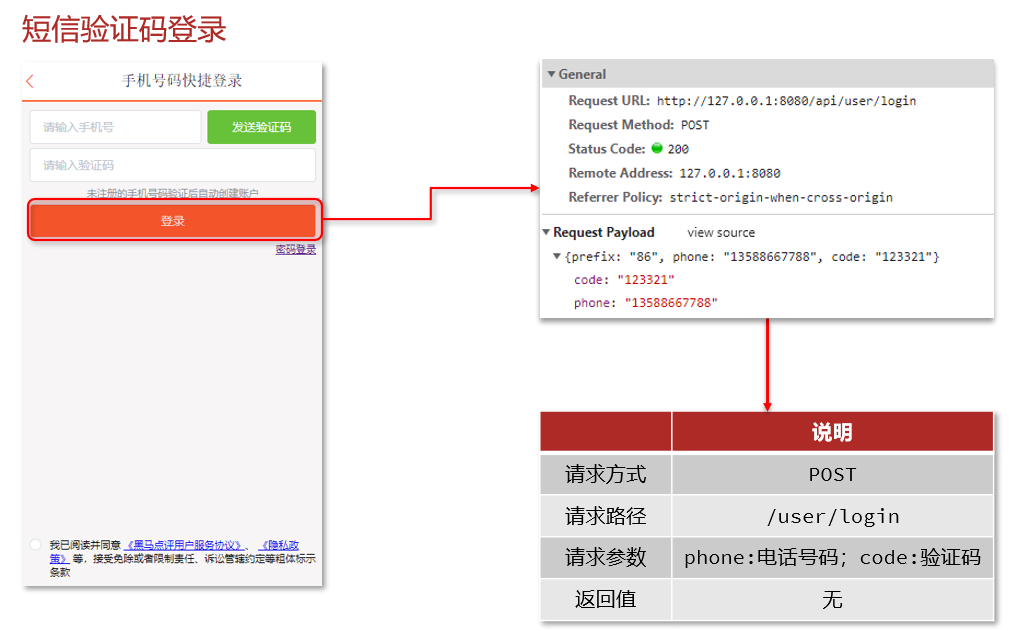
业务流程实现过程:当用户点击登录按钮后,获取到用户在前端提交的表格信息中的手机号和验证码,首先验证手机号是否合法,再验证输入的验证码是否和存在session中的验证码是否一致。验证完成后根据手机号查询用户状态,如果用户存在则登录,若不存在就首先创建用户。最后将用户信息存入session。
/** 实现登录功能* */ public Result login(LoginFormDTO loginForm, HttpSession session) {// 获取到用户输入的手机号和验证码 String phone = loginForm.getPhone(); String code = loginForm.getCode();// 校验手机号 if (RegexUtils.isPhoneInvalid(phone)){ return Result.fail("手机号格式有误!"); }// 校验验证码 if (loginForm.getCode() == null || !session.getAttribute("code").equals(code)){// 不一致,提示错误信息 return Result.fail("验证码错误!"); }// 一致,根据手机号查询用户 User user = query().eq("phone", phone).one();// 判断用户是否存在 if (user == null){// 不存在,创建新用户并保存 user = createUserWithPhone(phone); }// 保存用户信息到session当中 session.setAttribute("user",user); return Result.ok(); }/** 创建新用户* */ private User createUserWithPhone(String phone) { User user = new User(); user.setPhone(phone); user.setNickName(USER_NICK_NAME_PREFIX + RandomUtil.randomString(6));// 保存用户 save(user); return user; }15.4.3拦截器实现登陆验证
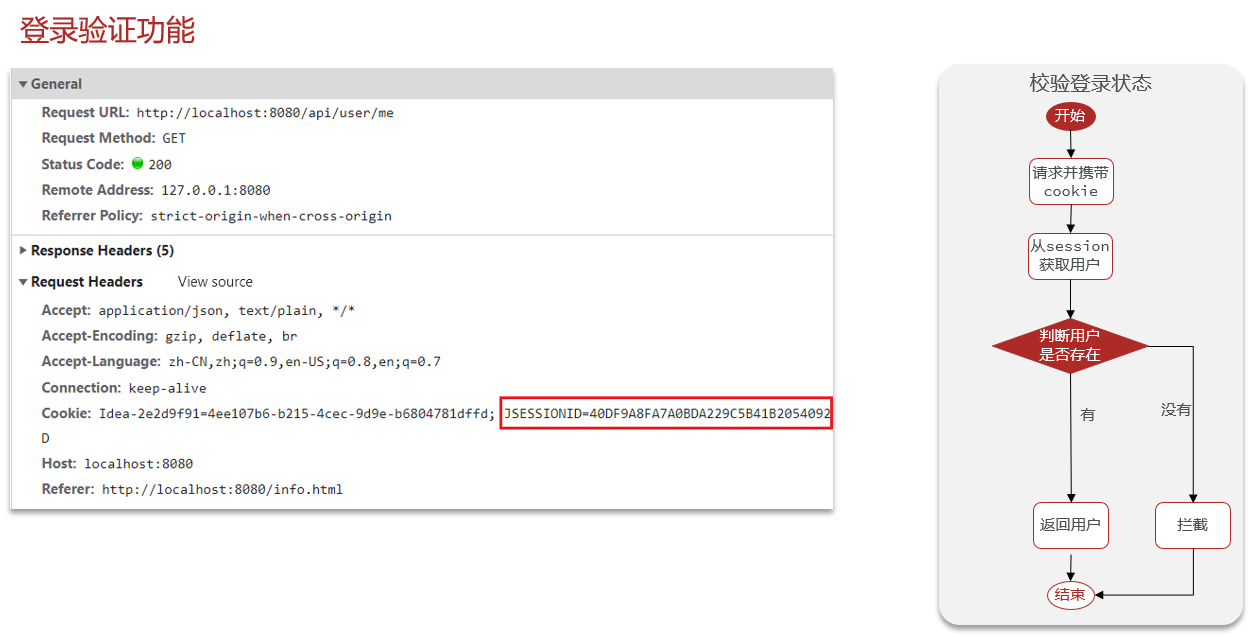
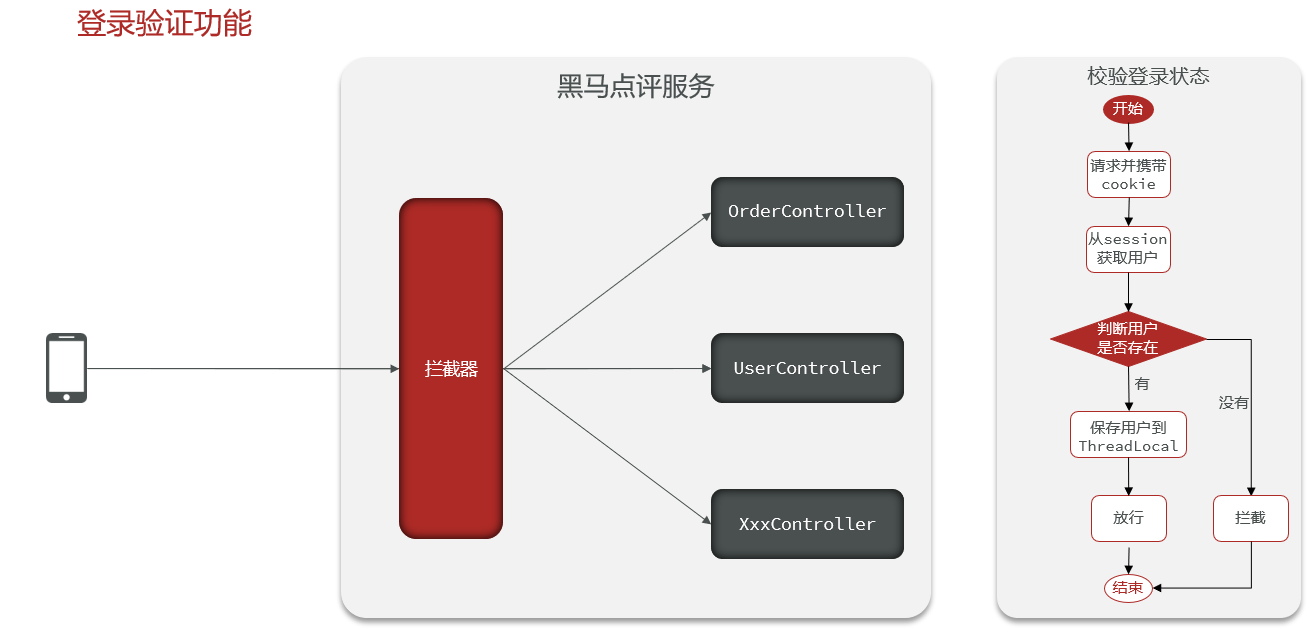
业务流程实现过程:当用户执行登录的时候,已经在sessino中存入了用户的相关信息。用户登录状态的校验在很多地方都需要执行,这样就会比较麻烦,所以配置拦截器来做用户登陆验证。所以在前端向Controller层发送请求的时候,都会先由拦截器判断用户的登录状态,如果用户信息已经在session中就证明用户已经登录,否则返回401状态码。
public class LoginIntercepter implements HandlerInterceptor { @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {// 获取到session HttpSession session = request.getSession();// 获取到session中的用户信息 Object user = session.getAttribute("user");// 判断用户是否存在 if (user == null){// 不存在就拦截 response.setStatus(401); return false; }// 存在,保存用户信息到ThreadLocal(存在线程当中) UserHolder.saveUser((User) user);// 放行 return true; } @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {// 移除用户 UserHolder.removeUser(); }}配置拦截器规则
// 添加拦截器 @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(new LoginIntercepter())// 排除拦截的路径 .excludePathPatterns( "/user/code", "/user/login", "/blog/hot", "/shop/**", "/shop-type/**", "/upload/**", "/voucher/**" ); }测试登录成功,显示用户信息。
15.4.4隐藏用户敏感信息
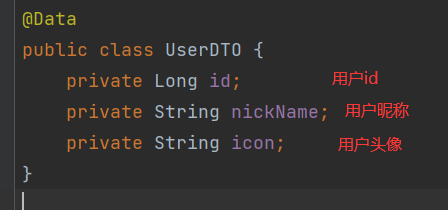
从响应信息中可以看出存在用户的敏感信息,如手机号,密码等等。这是因为向session中存入对象时是将用户的所有属性都存了进去。

下面进行隐藏用户的敏感信息,即更改存储到session中的对象属性
UserDTO只有以下三个属性,刚好满足我们的需求。
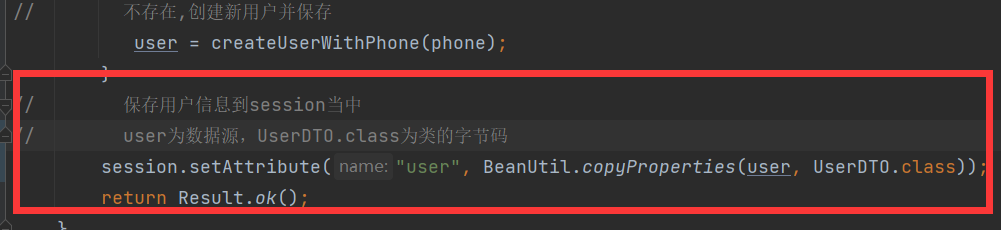
采用hutool的对象拷贝方法实现根据数据源对象获取到新对象,即存入session的对象类型为UserDTO


15.4.5集群的session的共享问题
session共享问题:多台Tomcat并不共享session存储空间,当请求切换到不同tomcat服务时导致数据丢失的问题。
session的替换方案应该满足以下特点:
数据共享内存存储key、value结构
15.5基于Redis实现短信登录
15.5.1为什么要使用redis代替session
前面已经提到,当项目部署在一个服务器当中的时候,session可以实现共享。但是负载均衡操作时将一个项目部署在多台服务器上,那么服务器之间的session共享问题就很显而易见了,如果多台服务器之间相互拷贝必将造成数据冗余和存储压力。所以采用Redis做持久化缓存就很有必要,它可以实现存储数据可以在多台服务器之间进行共享。
15.5.1Redis代替session的业务流程
redis替代短信验证码的业务流程
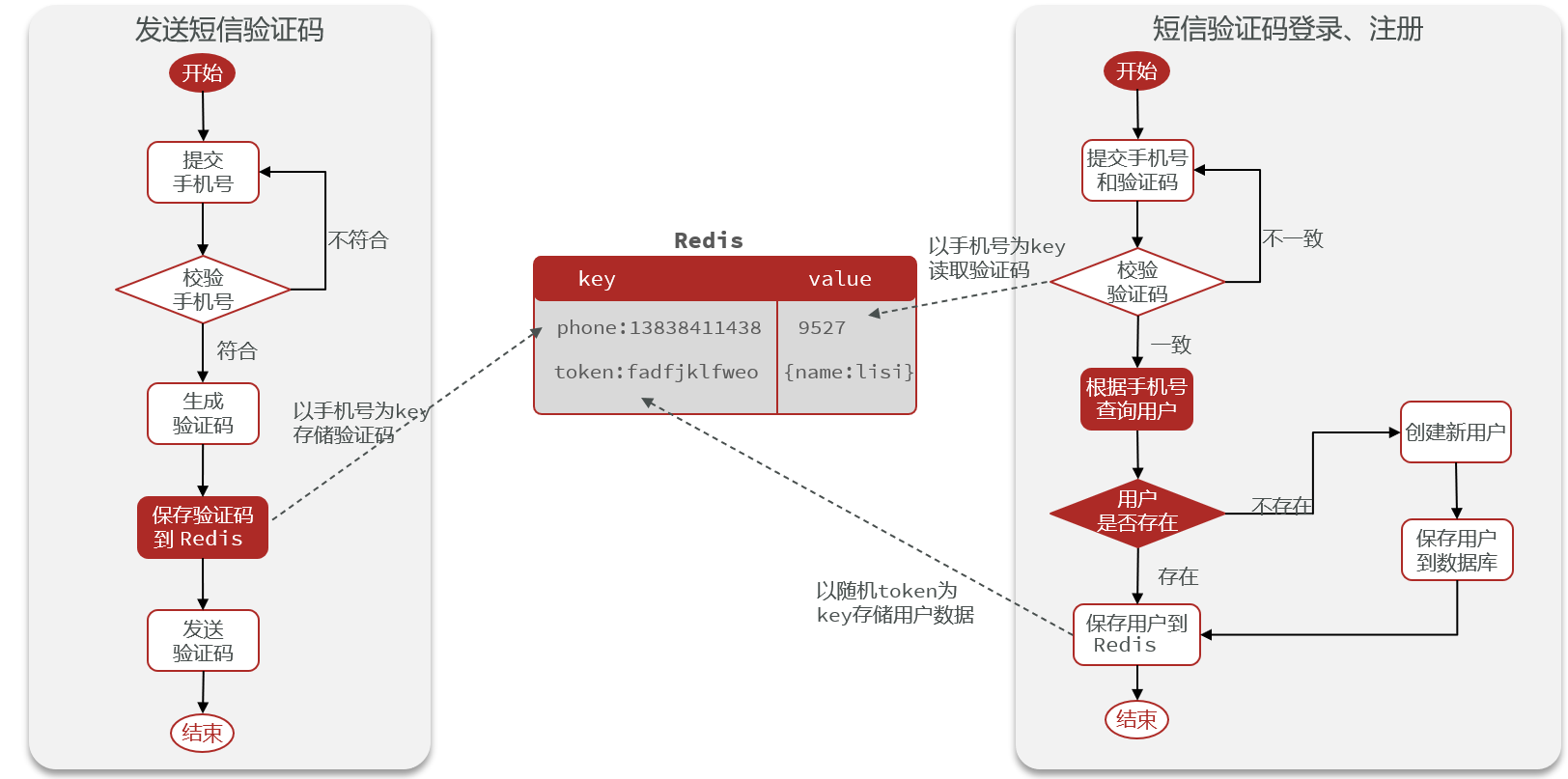
redis替代校验登录状态的业务流程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mz2yUJEz-1667304780212)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/image-20220924174321935.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GOXkdnt6-1667304780212)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/image-20220924173950100.png)]
15.5.2 Redis实现短信登录
@Slf4j@Servicepublic class UserServiceImpl extends ServiceImpl<UserMapper, User> implements IUserService { @Resource private StringRedisTemplate stringRedisTemplate;/** 获取到验证码* */ public Result sendCode(String phone, HttpSession session) {// 校验手机号 if (RegexUtils.isPhoneInvalid(phone)){ // 不符合,返回错误信息 return Result.fail("手机号格式错误!"); }// 符合,随机生成6位验证码 String code = RandomUtil.randomNumbers(6);// 分别以phone和code为key-value保存验证码到redis stringRedisTemplate.opsForValue().set(LOGIN_CODE_KEY + phone,code,LOGIN_CODE_TTL, TimeUnit.MINUTES);// 发送验证码(打印日志信息) log.debug("发送验证码成功,验证码为:"+code);// 返回OK return Result.ok(); }/** 实现登录功能* */ public Result login(LoginFormDTO loginForm, HttpSession session) {// 获取到用户输入的手机号和验证码 String phone = loginForm.getPhone(); String code = loginForm.getCode();// 校验手机号 if (RegexUtils.isPhoneInvalid(phone)){ return Result.fail("手机号格式有误!"); }// 从redis获取到验证码并校验 String redisCode = stringRedisTemplate.opsForValue().get(LOGIN_CODE_KEY + phone); if (loginForm.getCode() == null || !redisCode.equals(code)){// 不一致,提示错误信息 return Result.fail("验证码错误!"); }// 一致,根据手机号查询用户 User user = query().eq("phone", phone).one();// 判断用户是否存在 if (user == null){// 不存在,创建新用户并保存 user = createUserWithPhone(phone); }// 存储用户信息到redis// 随机生成token,作为登录令牌 String token = UUID.randomUUID().toString(true);// 对象拷贝 UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);// 将对象转为HashMap类型(方便后续向redis中批量存储),其中要将id类型由Long转为String,因为stringRedisTemplate只支持字符串类型 Map<String, Object> userMap = BeanUtil.beanToMap( userDTO, new HashMap<>(), CopyOptions.create().setFieldValueEditor((fieldName, fieldValue) -> fieldValue.toString()));// 存储对象采用Hash结构 stringRedisTemplate.opsForHash().putAll(LOGIN_USER_TOKEN + token,userMap);// 设置过期时间 stringRedisTemplate.expire(LOGIN_USER_TOKEN + token,LOGIN_USER_TTL,TimeUnit.MINUTES); return Result.ok(token); }/** 创建新用户* */ private User createUserWithPhone(String phone) { User user = new User(); user.setPhone(phone); user.setNickName(USER_NICK_NAME_PREFIX + RandomUtil.randomString(6));// 保存用户 save(user); return user; }}在拦截器中设置redis存储中登录对象的过期时间,因为拦截器可以检测用户的登录状态,只要前端向后端发送请求拦截器就会判断用户的登录状态,如果用户处在登录状态,就重设redis缓存的过期时间
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5KKFWF3l-1667304780212)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/image-20220924235848837.png)]
但是如果只有一个拦截器,当用户访问公共资源的时候并不会触发拦截器,这就导致当用户一直停留在公共资源的时候redis缓存中的数据更新时间并不会发生变化,直到缓存数据失效,用户登录状态变为未登录。
为解决以上问题,采用两个拦截器优化,第一个拦截器拦截所有路径,负责将用户信息存入redis缓存,存入线程并刷新token有效期。第二个只判断线程中是否有用户信息,没有就拦截。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RWaAWEUj-1667304780212)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/image-20220925000215851.png)]
存储用户信息,更新token的拦截器
public class RefreshTokenIntercepter implements HandlerInterceptor {/** 为什么拦截器中不能注入Bean?主要原因就是springboot拦截器是在Bean实例化之前执行的,Bean实例无法注入, 拦截器中没有实例化StringRedisTemplate,需要在加入拦截器之前,先进行bean处理。* */ private StringRedisTemplate stringRedisTemplate;// 采用构造函数注入 public RefreshTokenIntercepter(StringRedisTemplate stringRedisTemplate) { this.stringRedisTemplate = stringRedisTemplate; } @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {// 获取到前端请求头中的token String token = request.getHeader("authorization");// 使用工具类判断字符串是否为空 if (StrUtil.isBlank(token)){ return true; }// 基于Token获取到redis中的用户 Map<Object, Object> userMap = stringRedisTemplate.opsForHash().entries(LOGIN_USER_TOKEN + token);// 判断用户是否存在 if (userMap.isEmpty()){ return true; }// 将查询到的Hash数据转为UserDTO对象 UserDTO userDTO = BeanUtil.fillBeanWithMap(userMap, new UserDTO(), false);// 存在,保存用户信息到ThreadLocal(存在线程当中) UserHolder.saveUser(userDTO);// 刷新token的有效期 stringRedisTemplate.expire(LOGIN_USER_TOKEN + token,LOGIN_USER_TTL, TimeUnit.MINUTES);// 放行 return true; } @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {// 移除用户 UserHolder.removeUser(); }}登录拦截器,用于专门验证用户登录状态
public class LoginIntercepter implements HandlerInterceptor { @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { System.out.println("这里是登录验证拦截器");// 判断是否需要进行拦截(ThreadLocal中是否有用户) if (UserHolder.getUser() == null){ response.setStatus(401); return false; } return true; } @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {// 移除用户 UserHolder.removeUser(); }}拦截器的配置,设置拦截器等级,让刷新token、存储用户信息的拦截器首先执行,登录验证拦截器后执行。
@Configurationpublic class MvcConfig implements WebMvcConfigurer { @Resource private StringRedisTemplate stringRedisTemplate; @Override// 登录拦截器 public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(new LoginIntercepter())// 排除拦截的路径 .excludePathPatterns( "/user/code", "/user/login", "/blog/hot", "/shop/**", "/shop-type/**", "/upload/**", "/voucher/**" ).order(1);// token刷新拦截器 registry.addInterceptor(new RefreshTokenIntercepter(stringRedisTemplate)) .addPathPatterns(// 拦截所有请求,order控制拦截器的执行顺序,数字越小执行等级越高 "/**" ).order(0); }}查看存在redis中的验证码
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BvhuedZs-1667304780212)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/image-20220924230254706.png)]
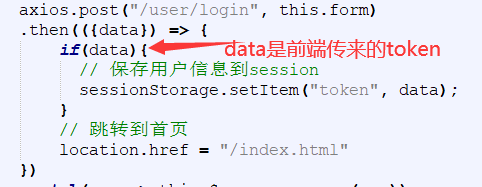
请求头中的token设置方式:
当调用login接口后,service层会返回toekn字符串,再经由控制层返回给前端,前端将token信息保存到sessionStorage会话存储中。

在前端设置拦截器,每次发送请求时都会从sessionStorage获取到token,并在请求头中添加token信息
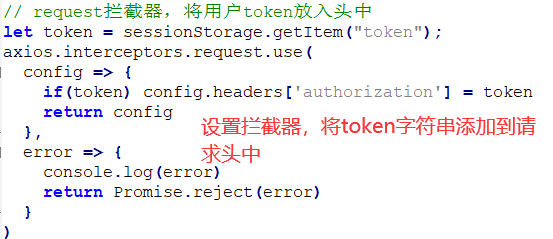
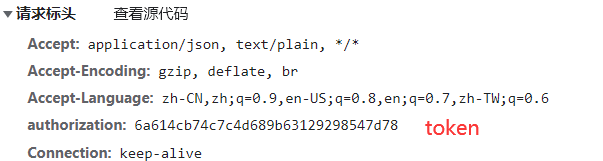
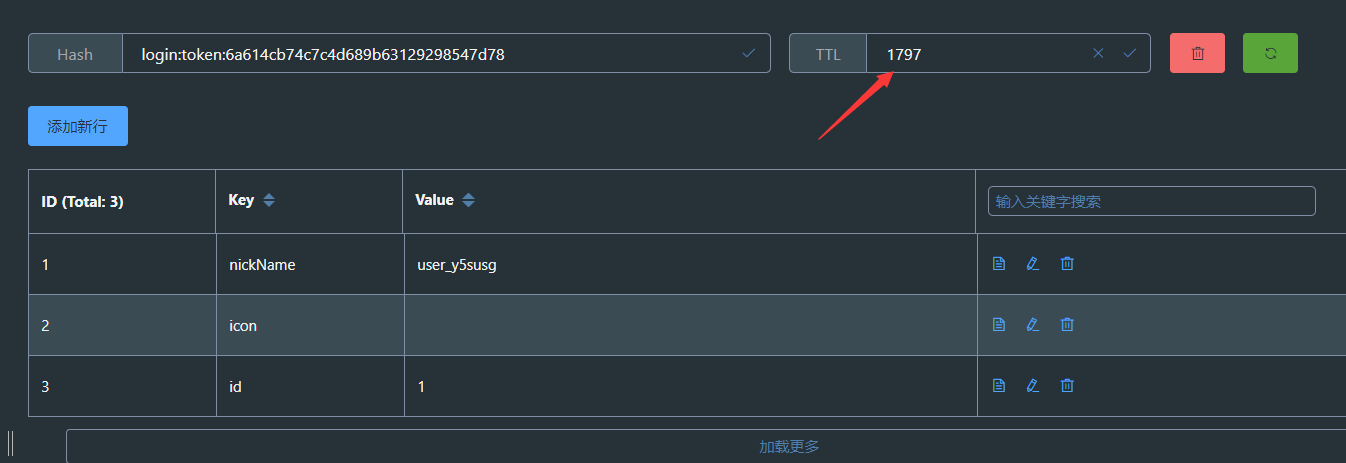
有了请求头中的token, 就能够在后端拦截器中获取到token,进而通过token去获取到存储在redis中的用户信息,刷新用户信息存储时间
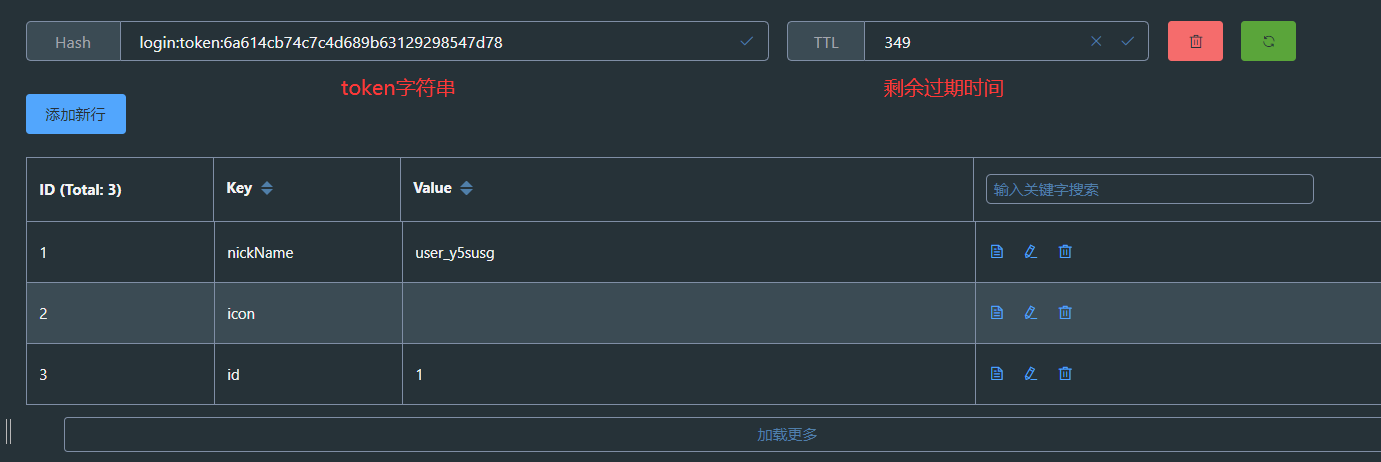
重新发送请求后token过期时间刷新
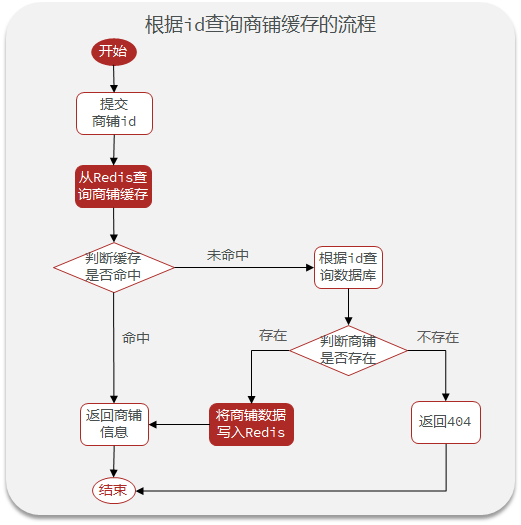
15.6商户查询缓存
15.6.1添加商户缓存
添加商户缓存业务流程图
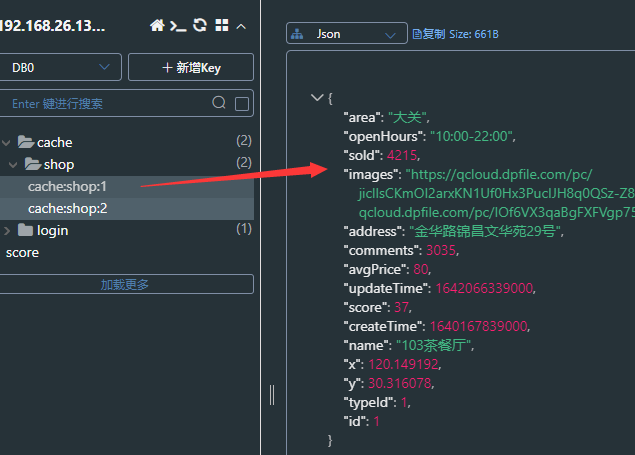
// 根据id查询商户信息 public Result queryById(Long id) {// 从redis查询用户缓存 String shopStr = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);// 判断是否存在 if (StrUtil.isNotBlank(shopStr)){// 存在,直接返回 Shop shop = JSONUtil.toBean(shopStr, Shop.class); return Result.ok(shop); }// 不存在,根据id查询关系型数据库 Shop shopById = getById(id);// 关系型数据库中不存在就返回错误 if (shopById == null){ return Result.fail("店铺不存在!"); }// 存在就写入缓存 stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id,JSONUtil.toJsonStr(shopById));// 返回 return Result.ok(shopById); }查看缓存
15.6.2采用缓存更新策略优化商户缓存
修改ShopController中的业务逻辑,满足下面的需求:
①根据id查询店铺时,如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间
②根据id修改店铺时,先修改数据库,再删除缓存
在添加缓存的时候设置过期时间
@Resource StringRedisTemplate stringRedisTemplate;// 根据id查询商户信息 public Result queryById(Long id) {// 从redis查询用户缓存 String shopStr = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);// 判断是否存在 if (StrUtil.isNotBlank(shopStr)){// 存在,直接返回 Shop shop = JSONUtil.toBean(shopStr, Shop.class); return Result.ok(shop); }// 不存在,根据id查询关系型数据库 Shop shopById = getById(id);// 关系型数据库中不存在就返回错误 if (shopById == null){ return Result.fail("店铺不存在!"); }// 存在就写入缓存,并设置缓存过期时间 stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id,JSONUtil.toJsonStr(shopById),CACHE_EXPIRE_TTL, TimeUnit.MINUTES);// 返回 return Result.ok(shopById); }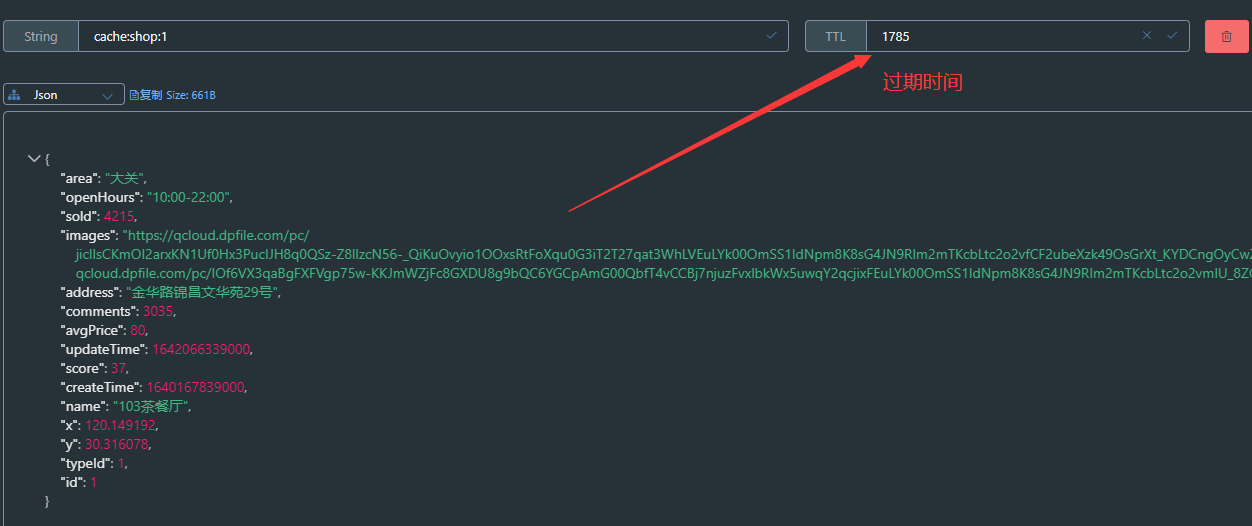
找到shopController,将之前在控制层直接更改数据库的操作放到service层
@PutMappingpublic Result updateShop(@RequestBody Shop shop) { // 写入数据库 return shopService.updateShop(shop);}在service层首先更改数据库数据,然后删除缓存
// 根据id修改商户信息 @Transactional public Result updateShop(Shop shop) { Long id = shop.getId(); if (id == null){ return Result.fail("商户id不能为空"); }// 更新数据库信息 updateById(shop);// 删除缓存 stringRedisTemplate.delete(CACHE_SHOP_KEY + shop.getId()); return Result.ok(); }采用postman进行接口测试:
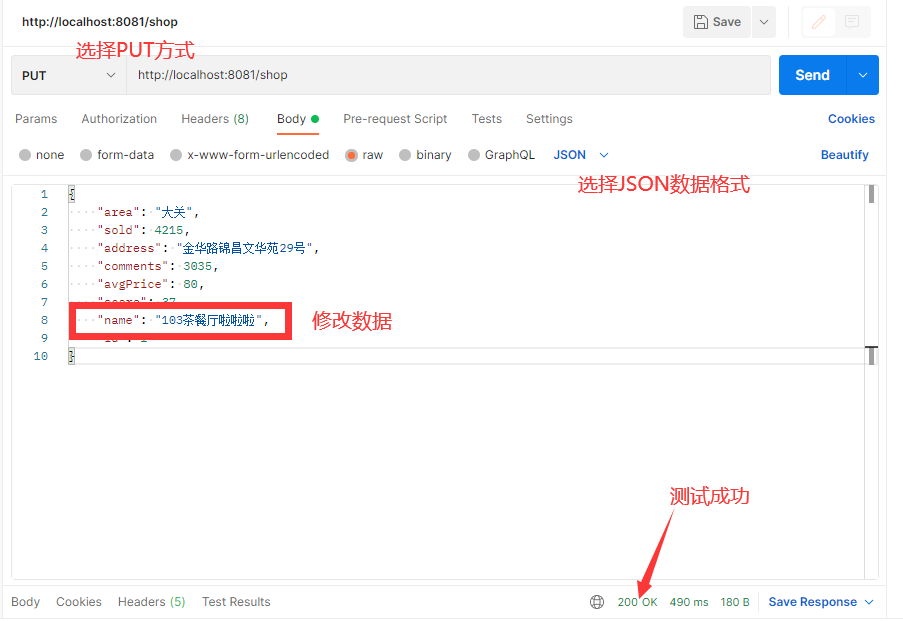
数据库内容修改成功
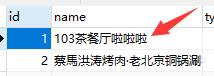
再次请求,缓存重建

15.6.3解决查询商户不存在时出现的缓存穿透问题
// 根据id查询商户信息 public Result queryById(Long id) {// 从redis查询用户缓存 String shopStr = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);// 判断缓存中是否存在 if (StrUtil.isNotBlank(shopStr)){// 存在,直接返回 Shop shop = JSONUtil.toBean(shopStr, Shop.class); return Result.ok(shop); }// 判断命中的是否为空字符串 if (shopStr != null){// 不为空就是空字符串,就是解决缓存穿透时设置的空值 return Result.fail("商户不存在"); }// 缓存中不存在,且不为空字符串就去查数据库 Shop shopById = getById(id);// 数据库中不存在就缓存空对象 if (shopById == null){ stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id,"",CACHE_NULL_TTL,TimeUnit.MINUTES); return Result.fail("店铺不存在!"); }// 存在就写入缓存,并设置缓存超时时间 stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id,JSONUtil.toJsonStr(shopById),CACHE_EXPIRE_TTL, TimeUnit.MINUTES);// 返回 return Result.ok(shopById); }测试:
一:redis中没有真实商铺的缓存数据,也没有空值
postman进行测试
控制台打印查询数据库信息:

将数据存入缓存
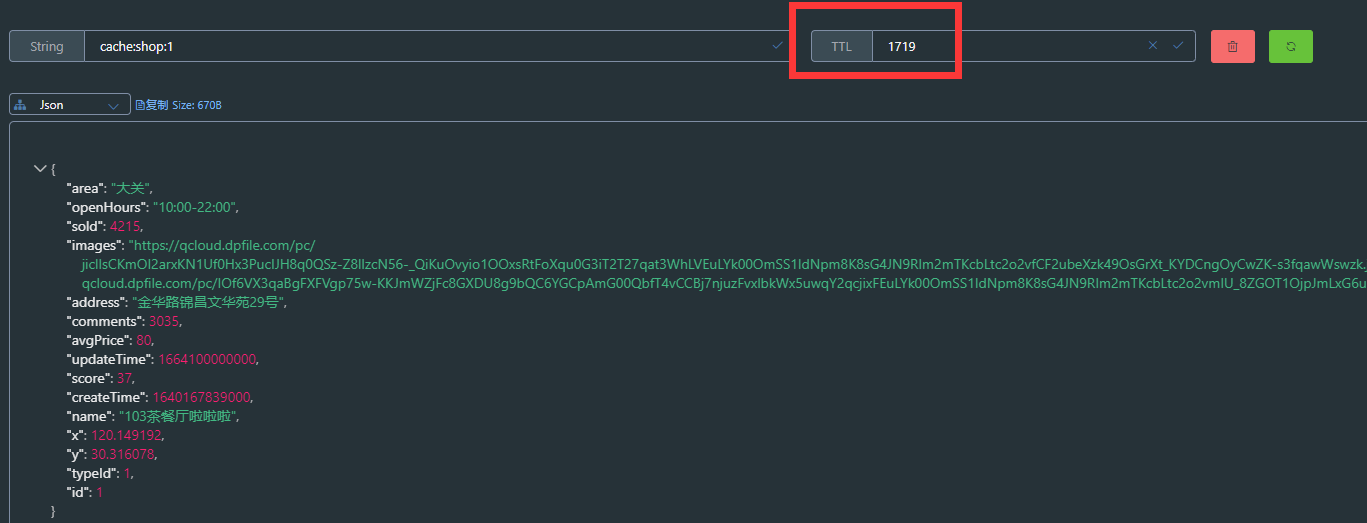
在缓存未过期的时间内再次发送请求会获取到缓存中的数据,而不会获取数据库中的数据,控制台没有sql信息
二:测试数据库中和缓存中都不存在的情况
打印信息为商铺不存在

15.6.4基于互斥锁的方式解决缓存击穿问题
需求:修改根据id查询商铺的业务,基于互斥锁方式来解决缓存击穿问题
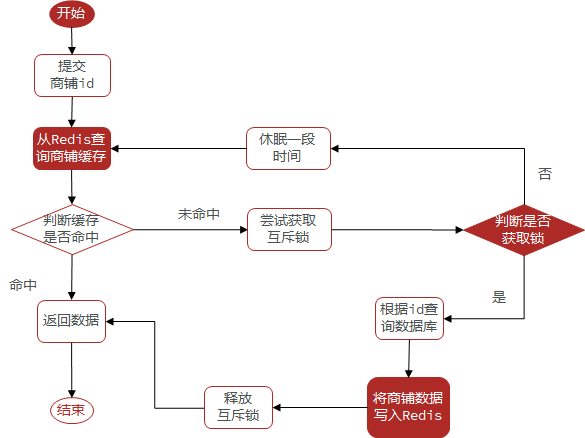
// 根据id查询商户信息 public Result queryById(Long id) {// 利用互斥锁解决缓存击穿问题 Shop shop = CacheAttackThroughByMutex(id); if (shop == null){ return Result.fail("商户不存在!!!"); }// 返回 return Result.ok(shop); }// 利用互斥锁解决缓存击穿问题 public Shop CacheAttackThroughByMutex(Long id) {// 查询缓存 String shopStr = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id); if (StrUtil.isNotBlank(shopStr)) {// 缓存存在对象字符串就返回 return JSONUtil.toBean(shopStr, Shop.class); }// 判断命中的是否为空值 if (shopStr != null) {// 是空值就返回空 return null; } Shop shop = null; try {// 获取互斥锁 String lockKey = SHOP_LOCK_KEY + id; boolean flag = tryLock(lockKey);// 获取互斥锁失败就休眠返回 if (!flag) { // 让当前线程停止 Thread.sleep(50); // 递归调用当前方法 return CacheAttackThroughByMutex(id); }// 获取互斥锁成功就查询数据库 shop = getById(id);// 模拟缓存重建延时 Thread.sleep(200); // 如果数据库中没有就设置空值 if (shop == null) { stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, "", CACHE_NULL_TTL, TimeUnit.MINUTES); } // 存在将查询的数据存到缓存当中 stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(shop), CACHE_EXPIRE_TTL, TimeUnit.MINUTES); } catch (InterruptedException e) { throw new RuntimeException(); } finally { // 释放互斥锁 releaseLock(SHOP_LOCK_KEY + id); } return shop; } // 获取锁 private boolean tryLock(String key) { Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "互斥锁", 10, TimeUnit.SECONDS);// 为了防止自动拆箱的过程中出现空指针的现象采用手动拆箱 return BooleanUtil.isTrue(flag); } // 释放锁 private void releaseLock(String key) { stringRedisTemplate.delete(key); }一:采用性能测试工具JMeter进行高并发请求测试,以用来检验基于互斥锁实现的解决缓存击穿的问题是否能够得到解决。
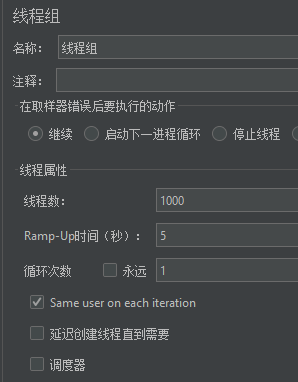
二:设置线程组规则,测试1000条线程在5秒内请求完成
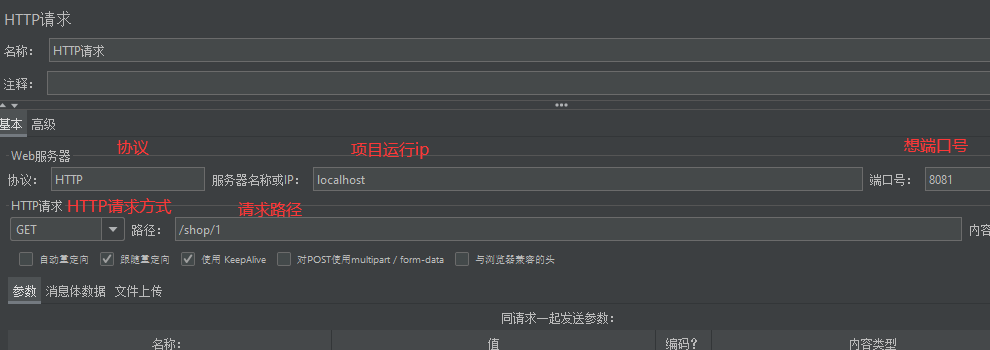
三:设置HTTP请求
四:开始测试
所有请求均已得到响应
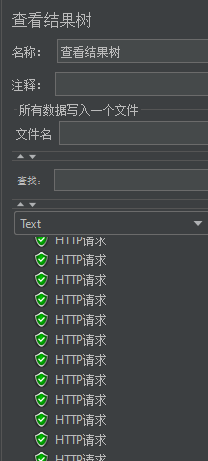
可以看到控制台只打印一条数据库查询信息

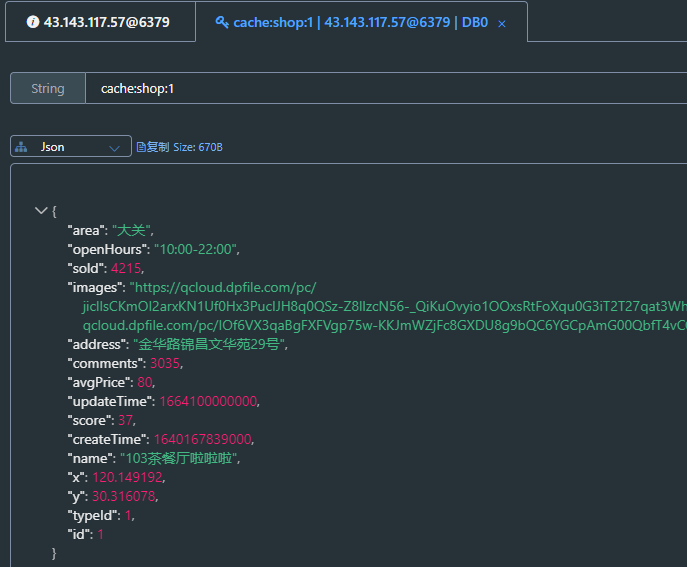
redis中已经存入缓存
15.6.5基于逻辑过期的方式解决缓存击穿问题
需求:修改根据id查询商铺的业务,基于逻辑过期方式来解决缓存击穿问题
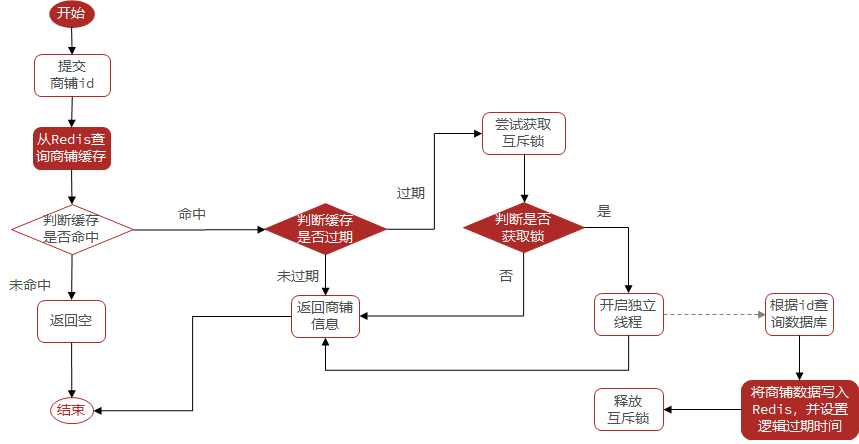
一:设置工具类,添加过期时间属性和对象属性,这个对象属性就是返回给前端的数据
@Datapublic class RedisData { private LocalDateTime expireTime; private Object data;}二:设置热点数据,并采用单元测试的方式进行热点数据写入缓存
// 设置热点数据,由于热点数据需要提前导入,因为没有管理系统,所以采用单元测试的方式进行热点数据的导入 public void saveShopToRedis(Long id,long expireSeconds){// 查询店铺数据 Shop shop = getById(id);// 封装数据和逻辑过期时间 RedisData redisData = new RedisData(); redisData.setData(shop); redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireSeconds));// 存入缓存,不设置过期时间 stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id,JSONUtil.toJsonStr(redisData)); } @Test// 测试逻辑过期解决缓存击穿 public void test1() {// 查询所有商户 QueryWrapper<Shop> queryWrapper = new QueryWrapper<>(); queryWrapper.select("*"); List<Shop> shops = shopMapper.selectList(queryWrapper); for (Shop shop : shops) {// 根据商户id存入缓存 shopService.saveShopToRedis(shop,10L); } }
二:由于之前向缓存中提前加入热点数据的时候设置的逻辑过期时间为10s,所以逻辑时间已经过期。
// 获取缓存重建线程池 private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);// 利用逻辑过期的方式解决缓存击穿的问题 public Shop CacheAttackThroughByLogicExpire(Long id){// 查询缓存 String shopStr = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id); if (StrUtil.isBlank(shopStr)){ return null; }// 缓存命中,将Json字符串反序列化为对象,判断逻辑过期时间 RedisData redisData = JSONUtil.toBean(shopStr, RedisData.class); Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class); LocalDateTime expireTime = redisData.getExpireTime();// 判断逻辑过期时间是否在当前时间之后 if (expireTime.isAfter(LocalDateTime.now())){// 未过期返回商户信息 return shop; }// 过期,获取互斥锁,重建缓存 String lockKey = SHOP_LOCK_KEY + id; boolean flag = tryLock(lockKey);// 获取互斥锁成功,利用线程池开启独立线程,实现缓存重建 if (flag){ CACHE_REBUILD_EXECUTOR.submit(() -> { try { saveShopToRedis(id, 20L); } catch (Exception e) { throw new RuntimeException(); } finally { releaseLock(lockKey); } }); }// 获取互斥锁失败,返回过期商铺信息系 return shop; }// 设置热点数据,由于热点数据需要提前导入,因为没有管理系统,所以第一次采用单元测试的方式进行热点数据的导入 public void saveShopToRedis(Long id,long expireSeconds){// 查询店铺数据 Shop shop = getById(id);// 封装数据和逻辑过期时间 RedisData redisData = new RedisData(); redisData.setData(shop); redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireSeconds));// 存入缓存,不设置过期时间 stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id,JSONUtil.toJsonStr(redisData)); } // 获取锁 private boolean tryLock(String key) { Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "互斥锁", 10, TimeUnit.SECONDS);// 为了防止自动拆箱的过程中出现空指针的现象采用手动拆箱 return BooleanUtil.isTrue(flag); } // 释放锁 private void releaseLock(String key) { stringRedisTemplate.delete(key); }测试:
一:在高并发情况下,会不会出现多个线程重建缓存的情况(并发的安全问题)
二:数据一致性的问题(在缓存重建之前查询的是旧数据)
缓存中的热点数据
修改数据库
在JMeter模拟高并发场景,查看逻辑过期后重新构建缓存查询数据库时,数据前后是否一致。
可以看到数据前后不一致。
热点数据已经更改
15.7优惠券秒杀
15.7.1全局ID生成器
当用户购买商品时,就会生成订单并保存到tb_voucher_order这张表中,而订单表如果使用数据库自增ID就存在一些问题
id的规律性太明显受单表数据量的限制这样的情况下可以考虑使用全局ID生成器
全局唯一ID生成策略:
UUID
Redis自增
snowflake算法
数据库自增
Redis自增ID策略:
每天一个key,方便统计订单量
ID构造是 时间戳 + 计数器
全局ID生成器,是一种在分布式系统下用来生成全局唯一ID的工具,一般要满足下列特性:
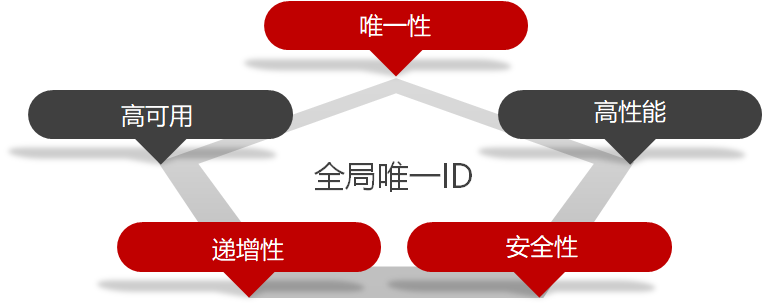
为了增加ID的安全性,我们可以不直接使用Redis自增的数值,而是拼接一些其它信息:

ID的组成部分:
符号位:1bit,永远为0,表示为正数时间戳:31bit,以秒为单位,可以使用69年序列号:32bit,秒内的计数器,每秒支持2*32次方个不同的ID// 设置左移位数 private static final int COUNT_BITS = 32; @Resource StringRedisTemplate stringRedisTemplate; public long uniqueId(String keyPrefix){ // 1.生成时间戳 LocalDateTime now = LocalDateTime.now(); long nowTime = now.toEpochSecond(ZoneOffset.UTC); // 2.生成序列号 // 获取到当前日期 String date = now.format(DateTimeFormatter.ofPattern("yyyyMMdd")); long increment = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date); // 3.拼接并返回 return nowTime << COUNT_BITS | increment; }
15.7.2添加优惠券
每个店铺都可以发布优惠券,分为平价券和特价券。平价券可以任意购买,而特价券需要秒杀抢购:
在VoucherController中提供了一个接口,可以添加秒杀优惠券:
Controller层:
@PostMapping("seckill")public Result addSeckillVoucher(@RequestBody Voucher voucher) { voucherService.addSeckillVoucher(voucher); return Result.ok(voucher.getId());}Service层:
@Resourceprivate ISeckillVoucherService seckillVoucherService;@Transactionalpublic void addSeckillVoucher(Voucher voucher) { // 保存优惠券 save(voucher); // 保存秒杀信息(另外一张表) SeckillVoucher seckillVoucher = new SeckillVoucher(); seckillVoucher.setVoucherId(voucher.getId()); seckillVoucher.setStock(voucher.getStock()); seckillVoucher.setBeginTime(voucher.getBeginTime()); seckillVoucher.setEndTime(voucher.getEndTime()); seckillVoucherService.save(seckillVoucher);}进行接口测试:
JSON数据
{ "shopId": 1, "title": "100元代金券", "subTitle": "周一至周五均可使用", "rules": "全场通用\\n无需预约\\n可无限叠加\\不兑现、不找零\\n仅限堂食", "payValue": 8000, "actualValue": 10000, "type": 1, "stock": 100, "beginTime": "2022-09-28T10:00:00", "endTime": "2022-09-28T16:00:00"}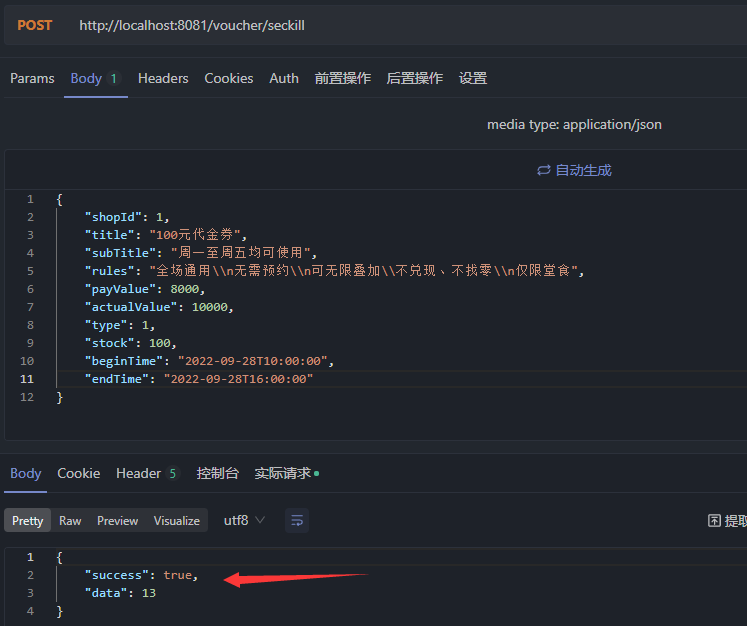


优惠券添加成功
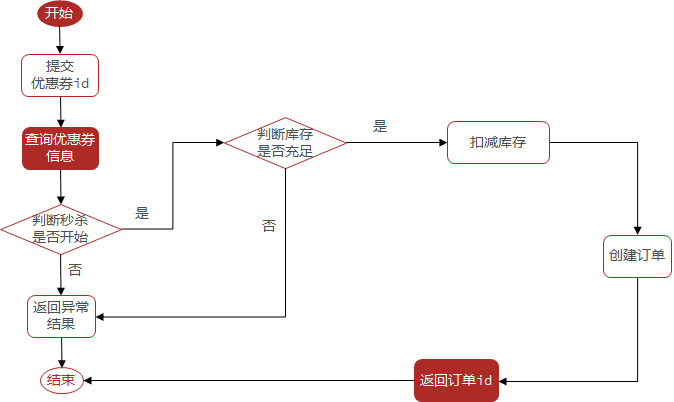
15.7.3实现秒杀下单
用户可以在店铺页面中抢购这些优惠券
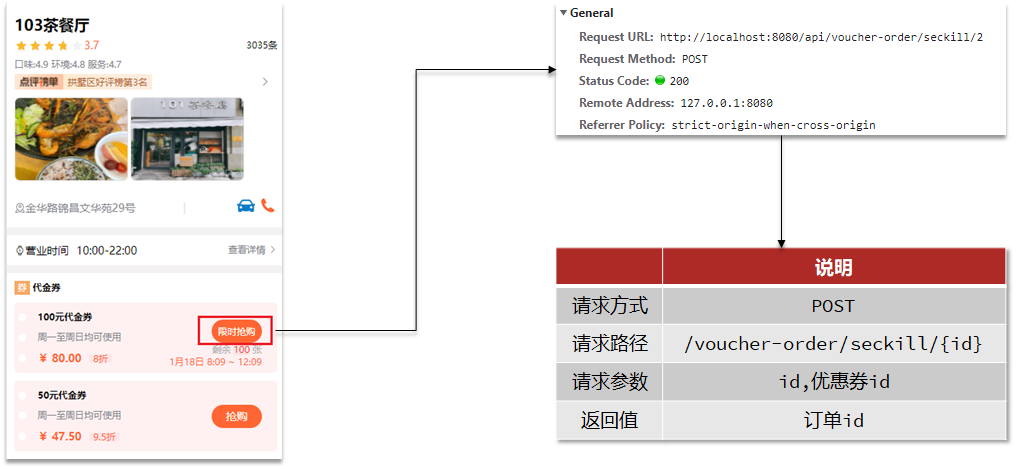
下单时需要判断两点:
秒杀是否开始或结束,如果尚未开始或已经结束则无法下单
库存是否充足,不足则无法下单
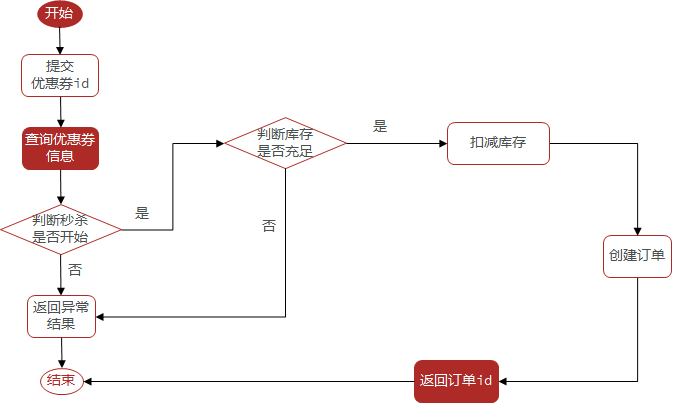
@Resource private ISeckillVoucherService seckillVoucherService; @Resource private SeckillVoucherMapper seckillVoucherMapper; @Resource private RedisIdWorker redisIdWorker; // 秒杀优惠券订单 @Transactional public Result seckillVoucherOrder(Long voucherId) {// 1.根据id查询优惠券 SeckillVoucher seckillVoucher = seckillVoucherService.getById(voucherId);// 2.判断秒杀是否开始 if (seckillVoucher.getBeginTime().isAfter(LocalDateTime.now())) {// 秒杀未开始 return Result.fail("秒杀尚未开始"); }// 3.判断秒杀是否结束 if (seckillVoucher.getEndTime().isBefore(LocalDateTime.now())) {// 秒杀已经结束 return Result.fail("秒杀已经结束"); }// 4.判断库存是否充足 if (seckillVoucher.getStock() < 1){// 库存不足 return Result.fail("库存不足"); }// 5.扣减库存 UpdateWrapper<SeckillVoucher> updateWrapper = new UpdateWrapper<>(); updateWrapper.set("stock",seckillVoucher.getStock() - 1); int update = seckillVoucherMapper.update(null, updateWrapper);// 6.创建订单 VoucherOrder voucherOrder = new VoucherOrder();// 订单id long orderId = redisIdWorker.uniqueId("order"); voucherOrder.setId(orderId);// 用户id voucherOrder.setVoucherId(UserHolder.getUser().getId());// 代金券id voucherOrder.setUserId(voucherId); save(voucherOrder);// 7.返回订单id return Result.ok(orderId); }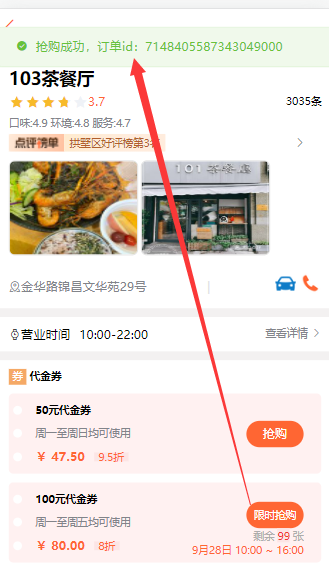
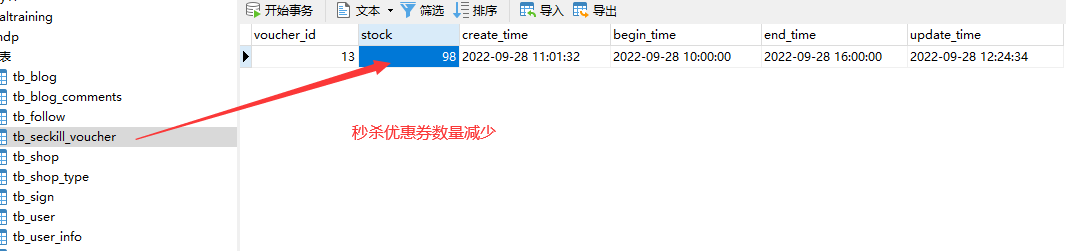
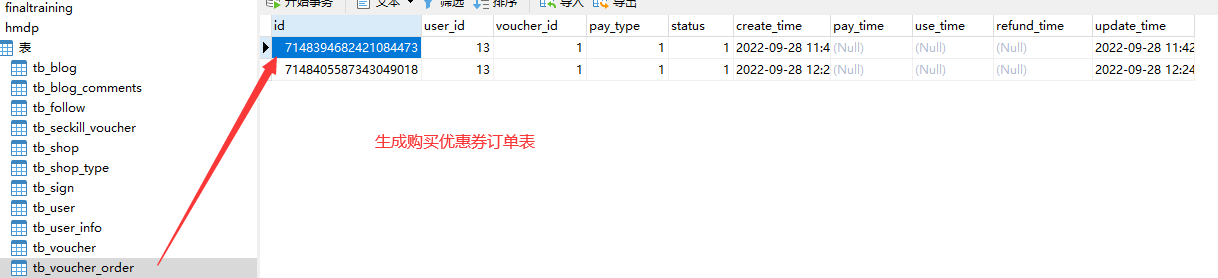
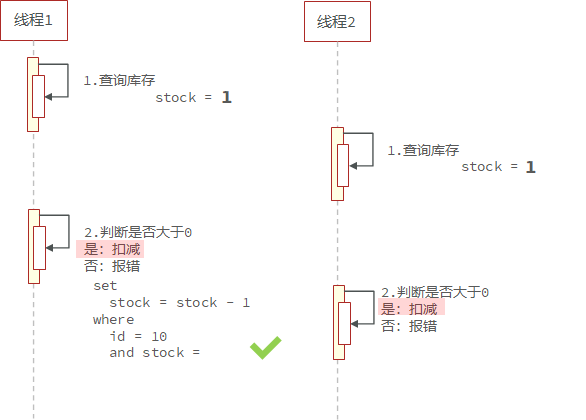
15.7.4库存超卖问题(多线程并发问题)分析
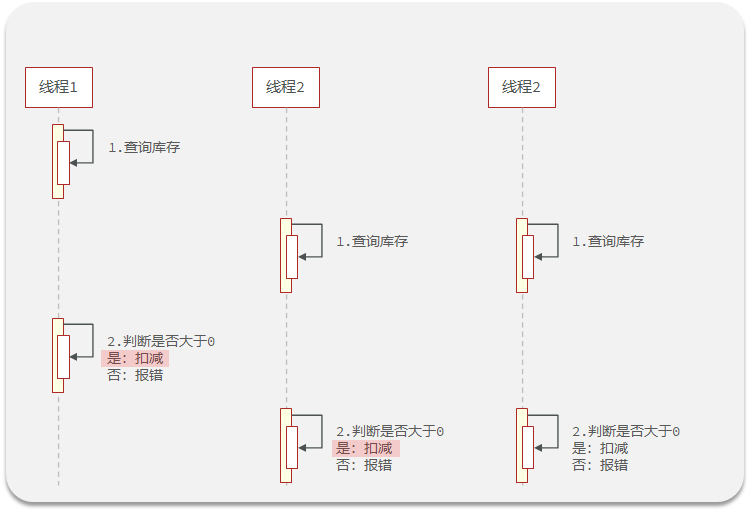
就是在高并发的场景下,可能会有多个线程同时进行查询,当商品数量仅剩1个时,多个线程同时查询,都判断为1,都会进行下单。
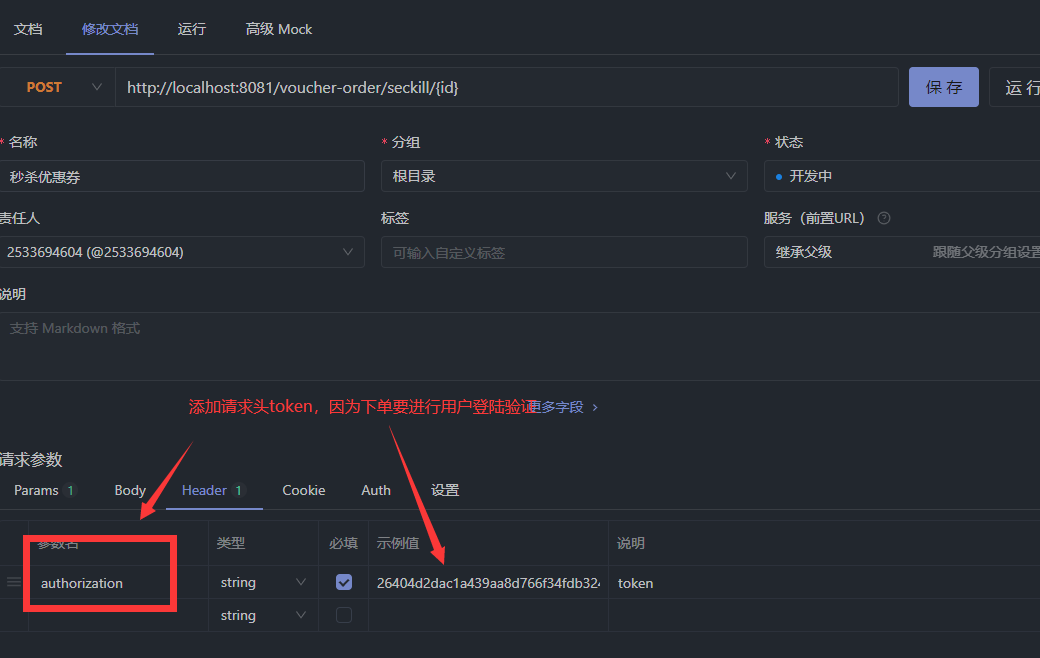
使用ApiFox测试接口是否可用:
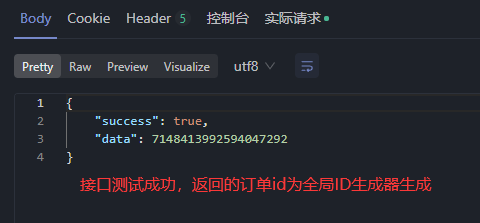
模拟高并发场景下,库存的超卖问题

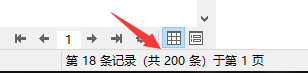
测试:
出现超卖问题,最多只能卖100件,在高并发的场景下却卖出了200件
15.7.5悲观锁和乐观锁
超卖问题是典型的多线程安全问题,针对这一问题的常见解决方案就是加锁:
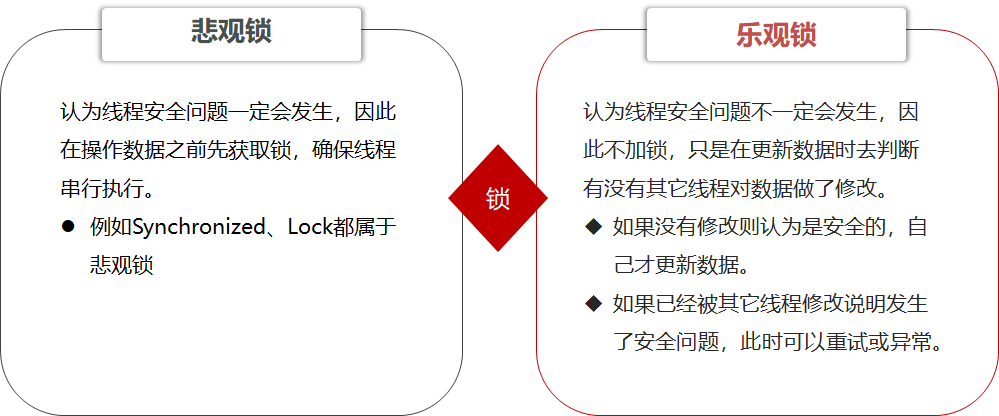
1.悲观锁:添加同步锁,让线程串行执行
优点:简单粗暴
缺点:性能一般
2.乐观锁:不加锁,在更新时判断是否有其它线程再修改
优点:性能好
缺点:存在成功率低的问题
乐观锁
乐观锁的关键是判断之前查询得到的数据是否有被修改过,常见的方式有两种:
版本号法
设置一个版本的标识号,用于数据更新的标记。就是相当于Git版本控制一样。一个线程先查询需要修改的数据和版本号,修改的时候再去判断当前版本是否和开始查询的版本是否相同,如果相同就修改,不同就不修改。
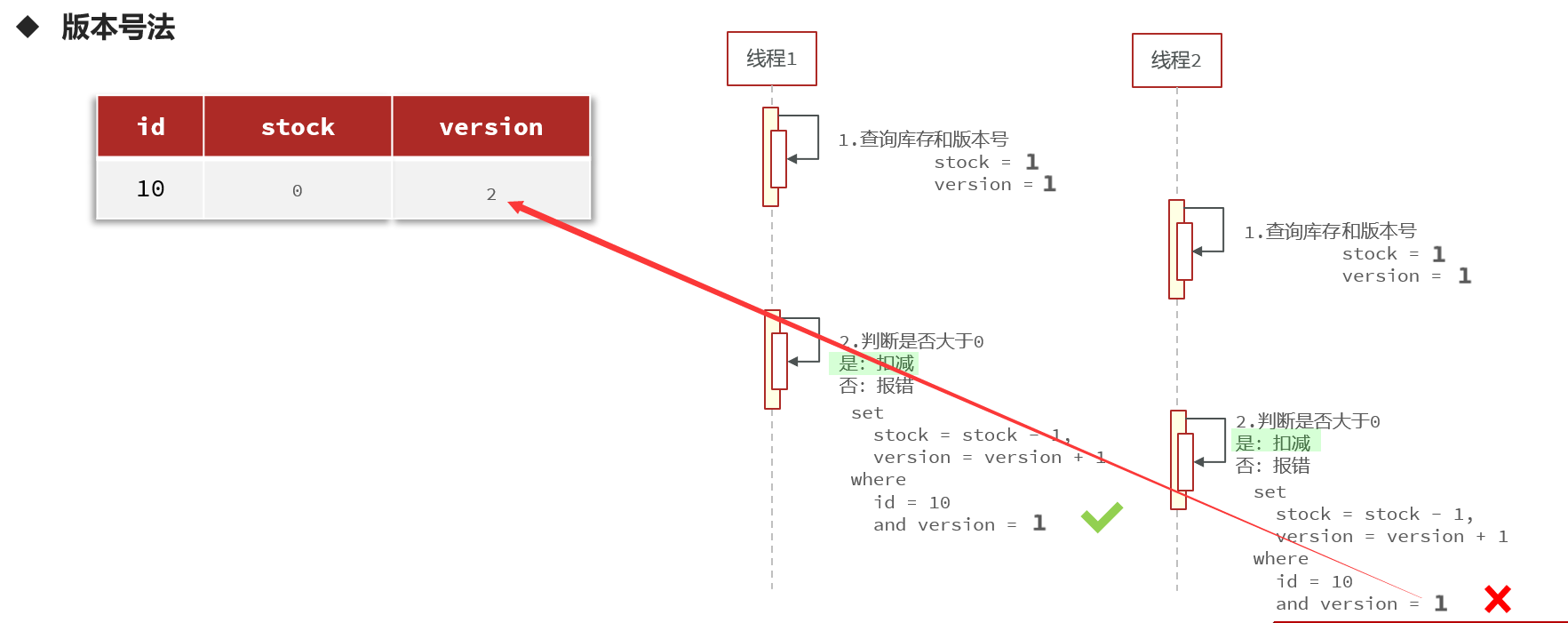
15.7.6使用乐观锁解决库存超卖(多线程并发安全)
采用CAS法解决多线程并发安全问题:
@Resource private ISeckillVoucherService seckillVoucherService; @Resource private SeckillVoucherMapper seckillVoucherMapper; @Resource private RedisIdWorker redisIdWorker; // 秒杀优惠券订单 @Transactional public Result seckillVoucherOrder(Long voucherId) {// 1.根据id查询优惠券 SeckillVoucher seckillVoucher = seckillVoucherService.getById(voucherId);// 2.判断秒杀是否开始 if (seckillVoucher.getBeginTime().isAfter(LocalDateTime.now())) {// 秒杀未开始 return Result.fail("秒杀尚未开始"); }// 3.判断秒杀是否结束 if (seckillVoucher.getEndTime().isBefore(LocalDateTime.now())) {// 秒杀已经结束 return Result.fail("秒杀已经结束"); }// 4.判断库存是否充足 if (seckillVoucher.getStock() < 1){// 库存不足 return Result.fail("库存不足"); }// 5.扣减库存 boolean update = seckillVoucherService .update() .setSql("stock = stock -1") .eq("voucher_id", voucherId) .gt("stock", 0).update(); //设置库存大于0 if (!update){ return Result.fail("库存不足!"); }// 6.创建订单 VoucherOrder voucherOrder = new VoucherOrder();// 订单id long orderId = redisIdWorker.uniqueId("order"); voucherOrder.setId(orderId);// 用户id voucherOrder.setUserId(UserHolder.getUser().getId());// 代金券id voucherOrder.setVoucherId(voucherId); save(voucherOrder);// 7.返回订单id return Result.ok(orderId); }
15.7.7使用悲观锁实现一人一单功能
需求:修改秒杀业务,要求同一个优惠券,一个用户只能下一单

<!-- 基于aop代理工厂面向切面编程所需依赖--> <dependency> <groupId>org.aspectj</groupId> <artifactId>aspectjweaver</artifactId> </dependency>
@Servicepublic class VoucherOrderServiceImpl extends ServiceImpl<VoucherOrderMapper, VoucherOrder> implements IVoucherOrderService { @Resource private ISeckillVoucherService seckillVoucherService; @Resource private RedisIdWorker redisIdWorker; // 秒杀优惠券订单 public Result seckillVoucherOrder(Long voucherId) {// 1.根据id查询优惠券 SeckillVoucher seckillVoucher = seckillVoucherService.getById(voucherId);// 2.判断秒杀是否开始 if (seckillVoucher.getBeginTime().isAfter(LocalDateTime.now())) {// 秒杀未开始 return Result.fail("秒杀尚未开始"); }// 3.判断秒杀是否结束 if (seckillVoucher.getEndTime().isBefore(LocalDateTime.now())) {// 秒杀已经结束 return Result.fail("秒杀已经结束"); }// 4.判断库存是否充足 if (seckillVoucher.getStock() < 1) {// 库存不足 return Result.fail("库存不足"); } Long userId = UserHolder.getUser().getId();// 确保当用户id一样时,锁就会一样 synchronized (userId.toString().intern()) {// createVoucherOrder不具有事务功能,需要获得当前对象的代理对象 IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy(); return proxy.createVoucherOrder(voucherId); } } @Transactional public Result createVoucherOrder(Long voucherId) { Long userId = UserHolder.getUser().getId(); //查询用户是否已经购买过了 int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count(); if (count > 0) { return Result.fail("您已经购买过了!"); }// 6.扣减库存 boolean update = seckillVoucherService .update() .setSql("stock = stock -1") .eq("voucher_id", voucherId) .gt("stock", 0).update(); if (!update) { return Result.fail("库存不足!"); }// 7.创建订单 VoucherOrder voucherOrder = new VoucherOrder();// 订单id long orderId = redisIdWorker.uniqueId("order"); voucherOrder.setId(orderId);// 用户id voucherOrder.setUserId(userId);// 代金券id voucherOrder.setVoucherId(voucherId); save(voucherOrder);// 8.返回订单id return Result.ok(orderId); }}测试:
发现只有第一个请求成功了
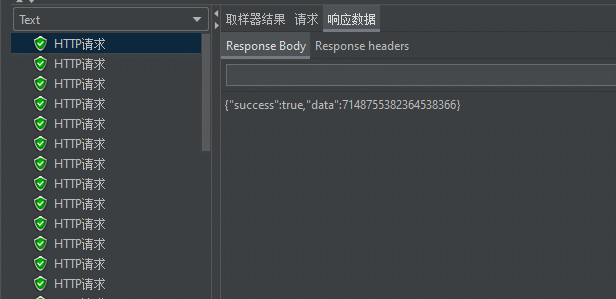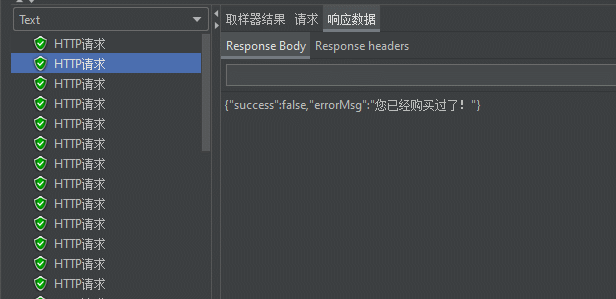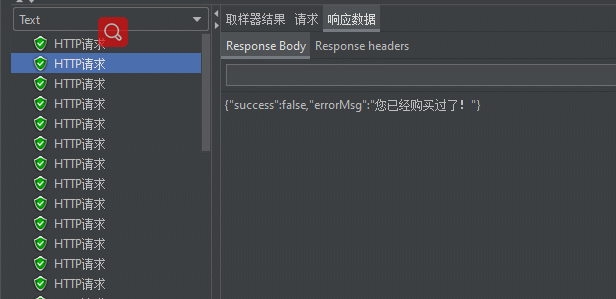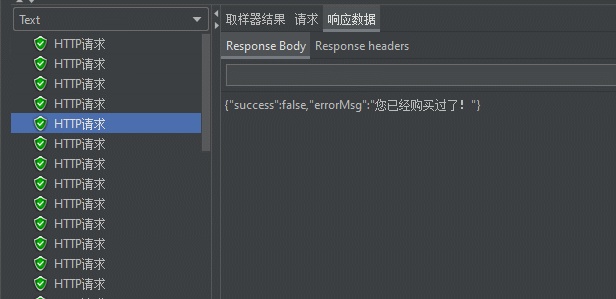
查看数据库:
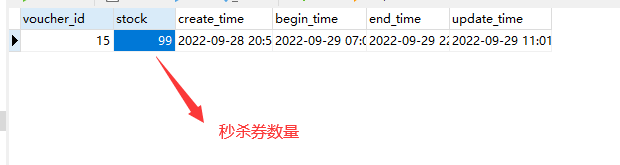
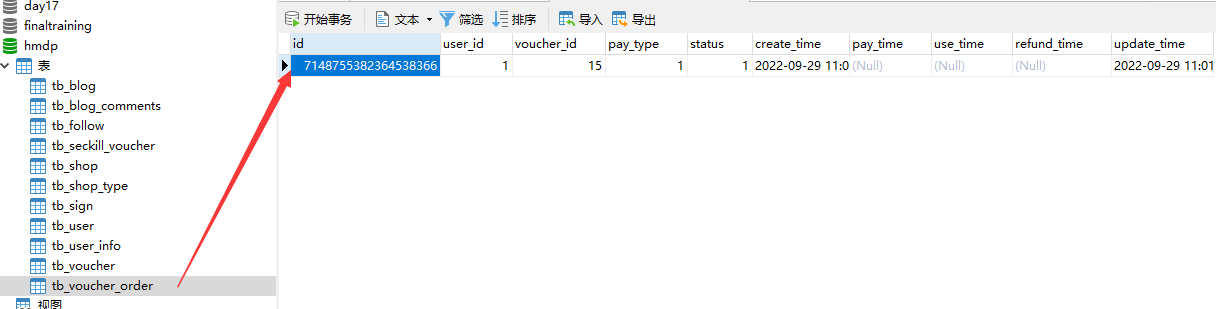
订单表中只有一条订单信息
15.7.8集群下线程并发安全问题
将当前项目放到两台Tomcat服务器下进行运行:
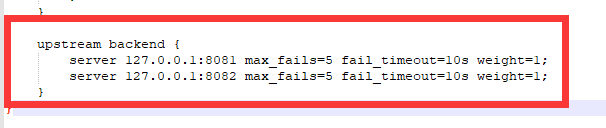
修改nginx的conf目录下的nginx.conf文件,配置反向代理和负载均衡
重启nginx服务(不行就关机重启)
访问两次测试端口:
两个端口下都有日志信息,表名该项目已经在两台服务器上部署。
测试订单接口
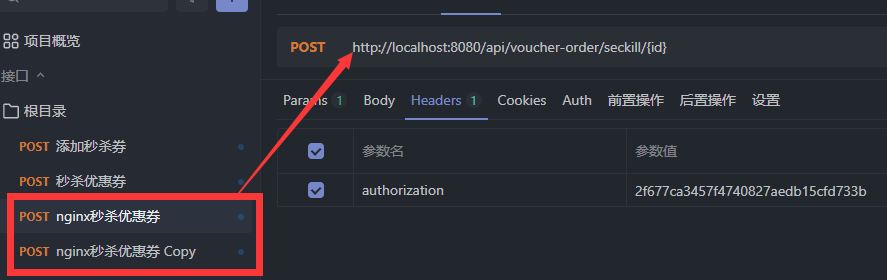


放行之后数据库中有两条数据


出现以上问题的原因是因为多个JVM都是属于自己的锁监视器,每个JVM中的线程运行时,都会根据自己的锁监视器进行多线程之间的调用。而不会和其他JVM中的锁监视器有关系。所以集群部署的方式下,使用synchronized锁并不能解决多线程并发安全问题。
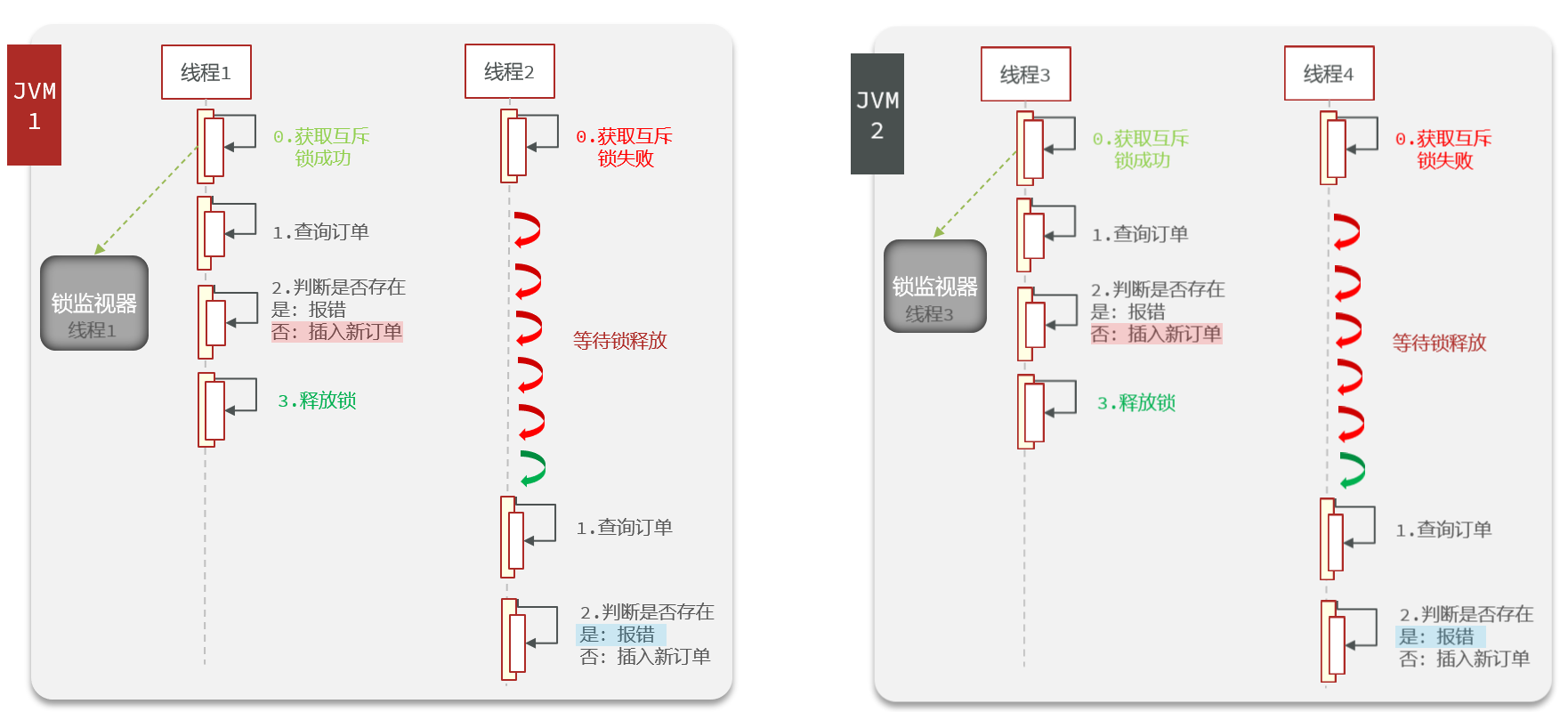
为了解决集群模式下多线程并发的安全问题,可以采用分布式锁的办法解决。
15.7.9使用分布式锁优化一人一单问题
使用悲观锁解决一人一单问题时时采用synchronize(同步锁)的方式来实现,但是在集群部署的模式下并不能解决多线程并发的安全性问题。所以可以采用Redis中的setnx在集群当中充当锁监视器,实现在多个服务器当中只有一个锁。
创建锁监视器
public class ILockService implements ILock { private String keyName; private StringRedisTemplate stringRedisTemplate; public ILockService(String keyName, StringRedisTemplate stringRedisTemplate) { this.keyName = keyName; this.stringRedisTemplate = stringRedisTemplate; } @Override public boolean tryLock(Long timeOutSec) {// 获取线程id long id = Thread.currentThread().getId();// 获取锁,以当前线程的id作为value Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(DISTRI_LOCK_KEY + keyName, id+"", timeOutSec, TimeUnit.SECONDS); return BooleanUtil.isTrue(flag); } @Override public void releseLock() {// 释放锁 stringRedisTemplate.delete(DISTRI_LOCK_KEY + keyName); }}调用分布式锁,实现一人一单功能优化,在集群部署下不会出现多线程并发的安全性问题。
@Servicepublic class VoucherOrderServiceImpl extends ServiceImpl<VoucherOrderMapper, VoucherOrder> implements IVoucherOrderService { @Resource private ISeckillVoucherService seckillVoucherService; @Resource StringRedisTemplate stringRedisTemplate; @Resource private RedisIdWorker redisIdWorker; // 秒杀优惠券订单 public Result seckillVoucherOrder(Long voucherId) {// 1.根据id查询优惠券 SeckillVoucher seckillVoucher = seckillVoucherService.getById(voucherId);// 2.判断秒杀是否开始 if (seckillVoucher.getBeginTime().isAfter(LocalDateTime.now())) {// 秒杀未开始 return Result.fail("秒杀尚未开始"); }// 3.判断秒杀是否结束 if (seckillVoucher.getEndTime().isBefore(LocalDateTime.now())) {// 秒杀已经结束 return Result.fail("秒杀已经结束"); }// 4.判断库存是否充足 if (seckillVoucher.getStock() < 1) {// 库存不足 return Result.fail("库存不足"); } Long userId = UserHolder.getUser().getId();// 创建分布式锁对象 ILockService distriLock = new ILockService("order:" + userId, stringRedisTemplate); boolean isLock = distriLock.tryLock(1200L);// 判断是否获取锁成功 if (!isLock) {// 获取锁失败 return Result.fail("不允许重复下单"); }// 获取锁成功// createVoucherOrder不具有事务功能,需要获得当前对象的代理对象 try { IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy(); return proxy.createVoucherOrder(voucherId); } finally { distriLock.releseLock(); } }// 扣减库存、创建订单 @Transactional public Result createVoucherOrder(Long voucherId) { Long userId = UserHolder.getUser().getId(); //查询用户是否已经购买过了 int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count(); if (count > 0) { return Result.fail("您已经购买过了!"); }// 6.扣减库存 boolean update = seckillVoucherService .update() .setSql("stock = stock -1") .eq("voucher_id", voucherId) .gt("stock", 0).update(); if (!update) { return Result.fail("库存不足!"); }// 7.创建订单 VoucherOrder voucherOrder = new VoucherOrder();// 订单id long orderId = redisIdWorker.uniqueId("order"); voucherOrder.setId(orderId);// 用户id voucherOrder.setUserId(userId);// 代金券id voucherOrder.setVoucherId(voucherId); save(voucherOrder);// 8.返回订单id return Result.ok(orderId); }}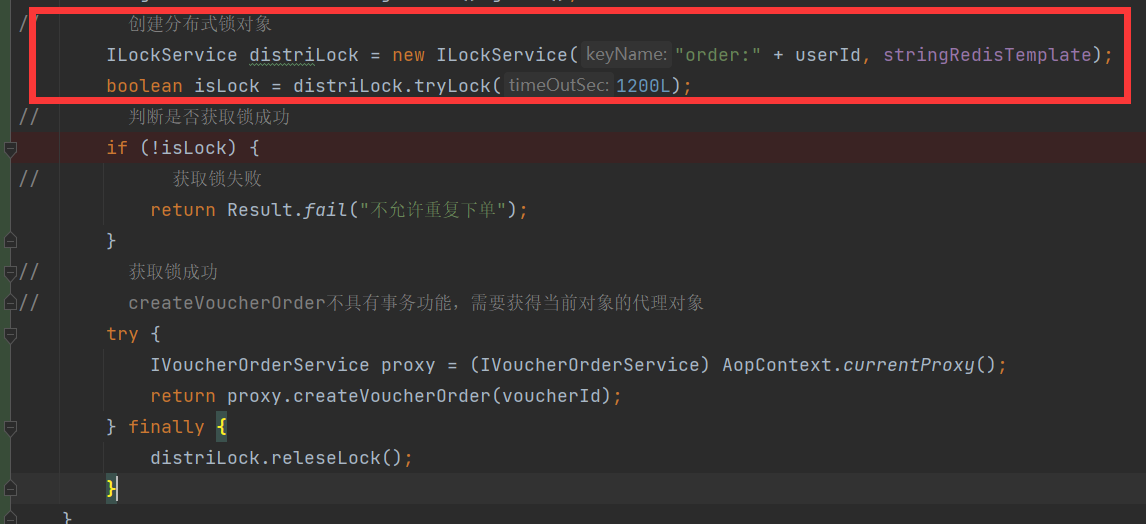
采用ApiFox进行测试:
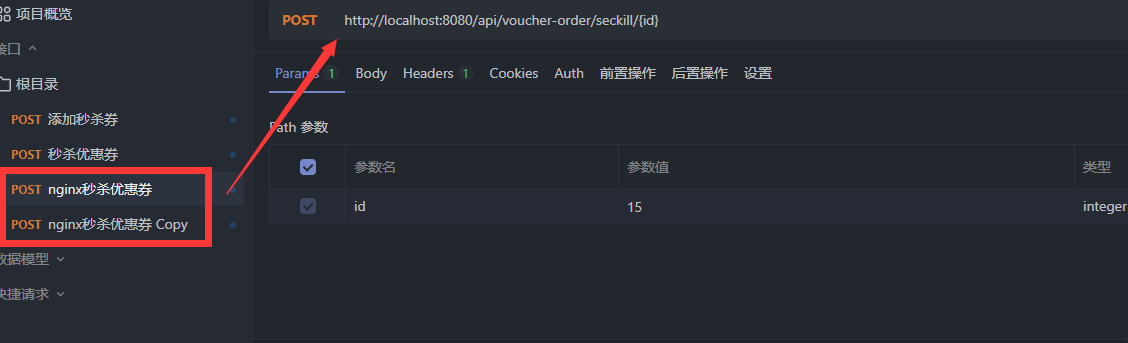
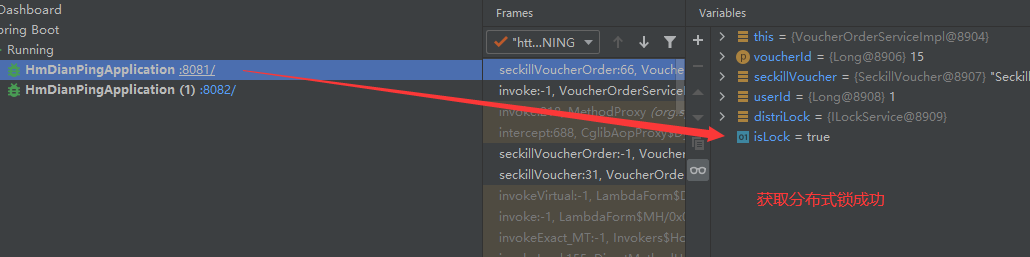
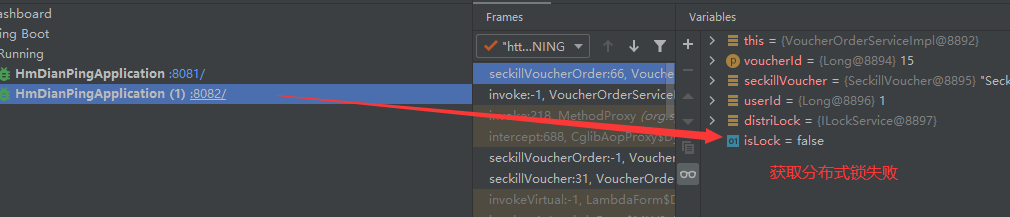


15.7.10分布式锁误删优化
为了防止因为线程阻塞而导致的分布式锁误删问题,在线程获取分布式锁的时候,向缓存中添加分布式锁的标识。当线程要释放锁的时候,查询缓存中的分布式锁的标识是否和自己的相同,相同的话就释放锁,不同的话就不做操作。
让第1台服务器获取到分布式锁
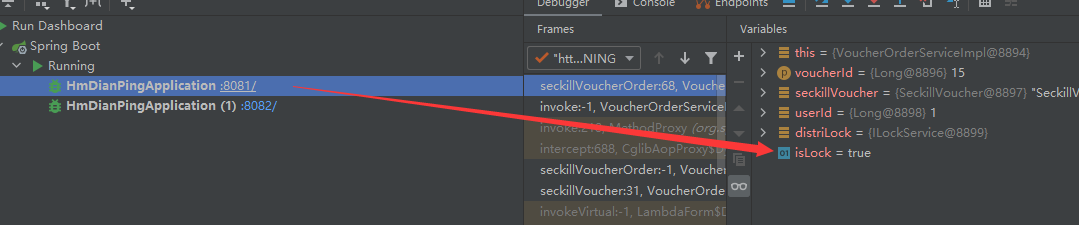
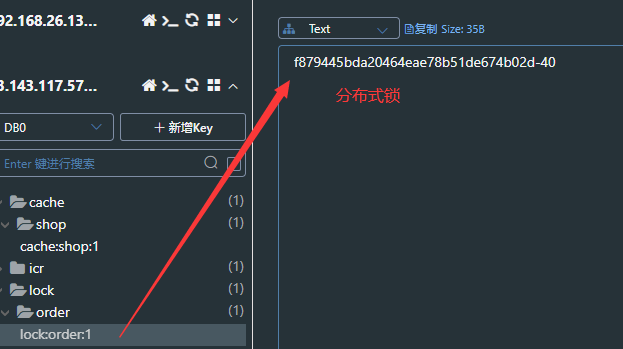
删除刚刚生成的分布式锁,模拟超时过期,让服务器2获取到分布式锁
服务器2成功获取到分布式锁

服务器2成功获取到分布式锁并且最后释放锁。
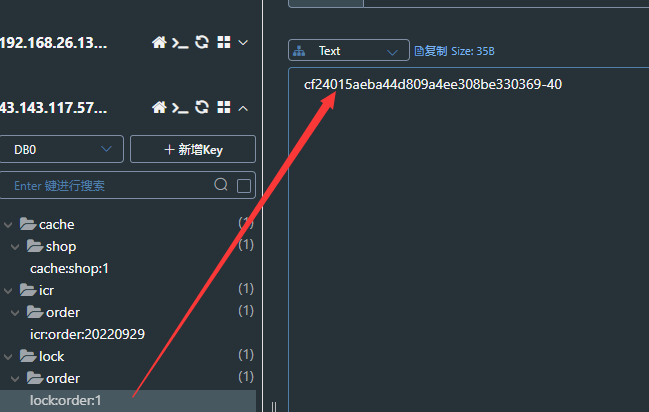
数据库新增一条数据


15.7.11使用Lua脚本实现分布式锁的原子性
一:首先编写Lua脚本
if (redis.call('get',KEYS[1]) == ARGV[1]) then-- 释放锁 return redis.call('del',KEYS[1])endreturn 0
private static final DefaultRedisScript<Long> UNLOCK_SCRIPT; static { UNLOCK_SCRIPT = new DefaultRedisScript<>();// 设置脚本位置 UNLOCK_SCRIPT.setLocation(new ClassPathResource("distri_lock.lua")); UNLOCK_SCRIPT.setResultType(Long.class); } // 释放锁 public void releseLock() {// 调用Lua脚本 stringRedisTemplate.execute(UNLOCK_SCRIPT, Collections.singletonList(keyName),THREADUUID + Thread.currentThread().getId()); }15.7.12使用Redisson实现分布式锁
Redisson是一个在Redis的基础上实现的Java驻内存数据网格。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。其中就包含了各种分布式锁的实现。
@Resource private ISeckillVoucherService seckillVoucherService; @Resource RedissonClient redissonClient; @Resource private RedisIdWorker redisIdWorker; // 秒杀优惠券订单 public Result seckillVoucherOrder(Long voucherId) {// 1.根据id查询优惠券 SeckillVoucher seckillVoucher = seckillVoucherService.getById(voucherId);// 2.判断秒杀是否开始 if (seckillVoucher.getBeginTime().isAfter(LocalDateTime.now())) {// 秒杀未开始 return Result.fail("秒杀尚未开始"); }// 3.判断秒杀是否结束 if (seckillVoucher.getEndTime().isBefore(LocalDateTime.now())) {// 秒杀已经结束 return Result.fail("秒杀已经结束"); }// 4.判断库存是否充足 if (seckillVoucher.getStock() < 1) {// 库存不足 return Result.fail("库存不足"); } Long userId = UserHolder.getUser().getId(); RLock lock = redissonClient.getLock(DISTRI_LOCK_KEY + userId); boolean isLock = lock.tryLock();// 判断是否获取锁成功 if (!isLock) {// 获取锁失败 return Result.fail("不允许重复下单"); }// 获取锁成功,创建订单 try { return createVoucherOrder(voucherId); } finally { lock.unlock(); } } // 扣减库存、创建订单 @Transactional public Result createVoucherOrder(Long voucherId) { Long userId = UserHolder.getUser().getId(); //查询用户是否已经购买过了 int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count(); if (count > 0) { return Result.fail("您已经购买过了!"); }// 6.扣减库存 boolean update = seckillVoucherService .update() .setSql("stock = stock -1") .eq("voucher_id", voucherId) .gt("stock", 0).update(); if (!update) { return Result.fail("库存不足!"); }// 7.创建订单 VoucherOrder voucherOrder = new VoucherOrder();// 订单id long orderId = redisIdWorker.uniqueId("order"); voucherOrder.setId(orderId);// 用户id voucherOrder.setUserId(userId);// 代金券id voucherOrder.setVoucherId(voucherId); save(voucherOrder);// 8.返回订单id return Result.ok(orderId); }使用ApiFox测试接口:
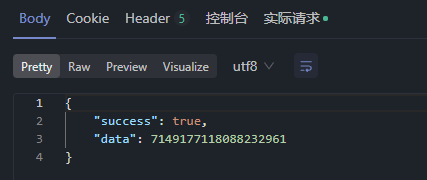
使用JMeter进行压力测试:
数据库只有一条数据


15.7.13秒杀优化(异步秒杀)
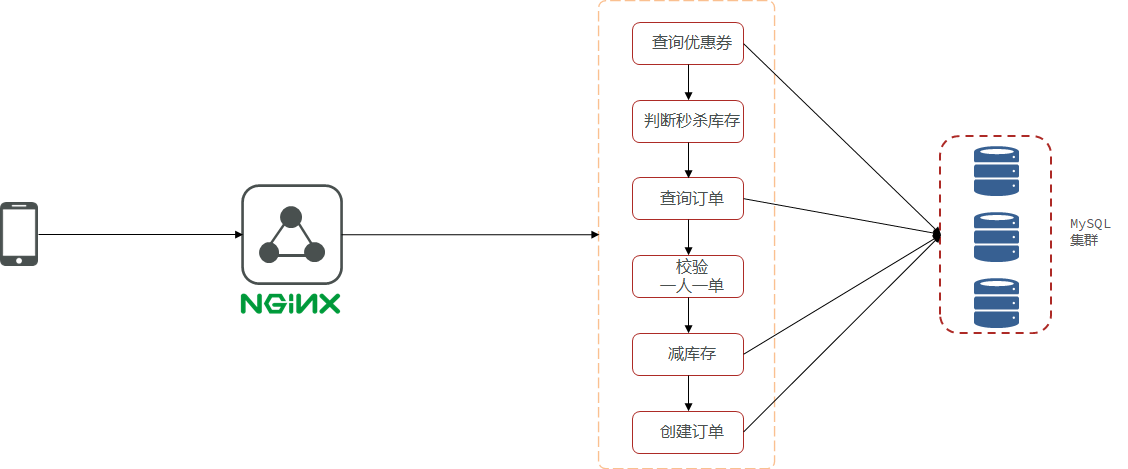
问题描述:在之前的秒杀业务中,客户端向Nginx代理服务器发送请求,Nginx做负载代理到Tomcat服务器,整个业务流程中,查询优惠券、查询订单、减库存、创建订单都是操作数据库来完成的。对数据库做太多的读写操作的话整个业务耗时就会很长,并发能力就会很差。
该如何解决以上问题呢?可以采用异步操作来完成。
将校验用户购买资格的业务流程放到Redis缓存当中,当客户端发送请求时就会在缓存当中判断用户的购买资格,如果没有购买资格就直接返回错误。
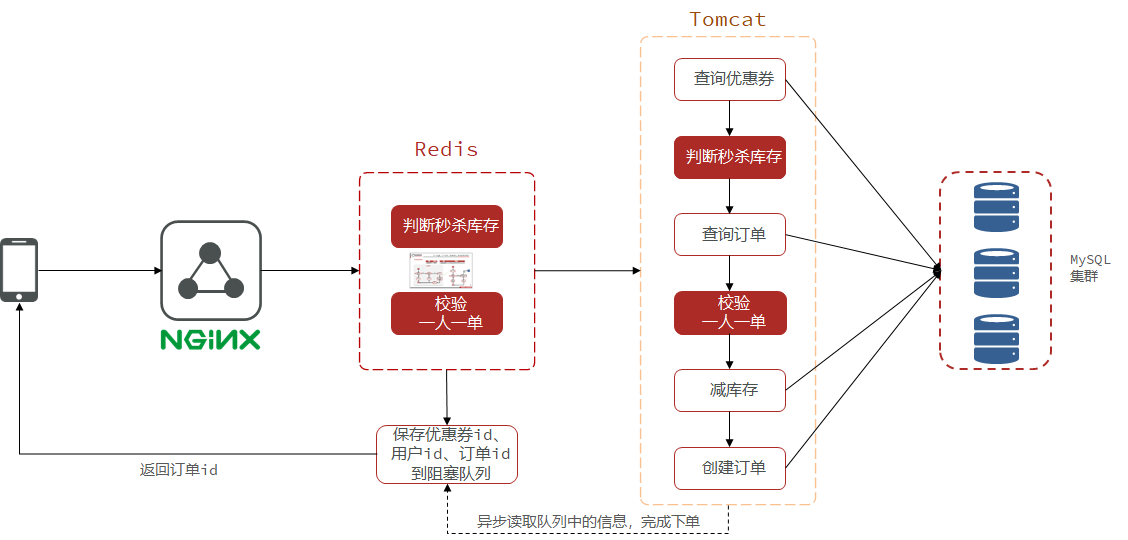
如果有购买资格就保存优惠券、用户、订单id到阻塞队列,然后后台数据库异步读取队列中的信息,完成下单。
为了保证判断用户是否有购买资格的业务的原子性,需要使用Lua脚本执行业务。
如果用户没有购买资格,就直接返回异常。如果有购买资格,完成将优惠券、用户、订单id写入阻塞队列,等待数据库完成异步下单操作。
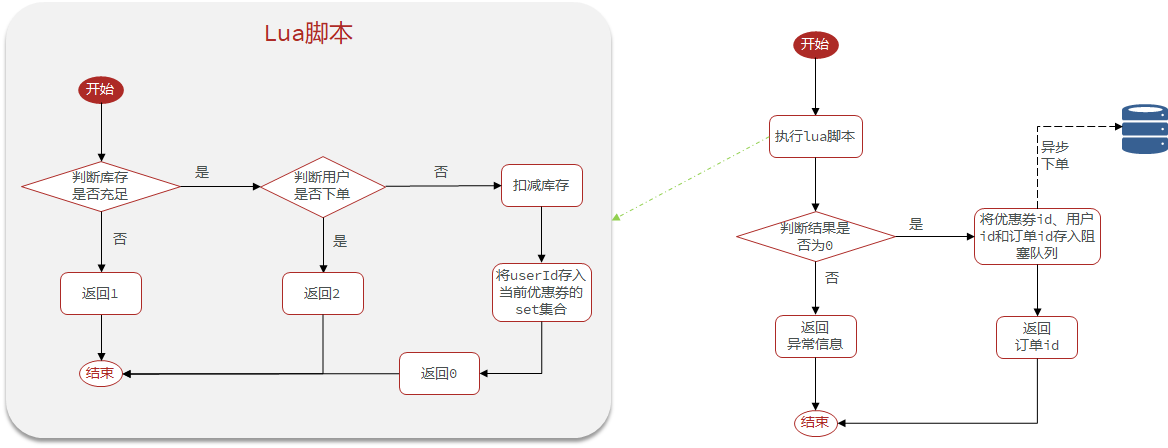

需求:
新增秒杀优惠券的同时,将优惠券信息保存到Redis中
基于Lua脚本,判断秒杀库存、一人一单,决定用户是否抢购成功
如果抢购成功,将优惠券id和用户id封装后存入阻塞队列
开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能
开始创建需求
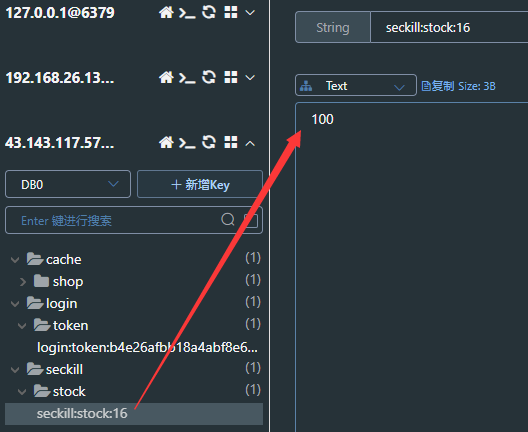
1.在创建秒杀券的同时将秒杀券的库存存入缓存当中。
@Transactional public void addSeckillVoucher(Voucher voucher) { // 保存优惠券 save(voucher); // 保存秒杀信息(另外一张表) SeckillVoucher seckillVoucher = new SeckillVoucher(); seckillVoucher.setVoucherId(voucher.getId()); seckillVoucher.setStock(voucher.getStock()); seckillVoucher.setBeginTime(voucher.getBeginTime()); seckillVoucher.setEndTime(voucher.getEndTime()); seckillVoucherService.save(seckillVoucher);// 保存秒杀库到Redis缓存当中 stringRedisTemplate.opsForValue().set(SECKILL_STOCK + voucher.getId(),voucher.getStock().toString()); }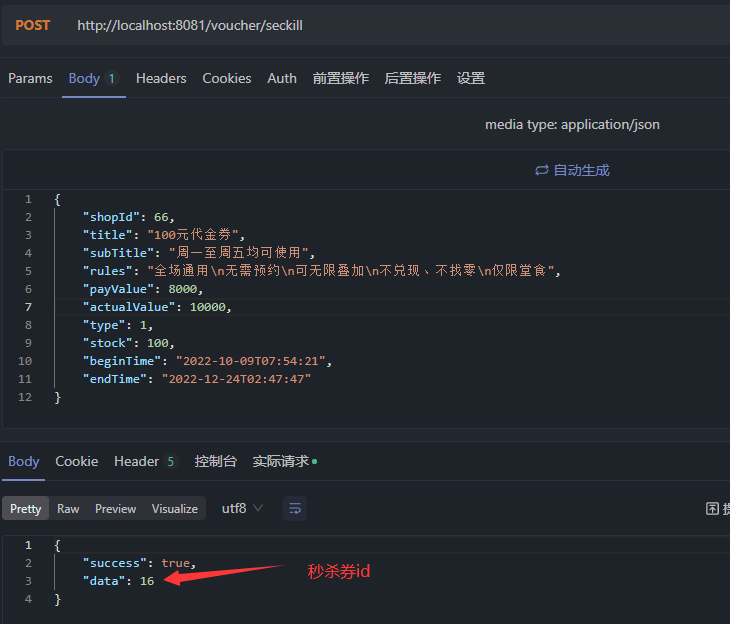
查看数据库

查看缓存中有秒杀券库存数量:
2.基于Lua脚本完成用户下单资格验证
lua脚本文件内容
--1.列表参数--1.1优惠券idlocal voucherId = ARGV[1]--1.2用户idlocal userId = ARGV[2]--2.数据key--2.1库存keylocal stockSky = 'seckill:stock:' .. voucherId--2.1订单keylocal orderSky = 'seckill:order:' .. voucherId--3.脚本业务--3.1判断库存是否充足if (tonumber(redis.call('get',stockSky)) <= 0) then --3.2库存不足 return 1end--3.3判断用户是否下单if (redis.call('sismember',orderSky,userId) == 1) then-- 3.4不能重复下单 return 2end--3.5扣库存redis.call('incrby',stockSky,-1)--3.6创建订单redis.call('sadd',orderSky,userId)return 0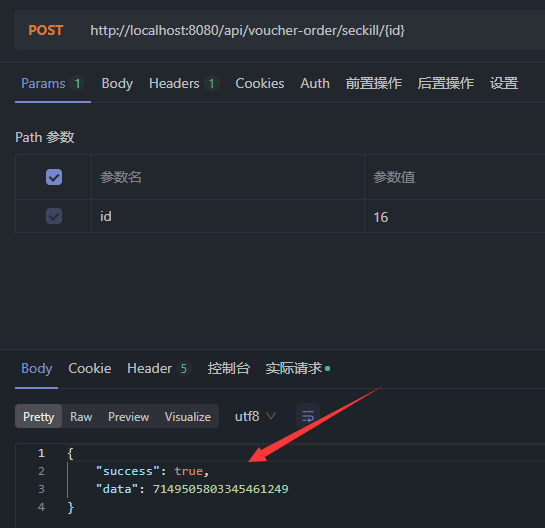
缓存中订单数加1,库存数减1
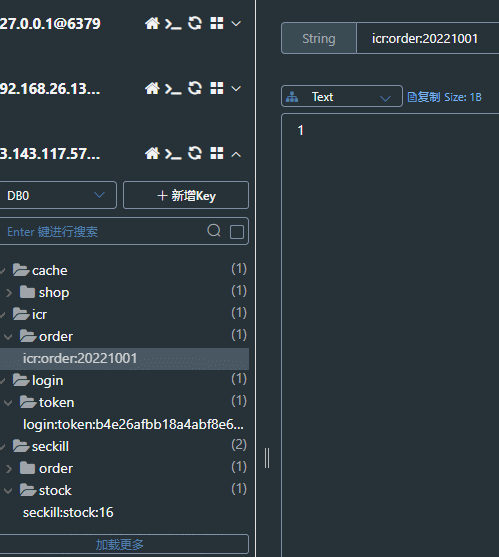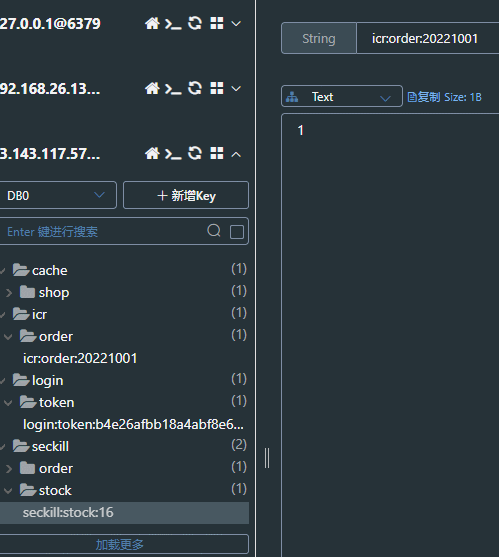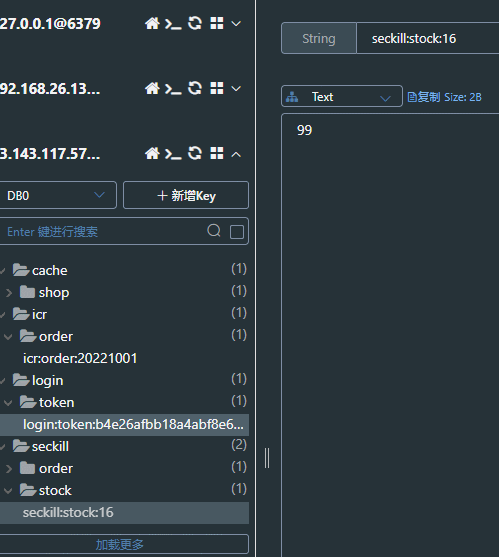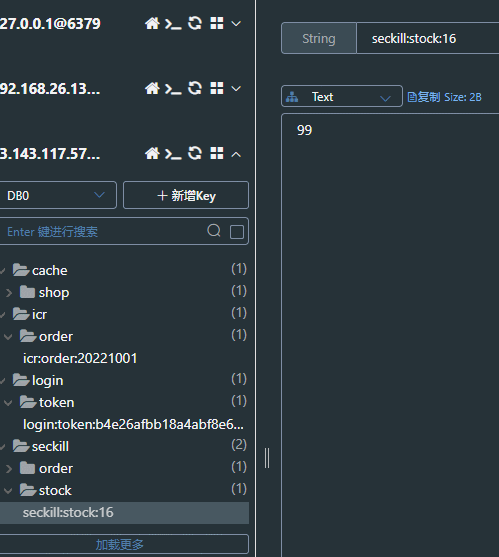
同一用户再次下单显示不能再次下单
如果抢购成功,将优惠券id和用户id封装后存入阻塞队列
开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能
使用ApiFox进行测试:
第一次下单成功
数据库完成异步更新


同一用户再次发送请求失败
使用JMeter进行高并发测试:
数据库只填加一条信息


秒杀业务的优化思路是什么?
先利用Redis完成库存余量、一人一单判断,完成抢单业务
再将下单业务放入阻塞队列,利用独立线程异步下单
基于阻塞队列的异步秒杀存在哪些问题?
一:内存限制问题
因为实现异步秒杀功能所使用的阻塞队列是JDK的阻塞队列,JDK的阻塞队列会使用JVM的内存,在高并发的场景下,会有无数的订单对象被创建并被放到阻塞队列里,可能会导致内存溢出。
二:数据安全问题
基于缓存保存的订单信息,如果服务崩溃,则所有的订单信息都会失效。
15.8达人探店
15.8.1发布探店博客
探店笔记类似点评网站的评价,往往是图文结合。对应的表有两个:
tb_blog:探店笔记表,包含笔记中的标题、文字、图片等
tb_blog_comments:其他用户对探店笔记的评价

上传图片的接口:
@PostMapping("blog")public Result uploadImage(@RequestParam("file") MultipartFile image) { try { // 获取原始文件名称 String originalFilename = image.getOriginalFilename(); // 生成新文件名 String fileName = createNewFileName(originalFilename); // 设置上传文件目录,保存文件 image.transferTo(new File(SystemConstants.IMAGE_UPLOAD_DIR, fileName)); // 返回结果 log.debug("文件上传成功,{}", fileName); return Result.ok(fileName); } catch (IOException e) { throw new RuntimeException("文件上传失败", e); }}设置图片的保存地址:

发布的接口:
@PostMappingpublic Result saveBlog(@RequestBody Blog blog) { // 获取登录用户 UserDTO user = UserHolder.getUser(); blog.setUserId(user.getId()); // 保存探店博文 blogService.save(blog); // 返回id return Result.ok(blog.getId());}
15.8.2查看探店博客
需求:点击首页的探店笔记,会进入详情页面,实现该页面的查询接口:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZGfEKTMg-1667304780283)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/image-20221001205244620.png)]
在Blog类中有三个不属于Blog类的字段,分别是用户id,用户头像和用户姓名,用于在博客页面展示用户信息
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jtb3gn23-1667304780284)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/image-20221001205938724.png)]
控制层
@GetMapping("/blog/{id}")public Result showBlog(@PathVariable("id") Long id){ return blogService.queryBlogById(id);}service层
// 根据用户id查询博客 public Result queryBlogById(Long id) { Blog blog = getById(id); if (blog == null){ return Result.fail("博客不存在!"); } queryBlogUser(blog); return Result.ok(blog); }// 查询与博客有关的用户信息 private void queryBlogUser(Blog blog) { // 存在就查询与博客有关的用户id Long userId = blog.getUserId();// 根据id查询和用户有关的信息 User user = userService.getById(userId); blog.setName(user.getNickName()); blog.setIcon(user.getIcon()); }实现成功
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-poQ2g7NX-1667304780284)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/image-20221001212553145.png)]
15.8.3点赞博客(限制点赞次数)
在首页的探店笔记排行榜和探店图文详情页面都有点赞的功能:
需求:
同一个用户只能点赞一次,再次点击则取消点赞
如果当前用户已经点赞,则点赞按钮高亮显示(前端已实现,判断字段Blog类的isLike属性)
实现步骤:
①给Blog类中添加一个isLike字段,标示是否被当前用户点赞
②修改点赞功能,利用Redis的set集合判断是否点赞过,未点赞过则点赞数+1,已点赞过则点赞数-1
③修改根据id查询Blog的业务,判断当前登录用户是否点赞过,赋值给isLike字段
④修改分页查询Blog业务,判断当前登录用户是否点赞过,赋值给isLike字段
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2ed4AAcG-1667304780285)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/image-20221001212755548.png)]
实现步骤:
为Blog添加isLike属性,表示点赞的状态
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bg9xzx7I-1667304780285)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/image-20221001213942276.png)]
@Servicepublic class BlogServiceImpl extends ServiceImpl<BlogMapper, Blog> implements IBlogService { @Resource private IUserService userService; @Resource private StringRedisTemplate stringRedisTemplate; // 根据用户id查询博客 public Result queryBlogById(Long id) { Blog blog = getById(id); if (blog == null) { return Result.fail("博客不存在!"); } queryBlogUser(blog);// 查询blog是否被点赞 isBlogLiked(blog); return Result.ok(blog); }// 判断博客的点赞情况 private void isBlogLiked(Blog blog) { // 1.获取到登录用户的id Long userId = UserHolder.getUser().getId();// 2.根据用户id和博客id判断当前用户是否已经点赞 Boolean flag = stringRedisTemplate.opsForSet().isMember(BLOG_LIKED + blog.getId(), userId.toString()); blog.setIsLike(BooleanUtil.isTrue(flag)); } // 查询与博客有关的用户信息 private void queryBlogUser(Blog blog) { // 存在就查询与博客有关的用户id Long userId = blog.getUserId();// 根据id查询和用户有关的信息 User user = userService.getById(userId); blog.setName(user.getNickName()); blog.setIcon(user.getIcon()); } // 查询热门博客 public Result queryHotBlog(Integer current) { // 根据用户查询 Page<Blog> page = query() .orderByDesc("liked") .page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE)); // 获取当前页数据 List<Blog> records = page.getRecords(); // 查询用户 records.forEach(blog -> { this.queryBlogUser(blog); this.isBlogLiked(blog); }); return Result.ok(records); } // 点赞功能 public void blogLike(Long id) {// 1.获取到登录用户的id Long userId = UserHolder.getUser().getId();// 2.根据用户id和博客id判断当前用户是否已经点赞 Boolean flag = stringRedisTemplate.opsForSet().isMember(BLOG_LIKED + id, userId.toString());// 3.未点赞可以点赞 if (BooleanUtil.isFalse(flag)) {// 4.数据库点赞数加1 boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update();// 5.保存博客id和用户id到缓存中的set集合 if (isSuccess) { stringRedisTemplate.opsForSet().add(BLOG_LIKED + id, userId.toString()); } } else {// 6.再次点击取消点赞,数据库点赞数减1 boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update();// 7.从set集合当中移除用户 if (isSuccess) { stringRedisTemplate.opsForSet().remove(BLOG_LIKED + id,userId.toString()); } } }}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xecWMmzY-1667304780285)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/image-20221001221314975.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4ADk5c1j-1667304780285)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/image-20221001221332473.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SgRRudvf-1667304780286)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/image-20221001220925594.png)]
15.8.4点赞排行榜
在探店笔记的详情页面,应该把给该笔记点赞的人显示出来,比如最早点赞的TOP5,形成点赞排行榜:
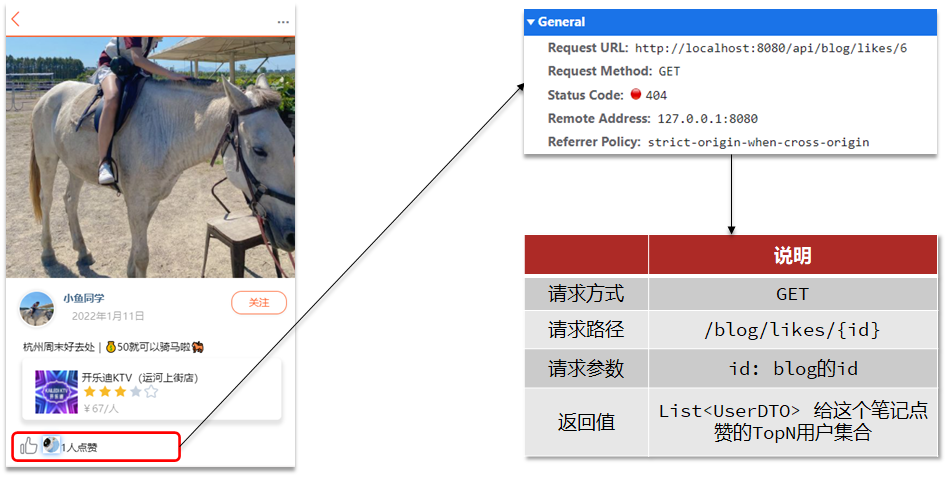

可以采用Redis中的有序列表进行排序,以博客id为key,用户id为value,用户点赞时间戳为score,以score作为排序的条件。
@Servicepublic class BlogServiceImpl extends ServiceImpl<BlogMapper, Blog> implements IBlogService { @Resource private IUserService userService; @Resource private StringRedisTemplate stringRedisTemplate; // 根据用户id查询博客 public Result queryBlogById(Long id) { Blog blog = getById(id); if (blog == null) { return Result.fail("博客不存在!"); } queryBlogUser(blog);// 查询blog是否被点赞 this.isBlogLiked(blog); return Result.ok(blog); }// 判断博客的点赞情况 private void isBlogLiked(Blog blog) {// 判断用户是否登录 UserDTO user = UserHolder.getUser();// 用户未登录就不查询点赞情况 if (user == null){ return; } // 1.获取到登录用户的id Long userId = user.getId();// 2.根据博客id和用户id判断当前用户是否已经点赞 Double score = stringRedisTemplate.opsForZSet().score(BLOG_LIKED_KEY + blog.getId(), userId.toString()); blog.setIsLike(score != null); } // 公共方法:查询与博客有关的用户信息 private void queryBlogUser(Blog blog) { // 存在就查询与博客有关的用户id Long userId = blog.getUserId();// 根据id查询和用户有关的信息 User user = userService.getById(userId); blog.setName(user.getNickName()); blog.setIcon(user.getIcon()); } // 查询热门博客 public Result queryHotBlog(Integer current) { // 根据用户查询 Page<Blog> page = query() .orderByDesc("liked") .page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE)); // 获取当前页数据 List<Blog> records = page.getRecords(); // 查询用户 records.forEach(blog -> { this.queryBlogUser(blog); this.isBlogLiked(blog); }); return Result.ok(records); } // 点赞功能 public void blogLike(Long id) {// 1.获取到登录用户的id Long userId = UserHolder.getUser().getId();// 2.根据用户id和博客id判断当前用户是否已经点赞 Double score = stringRedisTemplate.opsForZSet().score(BLOG_LIKED_KEY + id, userId.toString());// 3.未点赞可以点赞 if (score == null) {// 4.数据库点赞数加1 boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update();// 5.以博客id为key、用户id为value,当前时间戳为score if (isSuccess) { stringRedisTemplate.opsForZSet().add(BLOG_LIKED_KEY + id, userId.toString(), System.currentTimeMillis()); } } else {// 6.再次点击取消点赞,数据库点赞数减1 boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update();// 7.从set集合当中移除用户 if (isSuccess) { stringRedisTemplate.opsForZSet().remove(BLOG_LIKED_KEY + id,userId.toString()); } } } /** * 查询点赞博客的前五名用户 * @param id * @return */ public Result queryBlogLikes(Long id) {// 查询出前五名的用户id Set<String> userSet = stringRedisTemplate.opsForZSet().range(BLOG_LIKED_KEY + id, 0, 4); if (userSet == null || userSet.isEmpty()){ return Result.ok(); }// 解析出set集合中的用户id List<Long> usersId = userSet.stream().map(Long::valueOf).collect(Collectors.toList());// 根据用户id查询用户 String ids = StrUtil.join(",", usersId); List<UserDTO> userDTOS = userService.query()// 解决数据库传入的字段顺序问题 .in("id",usersId).last("ORDER BY FIELD(id," + ids + ")").list() .stream() .map(user -> BeanUtil.copyProperties(user, UserDTO.class)) .collect(Collectors.toList()); return Result.ok(userDTOS); }}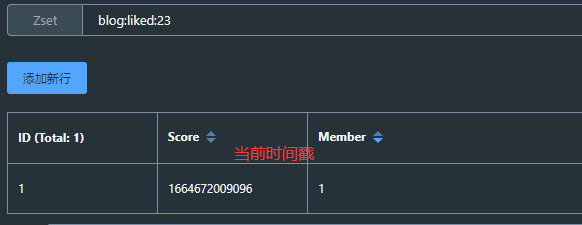
解决查询数据库in字段顺序不一致问题
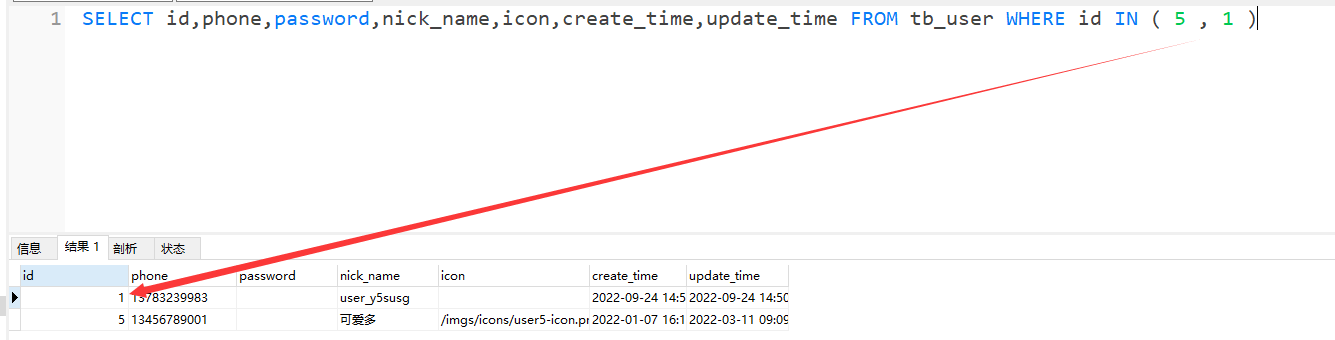
添加ORDER BY FIELD字段指定参数顺序
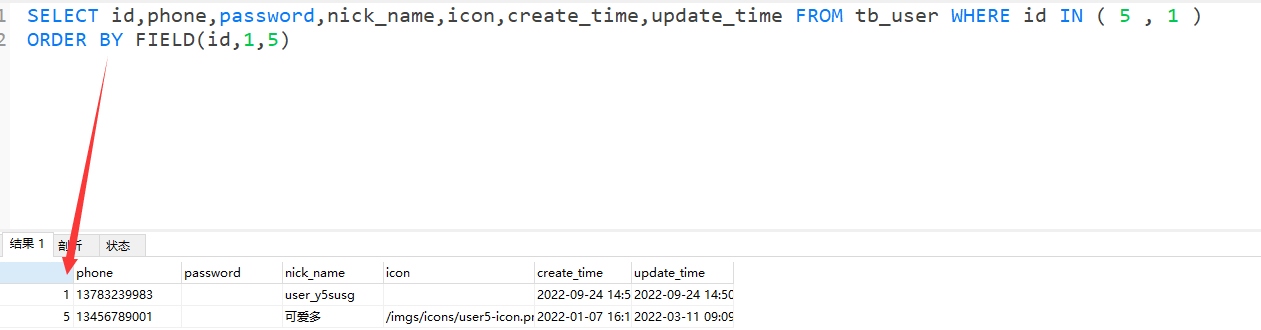
修改前

修改后

15.8.5关注和取关
在探店图文的详情页面中,可以关注发布博客的作者:
需求:基于该表数据结构,实现两个接口:
①关注和取关接口
②判断是否关注的接口
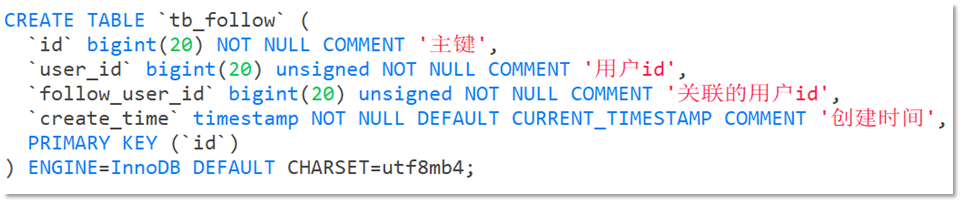
关注是User之间的关系,是博主与粉丝的关系,数据库中有一张tb_follow表来标示:
控制层
/** * 关注和取关 * @param followUserId * @param isFollow * @return */@PutMapping("/{id}/{isFollow}")public Result follow(@PathVariable("id") Long followUserId,@PathVariable("isFollow") Boolean isFollow){ return followService.follow(followUserId,isFollow);}/** * 判断关注状态,加载页面时自动查询 * @param followUserId * @return */@GetMapping("/or/not/{id}")public Result queryFollow(@PathVariable("id") Long followUserId ){ return followService.queryFollow(followUserId);}Service层
/** * 关注和取关 * * @param followUserId * @param isFollow * @return */ @Resource private IFollowService followService; @Override public Result follow(Long followUserId, Boolean isFollow) {// 1.获取到登录用户id Long userId = UserHolder.getUser().getId();// 2.判断是关注还是取关 if (isFollow) {// 3.关注,新增数据 Follow follow = new Follow();// 设置用户id follow.setUserId(userId);// 设置博主id follow.setFollowUserId(followUserId); save(follow); } else {// 4.取关,删除数据 delete from tb_follow where userId = ? and follow_user_id = ? QueryWrapper<Follow> queryWrapper = new QueryWrapper<>(); queryWrapper.eq("user_id", userId); queryWrapper.eq("follow_user_id", followUserId); followService.remove(queryWrapper); } return Result.ok(); } /** * 判断用户是否关注状态 * @param followUserId * @return */ @Override public Result queryFollow(Long followUserId) {// select * from tb_follow where userId = ? and follow_user_id = ? // 1.获取到登录用户id Long userId = UserHolder.getUser().getId(); Integer count = query().eq("user_id", userId).eq("follow_user_id", followUserId).count(); return Result.ok(count > 0); }
关注成功,数据库插入一条数据
15.8.6共同关注
共同关注就是当前登录的用户和查看的博主共同关注的人
点击博主头像,可以进入博主首页:
首先实现点击用户头像进入博主页面,博主页面有博主信息和发布的博客信息。
查询用户信息的url http://localhost:8080/api/user/{用户id}
获取到用户博客信息的url http://localhost:8080/api/of/user
Service层
/** * 根据id查询用户 * @param id * @return */public Result queryUserById(Long id) { User user = getById(id); if (user == null){ return Result.ok(); } UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class); return Result.ok(userDTO);} /** * 查询博主的所有博客 */ @GetMapping("/of/user") public Result queryUserBlog(@RequestParam(value = "current", defaultValue = "1") Integer current, @RequestParam("id") Long id){// 根据用户id查询博客信息 Page<Blog> page = blogService.query().eq("user_id", id).page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));// 获取当前页信息 List<Blog> records = page.getRecords(); return Result.ok(records); }实现完成,接下实现共同关注
实现共同关注
需求:利用Redis中恰当的数据结构,实现共同关注功能。在博主个人页面展示出当前用户与博主的共同好友。
查询博主和当前用户的共同关注接口 http://localhost:8080/api/follow/common/{博主id}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9BWiQyqa-1667304780290)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/image-20221002171346858.png)]
在之间的关注功能业务里添加:当关注一个博主时,将以当前登录用户id做为key,关注的博主id做为value。查询两个用户的共同关注就求缓存中两个用户关注列表的交集。
Service层的FollowServiceImpl
添加用户关注博主时的缓存信息
@Override public Result follow(Long followUserId, Boolean isFollow) {// 1.获取到登录用户id Long userId = UserHolder.getUser().getId();// 2.判断是关注还是取关 if (isFollow) {// 3.关注,新增数据 Follow follow = new Follow();// 设置用户id follow.setUserId(userId);// 设置博主id follow.setFollowUserId(followUserId); boolean isSave = save(follow); if (isSave) {// 成功关注后以用户id作为key,关注的博主id作为value存入redis stringRedisTemplate.opsForSet().add(FOLLOW_BLOGGER_KEY + userId, followUserId.toString()); } } else {// 4.取关,删除数据 delete from tb_follow where userId = ? and follow_user_id = ? QueryWrapper<Follow> queryWrapper = new QueryWrapper<>(); queryWrapper.eq("user_id", userId); queryWrapper.eq("follow_user_id", followUserId); boolean remove = followService.remove(queryWrapper); if (remove) { // 在Redis集合中移除关注的用户id stringRedisTemplate.opsForSet().remove(FOLLOW_BLOGGER_KEY + userId, followUserId.toString()); } } return Result.ok(); } /** * 根据博主id查询和当前用的共同关注 * @param followUserId * @return */ @Override public Result queryFollowCommon(Long followUserId) {// 获取当前用户id Long userId = UserHolder.getUser().getId();// 传入两个key,求当前用户和博主的交集 Set<String> intersect = stringRedisTemplate.opsForSet() .intersect(FOLLOW_BLOGGER_KEY + userId, FOLLOW_BLOGGER_KEY + followUserId); if (intersect == null || intersect.isEmpty()){ return Result.ok(Collections.emptyList()); }// 将set集合类型解析为Long型的List集合 List<Long> ids = intersect.stream().map(Long::valueOf).collect(Collectors.toList());// 根据id集合查询用户 List<UserDTO> users = userService.listByIds(ids) .stream() .map(user -> BeanUtil.copyProperties(user,UserDTO.class)) .collect(Collectors.toList()); return Result.ok(users); }测试:
登录三个用户,分别是 阳光、可爱多、可可今天不吃肉,让前两者关注后者,在阳光账户下查看可爱多的共同关注列表。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tq8bPPGZ-1667304780290)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/image-20221002180636566.png)]
缓存信息,id为1(阳光)和id为5(可爱多)的用户共同关注了id为2(可可今天不吃肉)的用户
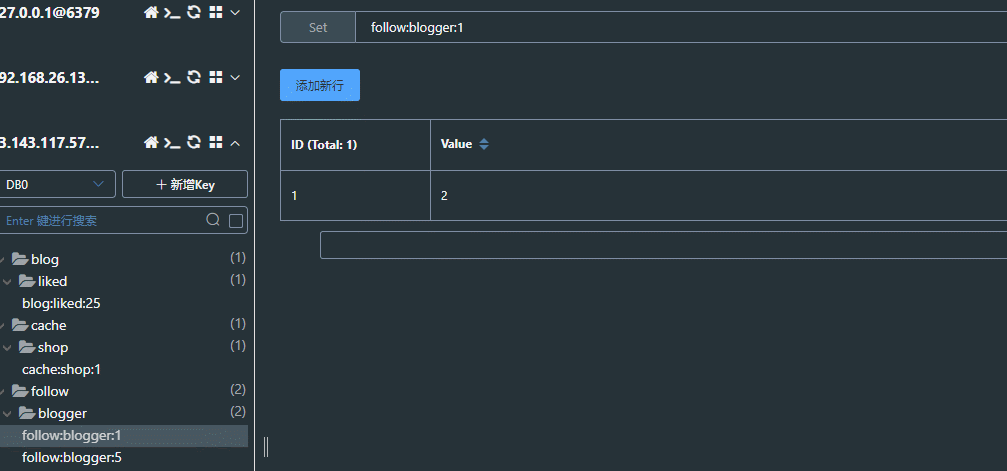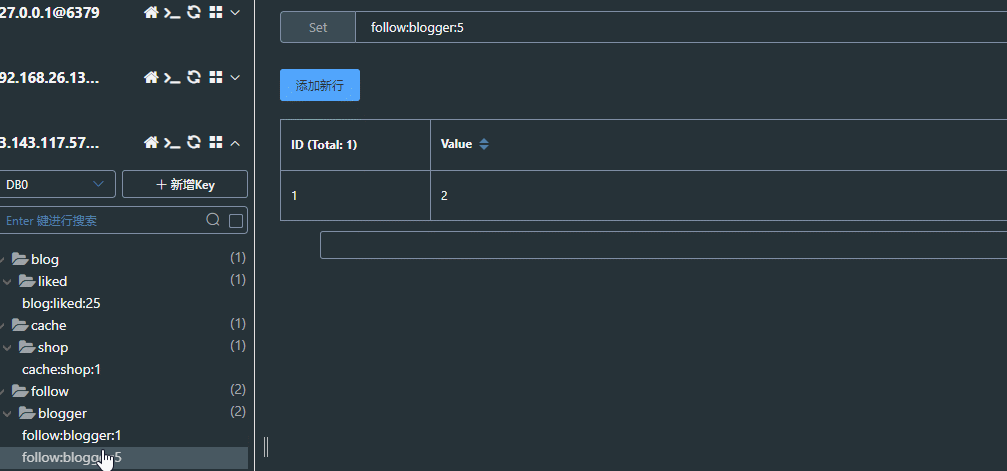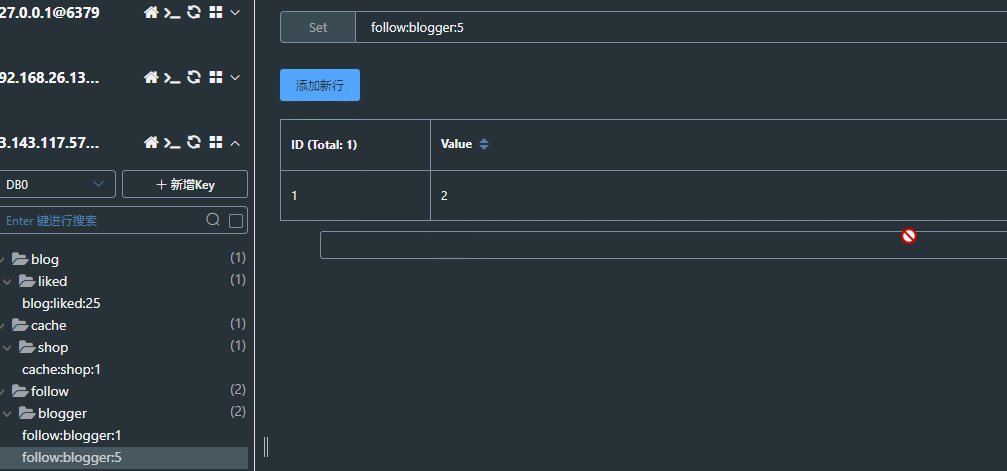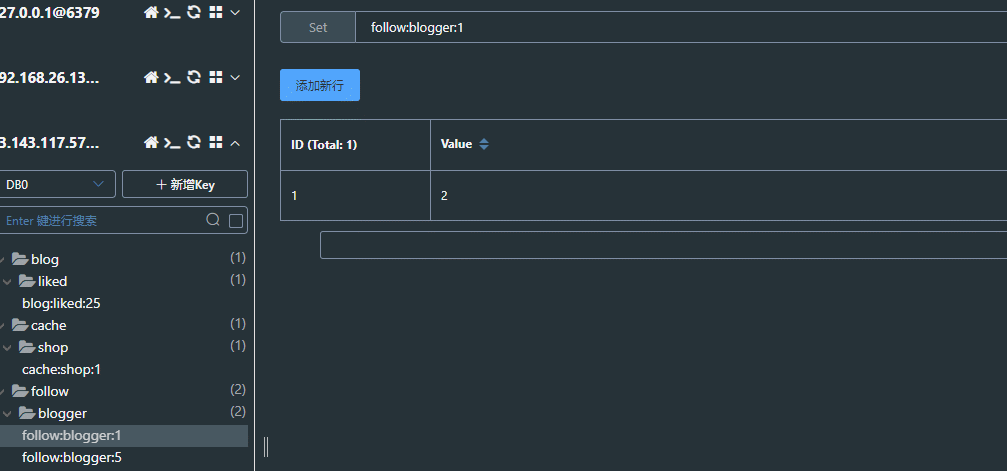
15.8.7关注推送(Feed流)
关注推送也叫做Feed流,直译为投喂。为用户持续的提供“沉浸式”的体验,通过无限下拉刷新获取新的信息。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-waxRovHq-1667304780290)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/image-20221002184404688.png)]
Feed流的模式:
Feed流产品有两种常见模式:
Timeline:不做内容筛选,简单的按照内容发布时间排序,常用于好友或关注。例如朋友圈
优点:信息全面,不会有缺失。并且实现也相对简单
缺点:信息噪音较多,用户不一定感兴趣,内容获取效率低
智能排序:利用智能算法屏蔽掉违规的、用户不感兴趣的内容。推送用户感兴趣信息来吸引用户
优点:投喂用户感兴趣信息,用户粘度很高,容易沉迷
缺点:如果算法不精准,可能起到反作用
本例中的个人页面,是基于关注的好友来做Feed流,因此采用Timeline的模式。该模式的实现方案有三种:
拉模式
推模式
推拉结合
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MRELMU1m-1667304780291)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/image-20221002191559541.png)]
一:拉模式
用户可以根据关注的博主对其发件箱中的内容进行拉取,然后将拉取的内容按照时间进行排序。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VIQEr3tY-1667304780291)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/GIF%202022-10-2%2019-10-27-1664709264861.gif)]
二:推模式
博主会将内容推送给所有的粉丝的收件箱中,并且会进行排序好。粉丝每次可以在收件箱中直接进行读取。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YjGSZUfQ-1667304780291)(https://imagebed-xuhuaiang.oss-cn-shanghai.aliyuncs.com/typora/GIF%202022-10-2%2019-12-06.gif)]
三:推拉结合
活跃粉丝采用推模式,普通粉丝采用拉模式。

15.8.9Feed的分页问题
Feed流中的数据会不断更新,所以数据的角标也在变化,会读取到重复的数据。因此不能采用传统的分页模式。
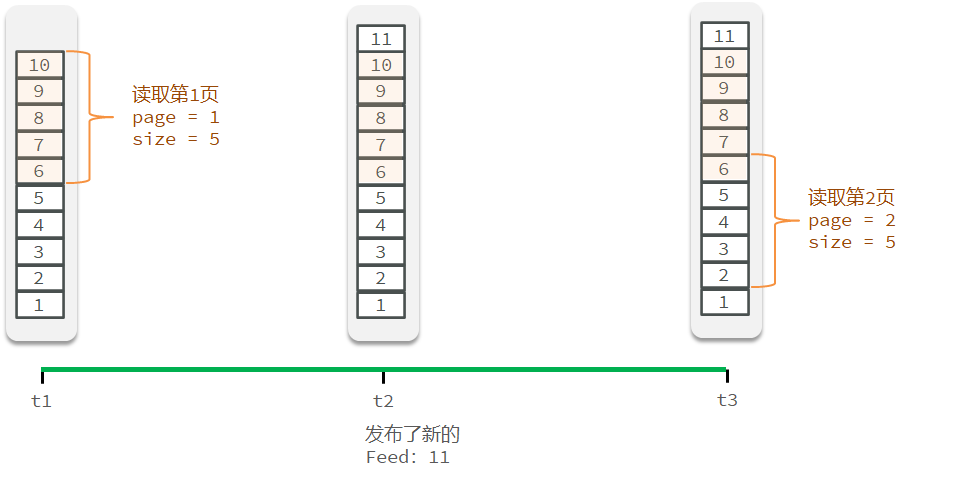
Feed流的滚动分页
记录上次最后的一条记录,下次分页在此记录之后进行分页
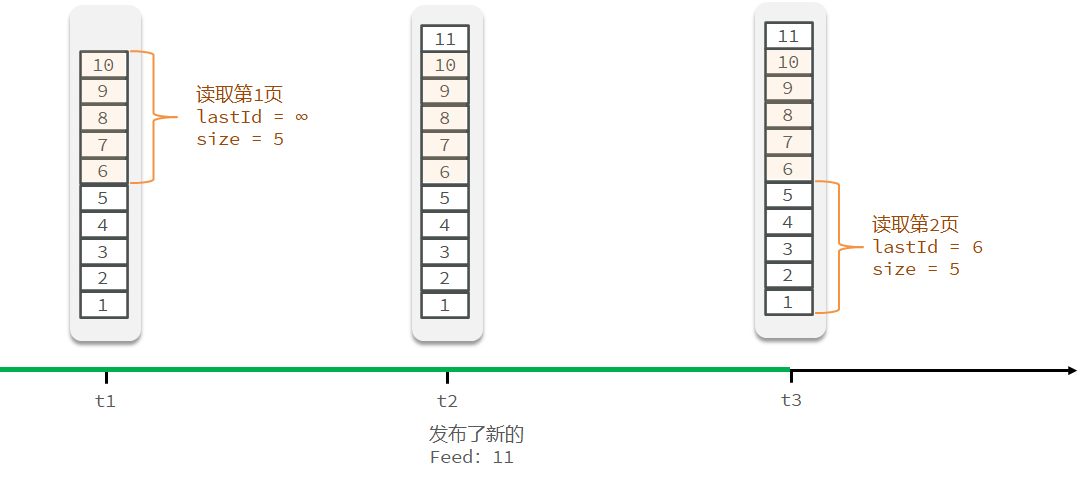
15.8.8基于Timeline模式的推方式实现关注推送
需求:
①修改新增探店笔记的业务,在保存blog到数据库的同时,遍历当前用户的粉丝,并将blog推送到粉丝的收件箱。
②收件箱满足可以根据时间戳排序,必须用Redis的数据结构实现。收件箱是以粉丝的id作为key,发布的新博客id作为value,时间戳为score。
③查询收件箱数据时,可以实现分页查询
public Result saveBlog(Blog blog) {// 获取到当前登录用户的id Long userId = UserHolder.getUser().getId(); blog.setUserId(userId); boolean isSave = save(blog); if (!isSave){ return Result.fail("添加博客失败"); }// 查询当前用户的所有粉丝select * from tb_follow where follow_user_id = ? List<Follow> follows = followService.query().eq("follow_user_id", userId).list();// 推送笔记给所有粉丝 for(Follow follow:follows){// 获取到粉丝id Long followId = follow.getId();// 推送:以粉丝的id作为key,发布的新博客id作为value,时间戳为score stringRedisTemplate.opsForZSet().add(FEED_FOLLOWS_KEY + followId,blog.getId().toString(),System.currentTimeMillis()); } return Result.ok(blog.getId()); }15.8.9实现关注页面的分页查询
需求:在个人主页的“关注”卡片中,查询并展示推送的Blog信息:

/** * 查询用户的关注者发布的所有博客 * * @param max * @param offset * @return */ @Override public Result queryBlogOfFollow(Long max, Integer offset) {// 1.获取到当前用户 Long userId = UserHolder.getUser().getId();// 2.查询收件箱 zrangebyscore key min max [limit offset count] Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet(). reverseRangeByScoreWithScores(FEED_FOLLOWS_KEY + userId, 0, max, offset, 2);// 3.判断是否为空 if (typedTuples == null || typedTuples.isEmpty()) { return Result.ok(); }// 4.解析blogId、score(时间戳)、offset(上次查询最小的相同的个数) List<Long> idList = new ArrayList<>(typedTuples.size()); long minTime = 0; int offsets = 1; for (ZSetOperations.TypedTuple<String> tuple : typedTuples) {// 4.1获取blog的id idList.add(Long.valueOf(tuple.getValue()));// 4.2获取时间戳 long time = tuple.getScore().longValue();// 4.3判断获取的时间戳是不是最小的 if (time == minTime) { offsets++; } else { minTime = time; //最小时间 offsets = 1; } }// StrUtil.join将数组用分隔字符串合(,)并为字符串 String idStr = StrUtil.join(",", idList);// 4.根据blog的id查询blog List<Blog> blogs = query() .in("id", idList) .last("ORDER BY FIELD(id," + idStr + ")") .list(); for (Blog blog : blogs) {// 4.1查询博主信息 queryBlogUser(blog);// 4.2查询blog是否被点赞 this.isBlogLiked(blog); }// 5.封装ScrollResult对象 ScrollResult scrollResult = new ScrollResult(); scrollResult.setList(blogs); scrollResult.setMinTime(minTime); scrollResult.setOffset(offsets); return Result.ok(scrollResult); }
15.9附近商户
15.9.1GEO数据结构概念
GEO就是Geolocation(地理坐标)的简写形式。Redis在3.2版本中加入了对GEO的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。常见的命令有:
GEOADD:添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)
GEODIST:计算指定的两个点之间的距离并返回
GEOHASH:将指定member的坐标转为hash字符串形式并返回
GEOPOS:返回指定member的坐标
GEOSEARCH:在指定范围内搜索member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。6.2.新功能
GEOSEARCHSTORE:与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。 6.2.新功能
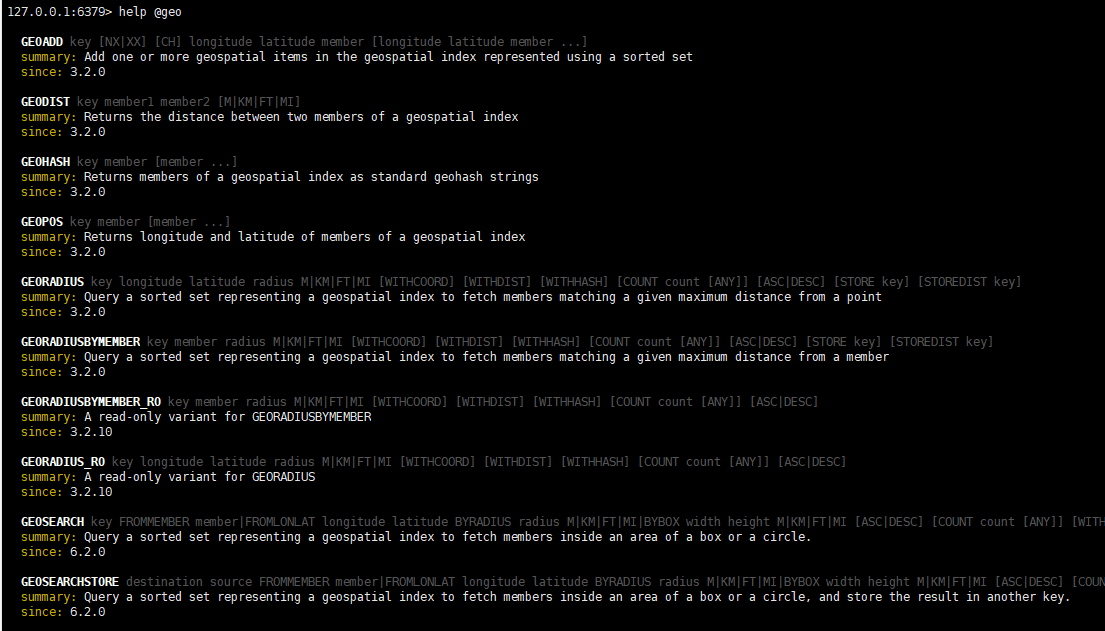
15.9.2GEO数据结构练习
1.添加下面几条数据:
北京南站( 116.378248 39.865275 )
北京站( 116.42803 39.903738 )
北京西站( 116.322287 39.893729 )
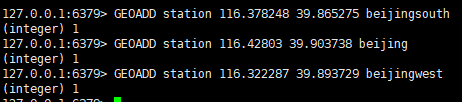
查看缓存
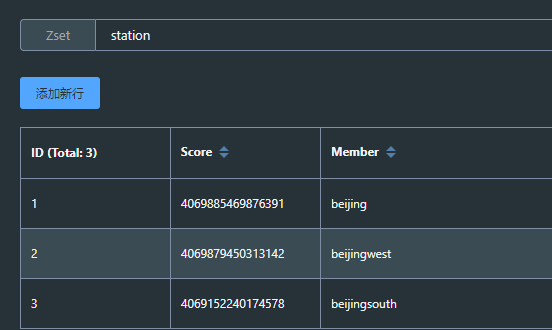
2.计算北京西站到北京站的距离

3.搜索天安门( 116.397904 39.909005 )附近10km内的所有火车站,并按照距离升序排序

15.9.3将商户按照类型分组并存入缓存
在首页中点击某个频道,即可看到频道下的商户:
按照商户类型做分组,类型相同的商户作为同一组,以typeId为key存入同一个GEO集合中即可
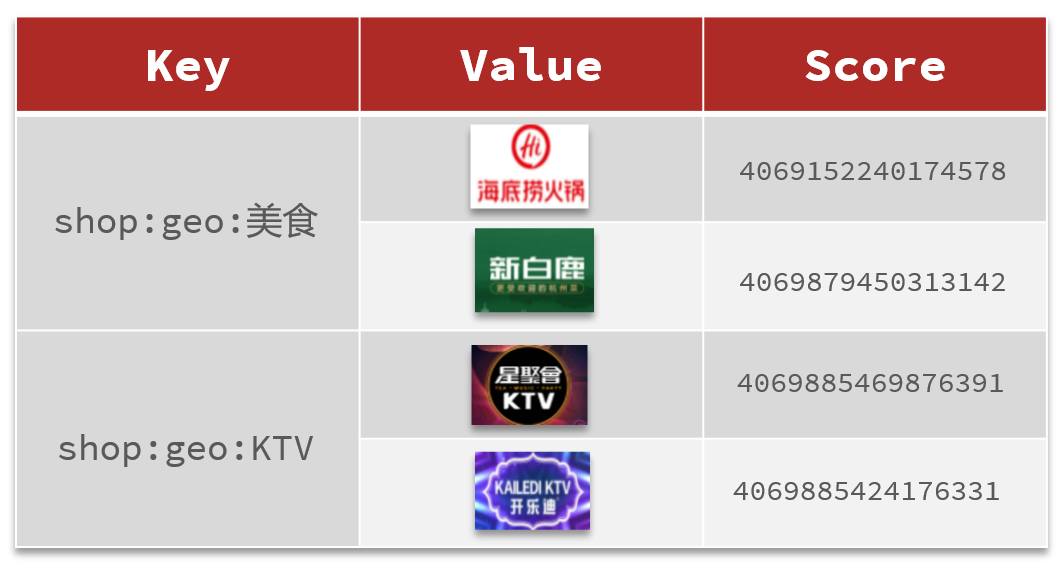
@Test public void addShop() {// 1.查询商户信息 List<Shop> shopList = shopService.query().list();// 2.按照商户的typeId进行分组 Map<Long, List<Shop>> shopMap = shopList .stream() .collect(Collectors.groupingBy(shop -> shop.getTypeId()));// 3.分批写入redis// 3.1Map.Entry里面包含getKey()和getValue()方法,该方法返回值就是这个map中各个键值对映射关系的集合。 for (Map.Entry<Long, List<Shop>> entry : shopMap.entrySet()) {// 3.2获取到类型id Long typeId = entry.getKey();// 3.2获取同类型店铺的集合 List<Shop> shops = entry.getValue();// 3.3写入redis GEOADD key 精度 维度 member for (Shop shop : shops) { stringRedisTemplate.opsForGeo() .add(SHOP_GEO_KEY + typeId, new Point(shop.getX(), shop.getY()), shop.getId().toString()); } } }
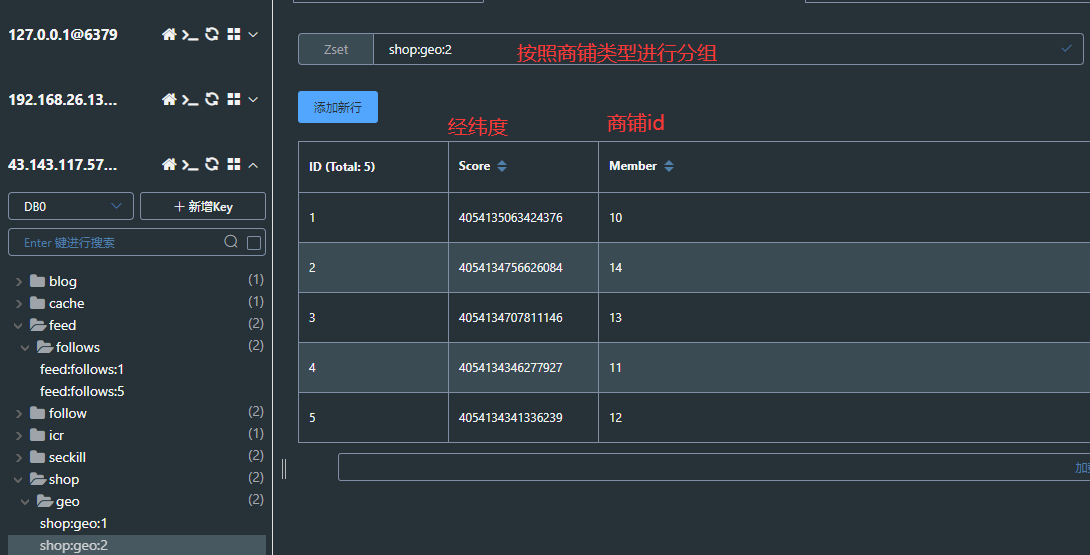
15.9.4搜索附近商户
因为GEO是在redis3.2版本加入的,所以对redis的依赖和lettuce连接池版本要求高。

进行排除,添加高版本的相关依赖
<!-- redis依赖--> <dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-redis</artifactId> <version>2.7.3</version> </dependency><!-- lettuce连接池--> <dependency> <groupId>io.lettuce</groupId> <artifactId>lettuce-core</artifactId> <version>6.1.9.RELEASE</version>
/** * 按照商户类型进行距离查询 * * @param typeId * @param current * @param x * @param y * @return */ @Override public Result queryShopByType(Integer typeId, Integer current, Double x, Double y) {// 1.判断是否需要根据坐标查询 if (x == null || y == null) { // 根据类型分页查询 Page<Shop> page = query() .eq("type_id", typeId) .page(new Page<>(current, SystemConstants.DEFAULT_PAGE_SIZE)); // 返回数据 return Result.ok(page.getRecords()); }// 2.计算分页参数 int start = (current - 1) * SystemConstants.DEFAULT_PAGE_SIZE; int end = current * SystemConstants.DEFAULT_PAGE_SIZE;// 3.查询redis、按照距离排序、分页。结果:shopId、distance GeoResults<RedisGeoCommands.GeoLocation<String>> results = stringRedisTemplate.opsForGeo() .search(SHOP_GEO_KEY + typeId, GeoReference.fromCoordinate(x, y), new Distance(5000), RedisGeoCommands. GeoSearchCommandArgs. newGeoSearchArgs(). includeDistance(). limit(end)); if (results == null){ return Result.ok(); } List<GeoResult<RedisGeoCommands.GeoLocation<String>>> list = results.getContent(); if (list.size() <= start){// 没有下一页,返回空 return Result.ok(); }// 4.截取start-end部分 List<Long> ids = new ArrayList<>(); Map<String,Distance> distanceMap = new HashMap<>(list.size()); list.stream().skip(start).forEach(result ->{// 获取商户id String shopIdStr = result.getContent().getName(); ids.add(Long.valueOf(shopIdStr));// 获取距离 Distance distance = result.getDistance(); distanceMap.put(shopIdStr,distance); });// 5.根据id查询Shop String idStr = StrUtil.join(",", ids); List<Shop> shops = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list(); for (Shop shop : shops) { shop.setDistance(distanceMap.get(shop.getId().toString()).getValue()); } return Result.ok(shops); }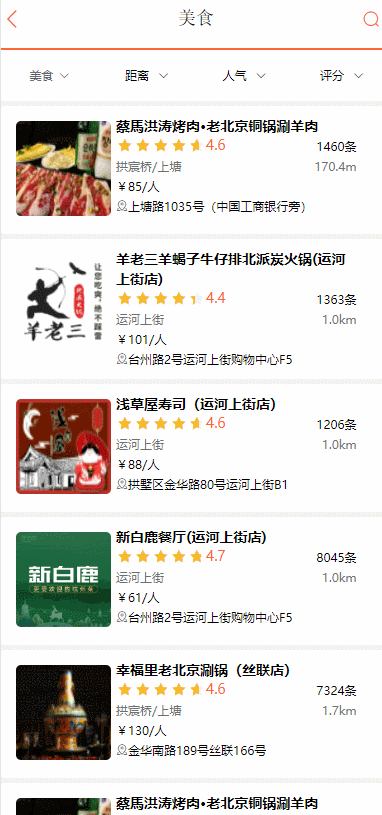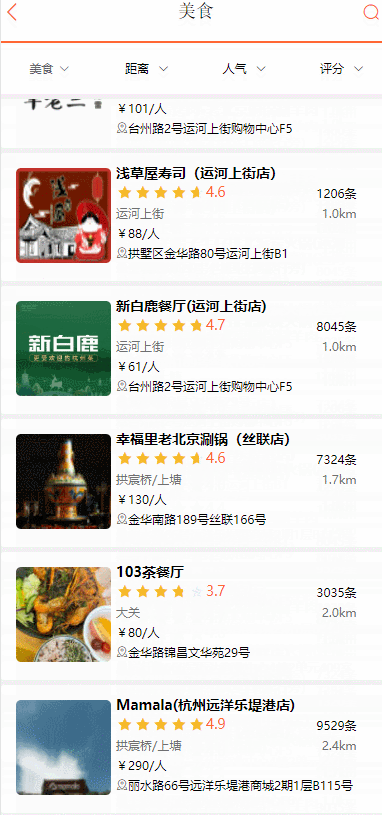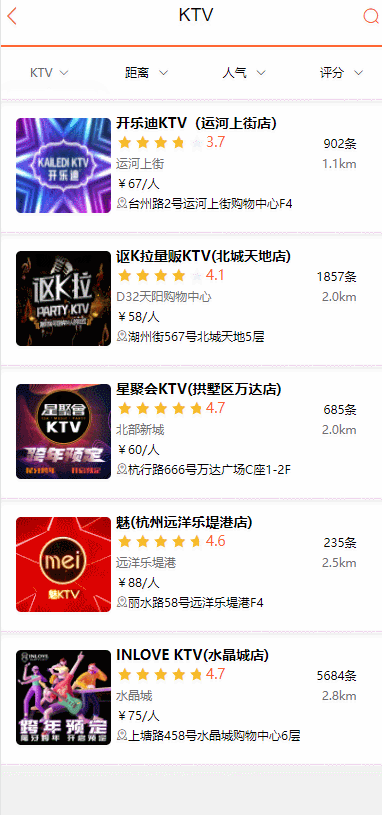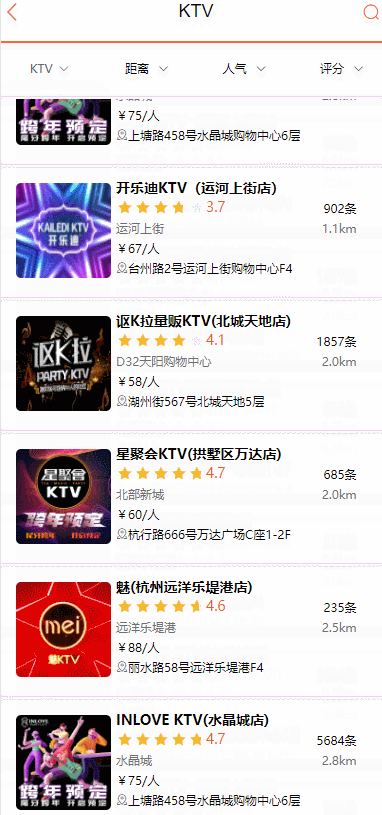
15.10用户签到
15.10.1BitMap的用法
假如我们用一张表来存储用户签到信息,其结构应该如下:
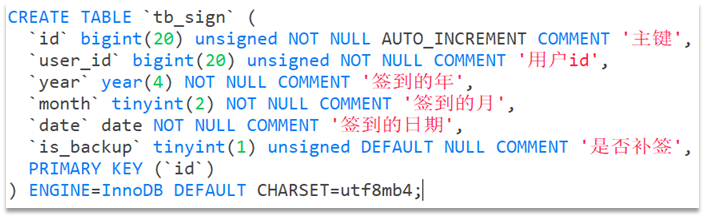
假如有1000万用户,平均每人每年签到次数为10次,则这张表一年的数据量为 1亿条
每签到一次需要使用(8 + 8 + 1 + 1 + 3 + 1)共22 字节的内存,一个月则最多需要600多字节
我们按月来统计用户签到信息,签到记录为1,未签到则记录为0.

Redis中是利用string类型数据结构实现BitMap**,**因此最大上限是512M,转换为bit则是 2^32个bit位。
BitMap的操作命令有:
SETBIT:向指定位置(offset)存入一个0或1
GETBIT :获取指定位置(offset)的bit值
BITCOUNT :统计BitMap中值为1的bit位的数量
BITFIELD :操作(查询、修改、自增)BitMap中bit数组中的指定位置(offset)的值
BITFIELD_RO :获取BitMap中bit数组,并以十进制形式返回
BITOP :将多个BitMap的结果做位运算(与 、或、异或)
BITPOS :查找bit数组中指定范围内第一个0或1出现的位置
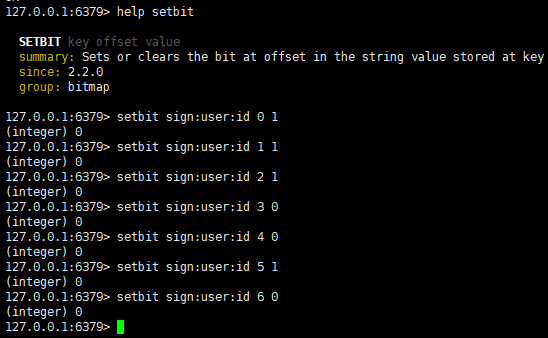
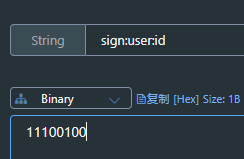
查询某一天的签到情况
使用BITFIELD命令查询指定位置的数值,返回的是十进制。
u表示是无符号(即正值),0表示从头开始查询
查询结果为7,即二进制111的十进制结果

15.10.2实现签到功能
需求:实现签到接口,将当前用户当天签到信息保存到Redis中
提示:因为BitMap底层是基于String数据结构,因此其操作也都封装在字符串相关操作中了。
/** * 用户签到 * @return */ public Result userSign() { // 1.获取当前用户 Long userId = UserHolder.getUser().getId();// 2.获取当前日期 LocalDateTime now = LocalDateTime.now(); String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));// 3.拼接key String key = SIGN_TIME_KEY + userId + keySuffix;// 4.获取当前是本月的第几天(offset) int dayOfMonth = now.getDayOfMonth();// 5.存入缓存 SETBIT key offset 0/1,因为setbit是从0开始的,所以这里要减1 stringRedisTemplate.opsForValue().setBit(key,dayOfMonth - 1,true); return Result.ok(); }测试签到接口,签到成功。
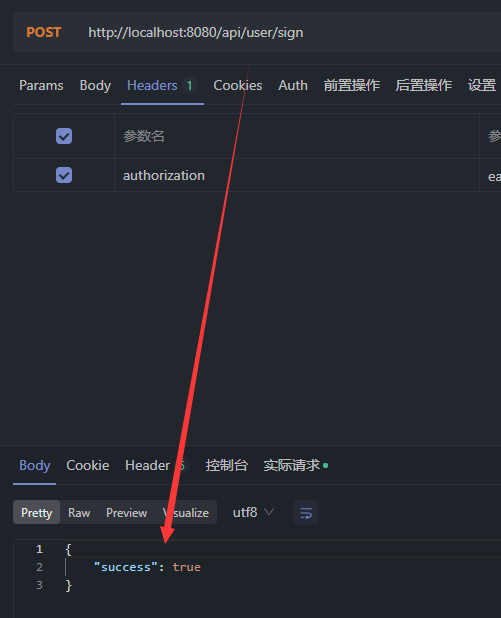
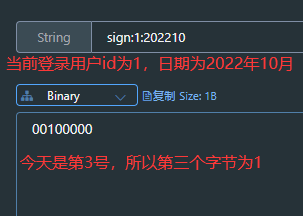
15.10.3统计连续签到
问题1:什么叫做连续签到天数?
从最后一次签到开始向前统计,直到遇到第一次未签到为止,计算总的签到次数,就是连续签到天数。
问题2:如何得到本月到今天为止的所有签到数据?
BITFIELD key GET u[dayOfMonth] 0
问题3:如何从后向前遍历每个bit位?
与 1 做与运算,就能得到最后一个bit位。
随后右移1位,下一个bit位就成为了最后一个bit位。
需求:实现下面接口,统计当前用户截止当前时间在本月的连续签到天数

/** * 统计用户的签到次数 * * @return */ @Override public Result signCount() {// 1.获取当前用户 Long userId = UserHolder.getUser().getId();// 2.获取当前日期 LocalDateTime now = LocalDateTime.now(); String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));// 3.拼接key String key = SIGN_TIME_KEY + userId + keySuffix;// 4.获取当前是本月的第几天(offset) int dayOfMonth = now.getDayOfMonth();// 5.获取到本月截止到今天为止所有的签到记录,返回的时一个十进制数 BITFIELD sign:1:202210 GET u3 0 List<Long> result = stringRedisTemplate.opsForValue().bitField( key, BitFieldSubCommands .create() .get(BitFieldSubCommands.BitFieldType.unsigned(dayOfMonth)).valueAt(0) ); if (result == null || result.isEmpty()) { return Result.ok(); } Long num = result.get(0); if (num == 0 || num == null) { return Result.ok(); }// 6.循环遍历 int count = 0; while (true) { if ((num & 1) == 0) {// 6.1为0未签到,循环结束 break; } else {// 6.2签到,计算器加1 count++; }// 6.3先右移一位,再赋值给num num >>>= 1; } return Result.ok(count); }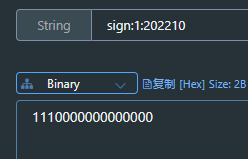
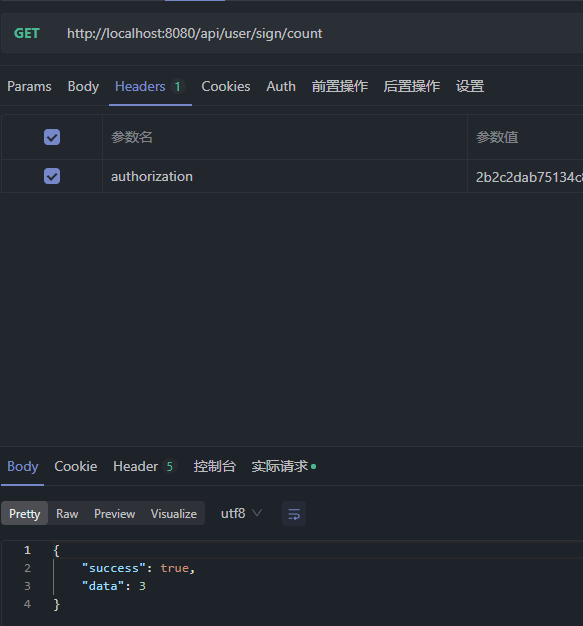
15.11UV统计
15.11.1HyperLogLog用法
UV:全称U**nique **Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。
PV:全称P**age **View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量。
UV统计在服务端做会比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存。但是如果每个访问的用户都保存到Redis中,数据量会非常恐怖。
Hyperloglog(HLL)是从Loglog算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值。Redis中的HLL是基于string结构实现的,单个HLL的内存永远小于16kb,内存占用低的令人发指!作为代价,其测量结果是概率性的,有小于0.81%的误差。不过对于UV统计来说,这完全可以忽略。
15.11.2实现UV统计
测试插入100万条数据
@Testvoid testHyperLogLog() { String[] values = new String[1000]; int j = 0; for (int i = 0; i < 1000000; i++) { j = i % 1000; values[j] = "user_" + i; if(j == 999){ // 发送到 Redis stringRedisTemplate.opsForHyperLogLog().add("hl2", values); } } // 统计数量 Long count = stringRedisTemplate.opsForHyperLogLog().size("hl2"); System.out.println("count = " + count);}
插入之前的内存大小
插入之后内存大小
2415512-2401128=14384
14384/1024约等于14kb,小于16kb
16.分布式缓存
16.1采用分布式缓存的原因
在前面的章节中都是使用redis的单节点部署,单点redis会出现很多问题。
数据丢失问题
Redis是内存存储,服务重启可能会丢失数据

并发能力问题
单节点Redis并发能力虽然不错,但也无法满足如618这样的高并发场景

故障恢复问题
如果Redis宕机,则服务不可用,需要一种自动的故障恢复手段

存储能力问题
Redis基于内存,单节点能存储的数据量难以满足海量数据需求

单点Redis出现的问题的解决方案如下:
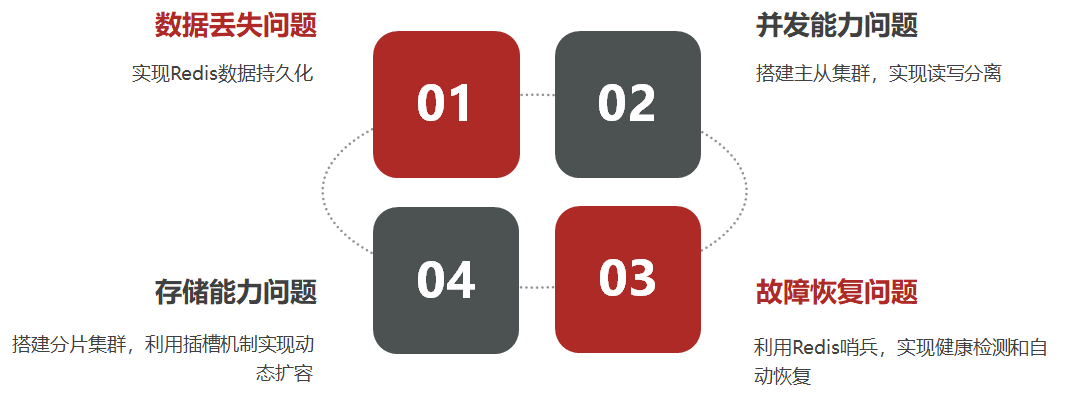
16.2Redis持久化
16.2.1RDB持久化
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
快照文件称为RDB文件,默认是保存在当前运行目录。


Redis停机时会执行一次RDB。

Redis内部有触发RDB的机制,可以在redis.conf文件中找到,格式如下:

RDB的其它配置也可以在redis.conf文件中设置:

采用vim编辑器进入redis.conf文件
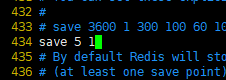
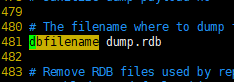
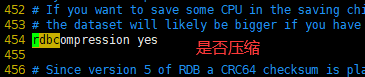

bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入 RDB 文件。
fork采用的是copy-on-write技术:
当主进程执行读操作时,访问共享内存;
当主进程执行写操作时,则会拷贝一份数据,执行写操作。
读时共享,写时复制
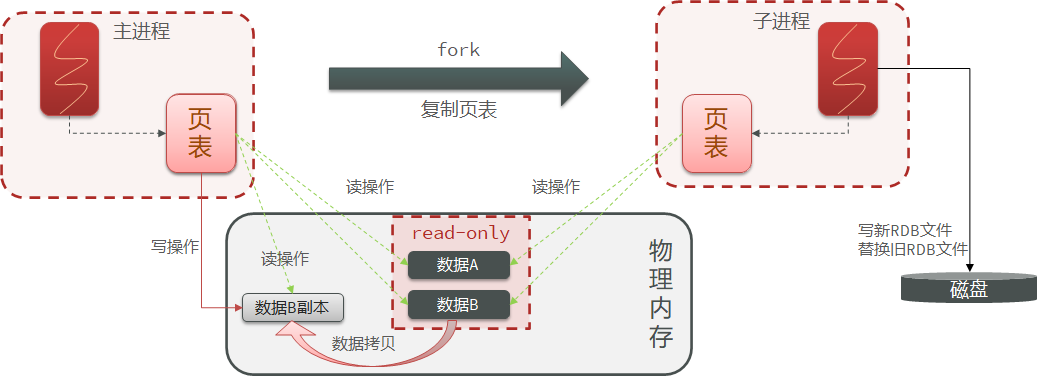
RDB方式bgsave的基本流程?
fork主进程得到一个子进程,共享内存空间
子进程读取内存数据并写入新的RDB文件
用新RDB文件替换旧的RDB文件。
RDB会在什么时候执行?save 60 1000代表什么含义?
默认是服务停止时。
代表60秒内至少执行1000次修改则触发RDB
RDB的缺点?
RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险
fork子进程、压缩、写出RDB文件都比较耗时
16.2.2AOF持久化
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。
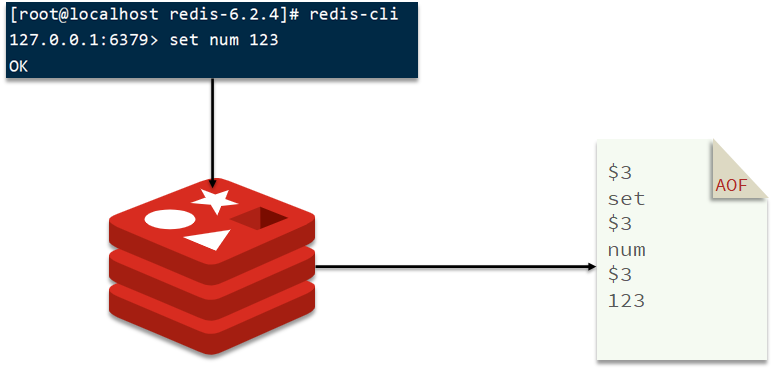
AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:

AOF的命令记录的频率也可以通过redis.conf文件来配:

| 配置项 | 刷盘时机 | 优点 | 缺点 |
|---|---|---|---|
| Always | 同步刷盘 | 可靠性高,几乎不丢数据 | 性能影响大 |
| everysec | 每秒刷盘 | 性能适中 | 最多丢失1秒数据 |
| no | 操作系统控制 | 性能最好 | 可靠性较差,可能丢失大量数据 |
为了验证AOF能否实现持久化的效果,首先禁用RDB

开启AOF
设置刷盘方式为每秒钟1次
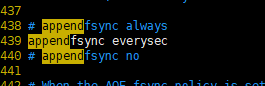
测试:
存储一条数据
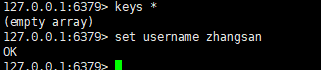
在redis目录下生成了aof文件

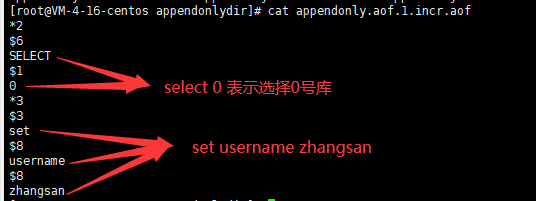
在存储一条数据

查看aof文件
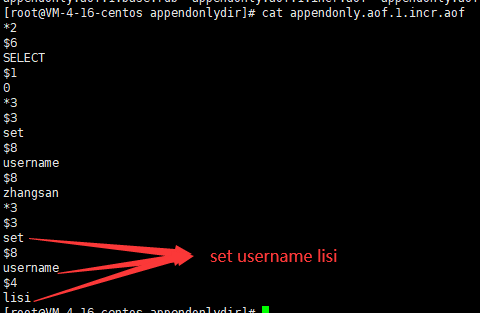
测试关闭redis服务

再次启动redis服务

数据依然存在
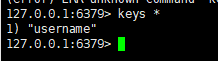
AOF文件存在的问题
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。

查看当前aof文件
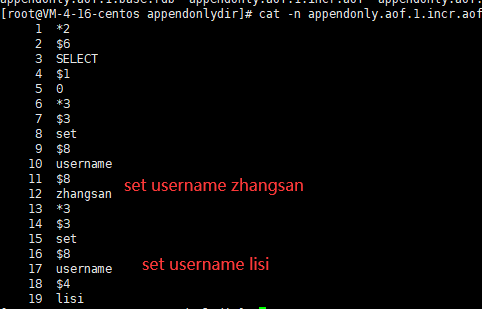
使用bgrewriteaof命令进行aof文件重写操作
bgrewriteaof
重启服务数据依旧存在
Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置:

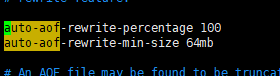
16.2.3RDB持久化和AOF持久化比较
RDB和AOF各有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用。
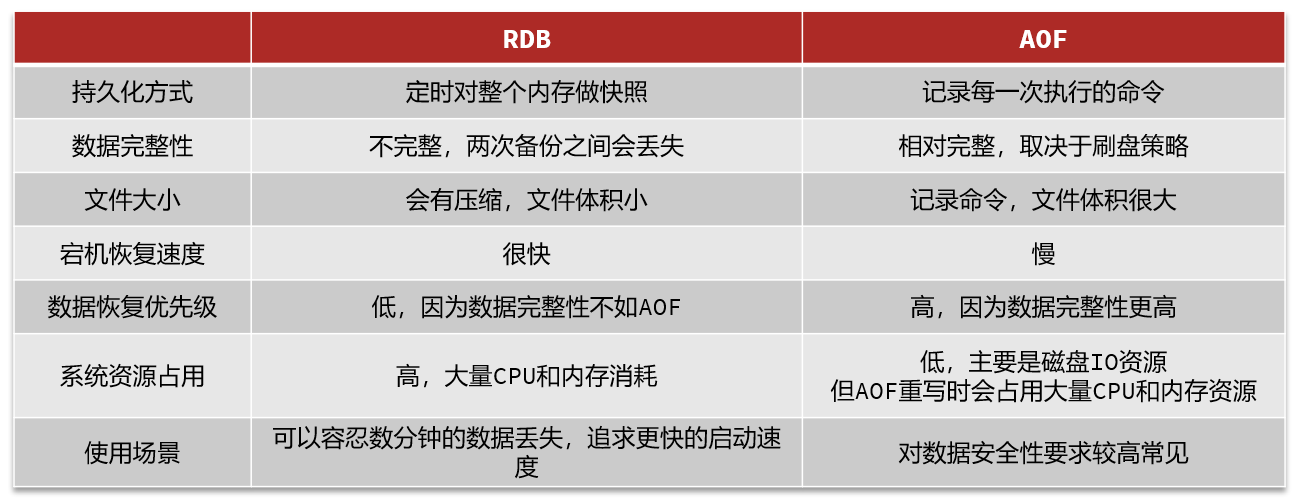
16.3Redis主从
16.3.1主从复制简介
主从复制,简单来说就是主机数据更新后根据配置和策略, 自动同步到从机的master/slaver机制,Master以写为主,Slave以读为主。
主节点承担写操作,并将数据同步到多个从节点上,实现数据同步。
多个从节点承担读操作,提高读操作的并发能力。
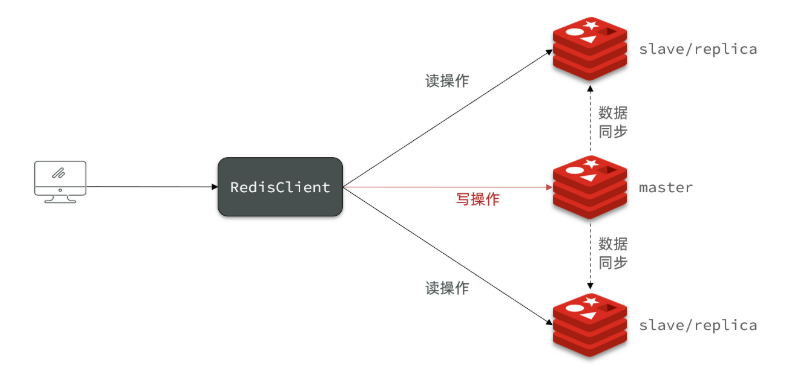
16.3.2主从集群搭建
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。
将redis.conf文件内容恢复到初始状态,并创建三个文件,将redis的配置文件redis.conf复制到这三个文件夹当中。
修改各个配置文件当中redis服务的端口号和修改数据保存目录(原始是dir。表示当前目录)
sed -i -e 's/6379/7001/g' -e 's/dir .\//dir \/opt\/7001\//g' 7001/redis.confsed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/opt\/7002\//g' 7002/redis.confsed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/opt\/7003\//g' 7003/redis.conf
修改每个实例的声明IP
虚拟机本身有多个IP,为了避免将来混乱,我们需要在redis.conf文件中指定每一个实例的绑定ip信息,格式如下:
redis实例的声明 IP
replica-announce-ip 192.168.150.101
每个目录都要改,我们一键完成修改(在/opt目录执行下列命令):
# 逐一执行sed -i '1a replica-announce-ip 192.168.150.101' 7001/redis.confsed -i '1a replica-announce-ip 192.168.150.101' 7002/redis.confsed -i '1a replica-announce-ip 192.168.150.101' 7003/redis.conf# 或者一键修改printf '%s\n' 7001 7002 7003 | xargs -I{} -t sed -i '1a replica-announce-ip 192.168.150.101' {}/redis.conf
启动
为了方便查看日志,我们打开3个ssh窗口,分别启动3个redis实例,启动命令:
# 第1个redis-server 7001/redis.conf# 第2个redis-server 7002/redis.conf# 第3个redis-server 7003/redis.conf
在新建的三个实例中同时开启redis服务
16.3.3开启主从关系
现在三个实例还没有任何关系,要配置主从可以使用replicaof 或者slaveof(5.0以前)命令。
有临时和永久两种模式:
修改配置文件(永久生效)
在redis.conf中添加一行配置:slaveof <masterip> <masterport> 使用redis-cli客户端连接到redis服务,执行slaveof命令(重启后失效):
slaveof <masterip> <masterport>设置将7001作为主节点,7002和7003做为从节点。
关闭主节点保护模式,不关闭从节点连接不上主节点
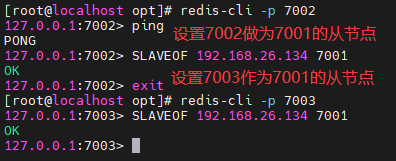
从节点7002、7003日志信息改变
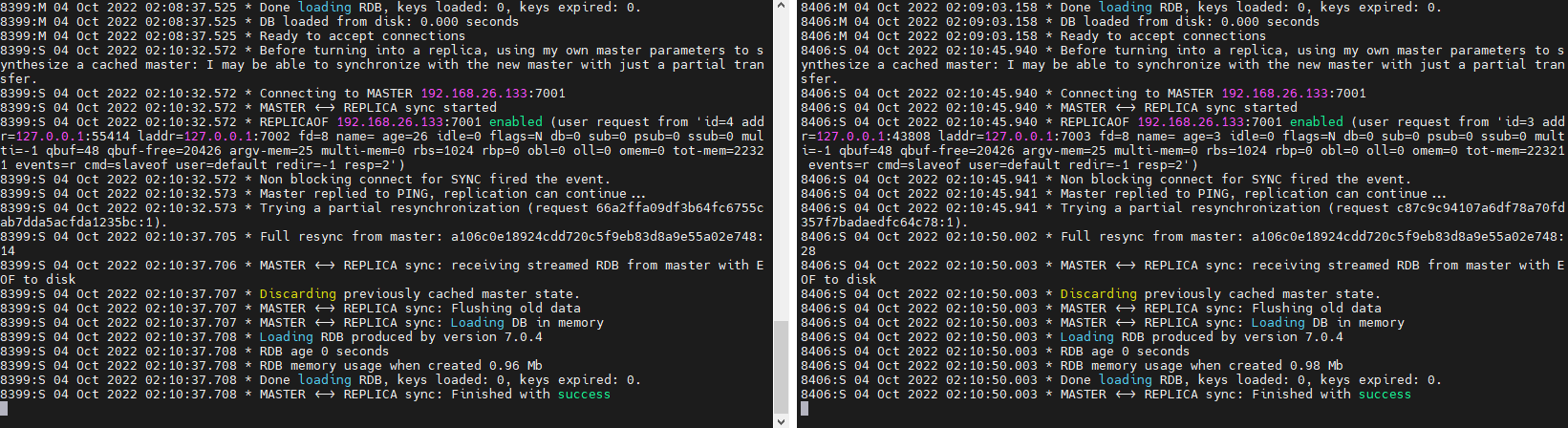
在主节点下查看主从架构状态信息
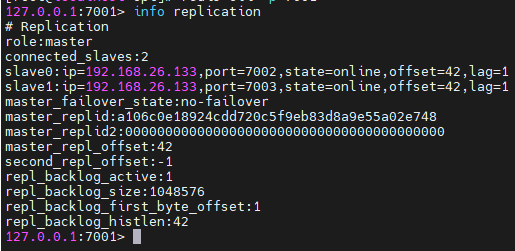
可以发现7001为主节点,旗下有两个从节点,端口号分别是7002、7003
16.3.4测试主从读写
在主节点上进行读写测试
在从节点进行读写操作

16.3.5主从数据同步原理
16.3.5.1全量同步
主从第一次同步是全量同步:

master如何判断slave是不是第一次来同步数据?这里会用到两个很重要的概念:
•Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
•offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
因此slave做数据同步,必须向master声明自己的replication id 和offset,master才可以判断到底需要同步哪些数据
全量同步的流程
slave节点请求增量同步
master节点判断replid,发现不一致,拒绝增量同步
master将完整内存数据生成RDB,发送RDB到slave
slave清空本地数据,加载master的RDB
master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
slave执行接收到的命令,保持与master之间的同步
16.3.5.2增量同步
主从第一次同步是全量同步,但如果slave重启后同步,则执行增量同步
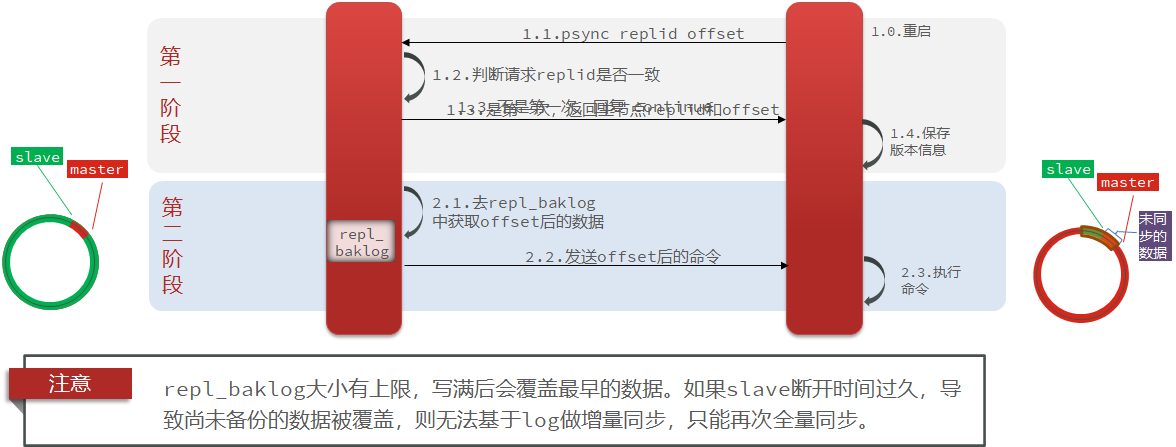
16.3.5.3从主优化
在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。
Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
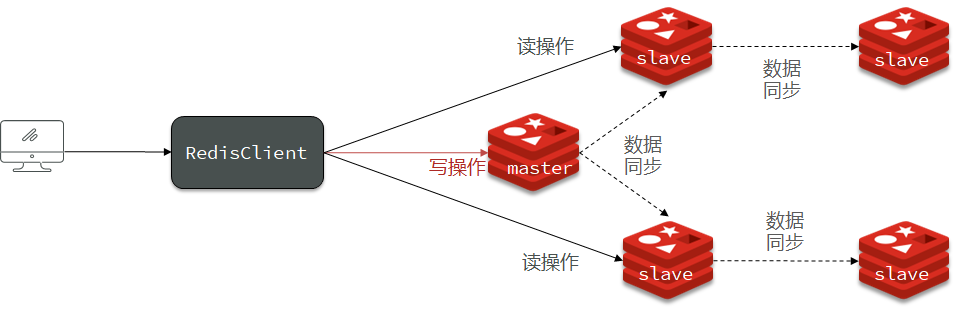
16.3.5.4全量同步和增量同步的区别
简述全量同步和增量同步区别?
全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave。
增量同步:slave提交自己的offset到master,master获取repl_baklog中从offset之后的命令给slave
什么时候执行全量同步?
slave节点第一次连接master节点时
slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
什么时候执行增量同步?
slave节点断开又恢复,并且在repl_baklog中能找到offset时16.4Redis哨兵
slave节点宕机恢复后可以找master节点同步数据,那master节点宕机怎么办?Redis中的哨兵机制可以解决这个问题
16.4.1哨兵的作用
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。哨兵的结构和作用如下:
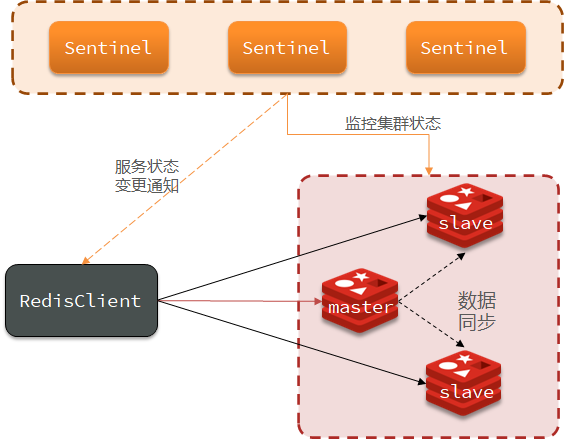
作用:
监控:Sentinel 会不断检查您的master和slave是否按预期工作
自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主
通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端
16.4.2哨兵的工作原理
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
主观下线:如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。
quorum值最好超过Sentinel实例数量的一半。
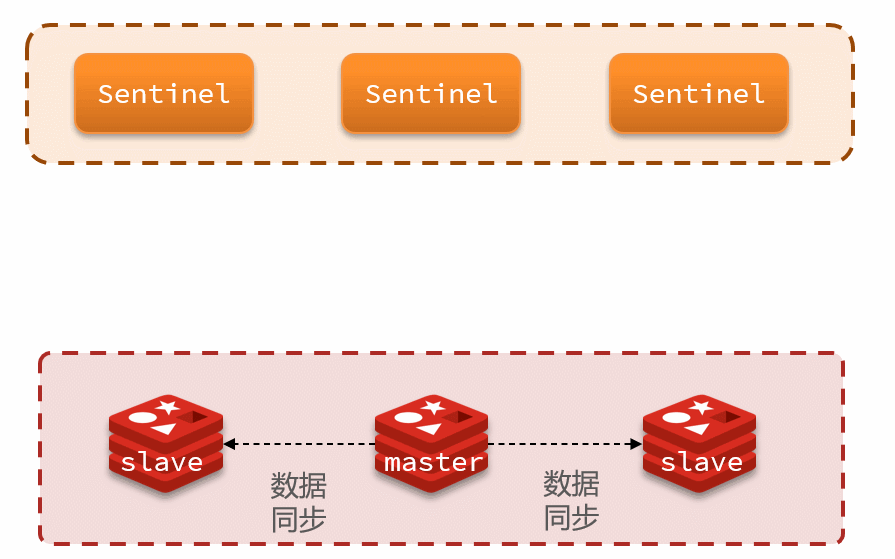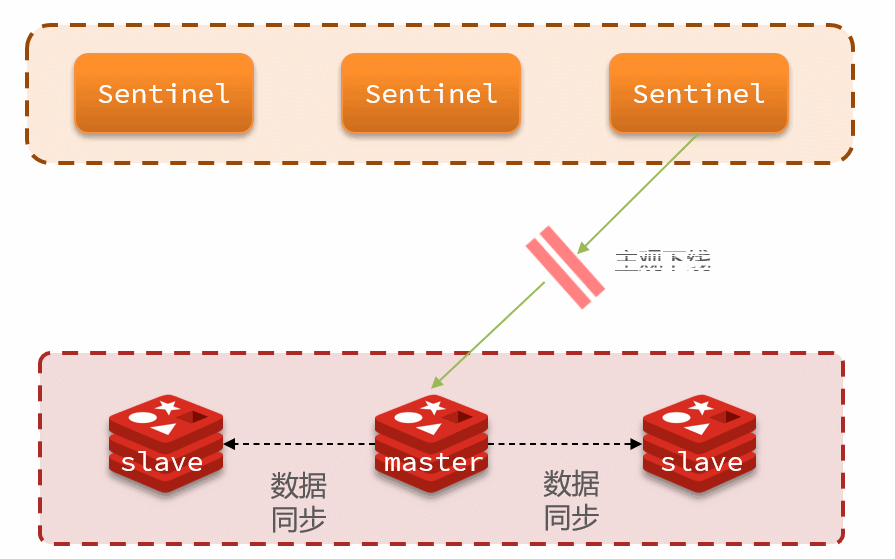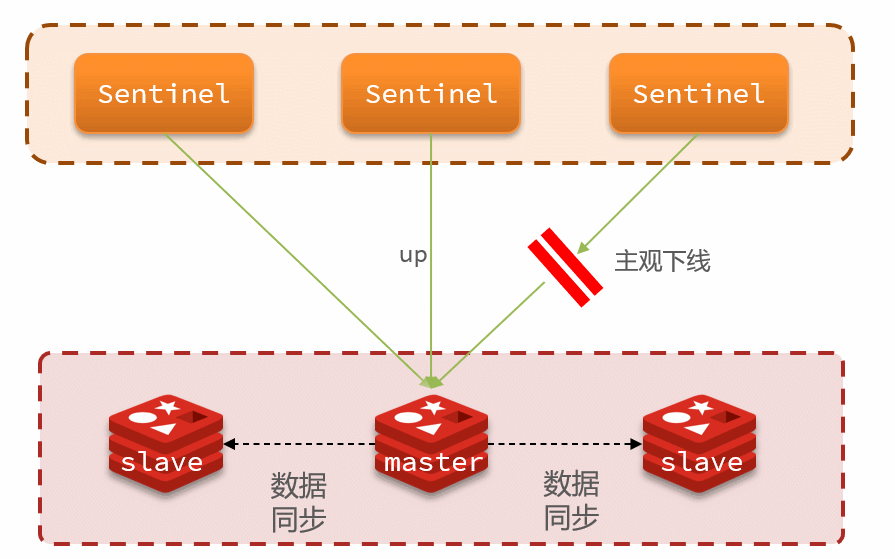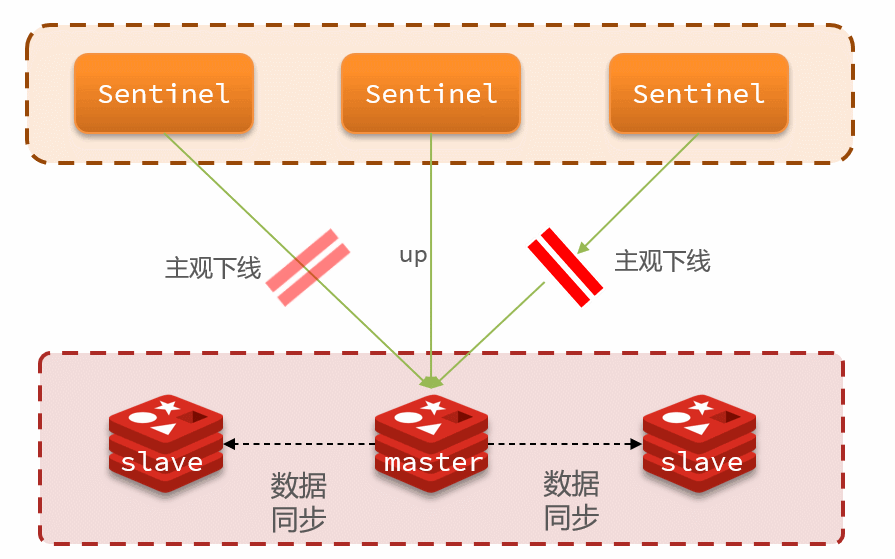
16.4.3主节点的选取方式
判定主节点下线后哨兵会从从节点中选取一个新的节点作为主节点
首先会判断slave节点与master节点断开时间长短,如果超过指定值(down-after-milliseconds * 10)则会排除该slave节点
然后判断slave节点的slave-priority值,越小优先级越高,如果是0则永不参与选举(默认都一样)
如果slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高
最后是判断slave节点的运行id大小,越小优先级越高。
16.4.4故障转移
当选中了其中一个slave为新的master后(例如slave1),故障的转移的步骤如下
sentinel给备选的slave1节点发送slaveof no one命令,让该节点成为master
sentinel给所有其它slave发送slaveof 192.168.150.101 7002 命令,让这些slave成为新master的从节点,开始从新的master上同步数据。
最后,sentinel将故障节点标记为slave,当故障节点恢复后会自动成为新的master的slave节点
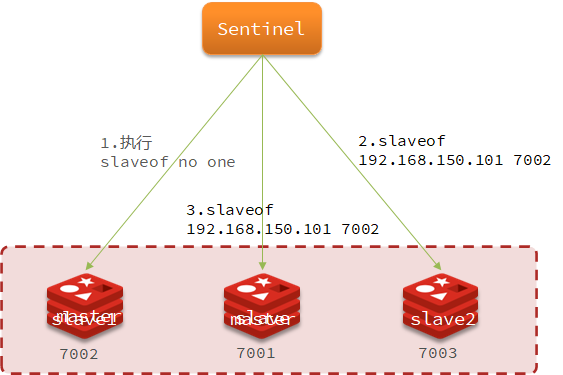
总结:
Sentinel的三个作用是什么?
监控
故障转移
通知
Sentinel如何判断一个redis实例是否健康?
每隔1秒发送一次ping命令,如果超过一定时间没有相向则认为是主观下线
如果大多数sentinel都认为实例主观下线,则判定服务客观下线
故障转移步骤有哪些?
首先选定一个slave作为新的master,执行slaveof no one
然后让所有节点都执行slaveof 新master
修改故障节点,执行slaveof 新master
16.4.5搭建哨兵集群
这里我们搭建一个三节点形成的Sentinel集群,来监管之前的Redis主从集群。如图:
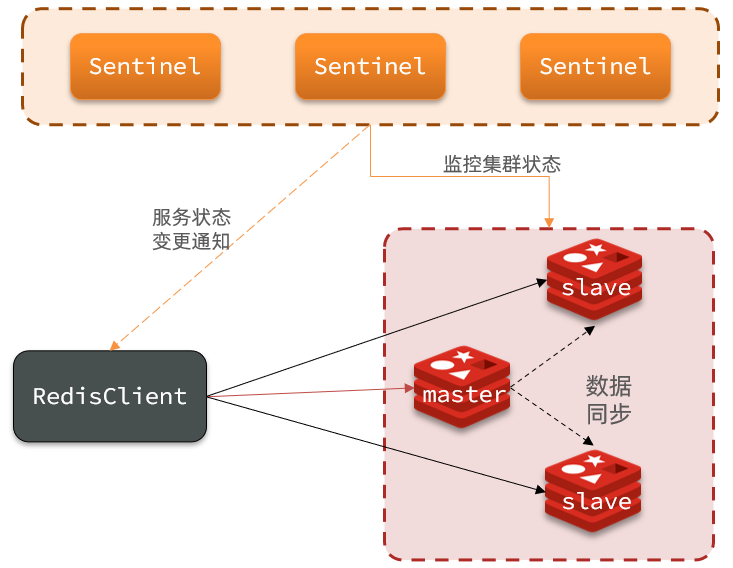
三个sentinel实例信息如下:
| 节点 | IP | PORT |
|---|---|---|
| s1 | 192.168.26.133 | 27001 |
| s2 | 192.168.26.133 | 27002 |
| s3 | 192.168.26.133 | 27003 |
要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。
我们创建三个文件夹,名字分别叫s1、s2、s3:
然后我们在s1目录创建一个sentinel.conf文件,添加下面的内容:
port 27001sentinel announce-ip 192.168.26.133sentinel monitor mymaster 192.168.26.133 7001 2sentinel down-after-milliseconds mymaster 5000sentinel failover-timeout mymaster 60000#主节点密码#sentinel auth-pass <master-name> <password>sentinel auth-pass mymaster 主节点密码dir "/opt/s1"解读:
port 27001:是当前sentinel实例的端口
sentinel monitor mymaster 192.168.26.133 7001 2:指定主节点信息
mymaster:主节点名称,自定义,任意写192.168.26.133 7001:主节点的ip和端口2:选举master时的quorum值 
然后将s1/sentinel.conf文件拷贝到s2、s3两个目录中(在/opt目录执行下列命令):
# 方式一:逐个拷贝cp s1/sentinel.conf s2cp s1/sentinel.conf s3# 方式二:管道组合命令,一键拷贝echo s2 s3 | xargs -t -n 1 cp s1/sentinel.conf修改s2、s3两个文件夹内的配置文件,将端口分别修改为27002、27003:
sed -i -e 's/27001/27002/g' -e 's/s1/s2/g' s2/sentinel.confsed -i -e 's/27001/27003/g' -e 's/s1/s3/g' s3/sentinel.conf
启动哨兵集群
为了方便查看日志,我们打开3个ssh窗口,分别启动3个redis实例,启动命令:
# 第1个redis-sentinel s1/sentinel.conf# 第2个redis-sentinel s2/sentinel.conf# 第3个redis-sentinel s3/sentinel.conf
开始监控主从集群

测试:
尝试让master节点7001宕机,查看sentinel日志:
主节点停机之后,从节点连接失败

主节点宕机后,哨兵集群会选出最先发现主节点宕机的哨兵作为leader在slave中选出新的主节点
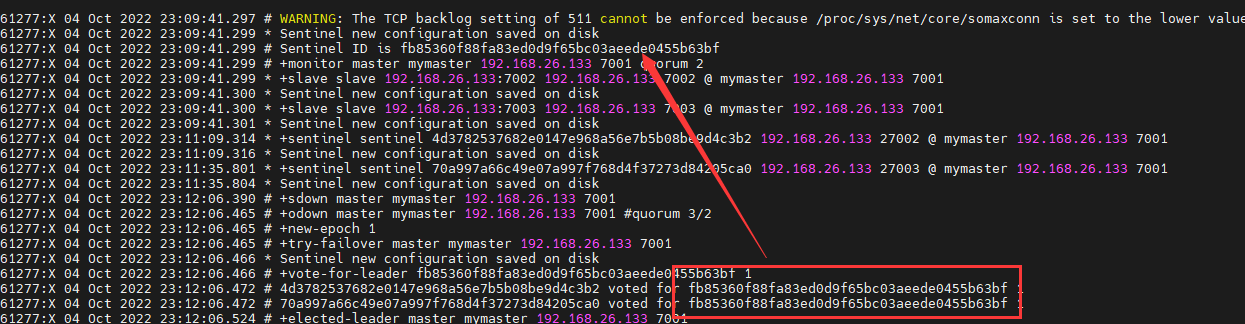
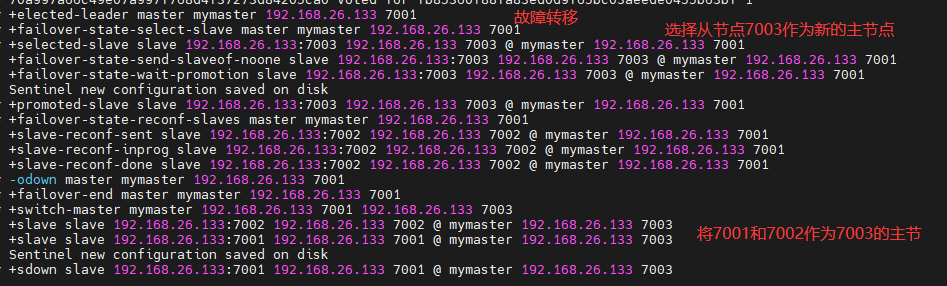
7003的主模式启用

恢复7001从节点
7001从节点读取RDB文件进行全量同步
7003主节点开始同步7001从节点
在7003查看主从架构信息
7003为主节点,7001和7002是他的从节点
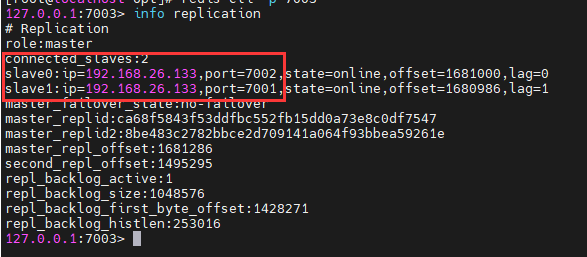
16.4.6RedisTemplate连接哨兵集群
首先关闭虚拟机防火墙,并重启redis和sentinel
在Sentinel集群监管下的Redis主从集群,其节点会因为自动故障转移而发生变化,Redis的客户端必须感知这种变化,及时更新连接信息。Spring的RedisTemplate底层利用lettuce实现了节点的感知和自动切换。
一:在pom文件当中添加SpringBoot对Redis的开发场景
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>二:在SpringBoot配置文件当中指定sentinel(哨兵)的信息
spring: redis: sentinel: master: mymaster #指定主节点名称 nodes: # 指定redis-sentinel集群信息 - 192.168.26.133:27001 - 192.168.26.133:27002 - 192.168.26.133:27003三:配置Redis主从读写分离(可以在配置文件当中或主类当中配置)
@Bean public LettuceClientConfigurationBuilderCustomizer configurationBuilderCustomizer(){ return clientConfigurationBuilder -> clientConfigurationBuilder .readFrom(ReadFrom.REPLICA_PREFERRED); }这里的ReadFrom是配置Redis的读取策略,是一个枚举,包括下面选择:
MASTER:从主节点读取
MASTER_PREFERRED:优先从master节点读取,master不可用才读取replica
REPLICA:从slave(replica)节点读取
REPLICA _PREFERRED:优先从slave(replica)节点读取,所有的slave都不可用才读取master
项目结构:
控制器:
@RestControllerpublic class HelloController { @Autowired private StringRedisTemplate redisTemplate; @GetMapping("/get/{key}") public String hi(@PathVariable String key) { return redisTemplate.opsForValue().get(key); } @GetMapping("/set/{key}/{value}") public String hi(@PathVariable String key, @PathVariable String value) { redisTemplate.opsForValue().set(key, value); return "success"; }}启动项目,测试接口。


读操作:
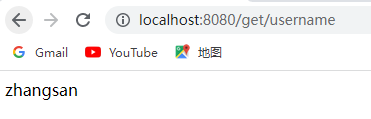
写操作是在主节点7002完成的

写操作:
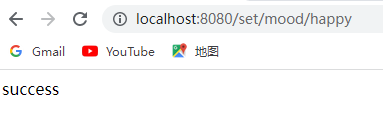
写操作是在主节点7001完成的

16.4.7测试lettuce的节点感知和自动切换
使主节点宕机,让哨兵集群选出新的主节点
主节点变为7003
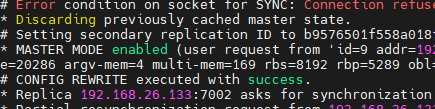
执行写操作,查看控制台

16.5Redis分片集群
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
海量数据存储问题
高并发写的问题
使用分片集群可以解决上述问题,分片集群特征:
集群中有多个master,每个master保存不同数据
每个master都可以有多个slave节点
master之间通过ping监测彼此健康状态
客户端请求可以访问集群任意节点,最终都会被转发到正确节点
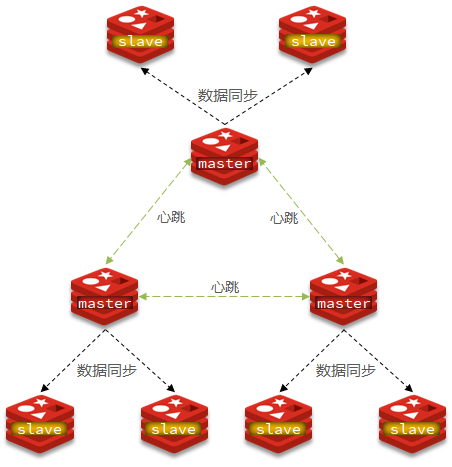
16.5.1搭建分片集群
分片集群需要的节点数量较多,这里我们搭建一个最小的分片集群,包含3个master节点,每个master包含一个slave节点,结构如下:
这里我们会在同一台虚拟机中开启6个redis实例,模拟分片集群,信息如下:
| IP | PORT | 角色 |
|---|---|---|
| 192.168.26.133 | 7001 | master |
| 192.168.26.133 | 7002 | master |
| 192.168.26.133 | 7003 | master |
| 192.168.26.133 | 8001 | slave |
| 192.168.26.133 | 8002 | slave |
| 192.168.26.133 | 8003 | slave |
删除搭建主从集群的文件夹,重新创建文件
# 进入/opt目录cd /opt# 删除旧的,避免配置干扰rm -rf 7001 7002 7003# 创建目录mkdir 7001 7002 7003 8001 8002 8003在7001下准备一个新的redis.conf文件,内容如下:
port 6379# 开启集群功能cluster-enabled yes# 集群的配置文件名称,不需要我们创建,由redis自己维护cluster-config-file /tmp/6379/nodes.conf# 节点心跳失败的超时时间cluster-node-timeout 5000# 持久化文件存放目录dir /opt/6379# 绑定地址bind 0.0.0.0# 让redis后台运行daemonize yes# 注册的实例ipreplica-announce-ip ip地址# 保护模式protected-mode no# 数据库数量databases 1# 日志logfile /opt/6379/run.log将这个文件拷贝到其他几个文件下:
修改每个redis.conf中的端口信息
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t sed -i 's/6379/{}/g' {}/redis.conf
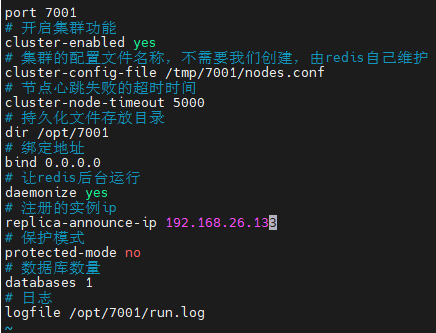
启动所有redis服务
# 一键启动所有服务 printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-server {}/redis.conf
虽然服务启动了,但是目前每个服务之间都是独立的,没有任何关联。
我们需要执行命令来创建集群,在Redis5.0之前创建集群比较麻烦,5.0之后集群管理命令都集成到了redis-cli中。
我们使用的是Redis5.0以上的版本,集群管理以及集成到了redis-cli中,格式如下:
redis-cli --cluster create --cluster-replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:8003命令说明:
redis-cli --cluster或者./redis-trib.rb:代表集群操作命令create:代表是创建集群--replicas 1或者--cluster-replicas 1 :指定集群中每个master的副本个数为1,此时节点总数 ÷ (replicas + 1) 得到的就是master的数量。因此节点列表中的前n个就是master,其它节点都是slave节点,随机分配到不同master 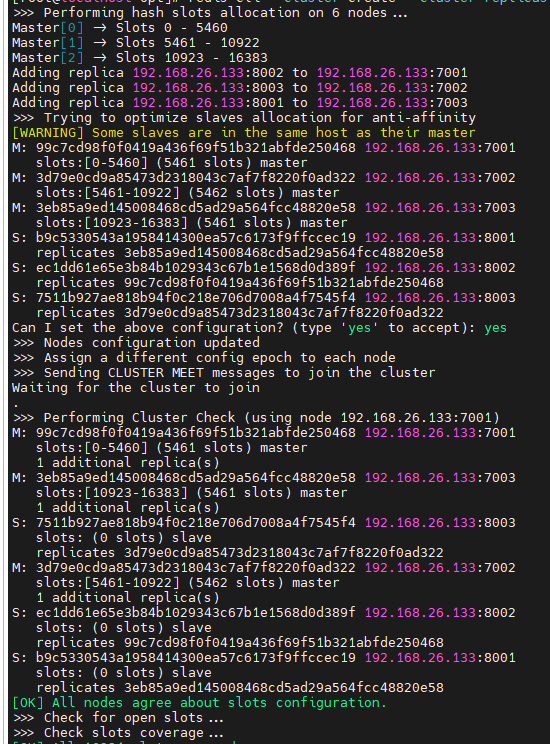
查看集群状态
redis-cli -p 7001 cluster nodes
16.5.2散列插槽
在创建分片集群的时候,每一个主节点后都有slots,这是散列插槽
Redis会把每一个master节点映射到0~16383共16384个插槽(hash slot)上,查看集群信息时就能看到:
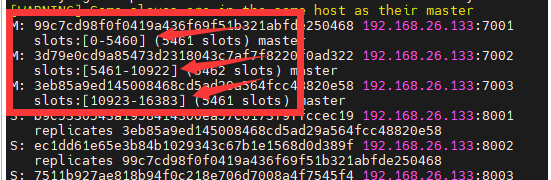
由上图可以看出:
主节点7001分配的插槽范围是[0-5460]
主节点7002分配的插槽范围是[5461-10922]
主节点7003分配的插槽范围是[10923-16383]
数据key不是与节点绑定,而是与插槽绑定。redis会根据key的有效部分计算插槽值,分两种情况:
key中包含"{}",且“{}”中至少包含1个字符,“{}”中的部分是有效部分
key中不包含“{}”,整个key都是有效部分
例如:key是num,那么就根据num计算,如果是{itcast}num,则根据itcast计算。计算方式是利用CRC16算法得到一个hash值,然后对16384取余,得到的结果就是slot值。
测试插槽:
redis-cli -p 端口号可以查看存入值后插槽位置是14315,属于主节点7003,则将客户端切换到7003

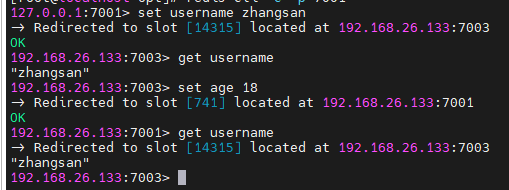
总结:
Redis如何判断某个key应该在哪个实例?
将16384个插槽分配到不同的实例
根据key的有效部分计算哈希值,对16384取余
余数作为插槽,寻找插槽所在实例即可
如何将同一类数据固定的保存在同一个Redis实例?
这一类数据使用相同的有效部分,例如key都以{typeId}为前缀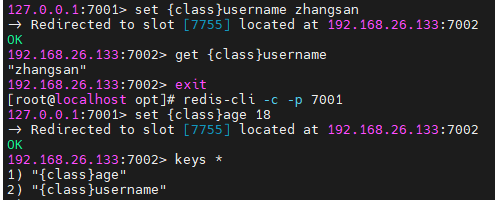
16.5.3集群伸缩
redis-cli --cluster提供了很多操作集群的命令,可以通过下面方式查看
向集群中添加一个新的master节点,并向其中存储 num = 10
需求:
启动一个新的redis实例,端口为7004
添加7004到之前的集群,并作为一个master节点
给7004节点分配插槽,使得num这个key可以存储到7004实例

修改复制后的配置文件端口,再启动7004文件中的redis服务
后面指定已经存在的集群节点
redis-cli --cluster add-node 192.168.26.133:7004 192.168.26.133:7001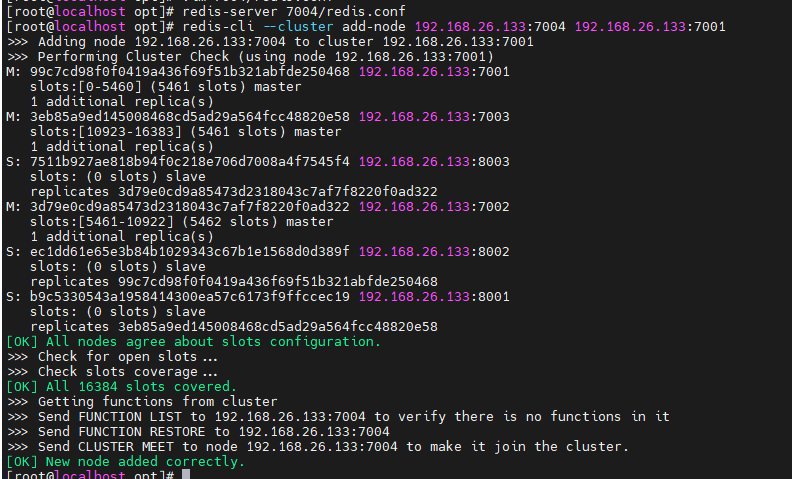
查看集群状态
redis-cli -p 7001 cluster nodes但是新创建的节点没有查询

向新的节点分配插槽
根据命名查看帮助文档
redis-cli --cluster help 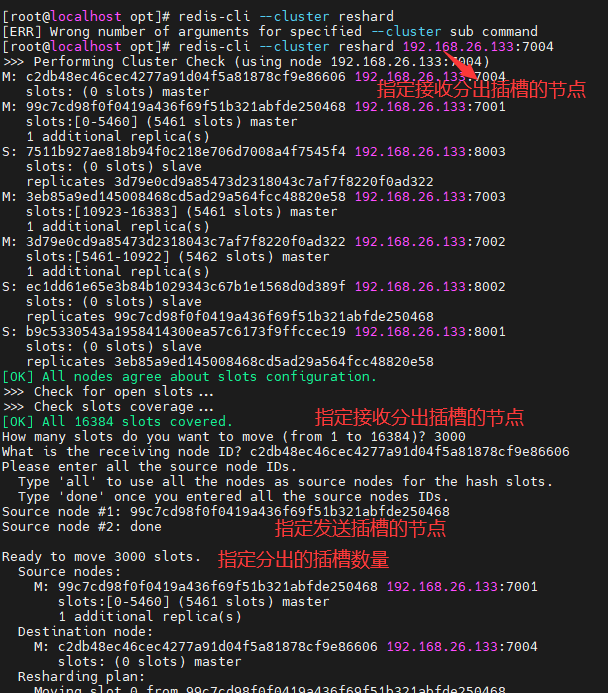

删除节点
首先将节点的插槽转移
删除节点
redis-cli --cluster del-node ip:端口 分支id
删除成功

16.5.4故障转移
采用watch的方式监控分片集群
watch redis-cli -p 7001 cluster nodes
测试将7002宕机

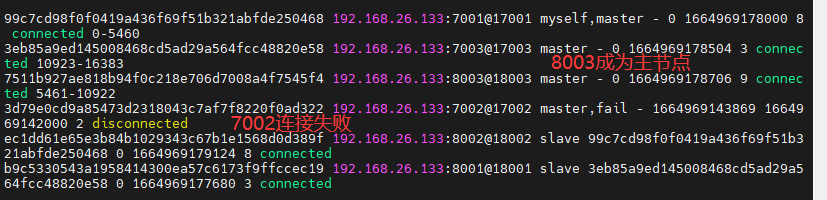
重启7002的redis服务
edis-server 7002/redis.conf
16.5.5数据迁移
利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令的这个slave节点,实现无感知的数据迁移。其流程如下:
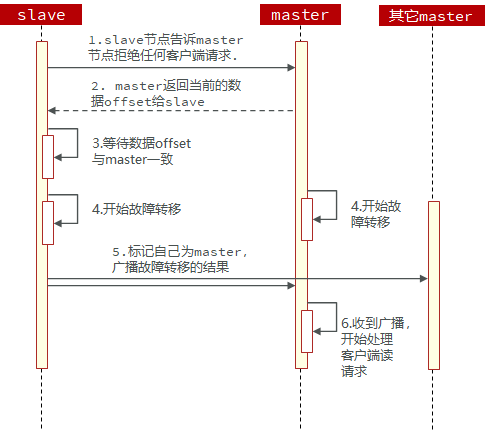
测试:将刚刚成为slave节点的7002变为master
利用redis-cli连接7002这个节点
执行cluster failover命令
查看集群状态信息

16.5.6RedisTemplate连接分片集群
首先关闭虚拟机防火墙,并重启redis和sentinel
RedisTemplate底层同样基于lettuce实现了分片集群的支持,而使用的步骤与哨兵模式基本一致:
引入redis的starter依赖
配置分片集群地址
配置读写分离
与哨兵模式相比,其中只有分片集群的配置方式略有差异,如下:
spring: redis: cluster: nodes: - 192.168.26.133:7001 - 192.168.26.133:7002 - 192.168.26.133:7003 - 192.168.26.133:8001 - 192.168.26.133:8002 - 192.168.26.133:8003测试接口:

查看控制台,读操作操作7002的从节点8003
写操作操作7002主节点
17.多级缓存
传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库,存在下面的问题:
请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈
Redis缓存失效时,会对数据库产生冲击
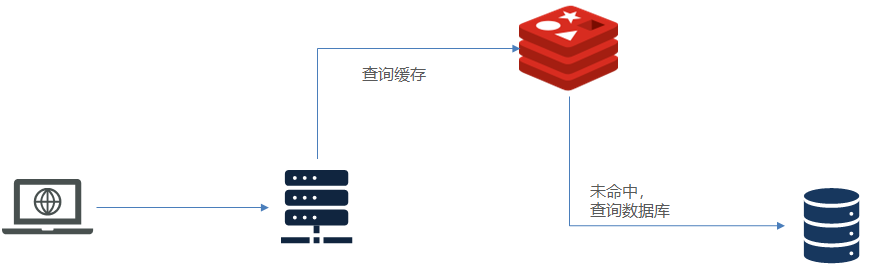
多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能:
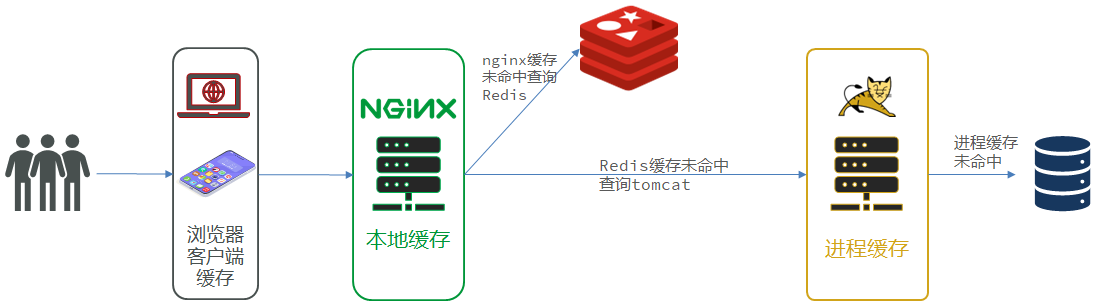
浏览器访问静态资源时,优先读取浏览器本地缓存
访问非静态资源(ajax查询数据)时,访问服务端
请求到达Nginx后,优先读取Nginx本地缓存
如果Nginx本地缓存未命中,则去直接查询Redis(不经过Tomcat)
如果Redis查询未命中,则查询Tomcat
请求进入Tomcat后,优先查询JVM进程缓存
如果JVM进程缓存未命中,则查询数据库
在多级缓存架构中,Nginx内部需要编写本地缓存查询、Redis查询、Tomcat查询的业务逻辑,因此这样的nginx服务不再是一个反向代理服务器,而是一个编写业务的Web服务器了。
因此这样的业务Nginx服务也需要搭建集群来提高并发,再有专门的nginx服务来做反向代理,如图:
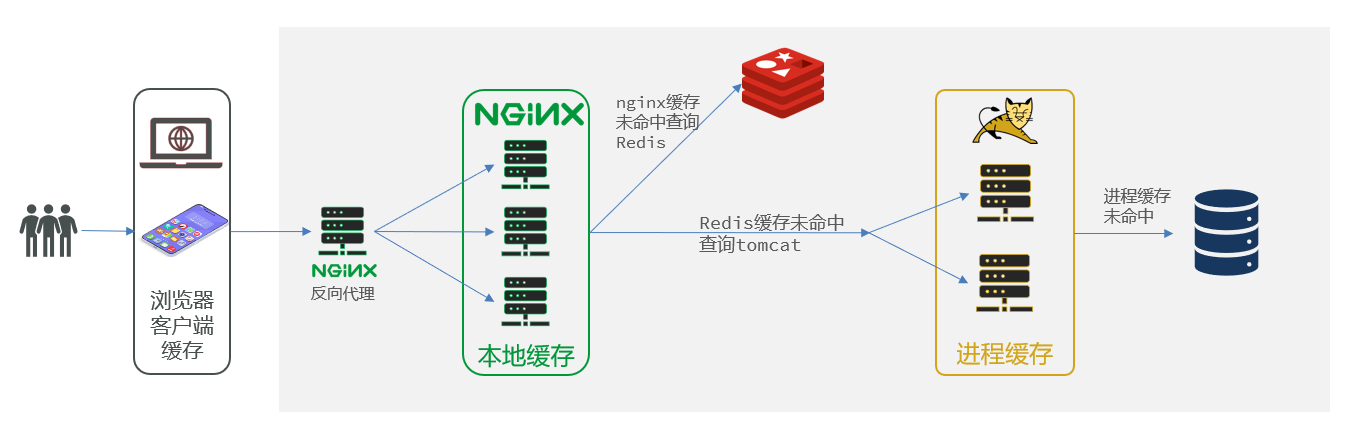
可见,多级缓存的关键有两个:
一个是在nginx中编写业务,实现nginx本地缓存、Redis、Tomcat的查询另一个就是在Tomcat中实现JVM进程缓存