对于复杂场景的文字识别,首先要定位文字的位置,即文字检测。这一直是一个研究热点。
相比较于EAST算法,CTPN对于水平文字的检测更好,而对于倾斜文本的检测却显得逊色很多。

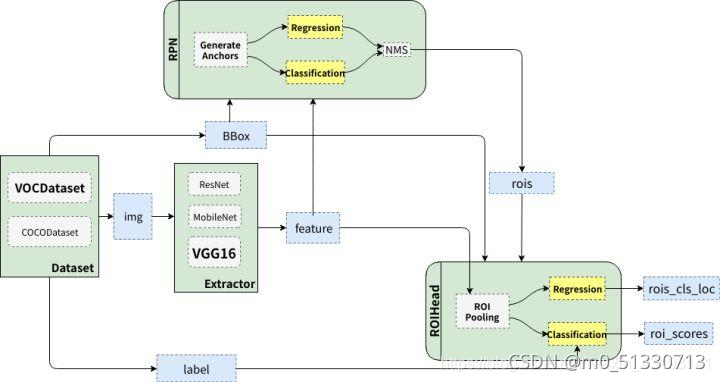
CTPN是在ECCV 2016提出的一种文字检测算法。CTPN结合CNN与LSTM深度网络,能有效的检测出复杂场景的横向分布的文字,效果如图1,是目前比较好的文字检测算法。由于CTPN是从Faster RCNN改进而来,本文默认读者熟悉CNN原理和Faster RCNN网络结构。
CTPN相关:
caffe代码:
http://github.com/tianzhi0549/CTPN
CTPN网络结构
原始CTPN只检测横向排列的文字。CTPN结构与Faster R-CNN基本类似,但是加入了LSTM层。假设输入 Images:
- 首先VGG提取特征,获得大小为
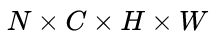 的conv5 feature map。
的conv5 feature map。 - 之后在conv5上做
 的滑动窗口,即每个点都结合周围
的滑动窗口,即每个点都结合周围  区域特征获得一个长度为
区域特征获得一个长度为 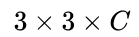 的特征向量。输出
的特征向量。输出 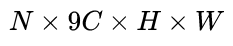 的feature map,该特征显然只有CNN学习到的空间特征。
的feature map,该特征显然只有CNN学习到的空间特征。 - 再将这个feature map进行Reshape
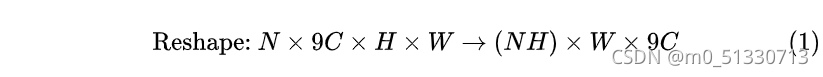
- 然后以
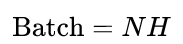 且最大时间长度
且最大时间长度 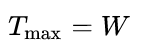 的数据流输入双向LSTM,学习每一行的序列特征。双向LSTM输出
的数据流输入双向LSTM,学习每一行的序列特征。双向LSTM输出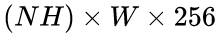 ,再经Reshape恢复形状:
,再经Reshape恢复形状:

该特征既包含空间特征,也包含了LSTM学习到的序列特征。
- 然后经过“FC”卷积层,变为
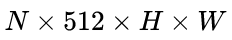 的特征
的特征 - 最后经过类似Faster R-CNN的RPN网络,获得text proposals,如图2-b。
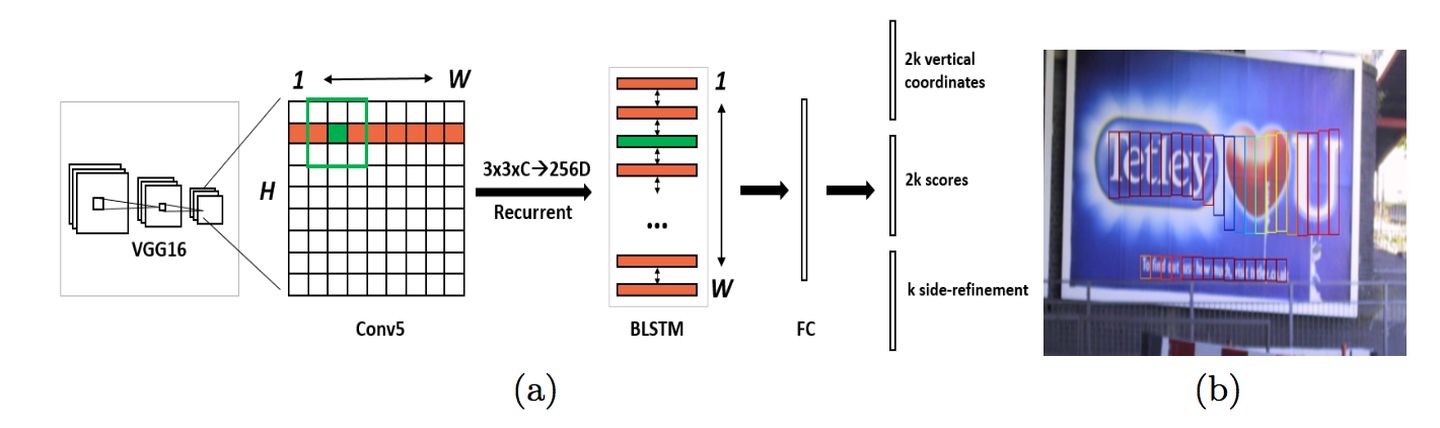
图2 CTPN网络结构
更具体的网络结构,请使用netscope查看CTPN的deploy.prototxt网络配置文件。
这里解释一下conv5 feature map如何从 ![]() 变为 :
变为 :![]()
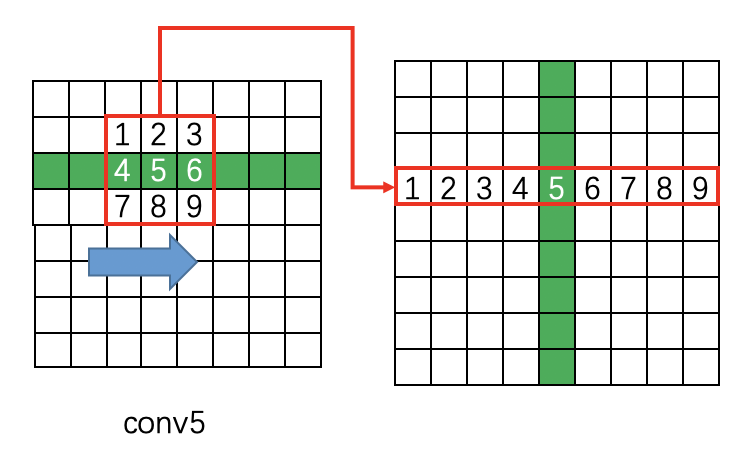
在原版caffe代码中是用im2col提取每个点附近的9点临近点,然后每行都如此处理:
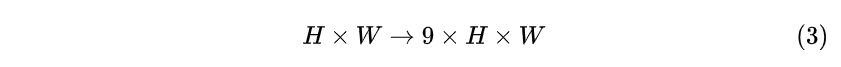
接着每个通道都如此处理:
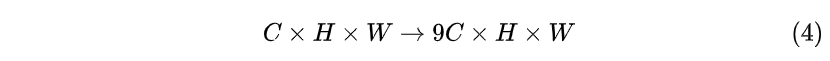
而im2col是用于卷积加速的操作,即将卷积变为矩阵乘法,从而使用Blas库快速计算。
特别说明:上述是对原Paper+Caffe代码的解释,其它代码实现异同不在本文讨论范围内!
接下来,文章围绕下面三个问题展开:
- 为何使用双向LSTM
- 如何通过FC层输出产生图2-b中的Text proposals
- 如何通过Text proposals确定最终的文本位置,即文本线构造算法
为何使用双向LSTM?
- 对于RNN原理不了解的读者,请先自寻RNN原理介绍
- 关于LSTM长短期记忆模型,请参考
Understanding LSTM Networks
colah.github.io/posts/2015-08-Understanding-LSTMs/正在上传…重新上传取消
- CTPN中为何使用双向LSTM?
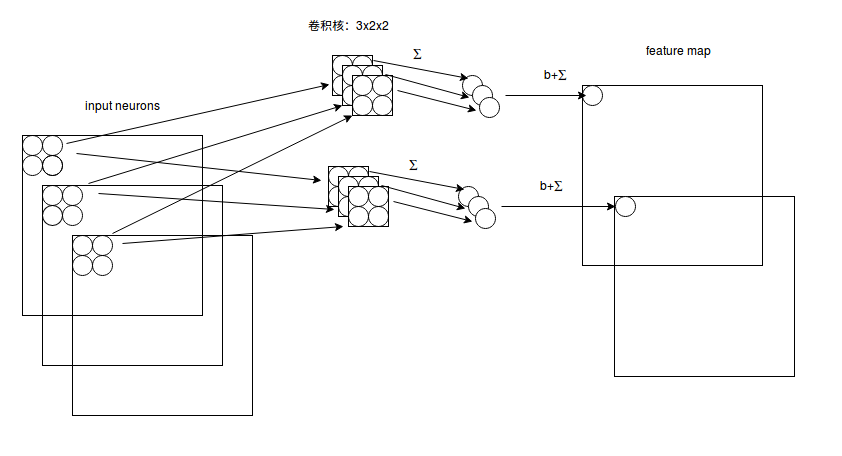
图3 CNN卷积计算示意图
CNN学习的是感受野内的空间信息,LSTM学习的是序列特征。对于文本序列检测,显然既需要CNN抽象空间特征,也需要序列特征(毕竟文字是连续的)。
CTPN中使用双向LSTM,相比一般单向LSTM有什么优势?双向LSTM实际上就是将2个方向相反的LSTM连起来,如图4。
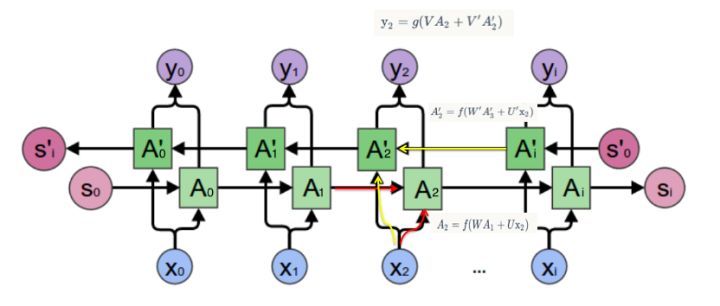
图4 BLSTM
一般来说,双向LSTM都好于单向LSTM。还是看LSTM介绍文章中的例子:
我的手机坏了,我打算____一部新手机。假设使用LSTM对空白部分填词。如果只看横线前面的词,“手机坏了”,那么“我”是打算“修”还是“买”还是“大哭一场”?双向LSTM能看到后面的词是“一部新手机“,那么横线上的词填“买“的概率就大得多了。显然对于文字检测,这种情况也依然适用。
如何通过"FC"卷积层输出产生图2-b中的Text proposals?
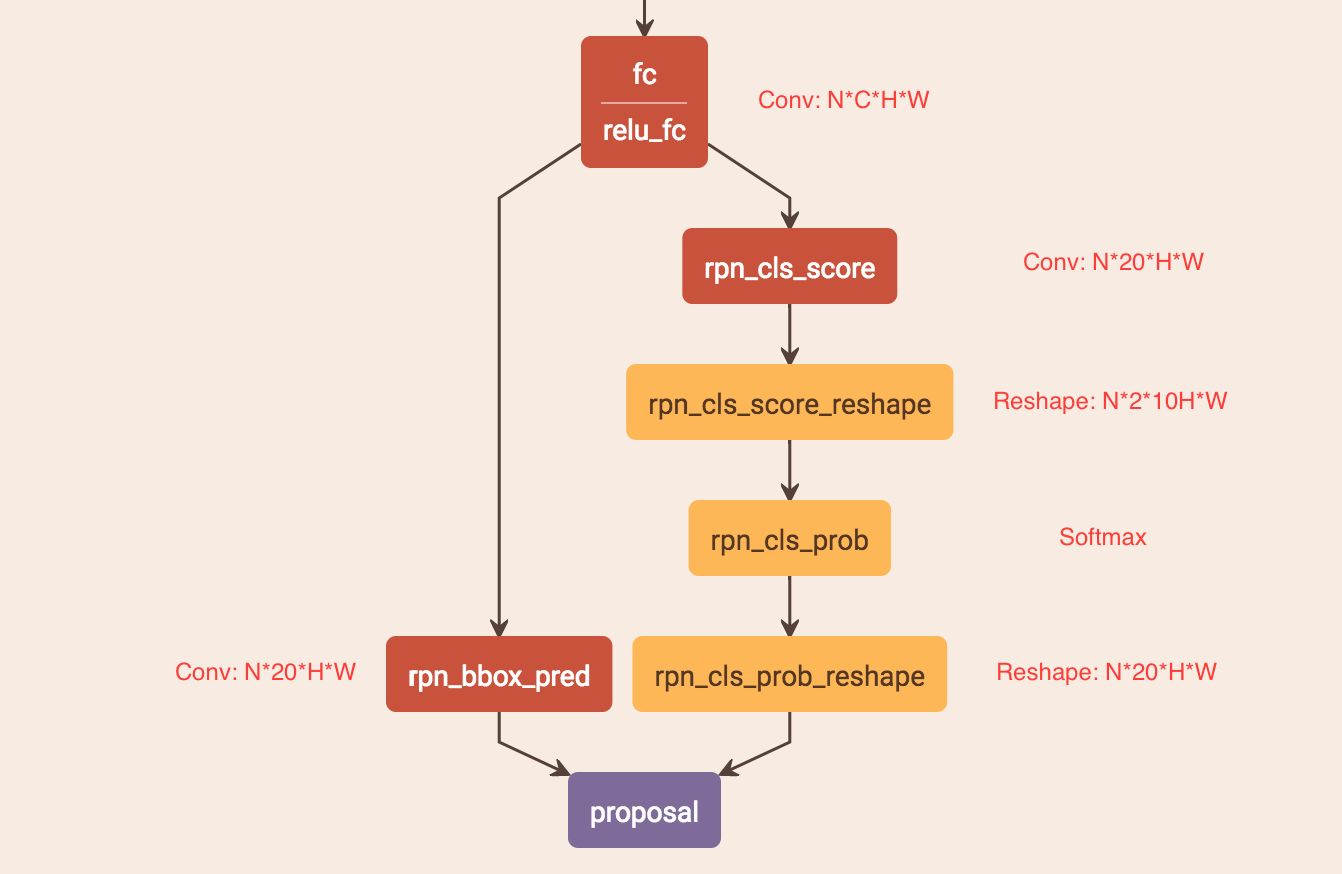
图5 CTPN的RPN网络
CTPN通过CNN和BLSTM学到一组“空间 + 序列”特征后,在"FC"卷积层后接入RPN网络。这里的RPN与Faster R-CNN类似,分为两个分支:
- 左边分支用于bounding box regression。由于fc feature map每个点配备了10个Anchor,同时只回归中心y坐标与高度2个值,所以rpn_bboxp_red有20个channels
- 右边分支用于Softmax分类Anchor
具体RPN网络与Faster R-CNN完全一样,所以不再介绍,只分析不同之处。
竖直Anchor定位文字位置
由于CTPN针对的是横向排列的文字检测,所以其采用了一组(10个)等宽度的Anchors,用于定位文字位置。Anchor宽高为:
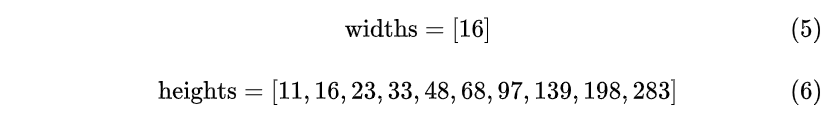
需要注意,由于CTPN采用VGG16模型提取特征,那么conv5 feature map的宽高都是输入Image的宽高的 1/16 。同时fc与conv5 width和height都相等。
与图像分类的任务中只有输出向量要匹配不同,这里我们有若干个参考位置要匹配。这意味着该网络可以一次性预测若干个物体。要预测的物体数量可以通过对多特征图层次进行预测或通过增加特征图上所谓的参考位置来增加。
这些参考位置就是anchor boxes或者default boxes。
如图6所示,CTPN为fc feature map每一个点都配备10个上述Anchors。

图6 CTPN Anchor
这样设置Anchors是为了:
- 保证在 x 方向上,Anchor覆盖原图每个点且不相互重叠。
- 不同文本在 y 方向上高度差距很大,所以设置Anchors高度为11-283,用于覆盖不同高度的文本目标。
Anchor大小为什么对应原图尺度,而不是conv5/fc特征尺度。这是因为Anchor是目标的候选框,经过后续分类+位置修正获得目标在原图尺度的检测框。那么这就要求Anchor必须是对应原图尺度!除此之外,如果Anchor大小对应conv5/fc尺度,那就要求Bounding box regression把很小的框回归到很大,这已经超出Regression小范围修正框的设计目的。
Faster R CNN结构详解

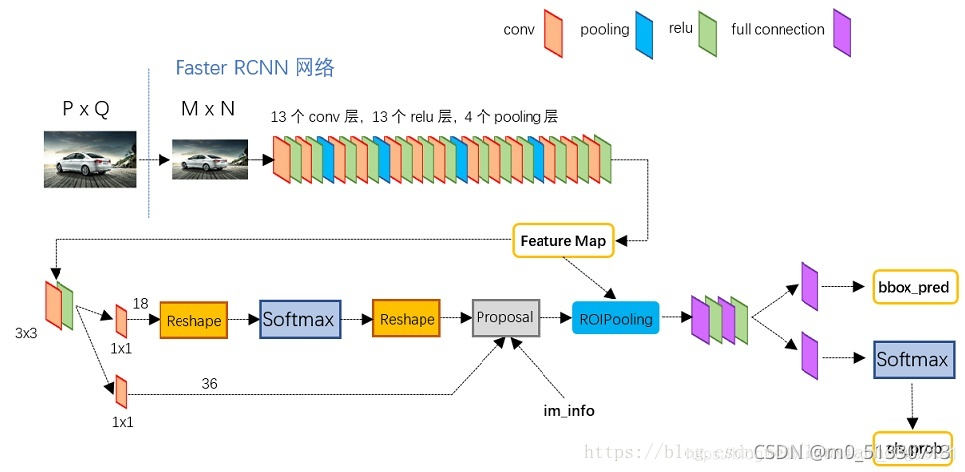
从上面的三张图可以看出,Faster R CNN由下面几部分组成:
1.数据集,image input
2.卷积层CNN等基础网络,提取特征得到feature map
3-1.RPN层,再在经过卷积层提取到的feature map上用一个3x3的slide window,去遍历整个feature map,在遍历过程中每个window中心按rate,scale(1:2,1:1,2:1)生成9个anchors,然后再利用全连接对每个anchors做二分类(是前景还是背景)和初步bbox regression,最后输出比较精确的300个ROIs。
3-2.把经过卷积层feature map用ROI pooling固定全连接层的输入维度。
4.然后把经过RPN输出的rois映射到ROIpooling的feature map上进行bbox回归和分类。
获得Anchor后,与Faster R-CNN类似,CTPN会做如下处理:
- Softmax判断Anchor中是否包含文本,即选出Softmax score大的正Anchor
- Bounding box regression修正包含文本的Anchor的中心y坐标与高度。
注意,与Faster R-CNN不同的是,这里Bounding box regression不修正Anchor中心x坐标和宽度。具体回归方式如下:
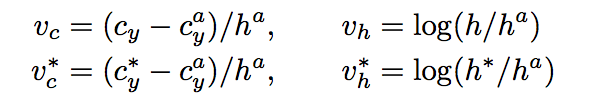
其中,![]() 是回归预测的坐标,
是回归预测的坐标, ![]() 是Ground Truth,
是Ground Truth,
Anchor经过上述Softmax和 y 方向bounding box regeression处理后,会获得图7所示的一组竖直条状text proposal。后续只需要将这些text proposal用文本线构造算法连接在一起即可获得文本位置。

图7 Text proposal
在论文中,作者也给出了直接使用Faster R-CNN RPN生成普通proposal与CTPN LSTM+竖直Anchor生成text proposal的对比,如图8,明显可以看到CTPN这种方法更适合文字检测。

图8
文本线构造算法
在上一个步骤中,已经获得了图7所示的一串或多串text proposal,接下来就要采用文本线构造办法,把这些text proposal连接成一个文本检测框。
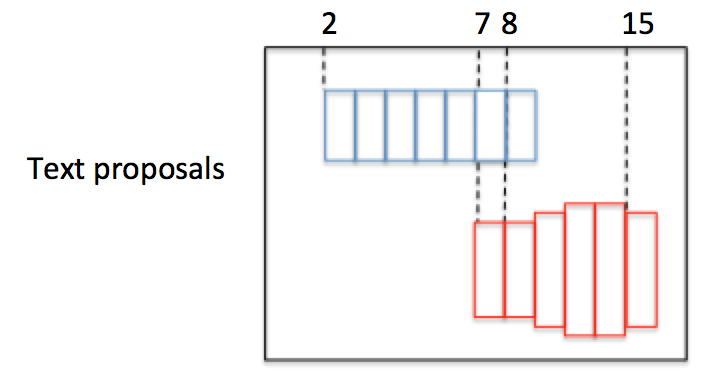
图9
为了说明问题,假设某张图有图9所示的2个text proposal,即蓝色和红色2组Anchor,CTPN采用如下算法构造文本线:
- 按照水平 x 坐标排序Anchor
- 按照规则依次计算每个Anchor
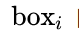 的
的 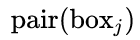 ,组成
,组成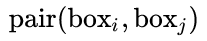
- 通过
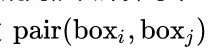 建立一个Connect graph,最终获得文本检测框
建立一个Connect graph,最终获得文本检测框
下面详细解释。假设每个Anchor index如绿色数字,同时每个Anchor Softmax score如黑色数字。
文本线构造算法通过如下方式建立每个Anchor ![]() 的 :
的 :![]()
正向寻找:
- 沿水平正方向,寻找和
 水平距离小于50像素的候选Anchor(每个Anchor宽16像素,也就是最多正向找50/16=3个)
水平距离小于50像素的候选Anchor(每个Anchor宽16像素,也就是最多正向找50/16=3个) - 从候选Anchor中,挑出与
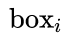 竖直方向
竖直方向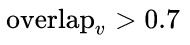 的Anchor
的Anchor - 挑出符合条件2中Softmax score最大的
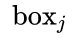
再反向寻找:
- 沿水平负方向,寻找和
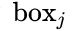 水平距离小于50的候选Anchor
水平距离小于50的候选Anchor - 从候选Anchor中,挑出与
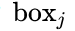 竖直方向
竖直方向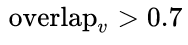 的Anchor
的Anchor - 挑出符合条件2中Softmax score最大的
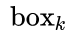
最后对比 ![]() 和
和 ![]() :
:
1、如果 ![]() ,则这是一个最长连接,那么设置
,则这是一个最长连接,那么设置
2、如果 ![]() ,说明这不是一个最长的连接(即该连接肯定包含在另外一个更长的连接中)。
,说明这不是一个最长的连接(即该连接肯定包含在另外一个更长的连接中)。
class TextProposalGraphBuilder:
......
def is_succession_node(self, index, succession_index):
precursors=self.get_precursors(succession_index)
# index 为上文中的 i, succession_index 为 j, precursors 为负向搜索找到的 k
if self.scores[index]>=np.max(self.scores[precursors]):
return True
return False
def build_graph(self, text_proposals, scores, im_size):
self.text_proposals=text_proposals
self.scores=scores
self.im_size=im_size
self.heights=text_proposals[:, 3]-text_proposals[:, 1]+1
boxes_table=[[] for _ in range(self.im_size[1])]
for index, box in enumerate(text_proposals):
boxes_table[int(box[0])].append(index)
self.boxes_table=boxes_table
graph=np.zeros((text_proposals.shape[0], text_proposals.shape[0]), np.bool)
for index, box in enumerate(text_proposals):
# 沿水平正方向寻找所有overlap_v > 0.7匹配
successions=self.get_successions(index)
if len(successions)==0:
continue
# 找匹配中socre最大的succession_index(即上文j)
succession_index=successions[np.argmax(scores[successions])]
# 沿水平负方向寻找socre最大的 k,如果socre_i >= score_k 则是一个最长连接
if self.is_succession_node(index, succession_index):
# NOTE: a box can have multiple successions(precursors) if multiple successions(precursors)
# have equal scores.
# 设置 Graph connection (i,j)为 True
graph[index, succession_index]=True
return Graph(graph)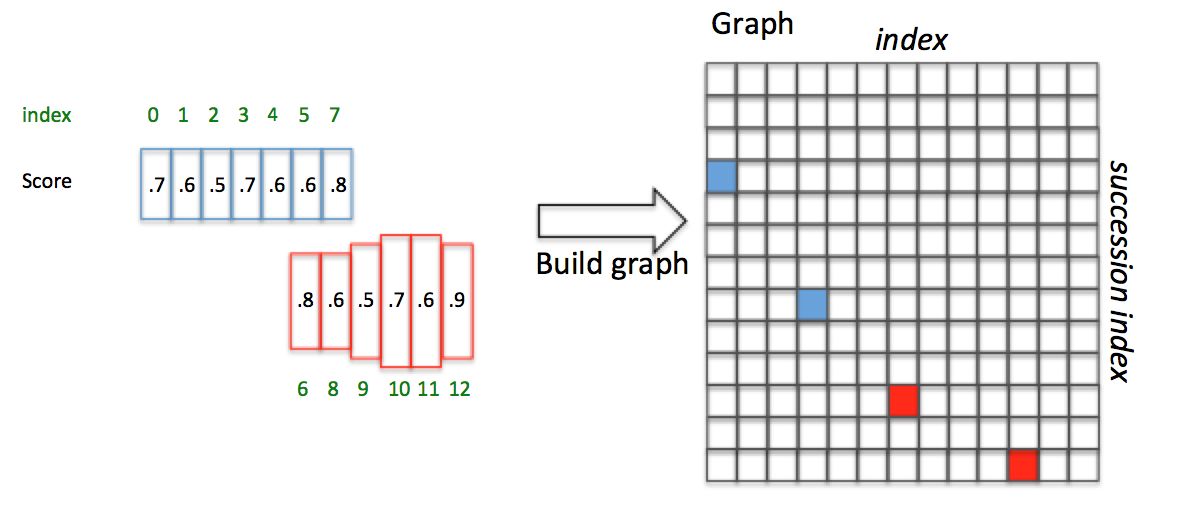
图10 构造文本线
举例说明,如图10,Anchor已经按照 x 顺序排列好,并具有图中的Softmax score(这里的score是随便给出的,只用于说明文本线构造算法):
- 对
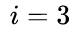 的
的 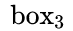 ,向前寻找50像素,满足 且score最大的是 ,即 ;
,向前寻找50像素,满足 且score最大的是 ,即 ; 反向寻找,满足
且score最大的是
,即
。由于
,
是最长连接,那么设置
- 对
 正向寻找得到
正向寻找得到 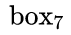 ; 反向寻找得到 ,但是 ,即
; 反向寻找得到 ,但是 ,即 不是最长连接,包含在
然后,这样就建立了一个 的Connect graph(其中 是正Anchor数量)。遍历Graph:
- 对
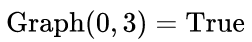 且
且  ,所以Anchor index 0->3->7组成一个文本,即蓝色文本区域。
,所以Anchor index 0->3->7组成一个文本,即蓝色文本区域。 - 对
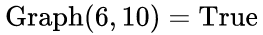 且
且 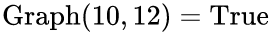 ,所以Anchor index 6->10->12组成另外一个文本,即红色文本区域。
,所以Anchor index 6->10->12组成另外一个文本,即红色文本区域。
这样就通过Text proposals确定了文本检测框。
训练策略
由于作者没有给出CTPN原始训练代码,所以此处仅能根据论文分析。
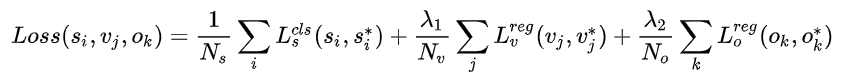
明显可以看出,该Loss分为3个部分:
- Anchor Softmax loss:该Loss用于监督学习每个Anchor中是否包含文本。 表示是否是Groud truth。
- Anchor y coord regression loss:该Loss用于监督学习每个包含为本的Anchor的Bouding box regression y方向offset,类似于Smooth L1 loss。其中 是 中判定为有文本的Anchor,或者与Groud truth vertical IoU>0.5。
- Anchor x coord regression loss:该Loss用于监督学习每个包含文本的Anchor的Bouding box regression x方向offset,与y方向同理。前两个Loss存在的必要性很明确,但这个Loss有何作用作者没有解释(从训练和测试的实际效果看,作用不大)
说明一下,在Bounding box regression的训练过程中,其实只需要注意被判定成正的Anchor,不需要去关心杂乱的负Anchor。这与Faster R-CNN类似。
总结
- 由于加入LSTM,所以CTPN对水平文字检测效果超级好。
- 因为Anchor设定的原因,CTPN只能检测横向分布的文字,小幅改进加入水平Anchor即可检测竖直文字。但是由于框架限定,对不规则倾斜文字检测效果非常一般。
- CTPN加入了双向LSTM学习文字的序列特征,有利于文字检测。但是引入LSTM后,在训练时很容易梯度爆炸,需要小心处理。