
国庆假期已经过半,你是出去浪了?还是在家里宅着呢?那你知道你的朋友去哪浪了吗?本文我们通过爬取去哪网售票数据(piao.qunar.com)来简单分析一下。
数据爬取
首选,我们打开网址:piao.qunar.com,在搜索框输入一个省级行政区划进行搜索,以浙江为例,如图所示:
再将页面向下拉,F12 打开开发者工具,点击下一页看一下 URL,如图所示:
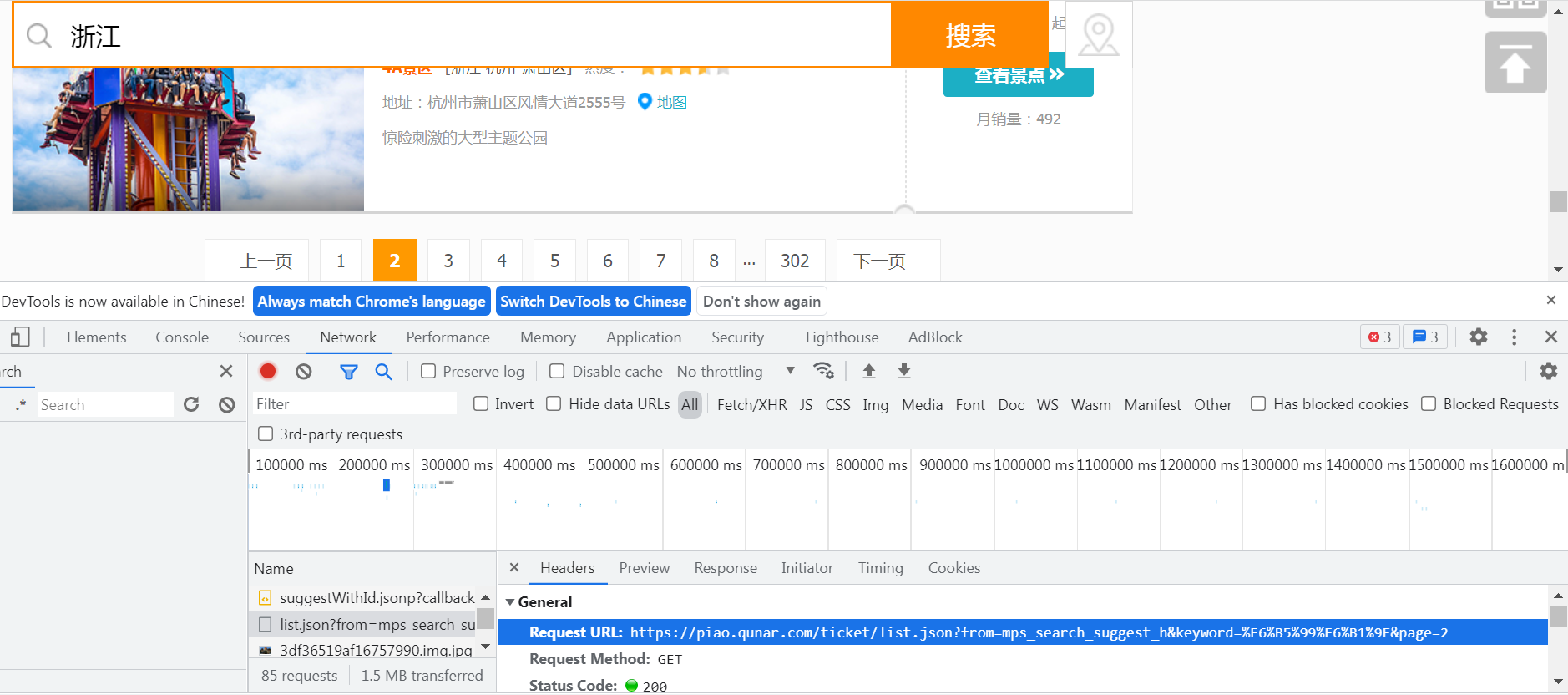
通过观察 URL 我们可以看出 keyword 和 page 是动态的,一个是输入条件值,另一个是页码值,当我们需要翻页爬取时可以进行动态赋值,再将开发者工具切到 Response,我们可以发现返回的数据是 JSON 格式的,如图所示:

这里我们以 34 个省级行政区划作为 keyword 进行分页爬取,主要爬取代码实现如下:
def get_city_data(cities, pages):
cityNames = []
sightNames = []
stars = []
scores = []
qunarPrices = []
saleCounts = []
districtses = []
points = []
intros = []
frees = []
addresses = []
for city in cities:
for page in range(1, pages+1):
try:
print(f'正在爬取{city}第{page}页数据...')
time.sleep(random.uniform(1.5, 2.5))
url = f'https://piao.qunar.com/ticket/list.json?from=mpl_search_suggest&keyword={city}&page={page}'
print('url:', url)
result = requests.get(url, headers=headers, timeout=(2.5, 5.5))
status = result.status_code
if(status == 200):
# 每页数据
response_info = json.loads(result.text)
print('数据:', response_info)
sight_list = response_info['data']['sightList']
for sight in sight_list:
sightName = sight['sightName'] # 名称
star = sight.get('star', None) # 星级
score = sight.get('score', 0) # 评分
qunarPrice = sight.get('qunarPrice', 0) # 价格
saleCount = sight.get('saleCount', 0) # 销量
districts = sight.get('districts', None) # 行政区划
point = sight.get('point', None) # 坐标
intro = sight.get('intro', None) # 简介
free = sight.get('free', True) # 是否免费
address = sight.get('address', None) # 地址
cityNames.append(city)
sightNames.append(sightName)
stars.append(star)
scores.append(score)
qunarPrices.append(qunarPrice)
saleCounts.append(saleCount)
districtses.append(districts)
points.append(point)
intros.append(intro)
frees.append(free)
addresses.append(address)
except:
continue
city_dic = {'cityName': cityNames, 'sightName': sightNames, 'star': stars,
'score': scores, 'qunarPrice': qunarPrices, 'saleCount': saleCounts,
'districts': districtses, 'point': points, 'intro': intros,
'free': frees, 'address': addresses}
city_df = pd.DataFrame(city_dic)
city_df.to_csv('cities.csv', index=False)
数据分析
现在数据有了,我们再来简单分析一下。
位置分布
首选,我们来看一下景区的位置分布情况。
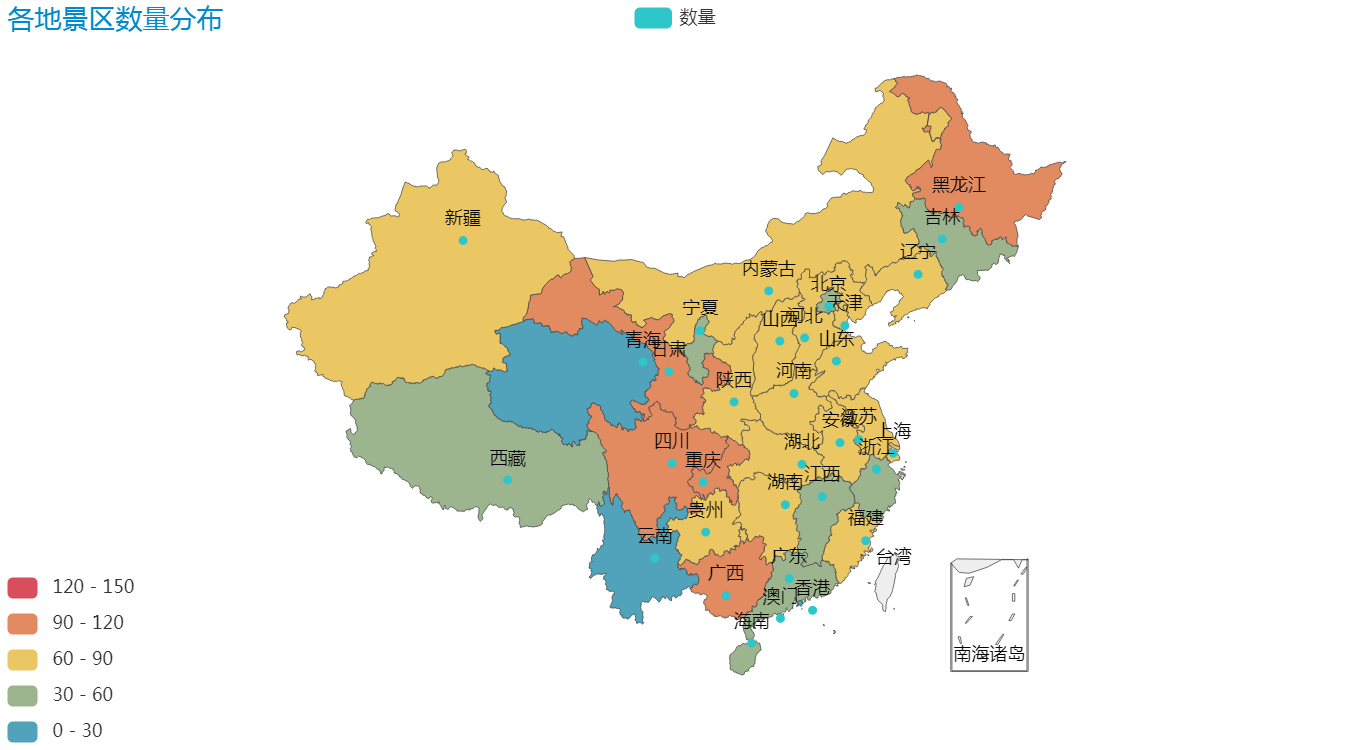
先看一下景区的整体分布情况,主要代码实现如下:
for city in df[(df.iloc[:, 5] > 0)].iloc[:, 0]:
if city != "":
cities.append(city)
data = Counter(cities).most_common(100)
gx = []
gy = []
for c in data:
gx.append(c[0])
gy.append(c[1])
(
Map(init_opts=opts.InitOpts(theme=ThemeType.MACARONS, height="500px"))
.add('数量', [list(z) for z in zip(gx, gy)], 'china')
.set_global_opts(
title_opts=opts.TitleOpts(title='各地景区数量分布'),
visualmap_opts=opts.VisualMapOpts(max_=150, is_piecewise=True),
)
).render_notebook()
看一下效果:
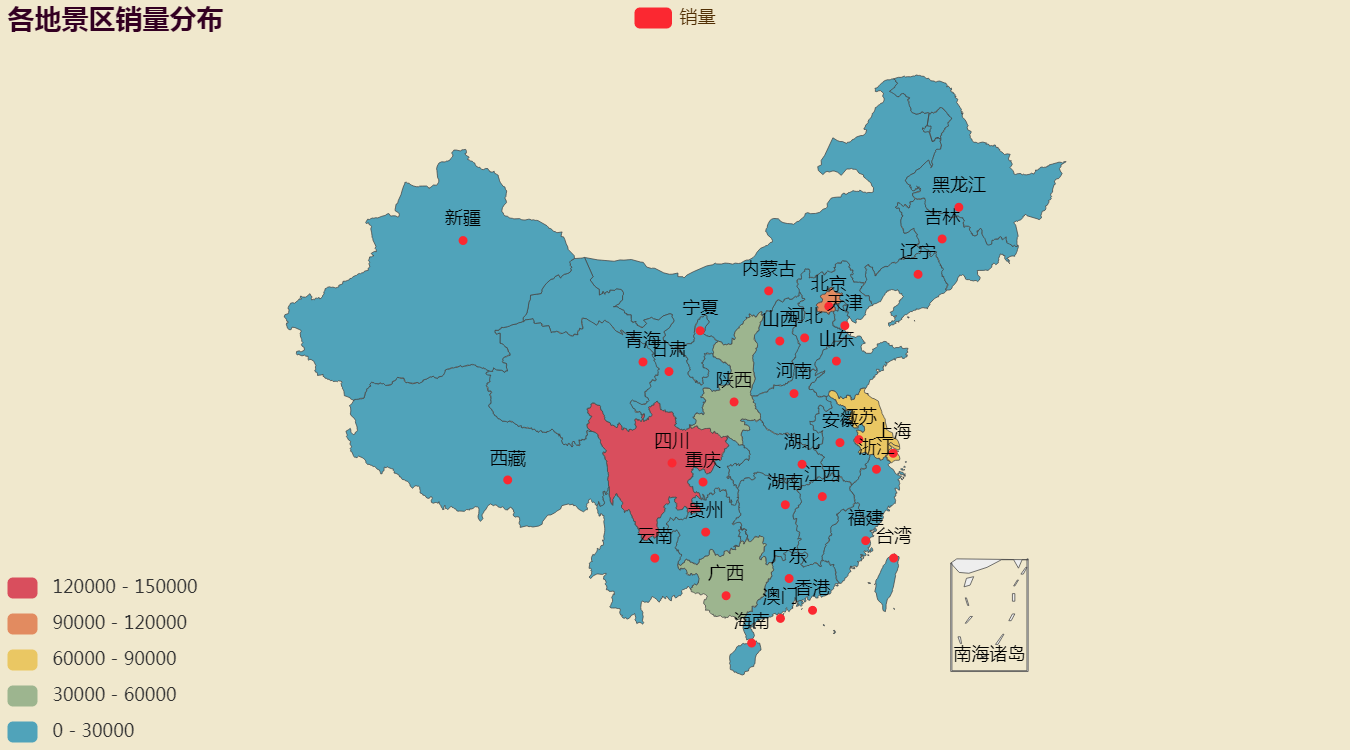
再看一下各地景区的销量情况,主要代码实现如下:
df_item = df[['cityName','saleCount']]
df_sum = df_item.groupby('cityName').sum()
(
Map(init_opts=opts.InitOpts(theme=ThemeType.ROMANTIC, height="500px"))
.add('销量', [list(z) for z in zip(df_sum.index.values.tolist(), df_sum.values.tolist())], 'china')
.set_global_opts(
title_opts=opts.TitleOpts(title='各地景区销量分布'),
visualmap_opts=opts.VisualMapOpts(max_=150000, is_piecewise=True)
)
).render_notebook()
看一下效果:
最热景区
我们接着看 TOP10 热门景区有哪些?它们的价格又是多少呢?主要代码实现如下:
sort_sale = df.sort_values(by='saleCount', ascending=True)
(
Bar(init_opts=opts.InitOpts(theme=ThemeType.MACARONS, width='125%'))
.add_xaxis(list(sort_sale['sightName'])[-10:])
.add_yaxis('销量', sort_sale['saleCount'].values.tolist()[-10:])
.add_yaxis('价格', sort_sale['qunarPrice'].values.tolist()[-10:])
.reversal_axis()
.set_global_opts(
title_opts=opts.TitleOpts(title='最热景区TOP10'),
yaxis_opts=opts.AxisOpts(name='名称', axislabel_opts=opts.LabelOpts(rotate=-30)),
xaxis_opts=opts.AxisOpts(name='销量/价格'),
)
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
).render_notebook()
看一下效果:
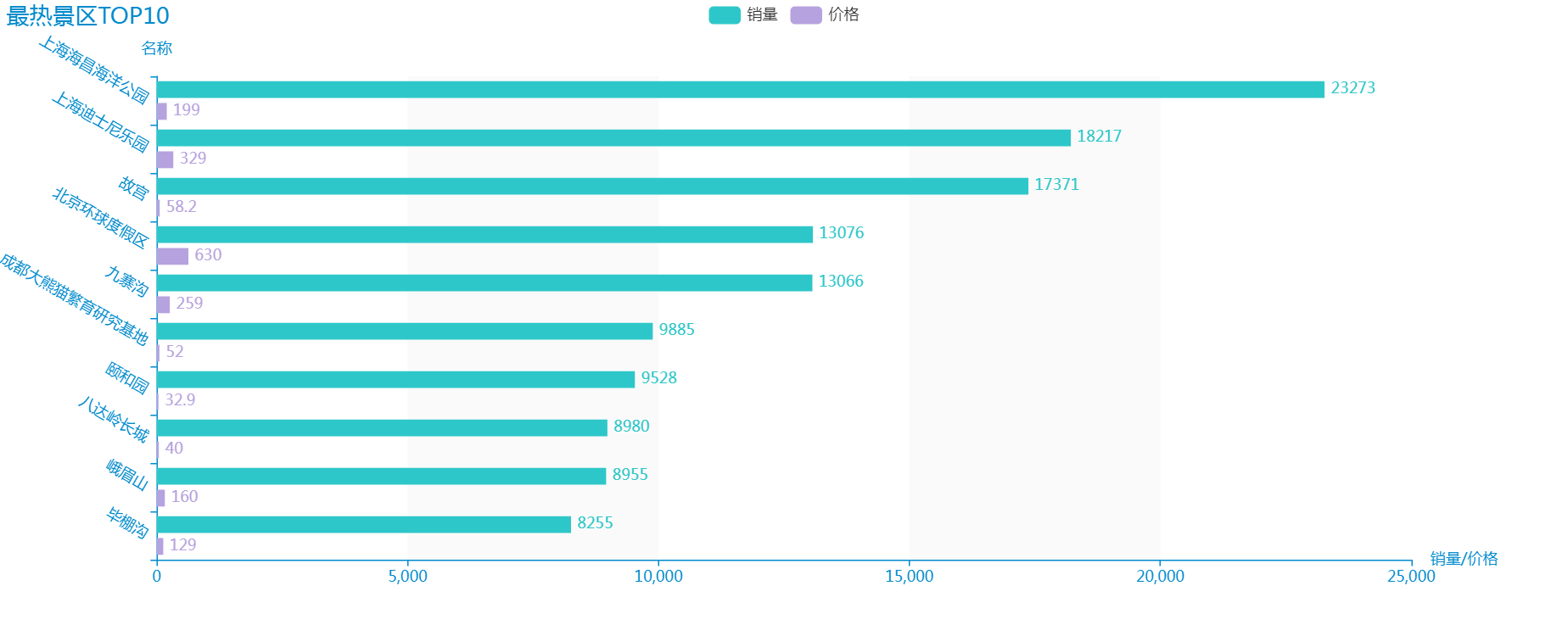
从图中我们可以看出 TOP10 热门景区的价格大多数都在 500 以内,算是比较亲民了。如果你的朋友喜欢热闹,他(她)可能去了热门景区。
再接着看热门景区的介绍情况,这里我们选取 T100 数据,通过词云来看一下。主要实现代码如下:
sort_sale = df.sort_values(by='saleCount', ascending=True)
stylecloud.gen_stylecloud(text=cts_str, max_words=100,
collocations=False,
font_path="SIMLI.TTF",
icon_name="fab fa-firefox",
size=800,
output_name="hot.png")
看一下效果:

最豪景区
我们再看一下票价 TOP10 景区有哪些?它们的销量怎么样呢?主要代码实现如下:
sort_price = df.sort_values(by='qunarPrice', ascending=True)
(
Bar(init_opts=opts.InitOpts(theme=ThemeType.ROMA))
.add_xaxis(list(sort_price['sightName'])[-10:])
.add_yaxis('价格', sort_price['qunarPrice'].values.tolist()[-10:])
.add_yaxis('销量', sort_price['saleCount'].values.tolist()[-10:])
.reversal_axis()
.set_global_opts(
title_opts=opts.TitleOpts(title='最豪景区TOP10'),
yaxis_opts=opts.AxisOpts(name='名称'),
xaxis_opts=opts.AxisOpts(name='价格/销量'),
)
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
).render_notebook()
看一下效果:
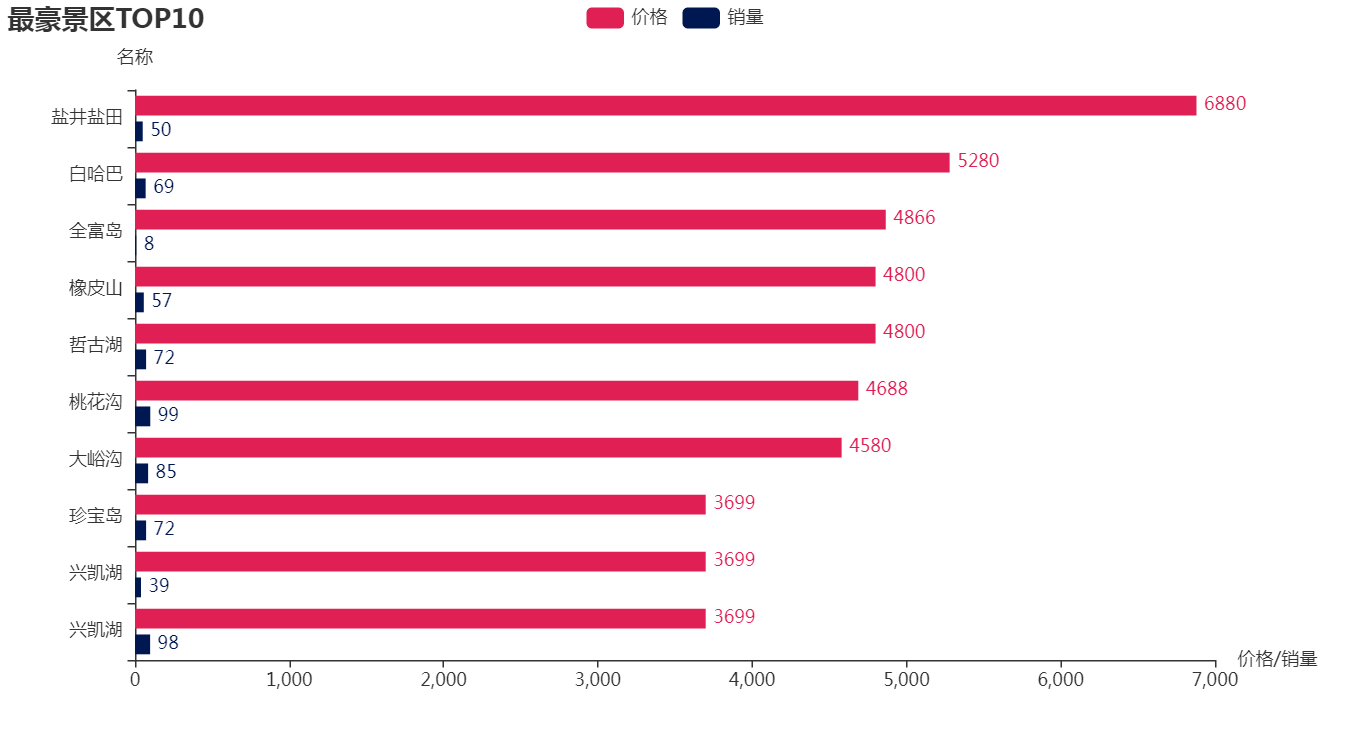
如果你的朋友是一个热爱旅游的土豪,他(她)很有可能去了土豪景区了。
再接着看一下土豪景区的介绍情况,这里我们还是选取 T100 数据,通过词云来看一下。
主要代码实现如下:
sort_price = df.sort_values(by='qunarPrice', ascending=True)
stylecloud.gen_stylecloud(text=cts_str, max_words=100,
collocations=False,
font_path="SIMLI.TTF",
icon_name="fas fa-yen-sign",#最豪
size=800,
output_name="money.png")
看一下效果:

景区星级
我们再来看一下各省级行政区划的 5A 级景区数量情况,主要代码实现如下:
df_sum = df[df['star']=='5A'].groupby('cityName').count()['star']
(
Bar(init_opts=opts.InitOpts(theme=ThemeType.MACARONS))
.add_xaxis(df_sum.index.values.tolist())
.add_yaxis('数量', df_sum.values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title='各地5A景区数量'),
datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(type_='inside')],
)
).render_notebook()
看一下效果:
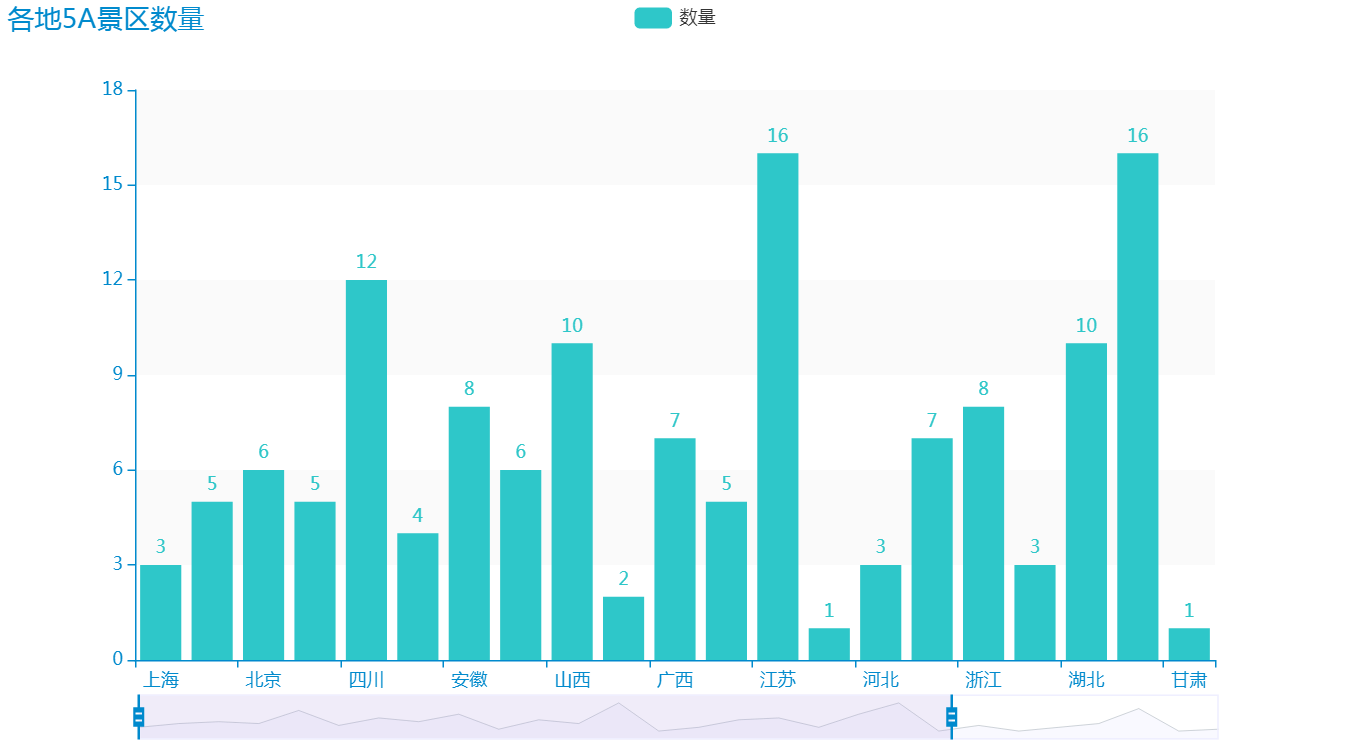
如果你的朋友热爱旅游且对 5A 级景区情有独钟,他(她)可能去了 5A 景区的城市了。
最后,我们看一下 T200 热门景区的星级比例情况是怎样的?主要代码实现如下:
sort_data = df.sort_values(by=['saleCount'], ascending=True)
rates = list(sort_data['star'])[-200:]
gx = ["3A", "4A", "5A"]
gy = [
rates.count("3A"),
rates.count("4A"),
rates.count("5A")
]
(
Pie(init_opts=opts.InitOpts(theme=ThemeType.MACARONS))
.add("", list(zip(gx, gy)), radius=["40%", "70%"])
.set_global_opts(title_opts=opts.TitleOpts(title="销量TOP200景区星级比例", pos_left = "left"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%", font_size=12))
).render_notebook()
看一下效果:
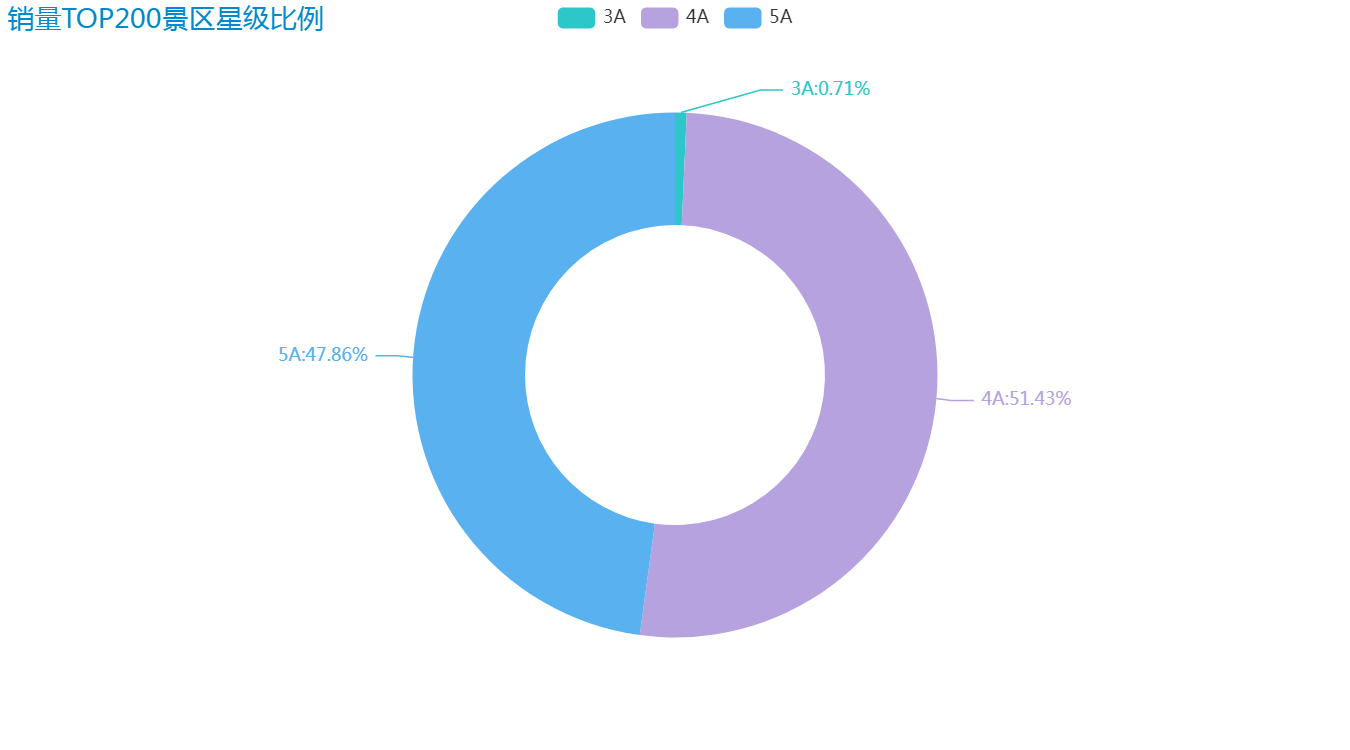
从图中我们可以看出 90% 以上的景区均为 4/5A 级。
好了,本文就到这里了,文中我们对去哪网售票数据中的几个指标进行了简单的分析,可以做个简单的参考,当然了,如果你感兴趣的话,还可以继续对其他指标进行分析。
源码在公众号Python小二后台回复qunar获取。