[python爬虫] 爬取学院老师信息_zcw1234515的博客
文章目录
- 任务
- 思路
- 分析
- 分析网页
- 结合代码
- 爬取结果
- 代码
- 展望
任务
- java 课堂的加分作业,原本应该使用java进行爬虫,但是在爬虫方面这个是python的优势,所以就趁此机会学习一下python爬虫,没有使用 java 进行实验;
- 过程比较辛苦,没有系统学过爬虫,但是python还是经常用的;初次尝试,很多不足,在此记录,下次完善!
思路
- 定位到提取信息的位置
- 将对应的信息提取出来,存到字典里
- 由于不是每个老师的信息都是相同的,需要进行判断处理
- 判断的过程中,对于关键字也是存在差异的,例如有的老师显示邮箱地址,有的是邮件地址;有的是讲课课程,有的是授课课程,有的是部门有的是研究所;还有的是,网页上信息多行写到一个段内,有的是一个信息一段,这个过程增加了信息提取的难度;这也让自己明白了,写代码一定要规范,相同的属性要用同一套标准,不能多种格式;
分析
分析网页
-
进入网址:
http://jsj.gzhu.edu.cn/szdw1/jsjkxywlgcxysz.htm

-
鼠标右键选择检查元素(火狐或者谷歌)快捷键 F12

结合代码
r = requests.get(url,headers=headers)
#设置编码方式,否则出现乱码
r.encoding='utf-8'
html = bs4.BeautifulSoup(r.text, "html.parser")
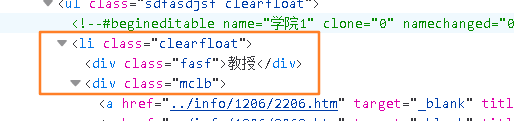
#找到网页标签为 "ul" 下 class_="sdfasdjsf clearfloat" 下的所有 "li" 列表标签 每个列表代表一个老师
all_job = html.find("ul", class_="sdfasdjsf clearfloat").find_all("li") # 找到所有列表 返回是列表代表教授,副教授,讲师
在变量这三个块 找到信息类的标志
for data in all_job:
zhichenk = data.find("div", class_="fasf").get_text() # 找到div class_="fast" 教授这个块
name = data.find("div", class_="mclb") # 找到对应的"mclb"类
进入到教授列表下,变量找到每个老师的下面和消息链接
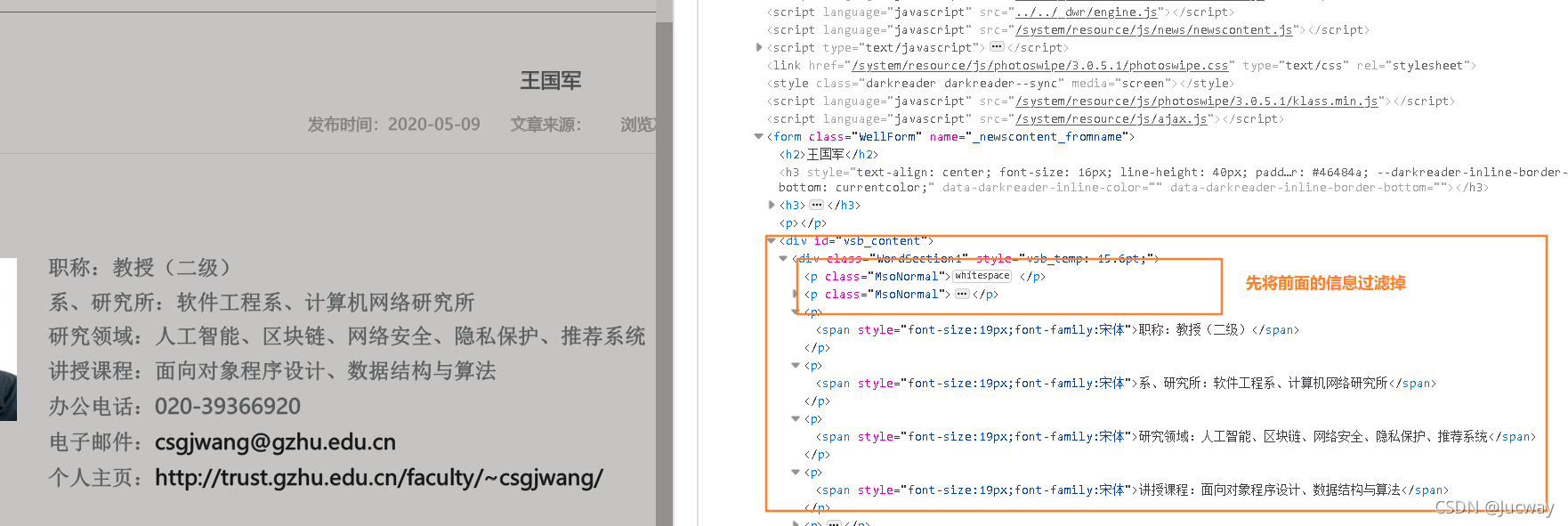
进入主页将每个老师的姓名和对应的详细的详细的链接提取出来进行拼接之后请求拼接后的新链接
for j in range(len(name)): # 循环每个老师 第一次进入的是教授这个列表的老师,第二次进入副教授,第三次进入讲师
l = len(name)
k = j*2+1 # 这个是网页是每个老师信息出现之后会空一行,所以有用的信息在奇数行下
if k>=len(name): # 越界退出
break
a = name.contents[k] # 获取这一行的信息
m_href = a.attrs['href'] # 找到进入老师详细信息的链接
xinming = a.attrs['title'] # 这里通过debug 发现title 属性是教师名称
result["姓名"][count] = xinming # 在字典对应位置写入
m_href = "http://jsj.gzhu.edu.cn/"+m_href[3:] # 提出出来的连接是相对地址,去掉开头.. 添加上完整地址
r1 = requests.get(m_href, headers=headers) # 请求新的链接进入信息页面
r1.encoding='utf-8'
bs1 = bs4.BeautifulSoup(r1.text, 'html.parser')
sour = bs1.find('div', id='vsb_content').find_all('p') # 信息在id 为"vsb_content" 的段内
爬取每个块(教授,副教授,讲师各为一个块) 的 信息
for x in sour: # 遍历每个段
inflag = count
str = x.text # 获取文本信息
str = str.lstrip() # 去除信息的左空格
if str.count(":") >= 2: # 这一步判断是因为网页的信息有部分没有规矩,不能直接提取
s = str.split(" ") # 取出字符串前后空格
for i in s:
title = i.split(":") # 按照: 进行分割字符串
if len(title) == 1: # 空字符
continue
if title[0] == "职务":
result["职称"][inflag] = title[1]
elif title[0] == "电子邮箱" or title[0] == "个人邮箱":
result["电子邮件"][inflag] = title[1]
elif title[0] == "讲述课程":
result["讲授课程"][inflag] = title[1]
elif title[0] == "部门":
result["系、研究所"][inflag] = title[1]
else:
result[title[0]][inflag] = title[1]
continue
str = "".join(str.split()) # 去除字符串中的空格
if str == '\n' or str == '' or len(str)==1 or str == '\r\n' or str == '\xa0\xa0\xa0': # 去除无关信息
continue
str = str.strip() # 去除空格
title = str.split(":") # 正常匹配按照冒号进行分割
if title[0] == "职务":
result["职称"][inflag] = title[1]
elif title[0] == "电子邮箱" or title[0] == "个人邮箱":
result["电子邮件"][inflag] = title[1]
elif title[0] == "讲述课程":
result["讲授课程"][inflag] = title[1]
elif title[0] == "部门":
result["系、研究所"][inflag] = title[1]
else:
result[title[0]][inflag]= title[1] # 不是特殊情况按照字典进行填写
infalg = j
爬取结果
- 由于是公共网站的资源,但是关键信息还是得遮挡一下;

代码
文件
# _*_coding:utf-8_*_
# create by Jucw on 2021/11/24 11:44
import requests
import bs4
import re
import pandas as pd # 存表格
n = 66 # 估计大概多少个教师
# 存储数据,这是对于每个老师的个人信息不是统一的,将没有的信息用空字符串填充
result = {"姓名": [""]*n,
"职称": [""]*n,
"系、研究所":[""]*n,
"研究领域":[""]*n,
"办公电话":[""]*n,
"电子邮件":[""]*n,
"讲授课程":[""]*n,
"个人主页":[""]*n,
"办公地点":[""]*n
}
# 计算机学院的网址
url = "http://jsj.gzhu.edu.cn/szdw1/jsjkxywlgcxysz.htm"
# 网址设置了反爬虫,添加请求头模拟浏览器登录
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:94.0) Gecko/20100101 Firefox/94.0'
}
# 请求数据
r = requests.get(url,headers=headers)
# 设置编码方式,否则出现乱码
r.encoding='utf-8'
# 解析
html = bs4.BeautifulSoup(r.text, "html.parser")
# 找到网页标签为 "ul" 下 class_="sdfasdjsf clearfloat" 下的所有 "li" 列表标签 每个列表代表一个老师
all_teacher = html.find("ul", class_="sdfasdjsf clearfloat").find_all("li")
# count 代表第几个老师,用于将数据写入到字典对应的位置
count = 0
for data in all_teacher:
zhichenk = data.find("div", class_="fasf").get_text() # 找到div class_="fast" 教授这个块
name = data.find("div", class_="mclb") # 找到对应的"mclb"类
for j in range(len(name)): # 循环每个老师 第一次进入的是教授这个列表的老师,第二次进入副教授,第三次进入讲师
k = j*2+1 # 这个是网页是每个老师信息出现之后会空一行,所以有用的信息在奇数行下
if k>=len(name): # 越界退出
break
a = name.contents[k] # 获取这一行的信息
m_href = a.attrs['href'] # 找到进入老师详细信息的链接
xinming = a.attrs['title'] # 这里通过debug 发现title 属性是教师名称
result["姓名"][count] = xinming # 在字典对应位置写入
m_href = "http://jsj.gzhu.edu.cn/"+m_href[3:] # 提出出来的连接是相对地址,去掉开头.. 添加上完整地址
r1 = requests.get(m_href, headers=headers) # 请求新的链接进入信息页面
r1.encoding='utf-8'
bs1 = bs4.BeautifulSoup(r1.text, 'html.parser')
sour = bs1.find('div', id='vsb_content').find_all('p') # 信息在id 为"vsb_content" 的段内
for x in sour: # 遍历每个段
inflag = count
str = x.text # 获取文本信息
str = str.lstrip() # 去除信息的左空格
if str.count(":") >= 2: # 这一步判断是因为网页的信息有部分没有规矩,不能直接提取
s = str.split(" ") # 取出字符串前后空格
for i in s:
title = i.split(":") # 按照: 进行分割字符串
if len(title) == 1: # 空字符
continue
if title[0] == "职务":
result["职称"][inflag] = title[1]
elif title[0] == "电子邮箱" or title[0] == "个人邮箱":
result["电子邮件"][inflag] = title[1]
elif title[0] == "讲述课程":
result["讲授课程"][inflag] = title[1]
elif title[0] == "部门":
result["系、研究所"][inflag] = title[1]
else:
result[title[0]][inflag] = title[1]
continue
str = "".join(str.split()) # 去除字符串中的空格
if str == '\n' or str == '' or len(str)==1 or str == '\r\n' or str == '\xa0\xa0\xa0': # 去除无关信息
continue
str = str.strip() # 去除空格
title = str.split(":") # 正常匹配按照冒号进行分割
if title[0] == "职务":
result["职称"][inflag] = title[1]
elif title[0] == "电子邮箱" or title[0] == "个人邮箱":
result["电子邮件"][inflag] = title[1]
elif title[0] == "讲述课程":
result["讲授课程"][inflag] = title[1]
elif title[0] == "部门":
result["系、研究所"][inflag] = title[1]
else:
result[title[0]][inflag]= title[1] # 不是特殊情况按照字典进行填写
infalg = j
count = count + 1 # 提取下一个老师信息
df = pd.DataFrame(result) #将字典使用格式转换
df.to_csv("jiaoshi1.csv", encoding="utf_8_sig") # 保存信息 防止csv 产生乱码
展望
-
python 爬虫涉及正则表达式,xpath解析等等,由于不太熟悉,没能很好优化! 占坑
学习! -
下一次学习!
-
下图是知乎上的总结图 知乎@流年 ,若侵,联系删!记录学习!

技术路线
登录后可发表评论
点击登录