yolov7从环境配置到训练自己的数据集人体姿态估计AlexeyAB版本
前言
本文将会持续更新!
前几天美团发布yolov6,已经让人学不过来了,今天又看到yolov7发布,并且有AB大佬站台!本文将使用yolov7的过程记录下来,尽量从环境配置、测试到训练全部过一遍。
电脑基本配置:
1.Ubuntu20.04
2.cuda+cudnn
3.pycharm
4.GPU==3060ti
一、环境配置
相较于yolov5与yolov6的代码,yolov7中没有requirements.txt文件,也没有给出具体的环境配置要求,因此这一部分基本摸着石头过河吧 新版本已经有了requirements.txt。本实验中继续使用pycharm进行配置。
1.新建yolov7的虚拟环境
点击pycharm右下角添加yolov7环境
2.安装pytorch
建议先自行安装pytorch,因为直接按照requirements.txt进行安装的话,有可能会安装cpu版本的pytorch。进入pytorch官网:https://pytorch.org/,根据自己的电脑配置安装pytorch,主要是对应自己的cuda版本。在pycharm中点击终端,输入安装指令。
3.下载权重
这一步开始就是一次次尝试,缺啥装啥!
在github上就能够下载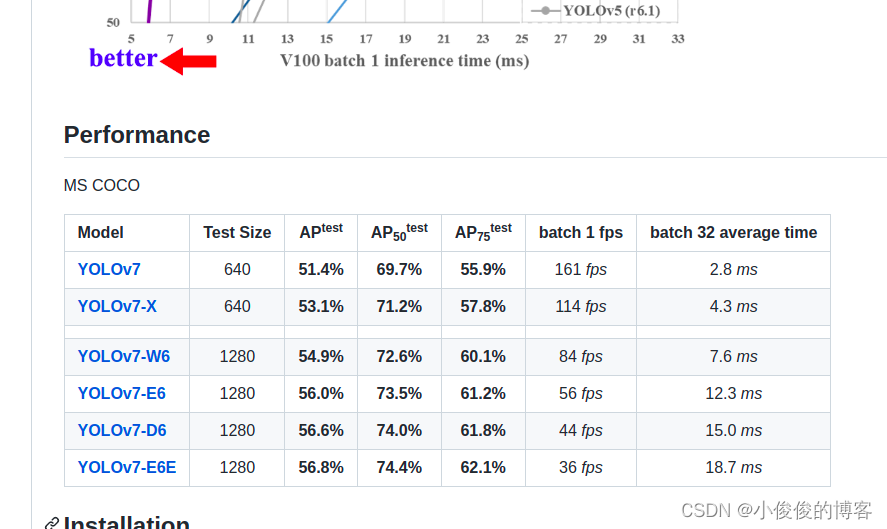
我在CSDN上也有分享:Yolov7权重文件
下载后置于yolov7文件夹下。
4.补充环境
修改requirements.txt文件,因为前面安装了pytorch,可以将torch和torchvision注释掉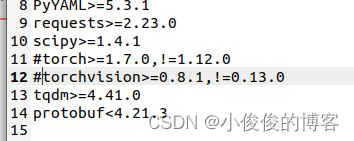
下一步就直接在终端输入:
pip install -r requirements.txt然后在pycharm的yolov7环境下,开始运行detect.py。
1)缺少opencv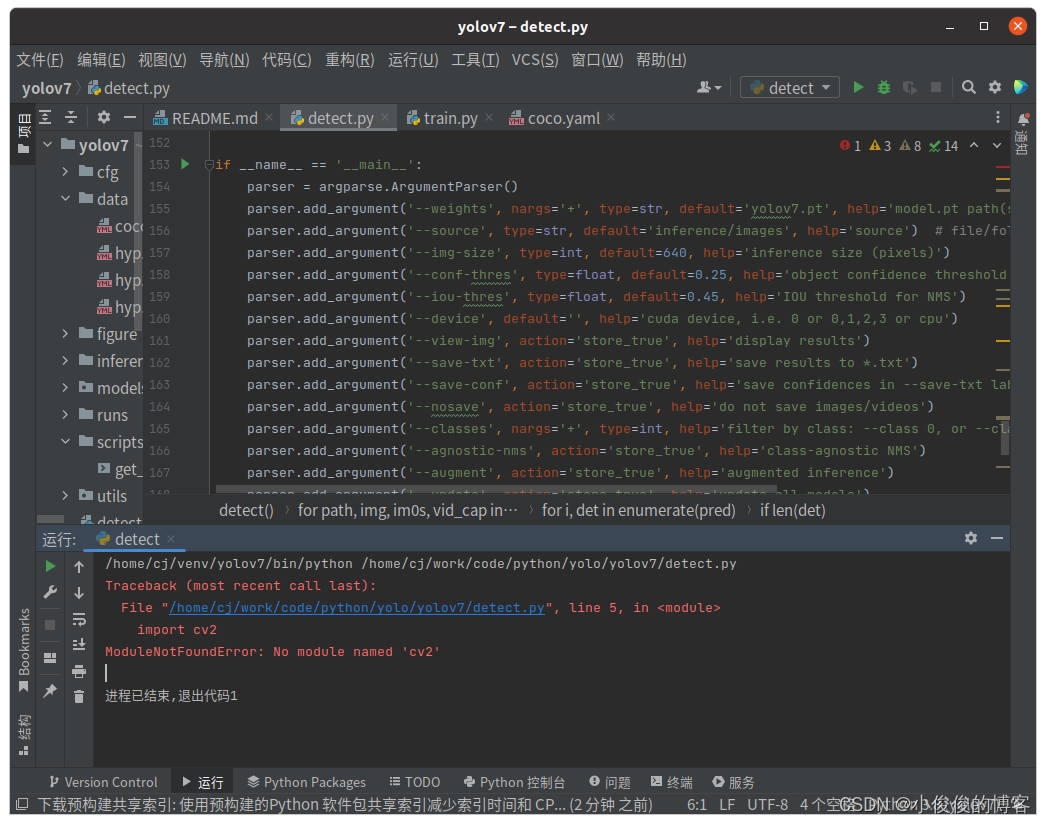
pycharm终端输入:
pip install opencv-python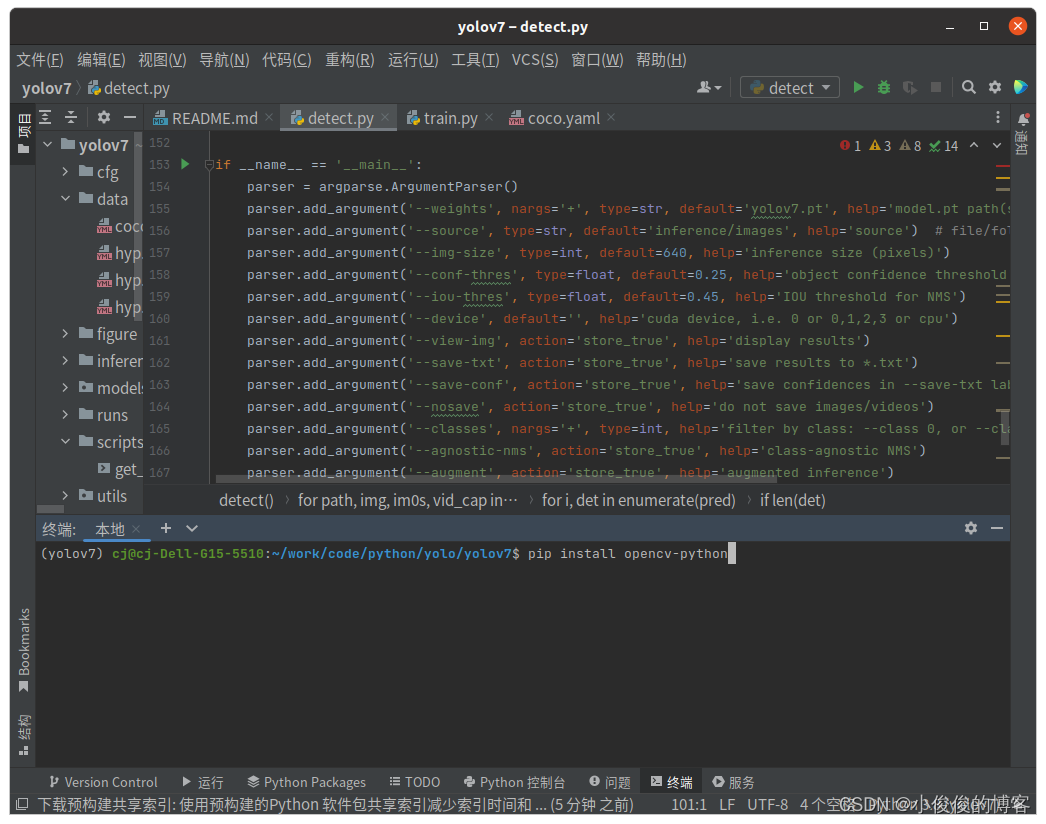
继续运行detect.py
2):ModuleNotFoundError: No module named ‘pandas’
pycharm终端类似上面一样输入:
pip install pandas3):ModuleNotFoundError: No module named ‘tqdm’
pycharm终端类似上面一样输入:
pip install tqdm4)ModuleNotFoundError: No module named ‘yaml’
pycharm终端类似上面一样输入:
pip install pyyaml5)ModuleNotFoundError: No module named ‘matplotlib’
pycharm终端类似上面一样输入:
pip install matplotlib6)ModuleNotFoundError: No module named ‘seaborn’
pip install seaborn至此我的环境配置可以满足yolov7的运行要求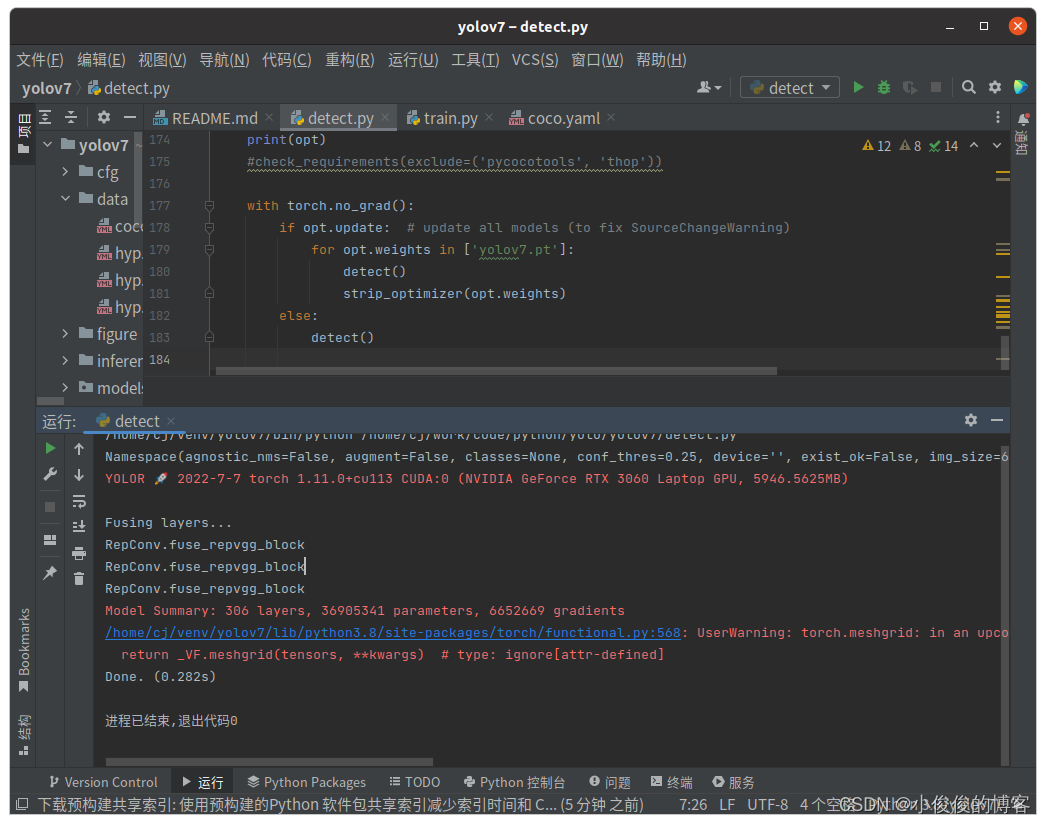
在yolov7/runs/detect文件下将看到检测结果。到这一步,代表环境配置结束!
二、制作自己的数据集
yolov7依旧采用labelImg进行数据标注工作,labelImg下载地址:labelImg
下载解压后,进入labelImg文件夹中,开启终端,依次输入
sudo apt-get install pyqt5-dev-toolssudo pip3 install -r requirements/requirements-linux-python3.txtmake qt5py3python3 labelImg.py安装后进行数据标注即可,注意选择yolo格式。
三、训练自己的数据集
1.划分数据
1)这里我是手动划分,没有写脚本。在yolov7/data文件夹下新建images和labels文件夹。
2)在images和labels文件夹下,分别新建三个文件夹(train、val、test)
在文件夹中对应手动放入图像和标签数据。
2.训练数据导入配置
在yolov7/data文件夹下新建dataset.yaml文件,并写入
train: pathto_you/data/images/train # train imagesval: pathto_you/data/images/val # val imagestest: pathto_you/data/images/test # test images (optional)# Classesnc: 1 # number of classesnames: ['QR'] # class names将路径(pathto_you)改为自己的数据集路径,类别也是一样修改为自己的。
3.修改train.py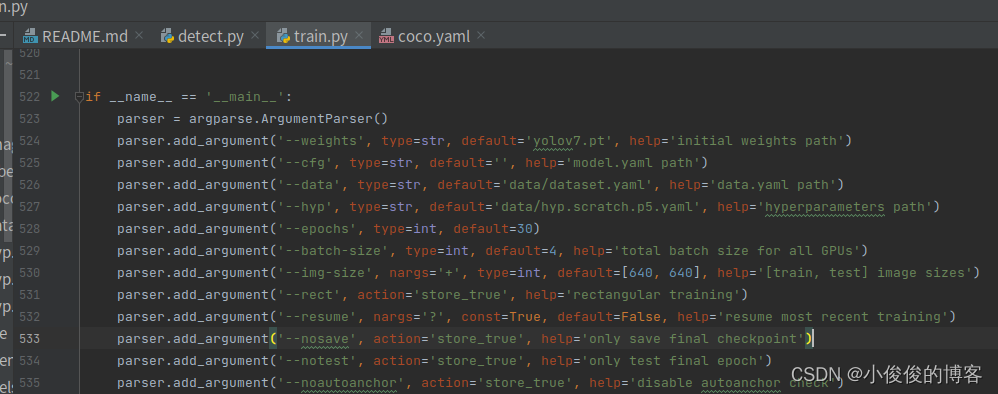
最主要是修改:
1)–weights:修改为yolov7.pt,也可以换为其他的预训练权重
2)–data:修改为上面的dataset.yaml
3)–epochs:酌情修改
4)–batch_size:数值越大,占用显卡内存越大
修改完成就可以开始训练了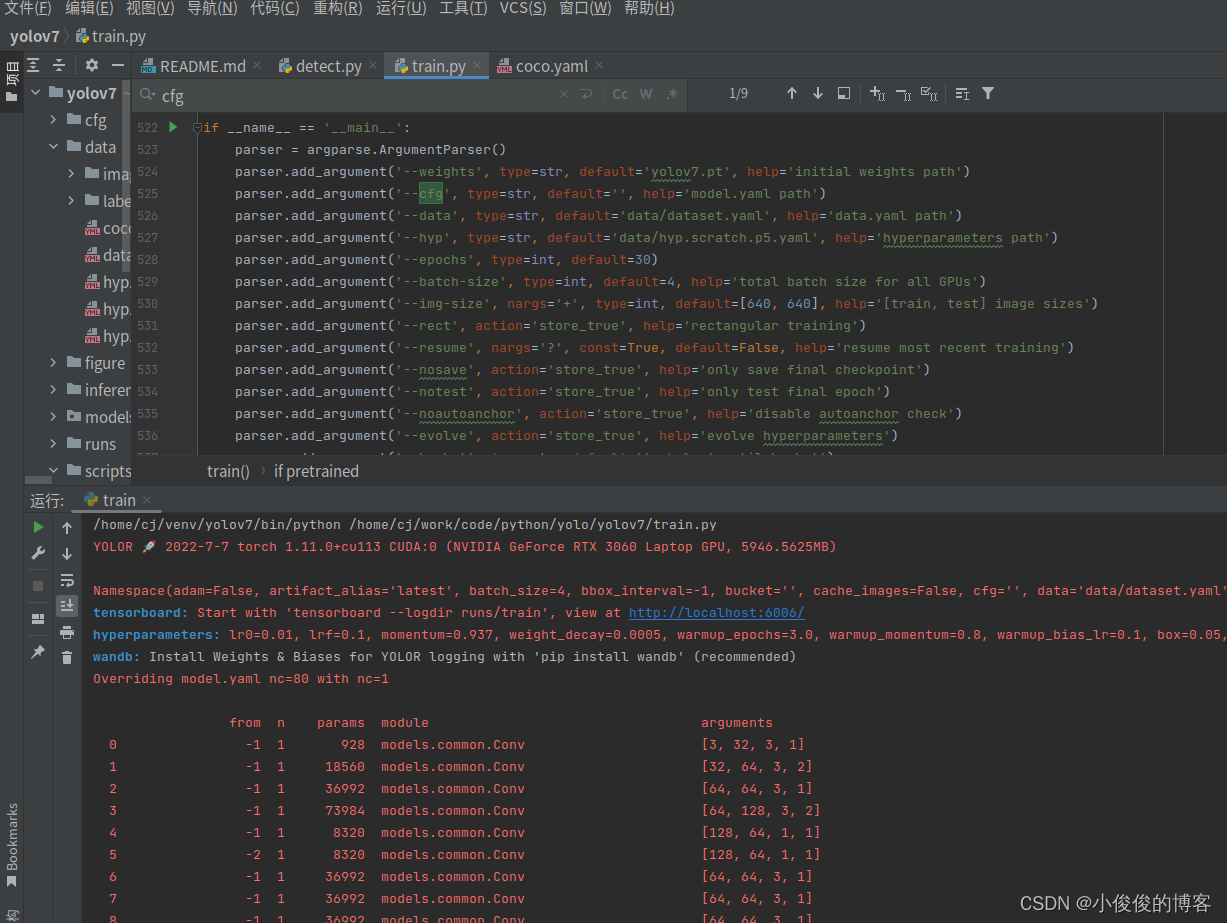
和yolov5一样,在训练过程中,会计算当前的精度。训练时,会在yolov7文件夹下出现runs文件夹,训练结果就存在该文件夹下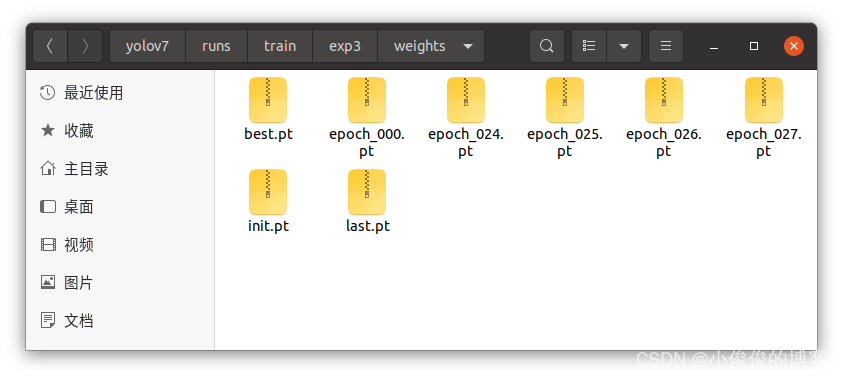
与yolov5只保留最好和最后两个权重不同,yolov7会保留多个权重文件。
四、测试自己的权重
1.修改detect.py
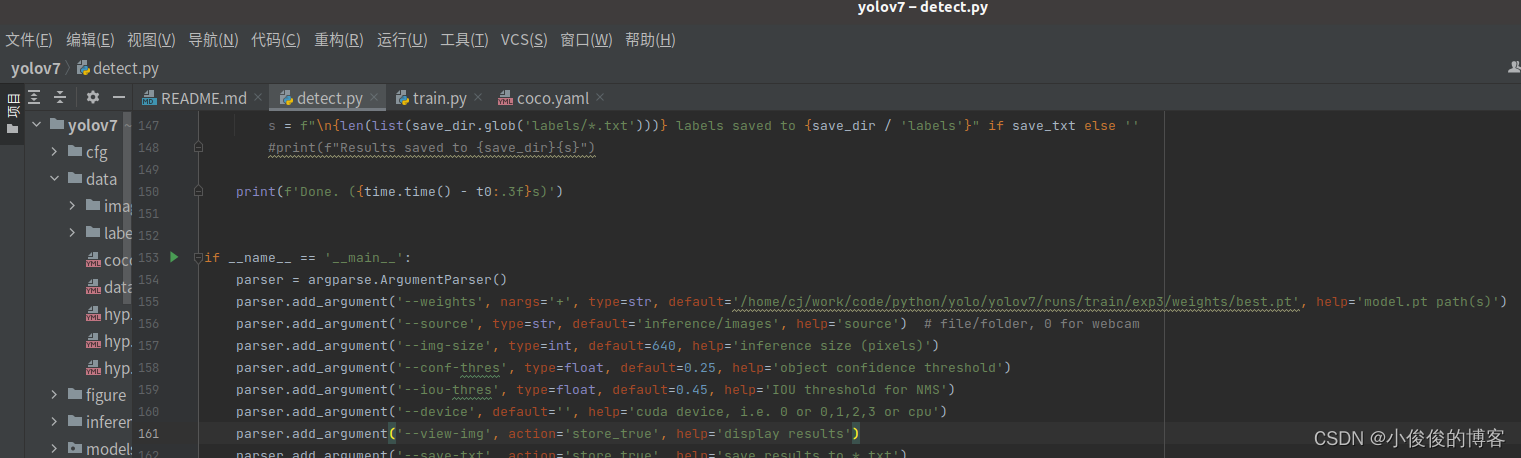
将–weights指定为自己训练好的权重即可。
2.测试图像
将测试图像放入inference/images文件夹下,运行detect.py即可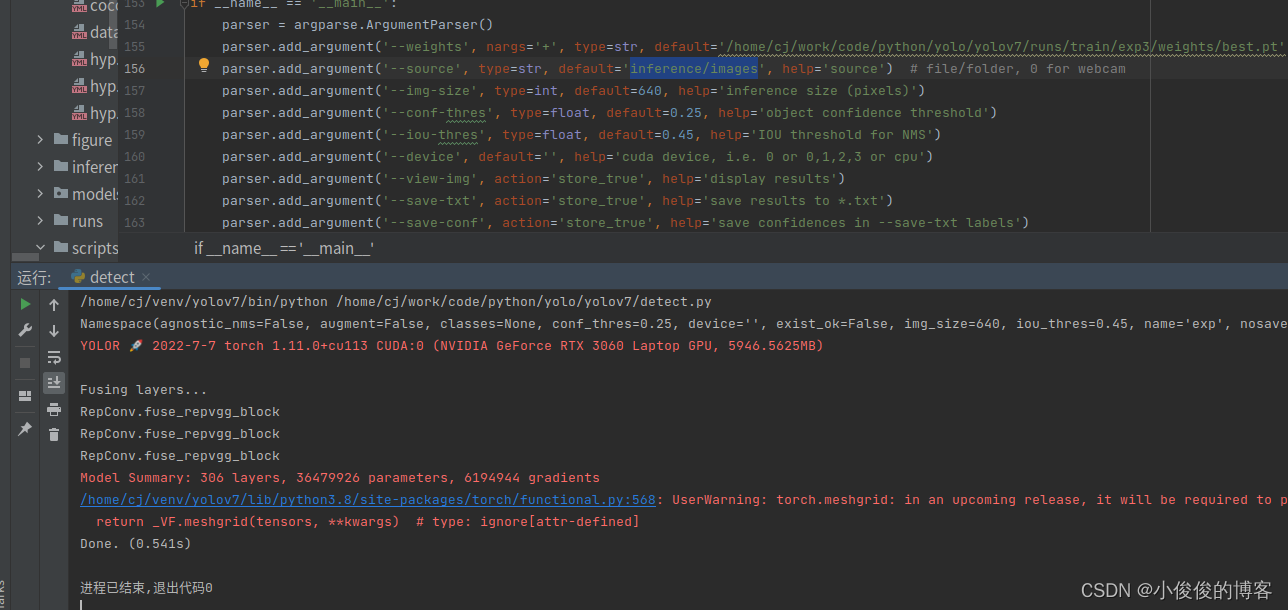
测试结果在yolov7/runs/detect下
到此,yolov7训练自己的数据集记录完成,后续有其他的收获将继续补充。
五、yolov7人体姿势估计
最近yolov7更新了人体姿态估计的相关
1.下载权重
点击上图中yolov7-w6-pose.pt下载权重,置于yolov7根目录下
2.新建脚本
在根目录下新建test_point.py脚本文件,并写入
import torchimport cv2from torchvision import transformsimport numpy as npfrom utils.datasets import letterboxfrom utils.general import non_max_suppression_kptfrom utils.plots import output_to_keypoint, plot_skeleton_kptsdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")weigths = torch.load('yolov7-w6-pose.pt')model = weigths['model']model = model.half().to(device)_ = model.eval()image = cv2.imread('./bus.jpg')image = letterbox(image, 960, stride=64, auto=True)[0]image_ = image.copy()image = transforms.ToTensor()(image)image = torch.tensor(np.array([image.numpy()]))image = image.to(device)image = image.half()output, _ = model(image)output = non_max_suppression_kpt(output, 0.25, 0.65, nc=model.yaml['nc'], nkpt=model.yaml['nkpt'], kpt_label=True)output = output_to_keypoint(output)nimg = image[0].permute(1, 2, 0) * 255nimg = nimg.cpu().numpy().astype(np.uint8)nimg = cv2.cvtColor(nimg, cv2.COLOR_RGB2BGR)for idx in range(output.shape[0]): plot_skeleton_kpts(nimg, output[idx, 7:].T, 3)#cv2.imwrite("pose.jpg",nimg)cv2.imshow("pose",nimg)cv2.waitKey(0)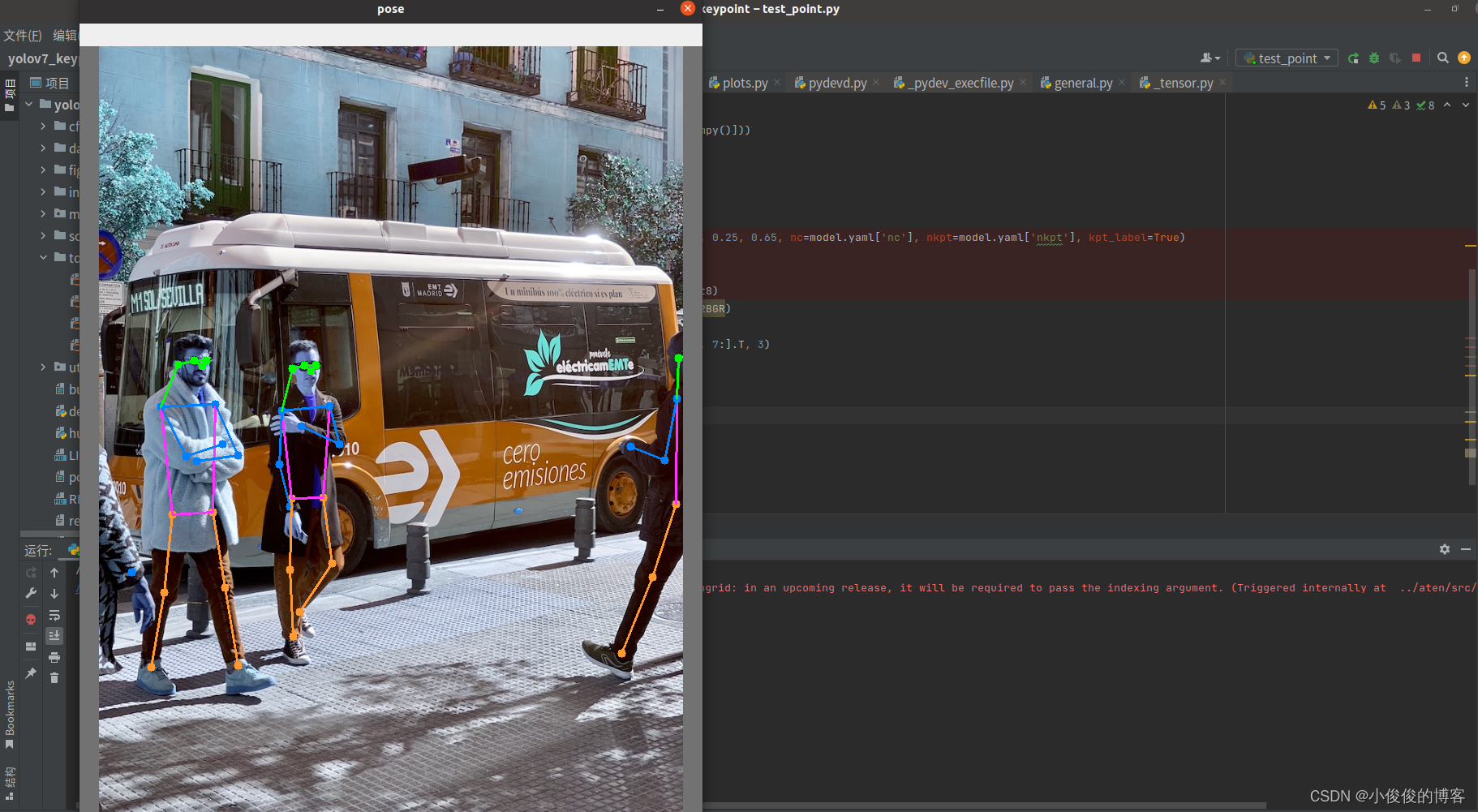
3.遇到的问题
1).代码不适配
需要更新代码,下载最新的yolov7代码,否则将会找不到non_max_suppression_kpt,output_to_keypoint, plot_skeleton_kpts
2).numpy
报错:RuntimeError: Can’t call numpy() on Tensor that requires grad. Use tensor.detach().numpy() instead.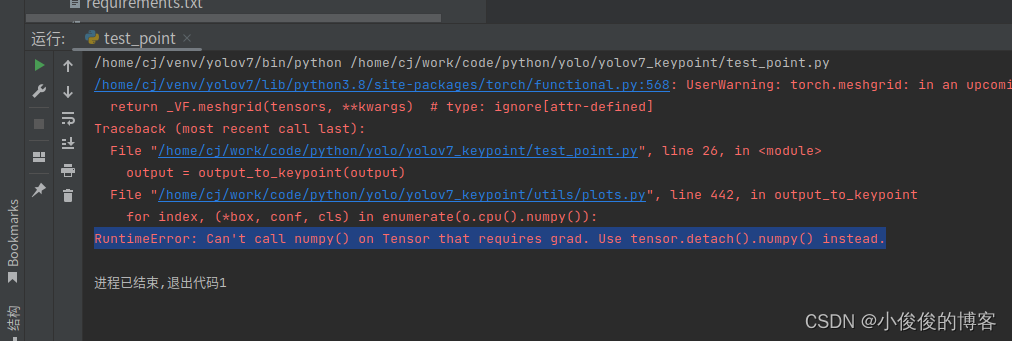
解决方法:
将上述位置修改一下,在cpu()后增加detach()
for index, (*box, conf, cls) in enumerate(o.cpu().detach().numpy()): targets.append([i, cls, *list(*xyxy2xywh(np.array(box)[None])), conf, *list(kpts.cpu().detach().numpy()[index])])六、补充
1.yolov7继续接着训练
–resume这一行将defaul填入之前训练的权重,实现继续训练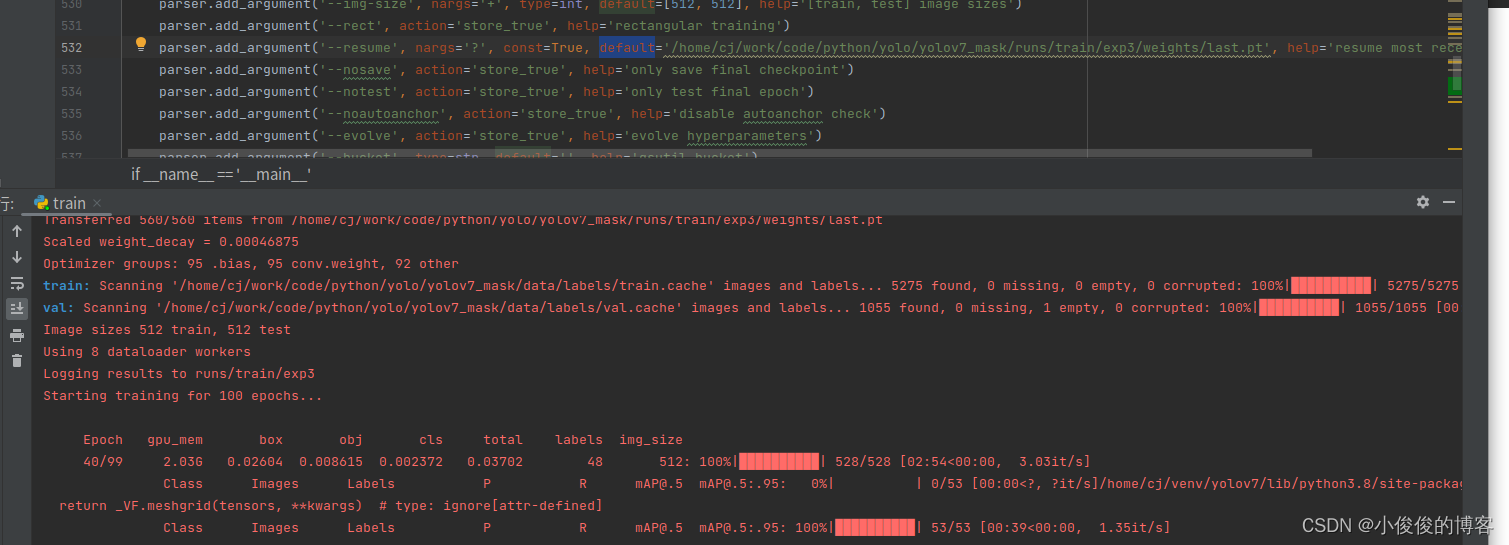
2.调用摄像头出现TypeError: argument of type ‘int‘ is not iterable
在使用yolov7时,–source选择’0’调用笔记本摄像头时
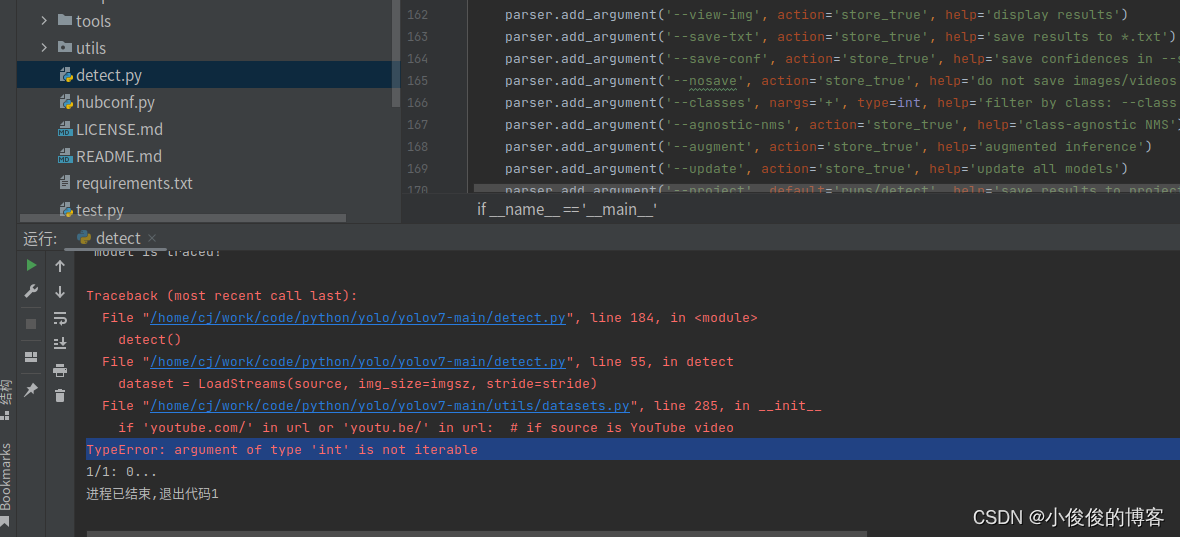
解决方法:
修改dataset.py的285行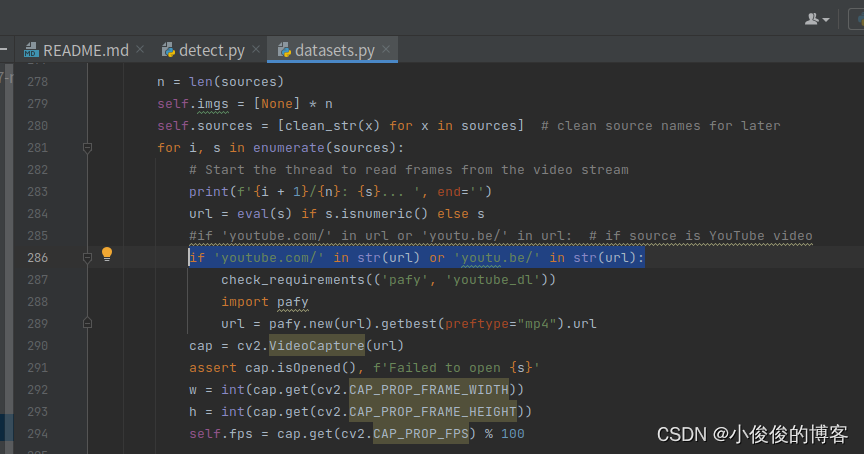
将原代码修改如下:
if 'youtube.com/' in str(url) or 'youtu.be/' in str(url):附带资源
1.本次实验的项目,包含训练好的模型,二维码检测数据集等—yolov7训练自己的数据集+教程+二维码检测
2.口罩目标检测数据集Yolo格式-----口罩数据集
3.基于yolov7的训练好的口罩检测模型----口罩检测模型