萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
用AI搞视频编解码器,现在路子有点“野”。
插帧、过拟合、语义感知、GAN……你想过这些“脑洞”或AI算法,也能被用到编解码器上面吗?
例如,原本的算法每帧压缩到16.4KB后,树林开始变得无比模糊:

但在用上GAN后,不仅画面更清晰,每帧图像还更小了,只需要14.5KB就能搞定!

又例如,用插帧的思路结合神经编解码器,能让最新压缩算法效果更好……
这一系列算法的思路,背后究竟是什么原理,用AI搞编解码器,潜力究竟有多大?
我们采访了高通工程技术副总裁、高通AI研究方向负责人侯纪磊博士,了解了高通一些AI编解码器中的算法细节和原理。
编解码器标准逐渐“内卷”
当然,在了解AI算法的原理之前,需要先了解视频到底是怎么压缩的。
如果不压缩,1秒30帧、8bit单通道色深的480p视频,每秒就要传输80+Mbps数据,想在网上实时看高清视频的话,几乎是不可能的事情。
目前,主要有色度子采样、帧内预测(空间冗余)和帧间预测(时间冗余)几个维度的压缩方法。
色度子采样,主要是基于我们眼睛对亮度比对颜色更敏感的原理,压缩图像的色彩数据,但视觉上仍然能保持与原图接近的效果。
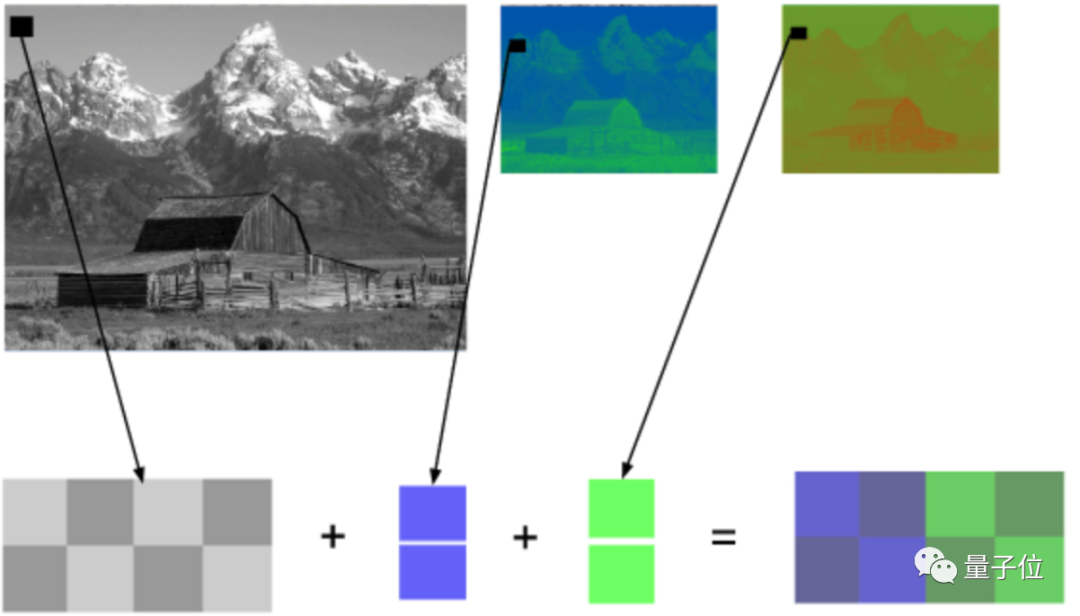
帧内预测,利用同一帧中的大片相同色块(下图地板等),预测图像内相邻像素的值,得出的结果比原始数据更容易压缩。

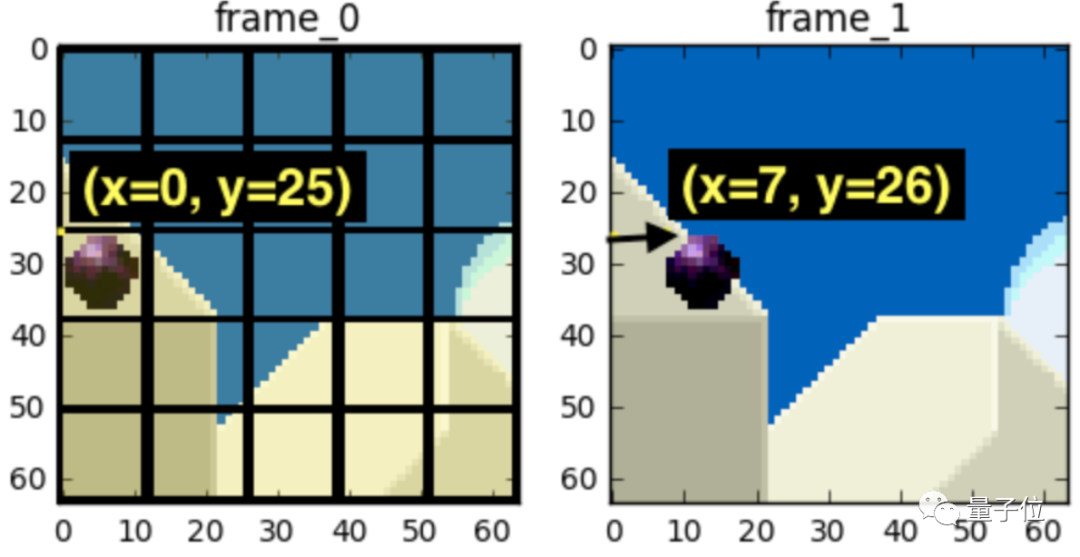
帧间预测,用来消除相邻帧之间大量重复数据(下图的背景)的方法。利用一种名叫运动补偿的方法,用运动向量(motion vector)和预测值计算两帧之间像素差:
这些视频压缩的方法,具体到视频编解码器上,又有不少压缩工作可以进行,包括分区、量化、熵编码等。
然而,据侯纪磊博士介绍,从H.265到H.266,压缩性能虽然提升了30%左右,但这是伴随着编码复杂度提高30倍、解码复杂度提高2倍达成的。
这意味着编解码器标准逐渐进入了一个“内卷”的状态,提升的压缩效果,本质上是用编解码器复杂度来交换的,并不算真正完成了创新。
因此,高通从已有压缩方法本身的原理、以及编解码器的构造入手,搞出了几种有意思的AI视频编解码方法。
3个方向提升压缩性能
具体来说,目前的AI研究包括帧间预测方法、降低解码复杂度和提高压缩质量三个方向。
“预判了B帧的预判”
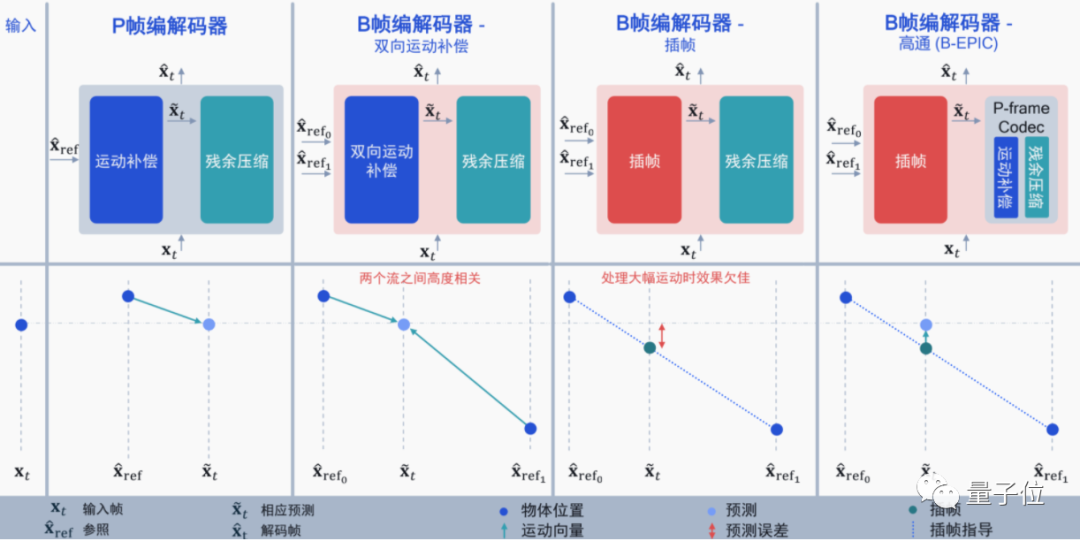
从帧间预测来看,高通针对B帧编解码提出了一种新思路,论文已经登上ICCV 2021。
I帧:帧内编码帧(intra picture)、P帧:前向预测编码帧(predictive-frame)、B帧:双向预测内插编码帧(bi-directional interpolated prediction frame)

目前的编解码大多集中在I帧(帧内预测)和P帧上,而B帧则是同时利用I帧和P帧的双向运动补偿来提升压缩的性能,在H.265中正式支持(H.264没有)。
虽然用上B帧后,视频压缩性能更好,但还是有两个问题:
一个是视频需要提前加载(必须提前编码后面的P帧,才能得到B帧);另一个是仍然会存在冗余,如果I帧和P帧高度相关,那么再用双向运动补偿就显得很浪费。
打个比方,如果从I帧→B帧→P帧,视频中只有一个球直线运动了一段距离,那么再用双向运动补偿的话,就会很浪费:

这种情况下,用插帧似乎更好,直接通过时间戳就能预测出物体运动的状态,编码计算量也更低。
但这又会出现新的问题:如果I帧和P帧之间有个非常大的突变,例如球突然在B帧弹起来了,这时候用插帧的效果就很差了(相当于直接忽略了B帧的弹跳)。
因此,高通选择将两者结合起来,将基于神经网络的P帧压缩和插帧补偿结合起来,利用AI预测插帧后需要进行的运动补偿:
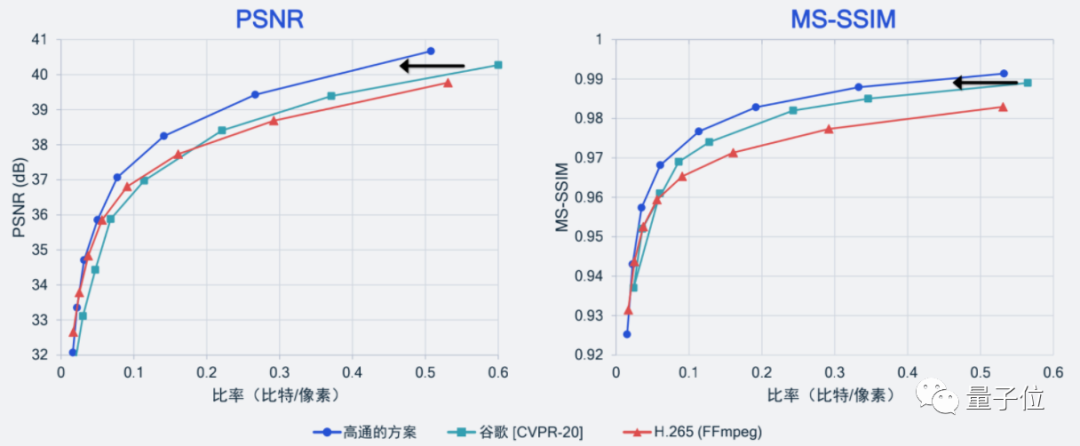
别说,效果还确实不错,比谷歌之前在CVPR 2020上保持的SOTA纪录更好,也要好于当前基于H.265标准实现开源编解码器的压缩性能。
除此之外,高通也尝试了一些其他的AI算法。
用“过拟合”降低解码复杂度
针对编解码器标准内卷的情况,高通也想到了用AI做自适应算法,来像“过拟合”一样根据视频比特流更新一个模型的权重增量,已经有相关论文登上ICLR 2021。
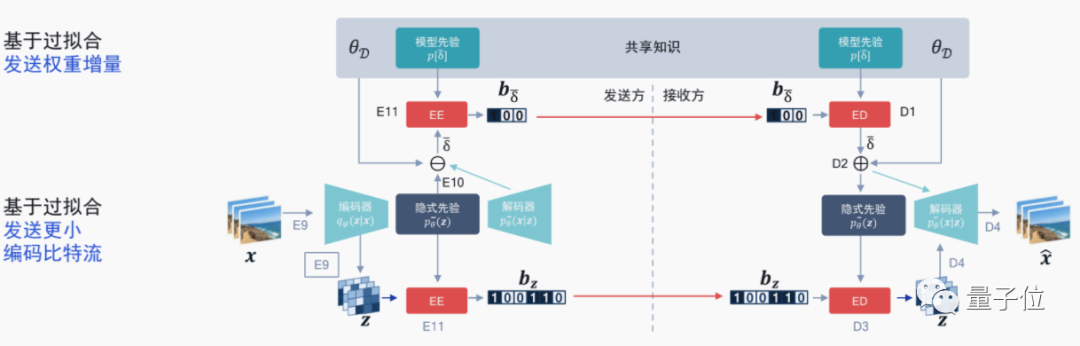
这种方法意味着针对单个模型进行“过拟合”,对比特流中的权重增量进行编码,再与原来的比特流进行一个比较。如果效果更好的话,就采用这种传输方式。
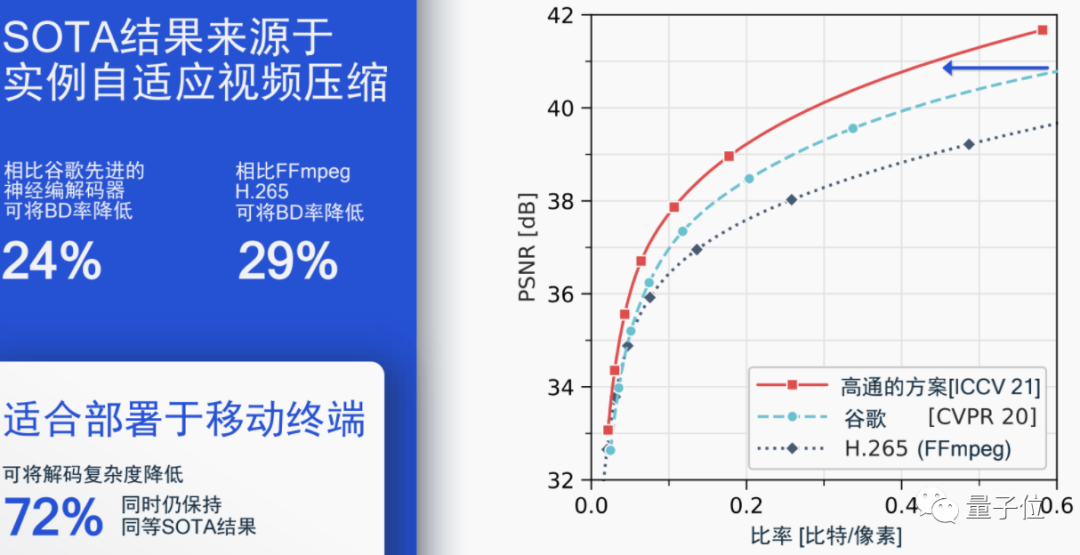
事实证明,在不降低压缩性能的情况下,这种方法能将解码复杂度降低72%,同时仍然保持之前B帧模型达到的SOTA结果。
当然,除了视频压缩性能以外,单帧图像被压缩的质量也需要考虑,毕竟视觉效果也是视频压缩追求的标准之一。
用语义感知和GAN提高压缩质量
用语义感知和GAN的思路就比较简单了。
语义感知就是让AI基于人的视觉来考虑,选出你在看视频时最关注的地方,并着重那部分的比特分配情况。
例如你在看网球比赛时,往往并不会关注比赛旁边的观众长什么样、风景如何,而是更关注球员本身的动作、击球方法等。
那么,就训练AI,将更多的比特放到目标人物身上就行,像这样:
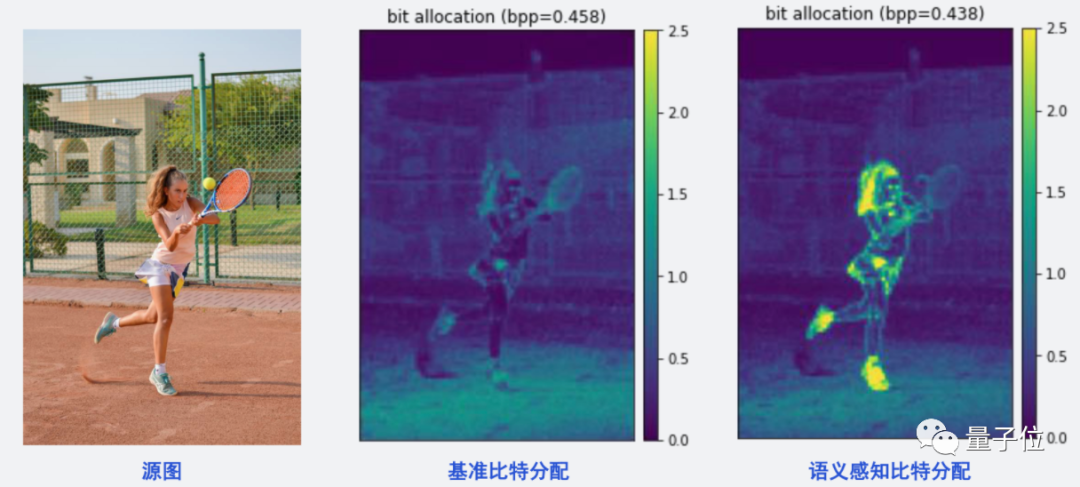
从结构上来讲也比较简单,也就是我们常见的语义分割Mask(掩膜):
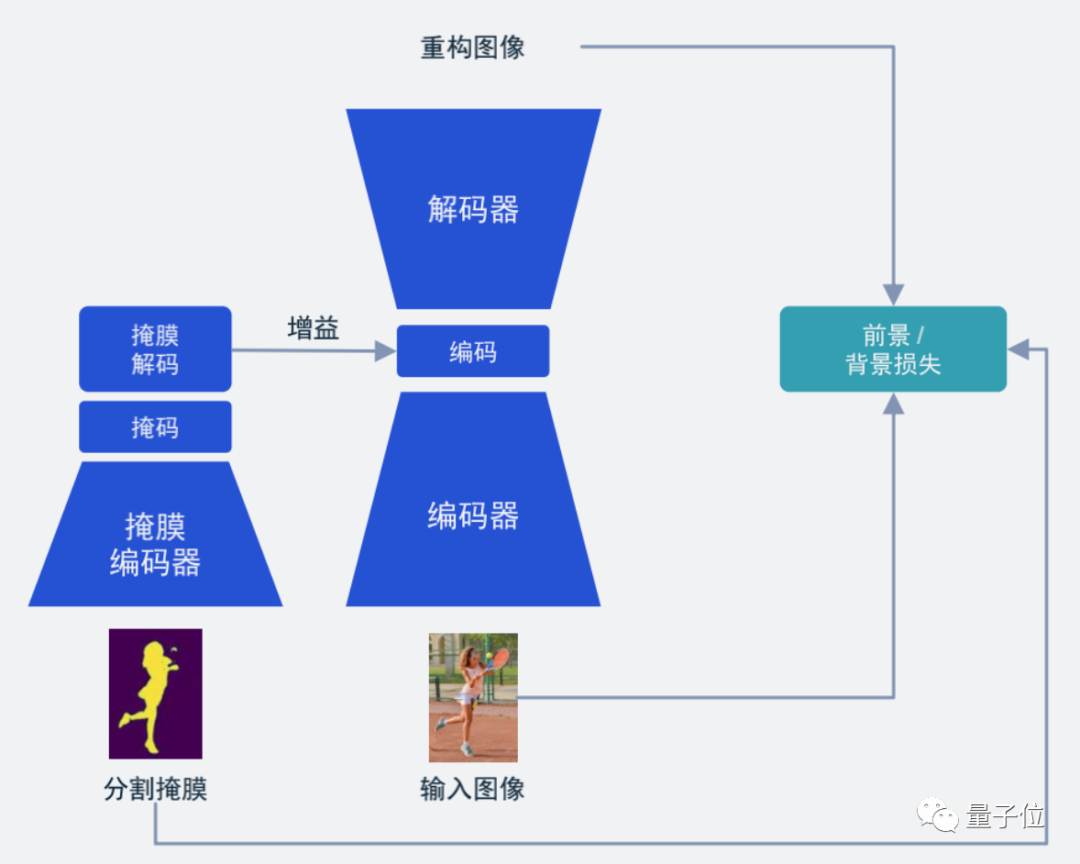
这种方法能很好地将受关注的局部区域帧质量提升,让我们有更好的观看效果,而不是在视频被压缩时,看到的整幅图像都是“打上马赛克”的样子。
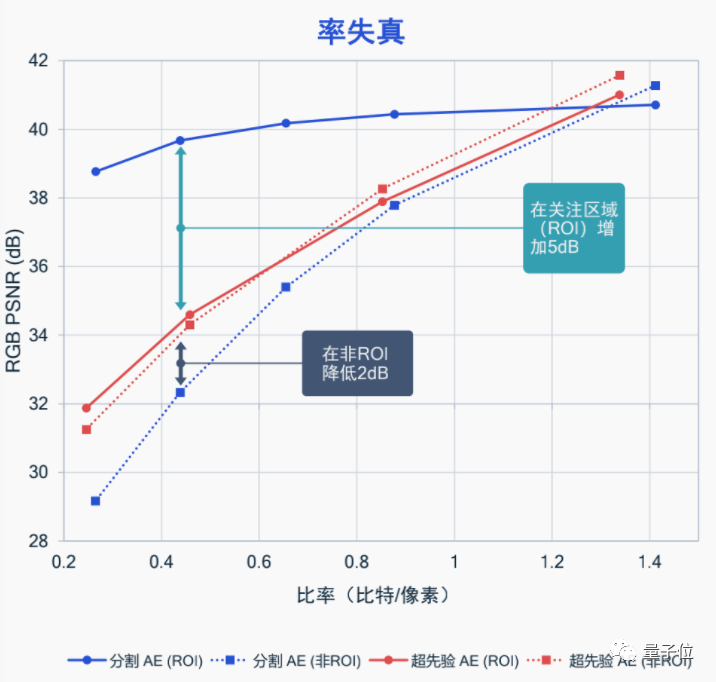
据高通表示,这种语义感知的图像压缩,目前已经在扩展到视频压缩上了,同样是关注局部的方法,效果也非常不错。
而基于GAN的方法,则更加致力于用更少的比特数生成视觉效果同样好的图像质量:

据高通表示,数据集来自CVPR中一个针对图像压缩的Workshop CLIC,提供了大约1600张的高清图片,利用自研的模型,能在上面训练出很好的效果:
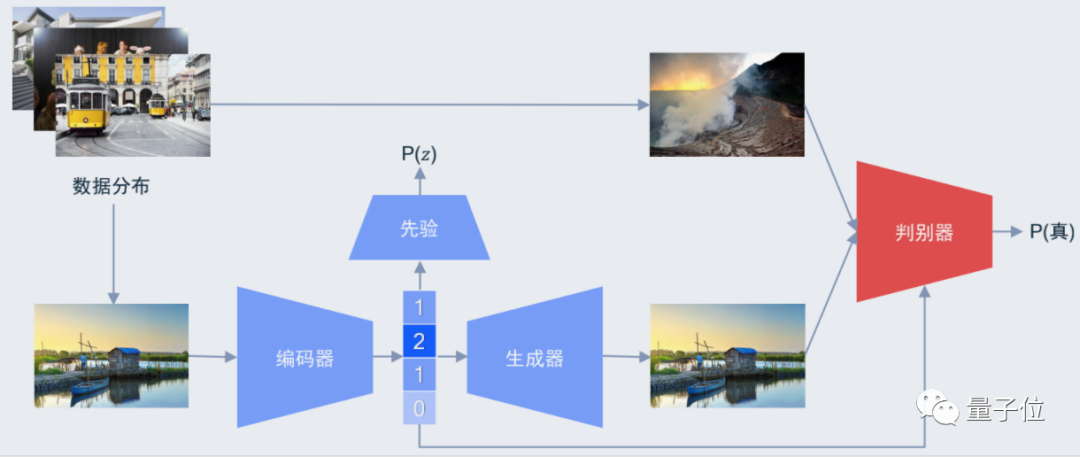
也就是开头的图片效果,即使在大小被压缩后,基于GAN的图像还是能取得更好的视觉质量:

期待这些技术能马上应用到手机等设备上,让我们看视频的时候真正变得不卡。
相关论文:
[1]https://arxiv.org/abs/2104.00531
[2]https://arxiv.org/abs/2101.08687
参考链接:
[1]https://www.qualcomm.com/news/onq/2021/07/14/how-ai-research-enabling-next-gen-codecs
[2]https://github.com/leandromoreira/digital_video_introduction