
欢迎来到我的博客
?博主是一名大学在读本科生,主要学习方向是前端。
?目前已经更新了【Vue】、【React–从基础到实战】、【TypeScript】等等系列专栏
?博客主页?codeMak1r.的博客
最新专栏【React–从基础到实战】
本文目录
一、开发范式 & 底层框架React Hooks基于编译的响应式系统统一模型的优势和代价基于编译的运行时优化 二、工具链原生语言在前端工具链中的使用工具链的抽象层次基于Vite的上层框架 三、上层框架数据的前后端打通类型的前后端打通JS全栈的代价社区探索的方向
?坚持创作✏️,一起学习?,码出未来???!
2022年7月22日,也就是前天,在某平台开发者大会上,知名前端框架Vue作者、知名前端构建工具Vite作者尤雨溪带来了2022最新的Web前端生态趋势分享。
图片来自于网络,如有侵权请联系笔者删除
(不得不说,尤大大真挺帅啊~~)
那么本文呢,就是对这次尤大大的演讲做一个分享,一起来看看尤大大对现如今Web前端的趋势有何看法吧~
(尤大大表示,由于他自己是前端框架VueJS与前端构建工具Vite的作者,所以在本次分享中仅代表尤大大个人观点,肯定会包含他个人的一些利益相关以及偏见…还请大家心平气和观看)
(笔者拙见:目前的前端生态是一个百花齐放的环境,有着很多优秀的开源框架以及周边库,大家可以持各自不同意见,多多在评论区探讨~)
这次的分享,尤大大从三个不同的层次出发,对Web前端的趋势做出分析:
一、开发范式 & 底层框架
底层框架层也就是我们比较熟悉的React、Vue这些框架层面。
React Hooks
在过去几年中,影响力最大的开发范式层面的变化肯定是React Hooks,目前已经彻底取代Class Components,启发了组件逻辑表达和逻辑复用的新范式。
尤雨溪:在其他框架中也受到了React Hooks的影响,比如Vue3的Composition API、Svelte的Svelte3(Svelte3整个组件编译的逻辑是由ReactHooks启发而来的)还有SolidJS。

Solid代码
// 状态const [count,setCount] = createSignal(0)// 副作用createEffect(() => console.log(`${count()}`))// 状态更新setCount(count() + 1)尤雨溪:Solid代码其实跟react代码是极其类似的,但是它的副作用createEffect与React的useEffect也是类似的。不过并不需要手动声明依赖,因为当你调用count这个函数的时候,其实就默认自动帮你收集了依赖。状态更新的时候其实并不需要去用useCallback这样的方式去创造一个函数来传给我们的事件监听器,这些都是非常符合直觉的。
Vue Composition API
// 状态const count = ref(0)// 副作用watchEffect(() => console.log(count.value))// 状态更新count.value++尤雨溪:同样的Vue的Composition API和Solid其实本质上他们的内部实现几乎是一样的,只是Solid看上去更像React,而Vue是更多的用一个ref对象,ref对象上的value既可以用来读也可以用来写。在读和写之中就会自动的追踪和更新依赖。
Ember Starbeam
// 状态const count = Cell(0)// 副作用DEBUG_RENDERER.render({ render:() => console.log(count.current)})// 状态更新count.set(prev => prev+1)尤雨溪:而Ember Starbeam其实也可以看到它的Cell这个API,几乎就跟Vue的ref这个API几乎就是一样的,他的上面这个暴露了一个current来代表当前的count值以及暴露了一个set()方法来行使状态更新。

这些基于依赖追踪的范式的共同点在于:
即使是深层嵌套的组件也会自发的更新,整体上的性能更好。
尤雨溪:React Hooks受制于“过期闭包”的问题,哪怕在社区中存在自动依赖追踪的实现方案,但是还是存在于ReactHooks中的,所以在这些方案之外的Hooks还是存在过期闭包、useEffect的一些问题。
React Hooks确实是启发了很多的开源框架、库的作者,打开了一个新的开发范式的时代。但是慢慢的发现了hooks自身存在的一些问题,React团队也正在试图解决这些问题。同时在React体系之外,我们发现了一些具有同等的逻辑组合能力,但是避免了React Hooks的问题的一些方案(也就是Solid、Vue Composition API、Ember Starbeam等等…)
基于编译的响应式系统

在React开发者团队逐渐重视ReactHooks的问题时,团队中的华人黄玄,正在开发React Forget,意在避免需要手动声明依赖。React Forget这个解决方案是在编译时,自动帮助用户声明依赖。
尤雨溪:React Forget是基于编译时的优化去改善开发体验的一个手段,那么即使是基于依赖追踪的方案我们也可以进行一些基于编译时的优化。首当其冲的就是Svelte:
// 状态let count = 0// 副作用$:console.log(count)// 状态更新count++*只能在Svelte组件内使用Svelte3在一开始就是采用基于编译时优化方案,这就是Svelte组件中使用状态的代码,他的状态就是JS中的let声明一个变量,就是一个响应式的状态,要更新状态就直接去操作这个变量就可以。副作用就是用一个$符去声明这是一个副作用的语法(其实就是JavaScript中的label语法),使用了label语法之后声明的这个语句就会去自动的追踪状态的变化,count变化的时候这个语句就会自动的执行。那么这个其实就是在编译的时候去对代码优化,让代码更加的简洁。
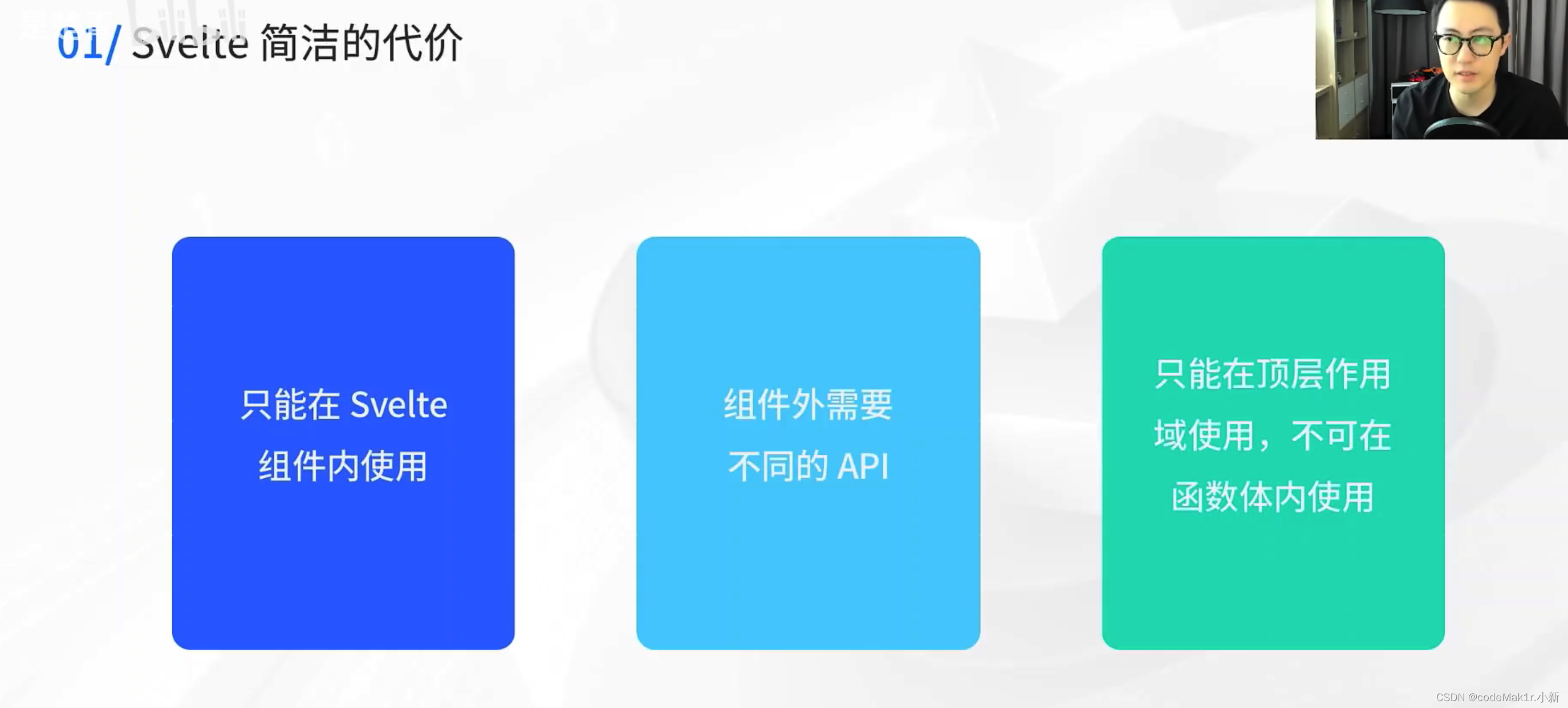
尤雨溪:受到Svelte的影响,Vue在3.2版本的时候引入了一个实验性的功能叫做Vue Reactivity Transform*,也就是响应式转换。使用响应式转换之后的代码如下:
Vue Reactivity Transform*
// 状态let count = $ref(0)// 副作用watchEffect(() => console.log(count))// 状态更新count++*可在组件和普通JS/TS文件中使用还是一个简单的变量声明,但是我们用一个$ref()函数,这个函数是在编译时类似于宏这样的一个概念(笔者这里也没听懂(●–●)),这个函数并不是真实存在的,只不过是给编译器一个提示,编译器在编译的时候就会把它转换成基于真实的ref的代码。但是使用的时候体验就变成了只是声明一个函数,但是之后使用这个变量和更新这个变量就跟使用普通的JavaScript变量没有区别了。同时我们在声明的时候会显式的声明哪个变量是响应式的,哪个变量不是响应式的,所以这个语法其实可以嵌套在函数中使用,也可以在普通的JS/TS文件中使用,所以这是一个更普式的基于编译时的响应式模型。
那么在Solid生态中,其实也有受启发于Vue Reactivity Transform*的社区用户的solid-labels,是一个基于Solid的一个响应式方案,再做一层编译时的优化。
Solid-labels
// 状态let count = $signal(0)// 副作用$effect(() => console.log(count))// 状态更新count++*可在组件和普通JS/TS文件中使用在代码中可以看到跟Vue Reactivity Transform*达成的效果其实非常的相似。
最终的目的是让大家可以用更简洁的方式去表达逻辑,同时放弃逻辑组合(像React Hooks那样进行自由逻辑组合的能力)。所以说,这也是一个很有意思的探索方向。
统一模型的优势和代价
优势:利于长期的重构和复用。
代价:底层实现的抽象泄漏、初期学习成本
基于编译的运行时优化
基于编译的运行时优化有三个主要的代表:Svelte、Solid和Vue Vapor Mode(其中Vue Vapor Mode是正在实验中的一个和Solid比较类似的一个方案)
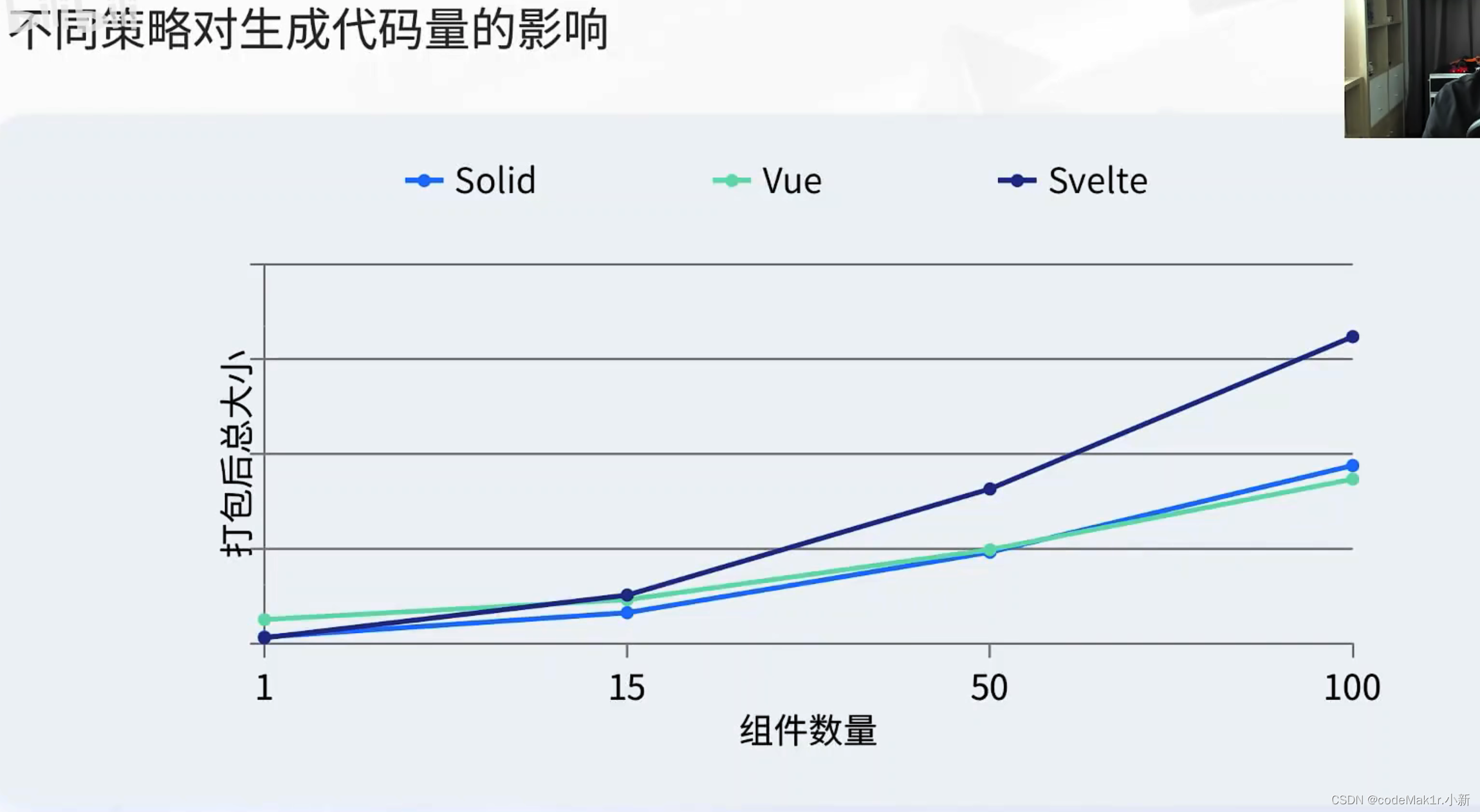
我们刻板印象中,Svelte都是以轻量著称。但其实当项目中组件超过15个以后,Svelte的打包优势就不明显了,当组件超过50个甚至达到100个以后,Svelte的体积会越来越臃肿。而相对而言,Vue和Solid的打包输入的体积会相对平缓些,所以在大型的项目中Svelte的体积优势反而成了劣势。
(尤雨溪:据我所知Svelte的团队也在对这一现象进行处理,可能会在下一个大版本中实现,我们拭目以待!)
Vue Vapor Mode(input)
<script setup>import { ref } from 'vue'const count = ref(0)</script><template> <div> <button :id="`foo-${count}`" :class="{ red: count % 2}" @click="count++" >{{ count }}</button> </div></template>Vue Vapor Mode(output)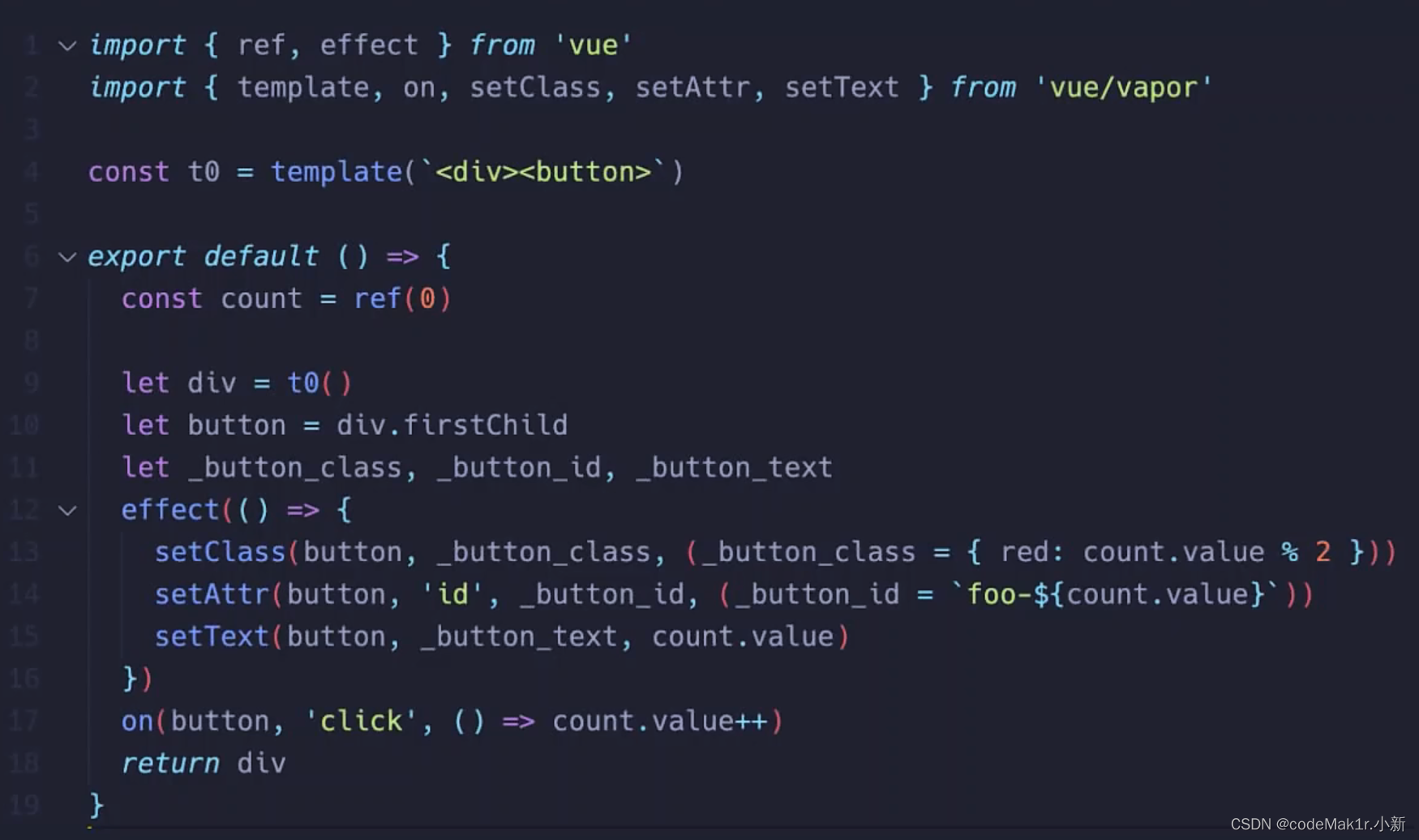
笔者水平实在有限,(●–●)这里也没懂,但是大家可以搜索本次开发者大会回放,去观看尤大大的演讲哟~
二、工具链
工具链层面也就是像WebPack这样的构建工具层面。
原生语言在前端工具链中的使用
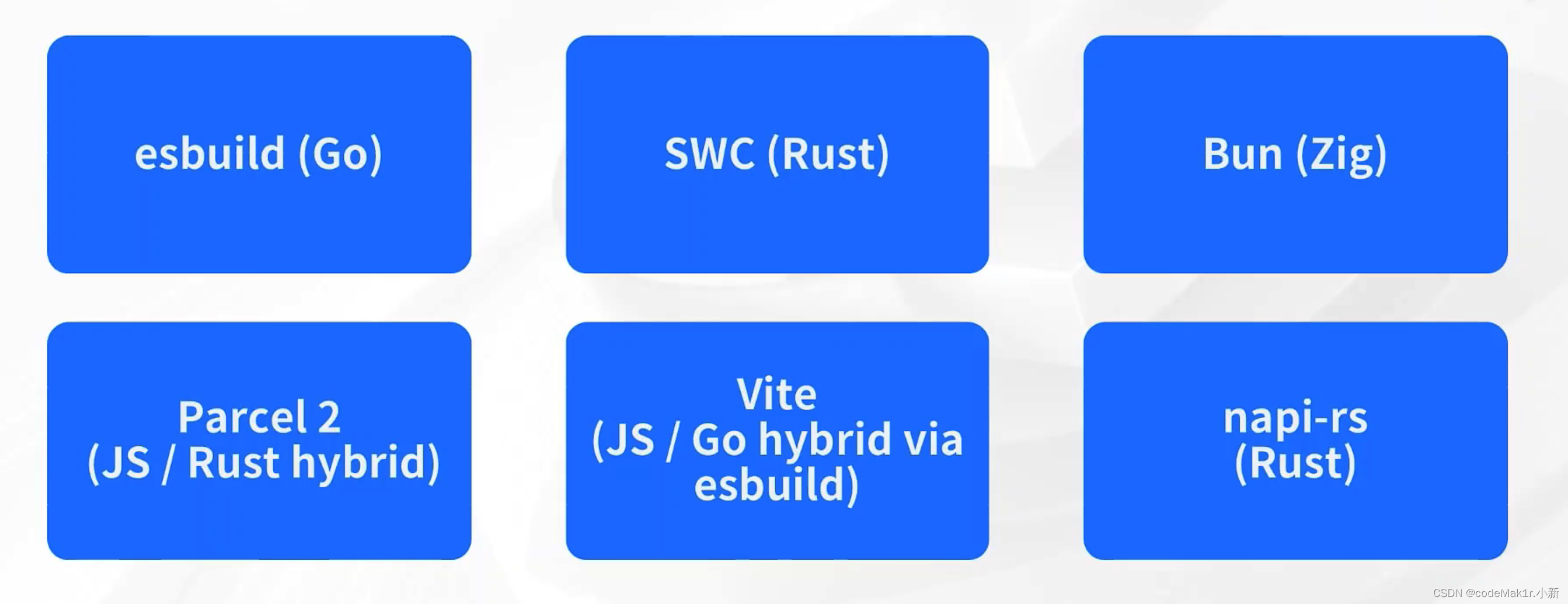
工具链(语言)
尤雨溪:原生语言被用在工具链中是越来越常态化的,但是所有的工具链彻底用原生语言重写是不太现实的。
工具链的抽象层次

基于Vite的上层框架

我们可以看到Nust3、SvelteKit、Shopify Hydrogen基于React18的上层框架、新的静态生成框架Astro、Angular作者在新公司正在开发的Qwik、FastifyDX、Solid Start 以及 Laravel现在已经转移到Vite作为其默认的前端方案……现在这些高层的框架都在基于Vite作为底层的工具链的实现,说明我们Vite的定位还是相当成功的。(尤大大在这里吹嘘了一波~Doge)
三、上层框架
上层框架也就是像NextJS、NuxtJS这样的上层框架层(Meta Frameworks)。
我们讲到这个Meta Frameworks最典型的例子就是NextJS、NuxtJS,SvelteKit以及现在React社区中有新秀Remix等等……
当我们思考这样类型的JS全栈的时候,我们需要思考JS全栈的意义是什么?
———我们可以用同一个语言,做前后的连接,我们可以做纯前端,也可以做纯后端都各自做不到的事情。或者之前只有前后端联调才能达成的事情,这个时候JS全栈可以更好的去完成。一个语言让我们可以把前后“打通”。
数据的前后端打通

NextJS的getStaticProps/getServerSideProps虽然写在用一个组件中,但是实际上是运行在服务端的这些函数使得让我们能在同一个文件中把整个数据流从后到前的数据流打通,是最早的一个例子。
NuxtJS就是API routes + useFetch + Top level await(Nuxt3)相互配合的一整套逻辑。
Remix就是在同一个组件中可以写loader / action(在服务端运行) + Enhanced + HTML Form表单组件强化 ,使得HTML Form和服务端的loader和action对应起来,从而实现一个非常简洁的数据流。
这些都是非常值得去探索的方向!
除了数据的打通之外,还有类型的前端后端打通。
类型的前后端打通

在数据打通的前提下,我们就注意到了类型前后端打通的重要性。因为当你的数据前后端打通了,如果类型不打通,那共用的开发体验和意义就会小很多,所以类型的前后打通也是一个接下来很重要的一个方向。
比较简单的就是通过显式的引入共享类型,比如说在Remix里面,你可以看一个TS文件,把你的数据的interface写好,然后在你的loader中可以引入,在你的客户端代码中可以引入,这个是一个比较基本的共享。
在后端也有一些方案,比如自动基于DB的schema生成类型的一些方案。
在Nuxt3当中,现在探索的方向就是开发体验里面的,当自动基于文件布局生成API/路由类型。
JS全栈的代价

这也是新的全栈框架现在正在改善的一些问题。
首先,我们现有的一些前端框架,比如Vue、React,我们在做了全栈的服务端渲染之后,在前端要进行一次所谓的注水(hydration)。在hydration过程中,我们要确保客户端和前端有同样的数据,所以其实虽然我们的数据已经用于渲染HTML了,也就是在HTML中已经都用过这些数据了,但是我们还得把这个数据再发送一次,一起发送到前端,让前端进行hydration的过程。因为没有这个数据我们在前端就没有办法保证hydration的正确性,以及有些组件在客户端是不需要交互的,是静态的,但是这个组件在服务端用到了动态的数据,这个组件依然会发到服务端,依然会产生JavaScript运行时的代价,缓慢的hydration会影响页面的交互指标。有一些复杂的庞大的项目在注水的过程中会把页面卡顿,以及虽然能看到页面但是没法交互的问题。
社区探索的方向

社区的探索是:下一代的全栈都在试图解决这些问题,比如说react提出的Server-only Components(react server components)但react-server-components从定义上就发现他是一个没有围绕全栈框架去做,其实用户是没有办法简单的使用的,Server-only Compnents是一个必须要全栈才能做的一个概念。
另一个方向就是减少注水,也就是局部的注水(Partial hydration)或者也叫Island Architecture(理解为,对大海中一个个的小岛进行注水,让他变得可交互),比较有代表性的是Astro、Isles以及Fresh这些框架使用了Partial hydration这个概念。
还有就是Fine-grained resumable hydration,细粒度懒加载 + 可继续的注水,这个术语其实是Qwik这个框架发明的。Qwik这个框架的作者就是Angular的原作者离开了Google之后新开发的框架,Qwik主打的就是不需要把数据重新发送一份,直接在生成的HTML中嵌入所需的数据,从而使得客户端的JS可以直接在HTML里面得到所需要的数据,那么也就是甚至可以跳过一些JS执行的步骤,直接跳到一个已经完成了的状态上面。
还有最后的VitePress,他是VuePress的后继者,探索的是一个在我们页面核心内容其实是静态的markdown文件的前提下如何做高效率的hydration,其实就是shell + partial hydration。就是整个外部,内容外包着的这一层UI是动态的,在内部静态是进行局部的注水,这样的话我们依然可以获得一个单页应用的体验,还可以获得一个客户端注水的性能。
好啦~
大致上这些就是尤大大在开发者大会中分享的内容啦,希望能够对你的前端的研究有所帮助。
在这次的分享中,不知道你能看懂多少,又会有怎么样的启发呢?
(笔者启发就是:学无止境!)