OK,上一章我们已经配置好爬虫所需的环境,现在就可以大展身手了!

一、获取图片网址
首先打开pythonIDLE输入:
from selenium import webdriver
driver = webdriver.Chrome()#用selenium库打开谷歌浏览器
#或driver = webdriver.Chrome(executable_path=r'C:/Users/dell/anaconda3/chromedriver.exe')
#博主自己的Chromewebdriver就下在C:\Users\dell\anaconda3\,如果直接复制记得把反斜杠改为斜杠(如果有报错看一下注释和上一章的注意事项,多半是版本问题)
如无意外浏览器成功打开:

(打开之后会看见上面有一行“浏览器正受到自动化软件控制,问题不大,下一章我们会说怎么去除)
开始前复习一下上一章的网页基本知识,下面按 找节点-->找要素-->得到要素的值
- 节点的名称有的叫div,有的叫a,有的叫img。
- 我们所需的要素也有一个名称,有的叫class,有的叫id,有的叫src。
- 这些节点里面的要素有一个值(比如class=“”里面的东西),网页上所有的元素,都存放在这一个个值中。通过这些要素的值,我们可以寻找到特定的节点;也可以根据值的名称,在节点里获取这个值
- 我们所需的图片地址,一般就是img节点的src要素的值
再看一下要用的函数
- find_elements类——根据关键词(节点名称或者节点内要素的值)返回一个数组,其中每个元素的类型是网络元素
- find_element类——根据关键词返回一个网络元素
- get_attribute——根据要素的名称返回要素的值,类型是字符串或数字
接下来,我们写程序的大思路就是 找图片所在节点-->找图片地址所在要素-->得到要素的值
而实现的方式就是用find_element(s)类函数找节点,用get_attribute函数找要素的值
01找图片所在节点
也就是,我们要定位到img节点
以花瓣https://huaban.com/discovery/travel_places/为例
driver.get('https://huaban.com/discovery/travel_places/')
这时点F12,打开开发者工具,找节点思路如下:

1.具体分析网络元素
- 首先对一个图片右键检查,看看想要的图片地址在哪里——发现图片地址就在img节点里面src元素的值里
- 然后看img节点是否包含在一个有特征要素值的节点中——找到了img节点包含在a节点里面,这个a节点有一个要素class 叫做'img x layer-view loaded'
注意:
- 要找包含img节点的节点(上级节点),同级别节点(缩进相同)无效
- 所谓特征要素值指的是,通过它就可以找到所有包含img节点的上级节点
2.验证特征要素值是否OK
在打开开发者工具的情况下,按Ctrl+F,找class叫img x layer-view loaded的节点

发现的确就找到了所有img节点的上级节点,所以这个特征要素值可行
3.代码实现
方法一分步找(在这个例子中不行):
target = driver.find_elements_by_class_name('img x layer-view loaded')
t0 = target[0]
img_list0 = t0.find_element_by_tag_name('img')#fine_element需要对单个元素操作
#在IDLE中我们先单个取,运行正常后再复制到pycharm写成循环形式
#dir(target)
#dir(t0)
#len(img_list)注意:
- 这个找法会报错(狗头)——因为用find_element(s)_by_class_name的名称中不能有空格
- find_element类函数不能对数组使用,只能对元素使用(所以例子中先取了一个元素)
- 可以用dir()函数查看一个变量包含了哪些类函数(如dir(t0))
- 可以用len()函数查看一个数组的长度,检验是否获取到了所需的元素(如len(target))
方法二xpath找:
img_list = driver.find_elements_by_xpath('//*[@class="img x layer-view loaded"]/img')
#或img_list = driver.find_elements_by_xpath('//a[@class="img x layer-view loaded"]/img')
#但有时候指明节点名容易报错,博主个人更喜欢通配符法用xpath语法在selenium库中找元素是很主流的,简单的介绍一下:
- 开头:相对路径查找——//;绝对路径查找——/(比如上面的例子,就是相对路径开始,绝对路径麻烦一般不用
- 节点中:根据要素的值找——*[@class=""];*[@id=""](上面例子用了class要素)
- 节点间:直接子节点——/;间接子节点——//(该例子中img节点是a节点的直接子节点)
感兴趣的同学可以看看这篇文章:
爬虫Xpath语法详解_T型人小付的博客-CSDN博客
另外通过开发者工具,我们也可以把某个元素的xpath找出来
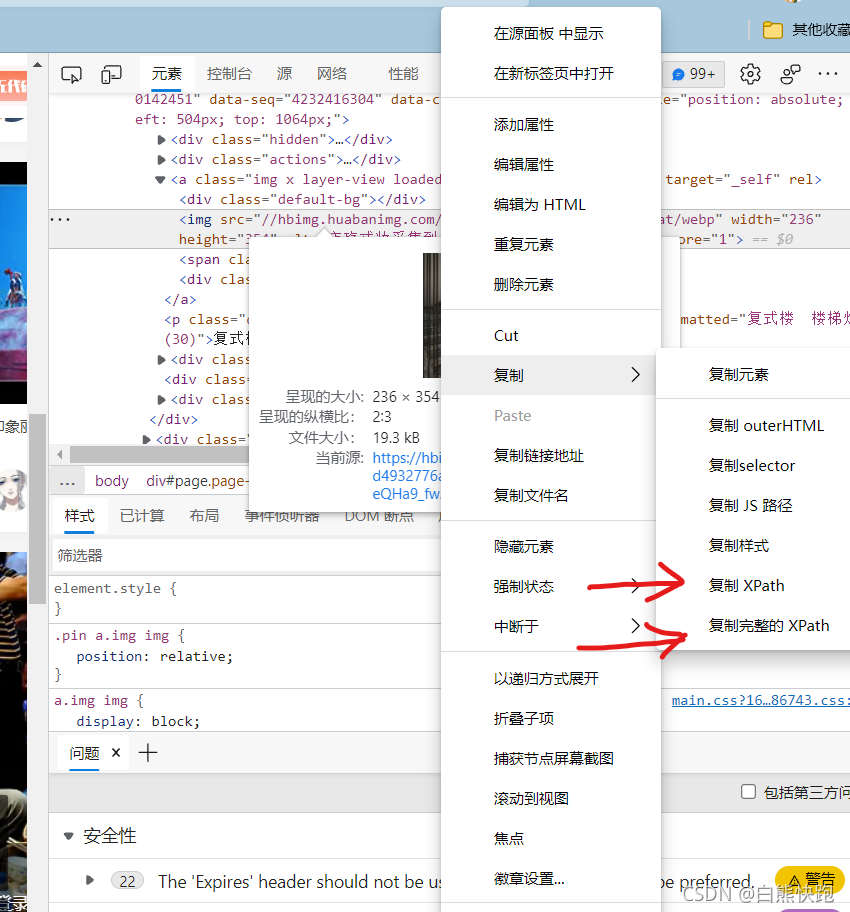
注意:
- xpath语法和selenium库中的xpath语法不尽相同,有传闻说不要超过两个节点,总之太复杂的时候就分步取,还是这个例子:
target = driver.find_elements_by_xpath('//*[@class="img x layer-view loaded"]')
t0 = target[0]
img_list0 = t0.find_element_by_tag_name('img')2.在IDLE调试正确才写入pycharm,因为xpath报错会很大一堆,极影响心态
方法三css找:
css也要求节点名无空格,因此这里不推荐
后面第四章我们讲到爬取商品信息时会较多用到css查找
4.下面分别再用这三种方法,看另一个实战案例

爬取某二次元图片网站https://pixivel.moe/rank/获取图片所在节点
观察到图像都在一个class名为one-img的div节点中(要使用Ctrl+F检验)
方法一分步查找
img_list = driver.find_elements_by_class_name('one-img') #这个案例一个要素名就搞定了方法二xpath查找
img_list = driver.find_elements_by_xpath('//*[@class="card the-img shadow--hover waterfall-item"]/div[2]') #或img_list = driver.find_elements_by_class_name('one-img')#这个更直接方法三css查找
img_list = driver.find_elements_by_css_selector('one-img')
02获取节点里要素的值(即图片网址)
无论用哪种方法上一步我们已经得到了一个由所有图片所在节点组成的数组,现在来取图片网址
img_list0 = img_list[0]
img_path0 = img_list0.get_attribute('src')
#dir(img_path0)这个img_path0就是我们成功获得的第一个图片网址!
然后我们写成循环遍历一下即可
img_path = []
for img in img_list:
path = img.get_attribute('src')
img_path.append(path)现在得到的img_path数组里面就是所有图片的网址!
二、下载图片
01修正网址
其实,上一步我们说已经得到所有图片网站,是不严谨的
首先有的网站爬取下来的网址不含http://或https://
其次是网站里面多半有防爬和略缩图机制存在,有时候爬取到的地址、在原页面中查看的图片地址和点入图片查看到的地址都是不同的!!!(离谱)
所以这就是为什么有的同学按教程爬到了图片,非常高兴,打开一看却全是小图
因此在写进循环前,我建议还要print一下图片网址


以这张图片为例
[1]爬取到的https://hbimg.huabanimg.com/f4222449cb11ee162a75eb366572cfc80738e1171b47d-exEtQp_fw236/format/webp
[2]原网页的(图2-1)https://hbimg.huabanimg.com/f4222449cb11ee162a75eb366572cfc80738e1171b47d-exEtQp_fw236/format/webp
[3]原图的(图2-2)https://hbimg.huabanimg.com/f4222449cb11ee162a75eb366572cfc80738e1171b47d-exEtQp_fw658/format/webp
可以发现我们爬取到的网址和原图有一个数字的差别,需要用字符串操作修正
这里用到的是字符串的截取和相加,要用时在CSDN查找“python字符串操作”翻阅即可
img_list0 = img_list0[0:-12] + 'fw658/format/webp'写进循环里面
img_path = []
for img in img_list:
path = img.get_attribute('src')
path = path[0:-12] + 'fw658/format/webp'
img_path.append(path)现在得到的img_path数组就是高清原图数组啦!
02由网址下载图片
首先要在程序最开头import两个库(requests是外部库,os是内部库)
然后按照这个模板写代码就OK
import requests
import os
img_dir = os.path.join(os.curdir, 'travel_images')#traval_images是文件夹名称
'''创建文件夹'''
if not os.path.isdir(img_dir):
os.mkdir(img_dir)
'''下载图片'''
for path in img_path:
img_name = 'flower' + path.split('/')[-3] + '.jpg'#图片名称
filepath = os.path.join(img_dir, img_name)
resp = requests.get(img)
with open(filepath, 'wb') as f:
for chunk in resp.iter_content(1024):#限速写入图片
f.write(chunk)(注意:如果同学们心急在pycharm上运行,记得一定要在最顶端输入
# -*- coding:UTF-8 -*-
不要问问就是编码方式)
上一章是完整配置流程欢迎进去坐坐
(35条消息) 【小白+python+selenium库+图片爬取+反爬+资料】超详细新手实现(01)webdriver环境配置+新手基础知识_白熊快跑的博客-CSDN博客![]() https://blog.csdn.net/qq_53021454/article/details/120538464?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_53021454/article/details/120538464?spm=1001.2014.3001.5501
下一章会继续仔细讲程序在pycharm上运行,包括防爬+翻页+完整代码,喜欢的朋友请追更~
过路的小伙伴觉得有用的话请帮我多多分享点赞!!!这对小透明的我很重要,感谢!
我们下章见~