读取“农村居民人均可支配收入来源 2016.xlsx”数据表,其中数据来源于 2016 年《中国统计年鉴》,对表中给出的我国内陆 31 个地区做 K-均值聚类分析(K=4),并在控制台中输出聚类结果和各个类的聚类中心。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.cluster import KMeans
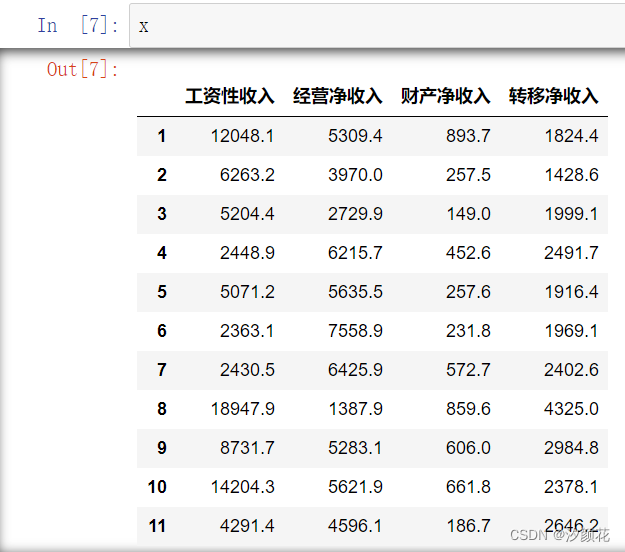
data=pd.read_excel('农村居民人均可支配收入来源2016.xlsx')
x=data.iloc[1:31,1:5]
x
#计算k均值聚类
kmeans = KMeans(n_clusters=4, random_state=0).fit(x)
#簇中心坐标
center = kmeans.cluster_centers_
plt.scatter(x,x)
plt.show()
#4个聚类中心,运行算法10次,取最优值。
kmeans_rnd_10_inits = KMeans(n_clusters=4, init="random", n_init=10,
algorithm="full", random_state=2)
kmeans_rnd_10_inits.fit(x)
k = 4
kmeans = KMeans(n_clusters=k, random_state=31)
y_pred = kmeans.fit_predict(x)
kmeans.cluster_centers_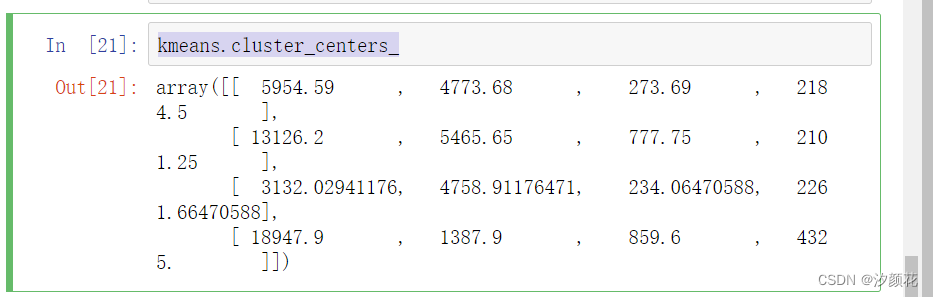
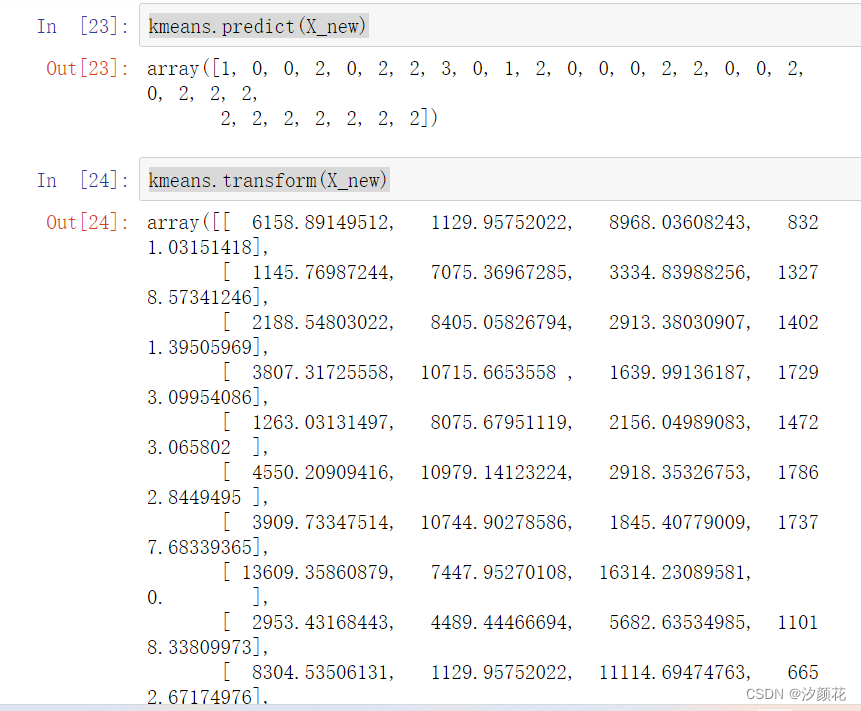
X_new = np.array(x)
kmeans.predict(X_new)
kmeans.transform(X_new)
#4个聚类中心,运行算法10次,取最优值。
kmeans_rnd_10_inits = KMeans(n_clusters=4, init="random", n_init=10,
algorithm="full", random_state=2)
kmeans_rnd_10_inits.fit(x)