HBase的Java代码开发(从Linux集群环境搭建开始)_她现在只能听说的博客
请您仔细阅读以下条款,如果您对本声明的任何条款表示异议,可以选择不阅读本文章。用户阅读本文章的行为将被视为对本声明全部内容的认可。
(1)本文章只供学习交流使用,严禁用作商业用途。
(2)本文章不对内容的真实、完整、准确及合法性进行任何保证。
(3)文章仅表明其个人的立场和观点,并不代表任何组织或机构的立场或观点。
(4)任何组织或个人认为本文章的内容可能涉嫌侵犯其合法权益,应该及时向作者反馈,并提供身份证明、权属证明及详细侵权情况证明,在收到上述法律文件后,作者将会尽快移除被控侵权内容。
本文使用Hadoop2.7.5 zookeeper3.4.9 HBase2.0.0 jdk1.8 Centos7
相关软件:VMware,SecureCRT,Intellij IDEA
集群环境搭建
1:注意事项
1.1 windows系统确认所有的关于VmWare的服务都已经启动

1.2 确认好VmWare生成的网关地址

1.3 确认VmNet8网卡已经配置好了IP地址和DNS

2:复制虚拟机
2.1 将创建好的虚拟机文件夹复制三份,并分别重命名, 并双击vmx文件使用VM打开重命名为node01,node02,node03


2.2分别设置三台虚拟机的内存
-
需要三台虚拟机, 并且需要同时运行, 所以总体上的占用为: 每台虚拟机内存 *3
-
在分配的时候, 需要在总内存大小的基础上, 减去2G-4G作为系统内存, 剩余的除以3, 作为每台虚拟机的内存
3:启动虚拟机并修改Mac和IP
3.1 集群规划
| IP | 主机名 | 环境配置 | 安装 |
|---|---|---|---|
| 192.168.xxx.100 | node01 | 关防火墙和selinux, host映射, 时钟同步 | JDK, NameNode, ResourceManager, Zookeeper |
| 192.168.xxx.120 | node02 | 关防火墙和selinux, host映射, 时钟同步 | JDK, DataNode, NodeManager, Zeekeeper |
| 192.168.xxx.130 | node03 | 关防火墙和selinux, host映射, 时钟同步 | JDK, DataNode, NodeManager, Zeekeeper |
3.2 :设置ip和Mac地址
每台虚拟机更改mac地址:
vim /etc/udev/rules.d/70-persistent-net.rules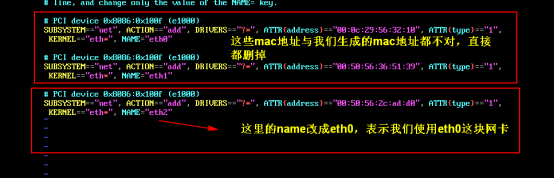
每台虚拟机更改IP地址:
vim /etc/sysconfig/network-scripts/ifcfg-eth0
每台虚拟机修改对应主机名(重启后永久生效)
vi /etc/sysconfig/networkHOSTNAME=node01
每台虚拟机设置ip和域名映射
vim /etc/hosts 
3.3 inux系统重启
关机重启linux系统即可进行联网了
第二台第三台机器重复上述步骤,并设置IP网址为192.168.174.110,192.168.174.120
4:三台虚拟机关闭防火墙和SELinux
4.1 关闭防火墙
现在开始我们Secure CRT通过IP地址来连接虚拟机进行下面操作
三台机器执行以下命令(root用户来执行)
service iptables stop #关闭防火墙
chkconfig iptables off #禁止开机启动 
4.2三台机器关闭selinux
# 修改selinux的配置文件
vi /etc/selinux/config
5: 虚拟机免密码登录
免密SSH 登录的原理

ssh-keygen -t rsa
ssh-copy-id node01scp /root/.ssh/authorized_keys node02:/root/.ssh
scp /root/.ssh/authorized_keys node03:/root/.ssh
## 安装
yum install -y ntp
## 启动定时任务
crontab -e*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
与阿里云服务器保持同步
随后重启,Linux环境搭建完成。
进行JDK安装

rpm -qa | grep java
rpm -e java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el6_8.x86_64 tzdata-java-2016j-1.el6.noarch java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el6_8.x86_64 --nodepsmkdir -p /export/softwares #软件包存放目录
mkdir -p /export/servers #安装目录#上传jdk到/export/softwares路径下去,并解压
rz -E
tar -zxvf jdk-8u141-linux-x64.tar.gz -C ../servers/vim /etc/profileexport JAVA_HOME = /export/servers/jdk1.8.0_141export PATH = : $JAVA_HOME /bin: $PATH
修改完成之后记得 source /etc/profile生效
source /etc/profile8: Zookeeper安装
集群规划
| 服务器IP | 主机名 | myid的值 |
|---|---|---|
| 192.168.174.100 | node01 | 1 |
| 192.168.174.110 | node02 | 2 |
| 192.168.174.120 | node03 | 3 |
第一步:下载zookeeeper的压缩包,下载网址如下
http://archive.apache.org/dist/zookeeper/
rz -Ecd /export/software
tar -zxvf zookeeper-3.4.9.tar.gz -C ../servers/cd /export/servers/zookeeper-3.4.9/conf/
cp zoo_sample.cfg zoo.cfg
mkdir -p /export/servers/zookeeper-3.4.9/zkdatas/dataDir=/export/servers/zookeeper-3.4.9/zkdatas
# 保留多少个快照
autopurge.snapRetainCount=3
# 日志多少小时清理一次
autopurge.purgeInterval=1
# 集群中服务器地址
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888echo 1 > /export/servers/zookeeper-3.4.9/zkdatas/myidscp -r /export/servers/zookeeper-3.4.9/ node02:/export/servers/
scp -r /export/servers/zookeeper-3.4.9/ node03:/export/servers/echo 2 > /export/servers/zookeeper-3.4.9/zkdatas/myid
echo 3 > /export/servers/zookeeper-3.4.9/zkdatas/myid
第六步:三台机器启动zookeeper服务
/export/servers/zookeeper-3.4.9/bin/zkServer.sh start查看启动状态
/export/servers/zookeeper-3.4.9/bin/zkServer.sh status| 服务器IP | 192.168.174.100 | 192.168.174.110 | 192.168.174.120 |
|---|---|---|---|
| 主机名 | node01 | node02 | node03 |
| NameNode | 是 | 否 | 否 |
| SecondaryNameNode | 是 | 否 | 否 |
| dataNode | 是 | 是 | 是 |
| ResourceManager | 是 | 否 | 否 |
| NodeManager | 是 | 是 | 是 |
cd /export/softwares
tar -zxvf hadoop-2.7.5.tar.gz -C ../servers/
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim core-site.xml<configuration><property><name> fs.default.name </name><value> hdfs://node01:8020 </value></property><property><name> hadoop.tmp.dir </name><value> /export/servers/hadoop-2.7.5/hadoopDatas/tempDatas </value></property><!-- 缓冲区大小,实际工作中根据服务器性能动态调整 --><property><name> io.file.buffer.size </name><value> 4096 </value></property><!-- 开启 hdfs 的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 --><property><name> fs.trash.interval </name><value> 10080 </value></property></configuration>
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim hdfs-site.xml<configuration><property><name> dfs.namenode.secondary.http-address </name><value> node01:50090 </value></property><property><name> dfs.namenode.http-address </name><value> node01:50070 </value></property><property><name> dfs.namenode.name.dir </name><value> file:///export/servers/hadoop 2.7.5/hadoopDatas/namenodeDatas,file:///export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2 </value></property><!-- 定义 dataNode 数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 --><property><name> dfs.datanode.data.dir </name><value> file:///export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas,file:///export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2 </value></property><property><name> dfs.namenode.edits.dir </name><value> file:///export/servers/hadoop-2.7.5/hadoopDatas/nn/edits </value></property><property><name> dfs.namenode.checkpoint.dir </name><value> file:///export/servers/hadoop-2.7.5/hadoopDatas/snn/name </value></property><property><name> dfs.namenode.checkpoint.edits.dir </name><value> file:///export/servers/hadoop- 2.7.5/hadoopDatas/dfs/snn/edits </value></property><property><name> dfs.replication </name><value> 3 </value></property><property><name> dfs.permissions </name><value> false </value></property><property><name> dfs.blocksize </name><value> 134217728 </value></property></configuration>
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim hadoop-env.shexport JAVA_HOME=/export/servers/jdk1.8.0_141
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim mapred-site.xml<configuration><property><name> mapreduce.job.ubertask.enable </name><value> true </value></property><property><name> mapreduce.jobhistory.address </name><value> node01:10020 </value></property><property><name> mapreduce.jobhistory.webapp.address </name><value> node01:19888 </value></property></configuration>
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim yarn-site.xml<configuration><property><name> yarn.resourcemanager.hostname </name><value> node01 </value></property><property><name> yarn.nodemanager.aux-services </name><value> mapreduce_shuffle </value></property><property><name> yarn.log-aggregation-enable </name><value> true </value></property><property><name> yarn.log-aggregation.retain-seconds </name><value> 604800 </value></property><property><name> yarn.nodemanager.resource.memory-mb </name><value> 20480 </value></property><property><name> yarn.scheduler.minimum-allocation-mb </name><value> 2048 </value></property><property><name> yarn.nodemanager.vmem-pmem-ratio </name><value> 2.1 </value></property></configuration>
修改mapred-env.sh
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim mapred-env.shexport JAVA_HOME=/export/servers/jdk1.8.0_141
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim slavesnode01node02node03
第一台机器执行以下命令
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/tempDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/nn/edits
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/snn/name
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/editscd /export/servers/
scp -r hadoop-2.7.5 node02:$PWD
scp -r hadoop-2.7.5 node03:$PWDvim /etc/profileexport HADOOP_HOME = /export/servers/hadoop-2.7.5export PATH = : $HADOOP_HOME /bin: $HADOOP_HOME /sbin: $PATH
配置完成之后生效
source /etc/profile
cd /export/servers/hadoop-2.7.5/
bin/hdfs namenode -format
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver三个端口查看界面
http://node01:50070/explorer.html#/查看hdfs
http://node01:8088/cluster查看yarn集群
10.HBase的集群环境搭建
下载Hbase的安装包,下载地址如下:
http://archive.apache.org/dist/hbase/2.0.0/hbase-2.0.0-bin.tar.gz
第二步:压缩包上传并解压
将我们的压缩包上传到node01服务器的/export/softwares路径下并解压
cd /export/softwares/
tar -zxf hbase-2.0.0-bin.tar.gz -C /export/servers/第三步:修改配置文件
node01机器进行修改配置文件
cd /export/servers/hbase-2.0.0/conf修改第一个配置文件hbase-env.sh
node01机器进行修改配置文件
注释掉HBase使用内部zk
cd /export/servers/hbase-2.0.0/conf
vim hbase-env.shexport JAVA_HOME=/export/servers/jdk1.8.0_141
export HBASE_MANAGES_ZK=false
修改第二个配置文件hbase-site.xml
node01机器进行修改配置文件
修改hbase-site.xml
cd /export/servers/hbase-2.0.0/conf
vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://node01:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98后的新变动,之前版本没有.port,默认端口为60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/export/servers/zookeeper-3.4.9/zkdatas</value>
</property>
</configuration>
修改第三个配置文件regionservers
node01机器进行修改配置文件
cd /export/servers/hbase-2.0.0/conf
vim regionserversnode01
node02
node03
创建back-masters配置文件,实现HMaster的高可用
node01机器进行修改配置文件
cd /export/servers/hbase-2.0.0/conf
vim backup-mastersnode02
第四步:安装包分发到其他机器
将我们node01服务器的hbase的安装包拷贝到其他机器上面去
cd /export/servers/
scp -r hbase-2.0.0/ node02:$PWD
scp -r hbase-2.0.0/ node03:$PWD
第五步:三台机器创建软连接
因为hbase需要读取hadoop的core-site.xml以及hdfs-site.xml当中的配置文件信息,所以三台机器都要执行以下命令创建软连接
ln -s /export/servers/hadoop-2.7.5/etc/hadoop/core-site.xml /export/servers/hbase-2.0.0/conf/core-site.xml
ln -s /export/servers/hadoop-2.7.5/etc/hadoop/hdfs-site.xml /export/servers/hbase-2.0.0/conf/hdfs-site.xml第六步:三台机器添加HBASE_HOME的环境变量
三台机器执行以下命令,添加HBASE_HOME环境变量
vim /etc/profileexport HBASE_HOME=/export/servers/hbase-2.0.0
export PATH=:$HBASE_HOME/bin:$PATH
第七步:HBase集群启动
第一台机器执行以下命令进行启动
cd /export/servers/hbase-2.0.0
bin/start-hbase.sh第八步:页面访问
浏览器页面访问
http://node01:16010/master-status
node01服务器执行以下命令进入hbase的shell客户端
cd /export/servers/hbase-2.0.0
bin/hbase shell
2、查看帮助命令
hbase(main):001:0> help
3、查看当前数据库中有哪些表
hbase(main):002:0> list
4、创建一张表
创建user表,包含info、data两个列族
hbase(main):010:0> create 'user', 'info', 'data'
或者
hbase(main):010:0> create 'user', {NAME => 'info', VERSIONS => '3'},{NAME => 'data'}
5、添加数据操作
向user表中插入信息,row key为rk0001,列族info中添加name列标示符,值为zhangsan
hbase(main):011:0> put 'user', 'rk0001', 'info:name', 'zhangsan'
向user表中插入信息,row key为rk0001,列族info中添加gender列标示符,值为female
hbase(main):012:0> put 'user', 'rk0001', 'info:gender', 'female'
向user表中插入信息,row key为rk0001,列族info中添加age列标示符,值为20
hbase(main):013:0> put 'user', 'rk0001', 'info:age', 20
向user表中插入信息,row key为rk0001,列族data中添加pic列标示符,值为picture
hbase(main):014:0> put 'user', 'rk0001', 'data:pic', 'picture'
6、查询数据操作
1、通过rowkey进行查询
获取user表中row key为rk0001的所有信息
hbase(main):015:0> get 'user', 'rk0001'
2、查看rowkey下面的某个列族的信息
获取user表中row key为rk0001,info列族的所有信息
hbase(main):016:0> get 'user', 'rk0001', 'info'
3、查看rowkey指定列族指定字段的值
获取user表中row key为rk0001,info列族的name、age列标示符的信息
hbase(main):017:0> get 'user', 'rk0001', 'info:name', 'info:age'
4、查看rowkey指定多个列族的信息
获取user表中row key为rk0001,info、data列族的信息
hbase(main):018:0> get 'user', 'rk0001', 'info', 'data'
或者你也可以这样写
hbase(main):019:0> get 'user', 'rk0001', {COLUMN => ['info', 'data']}
或者你也可以这样写,也行
hbase(main):020:0> get 'user', 'rk0001', {COLUMN => ['info:name', 'data:pic']}
11.HBase的java代码开发
IDEA新建maven工程

pom.xml导入jar包

<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>Hbase</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>16</maven.compiler.source>
<maven.compiler.target>16</maven.compiler.target>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-server -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
</plugins>
</build>
</project>在java文件下新建一个类
就可以进行hbase的Java开发了
以下是我的测试代码
package cn.itcast.hbase.demo1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.testng.annotations.AfterTest;
import org.testng.annotations.BeforeClass;
import org.testng.annotations.BeforeTest;
import org.testng.annotations.Test;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
public class HBaseOperate {
//创建一张HBase表myuser有两个列族f1 f2
@Test
public void createTable() throws IOException {
//连接HBase集群
Configuration configuration = HBaseConfiguration.create();
//指定hbase的zk连接地址
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
//获取管理员对象
Admin admin =connection.getAdmin();
//通过管理员对象创建表
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf("myuser"));
//给表添加列族 f1 f2
HColumnDescriptor f1 = new HColumnDescriptor("f1");
HColumnDescriptor f2 = new HColumnDescriptor("f2");
//将两个列族设置到HTableDescriptor里面去
hTableDescriptor.addFamily(f1);
hTableDescriptor.addFamily(f2);
//创建表
admin.createTable(hTableDescriptor);
//关闭管理员对象
admin.close();
connection.close();
}
/*
* 向表中添加数据*/
@Test
public void addDate() throws IOException {
//获取连接
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
//获取表对象
Table myuser = connection.getTable(TableName.valueOf("myuser"));
//创建put对象,并指定rowkey
Put put = new Put("0001".getBytes());
//数据内容
put.addColumn("f1".getBytes(),"id".getBytes(), Bytes.toBytes(1));//1是整型
put.addColumn("f1".getBytes(),"name".getBytes(),Bytes.toBytes("张三"));//“张三”是字符串
put.addColumn("f1".getBytes(),"age".getBytes(),Bytes.toBytes(18));
put.addColumn("f2".getBytes(),"address".getBytes(),Bytes.toBytes("地球村"));
put.addColumn("f2".getBytes(),"phone".getBytes(),Bytes.toBytes("10086"));
//插入数据
myuser.put(put);
//关闭表
myuser.close();
}
/*
* 插入大量数据*/
@Test
public void insertBatchData() throws IOException {
//获取连接
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "node01:2181,node02:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
//获取表
Table myuser = connection.getTable(TableName.valueOf("myuser"));
//创建put对象,并指定rowkey
Put put = new Put("0002".getBytes());
put.addColumn("f1".getBytes(),"id".getBytes(),Bytes.toBytes(1));
put.addColumn("f1".getBytes(),"name".getBytes(),Bytes.toBytes("曹操"));
put.addColumn("f1".getBytes(),"age".getBytes(),Bytes.toBytes(30));
put.addColumn("f2".getBytes(),"sex".getBytes(),Bytes.toBytes("1"));
put.addColumn("f2".getBytes(),"address".getBytes(),Bytes.toBytes("沛国谯县"));
put.addColumn("f2".getBytes(),"phone".getBytes(),Bytes.toBytes("16888888888"));
put.addColumn("f2".getBytes(),"say".getBytes(),Bytes.toBytes("helloworld"));
Put put2 = new Put("0003".getBytes());
put2.addColumn("f1".getBytes(),"id".getBytes(),Bytes.toBytes(2));
put2.addColumn("f1".getBytes(),"name".getBytes(),Bytes.toBytes("刘备"));
put2.addColumn("f1".getBytes(),"age".getBytes(),Bytes.toBytes(32));
put2.addColumn("f2".getBytes(),"sex".getBytes(),Bytes.toBytes("1"));
put2.addColumn("f2".getBytes(),"address".getBytes(),Bytes.toBytes("幽州涿郡涿县"));
put2.addColumn("f2".getBytes(),"phone".getBytes(),Bytes.toBytes("17888888888"));
put2.addColumn("f2".getBytes(),"say".getBytes(),Bytes.toBytes("talk is cheap , show me the code"));
Put put3 = new Put("0004".getBytes());
put3.addColumn("f1".getBytes(),"id".getBytes(),Bytes.toBytes(3));
put3.addColumn("f1".getBytes(),"name".getBytes(),Bytes.toBytes("孙权"));
put3.addColumn("f1".getBytes(),"age".getBytes(),Bytes.toBytes(35));
put3.addColumn("f2".getBytes(),"sex".getBytes(),Bytes.toBytes("1"));
put3.addColumn("f2".getBytes(),"address".getBytes(),Bytes.toBytes("下邳"));
put3.addColumn("f2".getBytes(),"phone".getBytes(),Bytes.toBytes("12888888888"));
put3.addColumn("f2".getBytes(),"say".getBytes(),Bytes.toBytes("what are you 弄啥嘞!"));
Put put4 = new Put("0005".getBytes());
put4.addColumn("f1".getBytes(),"id".getBytes(),Bytes.toBytes(4));
put4.addColumn("f1".getBytes(),"name".getBytes(),Bytes.toBytes("诸葛亮"));
put4.addColumn("f1".getBytes(),"age".getBytes(),Bytes.toBytes(28));
put4.addColumn("f2".getBytes(),"sex".getBytes(),Bytes.toBytes("1"));
put4.addColumn("f2".getBytes(),"address".getBytes(),Bytes.toBytes("四川隆中"));
put4.addColumn("f2".getBytes(),"phone".getBytes(),Bytes.toBytes("14888888888"));
put4.addColumn("f2".getBytes(),"say".getBytes(),Bytes.toBytes("出师表你背了嘛"));
Put put5 = new Put("0006".getBytes());
put5.addColumn("f1".getBytes(),"id".getBytes(),Bytes.toBytes(5));
put5.addColumn("f1".getBytes(),"name".getBytes(),Bytes.toBytes("司马懿"));
put5.addColumn("f1".getBytes(),"age".getBytes(),Bytes.toBytes(27));
put5.addColumn("f2".getBytes(),"sex".getBytes(),Bytes.toBytes("1"));
put5.addColumn("f2".getBytes(),"address".getBytes(),Bytes.toBytes("哪里人有待考究"));
put5.addColumn("f2".getBytes(),"phone".getBytes(),Bytes.toBytes("15888888888"));
put5.addColumn("f2".getBytes(),"say".getBytes(),Bytes.toBytes("跟诸葛亮死掐"));
Put put6 = new Put("0007".getBytes());
put6.addColumn("f1".getBytes(),"id".getBytes(),Bytes.toBytes(5));
put6.addColumn("f1".getBytes(),"name".getBytes(),Bytes.toBytes("xiaobubu—吕布"));
put6.addColumn("f1".getBytes(),"age".getBytes(),Bytes.toBytes(28));
put6.addColumn("f2".getBytes(),"sex".getBytes(),Bytes.toBytes("1"));
put6.addColumn("f2".getBytes(),"address".getBytes(),Bytes.toBytes("内蒙人"));
put6.addColumn("f2".getBytes(),"phone".getBytes(),Bytes.toBytes("15788888888"));
put6.addColumn("f2".getBytes(),"say".getBytes(),Bytes.toBytes("貂蝉去哪了"));
List<Put> listPut = new ArrayList<Put>();
listPut.add(put);
listPut.add(put2);
listPut.add(put3);
listPut.add(put4);
listPut.add(put5);
listPut.add(put6);
myuser.put(listPut);
//关闭表
myuser.close();
}
private Connection connection;
private Configuration configuration;
private Table table;
/*
* 初始化操作*/
@BeforeTest
public void initTable() throws IOException {
//获取连接
configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "node01:2181,node02:2181,node03:2181");
connection = ConnectionFactory.createConnection(configuration);
table = connection.getTable(TableName.valueOf("myuser"));
}
/*
* 查询操作查询rowkey为0003的人,所有的列*/
@Test
public void getData() throws IOException {
Get get = new Get("0003".getBytes());
//查询f1列族下面所有列的值
//get.addFamily("f1".getBytes());
//查询f1列族下面id列的值
//get.addColumn("f1".getBytes(),"id".getBytes());
//Result是一个对象,封装了所有的结果数据
Result result = table.get(get);
//获取0003这条数据所有的cell值
List<Cell> cells = result.listCells();
for (Cell cell : cells) {
//获取列族名称
String familyName = Bytes.toString(cell.getFamilyArray(), cell.getFamilyOffset(), cell.getFamilyLength());
//获取列的名称
String columnName = Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());
if (familyName.equals("f1") && columnName.equals("id") || columnName.equals("age")) {
int value = Bytes.toInt(cell.getValueArray(),cell.getValueOffset(),cell.getValueLength());
System.out.println("列族名为" + familyName + "列名为" + columnName + "列的值为" + value);
}else {
String value = Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());
System.out.println("列族名为" + familyName + "列名为" + columnName + "列的值为" + value);
}
}
}
/*
* 按照rowkey进行范围值的扫描
* 扫描rowkey范围是0004到0006*/
@Test
public void scanRange() throws IOException {
Scan scan = new Scan();
//设置起始和结束的rowkey,范围值扫描包前不包后:只能扫到0005不能扫到0006.没有设置范围将会全局扫描
scan.setStartRow("0004".getBytes());
scan.setStopRow("0006".getBytes());
//返回多条数据结果值都封装在resultScanner里面了
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner){
List<Cell> cells = result.listCells();
for (Cell cell : cells){
String rowkey = Bytes.toString(cell.getRowArray(),cell.getRowOffset(),cell.getRowLength());
//获取列族名
String familyName = Bytes.toString(cell.getFamilyArray(),cell.getFamilyOffset(),cell.getFamilyLength());
//获取列名
String columnName = Bytes.toString(cell.getQualifierArray(),cell.getQualifierOffset(),cell.getQualifierLength());
if (familyName.equals("f1") && columnName.equals("id") || columnName.equals("age")) {
int value = Bytes.toInt(cell.getValueArray(),cell.getValueOffset(),cell.getValueLength());
System.out.println("数据的rowkey为" + rowkey + "列族名为" + familyName + "列名为" + columnName + "列的值为" + value);
}else {
String value = Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());
System.out.println("数据的rowkey为" + rowkey + "列族名为" + familyName + "列名为" + columnName + "列的值为" + value);
}
}
}
}
@AfterTest
public void closeTable() throws IOException {
table.close();
}
}
登录后可发表评论
点击登录