YOLOV7改进--添加CBAM注意力机制
CBAM注意力机制代码在commen.py中添加CBAM模块在yolo.py中添加CBAM模块名在cfg文件中添加CBAM信息因为项目需要,尝试在yolov7上加入CBAM注意力机制,看看能不能提升点性能。之前有在yolov5上添加CBAM的经验,所以直接把yolov5中的CBAM搬过来,废话不多说,直接看代码吧!
CBAM注意力机制
首先,介绍一下CBAM注意力机制:
论文来源:https://arxiv.org/pdf/1807.06521.pdf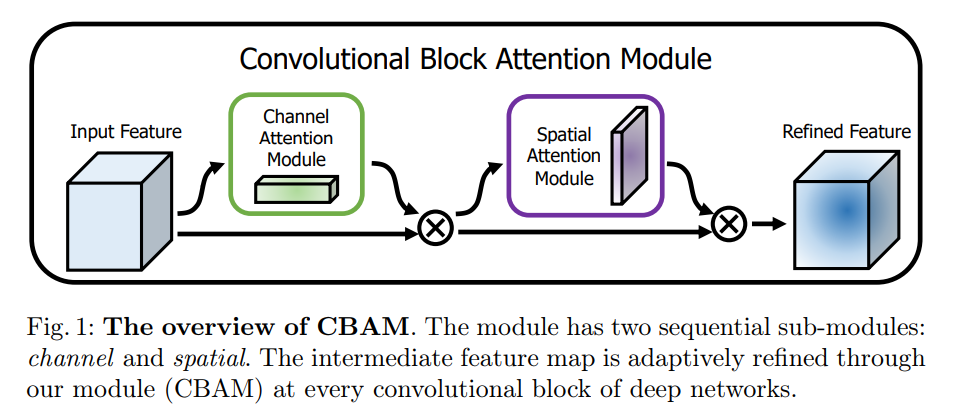
Convolutional Block Attention Module (CBAM)由两个模块构成,分别为通道注意力(CAM)和空间注意力模块(SAM),CAM可以使网络关注图像的前景,使网络更加关注有意义的gt区域,而SAM可以让网络关注到整张图片中富含上下文信息的位置。这两个模块即插即用,建议串行加入到网络中(论文里面是串行比并行好,在博主的数据集下,并行和串行效果不明显,博主认为特征融合没有苛刻的要求,视使用的数据集而定,怎么连效果好就怎么连),下面的展示的代码是串行方法。
代码
在commen.py中添加CBAM模块
这部分代码同yolov5的一样,直接拿来用!
class ChannelAttention(nn.Module): def __init__(self, in_planes, ratio=16): super(ChannelAttention, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) self.max_pool = nn.AdaptiveMaxPool2d(1) self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False) self.relu = nn.ReLU() self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): avg_out = self.f2(self.relu(self.f1(self.avg_pool(x)))) max_out = self.f2(self.relu(self.f1(self.max_pool(x)))) out = self.sigmoid(avg_out + max_out) return outclass SpatialAttention(nn.Module): def __init__(self, kernel_size=7): super(SpatialAttention, self).__init__() assert kernel_size in (3, 7), 'kernel size must be 3 or 7' padding = 3 if kernel_size == 7 else 1 self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): avg_out = torch.mean(x, dim=1, keepdim=True) max_out, _ = torch.max(x, dim=1, keepdim=True) x = torch.cat([avg_out, max_out], dim=1) x = self.conv(x) return self.sigmoid(x) class CBAM(nn.Module): # Standard convolution def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups super(CBAM, self).__init__() self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False) self.bn = nn.BatchNorm2d(c2) self.act = nn.Hardswish() if act else nn.Identity() self.ca = ChannelAttention(c2) self.sa = SpatialAttention() def forward(self, x): x = self.act(self.bn(self.conv(x))) x = self.ca(x) * x x = self.sa(x) * x return x def fuseforward(self, x): return self.act(self.conv(x))在yolo.py中添加CBAM模块名
找到yolo.py第459行,加入CBAM模块名。
if m in [nn.Conv2d, Conv, RobustConv, RobustConv2, DWConv, GhostConv, RepConv, RepConv_OREPA, DownC, SPP, SPPF, SPPCSPC, GhostSPPCSPC, MixConv2d, Focus, Stem, GhostStem, CrossConv, Bottleneck, BottleneckCSPA, BottleneckCSPB, BottleneckCSPC, RepBottleneck, RepBottleneckCSPA, RepBottleneckCSPB, RepBottleneckCSPC, Res, ResCSPA, ResCSPB, ResCSPC, RepRes, RepResCSPA, RepResCSPB, RepResCSPC, ResX, ResXCSPA, ResXCSPB, ResXCSPC, RepResX, RepResXCSPA, RepResXCSPB, RepResXCSPC, Ghost, GhostCSPA, GhostCSPB, GhostCSPC, SwinTransformerBlock, STCSPA, STCSPB, STCSPC, SwinTransformer2Block, ST2CSPA, ST2CSPB, ST2CSPC, CBAM]: c1, c2 = ch[f], args[0] if c2 != no: # if not output c2 = make_divisible(c2 * gw, 8) args = [c1, c2, *args[1:]] if m in [DownC, SPPCSPC, GhostSPPCSPC, BottleneckCSPA, BottleneckCSPB, BottleneckCSPC, RepBottleneckCSPA, RepBottleneckCSPB, RepBottleneckCSPC, ResCSPA, ResCSPB, ResCSPC, RepResCSPA, RepResCSPB, RepResCSPC, ResXCSPA, ResXCSPB, ResXCSPC, RepResXCSPA, RepResXCSPB, RepResXCSPC, GhostCSPA, GhostCSPB, GhostCSPC, STCSPA, STCSPB, STCSPC, ST2CSPA, ST2CSPB, ST2CSPC]: args.insert(2, n) # number of repeats n = 1在cfg文件中添加CBAM信息
这里以添加到backbone为例,将Conv替换成CBAM即可,同样也可在FPN里替换。
# parametersnc: 80 # number of classesdepth_multiple: 1.0 # model depth multiplewidth_multiple: 1.0 # layer channel multiple# anchorsanchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32backbone: # [from, number, module, args] c2, k=1, s=1, p=None, g=1, act=True # [[-1, 1, Conv, [32, 3, 2, None, 1, nn.LeakyReLU(0.1)]], # 0-P1/2 [[-1, 1, CBAM, [32, 3, 2, None, 1, nn.LeakyReLU(0.1)]], # 0-P1/2 # [-1, 1, Conv, [64, 3, 2, None, 1, nn.LeakyReLU(0.1)]], # 1-P2/4 [-1, 1, CBAM, [64, 3, 2, None, 1, nn.LeakyReLU(0.1)]], # 1-P2/4 [-1, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-2, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [[-1, -2, -3, -4], 1, Concat, [1]], [-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 7 [-1, 1, MP, []], # 8-P3/8 [-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [[-1, -2, -3, -4], 1, Concat, [1]], [-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 14 [-1, 1, MP, []], # 15-P4/16 [-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [[-1, -2, -3, -4], 1, Concat, [1]], [-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 21 [-1, 1, MP, []], # 22-P5/32 [-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-2, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [[-1, -2, -3, -4], 1, Concat, [1]], [-1, 1, Conv, [512, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 28 ]# yolov7-tiny headhead: [[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-2, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, SP, [5]], [-2, 1, SP, [9]], [-3, 1, SP, [13]], [[-1, -2, -3, -4], 1, Concat, [1]], [-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [[-1, -7], 1, Concat, [1]], [-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 37 [-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [21, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P4 [[-1, -2], 1, Concat, [1]], [-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [[-1, -2, -3, -4], 1, Concat, [1]], [-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 47 [-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [14, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P3 [[-1, -2], 1, Concat, [1]], [-1, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-2, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [[-1, -2, -3, -4], 1, Concat, [1]], [-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 57 [-1, 1, Conv, [128, 3, 2, None, 1, nn.LeakyReLU(0.1)]], [[-1, 47], 1, Concat, [1]], [-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [[-1, -2, -3, -4], 1, Concat, [1]], [-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 65 [-1, 1, Conv, [256, 3, 2, None, 1, nn.LeakyReLU(0.1)]], [[-1, 37], 1, Concat, [1]], [-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [[-1, -2, -3, -4], 1, Concat, [1]], [-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 73 [57, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [65, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [73, 1, Conv, [512, 3, 1, None, 1, nn.LeakyReLU(0.1)]], [[74,75,76], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]