
8 月 10 日,2022 OceanBase 年度发布会在京沪深三地同时召开,支付宝资深数据库专家邓荣伟在会上分享了《从“小”到“大”,支付宝分布式升级之路》的主题演讲 ,为我们带来了支付宝的架构演进以及上线 OceanBase 的故事。

以下为演讲实录分享:
大家都知道支付宝是 OceanBase 的“元老级”用户,支付宝的每一次架构演进都与 OceanBase 的版本迭代息息相关。今天,我将从支付宝的数据库架构演进展开,主要围绕以下三个方面进行分享:
第一, 支付宝在线库架构演进;
第二,支付宝历史库架构,面对 PB 级数据归档,如何横向无限扩展;
第三,面对多样化存储需求,支付宝的未来探索。
支付宝在线库架构演进
过去式:OceanBase 1.0时代的进化
支付宝一开始诞生在“IOE”时代,数据库首选 IBM 小型机+Oracle 数据库+EMC 的传统搭配。然而,当支付宝迎来第一个“双 11”,与之而来出现“峰值脉冲”,原单库单表的集中式数据库方案自然扛不住如此高的流量。所以,支付宝在很早期就进行了拆库拆表,由此诞生了基于中间件方案的第一代分布式架构。
随着支付宝的用户规模不断增长,以及历年“双 11”都需要应对超高并发,传统架构性能瓶颈凸显,数据存储成本攀升。2013 年 5 月,支付宝下线最后一台 IBM 小型机之后,开始下一步的升级迭代,众所周知,核心底层存储的替换挑战非常大,支付宝对新数据库不仅要求成本低,还要求具备高性能、可扩展、高可用等特性,OceanBase 就在这种背景下诞生了。
如下图所示,是支付宝在 2017 年之前整个数据库架构的演进。首先是底层存储全部替换为 X86,然后是数据库从 Oracle 升级为 OceanBase 0.5、再到 OceanBase 1.0。
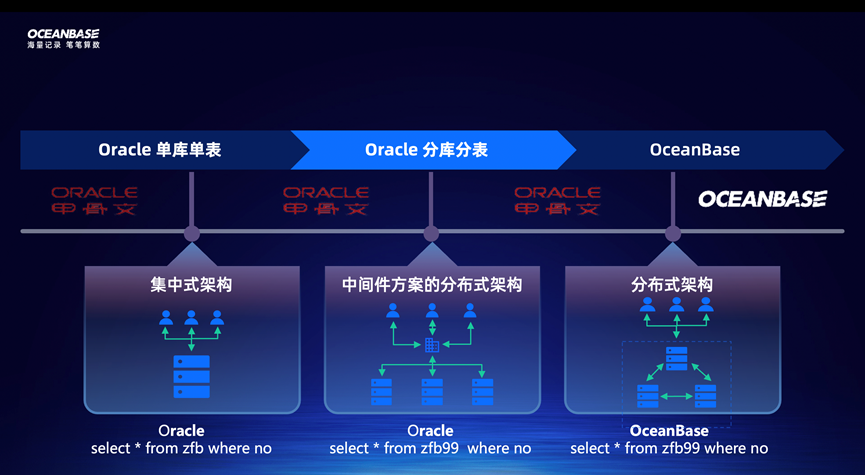
阳老师在《OceanBase 4.0 核心技术解读》中分享了 OceanBase 的版本迭代历程。在 0.5 时代,OceanBase 因为读是分布式的,写是集中式的,所以没有办法将性能做到极致。在 1.0 时代,OceanBase 实现了一个集群内所有节点都是对等的,每个节点都可以进行读写,成为真正的分布式数据库。
OceanBase 1.0 是支付宝投产时间最长、应用范围最广的版本,主要有以下三个特点:
多租户。多租户能在中小数据库整合场景中很好地提升资源利用率,例如,我们上线一套 MySQL 或 Oracle,遇到流量激增时会不得不进行拆库拆表,但 OceanBase 能以租户为资源载体的方式进行动态扩容。
高可用。支付宝的金融场景,要求数据库必须满足机房级容灾、城市级容灾,OceanBase 是基于 Paxos 协议的分布式数据库,先天满足这些诉求。
弹性伸缩。历年“双 11”,支付宝都会转移一部分流量去一个“泡”在湖水中的数据中心——千岛湖数据中心。当支付宝还在使用传统关系型数据库时,数据库弹出只能通过主备库的方式先在千岛湖数据中心搭一个备库,然后主备切换过去。但这种方式会有切换闪断问题,业务有感知。迁移至 OceanBase 后,数据库弹出可以直接使用 OceanBase 的加减副本、平滑切主特性,在用户不感知的情况下完成弹出。此外,OceanBase 可以做到在大促峰值结束 30 分钟内释放数千台服务器给其他业务使用。
现在式:稳定支撑每秒百万笔支付请求
大家都知道,每年双 11 的各项数据都在增长,到了 2017 年的双 11时期, 1 %的压力峰值就已经超过了单库单机的最大容量。传统数据库扩容方案主要依赖分库分表拆分进行水平扩容,用多套库的方式共同扛流量峰值。虽然这种方案可行,但存在很多弊端,比如多套数据源、多套 DB 集群,增加了配置管理、日常管理成本。
我们需要更优雅的分布式数据库解决方案,即只使用一个库,就可以支持百万甚至更高的支付峰值,让横向扩容直接在数据库闭环,做到应用不感知,OceanBase 2.0 分区提供了完美的解决方案。
OceanBase 2.0 分区方案思路和传统的分库分表拆分一样。我们在交易支付核心库上,在原有百库百表的基础上继续按用户 UID 进行更深层次拆分,每个分表再拆成一百个 Partition,应用端只看到一张表,在用户无感知的前提下把数据拆分到更多的机器上,突破单机性能瓶颈,自动负载均衡,从而实现稳定支撑每秒百万笔支付请求的能力。
这时候大家可能会有两个疑问,为什么已经拥有分区能力,还要用分表加上分区的方案。支付宝是一个单元化部署架构,分库分表是架构的一个基础,所以分库分表不能变,在此基础上可以继续分区。这样,用户看起来还是百库百表,然后通过 OceanBase 自动负载均衡,把 1% 的表自动均摊到多台机器上,以此突破单机容量上限。
那么,OceanBase 能否在不分区的前提下使用多台机器资源?答案是可以的,支付宝内部也有很多系统没有分区,直接将单库多表均摊到多台机上的应用场景。以及,OceanBase 的分区表,是否一定要业务指定分区 ID,这其实需要根据业务场景而定,如果业务场景追求极致性能,建议指定分区 ID,我们可以按照一定的规则分区,通过应用或中间件计算出分区 ID,只要让 OBProxy 感知到分区,SQL 路由到正确的机器上即可,否则需要 OceanBase 内部二次路由,性能稍有衰减。
同时,OceanBase 2.0 为了极致性能引入 Partition Group,将业务使用了一组逻辑表的相同分区,聚集在相同的 OceanBase 节点,使分布式事务退化为单机事务做到极致性能。具体来说,假设现在是单库单表,当某业务做一笔支付请求要在这三张表里落数据时,现在是按照用户的 UID 维度,按照相同的分表分区规则做拆分,用户支付之后一定是在这三个表的同一个分区落数据,也就是说,这三个表相同分区就可以满足用户的整个业务逻辑,所有操作不需要跨机、不需要产生分布式事务。
现在,OceanBase 2.0 版本在支付宝也承担了非常多的核心业务,主要有以下三个特点:
高兼容。OceanBase 支持 MySQL/Oracle 语法,让支付宝在数据库迁移时成本代价更低。
性能提升,成本下降。单库单表可以扩展到多机,单库容量不再受限于单机硬件能力。相对 OceanBase 1.0,数据库整体性能提升 50%,存储空间节省 30%。
更低的运维成本,更好的弹性能力。以前支付宝做数据库弹出的时候,需要业务配合。现在,OceanBase 数据库可以横向伸缩,在数据库上就已经闭环,业务不感知,基本一键完成了这件事。
迁移OceanBase之路
Oracle/MySQL 是支付宝最早投入使用的数据库,体量非常大,这种传统关系型数据库在扩展、容灾等能力上存在短板,没办法满足支付宝的发展诉求。此外,对于我们 DBA 来说,一是经常要去担心数据一致性问题,二是不得不重复维护多套运维体系、容灾体系以及生态工具,代价非常大。所以,支付宝开始规模化地将Oracle/MySQL 全部迁移至 OceanBase。现在,支付宝全栈都运行在 OceanBase 上。
异构数据库迁移是一个复杂的过程——主要是兼容性和数据质量的问题。为了高效迁移, OMS(OceanBase Migration Service,OceanBase 数据迁移工具)提供一站式的异构数据库上 OceanBase,首先为了应对兼容性问题,平台提供静态代码评估,动态流量回放评估,其次数据质量通过全量校验,增量校验,离线校验等多重手段实时保证数据一致性。
迁移至 OceanBase 后,一方面是效率提升,DBA 可以更从容地应对日常的容量容灾问题,日常容量应急、故障切换配合运维体系已经完全自动化,计划内的大促弹性和容灾演练都可以一键完成;一方面是成本降低,首先是 OceanBase 的多租户整合 Oracle/MySQL 长尾业务,优化碎片资源,其次是 OceanBase 的超高数据压缩比。让我印象非常深刻的是,当时支付宝最后一批传统集中式数据库下线,原本需要上百台机器,迁移至 OceanBase 后,10 台左右机器就解决了。
PB级数据归档
随着越来越多的业务迁移到 OceanBase,以及支付宝的业务发展迅猛,我们面临生产库磁盘不足、IOPS 性能下降,以及备份时间变长等问题,数据归档就变得非常重要。
如何高效且低成本地把这些数据归档呢?过去,我们要么引入高端商业存储阵列,要么引入新一代分布式存储。现在,我们只需要用 SATA 盘 X86 加 OceanBase 的分布式能力,就可以轻松搞定单库 PB 级存储。
其实,历史库总结起来就两个核心点,即负载均衡和故障恢复。
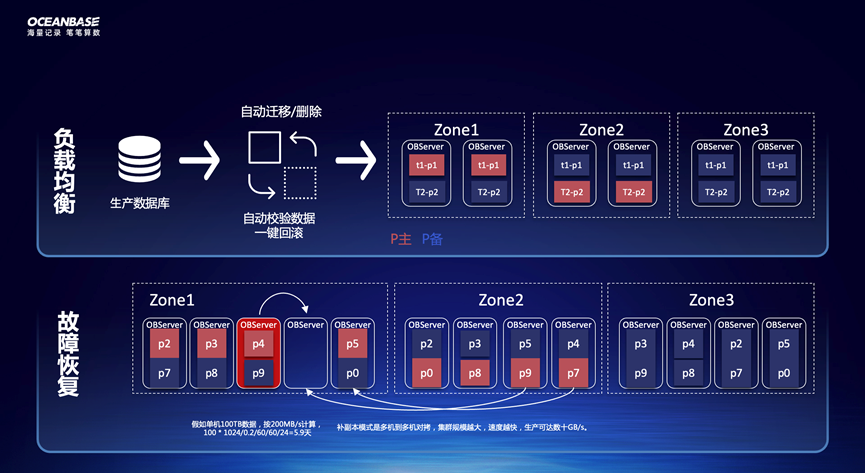
核心点一:负载均衡
负载均衡最主要的目的就是在成本尽量低的情况下让存储利用率和计算资源利用率尽量高。
存储利用率最大化。随着集群规模不断变大,不断接入更多业务,再加上不同年份采购机器型号的差异,会逐渐出现木桶短板效应,少部分机器影响整个集群磁盘使用率,浪费存储的问题。OceanBase 针对该问题做了特殊优化——基于分区级别进行动态的负载均衡,能最大限度利用每台机器的磁盘空间。
计算资源利用率最大化。历史库一般按照时间分区,很容易出现相同月份的分区聚集在少量机器,导致写入热点,压力不均衡。OceanBase 针对该问题也做了特殊优化——为了充分发挥每台机器的计算资源,OceanBase 将不同表相同月份的分区打散到不同机器,所有 Parition 的 leader 也均衡打散到所有机器,分散写入,防止写入热点。
核心点二:故障恢复
不论故障机器是否彻底宕机,替换的新机器都会作为目标迁入数据,瓶颈都在新机器单机的写入能力。按照普通 SATA 盘 200MB/s 的写入能力计算,100TB 数据迁移几乎需要一周时间。过长的替换时间会带来非常多的弊端,如可能出现二次宕机出现单副本,变更周期过长,容易出现失误。
鉴于常规替换时间长的种种弊病,我们利用 OceanBase 的原生分布式能力,加速替换。只需要两步,首先新机器上线,其次故障机器直接永久下线,OceanBase的总控服务 RootService 检测副本缺失,直接走补副本模式,补副本是多机到多机拷贝,生产可达 30-50GB/s,100TB 数据迁移只需两三个小时就可以完成。
支付宝的未来探索
支付宝的业务场景非常丰富,对存储能力的需求也是多样化的,未来,我们 DBA 团队主要会围绕 HTAP 和多模这两方面做一些探索,持续打磨 OceanBase 的能力。
一是 HTAP 方面的探索。目前蚂蚁实现 HTAP 链路复杂,和传统方案一样,订阅在线日志到数仓进行计算,不仅维护成本过高,而且过多依赖第三方组件,经常出现可用性事件。未来我们将在 OceanBase OLTP 能力的基础上扩展 OLAP 的能力,可以实现一个系统、一份数据同时处理交易和实时分析的高性价比方案,“一份数据”的多个副本可以存储成多种形态(行存/列存),用于不同的工作负载。
二是多模方面的探索。过去为了满足一种业务场景对存储的需求,比如文档、KV、时序等,我们需要引入全新的一种数据库,维护多套运维系统,重复建设容灾体系。在未来,我们将在 OceanBase 统一的存储引擎和分布式引擎之上发展多模型能力,实现一份数据,多种访问方式,更加轻松应对多样化的存储需求。
我今天的分享就到这里,希望能对大家有所帮助,谢谢大家。