文章目录
- 前言
- 一、CDC的种类?
- 二、通过FlinkCDC将数据从MySQL导入到Kafka
- 1.核心代码
- 2.工具类
- 三、结果展示
- 3.可能会出现的错误及解决
- 解决:
前言
CDC的Change Data Capture(变更数据捕获)的缩写FlinkCDC的核心思想是监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
一、CDC的种类?
CDC 主要分为基于查询和基于 Binlog 两种方式,简述两者的区别:| 基于查询的CDC | 基于binlog的CDC | |
|---|---|---|
| 常见的组件 | Sqoop | Maxwell、Canal、Debezium |
| 思想 | Batch | Streaming |
| 延迟性 | 高 | 低 |
| 是否可以捕获所有数据变化 | 否 | 是 |
Flink 社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件。
二、通过FlinkCDC将数据从MySQL导入到Kafka
1.核心代码
:
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import com.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;
import com.atguigu.app.function.CustomerDeserialization;
import com.atguigu.utils.MyKafkaUtil;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class FlinkCDC {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.flinkcdc构建SourceFunction
DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname("hadoop101")
.port(3306)
.username("root")
.password("123456")
.databaseList("gmall-flink")
.tableList("gmall-flink.base_trademark")
.deserializer(new CustomerDeserialization())
.startupOptions(StartupOptions.latest())
.build();
DataStreamSource<String> streamSource = env.addSource(sourceFunction);
//3.打印数据并将数据写入kafka
streamSource.print();
String sinkTopic = "ods_base_db";
streamSource.addSink(MyKafkaUtil.getKafkaProducer(sinkTopic));
//4.启动任务
env.execute("FlinkCDC");
}
}
2.工具类
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
public class MyKafkaUtil {
public static FlinkKafkaProducer<String> getKafkaProducer(String topic){
return new FlinkKafkaProducer<String>("192.168.2.101:9092", topic, new SimpleStringSchema());
}
}
三、结果展示
我在MySQL数据库中每变更一条数据,在IDEA和kafka这边都可以检测到:
IDEA:

Kafka:

3.可能会出现的错误及解决
org.apache.kafka.common.errors.TimeoutException: Topic ods_base_database not present in metadata after 60000 ms
解决:
1.vi kafka/config.server.properties
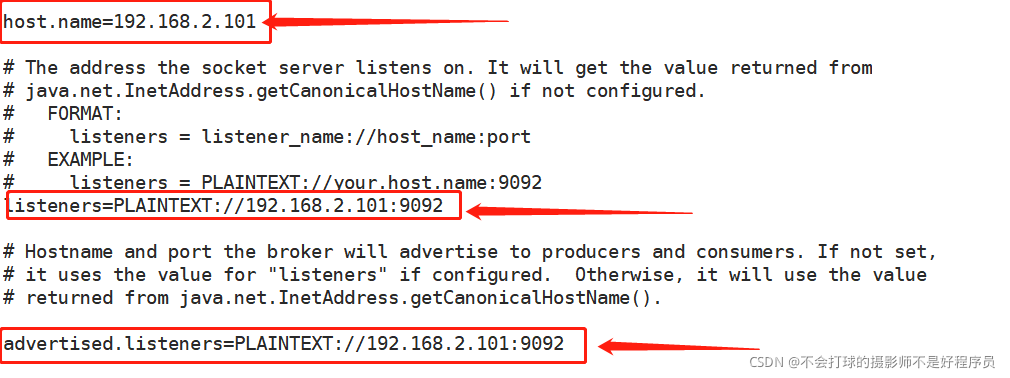
修改这三个地方,切记用IP地址,之前用的hadoop101一直出错
2.重启kafka,重启zookeeper,问题解决!