经过前六章的阅读,我从三个世界、数据法则、信息纽带、知识升华、自然智能以及人工智能六个方面对于信息科学技术与创新有了深层次的认识与了解。从对于三个世界的描述中,我了解到了物理、生物和数字世界的区别和联系。同时也明白了物质、能量与数据构成了人类所赖以生存和发展的客观和主观世界。通过这样的三个世界基本底层架构的认知,展开了之后的讨论,之后详细地了解到数据的作用,例如数据在生命的产生与演化中起着至关重要的作用,在生命体内DNA中的数据就记录了遗传的基本信息,大脑中的储存数据量与神经元细胞和它们的数量存在着正相关的关系。 数据之间的快速传导使各网络之间可以不考虑地理上的联系而重新组合在一起。信息的传递和交换也变得日益频繁。而在之后对于信息的定义及作用介绍之中,通过对于信息法则的介绍以及对于信息编码过程的展示,让我明白了信息的结构、含义与效用。信息的提取与升华成为知识,我对知识的描述性与程序性、显性与隐性、公共性与私密性有了进一步的认识。由知识的不断进化集合的过程中,自然智能也逐渐彰显出其作用,自然智能也拥有其法则。无独有偶,针对于自然智能的研究也不断启发着人工智能的发展。上一章重点讲述了人工智能的历史、概念、算法以及人工智能的面临障碍。使我对于人工智能的理解有了很大提升。本章就人工智能的应用技术进行了更深层次的分析与讲解。同时本章讨论的课题如下:

(本章讨论的课题)
一、卷积神经网络
在对于人工智能的研究之中,科学家们将目光由限制在一定规则内的棋牌类竞技的算法研究转向了更加广阔的更加复杂多样的现实环境之中,作为人工智能的应用,它的数据来源多种多样,但是最为直接,也最为实际的便是视觉所获得的数据,如何收集并且处理视觉数据成为了人工智能研究的领域之一。
以人类的视角来看,在看到实在物体之后,经过多次观察与记忆便可以在再次看到相同物体时准确地分辨出来事物的外形特征,这是自然智能基于构造层面所给予我们的特性。但是与人类不同,传统机器并没有自然智能的一系列特性,因此它们对于物体图像的识别能力非常低。科学家们常常采取数学的方式描述这一问题,即:基于视觉自然感知与识别能力相当于将极高维度的图像数据空间中某些特征或模式信息经过感官和大脑处理后转化为知识映射到一个低维度的特征空间,在数学上可以用流型空间模型描述。
虽然人类对于生物神经系统的认知并非十分透彻,但针对于这个问题,科学家采取了人工神经网络的算法进行应对。并随着机器深度学习算法的不断进步,对于物体识别与图像处理的机器应用与研究方面也有很大的帮助。不仅如此,人工神经网络的算法也在不断地完善与创新。从最开始地手写数字的自动识别时开始传统神经网络的应用。但是这种图像识别首先需要大量的正负标记的物体样本数据,然后使用选定的神经网络和损失函数模型通过监督学习的方法进行训练,以确定网络中不同神经元的权重。学习过程中的知识是成功的关键。为了增强网络的表达能力,需要足够数量的隐藏层和神经网络中的神经元数量。由于一般图像中包含的像素数量非常多,相应的神经网络的参数量也很大。虽然理论上全连接神经网络可以将包含图像的高纬度像素空间映射到代表类别的低纬度特征空间,但实际应用中所需的神经元参数空间是巨大的,尤其是隐藏层增加了训练成本和难度也大大增加,在很大程度上影响了手写图片的识别准确率。
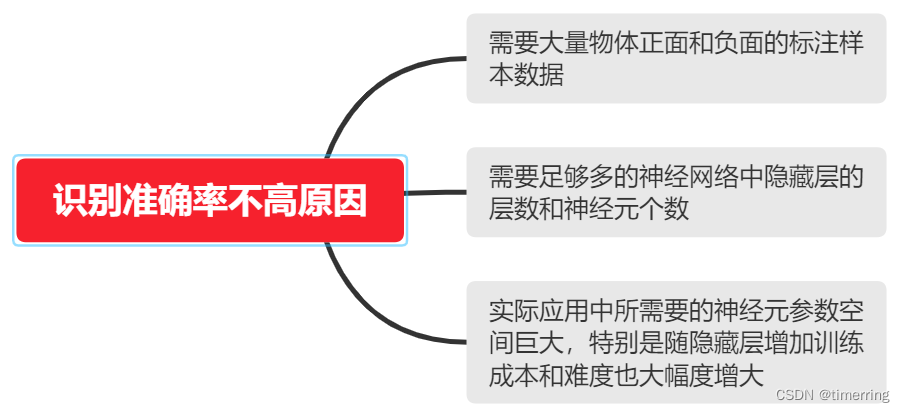
(识别准确率不高原因)
相较于传统的神经网络带来的种种不便,法裔美国计算机学家杨立昆1989年发明了卷积神经网络。这项研究成果是人工智能深度学习历史上划时代的里程碑,其核心思想得益于美国神经学家大卫·休伯尔和托斯坦·威泽尔对动物视觉神经感知过程的研究成果,也受到日本计算机科学家福島邦彦的新认知子理论模型的启发。
(卷积神经网络的发展历程)
卷积神经网络的基本结构由输入层、卷积层、池化层(也称为取样层)、全连接层及输出层构成。卷积层和池化层一般会取若干个,采用卷积层和池化层交替设置,即一个卷积层连接一个池化层,池化层后再连接一个卷积层,依此类推。由于卷积层中输出特征面的每个神经元与其输入进行局部连接,并通过对应的连接权值与局部输入进行加权求和再加上偏置值,得到该神经元输入值,该过程等同于卷积过程。[1]
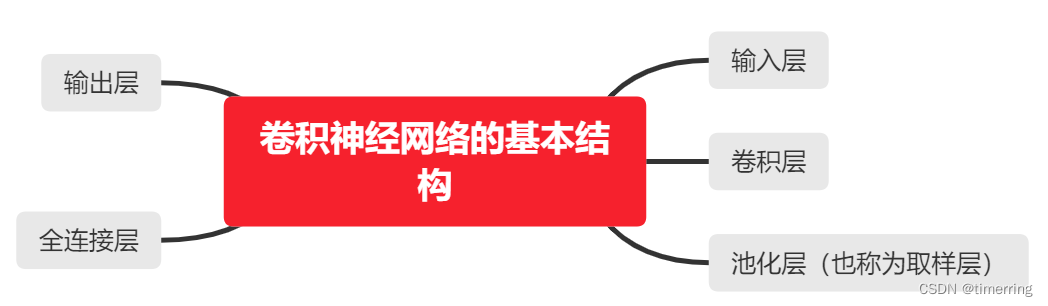
(卷积神经网络的基本结构)
同样,图像识别的实质是将图像的像素数据经过某种压缩编码提取其中物体的语义信息,卷积神经网络发挥着关键的作用,它通过使用低维度卷积核或滤波器对图像的局部像素空间进行卷积,然后进入神经元激活来提取图像的特征,所产生图像被称为特征图。接下来可以对卷积后的特征图进行池化,即首先用滤波器在特征图按给定步长移动,每次对每个区域的元素通过“平均”或“最大”化操作进行数据压缩,从而产生一组维度更低的特征图。
卷积网络相邻连接的局部性导致整体连接的稀疏性,有助于减少训练过程中的过度拟合,提高的网络的泛化能力。使用同一滤波器以实现参数共享,不仅大大减少的网络的参数空间,也在一定程度上确保了特征对位移、拉伸和旋转的相对不变性,从而提高了算法的鲁棒性。在深度学习神经网络中,一般均采取多个“卷积-激活-池化”层分级提取图像的特征信息,不断对原始图像数据进行压缩编码最终通过完全连接网络实现图像分类与识别。[2]
卷积神经网络由浅到深、从局部到全局,通过不断提取和压缩图像的特征数据,最终实现对图像中数字识别的过程。
在这个过程中“编码-解码”的基本规则不可忽视。卷积神经网络通过不断卷积和池化编码提取图像的宏观特征和语义,但同时会损失图像的空间分辨率和局部特征。为了平衡全局物体分类和局部物体定位之间的矛盾,科学家采用了通过数据扩展的“上采样”提高图像的分辨率和获取图像的局部特征,这种方式很好地弥补了卷积池化这种数据压缩的“下采样”带来的问题。韩国浦项工科大学的研究者在标准卷积网络上附加一个对称的“反卷积”网络,对卷积网络产生的特征图进行对应的上采样,最终输出与输入图像同样尺寸和分辨率的语义分割图像。这种端到端“编码-解码”神经网络的下采样和上采样参数均通过训练学习获得,能够取得更高的语义分割精度。
在图像识别与人工智能的处理过程中,先验知识也起到关键的作用。因为虽然通过人工智能的相关算法可以较为精准地识别出图像。但是针对于图像应该作出地判断与反应,例如识别出该图像具体是一个什么事物,这些事物之间的可能存在的关系,以及这些事物所代表的含义等等,却是需要先验知识作为前提,再用现有知识与之进行比对才能做出合适的判断。正如我们在“自然智能”章节中所讲到的有关情绪智能的部分。如果想让人工智能真正如电影《人工智能》里面一般,可以通过图像识别分辨出人的表情,从而分析出他的喜怒哀乐的情感。那么这个图像识别程序中就必须要有一定的先验知识,才能达到这样的境界。

(电影《人工智能》海报)
二、矛盾的解决
物体识别既要提取语义信息,又要获取位置信息,前者需要全局特征,而后者需要局部特征。这两个矛盾看似不可调和,实际上却存在非常丰富的解决办法。在讨论这个问题之前。我们要先明确计算机视觉的任务,它主要分为两大类:物体检测与实例分割。物体检测即确定包含目标物体边框的大小与位置并识别其所属类别,而实例分割即确定包含目标物的像素空间并识别其所属类别。物体检测或事件分割既需要识别目标物体的类别,又需要确定被识别物体的定位边框或所占据的像素空间。
当只有单物体需要识别时,通过神经网络卷积与池化之后产生了一组特征图,通过两个完全连接网络,我们既可以对图像中的物体进行分类,也可以对物体所处的边框参数进行回归等等的方法解决。
如果要进行多物体的识别,解决这两个矛盾的基本方法之一是先设法确定图像中可能包含不同物体的边框,再对每一个边框中的单一物体进行分类。这种先分割、在分类的策略需要找到可以包含被识别物体的边框。但是由于现实中图像中的物体呈现的情形非常复杂以及综合原因的影响,在分类之前识别和定位这些物体本身也是一件极具挑战性的问题。虽然理论上可以先将图像按某种方式分为不同尺寸的边框,希望这些边框能够以最小边框最大限度覆盖图像中包含的物体。针对这个问题,科学家们人工设计一种选择搜索的算法,对一幅给定图像产生若干个可能覆盖物体的边框。于是美国加州大学伯克利分校的博士后研究员 Girshick及合作者在骨干网络产生特征图之后再用选择搜索算法产生定位边框,从而大大减少了图像分类的重复计算。[3] 虽然这种方法可以取得比较高的精度,但网络训练过程复杂且效率低。
为了解决这个问题,科学家们提出了单步算法,美国华盛顿大学博士研究生Redmon 等提出的“你只看一次”(YOLO)算法,基本思想是将物体识别问题视为针对不同定位边框和分类概率的回归问题,YOLO首先将输入图像划分为网格,然后以每个网格为中心定义若干个不同比例和尺寸的锚定边框,作为卷积神经网络的输入。在卷积神经网络的输出端对每个网格输出所有锚定边框与基础真相边框的相对位置和尺寸参数以及对应边框中不同类别的概率。我们只考虑信心系数大于一定阈值的锚定边框,最终只输出包含目标物体的边框,否则则认为边框所对应的是背景。[4]其应用非常广泛,如识别下面图像中自行车和小狗的应用:
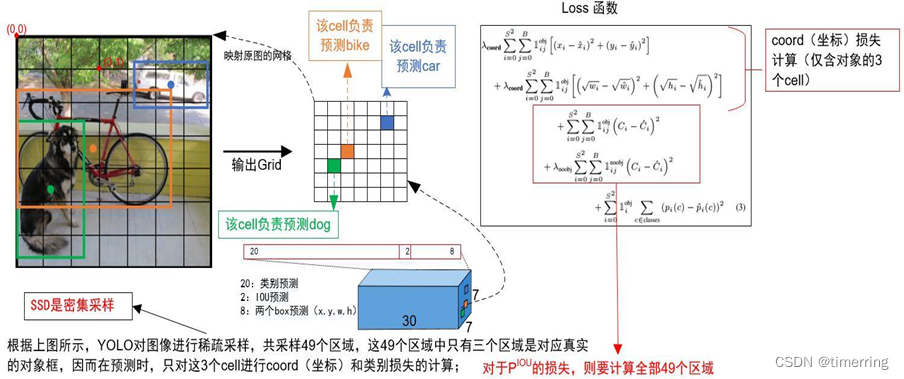
(YOLO算法的实际应用)
为了更进一步的保证定位边框的精度,微软研究院何凯明等人于2017年发明了“掩膜R-CNN”, 在原Fast R-CNN基础上引入一个与物体检测平行的卷积神经网络对区域建议网络产生的物体区域提取掩膜。为了克服原来物体识别网络“关注区域池化”中输入图像与特征图图像像素之间产生的偏移误差,采取了线性插值方法进行校准,并以“关注区域对准”取而代之。[5]这种在包含物体的定位边框内生成物体所对应的像素空间的方法是一种“先检测再区分”的策略。这在极大程度上解决了这两者之间的矛盾。
通过本章人工智能的深入学习,让我对于人工智能在图像识别与物体感知方面的应用有了一个全新的感受。特别是作为图像识别的内核的卷积神经网络及其算法让我印象十分深刻,对于卷积神经网络在图像识别中的具体作用,编码解码的基本规则以及先验知识的重要作用的讨论强化了我对与卷积神经网络的认知,更顺着解决提取语义信息与获取位置信息的矛盾的思路,学习了解了二步法,YOLO算法,掩膜R-CNN算法等等。这些收获让我在脑海中构建了一个关于人工智能的大体框架,启发我今后不断学习去填充完善它。
参考文献:
[1]周飞燕,金林鹏,董军.卷积神经网络研究综述[J].计算机学报,2017,40(06):1229-1251.
[2] [5]黄卫平. 数据智能科学技术导论[M].北京:清华大学出版社,1-274.
[3] R. Girshick,Fast R-CNN, arXiv:1504.08083v2 [cs.CV] 27 Sep 2015.
[4] J. Redmon, et.al., You only look once: Unified, real-time object detection, Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 779–788, arXiv:1506.02640v5 [cs.CV] 9 May 2016.