《用于低分辨率图像和小物体的新 CNN 模块》
《No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects》
2022年8月7日发表在ECML PKDD 2022论文集上的最新paper
作者:来自于 Missouri 大学的 Raja Sunkara and Tie Luo
论文地址:https://arxiv.org/abs/2208.03641v1
项目地址:https://github.com/labsaint/spd-conv
文章目录
《用于低分辨率图像和小物体的新 CNN 模块》1 摘要精读2 SPD-Conv原理2.1 Space-to-depth(SPD)2.2 Non-strided Convolution 3 如何使用SPD-Conv3.1 检测:Yolov5改进方式3.2 分类:ResNet改进方式 4 论文实验结果4.1 目标检测4.2 图像分类 5 YOLOv5官方项目改进教程内容导航
1 摘要精读
卷积神经网络(CNN)在图像分类、目标检测等计算机视觉任务中取得了巨大的成功。然而,在图像分辨率较低或对象较小的更困难的任务中,它们的性能会迅速下降。
这源于现有CNN体系结构中一个有缺陷但却很常见的设计,即使用strided convolution和/或池化层,这导致了细粒度信息的丢失和较低效率的特征表示的学习。为此,我们提出了一种新的CNN模块,称为SPD-Conv,以取代每个strided convolution和每个池化层(从而完全消除了它们)。SPD-Conv由 space-to-depth (SPD)层和non-strided convolution(Conv)层组成,可以应用于大多数CNN架构。
我们在两个最具代表性的计算机视觉任务下解释了这种新的设计:目标检测和图像分类。然后,我们通过将SPD-Conv应用于YOLOv5和ResNet来创建新的CNN架构,实验表明我们的方法显著优于最先进的深度学习模型,特别是在处理低分辨率图像和小对象的更困难的任务时。
2 SPD-Conv原理
2.1 Space-to-depth(SPD)
SPD-Conv 由一个SPD层和一个non-strided convolution层组成,SPD组件将(原始)图像转换技术推广到对 CNN 内部和整个CNN中的特征图进行下采样,如下所示
考虑任何大小为 S × S × C 1 S × S × C1 S×S×C1的中间特征图 X X X,切出一系列子特征图为
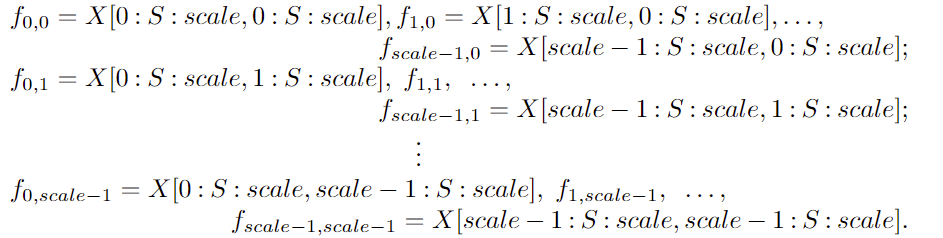
一般来说,给定任何(原始)特征图 X X X,子图 f x , y f_{x,y} fx,y由 i + x i+x i+x 和 i + y i+y i+y 可按比例整除的所有条目 X ( i + y ) X(i+y) X(i+y) 形成。因此,每个子图按比例因子对 X X X进行下采样。下图给出了 s c a l e = 2 scale=2 scale=2时的例子,得到4个子图 f 0 , 0 f_{0,0} f0,0 , f 1 , 0 f_{1,0} f1,0 , f 0 , 1 f_{0,1} f0,1 , f 1 , 1 f_{1,1} f1,1 每个都具有形状 ( S / 2 , S / 2 , C 1 ) (S/2,S/2,C_1) (S/2,S/2,C1)并将 X X X下采样 2 2 2 倍。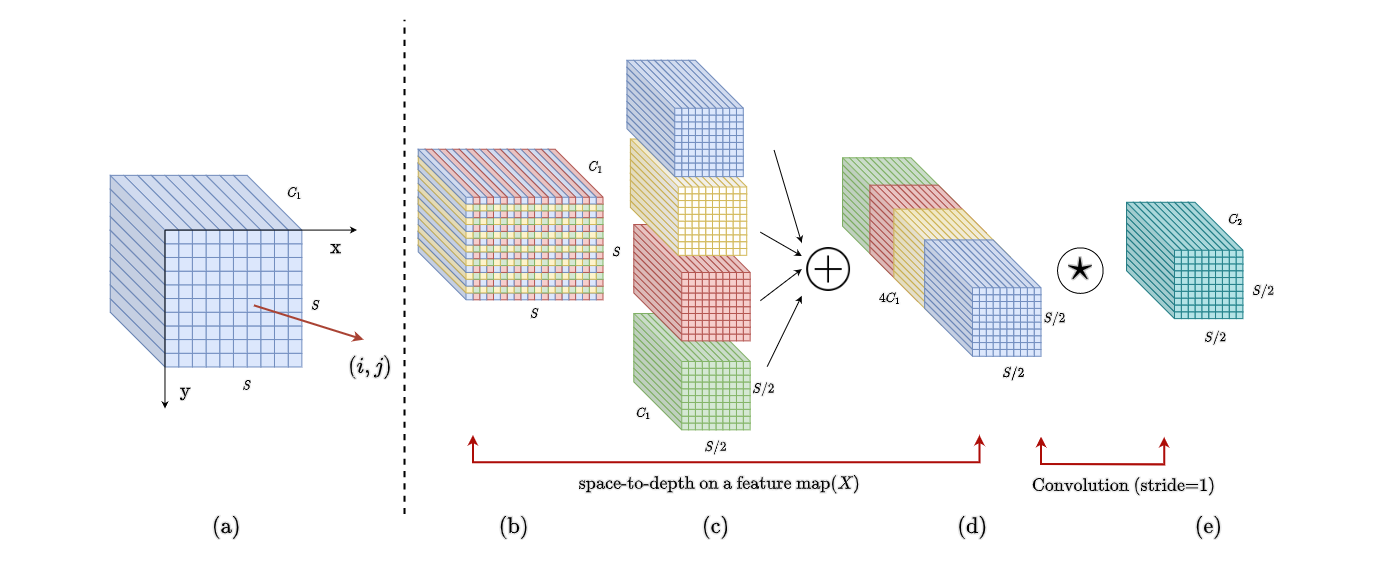
接下来,沿着通道维度连接这些子特征图,从而获得一个特征图 X ′ X' X′,它的空间维度减少了一个比例因子,通道维度增加了一个比例因子 2 2 2。换句话说,SPD将特征图 X ( S , S , C 1 ) X(S,S,C_1) X(S,S,C1) 转换为中间特征图 X ′ ( S / s a c l e , S / s a c l e , s c a l e 2 C 1 ) X'(S/sacle,S/sacle,scale^2C_1) X′(S/sacle,S/sacle,scale2C1)
2.2 Non-strided Convolution
在SPD特征变换层之后,添加了一个带有 C 2 C_2 C2滤波器的非跨步(即 stride=1)卷积层,其中 C 2 < s c a l e 2 C 1 C_2<scale^2C_1 C2<scale2C1 ,并进一步变换 X ′ ( S / s a c l e , S / s a c l e , s c a l e 2 C 1 → X ′ ′ ( S / s a c l e , S / s a c l e , C 2 ) X'(S/sacle,S/sacle,scale^2C_1→X''(S/sacle,S/sacle,C_2) X′(S/sacle,S/sacle,scale2C1→X′′(S/sacle,S/sacle,C2) 。
使用非跨步卷积的原因是尽可能地保留所有的判别特征信息。否则,例如,使用 s t r i d e = 3 stride=3 stride=3 的 3 × 3 3×3 3×3 卷积,特征图将“缩小”,但每个像素只采样一次;如果 s t r i d e = 2 stride=2 stride=2,将发生不对称采样,其中偶数和奇数行/列的采样时间不同。一般来说,步长大于 1 1 1 会导致信息的非歧视性丢失,尽管在表面上,它似乎转换了特征图 X ( S , S , C 1 ) → X ′ ′ ( S / s a c l e , S / s a c l e , C 2 ) X(S,S,C_1)→X''(S/sacle,S/sacle,C_2) X(S,S,C1)→X′′(S/sacle,S/sacle,C2)(但没有 X ′ X' X′)
3 如何使用SPD-Conv
为了解释如何将提出的方法应用到重新设计CNN架构中,使用了2个最具代表性的计算机视觉模型类别:目标检测和图像分类
3.1 检测:Yolov5改进方式
并且作者将这个模块应用到了YOLOv5中,取得了很好的效果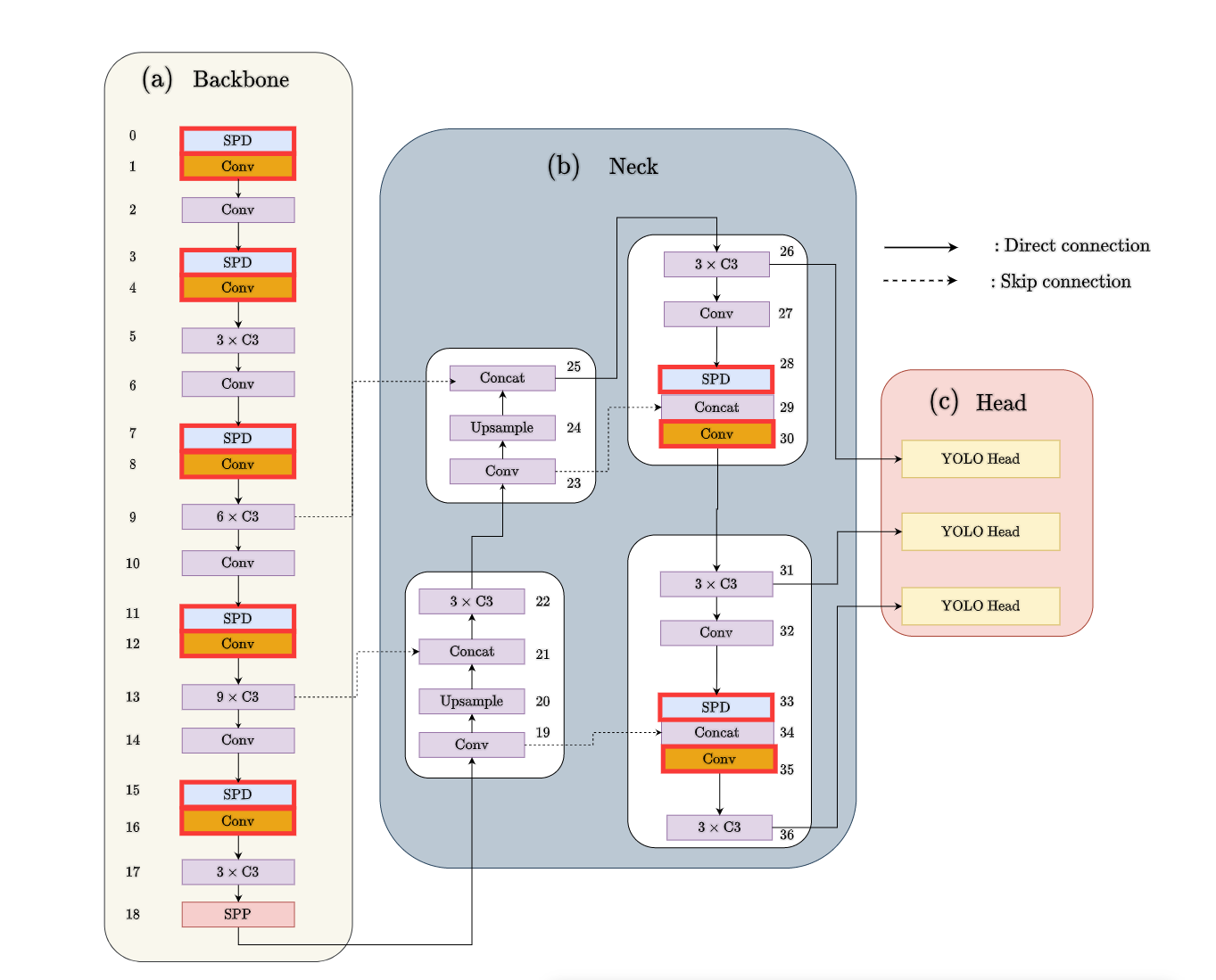
YOLOv5-SPD:将第 3 节中描述的方法应用于YOLOv5并获得 YOLOv5-SPD,只需用 SPD-Conv 替换YOLOv5 s t r i d e − 2 stride-2 stride−2 卷积即可。这种替换有 7 7 7 个实例,因为 YOLOv5 在主干中使用 5 5 5个 s t r i d e − 2 stride-2 stride−2 卷积层将特征图下采样 25 25 25 倍,并在颈部使用 2 2 2个 s t r i d e − 2 stride-2 stride−2 卷积层。YOLOv5颈部的每个跨步卷积之后都有一个连接层;这不会改变本文的方法,只是将它保持在 SPD 和 Conv 之间。
可扩展性:YOLOv5-SPD 可以通过与 YOLOv5 相同的方式轻松扩展和缩减来适应不同的应用程序或硬件需求
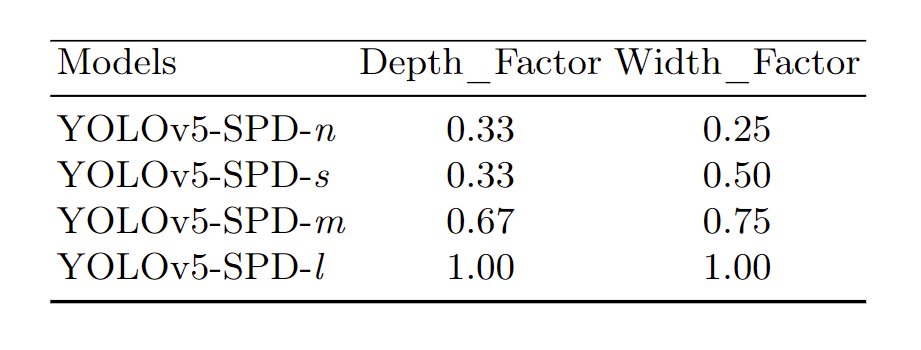
具体来说,可以简单地调整(1)每个非跨步卷积层中的过滤器数量和/或(2)C3模块的重复次数(如图4所示),以获得不同版本的YOLOv5-SPD
第1个称为宽度缩放:它将原始宽度 n w nw nw(通道数)更改为 n w × w i d t h f a c t o r e nw × width_f actore nw×widthfactore(四舍五入到最接近的 8 倍数)
第2个称为深度缩放:它将原始深度 n d nd nd(重复 C3 模块的次数;例如,图 4 中的 9 × C 3 9 × C3 9×C3 中的 9)更改为 n d × d e p t h f a c t o r nd × depth_factor nd×depthfactor
这样,通过选择不同的宽度/深度因子,我们得到了YOLOv5-SPD的nano、small、medium和large版本,如表2所示,其中因子值选择与YOLOv5相同,以便在后面的实验中进行比较 .
3.2 分类:ResNet改进方式
分类 CNN通常从一个由 s t r i d e − 2 stride-2 stride−2 卷积和池化层组成的stem单元开始,以将图像分辨率降低 4 4 4倍。一个流行的模型是 ResNet,它赢得了 ILSVRC 2015 挑战。ResNet引入了残差连接,以允许训练高达 152 152 152 层的网络。它还通过仅使用单个全连接层显着减少了参数的总数。最后使用 softmax层对类预测进行归一化。
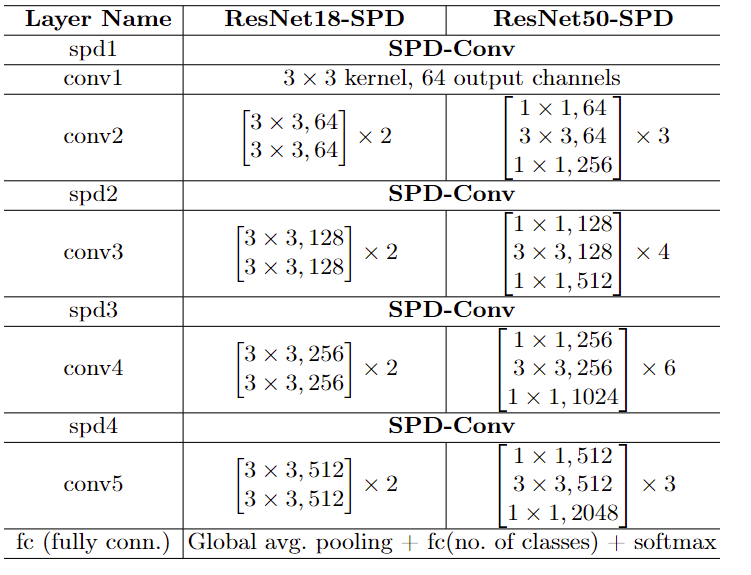
ResNet-18和ResNet-50都使用总共 4 4 4个 s t r i d e − 2 stride-2 stride−2卷积和一个 s t r i d e 2 stride 2 stride2的最大池化层,将每个输入图像下采样 25 25 25倍。应用我们提出的构建块,用SPD-Conv替换了四个跨步卷积;但另一方面,我们只是删除了最大池化层,因为我们的主要目标是低分辨率图像,我们实验中使用的数据集的图像相当小(Tiny ImageNet 中为 64 × 64 64 × 64 64×64,CIFAR-10中为 32 × 32 32 × 32 32×32)因此不需要池化, 对于更大的图像,这样的最大池化层仍然可以用SPD-Conv以相同的方式替换
4 论文实验结果
4.1 目标检测
MS-COCO 验证数据集的比较(val2017)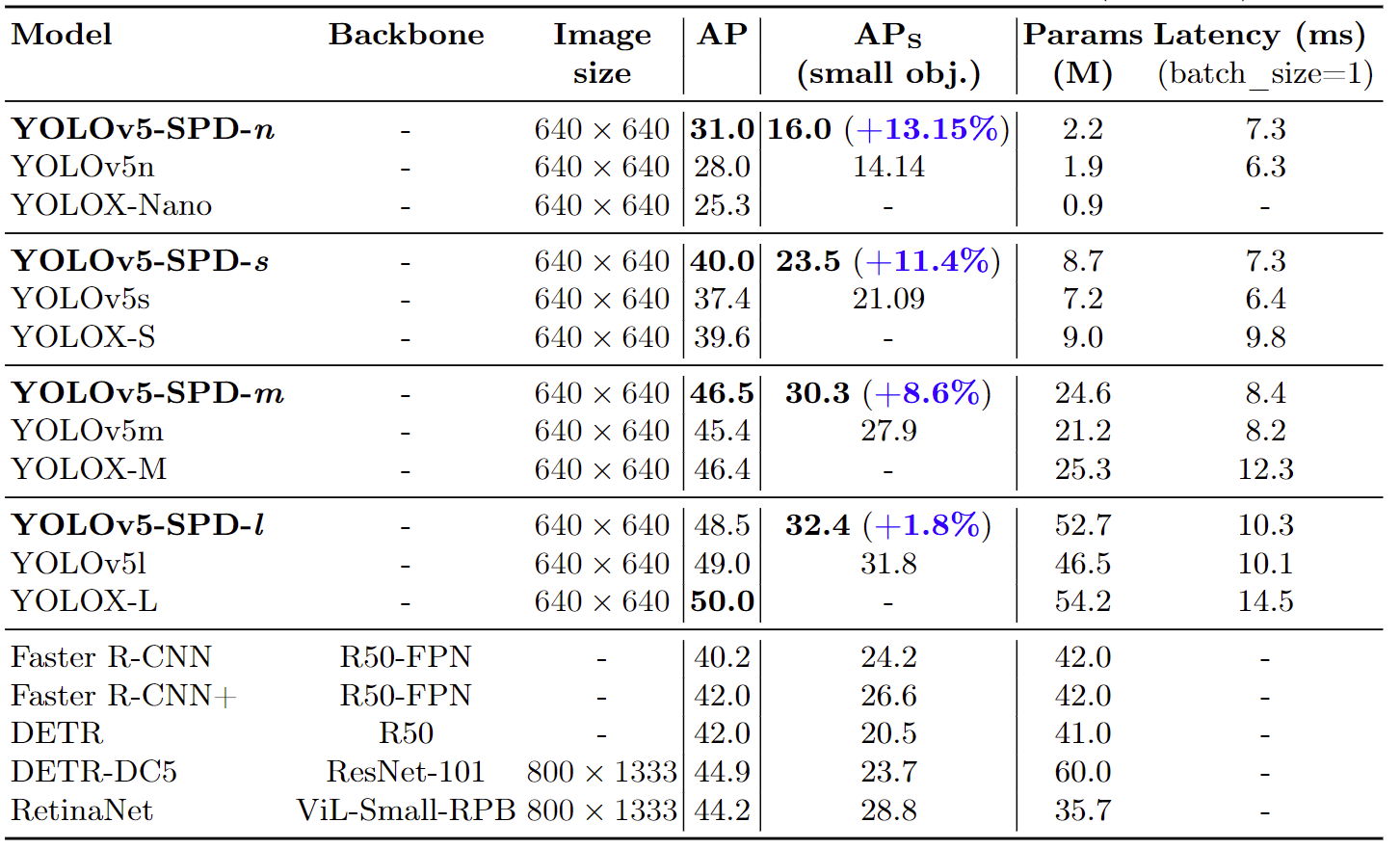
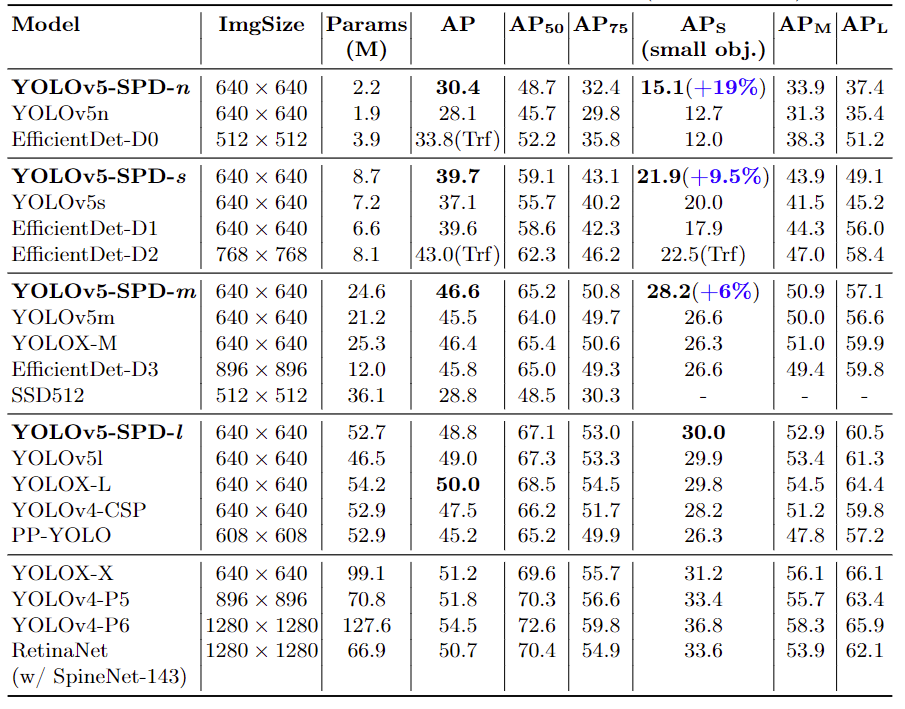

4.2 图像分类
图像分类性能比较
5 YOLOv5官方项目改进教程
YOLO Magic项目同步更新
第一步:
common.py中添加如下代码
class space_to_depth(nn.Module): # Changing the dimension of the Tensor def __init__(self, dimension=1): super().__init__() self.d = dimension def forward(self, x): return torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)第二步;yolo.py中添加如下代码
elif m is space_to_depth: c2 = 4 * ch[f]第三步;修改配置文件(以为yolov5s为例)
其它版本依然可以通过调整宽度和深度控制
# Parametersnc: 80 # number of classesdepth_multiple: 0.33 # model depth multiplewidth_multiple: 0.50 # layer channel multipleanchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbonebackbone: # [from, number, module, args] [[-1, 1, Focus, [64, 3]], # 0-P1/2 [-1, 1, Conv, [128, 3, 1]], # 1 [-1,1,space_to_depth,[1]], # 2 -P2/4 [-1, 3, C3, [128]], # 3 [-1, 1, Conv, [256, 3, 1]], # 4 [-1,1,space_to_depth,[1]], # 5 -P3/8 [-1, 6, C3, [256]], # 6 [-1, 1, Conv, [512, 3, 1]], # 7-P4/16 [-1,1,space_to_depth,[1]], # 8 -P4/16 [-1, 9, C3, [512]], # 9 [-1, 1, Conv, [1024, 3, 1]], # 10-P5/32 [-1,1,space_to_depth,[1]], # 11 -P5/32 [-1, 3, C3, [1024]], # 12 [-1, 1, SPPF, [1024, 5]], # 13 ]# YOLOv5 v6.0 headhead: [[-1, 1, Conv, [512, 1, 1]], # 14 [-1, 1, nn.Upsample, [None, 2, 'nearest']], # 15 [[-1, 9], 1, Concat, [1]], # 16 cat backbone P4 [-1, 3, C3, [512, False]], # 17 [-1, 1, Conv, [256, 1, 1]], # 18 [-1, 1, nn.Upsample, [None, 2, 'nearest']], # 19 [[-1, 6], 1, Concat, [1]], # 20 cat backbone P3 [-1, 3, C3, [256, False]], # 21 (P3/8-small) [-1, 1, Conv, [256, 3, 1]], # 22 [-1,1,space_to_depth,[1]], # 23 -P2/4 [[-1, 18], 1, Concat, [1]], # 24 cat head P4 [-1, 3, C3, [512, False]], # 25 (P4/16-medium) [-1, 1, Conv, [512, 3, 1]], # 26 [-1,1,space_to_depth,[1]], # 27 -P2/4 [[-1, 14], 1, Concat, [1]], # 28 cat head P5 [-1, 3, C3, [1024, False]], # 29 (P5/32-large) [[21, 25, 29], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]| 模型 | 参数量parameters | 计算量GFLOPs |
|---|---|---|
| yolov5s | 7235389 | 16.5 |
| yolov5s_SPD | 8771389 | 33.9 |
| yolov5n_SPD | 2256157 | 8.9 |
| yolov5m_SPD | 24646557 | 88.0 |
| yolov5l_SPD | 52707709 | 178.6 |
内容导航
本人更多改进YOLOv5内容导航
1.手把手带你调参Yolo v5 (v6.1)(一)?强烈推荐
2.手把手带你调参Yolo v5 (v6.1)(二)?
3.如何快速使用自己的数据集训练Yolov5模型
4.手把手带你Yolov5 (v6.1)添加注意力机制(一)(并附上30多种顶会Attention原理图)?
5.手把手带你Yolov5 (v6.1)添加注意力机制(二)(在C3模块中加入注意力机制)
6.Yolov5如何更换激活函数?
7.Yolov5 (v6.1)数据增强方式解析
8.Yolov5更换上采样方式( 最近邻 / 双线性 / 双立方 / 三线性 / 转置卷积)
9.Yolov5如何更换EIOU / alpha IOU / SIoU?
10.Yolov5更换主干网络之《旷视轻量化卷积神经网络ShuffleNetv2》?
11.YOLOv5应用轻量级通用上采样算子CARAFE?
12.空间金字塔池化改进 SPP / SPPF / ASPP / RFB / SPPCSPC?
13.持续更新中
觉得有帮助请点赞支持一下?,如多觉得有问题欢迎指正?