图书管理系统重构版Mysql
- 曾经沧海难为水
- 回眸只在一瞬间
- 关于文档的那些事
- 关于格式的那些解
- 关于需求的那些法
- 光景更替这般道
- 结构基本设计
- 处理流程分析
- 除却巫山不是云
- 迷雾拨开亮点
- 附上真诚代码

曾经沧海难为水
博主经历了九九八十一难,也走过了无数的大坑小坑,在学完数据库之后,终于在和小伙伴的共同努力下,把这个图书馆管理系统重构版本给完成啦,在之前呢,博主也完成过图书管理系统,不过在那次主要是实现的IO流,而这次改用不同数据保存,本项目的数据是存储在MySql数据库中,严格按照项目结构图和多个说明文档实现,而且是合作完成的,很庆幸能有一个好的搭档,做起事来能够达到事半功倍的效果。
| 虽然过程也会有许些坎坷,但是在历经几天的努力之后,还是有收获到不少的成果。采用了SQL数据库的方式,能够更加高效的运行整个程序,就让这个项目暂时结束博主在后端的学习 ! |
回眸只在一瞬间
关于文档的那些事
这次项目和以往项目不同的是这次在写项目代码之前,写了四个文档,对整个项目做了规划,其中包括概要设计说明书、软件需求说明书、数据库设计说明书、以及接口设计说明书,这样的同时也规范了我们对于项目的操作,也让我们明白,一个项目不仅仅是简单的代码编写,同时还需要我们做很多的准备工作,比如一些需求分析,设计报告,还有可行性分析等等,都是值得我们思考的,这也是在完成这次项目时进步的一点。
关于格式的那些解
格式对于一个程序员来说也是很重要的,不仅仅是让自己一目了然,更重要的是让伙伴或者其他人能够看懂你的程序。比如我们应该注意什么呢?
首先我们应该注意命名(类名,包名,方法名,注释等),严格遵循Java命名规则。因为我们知道这次项目为项目二的重构版,具体可以参考博主之前的博客,所以关于项目的基本功能可以不变,但是其设计结构需要改变
①、严格按照三层架构的方式去设计模块。(三层架构博客链接)

②、设计至少需要使用一种常用设计模式 (常用设计模式博客链接)
③、项目为团队合作,需要使用Git版本控制工具,协同开发。(Git博客链接)
④、将项目二的所有存储在文件里的数据,全部放在数据库中,通过JDBC完成CRUD操作,需要个人设计好数据库表。(数据库操作博客链接)
关于需求的那些法
长期以来,人们使用传统的人工方式管理图书馆的日常业务,其操作流程比较烦琐。在借书时,读者首先将要借的书和借阅证交给工作人员,然后工作人员将每本书的信息卡片和读者的借阅证放在一个小格栏里,最后在借阅证和每本书贴的借阅条上填写借阅信息。在还书时,读者首先将要还的书交给工作人员,工作人员根据图书信息找到相应的书卡和借阅证,并填好相应的还书信息。太过于繁琐了!所以,我们需求设计一个图书管理系统来方便学生的借书和图书馆管理书籍。
- 本系统在项目3基础上进行重构操作,调整了基本流程,增加了管理员和操作员不同角色的操作图书馆的功能。
- 本系统首先需要进行登录或者注册,根据不同身份操作不同的功能。
- 管理员主要负责对操作员的基本信息管理和相关逾期金额的设定和查看。
- 操作员主要负责对读者的信息进行管理和相关图书进行管理。
- 本项目还会利于数据库进行数据的读取和存储。
光景更替这般道
结构基本设计

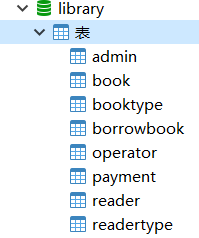
通过上面的图我们可以了解到整个图书馆管理系统的大体设计,主要分为:
(1) 登录模块:管理员与操作员登录,注册功能,还有登录日志和修改密码
(2) 管理员模块:四大基本功能(见下)
(3) 操作员模块:读者信息管理、图书信息管理、图书借阅管理、基础信息维护。
操作员板块

处理流程分析

以管理员为例,首先需要登录,有一个验证过程,然后里面四大基本功能:员工工作日志记录(记录了每个操作员的登录时间和各种操作信息,日志可通过I/O流放在相对应的文件里),图书借阅金额设定,对操作员信息进行管理(增删改查),图书逾期罚金总账单查询(该账单记录了所有预期的图书的逾期金额明细和最后图书馆所有书的逾期总金额数)。
除却巫山不是云
迷雾拨开亮点
对于代码部分其实没有什么需要具体讲解的,可以参考之前图书管理系统项目,这里主要是讲一下的是关于数据库的连接一个很适用的JdbcTemplate方法,相信JDBC已经能够满足大部分用户最基本的需求,但是在使用JDBC时,必须自己来管理数据库资源如:获取PreparedStatement,设置SQL语句参数,关闭连接等步骤。
在这里JdbcTemplate是Spring对JDBC的封装,目的是使JDBC更加易于使用。JdbcTemplate是Spring的一部分。JdbcTemplate处理了资源的建立和释放。他帮助我们避免一些常见的错误,比如忘了总要关闭连接。他运行核心的JDBC工作流,如Statement的建立和执行,而我们只需要提供SQL语句和提取结果。
JdbcTemplate使用步骤:
-
准备DruidDataSource连接池
-
导入依赖的jar包
spring-beans-4.1.2.RELEASE.jar
spring-core-4.1.2.RELEASE.jar
spring-jdbc-4.1.2.RELEASE.jar
spring-tx-4.1.2.RELEASE.jar
com.springsource.org.apache.commons.logging-1.1.1.jar -
创建JdbcTemplate对象,传入Druid连接池
-
调用update、queryXxx等方法
JdbcTemplate template=new JdbcTemplate(JDBCUtils.getDataSoure());
update():执行DML语句,增,删,改
queryForMap():查询结果将结果集封装为map集合
注意:这个方法查询的结果集长度只能1,将列名作为key,将值作为value将这条记录封装进Map集合
queryForList():查询结果将结果集封装为list集合
注意:将每一条记录封装为一个Map集合,再将Map集合装载到List集合中
query():查询结果,将结果封装为JavaBean对象
注意:query的参数:RowMapper
一般使用BeanPropertyRowMapper实现类
queryForObject():查询结果,将结果封装为对象
附上真诚代码
其实对于本次项目在之前编写当中具有了一些经验,很多地方都是可以借鉴的难度差距不是很多,只是在一些细节处理上需要注意一下,难度最大的话,博主认为还是文档,以为代码是建立在文档当中,当你有了思路,那么写起来也是很快的,现在看来整体上还是不错的哈哈。冲冲冲!!
代码连接
提取码:yy52
