C Pretreatment - C 预处理
前言
本文讲的是 BIT - 0 - 程序环境和预处理。
这将是我们C语言最后一篇知识总结了,之后我会利用时间,把前面的没有排版的,都给弄一下,这意味我国庆闲不下来了==。
我只修改 像这篇文章一样的,知识总结 和 有必要修改的文章(比如:指针笔试题)
静候佳音吧,各位!
本文重点
- C Pretreatment - C 预处理
- 前言
- 1.程序的翻译环境 && 执行环境
- 2.详解:C语言程序的翻译 - 链接
- 程序整个过程的概略总结:
- 编译本身 也可以分成 几个阶段
- 下面我们来讲讲 翻译的三部分 —— 预编译
- 翻译—— 编译
- 翻译 —— 汇编
- 汇编的任务
- 形成符号表 顾名思义 就是把 符号汇总的 符号,放进 一个表里
- 链接:
- 总结(翻译环境):
- 下面进入 运行环境
- 程序运行的过程
- 3.预定义符号介绍
- 4.预处理指令
- #define 定义标识符(可以定义宏)
- 那么问题来了,#define 定义完之后,要不要加上一个 ;号 会发生什么?
- 再举个列子
- #define 定义宏
- 下面是宏的声明方式
- 下面我们来实践
- 程序一:
- 程序二:
- 程序三:
- 总结:
- #define 替换规则
- #define 替换规则 注意事项:
- 带有副作用的 宏参数
- 程序一:
- 程序二:
- 程序三(建议 与程序二 对着看)
- 5.宏 和 函数 的 对比
- 先来看看 两者 在程序中的表现
- 那么 函数 跟 宏 谁更好呢?
- 宏的优势一:
- 宏的第二个优势:
- 通过 F10(调试),然后点到程序这里,反键选择 转到反汇编
- 总结
- 宏 有时候 可以做到函数做不到的事情
- 总结(宏与函数的对比)
- 6.预处理操作符 # 和 ## 的介绍
- # 符号 和 ## 符号
- # 符号
- 程序一:
- 程序二:
- 程序三(程序一 运用 宏 之后):
- ## 符号
- 程序一:
- 7.命名定义(命名约定)
- 8.命令行定义(在预编译期间处理的)
- 举个例子
- 附图
- 9.预处理之指令 #undef
- 程序如下
- 10.条件编译
- 举个例子
- 如果列子中的 DEBUG 被定义了,按照规则 删除 #ifdef 和 #endif 这两条语句
- DEBUG 未定义, 按照规则 删除 #ifef 和 #endif之间的语句(包括它们自身两个语句)
- 常见的 条件编译 指令
- 1. #if + 常量表达式
- .....
- #endif 来收尾
- 实例:
- 2.多个分支 条件编译
- #if + 常量表达式
- .....
- #elif + 常量表达式 (跟 else if 意思差不多)
- .....
- #else
- ......
- #endif
- 实例:
- 3. 判断是否被定义
- #if defined(symbol)
- ifdef symbol
- #if !defined(symbol)
- #ifndef symbol
- 实例:
- 嵌套指令
- 11.预处理指令 #include(文件包含)
- 头文件 被包含的方式:
- 1.本地文件包含
- 2. 库文件包含
- 嵌套文件包含
- 解决方法(修改 add.h)
- 第一种写法
- 第二种写法
- 让我们来看看看程序怎么写
- 总结
- 如果我们像 stdio.h 头文件 里一样 在里加上 #pragma once 的 话,效果会是什么样的?
- 其他的 预处理指令
- 在文章 的 最后 我们来讲讲 一道百度笔试题
- 首先我们知道 有一个 函数 offsetof 是用来计算 结构体中成员 相对于 首地址的偏移量的
- 而我们接下来写的 宏 就是 模拟实现 offsetof
- 本文至此结束。

1.程序的翻译环境 && 执行环境
在 ANSIC 的 任何一种 实现中,存在两个不同的环境。
第一种是翻译环境: 把 一个 .c文件 编译产生一个可执行程序的时候,它所依赖的整个过程,整个环境,就被称为翻译环境
在这个环境中 源代码 被转换为 可执行的 机器指令
第二种是执行环境:当产生一个可执行程序,如果想运行起来,这时候最终产生我们想要的结果。而 运行程序 产生的结果,所依赖的环境 被称为执行(运行)环境
用于 实际 执行代码。
2.详解:C语言程序的翻译 - 链接
编译环境(依赖编译器) && 链接(依赖链接器)
由 编译器 处理的过程,称为编译 ,而由 链接器 处理的过程,称为链接
下面让我们通过程序来看看,最好跟着敲敲。
#include<stdio.h>
int main()
{
int arr[10] = { 0 };
int i = 0;
for (i = 0; i < 10; i++)
{
arr[i] = i;
}
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
执行该文件之前,先观察 该程序项目中,包含哪些?
C pretreatment 中的文件,其中 后缀为 .c 文件,其实是文本文件,也就是我们写的程序一开始 是一个一个文本文件
在执行完程序后,你会发现多了一个 Debug 文件

点开 Debug 文件后,我们发现里面有一个 .exe文件(可执行文件【二进制文件】)

** 我们再点开 项目 C pretreatment 中 C pretreatment 文件 里面也多;了一个 Debug 文件

让我们一起来看看里面的内容

让我们再来通过一个程序,来讲解

#include<stdio.h>
extern int add(int, int);// 函数声明,功能就是 把两个整数进行相加。函数功能的实现在 另一个 add,c 文件 中
int main()
{
int a = 10;
int b = 20;
int c = add(a, b);
int arr[10] = { 0 };
int i = 0;
for (i = 0; i < 10; i++)
{
arr[i] = i;
}
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
printf("c = %d\n", c);
return 0;
}
通过下方图片,我们会发现,每个源文件都会经过 编译器单独处理,生成自己对应 .obj 目标文件

我们再来看看 链接器 的 效果图

程序整个过程的概略总结:
组成 一个完整 的 程序 的 每个源文件(.c 文件) 各自单独 通过 编译器 转换成 目标代码(object code).
每个目标文件(.obj) 由 链接器(linker)捆绑在一起,形成一个 单一 而 完整 的 可执行程序。
链接器同时也会引入 标准 C 函数库 中 任何被 该程序 所用到的函数(见下方附图 ),而且 它 可以搜索 程序员 个人的程序库,将其需要的函数 也 链接到 程序中

笼统来说:一个源文件 变成 可执行程序的时候,经过 编译器 编译处理,经过 链接器 链接处理,最后生成我们的可执行程序。
编译本身 也可以分成 几个阶段

翻译环境(编译环境):可分为 2 部分:编译(翻译) 和 链接
将 翻译 细分 又可以 分成 预编译、编译、汇编
一个源文件 经过了 整个编译环境(编译 和 链接) 阶段后,才能生成后缀为 ,exe 的文件【可执行文件】
下面我们来讲讲 翻译的三部分 —— 预编译
总得来说 预处理/预编译 ( 生成一个 .i 文件【无法解释,简单来说就是通过预编译生成一个文件】) , 该操作又被称为 文本操作
( 预编译所做的事: 删除注释 和 把 #include<stdio.h>中 stdio.h 包含 数据 拿出来)
#include<头文件>的 头文件 所包含的数据,当然 这是一部分(注意傍边的 代码行)

那是不是真的呢?
我在 linux 系统中,输入一条指令 vim /usr/include/stdio.h,我就能打开 linux 系统的 stdio.h 。
你把你键盘大写打开,按个 G 就能跳到最后了
你会发现 两者 是一致的,所以 是真的。

我在程序中放 2个注释

我们在对其 进行 预编译 指令

你会发现 那两个注释已经不在了

因为小编 还没搞明白 linux 系统,所以无法详解
想更进一步了解 预处理,编译,汇编的,推荐一个b站 up 主 》 鹏哥C语言 》 第 80 个视频 》 25 分钟 左右
【不过这里只是 提及不多,建议找一个 linux 系统 教程 自己尝试一下。】
翻译—— 编译
编译 :
把 c语言代码 翻译成 汇编代码(把预编译生成 .i 文件 转换成 .s【汇编语言】)
把 c语言代码 翻译成 汇编代码 所做的工作:
1.语法分析 - 判断语句写法有没有问题 (类似 英语判断语法错误)
2.词法分析 - 词法分析,涉及到 《编译原理》 (如何把c语言代码 翻译成 汇编代码)
3.语义分析 - 判断 该语句想表示意思是否明显 (类似英语中,判断 句意 是否矛盾)
4.符号汇总 - 把 代码中 的 一些符号 汇总出来 (不是标点符号,而是函数符号(全局变量,函数名))
翻译 —— 汇编
预编译 编译 汇编
(每个源文件[.c文件] -》 .i 文件 -》 .s 文件【汇编代码】 -》 目标文件【 .o / .obj 】)
&ensp 后缀为 ,s 文件编译结束之后生成的汇编代码
汇编的任务
1.生成可重定位目标文件(.o / .obj) —— 把 汇编代码 转换成 二进制代码(二进制指令)
在 Linux 环境中 目标文件后缀为 .o
在 windows 环境中,目标文件后缀为 .obj
2. 形成符号表:在编译的过程 有一项符号汇总,当汇总完成了(编译环节结束了),汇编会对其进行一个动作,就是形成符号表
(其实 编译 会对 每个 .c 文件(源文件)的符号,进行符号汇总【函数名 和 全局变量】。)
下面用程序来讲解一下
还是一个简单 计算 两个整数之和 的 程序
#include<stdio.h>
extern int add(int, int);//( add.c 文件)
// 对 add 进行编译, 符号汇总(函数名,全局变量) 时,发现 函数名 add
int main() // 对主函数 进行编译, 符号汇总,发现 函数名 main 主函数名
{
int a = 10;
int b = 20;
int c = add(a, b);
printf("%d\n", c);
return 0;
} // 在对这个程序进行编译时,符号汇总 :有 2个 符号(函数名 add main)
形成符号表 顾名思义 就是把 符号汇总的 符号,放进 一个表里
假设 add 的 地址 0x 12 34 56 78 , main 0x 87 65 43 21
表格 的形式就是 函数名 + 地址
| 符号 | 符号地址 |
|---|---|
| add | 无意义的地址 |
| main | 0x 87 65 43 21 |
为什么 add 是 无效地址?我们刚才明明就 假设 add 的地址了。
那是 由于 我们的 add 只是在 主程序中 声明一下(告诉你有,但是是什么,不知道),这个 add 函数的地址无法找到的,所以放了一个无意义的地址
| 符号 | 符号地址 |
|---|---|
| add | 0x 12 34 56 78 |
add,c 文件里 只有一个符号 add 函数名

也就是说 这两个源文件(.c文件),在汇编功能中,各自生成一个 符号表
汇编最终生成的是 一个 目标文件(.obj / .o),而 一个程序中有多个 源文件,也就是会生成 多个 目标文件
多个 目标文件(.o / .obj),会经过 链接器 进行链接,最后生成 可执行程序(.exe 文件),

链接:
在 链接 环节中, 链接需要完成 2 个任务
1.合并段表
2.符号表的合并 和 重定位
我们还是痛果盘那个程序来讲解
test.c
#include<stdio.h>
extern int add(int, int);
int main()
{
int a = 10;
int b = 20;
int c = add(a, b);
printf("%d\n", c);
return 0;
}
add.c
#define _CRT_SECURE_NO_WARNINGS 1
int add(int x, int y)
{
return x + y;
}
上面程序(有 add.c 和 test.c,这两个源文件,这两个源文件 各自 进行了一个 相对应的编译过程之后,生成了自己的目标文件(add.o / test.o)
链接器 会把这两个目标文件 进行链接,将其 捆绑 在一起时,随后 链接器 会进 行一个动作 合并段表
有人可能会问 段表 是什么? 答:是一种 文件格式
每个目标文件 都有 自己的格式(每个目标文件 会将自己 分成几个段,虽然它们段的意义是一样的,但各自段里放的数据不同的)
这种文件格式 被称为 elf的格式
我们在 linux 系统中,使用一个 工具 readelf ,是专门用来读 elf 格式 的 文件。

我们来看看效果(出现一堆相关的信息)

此时,我们在输入一条指令 readelf test.o -a

其实 这个 时候 展示的 就是 我们的 段( test 文本段、data 数据段【0000000~00024】等等。 )
链接器会把多个目标文件链接在一起,然后进行 合并段表 就是 把 多个目标文件 的 对应的段上信息进行合并 【合并是有它自己的规则的】 (见附图)

然后需要注意一点,生成 的 可执行程序(.exe) 也是 elf 格式文件
然在 合并段表 之后,就是 合并符号表`(把 add.c 和 test.c 中 由符号【函数名 和 全局变量】组成的符号表 进行合并)
add.c 中 有一个 add 地址,test.c 也有一个 add 地址(无意义),一定要用有效的地址,也就是 add.c 中的 add 地址,放进表里(函数名 + 有效地址)
main 函数 没有冲突 直接放进表里(函数名 + 地址)
最终表格 见下方附图,其实这就是 合并符号表 和 (一些符号的地址)重定位

详情过程如下方附图

直至,经过这 一系列的操作,这个时候 可执行程序 就彻底生成了。
意味着 整个 翻译 环节 就结束了。
总结(翻译环境):

下面进入 运行环境
程序运行的过程
(1. 是重点)
1.程序必须戴入内存中,在有操作系统的环境中:一般这个由操作系统完成。
在独立的环境中,程序的载入 必须 由 手工安排,也可能是通过 可执行代码 置入 只读内存来完成。
2.程序的执行 便开始。接着 便调用 main 函数
3.开始执行程序代码,这个时候 程序 将使用一个运行时 的 堆栈(stack)【函数栈帧】;存储函数的局部变量和返回地址。
程序 同时 也可以 使用静态(static)内存,存储于 静态内存中 的 变量,在程序 的 整个执行过程一直保留他们的值。
4.终止程序,正常终止 main 函数;也可能意外终止
3.预定义符号介绍
| FILE | 进行编译的源文件 |
|---|---|
| LINE | 文件当前的行号 |
| DATE | 文件被编译的日期 |
| TIME | 文件被编译的时间 |
| STDC | 如果编译器是 遵循 ANSIC标准,其值为1,否则未定义(stdc - 标准控制显示单元) |
这些预定义符号都是语言内置的,举个栗(例)子:
#include<stdio.h>
int main()
{
printf("%d\n", __STDC__);// 但是在 vs 环境中 是不支持的。因为在 vs 中 没有 __STDC__ 这个定义
return 0; // 但是linux 中可以使用,输出为 1
}
以下数据 皆是 我 个人数据(你总不能说,你就是我吧==,这些 输出 信息,都是正确,只不过以我 执行这条程序 打印出 的 信息)
#include<stdio.h>
int main()
{
//printf("%s\n",__FILE__);// 该程序的绝对路径: g:\程序\c pretreatment\c pretreatment\c pretreatment.c
//printf("%d\n", __LINE__);// 261,正好对应着 该语句所在的对应行数
//printf("%s\n", __DATE__); // Sep 22 2021 ,打印的是我执行这代码,当天的日期 2021 年 九月 22日
//printf("%s\n", __TIME__);// 16:14:00 // 执行程序时,当时的时间。
// 那么什么时候,会用到这些预定义符号呢?
写日志文件
int arr[10] = { 0 };
FILE* pf = fopen("log,txt", "w");
int i = 0;
for (i = 0; i < 10; i++)
{
arr[i] = i;
fprintf(pf, "file:%s line:%d date:%s;time:%s i= %d",
__FILE__,__LINE__,__DATE__,__TIME__,i);
printf("%s\n", __FUNCTION__);// 打印了 10 个 main 函数,该语句所在的函数名
}// 效果 见 下方附图
fclose(pf);
pf = NULL;
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
return 0;
}

4.预处理指令
# 开头的指令,都是预处理指令(#define,#include,#pragma pack(),#if。#endif,#ifdef,#line)
#define 定义标识符(可以定义宏)
#include<stdio.h>
#define MAX 100
#define STR "hehe"
#define reg register
#define do_Forever for(;;)
int main()
{
do_Forever;
//do_Forever 放在程序会造成死循环,因为它在预编译期间替换成 for循环,没有条件束缚,所以会导致死循环
// do Forever; 》》 for(;;) ;
// return 0 ; return 0;
// 分号不能省略 ;
// 如果省略 return 0; 就变成了for循环的执行内容,直接return 0;结束程序
如下所示
// do_Forever == for(;;)
// return 0; return 0;
reg int a;// 这里的 reg == register ,因为在预编译中,会完成替换
int max = MAX;// 在预编译截断,把主程序中 #define 定义的 MAX 替换成 100
// 即 int max = MAX; == int max = 100;
printf("%d\n", max);// 100
printf("%s\n", STR);// hehe 和上面程序一样的道理,在预编译中,完成替换,把 STR 替换成 字符串 "hehe"
return 0;
}
那么问题来了,#define 定义完之后,要不要加上一个 ;号 会发生什么?
#include<stdio.h>
#define MAX 100;
int main()
{
int a = MAX;// int a = 100;;(这是define 定义的MAX自带一个分号,而 为了满足 程序书写的格式,我们一般会加一个 分号),所以如果#define 在定义完之后,加一个分号的话, 在完成替换之后,程序就会多出一个分号( MAX == 100;)。
// 虽然这样写没有问题,但是不提倡
但是 !!!
printf("%d\n",a);// 如果我这里是 printf("%d\n",MAX) == printf("%d\n",100;);
// 这样写,语法就会出现错误,说 分号 前面 应该加个括号(也就是在替换完 MAX 之后,在100的后面加个括号),
// 而且 看着 也别扭,当然,这是肉眼看不出的错误,因为我们看得是 未替换的程序,仅凭肉眼去看是发现不了错误的。
return 0;
}// 最好不要在 #define 定义完之后,加上一个分号,容易出现问题,还是肉眼无法发现的,因为编译器报错,报的是替换完数据之后 发生的错误
// 而我们直接肉眼去看程序,也就是还没有替换的程序,是没有错误的(因为我们写的代码符合格式,但是你要把一些替换成别的,就可能会出现问题)。
// 所以在 #define 定义完之后,不要画蛇添足(加分号),以免造成意外错误(而且该错误很难肉眼去发现)。
再举个列子
#define max 100;
if()
MAX = max;
即
if()
MAX = 100;;
对于if语句来说,下面的表达式是两句话(两个分号),if后面在没有大括号的前提下,它只管一句,所以会出现语法错误。
#define 定义宏
#define 机制包括了一个规定,允许 把参数 替换到 文本中,这种实现通常称为宏(macro - 宏指令/宏)或 定义宏(define macro)
下面是宏的声明方式
#include<stdio.h>
#define name(parameter,list/*参数列表*/) stuff
// 其中 parameter,list 是一个由逗号隔开的符号表,他们可能出现在 stuff
// 参数列表 的 左括号必须与 name 紧邻,如果两者之间有 任何空白 存在,参数列表 就会 被解释为 stuff 的 一部分。
int main()
{
return 0;
}
下面我们来实践
程序一:
#include<stdio.h>
#define SQUARE(X) X*X
int main()
{
int ret = SQUARE(5); // SQUARE(5) == 5*5 参数5 会在替换的时候,把 X 替换成 5
printf("ret = %d\n", ret);// 25
return 0;
}// SQUARE 就是我们所说的宏
宏 其实是一个 由 #define 定义的东西,它 有名字、有参数,参数可以替换到内容里面去。
程序二:
#include<stdio.h>
#define SQUARE(X) X*X //如果想得到 36 ,则把 X*X 改成 (X)*(X)
// 因为括号 比 乘号 的优先级高,所以会先算括号里的内容
// (5+1)*(5+1) == 36
int main()
{
int ret = SQUARE(5 + 1);// 5 + 1*5 + 1 == 5+5+1 ==11
printf("ret = %d\n", ret);// 11
return 0;
}// 宏的参数 替换 内容时,是直接把整个参数替换过去,没有任何加工,如果 跟 替换内容的符号不相同,就意味着运算的顺序,可能会跟我们想的不一样
// 所以需要注意这一点,如果想保证运算的顺序跟我们想的一样,最好加上括号,让参数 成为一个 独立的部分
程序三:
我们希望下面输出100
#include<stdio.h>
#define DOUBLE(X) X+X // /*((X)+(X))*/
// 为了避免 出现 我们意想不到的结果,我们最好保持 参数 的独立性
// 即(X)+(X) ,但是 结果依然不是我们想要的,没有变化。所以还需要一个括号来保证 整个替换的内容的独立性
// 故 ((X)+(X)),这样,才能保证我们的结果为100
int main()
{
int a = 5;
int ret = 10 * DOUBLE(a);// == 10* 5 + 5 == 50 + 5
printf("%d\n", ret); // 55
return 0;
}// 在我们使用 宏 的时候, 请不要吝啬 括号。
总结:
用于 对 数值表达式 进行求值 的 宏定义 都应该用这种方式 加上括号,
避免 在使用宏时
由于 参数 中的 操作符 或 邻近操作符 之间 不可预判 的 相互作用
#define 替换规则
在 程序中 扩展 #define 定义符号 和 宏 时,需要涉及几个步骤。
1.在调用 宏 时,首先对参数进行检查,看看是否 包含任何 由 #define 定义的符号,如果是,它们 首先 被替换。
2.在替换文本完成了的时候, 随后 被插入到程序中 原来的位置。对于宏,参数名 被 他们的值替换。
3.最后,再次 对 结果文件 进行扫描,看看它 是否 包含任何 由 #define 定义的符号。如果是,就重复上述处理过程。
#define 替换规则 注意事项:
1.宏参数 和 #define 定义中 可以出现其它 #define 定义 的 变量,但是对于宏,不能出现递归。(宏是没有递归概念的)
2.当 预处理器 搜索 #define 定义的符号的时候,字符串常量的内容并不被搜索
针对第二个注意事项 举一个例子
#include<stdio.h>
#define MAX 100
int main()
{
printf("MAX = %d\n" , MAX);// MAX = 100
//这个MAX就不用替换
return 0;
}
带有副作用的 宏参数
当 宏参数 在 宏的定义中 出现 超过一次 的 时候,如果 参数 带有 副作用
那么 你在使用 这个宏的时候 就可能 导致 不可预测的后果。
副作用 就是 表达式求值 的时候 出现的永久性效果。
再了解 有副作用 的 宏参数 之前,让我们先来看下面这个程序
程序一:
#include<stdio.h>
int main()
{
int a = 10;
/*代码一*/
int b = a + 1;// 11 a没变,a == 10
/*代码二*/
int c = ++a;// 11 a变了,a == 11
//其实 代码二 就是 有副作用的 代码,a的值 被改变了,而且是永久性的。
return 0;
}
现在我们来看看 带有副作用的 宏参数
程序二:
#include<stdio.h>
#define MAX(X,Y) ((X)>(Y)?(X):(Y))
int main()
{
int a = 10;
int b = 11;
int max = MAX(a, b);
printf("%d\n", max);// 11
return 0;
}
程序三(建议 与程序二 对着看)
那么 我们 把 程序二 这样写呢?
#include<stdio.h>
#define MAX(X,Y) ((X)>(Y)?(X):(Y))
int main()
{
int a = 10;
int b = 11;
int max = MAX(a++,b++);//这时候这两个参数 a,b 就带有副作用了
//#define 定义的宏,它的参数是直接传过去的(完全替换性,个人取名 == )
等价于 ( (a++) > (b++) ? (a++) : (b++))
意思就是 (a++)>(b++) -> 10 > 11 为假,调用完之后,a与b开始自增(后置加加【调用完之后,再加一】) a+1 == 11,b+1 == 12
然后根据 根据三目操作符表达的意思 是
如果 (a++) > (b++) 为假
则返回 b++。(此时 b == 12【没有进行后置加加之前的值】。 即 返回的值是 12,
也就是说 三目操作符 返回的值 是 12 ,被 max 接收。然后 b 开始进行自增(后置加加),即 b == 13
而 a++ 的语句不符合条件,所以没有执行,所以 a 还是 11
printf("%d\n", max);// 12
printf("%d\n", a);// 11
printf("%d\n", b);// 13
return 0;
}
5.宏 和 函数 的 对比
先来看看 两者 在程序中的表现
#include<stdio.h>
// 函数
int Max(int x, int y)
{
return ((x) > (y) ? (x) : (y));
}
// 宏
#define MAX(X,Y) ((X)>(Y)?(X):(Y))
int main()
{
int a = 10;
int b = 20;
int max = Max(a, b);
printf("%d\n", max);// 20
max = MAX(a, b);
printf("%d\n", max);// 20
return 0;
}// 由此不难看出,宏 和 函数 还是有很多相同之处的,而且都能达到我们想要的效果
那么 函数 跟 宏 谁更好呢?
宏的优势一:
#include<stdio.h>
// 函数
int Max(int x, int y)
{
return ((x) > (y) ? (x) : (y));
}
// 宏
#define MAX(X,Y) ((X)>(Y)?(X):(Y))
int main()
{
float a = 3.0f;
float b = 4.0f;// 我们 把 a 和 b 改成浮点型呢?
int max = Max(a, b);// 如果 这样写,函数 传值会发生错误,因为 两个数据的类型不同,无法进行传值
printf("%d\n", max);
max = MAX(a, b);// 而 宏 就不会存在这样的问题
printf("%d\n", max);
return 0;
} // 这是宏的 第一个优势
宏的第二个优势:
#include<stdio.h>
// 函数
float Max(float x, float y)
{
return (x > y ? x : y);
}
// 宏
#define MAX(X,Y) ((X)>(Y)?(X):(Y))
int main()
{
float a = 3.0f;
float b = 4.0f;// 我们 这里 还是把 a 和 b 改成浮点型
float max = Max(a, b);// 函数 已经改成 相应的 类型,所以不会出现问题
printf("%d\n", max);
max = MAX(a, b);
printf("%d\n", max);
return 0;
}
而 宏 就不会这样,因为 宏的定义 在 预处理阶段就完成了替换,
max = MAX(a, b); -> max =((a)>(b)?(a):(b));
你可以进入反汇编中去观察,发现 汇编代码量 比 函数的要少很多,说明 宏的效率 要比 函数 高很多
因为 宏 没有 函数的调用 和 返回的开销
通过 F10(调试),然后点到程序这里,反键选择 转到反汇编

你会发现 函数 实现 Max 需要 29 句 汇编代码。在执行关键性代码return ((x) > (y) ? (x) : (y)); 时,前前后后会有大量的汇编代码。 为了调用这个函数,在调用之前,要准备相关的工作(传参,调用完之后,需要再把参数带回来)。
总得来说,函数在被调用的时候,会有函数调用和返回的开销(需要准备时间,效率要低一些)

宏 就不会这样,因为 宏的定义 在 预处理阶段就完成了替换,
max = MAX(a, b); -> max =((a)>(b)?(a):(b));
你可以进入反汇编中去观察,发现 汇编代码量 比 函数的要少很多,说明 宏 的 效率 要比 函数 高很多
因为 宏 没有 函数的调用 和 返回的开销

总结
宏的优点:
1.宏 比 函数 在 程序中 的 规模 和 速度 方面 更胜一筹。 因为 调用函数 和 从函数返回的代码 可能 比 实际执行 这个小型计算工作 所需要的时间更多
2.宏 不受 数据的类型 影响,因为 函数方法, 它的参数必须声明为 特定类型。所以 函数 只能在 类型合适 的 表达式上使用
与之相反,宏 可以适用于 整形,长整形、浮点型等 可以用 > 符号 来比较 的 类型。
当然 宏有优点,就肯定有缺点:
1.每次使用 宏 的时候,一份宏定义 的 代码 将插入到程序中。除非 宏 比较短,否则 可能 大幅度增加程序的长度。
2.宏 是没办法调试的
3.由于 宏 与 数据的类型无关。也就意味着 不够严谨(不做类型检查)
4.宏 可能会 带来 运算符优先级 的 问题,导致程序 容易 出现错误
宏 有时候 可以做到函数做不到的事情
比如:宏 的参数 可以是 类型,但是函数做不到
打个比方:函数能不能 传个 int(只能说传值 和 传址),这肯定是不行的,只能说传一个 int类型 的 数据 过去。
来看个程序
#include<stdio.h>
#define SIZEOF(type) sizeof(type)
int main()
{
int ret = SIZEOF(int);
// 上方表达式会被替换成 int ret = sizeof(int);
printf("%d\n", ret);// 4
return 0;
}
再来看一道程序
#include<stdio.h>
#define MALLOC(num,type) (type*)malloc(num * sizeof(type));
int main()
{
int* p = MALLOC(10, int);
// int* p = (int*)malloc(10 * sizeof(int));
return 0;
}
总结(宏与函数的对比)
| 属性 | #define 定义的宏 | 函数 |
|---|---|---|
| 代码长度 | 每次使用时,宏代码都会被插入到程序中,除了 非常短 的宏之外,程序的长度 会 大幅度增长 | 函数代码只出现于一个地方;每次使用者个函数时,都调用那个地方的同一份代码 |
| 执行速度 | 更快 | 存在 函数的调用 和 返回的 额外开销,所以相对慢一些 |
| 操作符优先级 | 宏参数的求值 是在所有周围表达式的上下文环境里,除非加上括号[使 参数 和 整个替换的内容 具有独立性],否则邻近操作符的优先级可能会产生不可预料的后果,所以建议宏在书写的时候,不要吝啬括号。 | 函数参数只在函数调用的时候求值一次,它的结果值 传递给 函数,表达式的求职结果更容易预测 |
| 带有副作用的参数 | 参数可能被替换到宏体中多个位置,所以带有副作用的参数求值可能会产生不可预料的结果。 | 函数参数只在传参的时候求值一次,结果更容易控制。 |
| 参数类型 | 宏的参数与类型无关,只要参数的操作时合法的,它就可以使用与任何参数类型。 | 函数的参数是与类型有关的,如果参数的类型不同,就需要不同的函数,即使他们在执行的任务是不同的。(参数类型一定要匹配) |
| 调试 | 宏不方便调试(需要特殊操作系统(linux系统)中,才能观察 宏 是否存在错误,而且算不上是调试) | 函数是可以逐句调试的 |
| 递归 | 宏是不能递归的(宏 压根就没有 递归额概念) | 函数是可以递归的(这厮就是一个套娃狂魔,我就不解释了) |
另外在 C99 和 C++中,最新引入了一个 inline - 内联函数【具有 宏 和 函数 的 优点】,有兴趣的,可以自己搜索了解下
6.预处理操作符 # 和 ## 的介绍
# 符号 和 ## 符号
# 符号
注意:# 不是 #define 中的 #,是一个单独存在的 #
**接下来我们来通过程序来加深我们对它的理解
程序一:
#include<stdio.h>
void print(int a)
{
printf("the value of a is %d\n", a);
}// 无论你传过来的是什么参数,我的输出语句 那个 单独 a 是不可能变成 与传参 的 字母保持一致的,这 a 是定死了的
// 这个时候 就用到一个 宏 。
int main()
{
int a = 10;
int b = 20;
print(a);
print(b);
return 0;
}
**在 改进 程序一 之前,我们需要学习一个知识点
程序二:
#include<stdio.h>
int main()
{
printf("hello world\n");
printf("hello " "world\n");
printf("he""llo " "world\n");
return 0;
}//输出结果 你会发现 三者输出的结果 完全一致。【 hello world 】
// 由此看出 两个 相邻的 双引号,输出的内容,天生就是连在一起的。(当成 一个 字符串 来处理)
程序三(程序一 运用 宏 之后):
#include<stdio.h>
// X == a
#define PRINT(X) printf("the value of " #X " is %d\n",X)
// #X 让 X 不被替换 10,而是保持 X 所表达的内容的字符串
// 也就是 X == a -> #X == "a"
// 即 printf("the value of " "a" " is %d\n",X)
// 按照我们上面 所讲的那个程序,你就会发现 这条语句 等价于 printf("the value of a is %d\n",X)
// print(b) X == b -> #X =="b"
//即 printf("the value of " "b" " is %d\n", X) 等价于 printf("the value of b is %d\n",X)
int main()
{
int a = 10;
int b = 20;
PRINT(a);// 输出结果 :the value of a is 10
PRINT(b);// 输出结果 :the value of b is 20
return 0;
} // #的作用:就是说 把 参数 插入到 字符串中 【 # + X -> "X" 把一个数据变成字符串】
## 符号
## 符号,可以把 位于 它 两边的符号 合成一个符号,它 允许 宏定义 从 分离的文本片段 创建标识符。
程序一:
#include<stdio.h>
#define CAT(x,y) x##y
int main()
{
int Class103 = 2021;
printf("%d\n", Class103);// 2021
printf("%d\n", CAT(Class,103));// 2021
return 0;
}
通过 ## 符号,处理后
printf("%d\n", CAT(Class,103)); 等价于 printf("%d\n", Class103);所以你发现了吗?
## 符号, 就是把 两个相离的符号,合成一个符号【 x##y -> xy 】
7.命名定义(命名约定)
一般来讲 函数 和 宏 使用的语法很相似,所以语言本身 没法 帮我们区分二者
那我们平时的一个习惯是:宏名全部大写,函数名首字母大写
8.命令行定义(在预编译期间处理的)
许多C的编译器 提供了 一种能力,允许 命令行中 定义符号,用于启动编译过程。
例如:
当我们根据 同一个源文件 要编译出 不同的一个程序 的 不同版本时候,这个特性 有点用处。
举个例子
#include<stdio.h>
int main()
{
int arr[sz] = { 0 };// sz 这个符号我们不去定义
int i = 0;
for (i = 0; i < sz; i++)
{
arr[i] = i;
}
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
如果此时 直接执行代码,会报错(sz未定义)
如何处理呢?
假设上面程序 是写在 test.c 的源文件中
在 linux 系统中,输入 gcc test.c -D sz=10
ls 看一下,有个可执行程序 a.out
执行一下 输入 ./a.out 输出结果为(见下方附图)【sz=10】
sz 是可以重复定义【修改】 gcc test.c -D sz=100(那么在对其进行输出,结果为 0~99)
其实 命令行定义 ,其实也是在 预编译 阶段,把 sz 替换成 10
附图

9.预处理之指令 #undef
这条指令 用于 移除 一个 宏定义
程序如下
#include<stdio.h>
#define MAX 100
int main()
{
printf("MAX =%d\n", MAX);// 这里是可以使用 MAX 的,输出为 100
#undef MAX// 这里的 #undef MAX 的意思是 把 #define 定义的 MAX 给 移除了
printf("MAX =%d\n", MAX);// 因为 #define 定义的 MAX 被 #undef 移除了
// 所以 这里的 MAX 是不能使用,程序会报错
return 0;
}
10.条件编译
在 编译 一个程序的时候 我们如果 将一条语句(一组语句)编译 或者 放弃 是很方便的。因为我们有编译指令
比如说:
调试性的代码,删除可惜,保留又碍事,所以我们可以 选择性的编译。
举个例子
#include<stdio.h>
// #define DEBUG(已屏蔽)
int main()
{
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };
int i = 0;
for (i = 0; i < 10; i++)
{
arr[i] = 0;
// 如果我们有时候不想 执行 printf 语句我们该怎么去做呢?
#ifdef DEBUG// 如果 DEBUG 被定义过,那么 下面这条语句 将会 参与编译,否则(DEBUG没有被定义过),就不参与编译
printf("%d\n", arr[i]);// 而现在 DEBUG 是没有被定义过的,所以这条代码 不会被 编译,就好像删掉了
#endif// #ifdef 与 endif 是 组合使用的
}
return 0;
}
满足条件,我让它编译,不满足,就不让它编译。
条件编译 :还是 在 预处理阶段 处理,在 预处理阶段 去看 DEBUG 有没有被定义(#ifdef)
如果有,就把 #ifdef 和 #endif 这两条语句 删掉。
如果没有, 把从 #ifdef 到 #endif 之间的语句(包括它们自身)全部删除
如果列子中的 DEBUG 被定义了,按照规则 删除 #ifdef 和 #endif 这两条语句
#include<stdio.h>
#define DEBUG
int main()
{
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };
int i = 0;
for (i = 0; i < 10; i++)
{
arr[i] = 0;
printf("%d\n", arr[i]);
}
return 0;
}
DEBUG 未定义, 按照规则 删除 #ifef 和 #endif之间的语句(包括它们自身两个语句)
#include<stdio.h>
int main()
{
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };
int i = 0;
for (i = 0; i < 10; i++)
{
arr[i] = 0;
}
return 0;
}
常见的 条件编译 指令
1. #if + 常量表达式
…
#endif 来收尾
实例:
#include<stdio.h>
int main()
{
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };
int i = 0;
for (i = 0; i < 10; i++)
{
arr[i] = 0;
#if 1 //#if 后面的常量表达式为 1 为真 ,输出下面语句
printf("%d\n", arr[i]);
#endif// #if 与 endif 是 组合使用的
#if 0 // 如果#if 后面的常量表达式为 0 ,为假,则不输出下面语句
printf("%d\n", arr[i]);
#endif// #if 与 endif 是 组合使用的
#if 1-1 //#if 后面的常量表达式结果为 0 为假 ,不输出下面语句
printf("%d\n", arr[i]);
#endif// #if 与 endif 是 组合使用的
}
return 0;
}
2.多个分支 条件编译
#if + 常量表达式
…
#elif + 常量表达式 (跟 else if 意思差不多)
…
#else
…
#endif
实例:
#include<stdio.h>
int main()
{
#if 1 == 1 //#if 后面的常量表达式 条件为真 ,输出下面语句
printf("haha");
#elif 2 == 1 //#elif 后面的常量表达式 条件为假 ,不输出下面语句
printf("hehe");
#else // 如果 上面 两个 条件都不满足,则输出 下面语句
printf("hei hei\n");
#endif// #if 与 endif 是 组合使用的
return 0;
}
3. 判断是否被定义
#if defined(symbol)
(等价于)
ifdef symbol
#if !defined(symbol)
(等价于)
#ifndef symbol
实例:
#include<stdio.h>
int main()
{
#if defined(DEBUG)
printf("hehe\n");// DEBUG 没有被定义过,所以不输出 该语句
#endif
return 0;
}
#include<stdio.h>
#define DEBUG
int main()
{
#if defined(DEBUG)
printf("hehe\n");// DEBUG 有被定义过,所以输出 该语句
#endif
等价于
#ifdef DEBUG
printf("hehe\n");// DEBUG 有被定义过,所以输出 该语句
#endif
如果 我想 DEBUG 没有被定义,输出我们的heh;定义了,反而不输出呢?
#if !defined (DEBUG)
printf("hehe\n");// DEBUG 被定义了,所以不输出 hehe
#endif
等价于
#ifndef DEBUG // ifndef == if not defined
printf("hehe\n");
#endif
return 0;
}
嵌套指令
#include<stdio.h>
int main()
{
#if defined(OS_UNIX)// 判断 OS_UNIX 是否被定义了,如果被定义了,则 执行编译下方语句,否,就不编译
#ifdef OPTION1 // 如果 OPTION1 被定义了,则 执行编译下方语句,否,就不编译
unix_version_option1();
#endif
#ifdef OPTION2// 如果 OPTION2 被定义了,则 执行编译下方语句,否,就不编译
unix_version_option2();
#endif
#elif defined(OS_MSDOS)// 如果 OS_UNIX 没有被定义了,则判断 OS_MSDOS 是否被定义,
// 如果定义了,则编译下面的语句,否,就不编译
#ifdef OPTION2// 如果 OPTION2 被定义了,则 执行编译下方语句,否,就不编译
wsdos_version_option2()
#endif
#endif
// #endif 是每个 条件编译 都要配备的
return 0;
}
11.预处理指令 #include(文件包含)
我们已经知道,#include 指令 可以 使另外一个文件(库) 被编译,就像 它 实际出现于 #include 指令的地方 一样。
#include<stdio.h>
假设我们定义了 一个 test,h 的头文件,如果 我们想使用 add 的功能 就必须 引用我们自定义的头文件 include "test.h"(注意 自定义 的 头文件 要用双引号来括起来)
这种 预处理指令 #include “test.h” 替换的方式很简单:预处理器 先删除这条指令,并用 包含的 头文件的内容 替换(就是把 test,h 头文件所包含的数据(test,h 里面放的是 add【加法】函数的声明)放进来,而位置就是 include 的位置)。
这样 一个源文件 被包含 10 次,那就被编译 10 次。
见下方附图:
附图1(我们这里包含了 3 次):

附图2:

头文件 被包含的方式:
1.本地文件包含
如果是 本地文件 也就是 我们自己创建的 头文件,也就是说 在使用 #include 包含 本地文件 的时候,要是用 ""【双引号】
即 : #include "add.h"
它的查找策略:现在源文件目录下查找,如果 该 头文件 所在目录下 未找到,编译器 就像 查找 库函数头文件 一样,在 标准位置查找 头文件。
如果找不到,就提示 编译错误。
linux 环境 的 标准头文件 的 路径
/usr/include
vs 环境 的 标准头文件 的路径:
"G:\Program Files (x86)\Microsoft Visual Studio 12.0\Common7\IDE\" (这个路径是我自己存储的位置,你们要看你们自己存储的位置)
方法:找到 vs 图标,反键 选择 打开文件位置,然后再反键,选择属性,你仔细看,就会看到 文件路径了
2. 库文件包含
#include<stdio.h>
查找策略: 查找头文件 直接 去标准路径下 去查找,如果找不到 就 提示 编译错误。
这样 是不是 可以说,对于 库文件来说 也可以 使用 "" 的形式包含?
答案是肯定的,可以
但是这样查找的效率就低些,当然这样也 不容易 区分 是 库文件 还是 本地文件 了。
嵌套文件包含
‘’

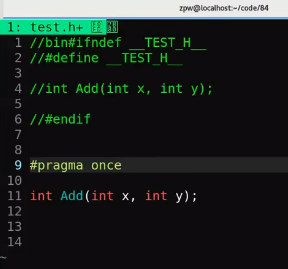
解决方法(修改 add.h)
第一种写法
#ifndef __ADD_H__// 如果它没有被定义
#define __ADD_H__// 我们就帮 它 定义下
int add(int x, int y);// 函数声明
#endif// 然后 #endif 收尾
这样写的好处是什么?
我来告诉你,第一次进入,add,h 没有定义,然后#define 定义了一波, 函数声明 被编译了
但是下一次进入程序的时候,再进行 判断 #ifndef __ADD_H__ 有没有被定义,那肯定是定义了的
所以 此次 函数声明 就不会纳入编译,以后也是一样。
这样我们 就 很好的 避免了 头文件 被 重复编译的情况 的发生
第二种写法
#pragma once
让我们来看看看程序怎么写
"test.h"
#pragma once // 只需写一个这个就OK了
int add(int x, int y);// 函数声明
其实 每个库文件 都 写了 #pragma once 防止 库文件被重复编译
而我们 自定义的头文件,就 需要 我们自己去写(用上面 任意方式都可以。
但是有一点: #pragma once,在比较 老的 编译器中,可能编译不过去。

总结
从这里就可以看出 条件编译 的用处:为了**避免 头文件 被 重复多次 编译(重复包含)**
如果我们像 stdio.h 头文件 里一样 在里加上 #pragma once 的 话,效果会是什么样的?
在 linux 系统中 输入 gcc test.c -E >test.i 【把 test.c 预编译的结果 重定向 放进 test.i 文件中】,输入 vim test,i,【打开 test,i 文件】

你就会发现,原本被包含三次的头文件,应该被编译三次,却值编译了一次

其他的 预处理指令
#error
#pragma
#line
...
如果大家想要深入了解,建议大家 参考 《C语言深度解剖》
在文章 的 最后 我们来讲讲 一道百度笔试题
写一个宏,计算 结构体中 某变量 相对于 首地址 的 偏移,并给说明
首先我们知道 有一个 函数 offsetof 是用来计算 结构体中成员 相对于 首地址的偏移量的
#include<stdio.h>
#include<stddef.h>
struct s
{
char c1;// 偏移量 0
int a;// 偏移量 4
char c2;// 偏移量 8
};
int main()
{
printf("%d\n", offsetof(struct s, c1));// 0
printf("%d\n", offsetof(struct s, a));// 4
printf("%d\n", offsetof(struct s, c2));// 8
return 0;
}
而我们接下来写的 宏 就是 模拟实现 offsetof
运用 宏的 参数 可以是 类型,这一点来实现 offsetof 函数功能的
首先我们要明白,结构体它的对齐原则,使我们的重点。
首成员 对齐地址 是 偏移量为0(相对于结构体的地址,首成员的地址就是结构体的地址,那么就不是为 0 嘛。) 的地址处
而 其他成员 的 对齐数,迫使它们对齐自身对齐数整数倍的地址处
如果我们将 结构体地址强制类型转换成 0,那么后面 地址 不就是 从 地址1开始嘛。
那么 结构体成员 各自对齐的地址,不就是我们想要的 结构体成员 各自的 偏移量 嘛、
#include<stdio.h>
struct s
{
char c1;// 偏移量 0
int a;// 偏移量 4
char c2;// 偏移量 8
};
struct_name 是 结构体的地址 member_name接收的是结构体成员
#define OFFSETOF(struct_name,member_name) (int)&(((struct_name*)0) -> member_name)
(int)&(((struct_name*)0) -> member_name)
我们 把 0 强制类型转换 为该结构体类型的地址,并且 作为 该结构体的地址(也就是说 该结构体的首成员地址是 0,那么后面的地址就自然而然的是 地址 1 ,2,3....)
我们再从这个地址,找成员,找到该成员之后,我们取这个成员的地址(该地址就是我们要找的偏移量)
因为 我们 offsetof 返回的是偏移量 是个整形
所以 我们 最后把 这个地址 强制转换成 整形
int main()
{
printf("%d\n", OFFSETOF(struct s,c1)) ;// 偏移量为 0
// printf("%d\n", OFFSETOF(struct s,c1)) ; -> printf("%d\n",(int)&( ( (struct s*) 0) -> c1) ;
首成员 对齐 地址 0 ,32位操作 系统(00000000 00000000 00000000 00000000)将其地址 当做 一个 整形输出 不就是 0.
// 而 首成员的偏移量就是0
printf("%d\n", OFFSETOF(struct s, a));//偏移量为 4
// -> printf("%d\n",(int)&( ( (struct s*) 0) -> a) ;
同理,a 的类型 是整形 根据 结构体存在 对齐原则,而 a 的 对齐数是 4 ,对齐 是 自身 对齐数整数倍的地址处,也就是 地址4
// 而 这个地址 4,也就是我们想要的 偏移量
// 00000000 00000000 00000000 00000004 转换成整形输出, 就是 4,偏移量也就为 4
printf("%d\n", OFFSETOF(struct s, c2));//偏移量为 8
// -> printf("%d\n",(int)&( ( (struct s*) 0) -> c2) ;
最后一个我就不讲,跟上面一样,尝试自己推一推
return 0;
}
