用python爬取微博评论数据,爬虫之路,永无止境。。(附源码)
今天目标爬取微博任意博文的评论信息
工具使用
开发环境:win10、python3.6
开发工具:pycharm
工具包 :requests,re, time, random,tkinter
项目思路分析
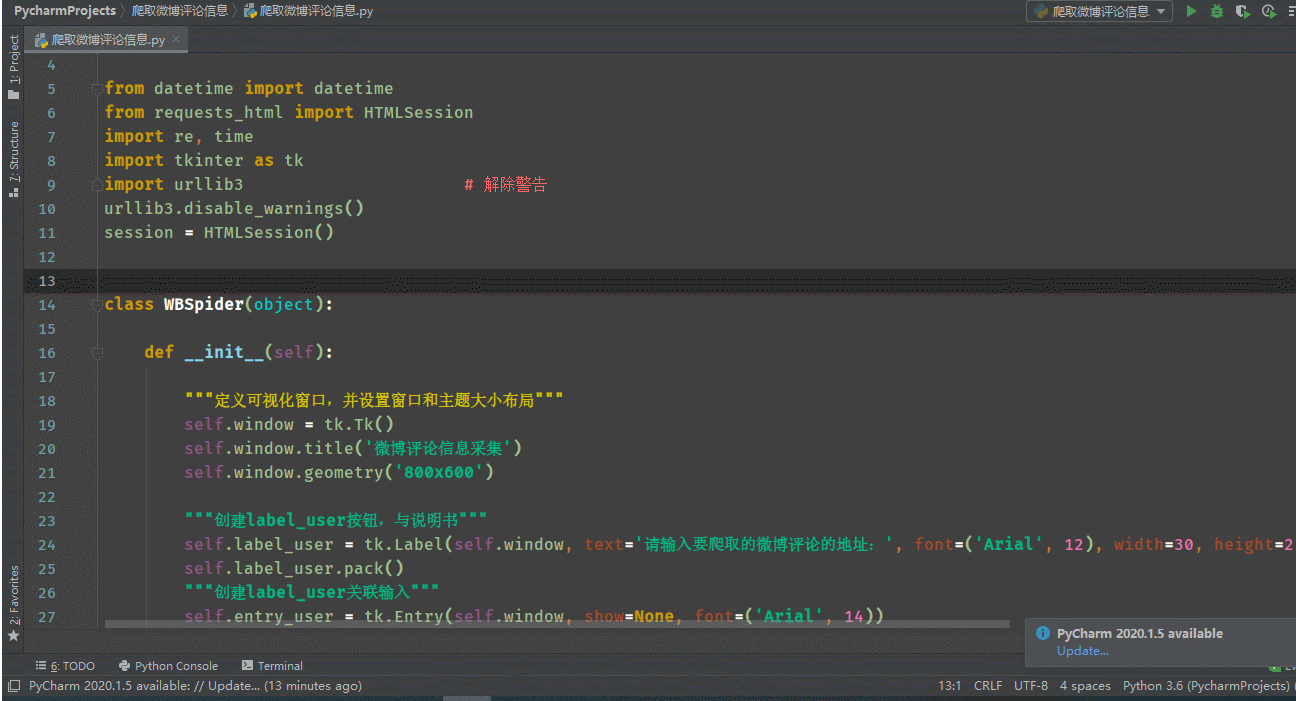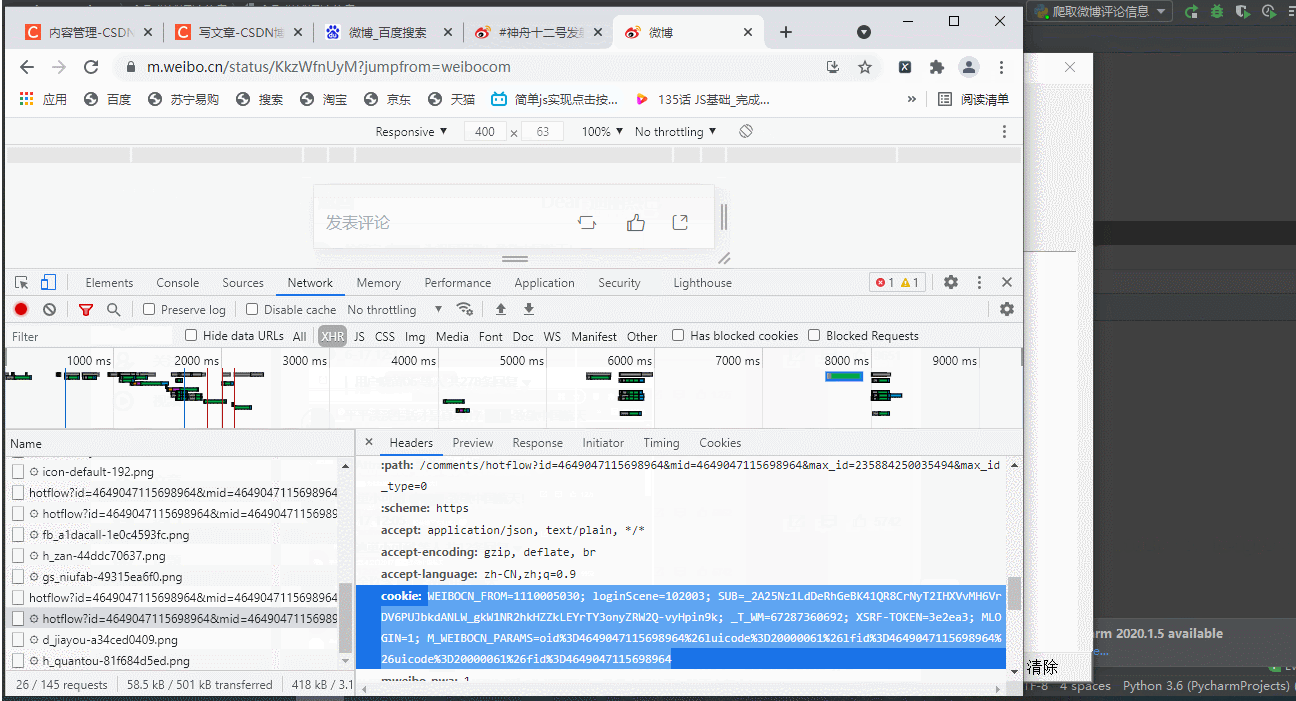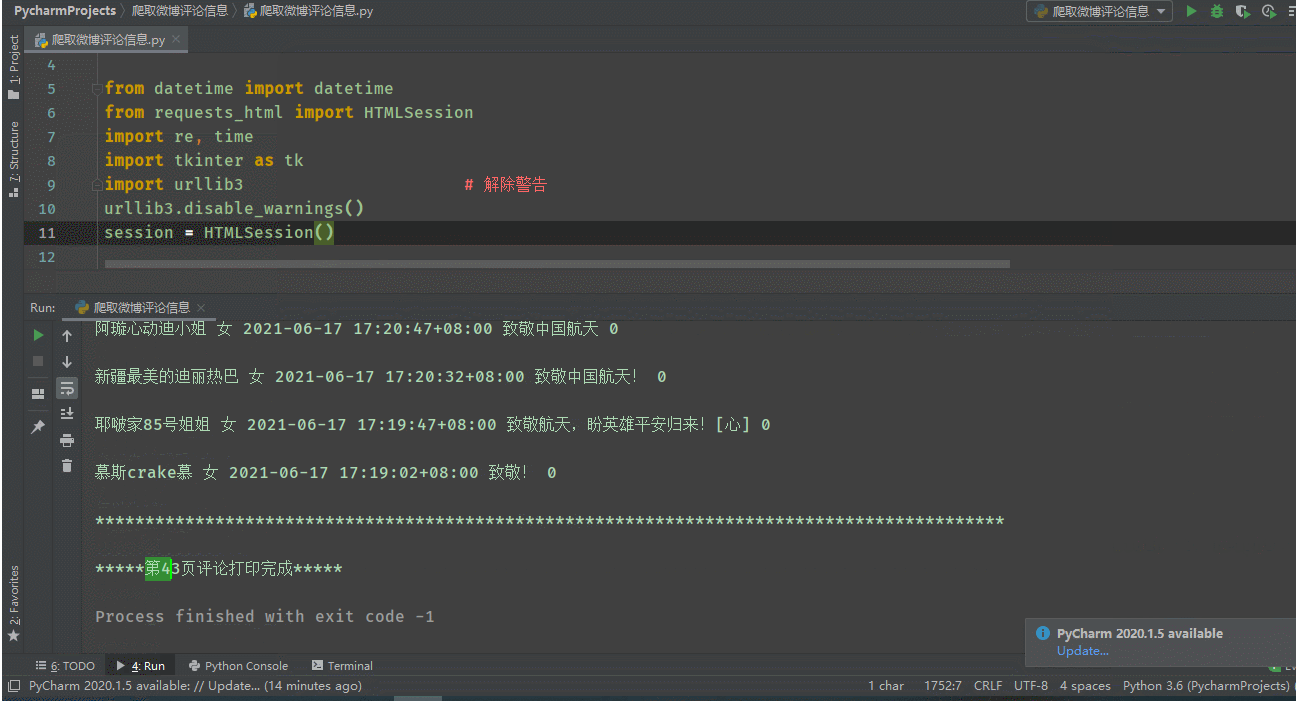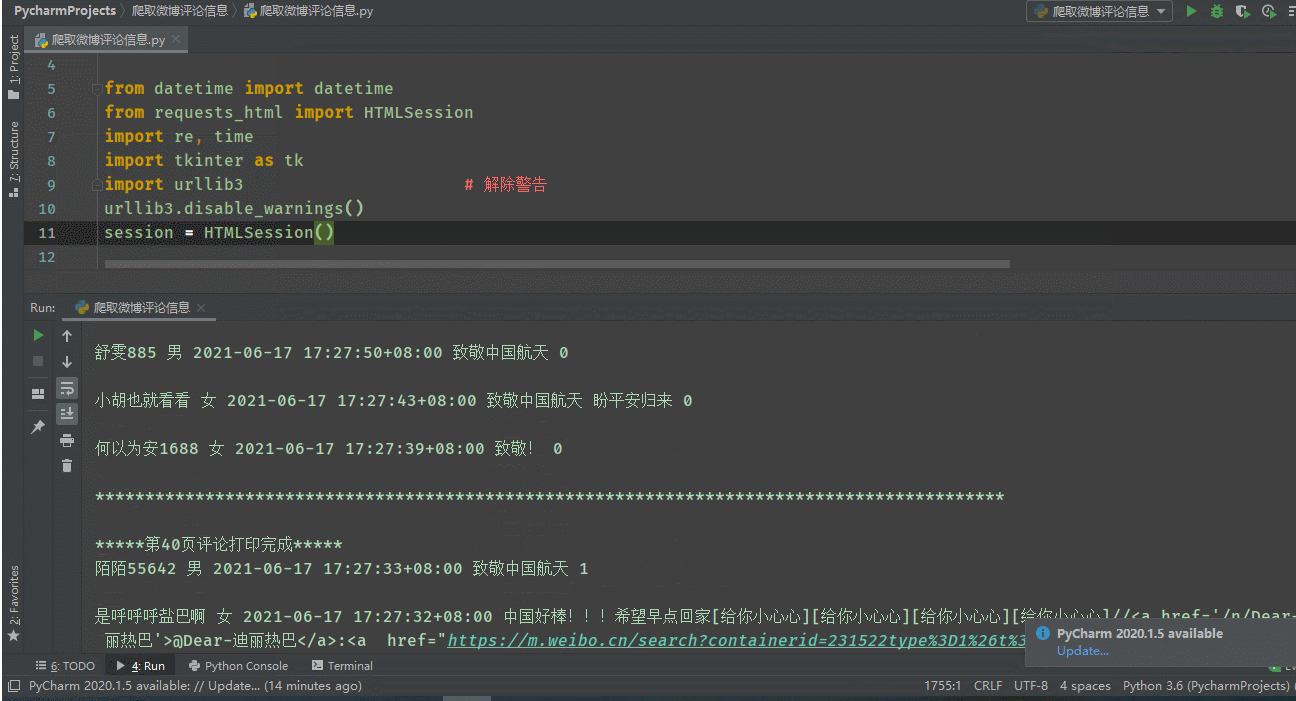
1.网页版登录拿回cookie值
2.选取要爬的博文评论信息的网页版网址
https://weibo.com/3167104922/Kkl7ar83T#comment为例
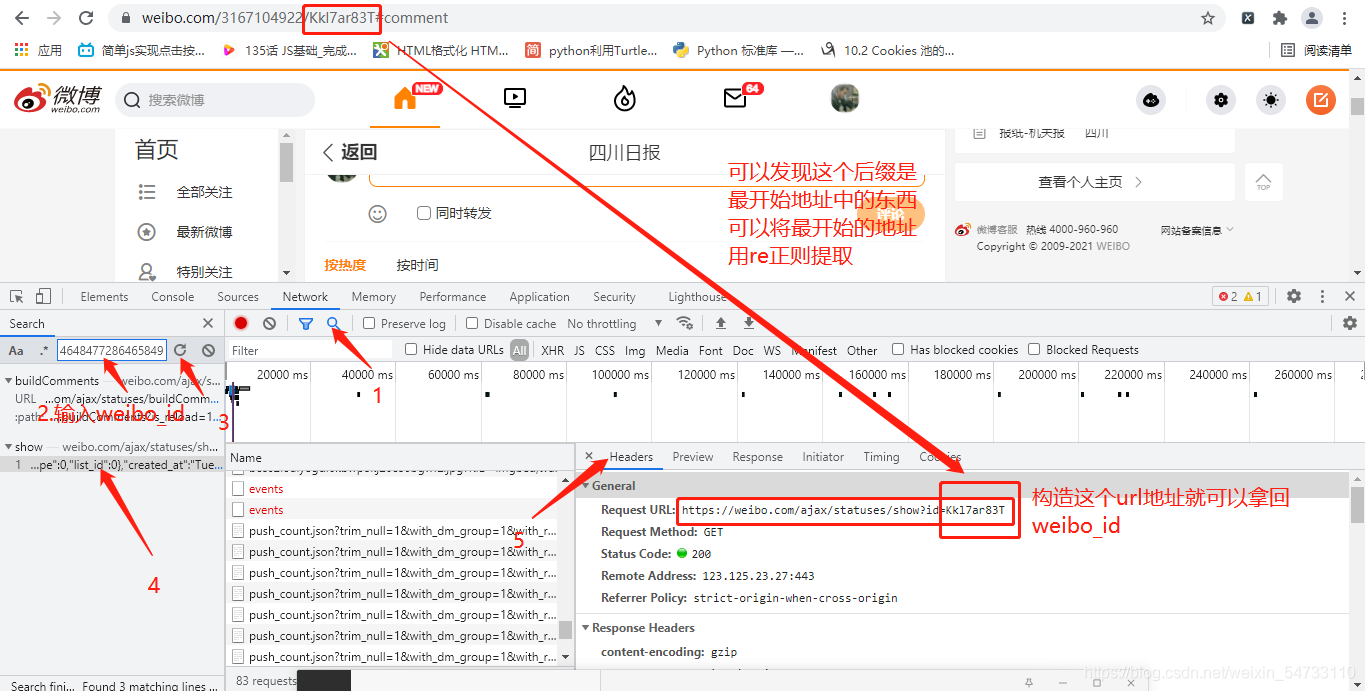
3.根据网页版的地址抓包拿回博文唯一的id值(weibo_id)
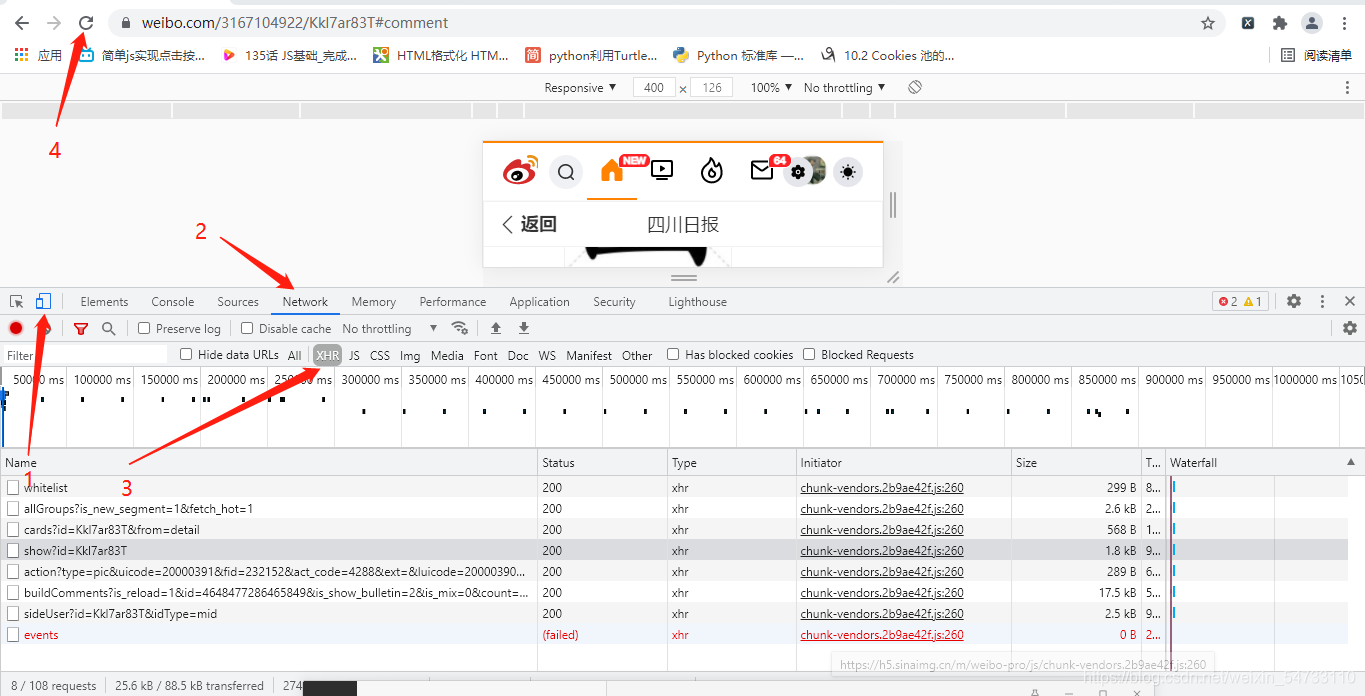
4.构造博文手机版评论请求的地址
f’https://m.weibo.cn/comments/hotflow?id={weibo_id}&mid={weibo_id}&max_id_type=0’
5.发送请求拿回响应的json数据
6.max_id和max_id_type的值确定
7.构造data参数,下次翻页请求要加上参数
"""构造GET请求参数"""
data = {
'id': weibo_id,
'mid': weibo_id,
'max_id': max_id,
'max_id_type': max_id_type
}
8.max_id为上一个包的翻页规律
9.然后继续解析数据,获取评论信息内容,然后再翻页,一直回调。
起始地址先进行登录
https://weibo.com/
登录之后点开一篇博文,点击评论,点击查看更多评论
本文以https://weibo.com/3167104922/Kkl7ar83T#comment为例
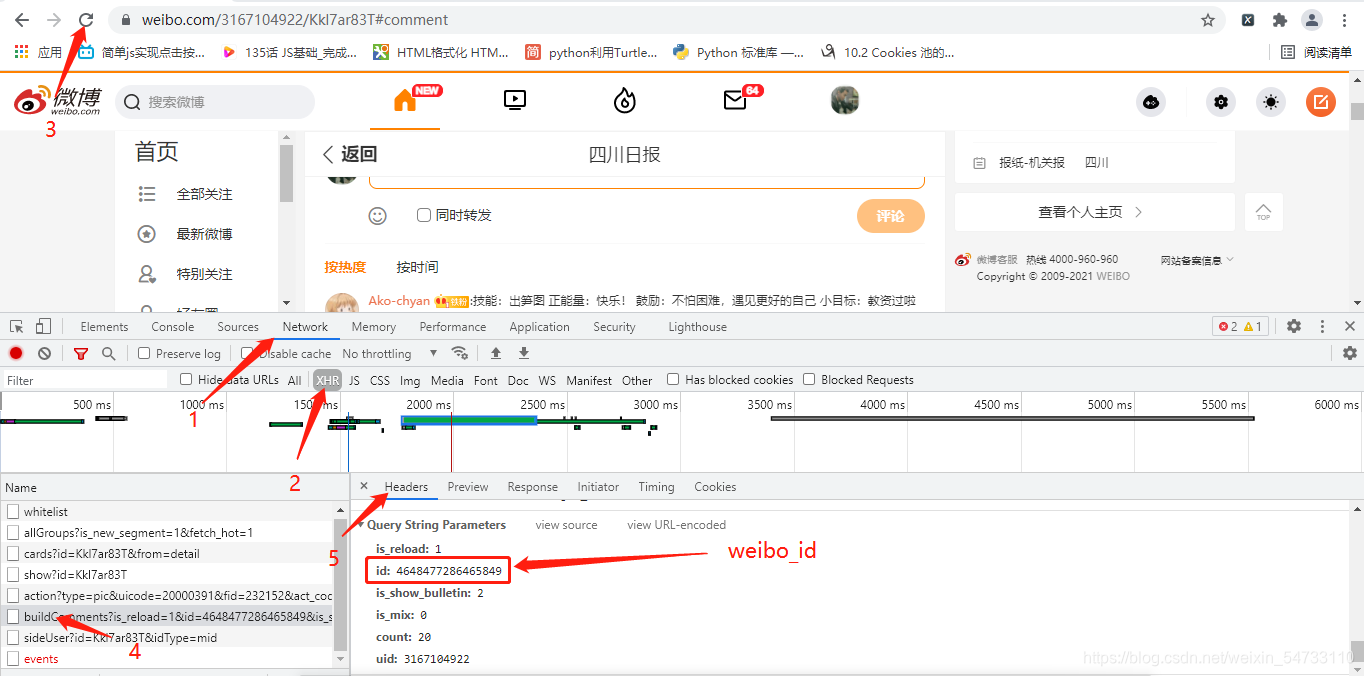
search搜索weibo_id,构造headers里面的requests url,发送请求拿回weibo_id的值
进入手机版模式进行XHR抓包
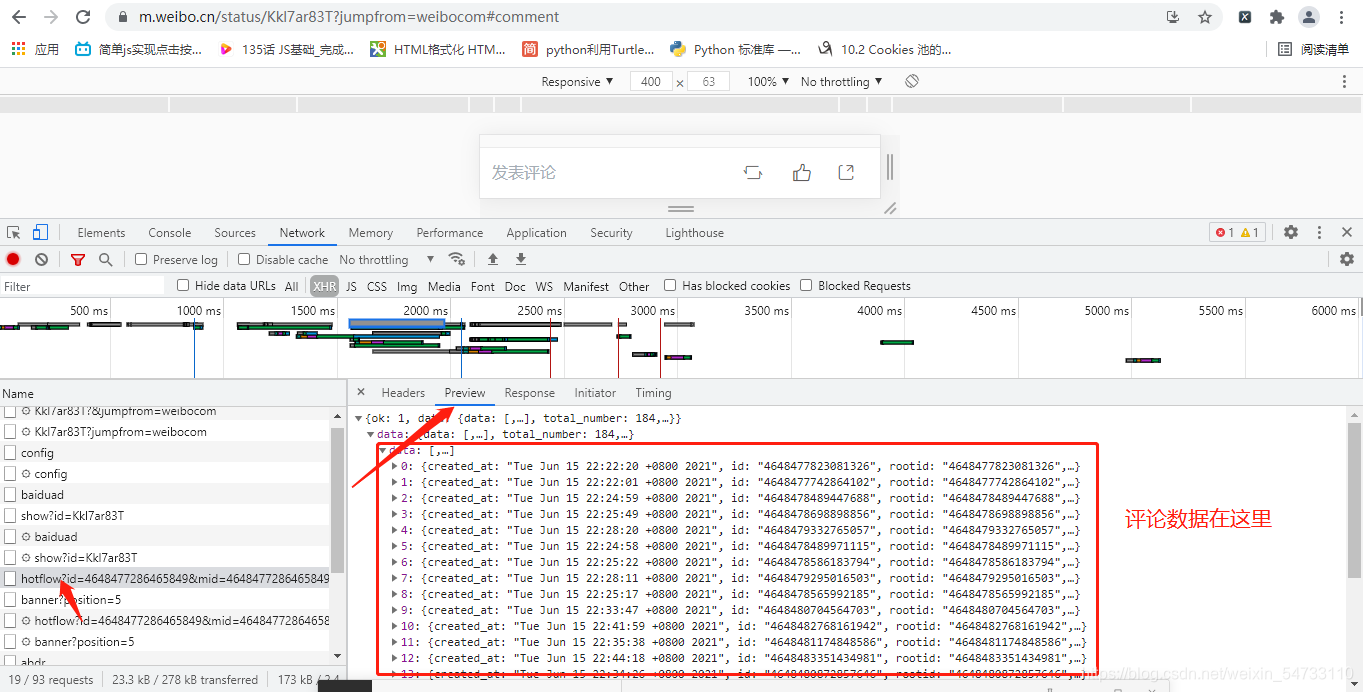
翻页用到data的参数
"""构造GET请求参数"""
data = {
'id': weibo_id,
'mid': weibo_id,
'max_id': max_id,
'max_id_type': max_id_type
}
先来个代码操作
本代码需要准备手机版登录后的cookie和博文网页版地址
源码展示:
# !/usr/bin/nev python
# -*-coding:utf8-*-
from datetime import datetime
from requests_html import HTMLSession
import re, time
import tkinter as tk
import urllib3 # 解除警告
urllib3.disable_warnings()
session = HTMLSession()
class WBSpider(object):
def __init__(self):
"""定义可视化窗口,并设置窗口和主题大小布局"""
self.window = tk.Tk()
self.window.title('微博评论信息采集')
self.window.geometry('800x600')
"""创建label_user按钮,与说明书"""
self.label_user = tk.Label(self.window, text='请输入要爬取的微博评论的地址:', font=('Arial', 12), width=30, height=2)
self.label_user.pack()
"""创建label_user关联输入"""
self.entry_user = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_user.pack(after=self.label_user)
"""创建label_passwd按钮,与说明书"""
self.label_passwd = tk.Label(self.window, text="请输入登陆后的cookie:", font=('Arial', 12), width=30, height=2)
self.label_passwd.pack()
"""创建label_passwd关联输入"""
self.entry_passwd = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_passwd.pack(after=self.label_passwd)
"""创建Text富文本框,用于按钮操作结果的展示"""
self.text1 = tk.Text(self.window, font=('Arial', 12), width=85, height=22)
self.text1.pack()
"""定义按钮1,绑定触发事件方法"""
self.button_1 = tk.Button(self.window, text='爬取', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_1)
self.button_1.pack(before=self.text1)
"""定义按钮2,绑定触发事件方法"""
self.button_2 = tk.Button(self.window, text='清除', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_2)
self.button_2.pack(anchor="e")
def parse_hit_click_1(self):
"""定义触发事件1,调用main函数"""
user_url = self.entry_user.get()
pass_wd = self.entry_passwd.get()
self.main(user_url, pass_wd)
def main(self, user_url, pass_wd):
i = 1
headers_1 = {
'cookie': pass_wd,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36'
}
headers_2 ={
"referer": "https://m.weibo.cn/status/Kk9Ft0FIg?jumpfrom=weibocom",
'cookie': pass_wd,
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Mobile Safari/537.36'
}
uid_1 = re.findall('/(.*?)#', user_url)[0]
uid_2 = uid_1.split('/', 3)[3]
# print(uid_2)
url_1 = f'https://weibo.com/ajax/statuses/show?id={uid_2}'
prox = ''
response = session.get(url_1, proxies={'http': prox, 'https': prox}, headers=headers_1, verify=False).content.decode()
# print(response)
weibo_id = re.findall('"id":(.*?),"idstr"', response)[0]
# print(weibo_id)
# 构造起始地址
start_url = f'https://m.weibo.cn/comments/hotflow?id={weibo_id}&mid={weibo_id}&max_id_type=0'
"""
2.发送请求,获取响应: 解析起始的url地址
:return:
"""
prox = ''
response = session.get(start_url, proxies={'http': prox, 'https': prox}, headers=headers_2, verify=False).json()
"""提取翻页的max_id"""
max_id = response['data']['max_id']
"""提取翻页的max_id_type"""
max_id_type = response['data']['max_id_type']
"""构造GET请求参数"""
data = {
'id': weibo_id,
'mid': weibo_id,
'max_id': max_id,
'max_id_type': max_id_type
}
"""解析评论内容"""
self.parse_response_data(response, i)
i+=1
"""参数传递,方法回调"""
self.parse_page_func(data, weibo_id, headers_2, i)
def parse_page_func(self, data, weibo_id, headers_2, i):
"""
:return:
"""
start_url = 'https://m.weibo.cn/comments/hotflow?'
prox = ''
response = session.get(start_url, proxies={'http': prox, 'https': prox}, headers=headers_2, params=data, verify=False).json()
"""提取翻页的max_id"""
max_id = response['data']['max_id']
"""提取翻页的max_id_type"""
max_id_type = response['data']['max_id_type']
"""构造GET请求参数"""
data = {
'id': weibo_id,
'mid': weibo_id,
'max_id': max_id,
'max_id_type': max_id_type
}
"""解析评论内容"""
self.parse_response_data(response, i)
i+=1
"""递归回调"""
self.parse_page_func(data, weibo_id, headers_2, i)
def parse_response_data(self, response, i):
"""
从响应中提取评论内容
:return:
"""
"""提取出评论大列表"""
data_list = response['data']['data']
# print(data_list)
for data_json_dict in data_list:
# 提取评论内容
try:
texts_1 = data_json_dict['text']
"""需要sub替换掉标签内容"""
# 需要替换的内容,替换之后的内容,替换对象
alts = ''.join(re.findall(r'alt=(.*?) ', texts_1))
texts = re.sub("<span.*?</span>", alts, texts_1)
# 点赞量
like_counts = str(data_json_dict['like_count'])
# 评论时间 格林威治时间---需要转化为北京时间
created_at = data_json_dict['created_at']
std_transfer = '%a %b %d %H:%M:%S %z %Y'
std_create_times = str(datetime.strptime(created_at, std_transfer))
# 性别 提取出来的是 f
gender = data_json_dict['user']['gender']
genders = '女' if gender == 'f' else '男'
# 用户名
screen_names = data_json_dict['user']['screen_name']
print(screen_names, genders, std_create_times, texts, like_counts)
print()
except Exception as e:
continue
print('*******************************************************************************************')
print()
print(f'*****第{i}页评论打印完成*****')
def parse_hit_click_2(self):
"""定义触发事件2,删除文本框中内容"""
self.entry_user.delete(0, "end")
self.entry_passwd.delete(0, "end")
self.text1.delete("1.0", "end")
def center(self):
"""创建窗口居中函数方法"""
ws = self.window.winfo_screenwidth()
hs = self.window.winfo_screenheight()
x = int((ws / 2) - (800 / 2))
y = int((hs / 2) - (600 / 2))
self.window.geometry('{}x{}+{}+{}'.format(800, 600, x, y))
def run_loop(self):
"""禁止修改窗体大小规格"""
self.window.resizable(False, False)
"""窗口居中"""
self.center()
"""窗口维持--持久化"""
self.window.mainloop()
if __name__ == '__main__':
w = WBSpider()
w.run_loop()
