文章目录
- 一、写在前面
- 二、准备工作
- 1、知识点
- 2、使用的软件
- 3、第三方库
- 三、大致流程
- 四、代码展示分析
- 1、爬虫部分
- 1.1 代码展示
- 2、效果展示
- 2.1 爬取中
- 2.2 保存的数据
- 3、数据分析部分
- 3.1 导入模块
- 3.2 Pandas数据处理
- 3.3 Pyecharts可视化
- 3.4 二手车推荐
- 4、数据分析代码运行
一、写在前面
兄弟们,你们的热情让我都不敢断更了,冲!

爬妹子什么的,虽然大家都很喜欢,但是也不能经常去爬对吧,身体重要,当然如果你们有什么好的网站,都可以推荐下,下次我爬完了给你们分享~

网友:其实就是你自己想看吧

二、准备工作
1、知识点
- requests 发送网络请求
- parsel 解析数据
- csv 保存数据
2、使用的软件
- 环境版本: python3.8
- 编辑器版本:pycharm2021.2
不会安装软件的看我之前发的:Python入门合集
Python安装/环境配置/pycharm安装/基本操作/快捷键/永久使用都有
3、第三方库
- requests
- parsel
这些是需要安装的第三方库,直接pip安装就好了。
pip install requests
pip install parsel
安装慢就使用镜像源安装
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple/
镜像源有很多,我这里用的清华的。
实在不会安装模块看我以前的文章:Python安装第三方模块及解决pip下载慢/安装报错
三、大致流程
- 找到 目标网址
https://www.dongchedi.com/usedcar/x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x?sh_city_name=%E5%85%A8%E5%9B%BD&page=1
a 确定我们要采集的目标 年份 品牌…
b 确定数据来源 (静态页面True 和 动态页面) - 发送请求
- 获取数据 html网页源代码
- 解析数据 re css xpath bs4 …
- 保存数据
- 数据分析 简单的数据可视化 推荐功能
工具是不一样的 anaconda(python解释器) 里面的 jupyter notebook
四、代码展示分析
1、爬虫部分
1.1 代码展示
import requests # 发送网络请求
import parsel # 解析数据
import csv # 保存数据
csv_dcd = open('dcd.csv', mode='a', encoding='utf-8', newline='')
csv_write = csv.writer(csv_dcd)
csv_write.writerow(['品牌', '车龄', '里程(万公里)', '城市', '认证', '售价(万元)', '原价(万元)', '链接'])
for page in range(1, 168):
# 1. 找到 目标网址
url = f'https://www.dongchedi.com/usedcar/x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x?sh_city_name=%E5%85%A8%E5%9B%BD&page={page}'
# 2. 发送请求
# 3. 获取数据 html网页源代码
# <Response [200]>: 请求成功的状态码 访问这个网站成功了
html_data = requests.get(url).text
# 4. 解析数据 re css xpath bs4 ...
selector = parsel.Selector(html_data)
# get(): 获取一个
# getall(): 获取全部
lis = selector.css('#__next > div:nth-child(2) > div.new-main.new > div > div > div.wrap > ul li')
for li in lis:
# 二次提取
# ::text: 提取文本内容
# 品牌
title = li.css('a dl dt p::text').get()
# 信息 年份 里程 城市
# :nth-child(2):伪类选择器
info = li.css('a dl dd:nth-child(2)::text').getall()
# info 列表里面有两个元素
# 列表合并为字符串
info_str = ''.join(info)
# 字符串的分割
info_list = info_str.split('|')
car_age = info_list[0]
mileage = info_list[1].replace('万公里', '')
city = info_list[2].strip()
# 链接
link = 'https://www.dongchedi.com' + li.css('a::attr(href)').get()
dds = li.css('a dl dd')
# 如果当前 有 4个dd标签
if len(dds) == 4:
# 懂车帝认证
dcd_auth = li.css('a dl dd:nth-child(3) span::text').get()
price = li.css('a dl dd:nth-child(4)::text').get()
original_price = li.css('a dl dd:nth-child(5)::text').get()
else:
dcd_auth = '无认证'
price = li.css('a dl dd:nth-child(3)::text').get()
original_price = li.css('a dl dd:nth-child(4)::text').get()
price = price.replace('万', '')
original_price = original_price.replace('新车含税价: ', '').replace('万', '')
print(title, car_age, mileage, city, dcd_auth, price, original_price, link)
csv_write.writerow([title, car_age, mileage, city, dcd_auth, price, original_price, link])
csv_dcd.close()
2、效果展示
2.1 爬取中
用pycharm打印出来有点乱码,它这个地方是有字体加密了,加密的部分就不显示,解密今天就先不分享了。

2.2 保存的数据
这是保存在Excel里面的数据,等下分析就分析这里面保存好的数据。
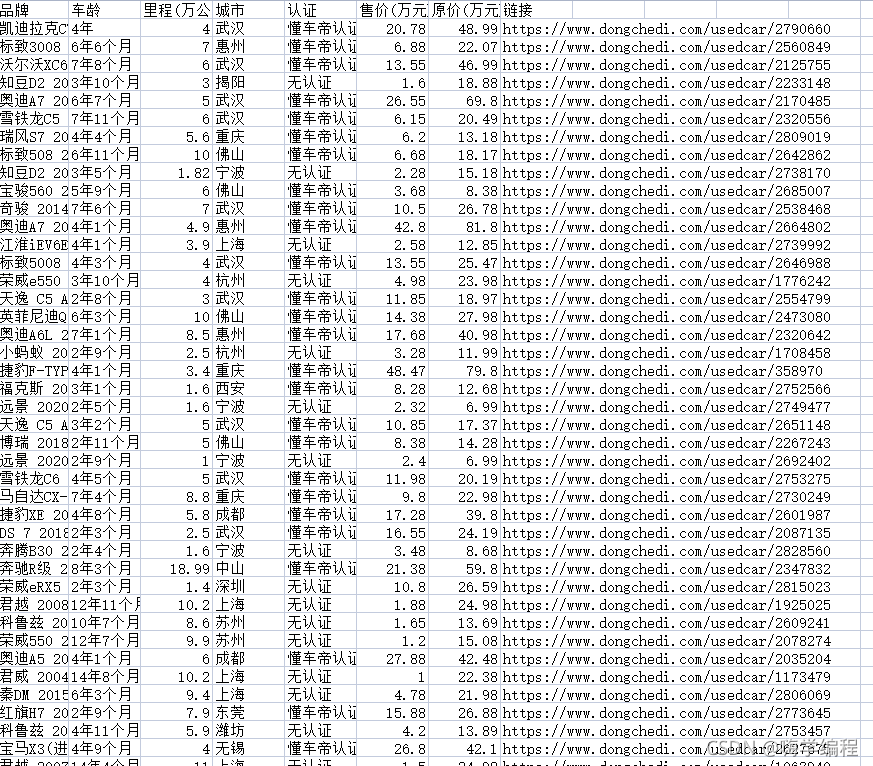
3、数据分析部分
3.1 导入模块
import pandas as pd
from pyecharts.charts import *
from pyecharts.commons.utils import JsCode
from pyecharts import options as opts
pyecharts 没有的话需要安装一下
3.2 Pandas数据处理
3.21 读取数据
df = pd.read_csv('dcd.csv', encoding = 'utf-8')
df.head()
3.22 查看表格数据描述
df.describe()
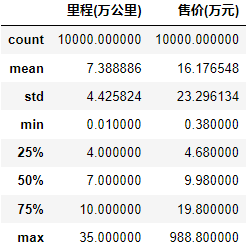
一共有10000条数据
3.23 查看表格是否有数据缺失
df.isnull().sum()

3.3 Pyecharts可视化
3.31 Pyecharts可视化
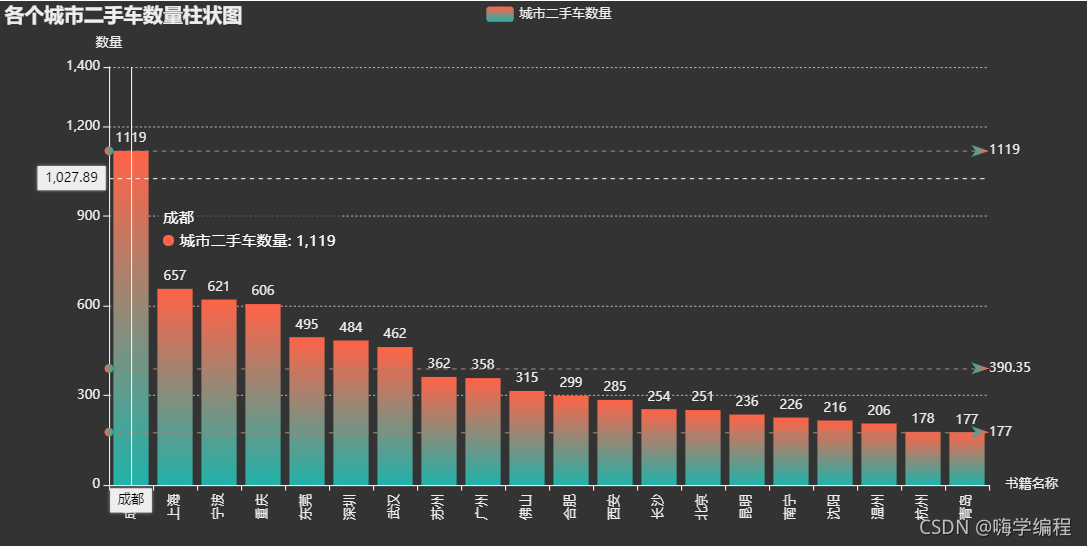
counts = df.groupby('城市')['品牌'].count().sort_values(ascending=False).head(20)
bar=(
Bar(init_opts=opts.InitOpts(height='500px',width='1000px',theme='dark'))
.add_xaxis(counts.index.tolist())
.add_yaxis(
'城市二手车数量',
counts.values.tolist(),
label_opts=opts.LabelOpts(is_show=True,position='top'),
itemstyle_opts=opts.ItemStyleOpts(
color=JsCode("""new echarts.graphic.LinearGradient(
0, 0, 0, 1,[{offset: 0,color: 'rgb(255,99,71)'}, {offset: 1,color: 'rgb(32,178,170)'}])
"""
)
)
)
.set_global_opts(
title_opts=opts.TitleOpts(
title='各个城市二手车数量柱状图'),
xaxis_opts=opts.AxisOpts(name='书籍名称',
type_='category',
axislabel_opts=opts.LabelOpts(rotate=90),
),
yaxis_opts=opts.AxisOpts(
name='数量',
min_=0,
max_=1400.0,
splitline_opts=opts.SplitLineOpts(is_show=True,linestyle_opts=opts.LineStyleOpts(type_='dash'))
),
tooltip_opts=opts.TooltipOpts(trigger='axis',axis_pointer_type='cross')
)
.set_series_opts(
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_='average',name='均值'),
opts.MarkLineItem(type_='max',name='最大值'),
opts.MarkLineItem(type_='min',name='最小值'),
]
)
)
)
bar.render_notebook()
可以看到成都的二手车数量是最多的,远超第二。
3.32 各省市二手车平均价格柱状图
means = df.groupby('城市')['售价(万元)'].mean().astype('int64').head(20)
bar=(
Bar(init_opts=opts.InitOpts(height='500px',width='1000px',theme='dark'))
.add_xaxis(means.index.tolist())
.add_yaxis(
'城市二手车平均价格',
means.values.tolist(),
label_opts=opts.LabelOpts(is_show=True,position='top'),
itemstyle_opts=opts.ItemStyleOpts(
color=JsCode("""new echarts.graphic.LinearGradient(
0, 0, 0, 1,[{offset: 0,color: 'rgb(255,99,71)'}, {offset: 1,color: 'rgb(32,178,170)'}])
"""
)
)
)
.set_global_opts(
title_opts=opts.TitleOpts(
title='各个城市二手车平均价格柱状图'),
xaxis_opts=opts.AxisOpts(name='城市名称',
type_='category',
axislabel_opts=opts.LabelOpts(rotate=90),
),
yaxis_opts=opts.AxisOpts(
name='平均价格',
min_=0,
max_=40.0,
splitline_opts=opts.SplitLineOpts(is_show=True,linestyle_opts=opts.LineStyleOpts(type_='dash'))
),
tooltip_opts=opts.TooltipOpts(trigger='axis',axis_pointer_type='cross')
)
.set_series_opts(
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_='average',name='均值'),
opts.MarkLineItem(type_='max',name='最大值'),
opts.MarkLineItem(type_='min',name='最小值'),
]
)
)
)
bar.render_notebook()
不过价格的话,成都就比较平均,帝都遥遥领先。
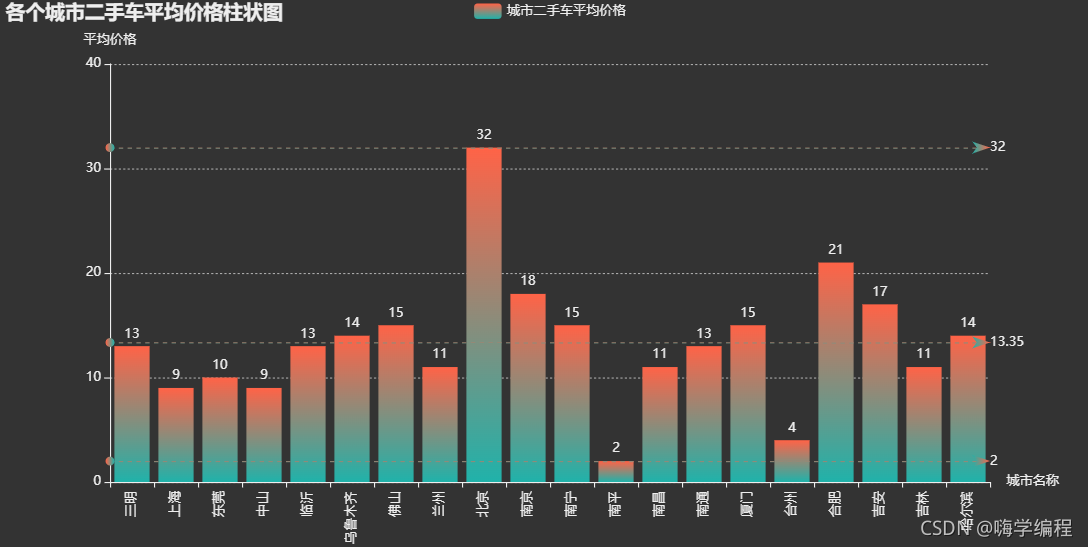
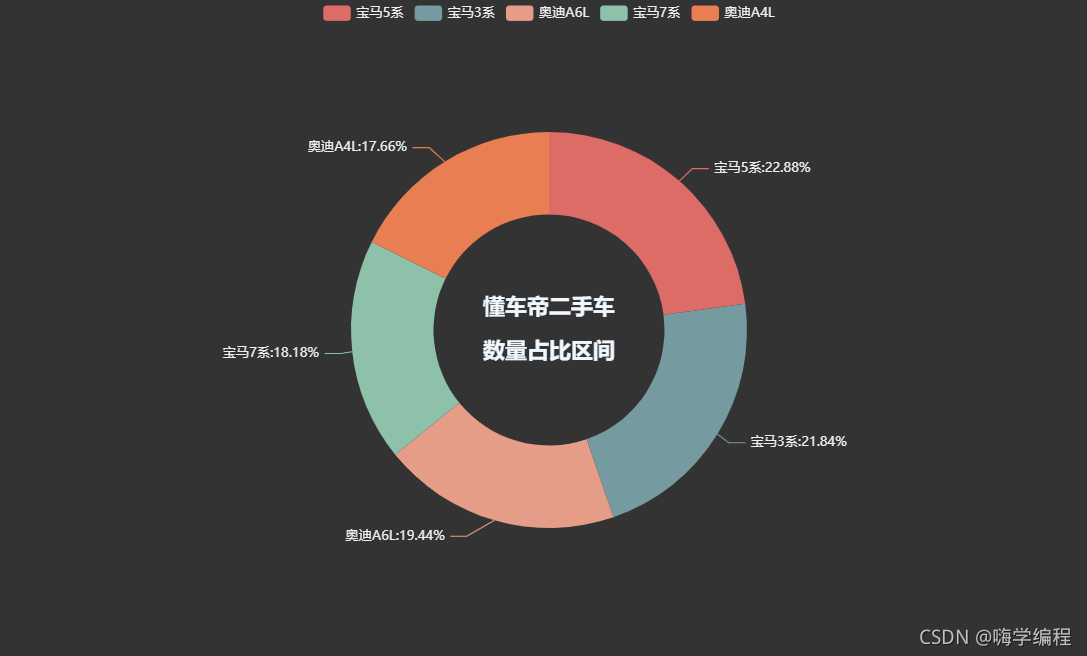
3.33 二手车品牌占比情况
dcd_pinpai = df['品牌'].apply(lambda x:x.split(' ')[0])
df['品牌'] = dcd_pinpai
pinpai = df['品牌'].value_counts()
pinpai = pinpai[:5]
datas_pair_1 = [[i, int(j)] for i, j in zip(pinpai.index, pinpai.values)]
datas_pair_1
pie1 = (
Pie(init_opts=opts.InitOpts(theme='dark',width='1000px',height='600px'))
.add('', datas_pair_1, radius=['35%', '60%'])
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
.set_global_opts(
title_opts=opts.TitleOpts(
title="懂车帝二手车\n\n数量占比区间",
pos_left='center',
pos_top='center',
title_textstyle_opts=opts.TextStyleOpts(
color='#F0F8FF',
font_size=20,
font_weight='bold'
),
)
)
)
pie1.render_notebook()
以宝马奥迪这几款车型来看,二手车品牌占比情况,宝马比奥迪胜出一筹。
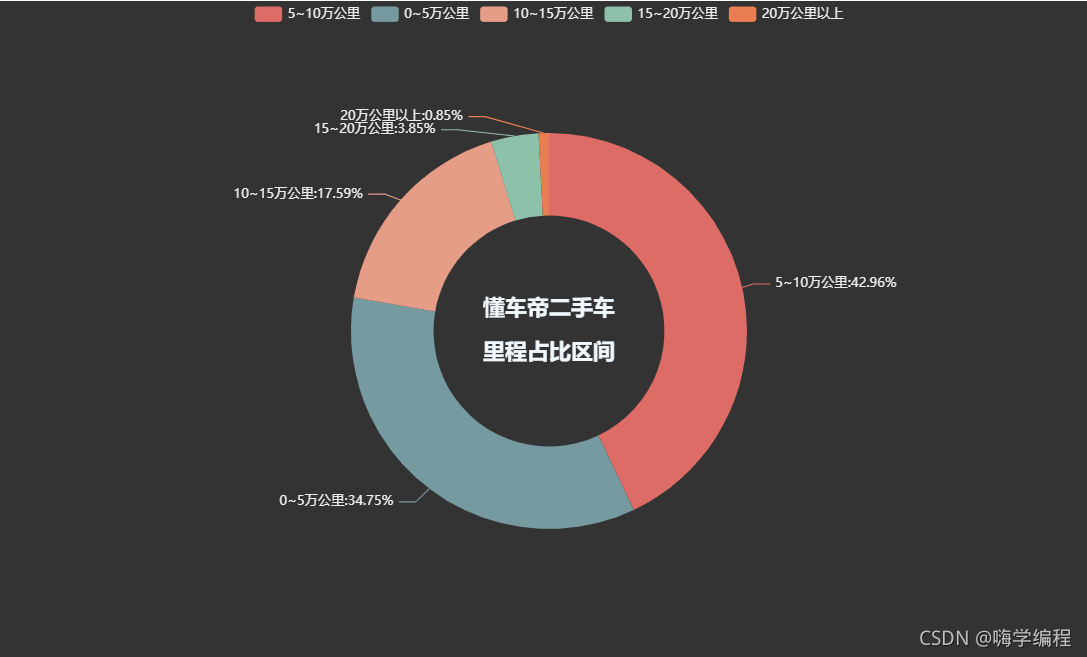
2.34 二手车里程区间
def tranform_price(x):
if x <= 5.0:
return '0~5万公里'
elif x <= 10.0:
return '5~10万公里'
elif x <= 15.0:
return '10~15万公里'
elif x <= 20.0:
return '15~20万公里'
else:
return '20万公里以上'
df['里程分级'] = df['里程(万公里)'].apply(lambda x:tranform_price(x))
price_1 = df['里程分级'].value_counts()
datas_pair_1 = [(i, int(j)) for i, j in zip(price_1.index, price_1.values)]
pie1 = (
Pie(init_opts=opts.InitOpts(theme='dark',width='1000px',height='600px'))
.add('', datas_pair_1, radius=['35%', '60%'])
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
.set_global_opts(
title_opts=opts.TitleOpts(
title="懂车帝二手车\n\n里程占比区间",
pos_left='center',
pos_top='center',
title_textstyle_opts=opts.TextStyleOpts(
color='#F0F8FF',
font_size=20,
font_weight='bold'
),
)
)
)
pie1.render_notebook()
基本上都是10公里以内的里程,还是非常有搞头的。看得我都想去冲两台了~
3.4 二手车推荐
k_list = []
the_list = []
keyword = input('请输入品牌:')
data5 = df.loc[df['品牌'].str.contains(str(keyword))]
keyword1 = eval(input('请输入里程(万公里)上限:'))
data6 = data5[data5['里程(万公里)'] <= keyword1]
city = input('请输入城市:')
data7 = data6[data6['城市'] == str(city)]
day1 = eval(input('请输入售价(万元)下限:'))
day2 = eval(input('请输入售价(万元)上限:'))
data8 = data7[(data7['售价(万元)']>=day1)&(data7['售价(万元)']<=day2)]
data8
哈哈 长沙居然没有奥迪 ,不给力啊
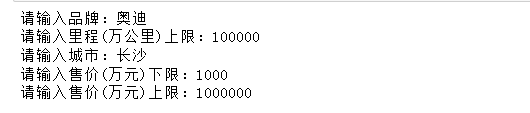
4、数据分析代码运行
数据分析代码的话,一般都是ipynb格式的,对于刚学数据分析的兄弟来说,就比较迷茫了,我简单分享下。
首先打开我们存放代码的文件夹,然后在地址栏输入 jupyter notebook 然后按回车。
如果你实在找不到代码存放的位置,右键点击代码打开属性。

比如我是放在C:\Users\Administrator\Desktop
然后打开一个新的文件窗口,把这个地址粘贴进去按回车进入这个位置。 继续前面讲的,我们按回车之后就会弹出这个窗口。
继续前面讲的,我们按回车之后就会弹出这个窗口。
 找到你要运行的代码点进去就打开这个代码了
找到你要运行的代码点进去就打开这个代码了
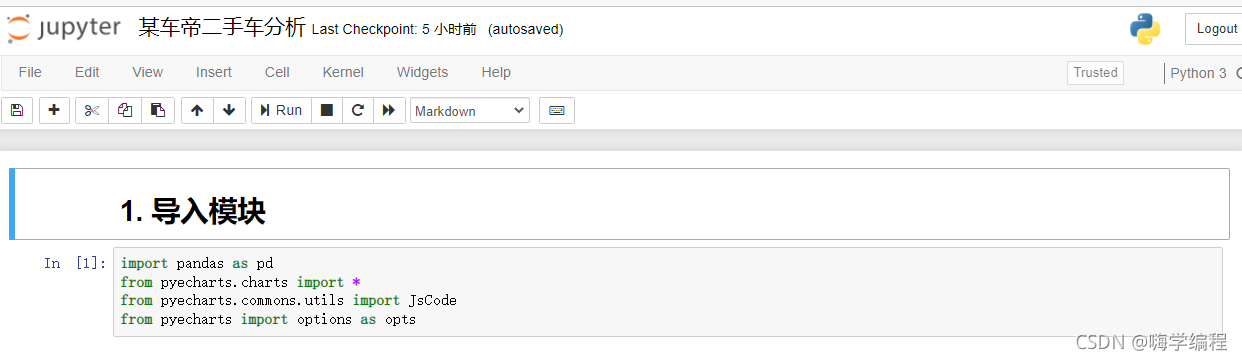 运行都是一样的 点 run 就好了,运行之前你下载的数据一定要准备好,没数据怎么分析呢,对吧~
运行都是一样的 点 run 就好了,运行之前你下载的数据一定要准备好,没数据怎么分析呢,对吧~
兄弟们,文章看不会的话,我把视频教程放在评论区置顶了。