计算机硬件基础(软件学院计组)P4——用Logisim实现流水线CPU
目录
- 计算机硬件基础(软件学院计组)P4——用Logisim实现流水线CPU
- 实验内容
- 实验要求
- 提交要求
- 题解
- 前言及其预备知识(请务必阅读)
- 流水线概述
- 理想流水线CPU
- 理想流水线测试(==极弱数据测试==)
- 流水线搭建(无冒险转发机制)
- 1.IF端
- PC
- NPC
- 2.ID端
- F_D_Reg
- Splitter:
- Ext
- controller
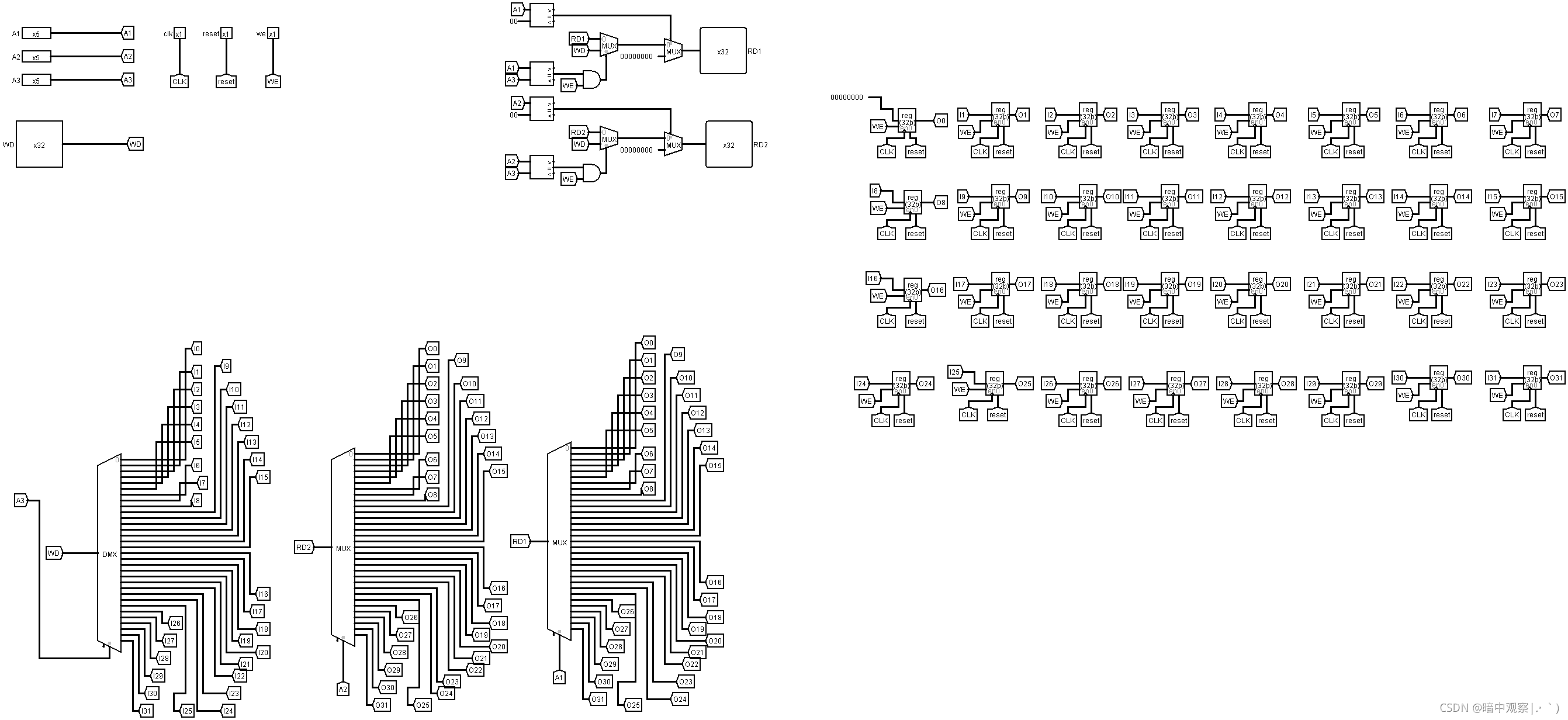
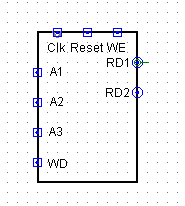
- GRF
- 3.EX端
- D_E_Reg
- ALU
- 4.MEM端
- EM_Reg
- DM
- 5. WB段
- M_W_Reg
- 流水线冒险与AT法介绍
- 流水线冒险
- 结构冒险
- 控制冒险
- 数据冒险
- AT法
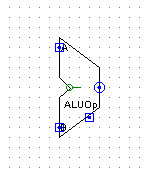
- AT法是什么
- 转发(旁路)机制的构造
- 暂停(阻塞)机制的构造
- Tuse 和Tnew的表格
- 流水线搭建(转发和暂停)(来自于软院gjz大哥的分析和操作,小弟现场打call!!该部分和gjz大哥的相近,增加的内容用黄色标注了)
- 流水线的分布式译码展示
- 流水线转发模块展示
- 流水线暂停模块展示
- 流水线CPU的冲突控制
- 流水线CPU的转发模块
- 具体分布式译码
- 内部转发
- 流水线CPU转发和冲突测试(==中等强度数据==,和课下数据数据强度一致,如果课下没有通过请务必测试该数据,亲测有效)
- 测试注意
- 测试细节
- 测试数据
- 正确结果
- 流水线CPU总体测试(==强测试==)
- 结语
实验内容
实验要求
使用logism自主搭建出一个支持所给指令集的32位五级流水线CPU,并通过课下正确性测试。
课上会通过新增指令的方式,来考核课下设计的CPU。
提供的所有模块请在课件下载中获得。
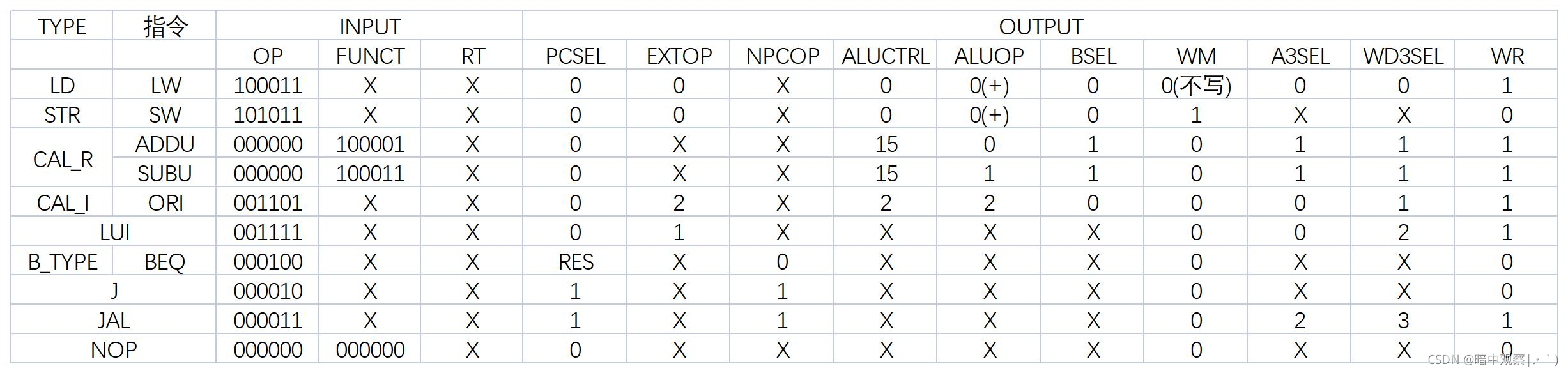
指令集:lw,sw,addu,subu,lui,ori,jal,j,beq,nop。
nop是空指令(0x00000000),不进行有效行为(修改内存、寄存器等)。
内存大小:32字。
ROM大小:要求能执行1024条指令。ROM不一定需要地址的全部位数。
PC需要复位功能,起始地址为0x00003000。
提交要求
顶层模块命名为main
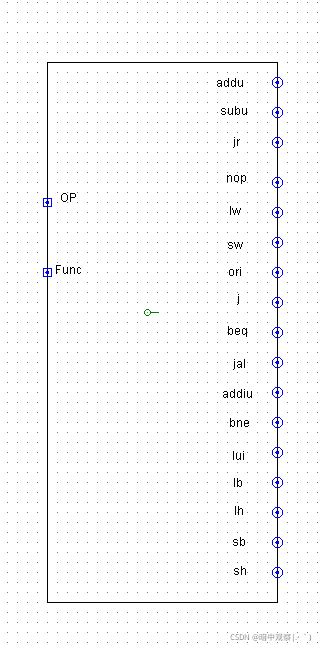
顶层模块样式及端口请严格按照以下提交:
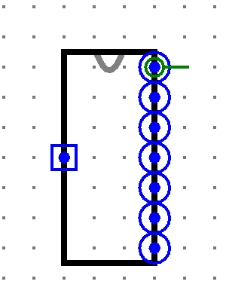
左侧端口是输入端口:Reset信号,可以对PC、GRF、DM、流水线寄存器复位。
右一端口是Instr:32位指令码。
右二端口是RegWrite:1位寄存器堆写入信号。
右三端口是RegAddr:5位寄存器编号。
右四端口是RegData:32位写入寄存器数据。
右五端口是MemWrite:1位DM写入信号。
右六端口是MemAddr:5位写入地址。
右七端口是MemData:32位写入DM数据。
上述所有信号均取自于W段的信号。
建议main内部端口的相对位置如下排列:
题解
参考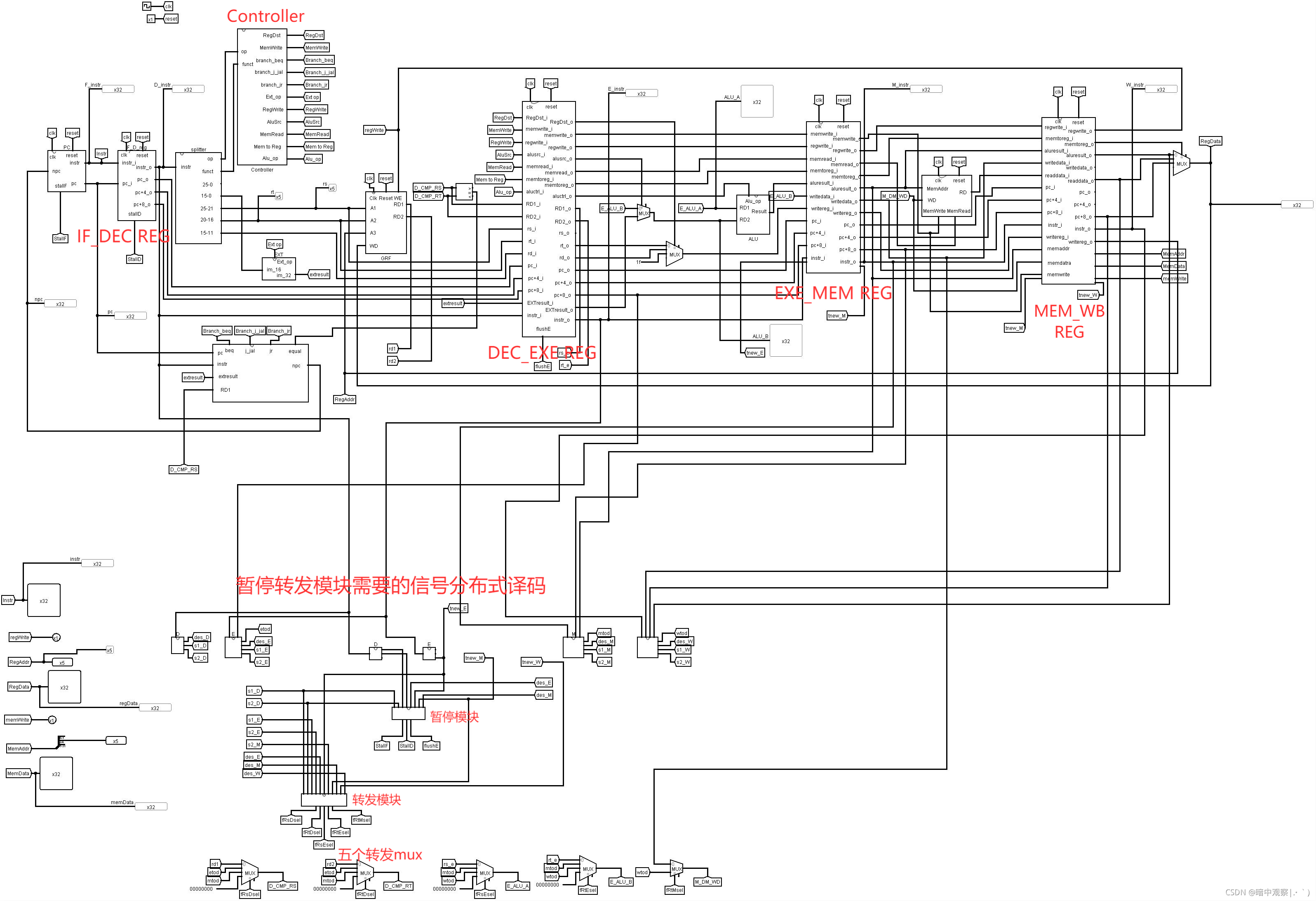
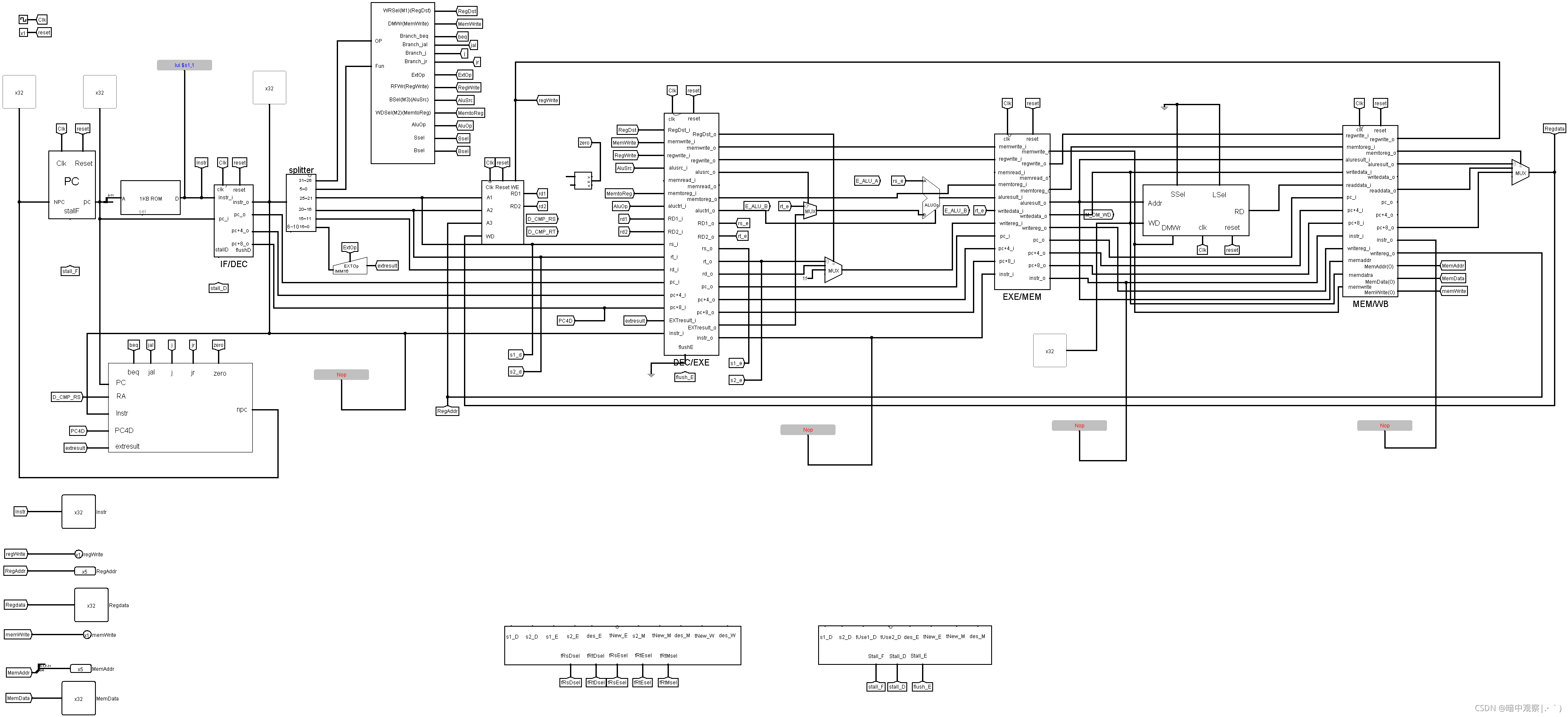
先附上一张助教哥提供的顶层视图,这个对我的流水线设计有很大的帮助,我最终的流水线也是根据这个来的
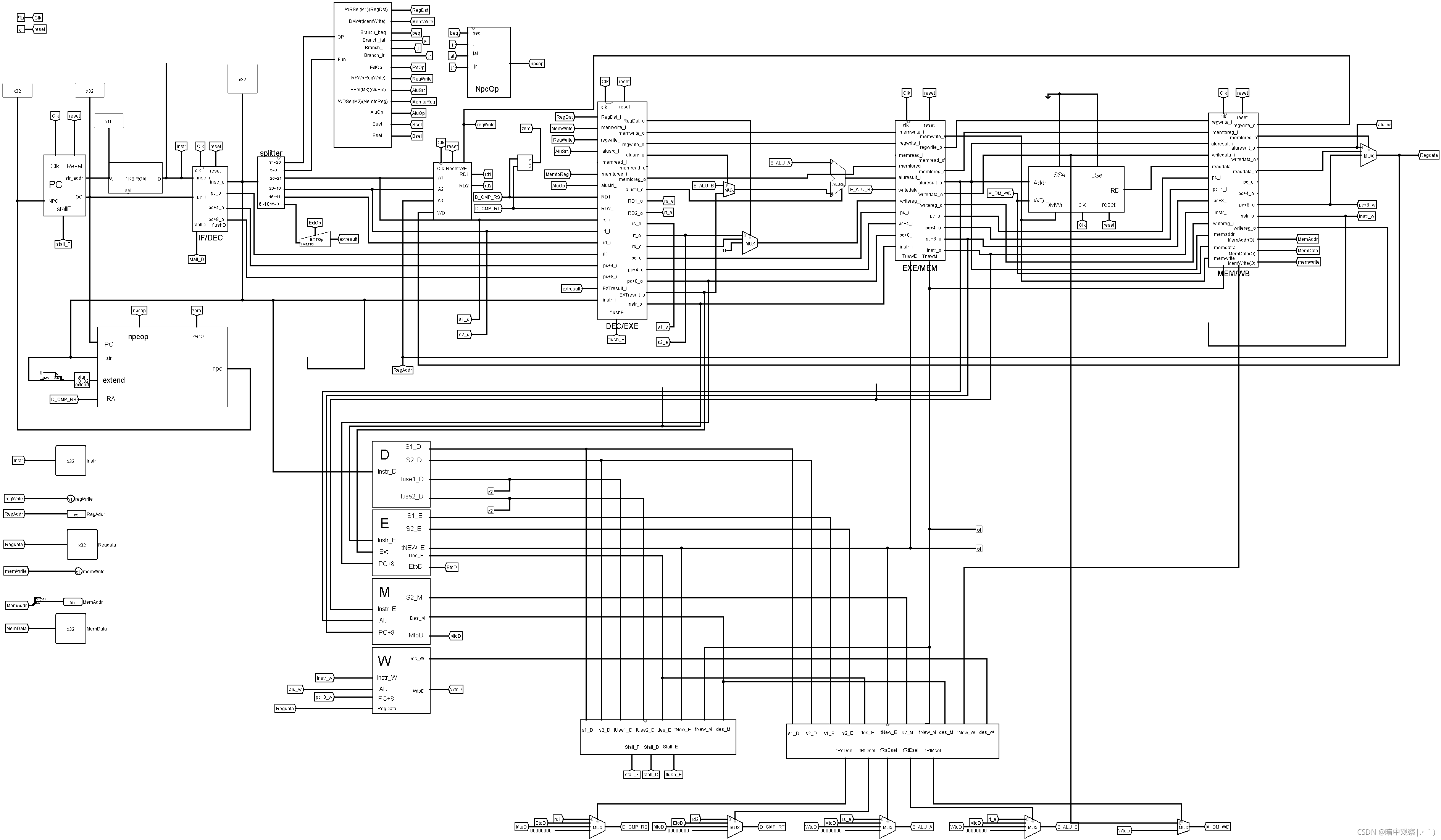
上面是我的流水线的整体视图,不难看出,其实照着搭的哈哈哈哈哈
前言及其预备知识(请务必阅读)
本篇文章参考了另一位软院大哥gjz大哥的文章——>点击这里
在获得大哥的允许下,我适当的引用了大哥写的很不错的地方,如果时间允许,希望可以去读一读大哥的文章,并且给一个赞同吧哈哈哈哈哈哈。
好久没有写过博客了,但是这一次流水线我还是打算写一下,因为这一次用Logisim搭流水线我遇到了挺多的问题,踩过很多坑,走过很多弯路,所以我写这一篇博客,目的不仅仅在于分享的CPU是如何搭建,更重要的是帮助搭建流水线CPU有困难的同学更好的掌握流水线的搭法,同时也希望借此机会可 以实现自己知识的梳理和总结。
但是要注意的是:
- 这篇文章的面向对象不是没有任何搭建CPU经验和基础的人,如果对于单周期CPU的搭建不是很熟练,而且对于流水线CPU理论上有不足的,请认真仔细阅读高老板的两个课件,这两个课件在当时直接把我的理论知识拉满了(我计组课上课就没有听过,甚至有时还没去哈哈哈哈),理论知识不够的可以看这个课件解决(比如暂停转发,AT法之类的)。
- 本篇文章更多是在于分享,而不是怎么手把手教你搭流水线CPU,更多的是在于问题的解答,内部模块的实现,以及图片的分享
- 对于本篇文章所以提供的测试数据,请务必用Logging功能进行测试,不会用Logging测试的请看自行去学习(或者找我要教学视频),因为测评机采用的测试模式基本和Logging相符,所以采用Logging功能可以更还原上机,而不是简单的查看DM模块的数值。同时在MARS上编译代码查看结果的时候,请务必开启延迟槽,否则测试结果不正确。
流水线概述
相比于单周期CPU,其实流水线的核心思想无非就是在单周期CPU的各个阶段之间加上寄存器,让控点数据和数据通路中的数据进入流水。每一个时钟周期内CPU的各个阶段专注于处理上一级流水传下来的数据,然后把结果传给下一级,就像流水线工人一样。这样带来的好处就是,时钟周期的长度就由最长的数据通路(LW)的时间变成了最耗时的访存阶段(MEM) 的时间,从而提升了CPU的频率。
这次搭建的五级流水CPU的阶段分为:**取指(Instruction Fetch)、译码(Instruction Decode)、执行(Excution)、访存(Memory Access)、写回(Write Back)五个部分,以下简称为IF、ID、EX、MEM、WB。**而流水线需要在每个阶段之间加入寄存器,接受并流水一个阶段产生的所有数据。根据寄存器的位置我们将四个寄存器命名为FD_Reg、DE_Reg、EM_Reg、MW_Reg。
同时流水线也带来分支冲突和数据冲突的问题。对于分支指令,无论是无条件分支(如beq)还是有条件分支(如jal),最早也得在ID阶段获取目标地址并且做出是否跳转的决断。那么无论如何下一条指令也会进入IF阶段。不跳转还好,一旦跳转已经进入IF的指令就会变成错误的指令,需要插入气泡造成性能下降。因此MIPS提出了延迟槽来解决这个问题,将一条与分支无关的指令放入分支指令的后面,让其也参与正常流水。当然决定延迟槽中是什么指令不是我们需要关注的事情,这部分将交由编译器后端来解决。
数据冲突就是指如果第i条指令的取值取决于第i-1条指令的结果,而第i-1条指令的结果还在流水线中的情况。对于这种情况我们有两种方案应对:一是阻塞流水线,等待i-1条指令写回寄存器再使用;二是设计数据旁路,将后阶段计算完成的数据转发给前面需要使用到此数据的阶段,以解燃眉之急。
显然上述竞争冒险的解决方案是有很多种选择的,比如华中科技大学的计组用的就是EX段决定分支+阻塞+数据旁路的方案。这里我明确一下我们设计CPU方案是延迟槽+阻塞+数据旁路的方案。
理想流水线CPU
先放上一张我的理想流水线的图片。
在真正搭建流水线CPU的时候,请务必注意你的理想流水线一定是正确的。假设指令序列不存在分支和数据冲突,段与段之间指令互不影响流水线CPU被称为理想流水线,我们可以用之前P3的单周期CPU改装成理想流水线CPU,改装方式就是通过加入助教哥给的模块即可,但是注意,你的每一条线请务必检查有没有连错,这个问题看起来很小但是引发的隐患是巨大无比的,所以搭建理想流水线的时候要小心连接接口哦~。
其次要注意的是,你的理想流水线应该是具备可拓展性的,如果之后加入的指令导致理想流水线需要进行大的改动,那么其实在后续的连锁修改上是十分困难的(比如lb,sb,lh,lh之类的指令)。上图给出的设计是不考虑分支的,因此NPC(NextPC)只会输出PC+4。
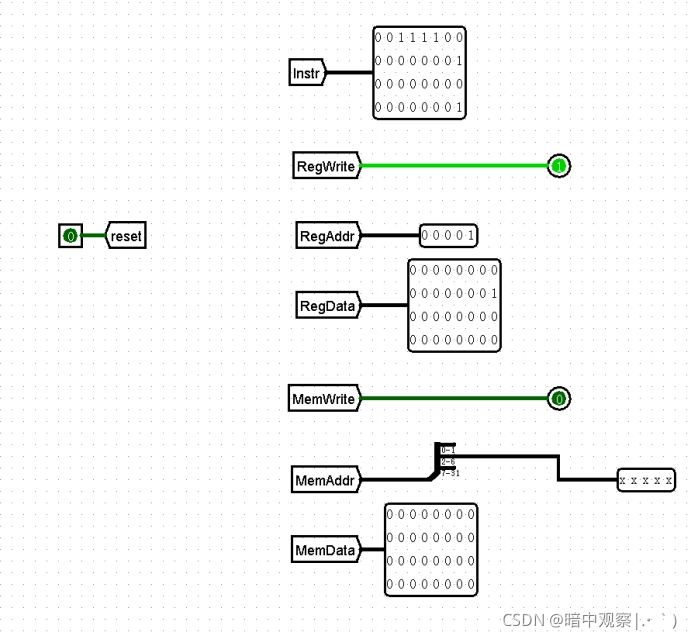
理想流水线测试(极弱数据测试)
可以用下列代码测试理想流水CPU是否有问题,对照Mars给出的结果(看看DM模块一不一样)和Logging的结果(正式测评):
#Mars测试代码
lui $s1, 1
lui $s2, 2
lui $s3, 3
lui $s4, 4
ori $s1, $s1, 1
ori $s2, $s2, 2
ori $s3, $s3, 3
ori $s4, $s4, 4
sw $s1,0($0)
sw $s2,4($0)
sw $s3,8($0)
sw $s4,12($0)
十六进制文件内容
v2.0 raw
3c110001
3c120002
3c130003
3c140004
36310001
36520002
36730003
36940004
ac110000
ac120004
ac130008
ac14000c
Logging测试结果
Instr regWrite RegAddr Regdata memWrite MemAddr MemData
0011 1100 0001 0001 0000 0000 0000 0001 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000
0011 1100 0001 0010 0000 0000 0000 0010 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000
0011 1100 0001 0011 0000 0000 0000 0011 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000
0011 1100 0001 0100 0000 0000 0000 0100 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000
0011 0110 0011 0001 0000 0000 0000 0001 1 1 0001 0000 0000 0000 0001 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000
0011 0110 0101 0010 0000 0000 0000 0010 1 1 0010 0000 0000 0000 0010 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000
0011 0110 0111 0011 0000 0000 0000 0011 1 1 0011 0000 0000 0000 0011 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000
0011 0110 1001 0100 0000 0000 0000 0100 1 1 0100 0000 0000 0000 0100 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000
1010 1100 0001 0001 0000 0000 0000 0000 1 1 0001 0000 0000 0000 0001 0000 0000 0000 0001 0 0 0000 0000 0000 0000 0001 0000 0000 0000 0000
1010 1100 0001 0010 0000 0000 0000 0100 1 1 0010 0000 0000 0000 0010 0000 0000 0000 0010 0 0 0000 0000 0000 0000 0010 0000 0000 0000 0000
1010 1100 0001 0011 0000 0000 0000 1000 1 1 0011 0000 0000 0000 0011 0000 0000 0000 0011 0 0 0000 0000 0000 0000 0011 0000 0000 0000 0000
1010 1100 0001 0100 0000 0000 0000 1100 1 1 0100 0000 0000 0000 0100 0000 0000 0000 0100 0 0 0001 0000 0000 0000 0100 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000 0 1 0001 0000 0000 0000 0000 0000 0000 0000 0000 1 0 0000 0000 0000 0000 0001 0000 0000 0000 0001
0000 0000 0000 0000 0000 0000 0000 0000 0 1 0010 0000 0000 0000 0000 0000 0000 0000 0100 1 0 0001 0000 0000 0000 0010 0000 0000 0000 0010
0000 0000 0000 0000 0000 0000 0000 0000 0 1 0011 0000 0000 0000 0000 0000 0000 0000 1000 1 0 0010 0000 0000 0000 0011 0000 0000 0000 0011
0000 0000 0000 0000 0000 0000 0000 0000 0 1 0100 0000 0000 0000 0000 0000 0000 0000 1100 1 0 0011 0000 0000 0000 0100 0000 0000 0000 0100
0000 0000 0000 0000 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 1100 0 0 0011 0000 0000 0000 0000 0000 0000 0000 0000
如果你的Logging测试正确,那么恭喜你,你的理想流水线没有问题。
流水线搭建(无冒险转发机制)
1.IF端
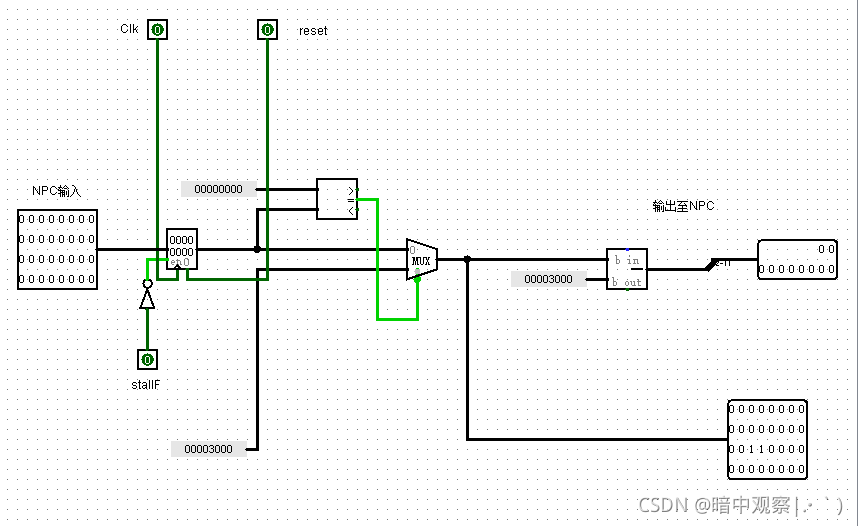
PC
- 坑点:
- 没有-3000回复原地址
- StallF接入寄存器使能端的时候没有加非门
- RAM要求的是1024条指令,所以str_addr要求的是2-11位
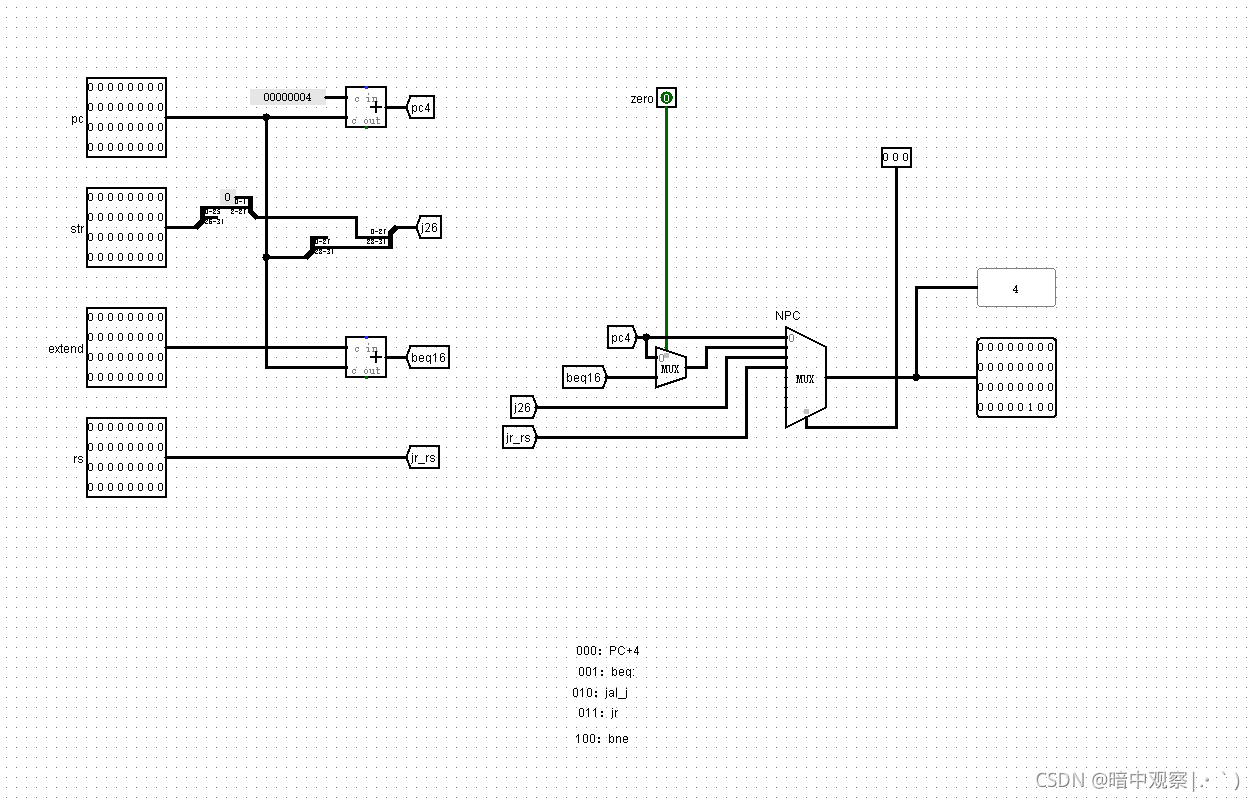
NPC
- 坑点:
- PC的输入值是从PC输入的,不是流水之后的PC值
- j_jal的结果需要小心([Imm_{26}->2]_{32}(无条件分支))
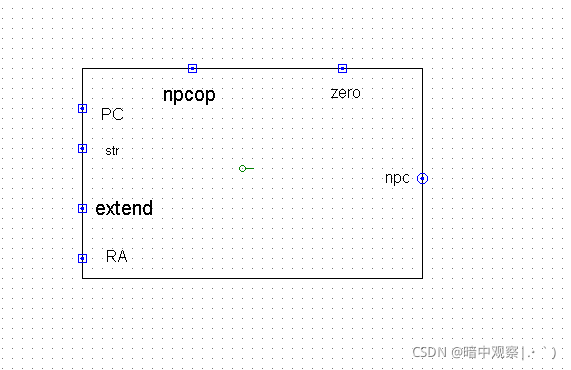
2.ID端
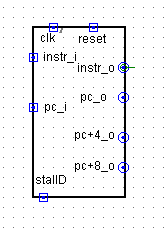
F_D_Reg
stallD高电平堵塞
Splitter:
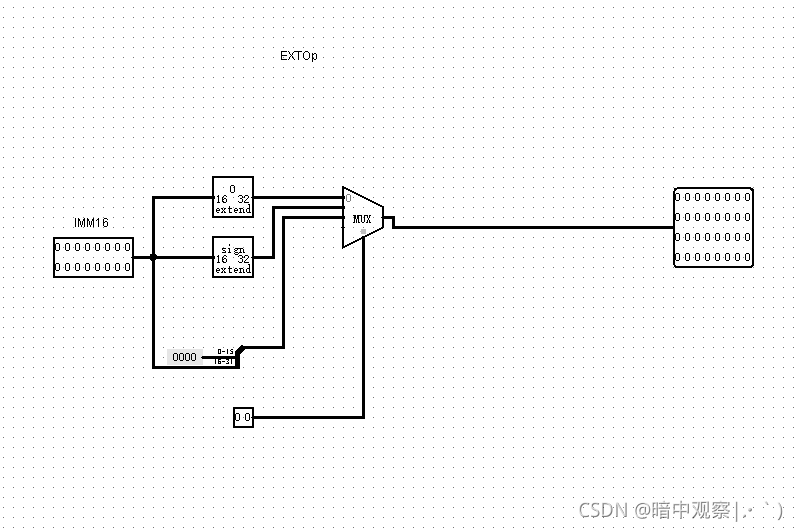
Ext
controller
这里为了方便之后的AT法实现转发和暂停,所以我还单独设了一个controller-part模块,主要就是实现与或门译码。
下面是controller-part模块
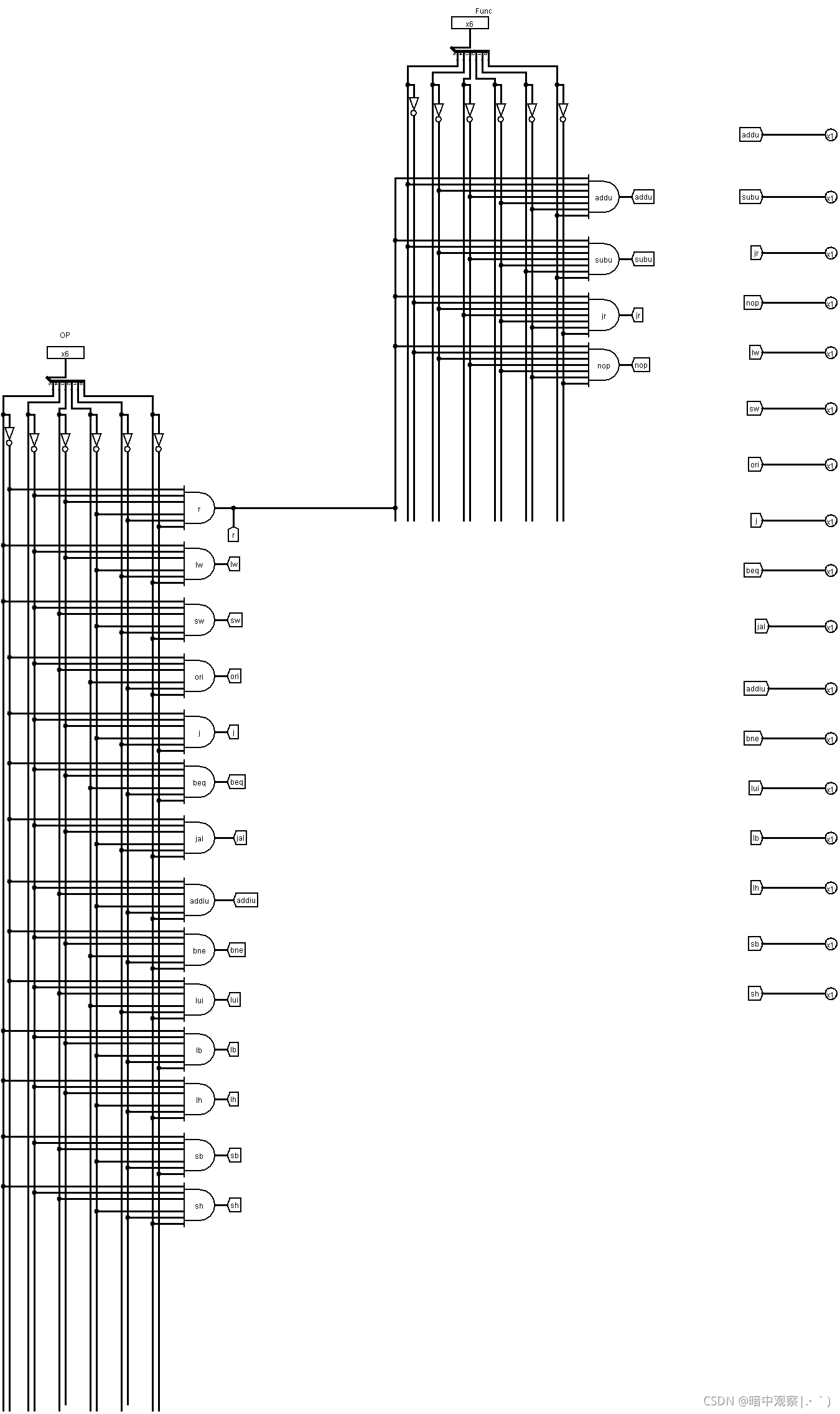
下面是整个controller
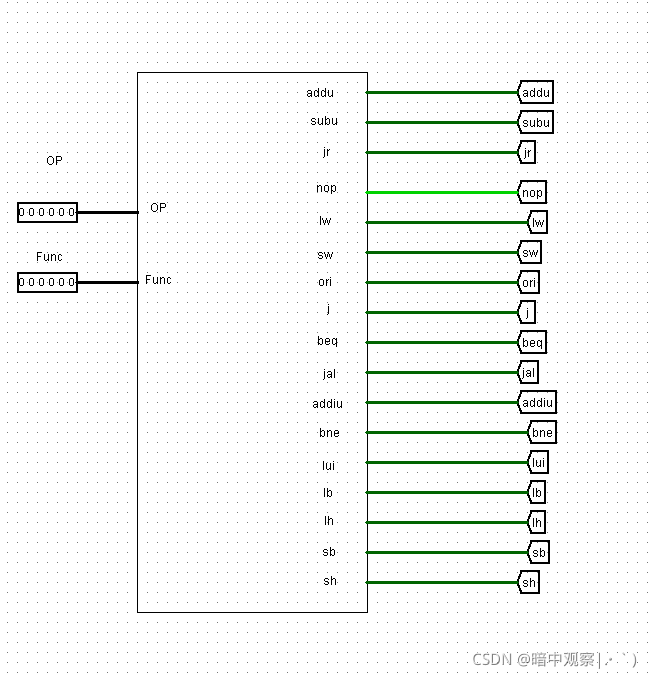
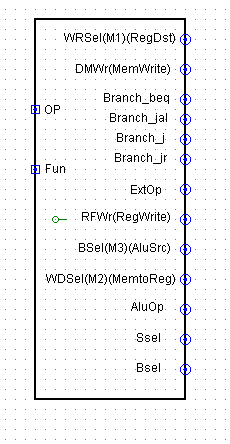
下面给出的参考构建的表格
GRF
- 坑点:不会实现内部转发(这个我们待会再说,先上图)
3.EX端
D_E_Reg
flushE高电平清空寄存器制造气泡
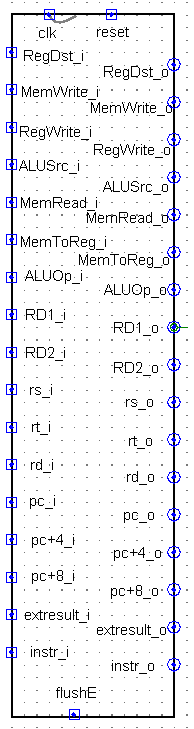
ALU

4.MEM端
EM_Reg
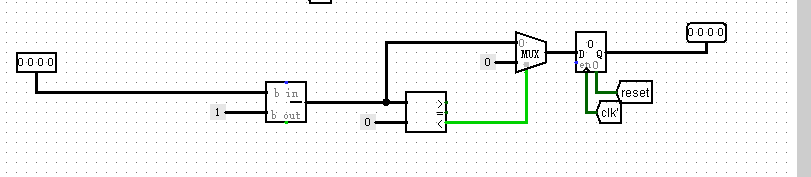
底部输入tnew_E,输出tnew_M = tnew_E - 1(AT法待会再讲)
- 坑点: 如果采用分布式译码,请务必采用时许逻辑(输入输出直接有寄存器,tnew_M和tnew_E 不是直接减 )
下面是tnew_M = tnew_E - 1的时序逻辑电路
DM
Ssel决定读入的位数,00:sw ,01:sb,10:sh
Bsel决定输出的位数,00:lw ,01:lb,10:lh
采用的结果是lyyf学长的结构
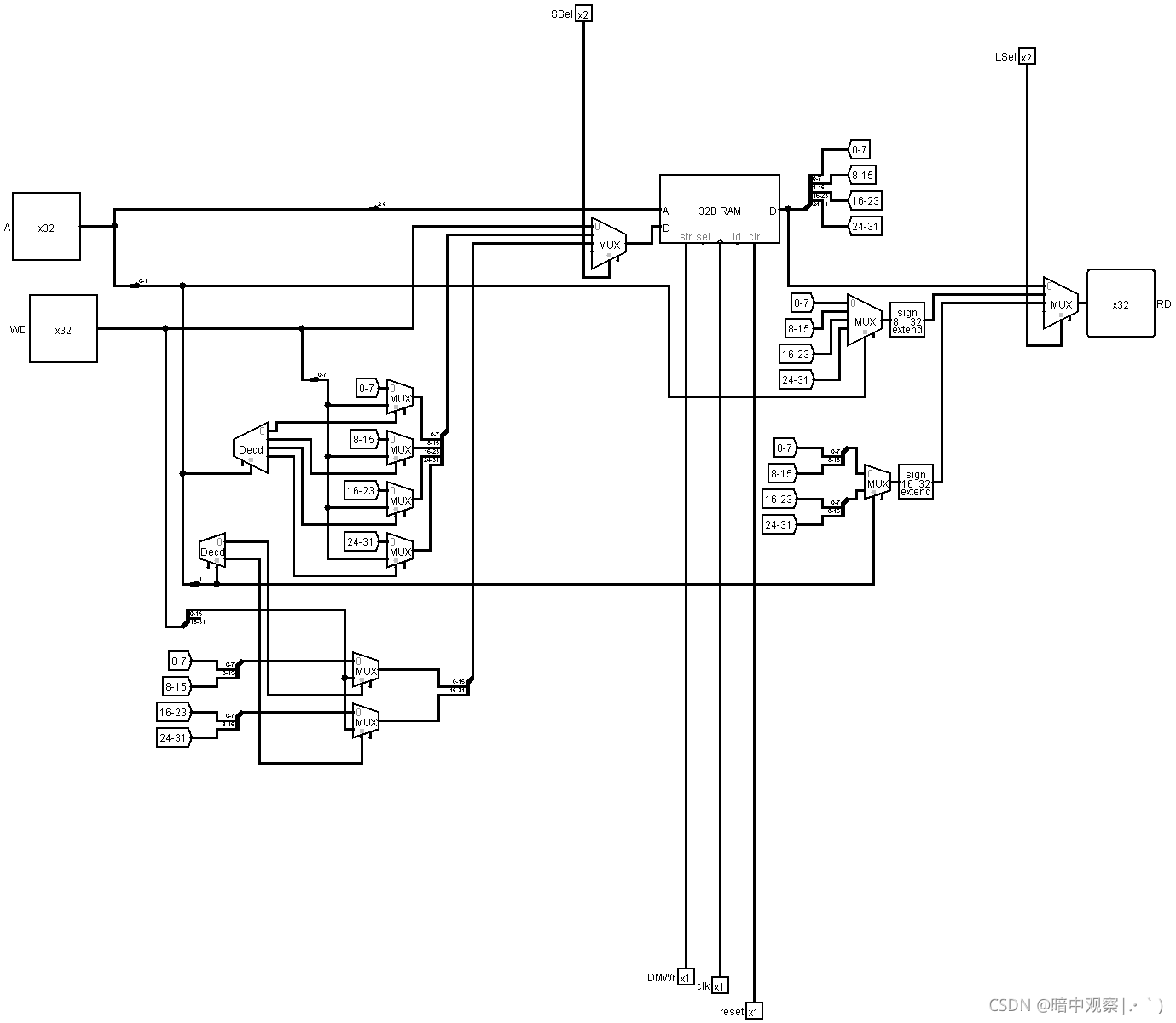
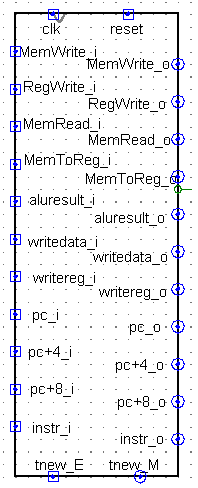
5. WB段
M_W_Reg
tnew_M,输出tnew_W = tnew_M - 1(AT法待会再讲)
- 坑点: 如果采用分布式译码,请务必采用时许逻辑(输入输出直接有寄存器,tnew_W 和tnew_M 不是直接减 )
下面是tnew_W = tnew_M - 1的时序逻辑电路

流水线冒险与AT法介绍
流水线冒险
之前我们已经讨论了不考虑冒险的情况下,数据通路的构造方法。这部分虽然工作量大,但是相对而言并不复杂。接下来,我们将从理论分析和工程实现两方面对冒险进行分析,并对转发和阻塞机制进行介绍。
在流水线 CPU 中,所谓冒险( Hazard ),就是指由于指令间存在相关性或依赖相同的部件,导致两条指令无法在相邻的时钟周期内相继执行的情况。冒险的类型,主要有结构冒险( Structural Hazard )、控制冒险( Control Hazard )和数据冒险( Data Hazard )三种。
在本节接下来的内容中,将对结构冒险和控制冒险以及它们的应对方法作一简要介绍。数据冒险则留待下一节介绍。
结构冒险
结构冒险是指不同指令同时需要使用同一资源的情况。例如在普林斯顿结构中,指令存储器和数据存储器是同一存储器,在取指阶段和存储阶段都需要使用这个存储器,这时便产生了结构冒险。我们的实验采用哈佛体系结构,将指令存储器和数据存储器分开(这种做法类似于现代 CPU 中指令和数据分离的 L1 Cache),因此不存在这种结构冒险。
另一种结构冒险主要在于寄存器文件需要在 D 级和 W 级同时被使用(读写)。由于我们使用分离的端口实现寄存器读写,并规定了读写同一寄存器时的行为(见后面的教程),这种冒险也得以解决。
综上所述,根据我们之前的设计,结构冒险无需进行特殊处理。
控制冒险
控制冒险,是指分支指令(如 beq )的判断结果会影响接下来指令的执行流的情况。在判断结果产生之前,我们无法预测分支是否会发生。然而,此时流水线还会继续取指,让后续指令进入流水线。对于这种情况,我们有什么办法解决呢?
一个简单粗暴的解决办法是:当分支指令进入流水线后,直接暂停取指操作,等待判断结果产生后再进行取指。这个做法的坏处也是显而易见的:如果判断结果在 E 级进行计算,我们需要等待分支指令进入 E/M 级寄存器中才可继续取指,这大大降低了流水线的执行效率。
一个改进思路是:将比较过程提前,在 D 级读取寄存器后立即进行比较。尽早产生结果可以缩短因不确定而带来的开销。这也正是前一小节中,我们构造数据通路时所采用的思路( CMP 模块)。
此外,我们还可以将暂停取指的时间利用起来:不论判断结果如何,我们都将执行分支或跳转指令的下一条指令。这也就是所谓的“延迟槽”。通过这种做法,我们可以利用编译调度,将适当的指令移入延迟槽中,充分利用流水线的性能。(注:延迟槽中的指令不能为分支或跳转指令,否则为未定义行为;对于jal指令,应当向 31 号寄存器写入当前指令的 PC+8。)
在我们的实验中,要求大家实现比较过程前移至 D 级,并采用延迟槽。
数据冒险
几乎每一条指令,都需要获取一定的数据输入,然后某些指令还会产生数据输出。流水线之所以会产生数据冒险,就是因为后面指令需求的数据,正好就是前面指令供给的数据,而后面指令在需要使用数据时,前面供给的数据还没有存入寄存器堆,从而导致后面的指令不能正常地读取到正确的数据。因此我们从需求数据和供给数据的行为来入手分析暂停、转发情况。
需求者:对于某条指令,实际上需求寄存器数据的是某些硬件部件。如,对于 addu 指令,需要数据的是位于流水线 E 级的 ALU,对于 BEQ 指令,需要数据的是位于流水线 D 级的比较器 CMP。而对于 SW 指令,需要数据的有 EX 级的 ALU(这个数据用来计算存储地址),还有 MEM 级的 DM(这里需要存入的具体的值)。
供给者:所有的供给者,都是存储了上一级传来的各种数据的流水级寄存器,而不是由 ALU 或者 DM 来提供数据。
分析清楚了数据的需求者和供给者,我们就可以理清处理数据冒险的策略了。假设当前我需要的数据,其实已经计算出来,只是还没有进入寄存器堆,那么我们可以用转发( Forwarding )来解决,即不引用寄存器堆的值,而是直接从后面的流水级的供给者把计算结果发送到前面流水级的需求者来引用。如果我们需要的数据还没有算出来。则我们就只能暂停( Stall ),让流水线停止工作,等到我们需要的数据计算完毕,再开始下面的工作。
那么,如何判断我们所需的数据是否已经计算出来了呢?我们为此提出一个简单高效的判定模型:需求时间——供给时间模型。
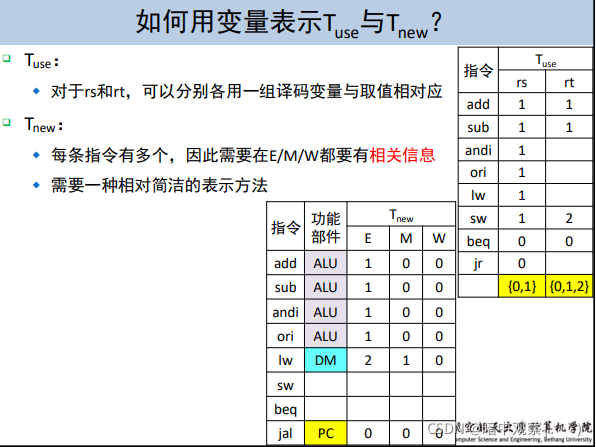
对于某一个指令的某一个数据需求,我们定义需求时间 Tuse 为:这条指令位于 D 级的时候,再经过多少个时钟周期就必须要使用相应的数据。
例如,对于 BEQ 指令,立刻就要使用数据,所以 Tuse=0。
对于 addu 指令,等待下一个时钟周期它进入 EX 级才要使用数据,所以 Tuse=1。
而对于 sw 指令,在 EX 级它需要 GPR[rs] 的数据来计算地址,在 MEM 级需要 GPR[rt] 来存入值,所以对于 rs 数据,它的 Tuse_rs=1,对于 rt 数据,它的 Tuse_rt=2。
在 P4 课下要求的指令集的条件下,Tuse 值有两个特点:
特点 1:是一个定值,每个指令的 Tuse 是一定的
特点 2:一个指令可以有两个 Tuse 值
对于某个指令的数据产出,我们定义供给时间 Tnew 为:位于某个流水级的某个指令,它经过多少个时钟周期可以算出结果并且存储到流水级寄存器里。
例如,对于 addu 指令,当它处于 EX 级,此时结果还没有存储到流水级寄存器里,所以此时它的 Tnew=1,而当它处于 MEM 或者 WB 级,此时结果已经写入了流水级寄存器,所以此时 Tnew=0。
在 P4 课下要求的指令集的条件下,Tnew 值有两个特点:
特点 1:是一个动态值,每个指令处于流水线不同阶段有不同的 Tnew 值
特点 2:一个指令在一个时刻只会有一个 Tnew 值(一个指令只有一个结果)
当两条指令发生数据冲突(前面指令的写入寄存器,等于后面指令的读取寄存器),我们就可以根据 Tnew 和 Tuse 值来判断策略。
Tnew=0,说明结果已经算出,如果指令处于 WB 级,则可以通过寄存器的内部转发设计解决,不需要任何操作。如果指令不处于 WB 级,则可以通过转发结果来解决。
Tnew<=Tuse,说明需要的数据可以及时算出,可以通过转发结果来解决。
Tnew>Tuse,说明需要的数据不能及时算出,必须暂停流水线解决。
在不考虑暂停的条件下(认为不会有 Tnew>Tuse 的情况)下,我们可以利用转发机制处理所有冒险。在考虑暂停之后,将会对某些情况进行暂停,这些情况下将会停止取指,同时插入 nop 指令,此时无论是原始读出的数据还是转发过来的数据,都不会被使用。因此,在下一节介绍实现转发与阻塞机制的时候,将首先无视阻塞实现转发机制,随后额外增加阻塞机制,即可正确地处理冒险。
AT法
AT法是什么
A 指 Address,也就是寄存器的地址(编号);T 指 Time,也就是前面所提到的 Tuse 和 Tnew。所谓 AT 法,就是指通过在 D 级对指令的 AT 信息进行译码并流水,就可以方便地构造出数据冒险的处理机制。
转发(旁路)机制的构造
首先,我们假设所有的数据冒险均可通过转发解决。也就是说,当某一指令前进到必须使用某一寄存器的值的流水阶段时,这个寄存器的值一定已经产生,并存储于后续某个流水线寄存器中。
我们接下来分析需要转发的位点。当某一部件需要使用 GPR( General Purpose Register )中的值时,如果此时这个值存在于后续某个流水线寄存器中,而还没来得及写入 GPR,我们就需要通过转发(旁路)机制将这个值从流水线寄存器中送到该部件的输入处。
根据我们对数据通路的分析,这样的位点有:
D 级比较器的两个输入(含 NPC 逻辑中寄存器值的输入);
E 级 ALU 的两个输入;
M 级 DM 的输入。
为了实现转发机制,我们对这些输入前加上一个 MUX。这些 MUX 的默认输入来源是上一级中已经转发过的数据。下面,我们继续分析这些 MUX 的其他输入来源和选择信号的生成。
GPR 是一个特殊的部件,它既可以视为 D 级的一个部件,也可以视为 W 级之后的流水线寄存器。基于这一特性,我们将对 GPR采用内部转发机制。也就是说,当前 GPR 被写入的值会即时反馈到读取端上。
在对 GPR 采取内部转发机制后,这些 MUX 的其他输入来源就是这些 MUX 之后所有流水线寄存器中对 GPR 写入的、且对当前 MUX 的默认输入不可见的数据。具体来说,D 级 MUX 的其他输入来源是 D/E 和 E/M 级流水线寄存器中对 GPR 写入的数据。由于 M/W 级流水线寄存器中对 GPR 写入的数据可以通过 GPR 的内部转发机制而对 D 级 MUX 的默认输入可见,因此无需进行转发。对于其他流水级的转发 MUX,输入来源可以类比得出。
选择信号的生成规则是:只要当前位点的读取寄存器地址和某转发输入来源的写入寄存器地址相等且不为 0,就选择该转发输入来源;在有多个转发输入来源都满足条件时,最新产生的数据优先级最高。为了获取生成选择信号所需的信息,我们需要对指令的读取寄存器和写入寄存器在 D 级进行译码并流水(指令的“ A 信息”)。
暂停(阻塞)机制的构造
接下来,我们来处理通过转发不能处理的数据冒险。在这种情况下,新的数据还未来得及产生。我们只能暂停流水线,等待新的数据产生。为了方便处理,本教程中所述暂停是指将指令暂停在 D 级。
首先,我们来回顾一下 Tuse 和 Tnew 的定义:
Tuse:指令进入 D 级后,其后的某个功能部件再经过多少时钟周期就必须要使用寄存器值。对于有两个操作数的指令,其每个操作数的 Tuse 值可能不等(如 store 型指令 rs、rt 的 Tuse 分别为 1 和 2 )。
Tnew:位于 E 级及其后各级的指令,再经过多少周期就能够产生要写入寄存器的结果。在我们目前的 CPU 中,W 级的指令Tnew 恒为 0;对于同一条指令,Tnew_M = max(Tnew_E - 1, 0)。
那么,我们什么时候需要在 D 级暂停呢?根据 Tuse 和 Tnew 所提供的信息,我们容易得出:当 D 级指令读取寄存器的地址与 E 级或 M 级的指令写入寄存器的地址相等且不为 0,且 D 级指令的 Tuse 小于对应 E 级或 M 级指令的 Tnew 时,我们就需要在 D 级暂停指令。在其他情况下,数据冒险均可通过转发机制解决。
为了获取暂停机制所需的信息,我们还需要对指令的 Tuse 和 Tnew 信息在 D 级进行译码,并将 Tnew 信息流水(指令的“ T 信息”)。
将指令暂停在 D 级时,我们需要进行如下操作:
冻结 PC 的值
冻结 F/D 级流水线寄存器的值
将 D/E 级流水线寄存器清零(这等价于插入了一个 nop 指令)
如此,我们就完成了暂停机制的构建。
Tuse 和Tnew的表格
流水线搭建(转发和暂停)(来自于软院gjz大哥的分析和操作,小弟现场打call!!该部分和gjz大哥的相近,增加的内容用黄色标注了)
流水线的分布式译码展示
分布式译码根据具体指令和寄存器给出转发模块和阻塞模块需要的数据。
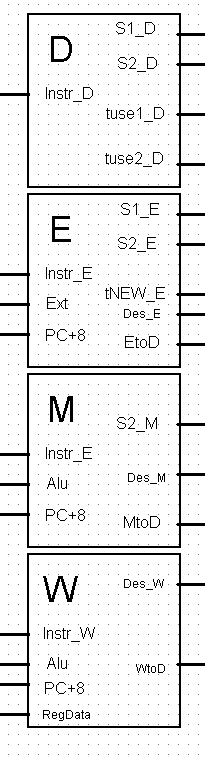
流水线转发模块展示
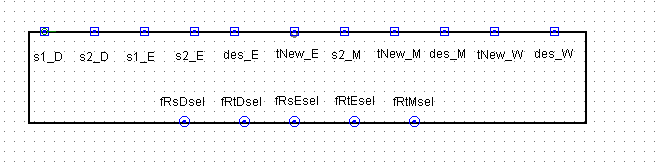
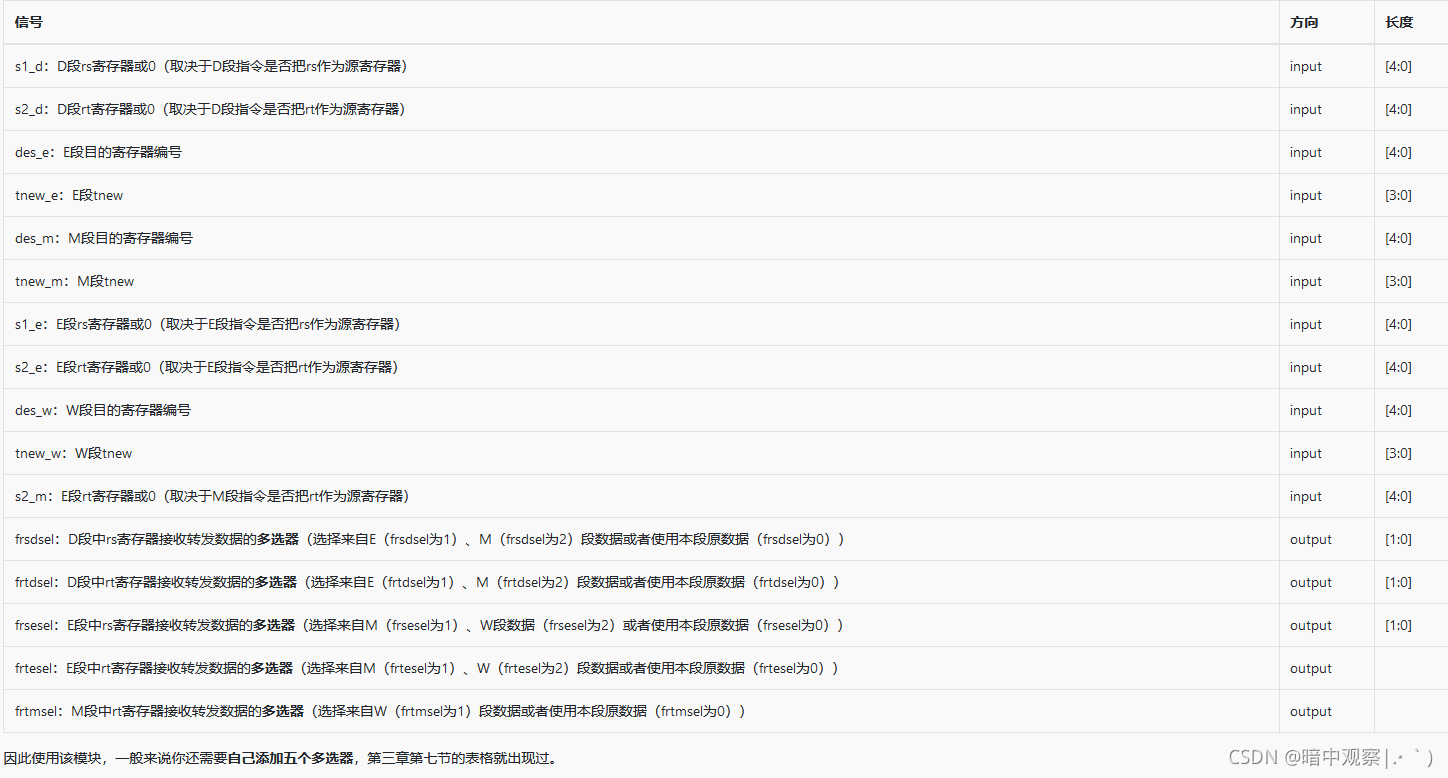
流水线暂停模块展示
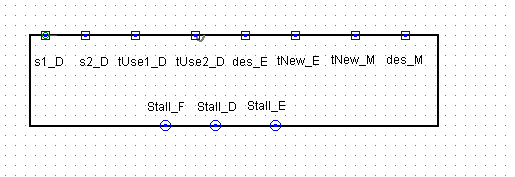
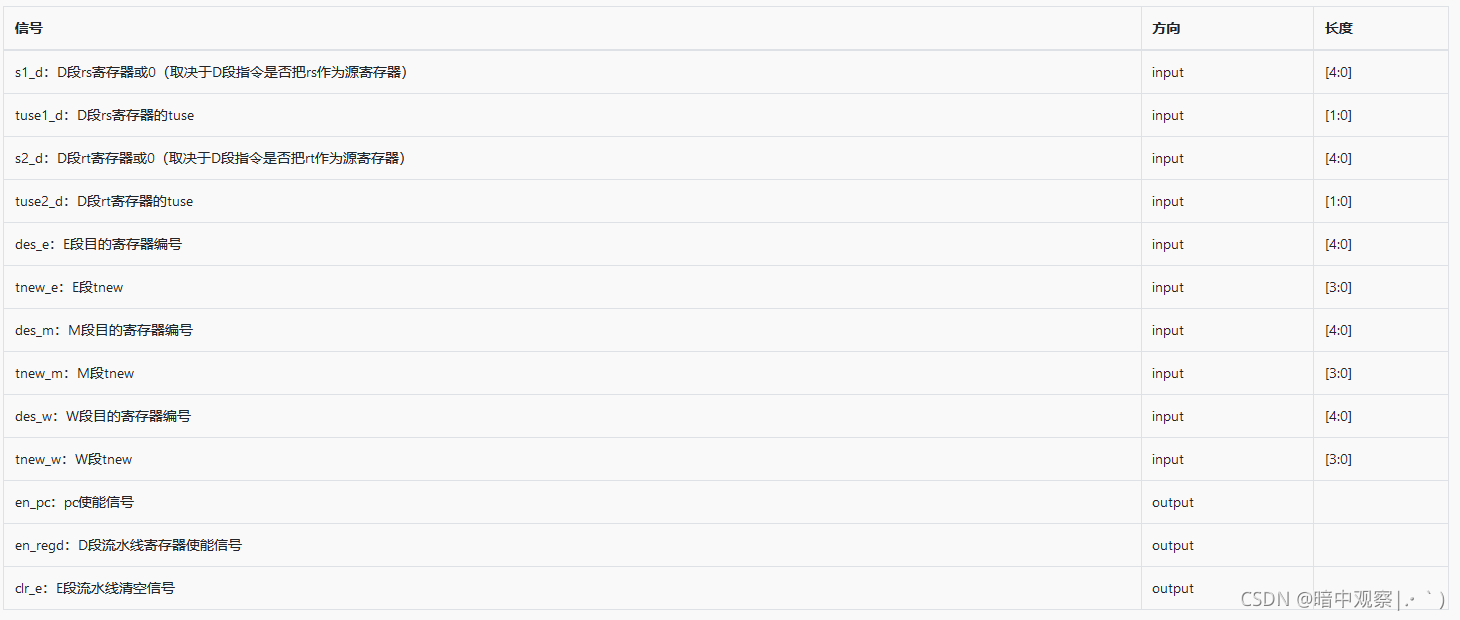
流水线CPU的冲突控制
首先解释一下指导书中的tuse和tnew的作用,指导书中给出了两个变量的定义:
对于指令的源寄存器s有时间tuse_D(/E/M),意思是在从D(/E/M)段开始,过几个时钟周期需要使用s里的数据。对于指令的目的寄存器des有数据tnew_D(/E/M),意思是从D(/E/M)段开始,过几个时钟周期将要写入des的数据产生
**阻塞的根本原因在于后面阶段的数据还未准备好,前面阶段就必须要用后面阶段的数据。**那我们就需要使用阻塞模块产生阻塞信号等待后面数据计算完转发给前面的阶段使用。
对于一条指令的两个源寄存器,它们都有可能用到其他指令的目标寄存器中的"不干净的"值,但是好消息是用时的位置是确定的。比如SW指令中RegData[rs]在EX阶段作为ALUSrc的A来使用,距离ID阶段为1;而RegData[rt]则一直会拖到MEM阶段作为DM访存地址使用,那么距离ID阶段而言就是2。这两个数字意味着“死线”,只有这个距离以内的阶段的目标寄存器的值是“干净的”。
对于一条指令的目标寄存器,最终产生即将存入目标寄存器中的值得位置也是确定的。比如LW指令中访存取值的结果必须在MEM阶段结束后在WB阶段才能得到,距离ID阶段为3。这也是一个“死线”,只有这个距离以后目标寄存器才被写入“干净的”值。
那我们就得到一个简单的表格表示死线位置距离ID阶段的距离:
(其实和高老板的图片是一样的)
一个合理的猜想就是流水线的行进条件必须是tuse>=tnew,两个死线中间的区域才是可以使用的值,否则流水线阻塞,以等待tnew递减至满足条件。
那么拿一段简单的程序试一试吧。假设有这样的指令序列:
lw $t1,0($0)
sw $t2,4($t1)
当LW在EX段,SW在ID段时查表得到:
s1_D = $t1(sw的rs源寄存器)
des_E = $t1(lw的rt目标寄存器)
tUse1_D = 1
tNew_E = 2
下面截图是流水线CPU中实验的结果,完全一致!且成功产生了Stall信号。
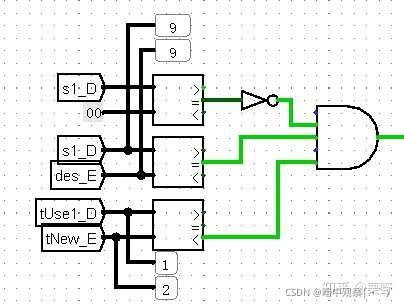
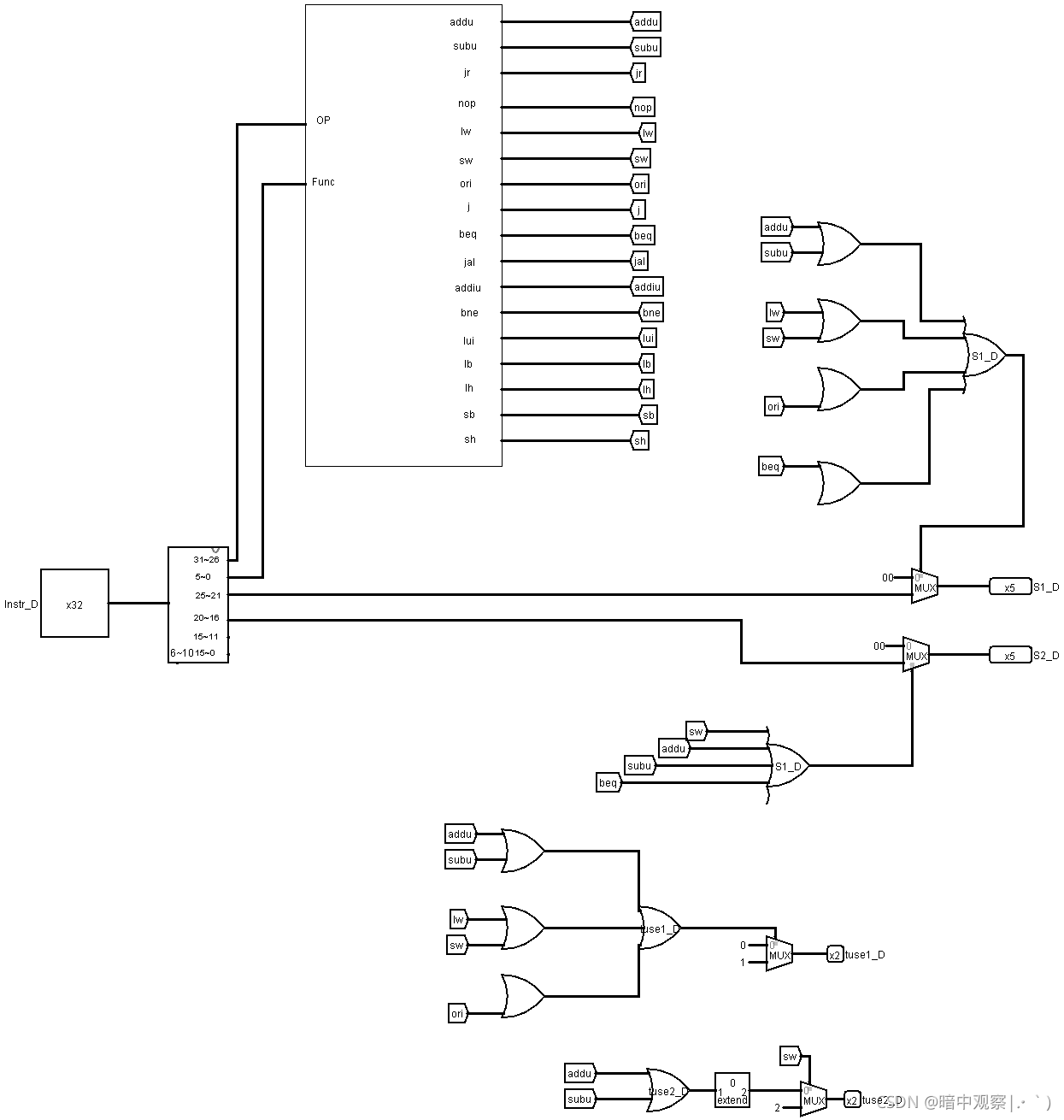
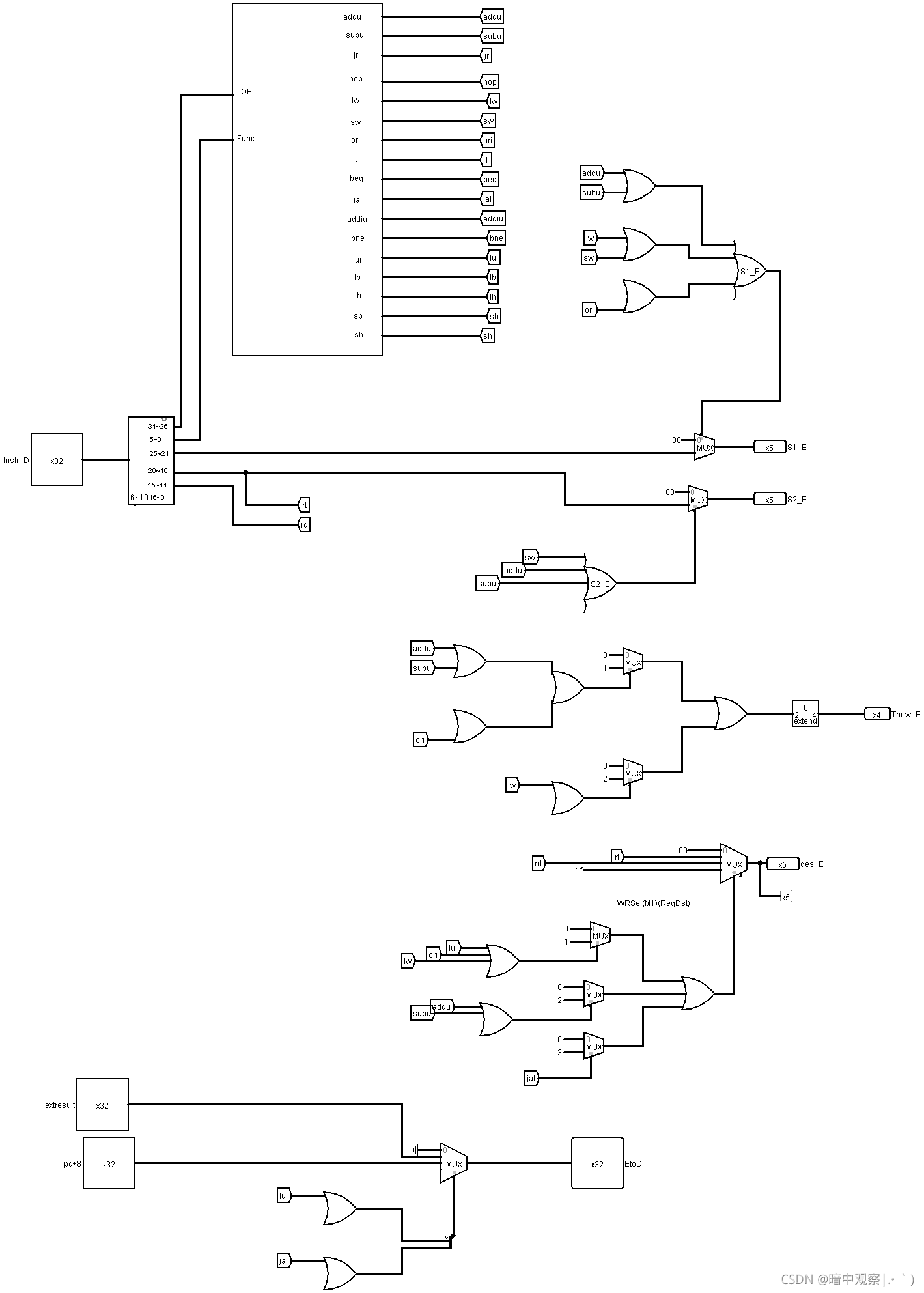
既然验证了我们想法的正确性,那么剩下的事情就很简单了,只需要在ID阶段的分布式译码模块中将所有的指令对应的tuse_1,tuse_2,源寄存器序号,目标寄存器序号译码得出传入阻塞模块即可。对于tnew,我选择的是放在EX阶段译码(因为放在ID段没有意义,不会有tuse与ID段的tnew比较)。下图是ID段分布式译码和EX段的分布译码
- ID段:
- EX段:
重要提醒:我对于目的寄存器一开始总有疑惑,不管是黑书(《数字设计和计算机体系结构》)还是狼书(《计算机组成与实现》)这两本书,里面对于目的寄存器(Des)的选择和该AT法的目的寄存器的选择是不一样的。我们先看看那两本书的图对于目的寄存器的选择
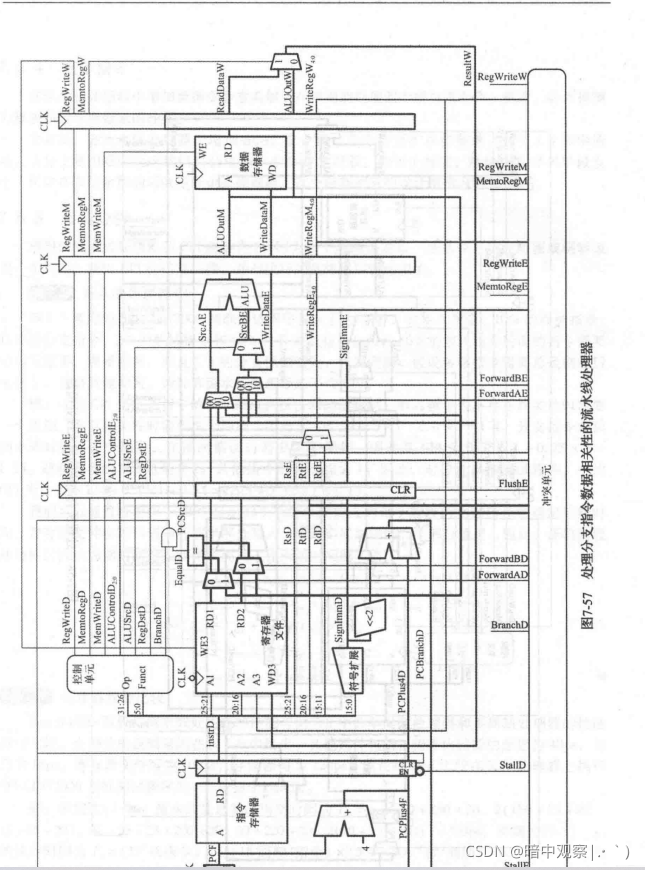
其中对于目的寄存器(WriteRegE/M/W)都是直接用一根线拉到冲突转发模块,但是在AT法中是不行的!!!!!,每一个阶段的目的寄存器(Des)都需要单独译码,不可以直接引入
流水线CPU的转发模块
转发模块虽然内容很多,但是其实逻辑相对还是简单一些。核心的思想就是数据一旦准备妥当,马上转发回前面所有需要的阶段。这里无论转发到什么阶段都当做转发到ID阶段,假装从ID阶段开始这些数据就是干净的数据。
这里以其中一个分支为例:
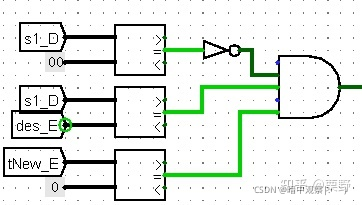
翻译翻译:if(s1_D!=0 && s1_D == des_E && tNew_E == 0) {转发E->D的数据},其他的分支也是同理。只要根据模块里输出的Select信号的顺序安排转发数据的5个MUX就大功告成了!
五个MUX前两个转发到ID段,作为Comparator的输入;中间两个转发到EX段,作为ALU的输入;最后一个转发到MEM段,作为DM的写入数据:

以下表格给出了需要转发数据的内容,在分布式译码中根据指令输出。(很重要很重要!!!!!!,这个是我搞清楚为什么那么多输入的原因)
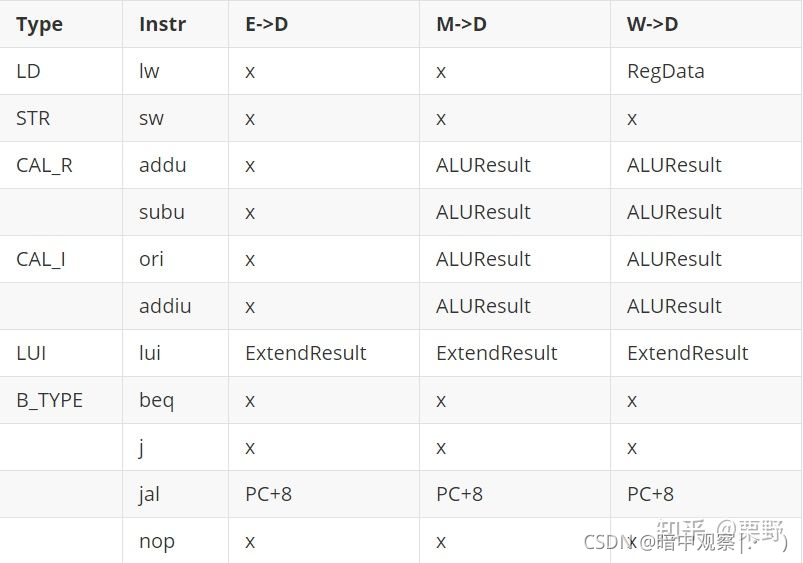
具体分布式译码
知道了阻塞模块和转发模块的工作原理之后,很容易就知道分布式译码的每一个阶段需要什么样的数据。这时候就可以参照参考书中的表搭建自己的分布式译码器。
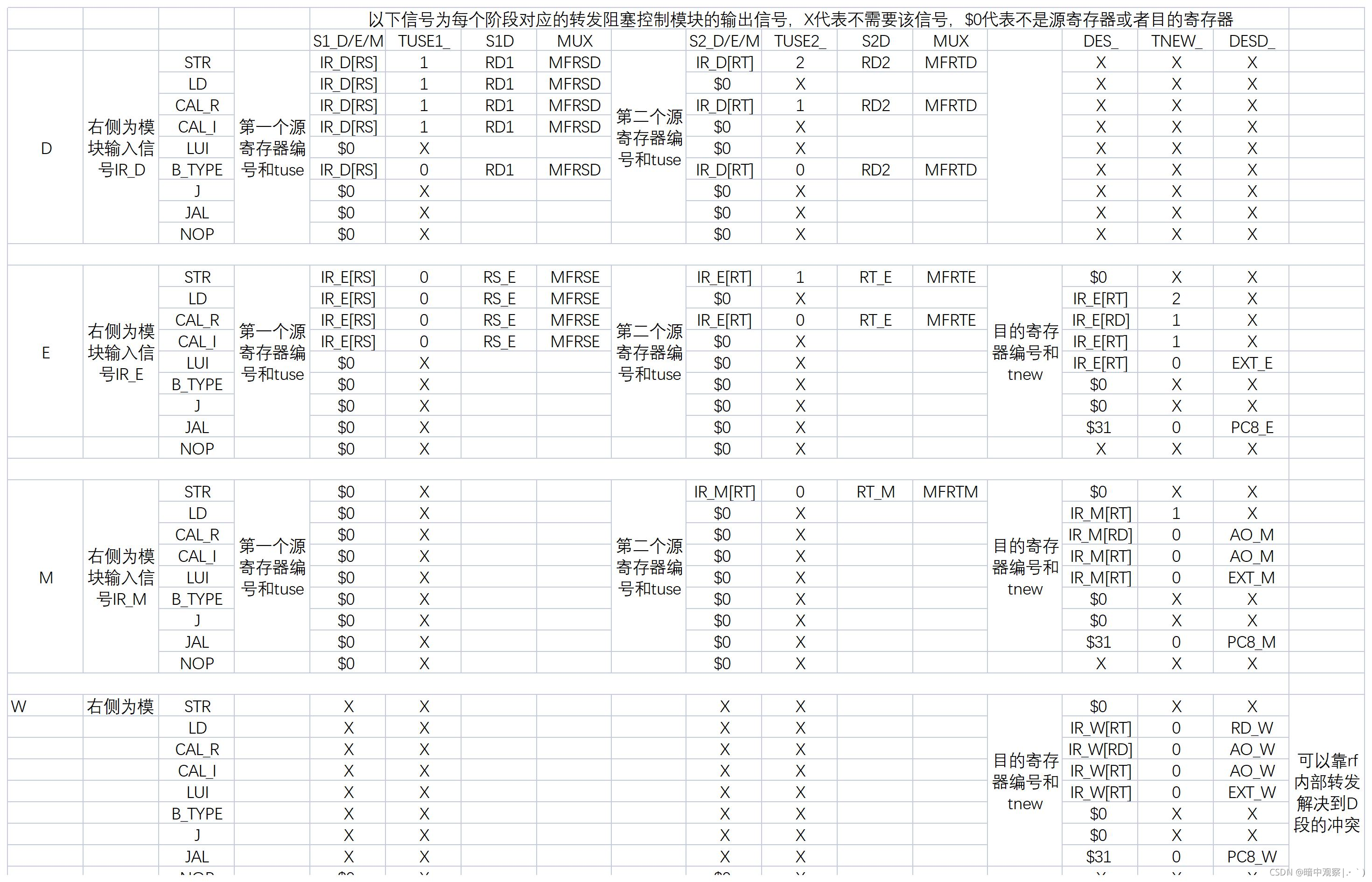
这里的x就是用不到的意思,默认为0就可以了。
注意EX段译码得到的tnew需要进入流水线,每次进入寄存器要-1。
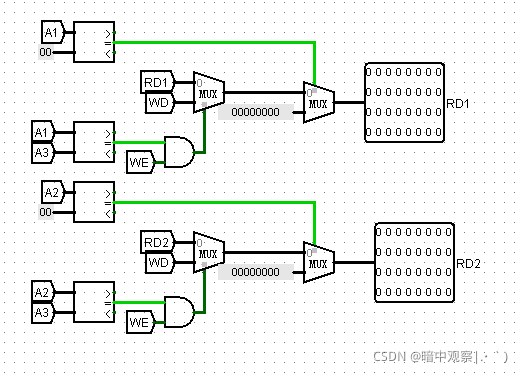
内部转发
转发模块的逻辑中既没有实现外部转发也没有实现内部转发。因此转发到ID段的两个MUX是没有W->D的选项的。外部转发因为需要修改转发模块的逻辑有点麻烦,所以我采用的是内部转发的方案。
内部转发逻辑:寄存器堆的RD1输出:是0当且仅当A1输入为0; 是将要写入寄存器A3的数据当且仅当将要写入的寄存器编号A3和读取寄存器编号A1相等; 是寄存器A1的数据当且仅当将要写入的寄存器编号A3和读取寄存器编号A1不相等。 寄存器堆的RD2输出:是0当且仅当A2输入为0; 是将要写入寄存器A3的数据当且仅当将要写入的寄存器编号A3和读取寄存器编号A2相等; 是寄存器A2的数据当且仅当将要写入的寄存器编号A3和读取寄存器编号A2不相等。
这段话用代码表示就是指:
// RF的内部转发逻辑
// RD1的数据
if(A1 == 0) RD1 = 0
if(A1 == A3) RD1 = A3.ToBeWrite
if(A1 != A3) RD1 = A1.RegData
// RD2的数据
if(A2.RegData == 0) RD2 = 0
if(A2 == A3) RD2 = A3.ToBeWrite
if(A2 != A3) RD2 = A2.RegData
内部转发避免了WB阶段转发回ID阶段的额外数据旁路,对于同一个寄存器下一个时钟上沿才能写入的数据将可以直接读出。我们只需要在RF内部输出的部分做一些判断的电路就可以了。
除了助教提供的这种思路,还有一种方法可以很简单的实现内部转发:**将寄存器写入信号改为沿时钟下沿。经测试可以通过AC。**原理很简单,时钟下沿写入相当于先写后读,将写入提前了半个周期,这样读到的就是干净的数据了。需要明确,内部转发的只有WB到ID的数据,WB到EX、MEM的数据仍然需要外部旁路。
在GRF中的实现:
流水线CPU转发和冲突测试(中等强度数据,和课下数据数据强度一致,如果课下没有通过请务必测试该数据,亲测有效)
这个数据我设置的很巧妙,采用了lw-beq的形式,使CPU出现连续的两次暂停在迅速接转发,我当时就是对着这个数据debug,这个数据过了,课下就AC了。
测试注意
- 我们采用DM匹配MARS和Logging双测试,保证数据充分使用到。
- 希望测试的时候,用鼠标点击时钟进行仿真,这样可以和之后提到的细节相匹配
- 对于Logging的匹配问题,请采用对比网址——>点击这里 。如果用肉眼看会出问题,因为时间周期有误差。请复制粘贴之后要点击AB两块之间的蓝色的匹配箭头,直到不可以点击为止,如果还有问题,那就是真有问题。



测试细节
- 在鼠标点击的第11次,会出现暂停信号
- 在11次-15次(11,12,13,14),暂停信号都是亮的
- 之后不会再出现暂停信号
- 该测试数据会插入两个气泡
- 该测试数据的beq要正常执行
- 该测试数据的sw语句要实现转发
测试数据
#MARS
ori $s0, $s0, 0
ori $s1, $s1, 3
ori $s7, $s7, 3
sw $s1, 0($s0)
lw $s2, 0($s0)
beq $s7, $s2, End
ori $s3, $s2, 4
End:
sw $s3, 4($s0)
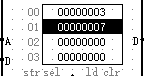
正确结果
- DM内部
- Logging结果
Instr regWrite RegAddr Regdata memWrite MemAddr MemData
0011 0110 0001 0000 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000
0011 0110 0011 0001 0000 0000 0000 0011 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000
0011 0110 1111 0111 0000 0000 0000 0011 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000
1010 1110 0001 0001 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000
1000 1110 0001 0010 0000 0000 0000 0000 1 1 0000 0000 0000 0000 0000 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000
0001 0010 1111 0010 0000 0000 0000 0001 1 1 0001 0000 0000 0000 0000 0000 0000 0000 0011 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000
0011 0110 0101 0011 0000 0000 0000 0100 1 1 0111 0000 0000 0000 0000 0000 0000 0000 0011 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000
0011 0110 0101 0011 0000 0000 0000 0100 0 1 0001 0000 0000 0000 0000 0000 0000 0000 0000 1 0 0000 0000 0000 0000 0000 0000 0000 0000 0011
0011 0110 0101 0011 0000 0000 0000 0100 1 1 0010 0000 0000 0000 0000 0000 0000 0000 0011 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000
1010 1110 0001 0011 0000 0000 0000 0100 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000 0 1 0010 0000 0000 0000 0000 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0011
0000 0000 0000 0000 0000 0000 0000 0000 1 1 0011 0000 0000 0000 0000 0000 0000 0000 0111 0 0 0001 0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000 0 1 0011 0000 0000 0000 0000 0000 0000 0000 0100 1 0 0001 0000 0000 0000 0000 0000 0000 0000 0111
0000 0000 0000 0000 0000 0000 0000 0000 0 0 0000 0000 0000 0000 0000 0000 0000 0000 0100 0 0 0001 0000 0000 0000 0000 0000 0000 0000 0000
流水线CPU总体测试(强测试)
暂未开放
结语
非常感谢软院大哥gjz大哥的帮助和软院大哥hb大哥的帮助,以及给个指点我的小伙伴的帮助,流水线CPU自己从头到尾搭下来真的很辛苦,谢谢大家