Explain
使用 EXPLAIN关键字可以模拟优化器执行 SQL 查询语句,从而知道 MySQL 是如何处理 SQL 语句的。分析查询语句或是表结构的性能瓶颈。
用法:
Explain+SQL 语句
Explain 执行后返回的信息:

各字段解释
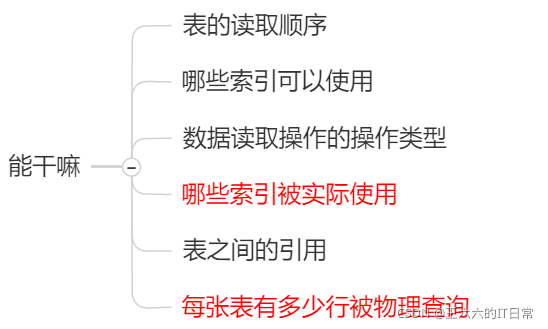
id(都是1是最好的) ★
select 查询的序列号,包含一组数字,表示查询中执行 select 子句或操作表的顺序。
CREATE DATABASE test1;
USE test1;
CREATE TABLE t1(
id INT(10) AUTO_INCREMENT,
content VARCHAR(100) NULL ,
PRIMARY KEY (id)
);
CREATE TABLE t2(
id INT(10) AUTO_INCREMENT,
content VARCHAR(100) NULL ,
PRIMARY KEY (id)
);
CREATE TABLE t3(
id INT(10) AUTO_INCREMENT,
content VARCHAR(100) NULL ,
PRIMARY KEY (id)
);
CREATE TABLE t4(
id INT(10) AUTO_INCREMENT,
content VARCHAR(100) NULL ,
PRIMARY KEY (id)
);
INSERT INTO t1(content) VALUES(CONCAT('t1_',FLOOR(1+RAND()*1000)));
INSERT INTO t2(content) VALUES(CONCAT('t2_',FLOOR(1+RAND()*1000)));
INSERT INTO t3(content) VALUES(CONCAT('t3_',FLOOR(1+RAND()*1000)));
INSERT INTO t4(content) VALUES(CONCAT('t4_',FLOOR(1+RAND()*1000)));
👇
①id 相同,执行顺序由上至下
EXPLAIN SELECT * FROM t1,t2,t3
WHERE t1.`id`=t2.`id`
AND t2.`id`=t3.`id`;

②id 不同,id 不同,如果是子查询,id 的序号会递增,id 值越大优先级越高,越先被执行
EXPLAIN SELECT t1.`id` FROM t1 WHERE t1.`id` IN(
SELECT t2.`id` FROM t2 WHERE t2.id IN(
SELECT t3.id FROM t3 WHERE t3.`content`='')
);

③有相同也有不同
EXPLAIN SELECT * FROM t2,(SELECT * FROM t3 WHERE t3.`content`='') t31
WHERE t31.id = t2.id;
id 如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id 值越大,优先级越高,越先执行衍生 = DERIVED
关注点: id 号每个号码,表示一趟独立的查询。一个 sql 的查询趟数越少越好。
select_type
select_type 代表查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询。
| select_type 属性 | 含义 |
|---|---|
| SIMPLE | 简单的 select 查询,查询中不包含子查询或者UNION |
| PRIMARY | 查询中若包含任何复杂的子部分,最外层查询则被标记Primary |
| DERIVED | 在 FROM 列表中包含的子查询被标记为 DERIVED(衍生) MySQL 会递归执行这些子查询, 把结果放在临时表里 |
| SUBQUERY | 在SELECT或WHERE列表中包含了子查询 |
| DEPEDENT SUBQUERY | 依赖子查询,在SELECT或WHERE列表中包含了子查询,子查询基于外层 |
| UNCACHEABLE SUBQUERY | 无法使用缓存的子查询,当使用了@@来引用系统变量的时候,不会使用缓存。 |
| UNION | 若第二个SELECT出现在UNION之后,则被标记为UNION; 若UNION包含在FROM子句的子查询中,外层SELECT将被标记为:DERIVED |
| UNION RESULT | 从UNION表获取结果的SELECT |
type ★ (带颜色的预警)
type 是查询的访问类型。是较为重要的一个指标,结果值从最好到最坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index >All
一般来说,得保证查询至少达到 range 级别,最好能达到 ref。

key
实际使用的索引。如果为NULL,则没有使用索引。
key_len ★
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。 key_len 字段能够帮你检查是否充分的利用上了索引。
ken_len 越长,说明索引使用的越充分。
ref
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值。
rows ★ (1最好了)
rows 列显示 MySQL 认为它执行查询时必须检查的行数。越少越好!
Extra ★
包含不适合在其他列中显示但十分重要的额外信息
红色预警
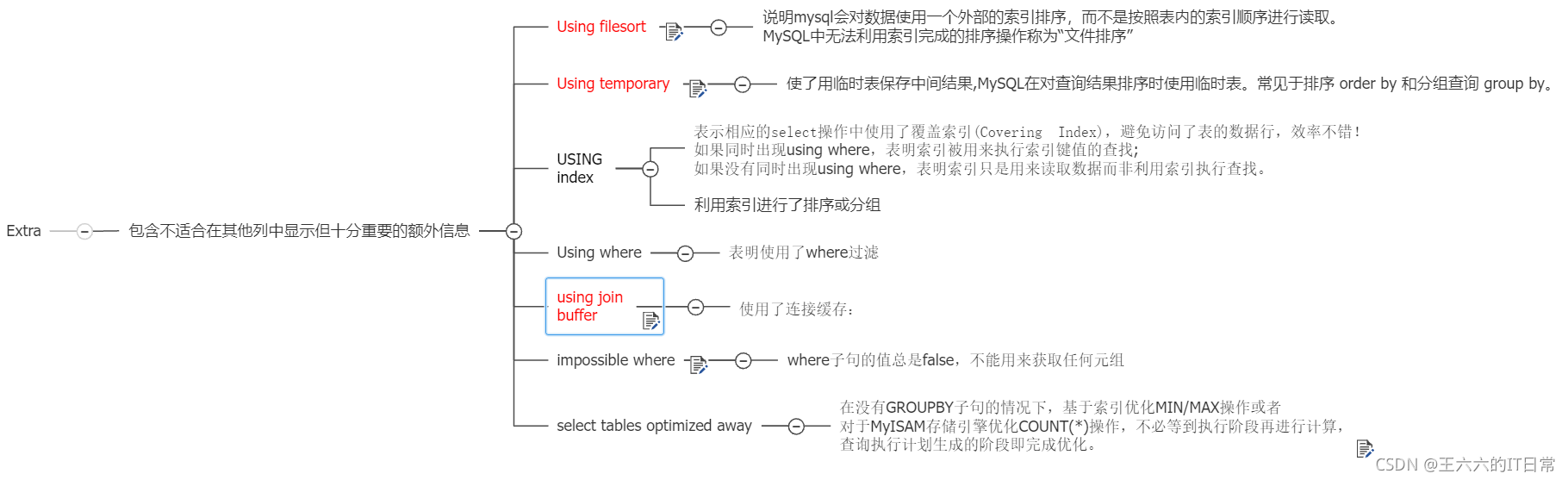
注意点:
group by 包含 order by;
如果group by用上索引,Using temporary和Using filesort都会消失
关联字段没用上索引:Using join buffer
出现impossible where说明SQL语句写错了
Using where 表明使用了 where 过滤,where后面的过滤条件用上了索引。