
关注”PandaCVer“公众号
深度学习Tricks,第一时间送达
论文题目:A ConvNet for the 2020s
论文地址:https://arxiv.org/abs/2201.03545
源代码:https://github.com/facebookresearch/ConvNeXt
纯卷积主干网络!可与大火的分层视觉Transformer竞争!多个任务性能超越Swin!
MetaAI在论文A ConvNet for the 2020s中, 从ResNet出发并借鉴Swin Transformer提出了一种新的 CNN 模型:ConvNeXt,其效果无论在图像分类还是检测分割任务上均能超过Swin Transformer,而且ConvNeXt和vision transformer一样具有类似的scalability(随着数据量和模型大小增加,性能同比提升)。
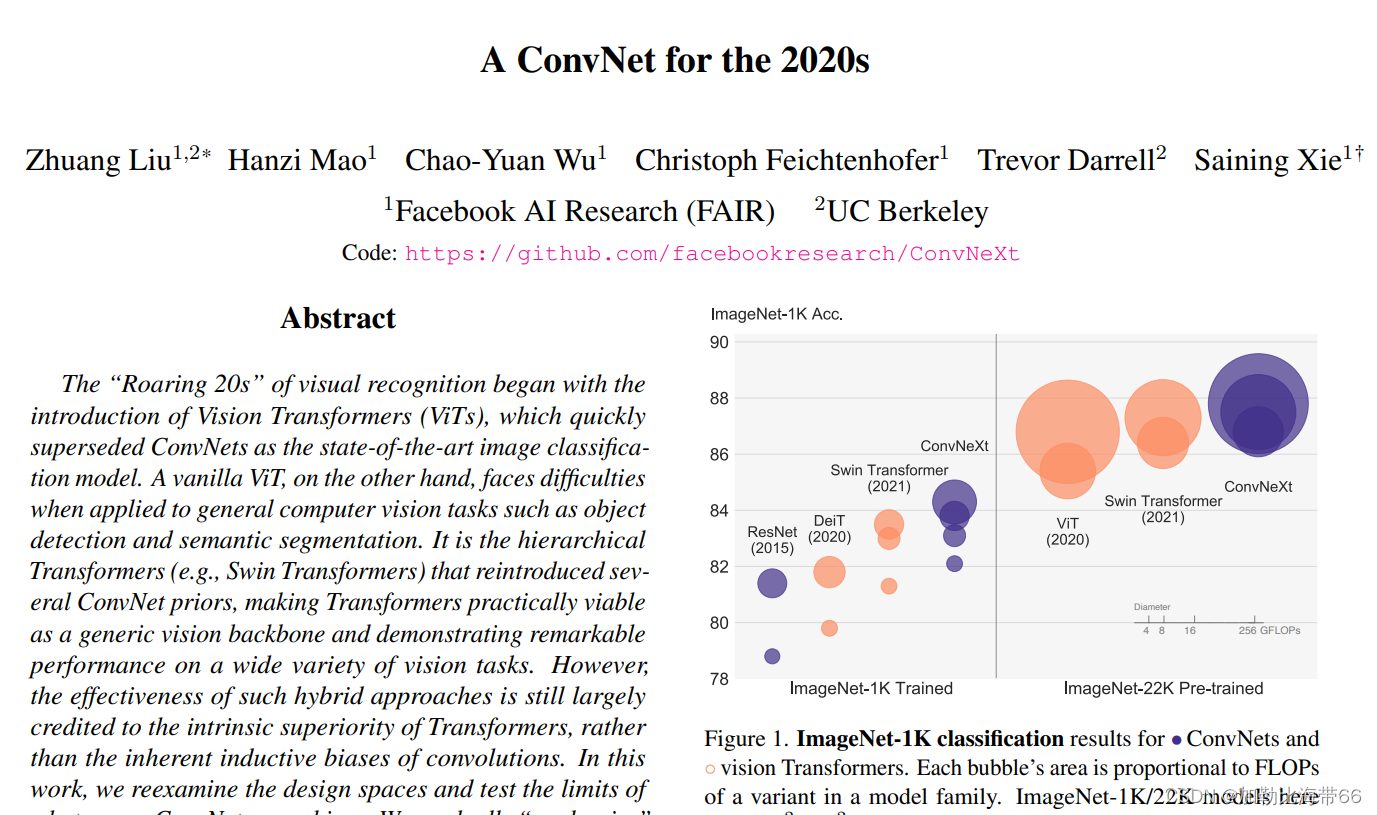
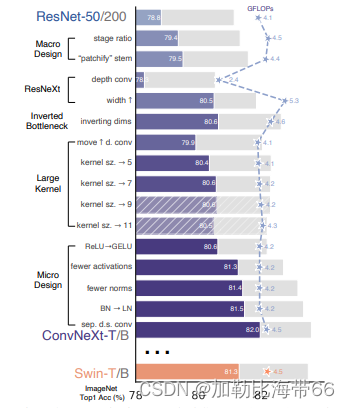
ConvNeXt 从原始的 ResNet 出发,逐步加入swin transform 的 trick,来改进模型。论文中适用 ResNet模型:ResNet50和ResNet200。其中ResNet50和Swin-T有类似的FLOPs(4G vs 4.5G),而ResNet200和Swin-B有类似的FLOPs(15G)。首先做的改进是调整训练策略,然后是模型设计方面的递进优化:宏观设计->ResNeXt化->改用Inverted bottleneck->采用large kernel size->微观设计。由于模型性能和FLOPs强相关,所以在优化过程中尽量保持FLOPs的稳定。
相关代码:
class ConvNeXt(nn.Module): r""" ConvNeXt A PyTorch impl of : `A ConvNet for the 2020s` - https://arxiv.org/pdf/2201.03545.pdf Args: in_chans (int): Number of input image channels. Default: 3 num_classes (int): Number of classes for classification head. Default: 1000 depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3] dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768] drop_path_rate (float): Stochastic depth rate. Default: 0. layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6. head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1. """ def __init__(self, in_chans=3, num_classes=1000, depths=[3, 3, 9, 3], dims: list = [96, 192, 384, 768], drop_path_rate=0., layer_scale_init_value=1e-6, head_init_scale=1., ): super().__init__() self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers stem = nn.Sequential( nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4), LayerNorm(dims[0], eps=1e-6, data_format="channels_first") ) self.downsample_layers.append(stem) for i in range(3): downsample_layer = nn.Sequential( LayerNorm(dims[i], eps=1e-6, data_format="channels_first"), # 下采样 nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2), ) self.downsample_layers.append(downsample_layer) # 4 feature resolution stages, each consisting of multiple residual blocks self.stages = nn.ModuleList() dp_rates = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] cur = 0 for i in range(4): stage = nn.Sequential( *[Block(dim=dims[i], drop_path=dp_rates[cur + j], layer_scale_init_value=layer_scale_init_value) for j in range(depths[i])] ) self.stages.append(stage) cur += depths[i] self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layer self.head = nn.Linear(dims[-1], num_classes) self.apply(self._init_weights) self.head.weight.data.mul_(head_init_scale) self.head.bias.data.mul_(head_init_scale) def _init_weights(self, m): if isinstance(m, (nn.Conv2d, nn.Linear)): trunc_normal_(m.weight, std=.02) nn.init.constant_(m.bias, 0) def forward_features(self, x): for i in range(4): x = self.downsample_layers[i](x) x = self.stages[i](x) return self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C) def forward(self, x): x = self.forward_features(x) x = self.head(x) return x通过借鉴Swin Transformer的设计来逐步地改进模型。论文共选择了两个不同大小的ResNet模型:ResNet50和ResNet200,其中ResNet50和Swin-T有类似的FLOPs(4G vs 4.5G),而ResNet200和Swin-B有类似的FLOPs(15G)。首先做的改进是调整训练策略,然后是模型设计方面的递进优化:宏观设计>ResNeXt化>改用Inverted bottleneck>采用large kernel size>微观设计。由于模型性能和FLOPs强相关,所以在优化过程中尽量保持FLOPs的稳定。 ConVNeXt 这篇文章,通过借鉴 Swin TransForm 精心构建的 tricks,卷积在图像领域反超 Transformerer。
如何结合YOLOv5,有需要且感兴趣的小伙伴关注互粉一下,一起学习!共同进步!