国庆节快乐!为每天进步一点点而努力。![]()
C++是计算机视觉的重要的一部分,虽然在初始学习时Python应用比较广,但是大多数公司还是C++做计算机视觉类的比较多,因为C++可加密,所以我们来一起探索吧!看了这系列博客,将会学到C++的基本操作!(如果不敲代码,可能会一知半解)
第九天-221007
chapter 10 函数对象,类模板和标准模板库Standard Template Library-STL
10.1.函数对象
函子(函数对象或函数)简单地放在object + ()中。换句话说,函子是可以以函数方式与()一起使用的任何对象。
函数对象很有用,因为它们可以进一步利用 STL 库。此外,它们是内联的,可以生成高效的目标代码。
这包括普通函数、指向函数的指针和() 运算符(函数调用运算符)被重载的类对象,即定义了函数operator()()的类。
有时我们可以在普通函数不起作用时使用函数对象。STL 经常使用函数对象,并提供了几个非常有用的函数对象。
函数对象是泛型编程和纯抽象概念的另一个例子。我们可以说任何表现得像函数的东西都是函数。所以,如果我们定义一个行为像函数的对象,它就可以用作函数。
实例:类对象作为函子工作,为给定的 y 截距(b)和斜率(a)获取x ,为我们提供相应的y坐标。
#include <iostream>using namespace std;class Line {double a;// slopedouble b;// y-interceptpublic:Line(double slope = 1, double yintercept = 1):a(slope),b(yintercept){} double operator()(double x){return a*x + b;}};int main () {Line fa;// y = 1*x + 1Line fb(5.0,10.0);// y = 5*x + 10double y1 = fa(20.0);// y1 = 20 + 1double y2 = fb(3.0);// y2 = 5*3 + 10cout << "y1 = " << y1 << " y2 = " << y2 << endl;return 0;}结果:
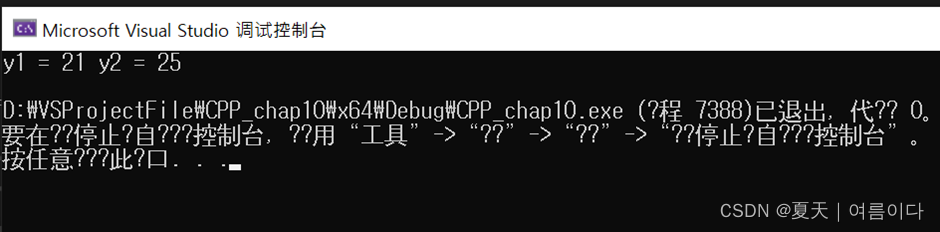
这里y1使用表达式1 * 20 + 1计算,y2使用表达式5 * 3 + 10计算。在表达式a *x + b中,b和a的值来自对象的构造函数,而x的值来自operator() () 的参数。
示例2:一个函数对象
#include <iostream>#include <vector>#include <algorithm>using namespace std;class Print {public:void operator()(int elem) const {cout << elem << " ";}};int main () {vector<int> vect;for (int i=1; i<10; ++i) {vect.push_back(i);}Print print_it;for_each (vect.begin(), vect.end(), print_it);cout << endl;return 0;}结果:
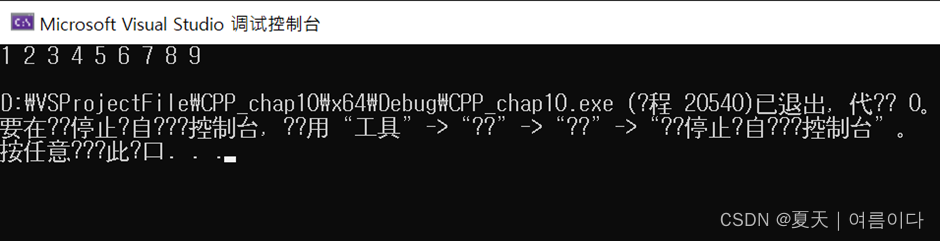
for_each函数将特定函数应用于范围的每个成员
for_each (vect.begin(), vect.end(), print_it);一般来说,第三个参数可以是一个仿函数,而不仅仅是一个常规函数。实际上,这提出了一个问题。我们如何声明第三个参数?我们不能将它声明为函数指针,因为函数指针指定了参数类型。因为容器可以包含几乎任何类型,所以我们事先不知道应该使用哪种特定类型。STL 通过使用template解决了这个问题。
Print类定义了我们可以使用int参数调用operator ()的对象:print_it.
创建该类的一个临时对象,该对象作为参数传递给for_each()算法。for_each算法如下所示:
template<typename Iterator, typename Function>Function for_each(Iterator first, Iterator last, Function f) {while (first != end) {f(*first);++first;}return f;}10.2.类模板
定义一个类模板——堆栈类
首先定义一个Stack类,然后定义一个Pair模仿 C++pair 结构的类。
堆栈是一种数据结构,其中数据被输入到堆栈顶部(通过push成员函数),而数据仅从堆栈顶部删除(通过pop成员函数)。唯一需要的其他主要成员函数是一个top函数,它检查并返回堆栈顶部的数据元素。(详情参考堆栈的blog)
堆栈可用于所有数据类型,并且此功能适用于通用实现。我们可能需要一个用于存放整数的堆栈,或者一个用于存放字符串的堆栈,或者一个用于存放浮点值的堆栈。为每种数据类型创建单独的实现是不切实际的,因此需要模板定义。
template <typename T> class Stack { // 声明和定义};每当我们需要引用一个数据类型时,要么是引用进入类的数据,要么是从类发送的数据,我们将使用T占位符键入数据。这是Stack该类的完整声明:
template <typename T>class Stack { private: vector<T> data; public: void push(T element); bool pop(); T top();};注意:在定义部分中使用模板参数占位符的位置。每次提到类名以及需要作为参数类型或返回类型的占位符时,它都必须放在括号中。
第二个例子:Pair 类
APair是一个包含两个数据元素的类。这些数据元素可以是任何类型,也可以是不同类型。我的定义将模仿pairSTL 中的结构,并与 STL 容器(例如 map)一起使用。
类的两个成员变量是first和second。为了更接近地模仿 STL 版本,这些将在public部分中声明,以便可以直接从pair对象访问它们。(由于成员变量的公共访问,我也可以将此类实现为结构。)
由于这是一个简单的类,因此声明也是Pair 该类的定义:
template <typename T1, typename T2>class Pair { public: T1 first; T2 second;}; 该pair结构有一个帮助生成配对对象的函数,设置为makePair:
template <typename T1, typename T2>|Pair<T1, T2> makePair(T1 first, T2 second) { Pair<T1, T2> p; p.first = first; p.second = second; return p;} Pair这是一个使用类和makePair函数的示例程序:
#include <iostream>#include <vector>#include <algorithm>using namespace std;template <typename T1, typename T2>class Pair {public: T1 first; T2 second;};template <typename T1, typename T2>Pair<T1, T2> makePair(T1 first, T2 second) { Pair<T1, T2> p; p.first = first; p.second = second; return p;}int main(){ Pair<string, int> nameAge; string name = "Mary"; int age = 23; nameAge = makePair<string, int>(name, age); cout << "Name: " << nameAge.first << endl; cout << "Age: " << nameAge.second << endl; return 0;}结果:
10.2.STL
标准模板库是 C++ 的最新版本。STL 使程序员能够有效地存储数据,并对存储的数据进行操作。这些是类和函数的通用模板,有助于实现基本算法和数据结构,如向量、列表、队列、堆栈等。
作为程序员,必须确保以这样一种方式存储数据,以便检索和操作变得容易解决,这称为标准模板库 (STL)。许多打算在各个技术领域带来巨大改变的创新者正在分别致力于设计新的算法和实现,而存储数据最终成为一项艰巨的任务,这使得 C++ 中的 STL 变得非常重要,它可以解决他们的查询。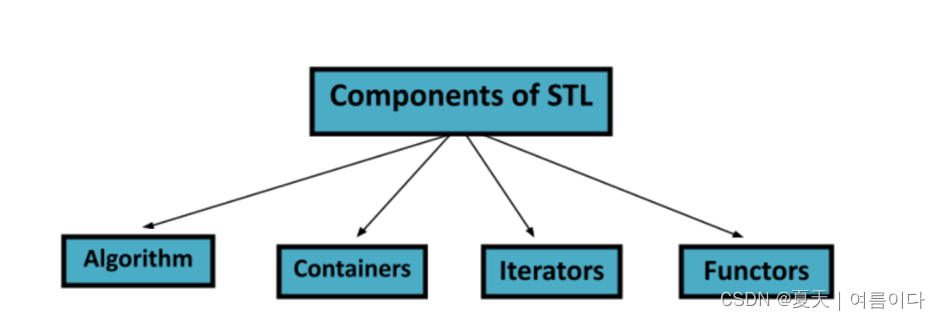
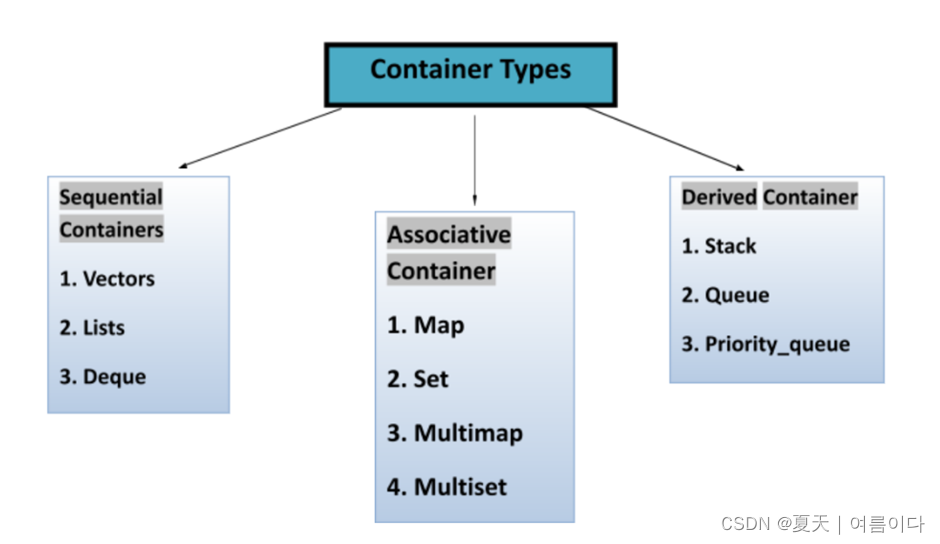
STL 有 4 个组件:
算法容器迭代器仿函数容器
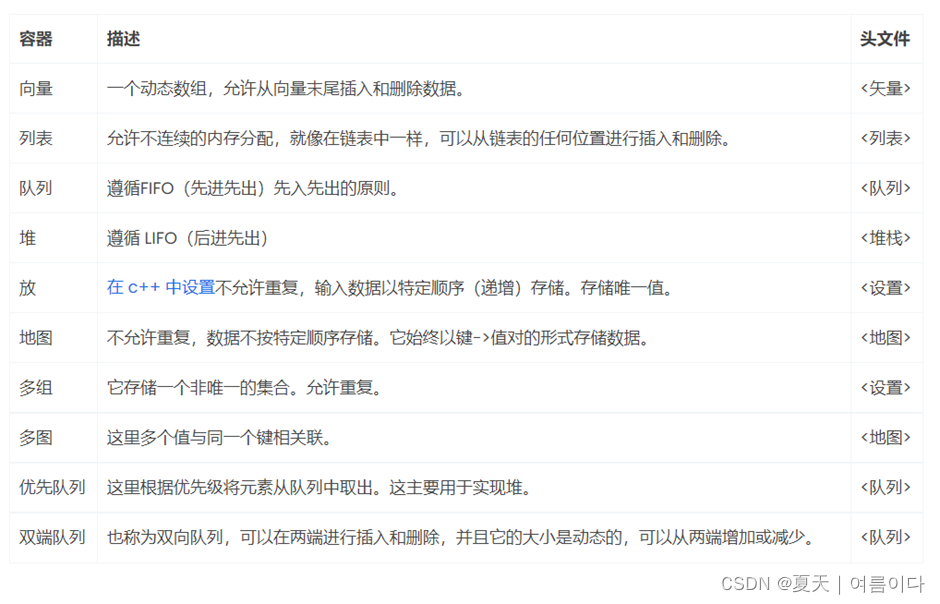
这有助于程序员将数据存储在下面列出的容器中,以便对数据进行进一步的操作。就像人排成一排;执行者有权根据他/她的选择来操纵行,并且可以以任何方式在行中添加更多人。以下是一些常用容器来保存数据的列表
算法
算法通过一些预定义的函数作用于容器数据,其中数据被更改以获得更好的结果,并为进一步的操作提供了一种平滑的方式。假设有一些硬币,必须按其价值的升序排列它们,因此应用“策略”将硬币排成一排,然后交换它们的位置以将它们按升序排序,因此“策略”或人们使用的技术可以说是一种能够对硬币进行分类的算法。 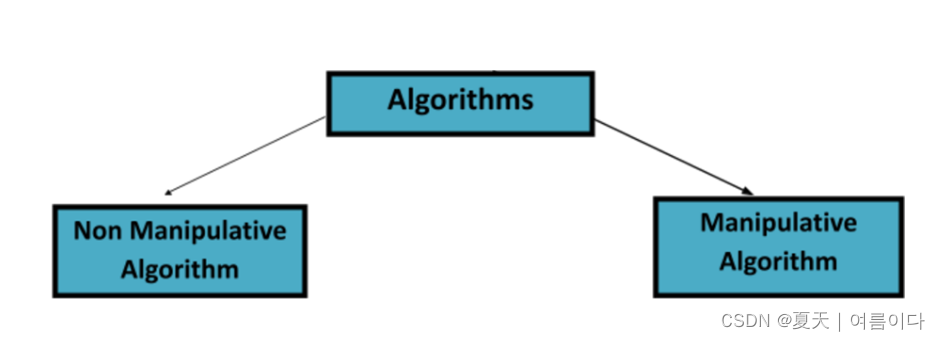
非操作性算法:-
sort(first_iterator,last_iterator) -> 按升序或升序排列数据。reverse(first_iterator,last_iterator) -> 它反转容器中元素的排列。*min_element(first_iterator,last_iterator) -> 返回向量的最小值。*max_element(first_iterator,last_iterator) -> 它返回向量中存在的最大值。count(first_iterator,last_iterator,x) -> 返回 'x' 在向量中出现的次数。find(first_iterator,last_iterator,x) -> 如果向量中不存在元素“x”,则返回指向向量末尾的指针或返回目标元素的位置。操纵算法:-
arr.erase(position_of_the_element_to_delete) -> 它删除位置作为参数发送的元素并调整向量的大小。next_permutation(first_iterator,last_iterator) -> 它修改向量以进行下一个排列。previous_permutation(first_iterator,last_iterator) -> 将向量修改为之前的排列。arr.erase(unique(arr.begin(),arr.end()),arr.end()) -> 它以排序方式擦除向量中所有多次出现的元素。迭代器
迭代器是“智能指针”,它像指针一样指向容器中的数据,但有助于遍历复杂的数据结构,而指针无法有效地完成这些数据结构。它类似于在编辑器中闪烁的文本光标,在键入时它们最初出现在开头,当我们键入时,它会自动将自身移动到内容的末尾,但可以在文本区域的任何地方进行。输入迭代器:- 所有算法都是顺序/线性遍历,其中每个元素只遍历一次。输出迭代器:- 它们就像输入迭代器,但它们只分配元素。前向迭代器:- 迭代器不向后遍历,而是向前遍历。双向迭代器:- 迭代器可以向前和向后遍历。随机访问迭代器:- 从容器中特定位置的容器中检索数据。
仿函数
仿函数是作为参数传递并指向要执行的那些函数的“函数对象”。仿函数主要用于处理事件。参考文献:
【1】https://levelup.gitconnected.com/learning-c-class-templates-and-the-stl-part-1-d3a9891f827e
【2】Standard Template Library in C++ - Great Learning
【3】【C++】标准模板库(STL):超快入门!算法竞赛必看! - 知乎 (zhihu.com)