前言
等到了我们学校的数据挖掘课程,就从最简单的pandas开始记录我的数据挖掘学习历程吧!希望这份手册能在之后需要的时候帮助到大家。
pandas使用手册
第一部分:series基础
操作参考:
创建series
取一个元素
取多个元素
赋值
Series间的计算
Series函数的使用
使用apply
练习题:
第二部分:dataframe基础
操作参考:
创建DataFrame
查看DataFrame信息
取一个列成一个series
取多个列成一个DataFrame
条件读取
取出一行成为series
赋值
groupby操作
使用apply
生成一列series数据的便捷方法:
练习题:
第三部分:dataframe绘图
操作参考:
条件删除行
直方图
散点图
箱型图
series基础
操作参考:
创建series
>>> ser2 = Series(range(4),index = ["a","b","c","d"])取一个元素
>>> ser2["a"]>>> ser2[1]取多个元素
>>> ser2[1:3]>>> ser2[['a', 'c']]赋值
>>> ser2["a"] = 7 #赋一个值>>> ser2[1:3] = 10 #批量赋值>>> ser2[['a', 'c']] = [9, 8]Series间的计算
>>> print(a + b) >>> print(a * 2)>>> print(a >= 3) #产生true false的新series>>> print(a[a >= 3]) #取出true false series的对应的值成series,相当于where条件Series函数的使用
>>> print(a.mean()) #均值>>> print(a.sum()) #求和使用apply
>>> print(a.apply(lambda x:x**2)) #全部平方练习题:
创建一个6个元素的Series, 值是[4,5,6,7,8,9], index是 ‘a’到 ‘f’两种方法取ser的第二个元素求ser的平均值和中位数找到ser中所有偶数:包含判断以及取数两部分将ser中所有偶数,改成10,12,14将ser中所有偶数,改成2将ser中所有偶数,翻倍将ser应用自定义函数,当数字是奇数,翻倍;当数字是偶数,除以2dataframe基础
操作参考:
创建DataFrame
>>> df = pd.DataFrame([[1,2,3], [6,7,8]],columns= ["a","b","c"])>>> df = pd.DataFrame({'country':['aaa','bbb','ccc'], 'population':[10,12,14]})>>> df = pd.read_csv("yours.csv")查看DataFrame信息
>>>df.info()>>>df.index>>>df.columns>>>df.dtypes>>>df.values取一个列成一个series
>>> df["a"]>>> df.loc[:, 'a']取多个列成一个DataFrame
>>> df[["a","c"]]>>> df.loc[[1,2], ['a']] #只取两行a列条件读取
>>> df[df['a'] > 3]>>> df[(df['a'] > 3) & (df['b']< 8)]取出一行成为series
>>> df.iloc[0]赋值
>>>df['a'] = [1,2,3] #注意行数一致 >>>df[['a', 'c']] = 8 #若要取指定行,需要用loc或iloc>>>df.loc[:, 'd'] = df.loc[:, 'b'] #将b列赋值到新的d列>>>df.loc[df['b'] < 3, 'c'] = df.loc[df['b'] < 3,'d'] #将b<3 的d列赋值到c列 注意两边的条件要一样,才能满足索引一致的要求,否则赋值越界groupby操作
>>> df = pd.DataFrame({'key':['A','B','C','A','B','C','A','B','C'],'data':[0,5,10,5,10,15,10,15,20]})>>> df.groupby('key').sum() #按key成组,每组所有列求和>>> df.groupby('key')['data'].mean() #按key成组,每组求均值,取data列的聚合结果series>>> for key, gdata in df.groupby('Sex'): #gdata是一个DataFrame>>>print(key, gdata.values) 使用apply
>>>def my_min(a, b): #先定义函数 return min(abs(a),abs(b))>>>df1['k'] = df.apply(lambda row: my_min(row['val_1'], row['val_2']), axis=1) #使用匿名函数传每行的特定列, 返回一个series 再赋值到k列,注意axis=1、生成一列series数据的便捷方法:
>>> df['val_1'] = df['value'].diff(k) #同列逐行向上/下相减>>> df['val_2'] = df[''value'].shift(k) #所有行向上/下移动k位练习题:
读取天气的数据文件weather.csv用apply实现一列rain = rain08+rain20;若一边存在999990,则返回999990按station补前一天日期: 按station分组,每组内部,使用shift方法将前一天的数据移动到今天按城市补全rain08: 按city分组,将同一天内rain08中999990的值,替换成同城所有station的rain08的非999990的 均值,如果都缺失则补0;dataframe绘图
操作参考:
条件删除行
df = df.drop( df[ ( df['value'] < 50) & ( df['value'] > 20)].index)其中drop传入的是 df条件取出的的index
直方图
df['temperature'].plot.hist( bins = 20)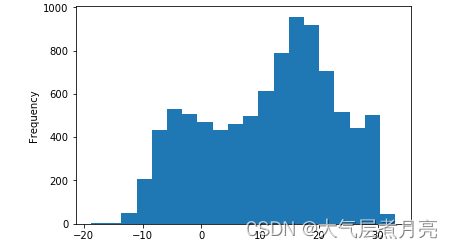
散点图
df.plot.scatter(x = 'humidity', y = 'temperature')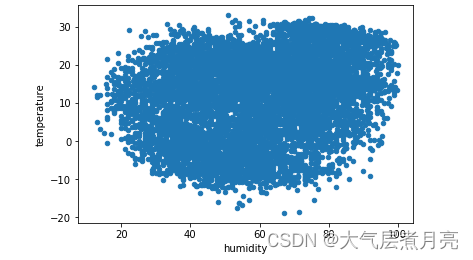
箱型图
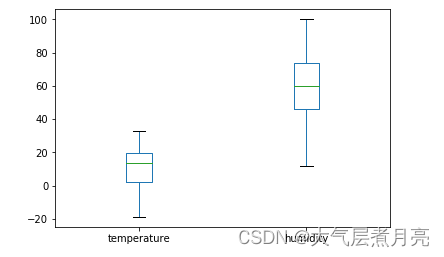
df[['temperature', 'humidity']].plot.box()