? 写在前面
?? 博主介绍:大家好,这里是hyk写算法了吗,一枚致力于学习算法和人工智能领域的小菜鸟。
?个人主页:主页链接(欢迎各位大佬光临指导)
⭐️近期专栏:机器学习与深度学习
LeetCode算法实例
目录
总览数据集简介第三方库准备加载数据搭建cnn模型类以及相关方法训练模型画图展示结果项目整体代码运行结果部分知识点整理模型建立model.compile训练模型打印网络结构和参数统计
总览
本节内容主要向大家介绍如何使用TensorFlow快速搭建自己的卷积神经网络,并通过cifar数据集训练验证。文章最后会有相关内容知识点的补给。
数据集简介
Cifar-10 是由 Hinton 的学生 Alex Krizhevsky、Ilya Sutskever 收集的一个用于普适物体识别的计算机视觉数据集,它包含 60000 张 32 X 32 的 RGB 彩色图片,总共 10 个分类。其中,包括 50000 张用于训练集,10000 张用于测试集。

第三方库准备
import tensorflow as tfimport numpy as npfrom matplotlib import pyplot as plt该项目使用上述第三方库,大家提前下载需要提前下载好。
加载数据
cifar10 = tf.keras.datasets.cifar10(x_train, y_train), (x_test, y_test) = cifar10.load_data()x_train, x_test = x_train / 255.0, x_test / 255.0首次使用需要联网下载一段时间数据集,大家耐心等待下。
搭建cnn模型类以及相关方法
# 继承自tf.keras.Modelclass Baseline(tf.keras.Model): def __init__(self): super(Baseline, self).__init__() # 第一层卷积 self.c1 = tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), padding='same') # 第一层BN self.b1 = tf.keras.layers.BatchNormalization() # 激活函数层 self.a1 = tf.keras.layers.Activation('relu') # 池化层 self.p1 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=2, padding='same') # Dropout层 self.d1 = tf.keras.layers.Dropout(0.2) # 将卷积获得的网络拉平以便后序全连接层使用 self.flatten = tf.keras.layers.Flatten() # 一层全连接 self.f1 = tf.keras.layers.Dense(128, activation='relu') # 又一层dropout self.d2 = tf.keras.layers.Dropout(0.2) # 第二层全连接 self.f2 = tf.keras.layers.Dense(10, activation='softmax')# 读入inputs数据,并进行操作返回 def call(self, inputs): x = self.c1(inputs) x = self.b1(x) x = self.a1(x) x = self.p1(x) x = self.d1(x) x = self.flatten(x) x = self.f1(x) x = self.d2(x) y = self.f2(x) return y训练模型
# 创建模型对象model = Baseline()# 指明优化器、损失函数、准确率计算函数model.compile(optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics=[tf.keras.metrics.sparse_categorical_accuracy])# 开始训练history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)# 展示训练的过程model.summary()画图展示结果
# showacc = history.history['sparse_categorical_accuracy']val_acc = history.history['val_sparse_categorical_accuracy']loss = history.history['loss']val_loss = history.history['val_loss']print(acc)print(val_loss)plt.figure(figsize=(8, 8))plt.subplot(1, 2, 1)plt.plot(acc, label='Training Accuracy')plt.plot(val_acc, label='Validation Accuracy')plt.title('Training and Validation Accuracy')plt.legend()plt.subplot(1, 2, 2)plt.plot(loss, label='Training loss')plt.plot(val_loss, label='Validation loss')plt.title('Training and Validation loss')plt.legend()plt.show()分别展示了训练集和测试集上精确度、损失值的对比
项目整体代码
import tensorflow as tfimport numpy as npfrom matplotlib import pyplot as pltnp.set_printoptions(threshold=np.inf)cifar10 = tf.keras.datasets.cifar10(x_train, y_train), (x_test, y_test) = cifar10.load_data()x_train, x_test = x_train / 255.0, x_test / 255.0class Baseline(tf.keras.Model): def __init__(self): super(Baseline, self).__init__() self.c1 = tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), padding='same') self.b1 = tf.keras.layers.BatchNormalization() self.a1 = tf.keras.layers.Activation('relu') self.p1 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=2, padding='same') self.d1 = tf.keras.layers.Dropout(0.2) self.flatten = tf.keras.layers.Flatten() self.f1 = tf.keras.layers.Dense(128, activation='relu') self.d2 = tf.keras.layers.Dropout(0.2) self.f2 = tf.keras.layers.Dense(10, activation='softmax') def call(self, inputs): x = self.c1(inputs) x = self.b1(x) x = self.a1(x) x = self.p1(x) x = self.d1(x) x = self.flatten(x) x = self.f1(x) x = self.d2(x) y = self.f2(x) return ymodel = Baseline()model.compile(optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics=[tf.keras.metrics.sparse_categorical_accuracy])history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)model.summary()# showacc = history.history['sparse_categorical_accuracy']val_acc = history.history['val_sparse_categorical_accuracy']loss = history.history['loss']val_loss = history.history['val_loss']print(acc)print(val_loss)plt.figure(figsize=(8, 8))plt.subplot(1, 2, 1)plt.plot(acc, label='Training Accuracy')plt.plot(val_acc, label='Validation Accuracy')plt.title('Training and Validation Accuracy')plt.legend()plt.subplot(1, 2, 2)plt.plot(loss, label='Training loss')plt.plot(val_loss, label='Validation loss')plt.title('Training and Validation loss')plt.legend()plt.show()运行结果
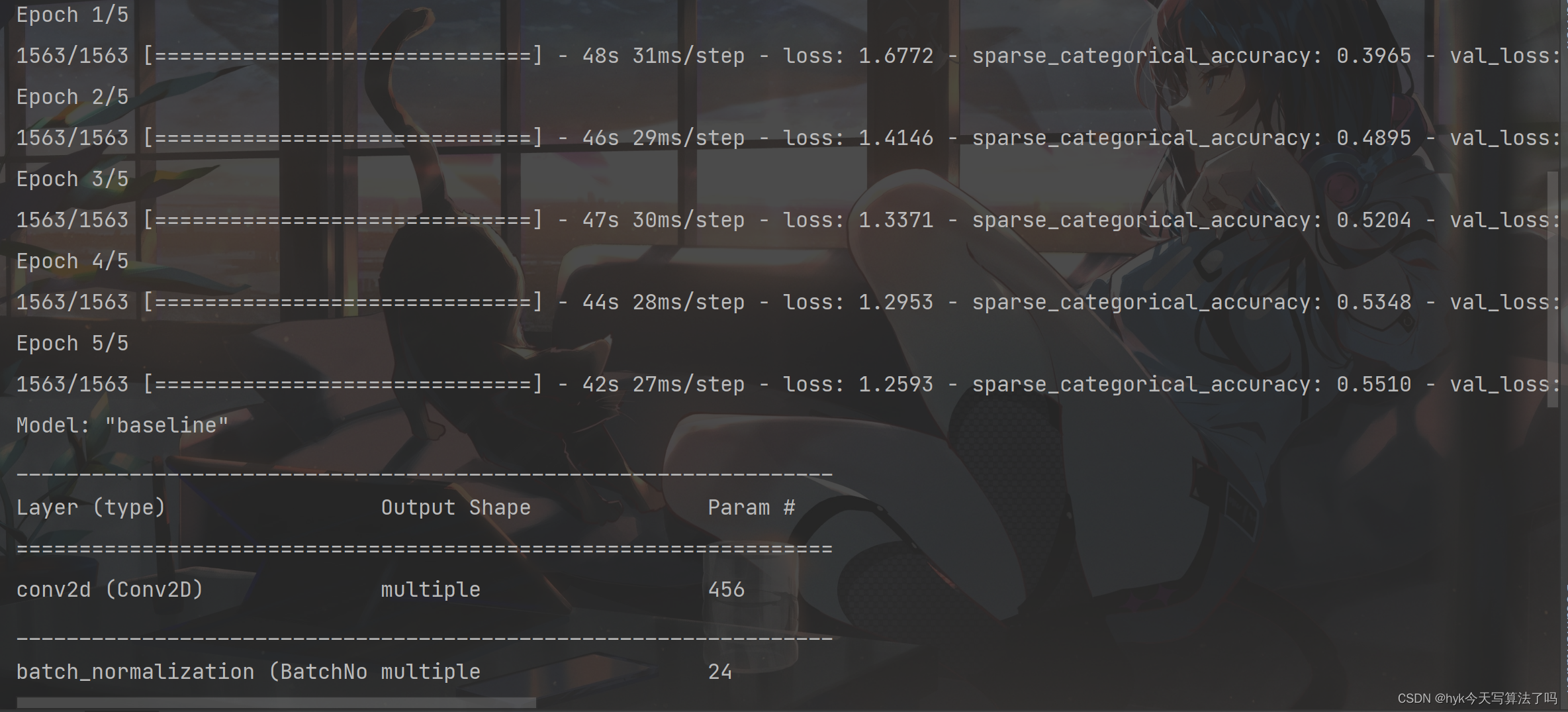
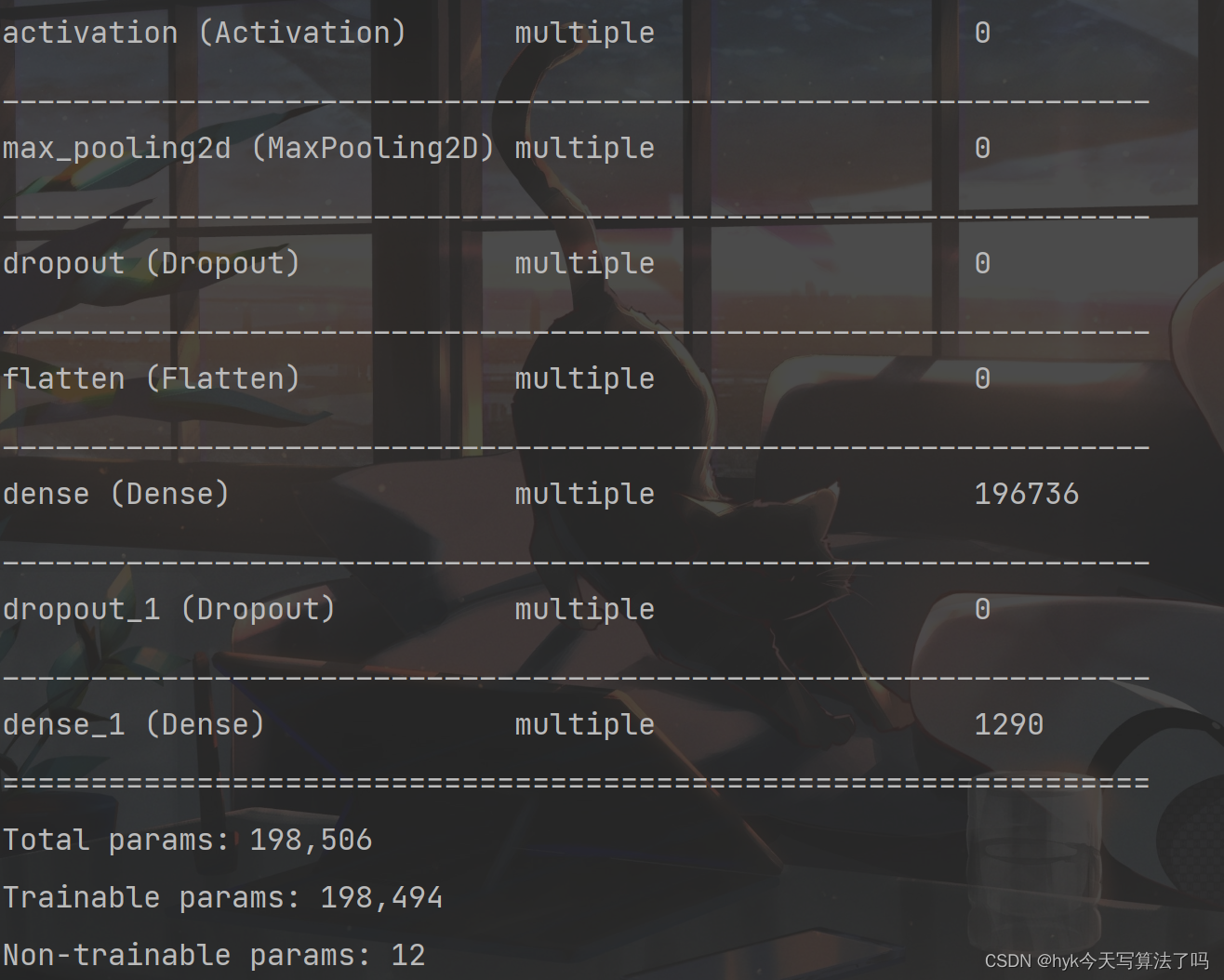
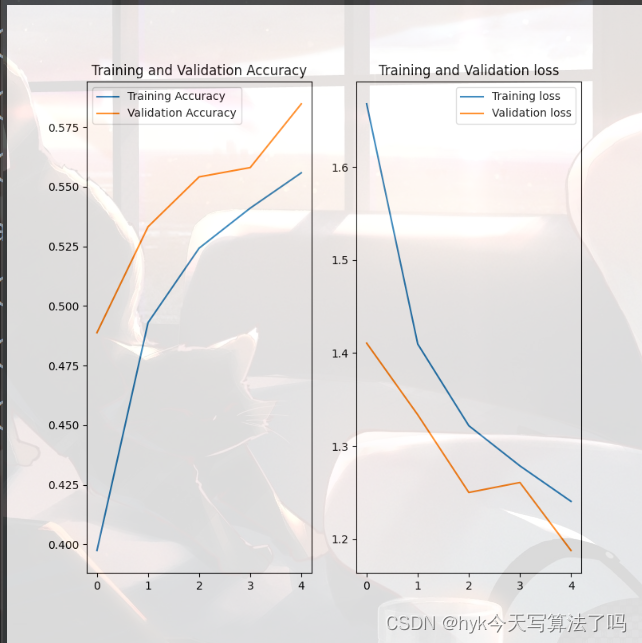
部分知识点整理
模型建立
tf.keras.models.Sequential([网络结构]) # 描述各层网洛Sequentail()可以认为是个容器,这个容器里封装了一个神经网络结构。在Sequential中要描述从输入层到输出层每一层的网络结构。每一层的网络结构可以是拉直层: tf.keras.layers.Flatten() ,这一层不含计算,只是形状转换,把输入特征拉直,变成一维数组全连接层:
tf.keras.layers.Dense(神经元个数,activation=“激活函数”,kernel_regularizer=哪种正则化),这一层告知神经元个数、使用什么激活函数、采用什么正则化方法 激活函数可以选择relu, softmax, sigmoid, tanh等正则化可以选择 tf.keras.regularizers.l1(), tf.keras.relularizers.l2()卷积神经网络层:tf.keras.layers.Conv2D(filters=卷积核个数,kernel_size=卷积核尺寸,strides=卷积步长, padding=“valid” or “same”)循环神经网络层:tf.keras.layers.LSTM()
model.compile
model.compile(optimizer=优化器,loss=损失函数,metrics=["准确率"])在这里告知训练时选择的优化器、损失函数、和评测指标。 这些参数都可以使用字符串形式或函数形式
optimizer: 引导神经网络更新参数
sgd or tf.keras.optimizer.SGD(lr=学习率,momentum=动量参数)adagrad or tf.keras.optimizer.Adagrad(lr=学习率)adadelta or tf.keras.optimizer.Adadelta(lr=学习率)adam or tf.keras.optimizer.Adam(lr=学习率, beta_1=0.9, beta_2=0.999)loss: 损失函数
mes or tf.keras.losses.MeanSquaredError()
sparse_categorical_crossentropy or
tf.keras.SparseCategoricalCrossentropy(from_logits=False)(是原始输出还是经过概率分布)
metrics:评测指标
accuracy:y_ 和 y 都是数值,如y_=[1] y=[1]categorical_accuracy: y_和y都是独热码(概率分布),如y_=[0, 1, 0], y=[0.256, 0.695,0.048]sparse_categorical_accuracy: y_是数值,y是独热码(概率分布),如y_=[1], y=[0.256,
0.695, 0.048]
训练模型
model.fit(训练集的输入特征,训练集的标签,batch_size= 每次喂入神经网络的样本数, epochs=迭代多少次数据集, validation_data=(测试集的输入特征,测试集的标签,), validation_split=从训练集划分多少比例给测试集,validation_freq=多少次epoch测试一次)打印网络结构和参数统计
model.summary()