1、前言
其实感觉自己做的这点sql优化也算是比较常规的,没什么太大的难度。
最近上线了一个新系统,刚试点运行,用户量不大还没什么大问题。但随之培训和大规模用户开始使用后,问题出现了。而且出现了好多问题,大部分都是后端的,这里就不细讲了。说说与我前端相关的吧。由于我会一点后端。
后端准备叫我开mysql客户端,删除多余的数据
删就删吧,但是要删除的多余数据还有点多
删除以后发现,还他妈有好多要删除的数据,原来三个后端也同时在删除数据
于是我优化了三次sql语句,轻松实现批量删除
如果下次再有这种类似的情况,我得写个相关的小工具了
真的太浪费时间了,也不明白后端为啥不想想办法呢?可能是因为线上bug的压力,没空想吧
2、看看重复记录
根据这三个筛选条件,本来是可以确定唯一记录的。可是并没有,有的记录甚至七八条重复的。

现在要做的就是把重复记录都只保留一条。
3、开始删除重复记录
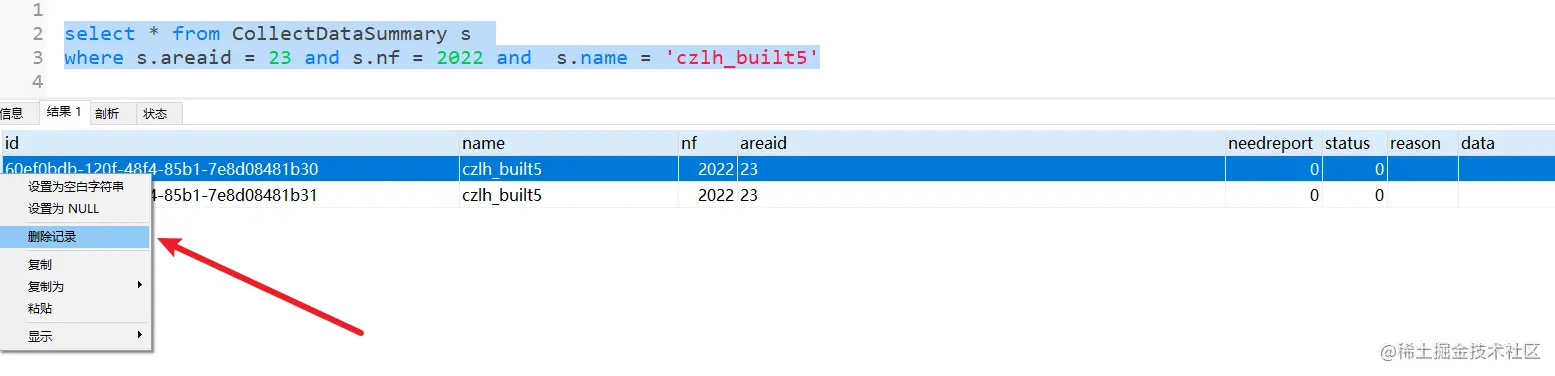
我这是在Navicat工具里删除的,如果只有一条或者几条重复记录这样删删也就完了。但是后端大佬给了100个areaid。年份是固定的2022没什么好说的,每个areaid下的name有89个不重复的。如果一个name一个name的删除要到猴年马月了。这里如上图所示就删除其中一条就好了。

这里是后端给我的要删除的areaid,也就是具体的name是不太清楚的,因为太多了,还得自己去查。
4、优化删除
因为这是三个查询条件下的数据,如果不加name,把所有这个areaid下的,所有的name 数据可能就有很多了,每次要根据给的areaid进行查询(年份是固定的这里我就不说了)
select s.name as 'sname', s.* from CollectDataSummary s where s.areaid = 23 and s.nf = 2022 order by s.name desc 复制代码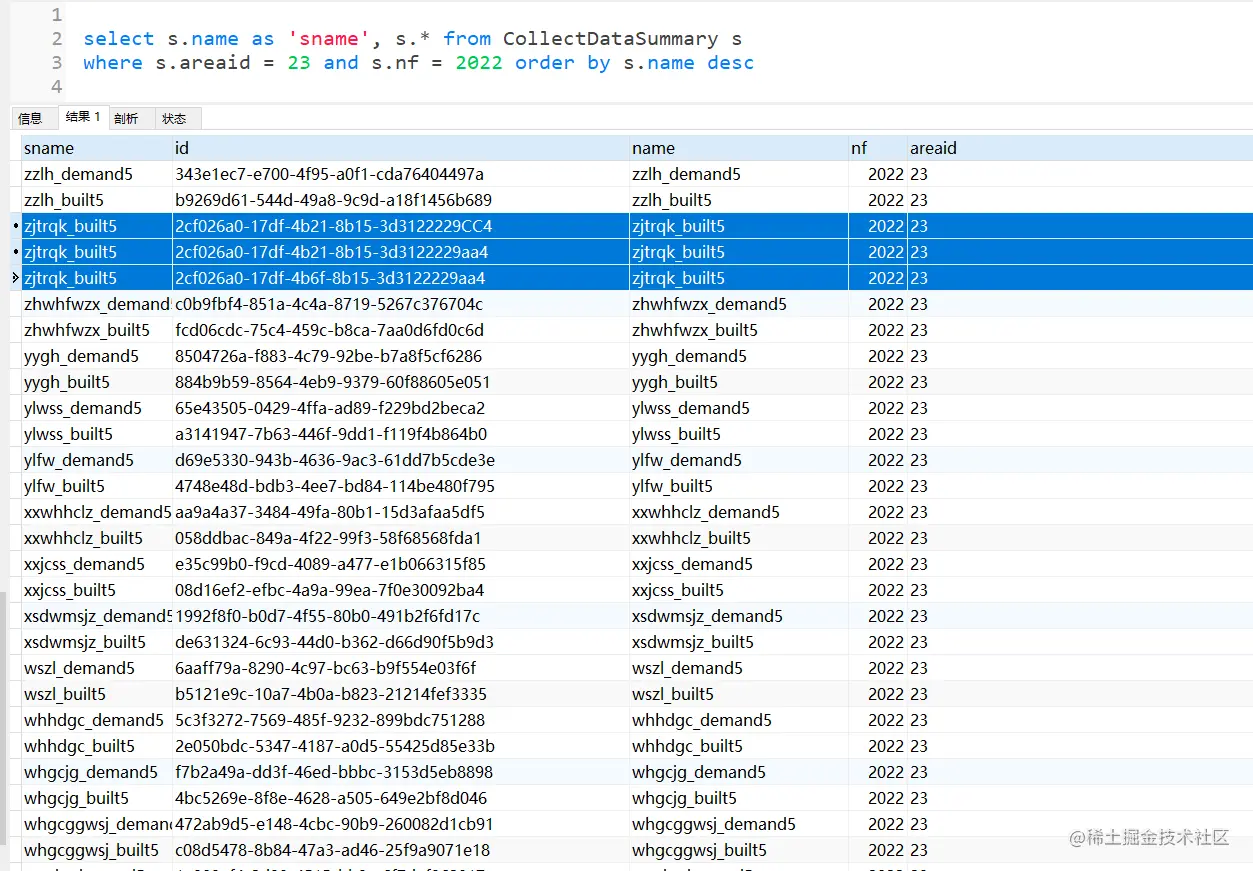
可以看到我只是加了一个排序,然后最上面几条就可以看出三条记录是重复的就要进行删除其中的两条。其实这里正式环境用户量很多,产生一样的数据也非常多,所以删除起来还是比较麻烦的。
这里我想了一下,先查出一个areaid下有重复记录的name
select s.name from CollectDataSummary s where s.areaid = 23 and s.nf = 2022 group by s.`name` HAVING count(s.`name`)> 1复制代码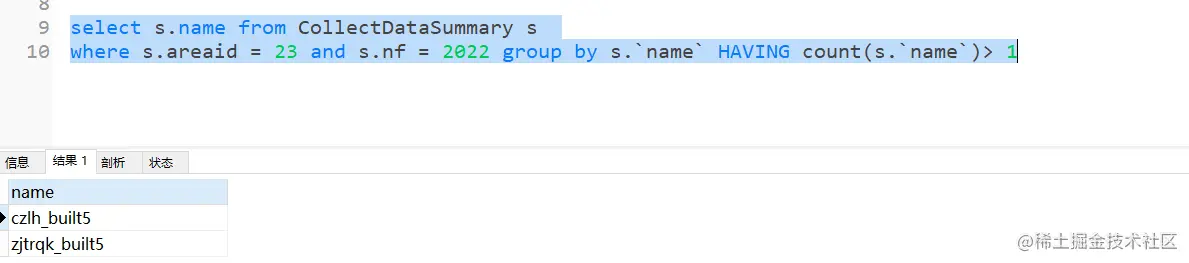
然后再查询一次,将上面查询的重复的name也作为条件进行查询
select * from CollectDataSummary c where c.areaid = 23 and c.nf = 2022 and c.name in (select s.name from CollectDataSummary s where s.areaid = 23 and s.nf = 2022 group by s.`name` HAVING count(s.`name`)> 1)复制代码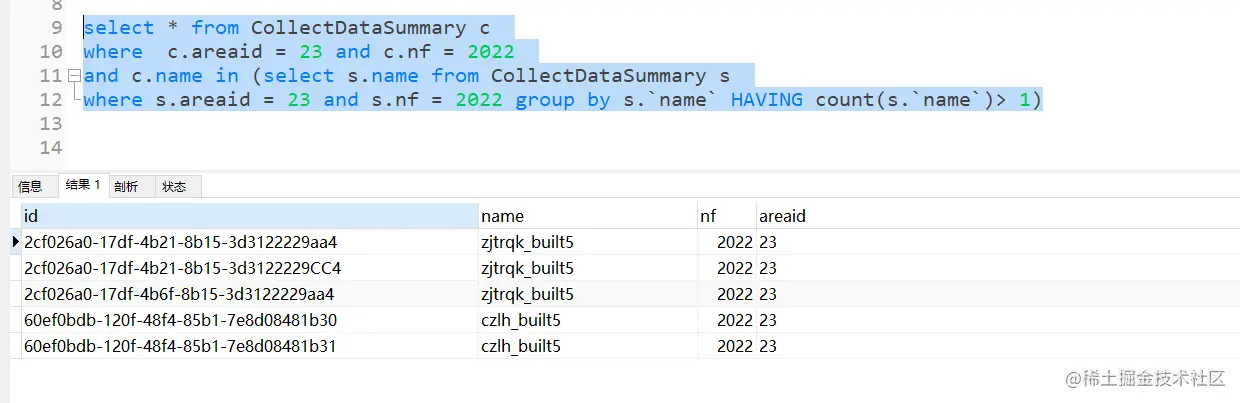
这样查出来可以发现,可以点点将重复的记录都进行删除。勉强一下干了半个小时,我把后端给我的areaid都删除了。
并且我把我这个sql给他们,他们三个后端也在进行删除了,一顿操作后,我手里的这一批几十个删完了。
然后我问了一下都删完了吗,尼玛还有好多好多,按照现在这样删除,他们三个人可能还要删除三个小时,于是我又陷入了沉思.....
5、再次优化删除
想了想,我可以根据name进行分组,然后其实就是只选择了相同数据的其中一行
select a.id from CollectDataSummary a where a.areaid in (23) and a.nf=2022 group by a.name having count(a.name)>1复制代码这样的话,我就把这些数据留下吧,然后结合了一下4、优化删除中的sql
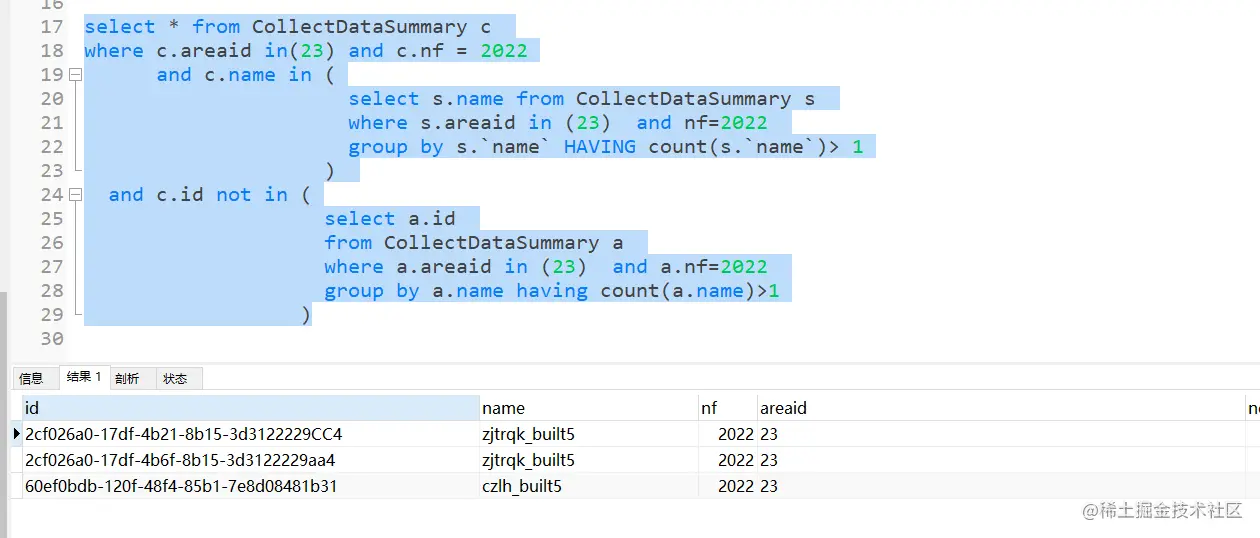
把通过group by 单独查询出来的一组数据通过not in 过滤掉,这样就留下这组数据,其他所有的数据都是要删除的,这样的话就是查询出来的数据,Ctrl + A全选再加上 Delete就完事了,还是非常的方便
6、总结
虽然我觉得这次我帮了大忙,但是这点sql好像也没啥技术含量
其实我想到还可以直接写个delete语句的,但是这样只能看到删除的数据量
然后再不行写一个存储过程将要删除的areaid传进去,循环慢慢删除
还有大招我直接写个页面调用接口来删除,可能更灵活一些,当然要做好检查和确认
第二天想去再看看的时候,数据库已经访问不了了,行吧,继续搞我的前端吧,有空去试试mysql的存储过程,免的啥时候真能派上用场。