上次把环境安装好了以后,就可以搞自己的数据集了。 l
目录
如何把.xml文件都转成.txt文件
搞数据集
开始训练!
我搞得是扇贝,图片贼绿,如下图,700张绿扇贝向你袭来...

首先就是搞你自己的数据集,用labelimg标注软件对数据集进行标注,标注完成后,每张图像会生成对应的xml标注文件。 我们将图像和数据统一放置到一个文件夹下(!命名为英文的文件夹!),我们几个小兵搞得是自己的姓,后来都反工了,🤮
标注步骤:open文件夹,w快捷键,框就完了,默认的是voc数据集,也就是说保存之后是.xml格式,yolo那玩意用的是txt格式,好吧,我们几个无名小卒不配问为啥不直接搞txt格式。
那么就多了一个步骤,把.xml文件都转成.txt文件
如何把.xml文件都转成.txt文件
我按照一个超级超级厉害的学妹写的教程来的,在这里!!其实学妹已经写的很详细了,但是我这种傻子就是那种得喂嘴里的那种,所以自己写一个~
新建一个文件夹起名为trans,随便起,这是我起的,转化嘛这不是哈哈
在你喜欢的位置新建trans文件用来转化。在trans里新建data文件夹,在data下再新建三个文件夹(Annotations,images,ImageSets),其中Annotations下存放.xml文件,images下存放图片,并在ImageSets里面新建一个Main文件夹。我看教程的时候会有疑问就是,怎么平白无故多了些别的,说的跟图片上的不一样,你不用管,我说啥就是啥就完事。(没错我说的就是我鼠标点的那个data哈哈哈,先不用管)
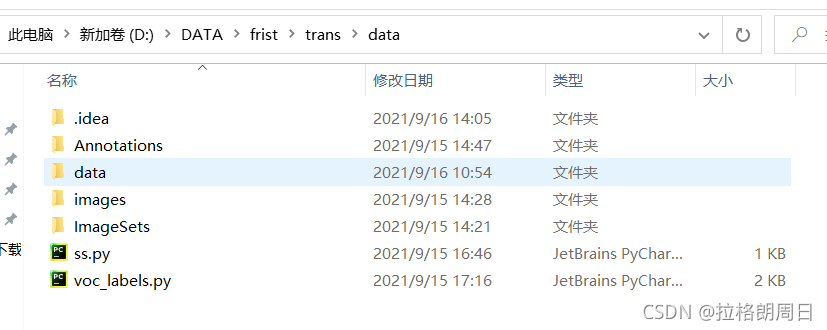
然后再你建的data文件夹下,右键打开pycharm,如下图新建一个ss.py文件(学妹起的这个名字我就也起了这个哈哈哈)
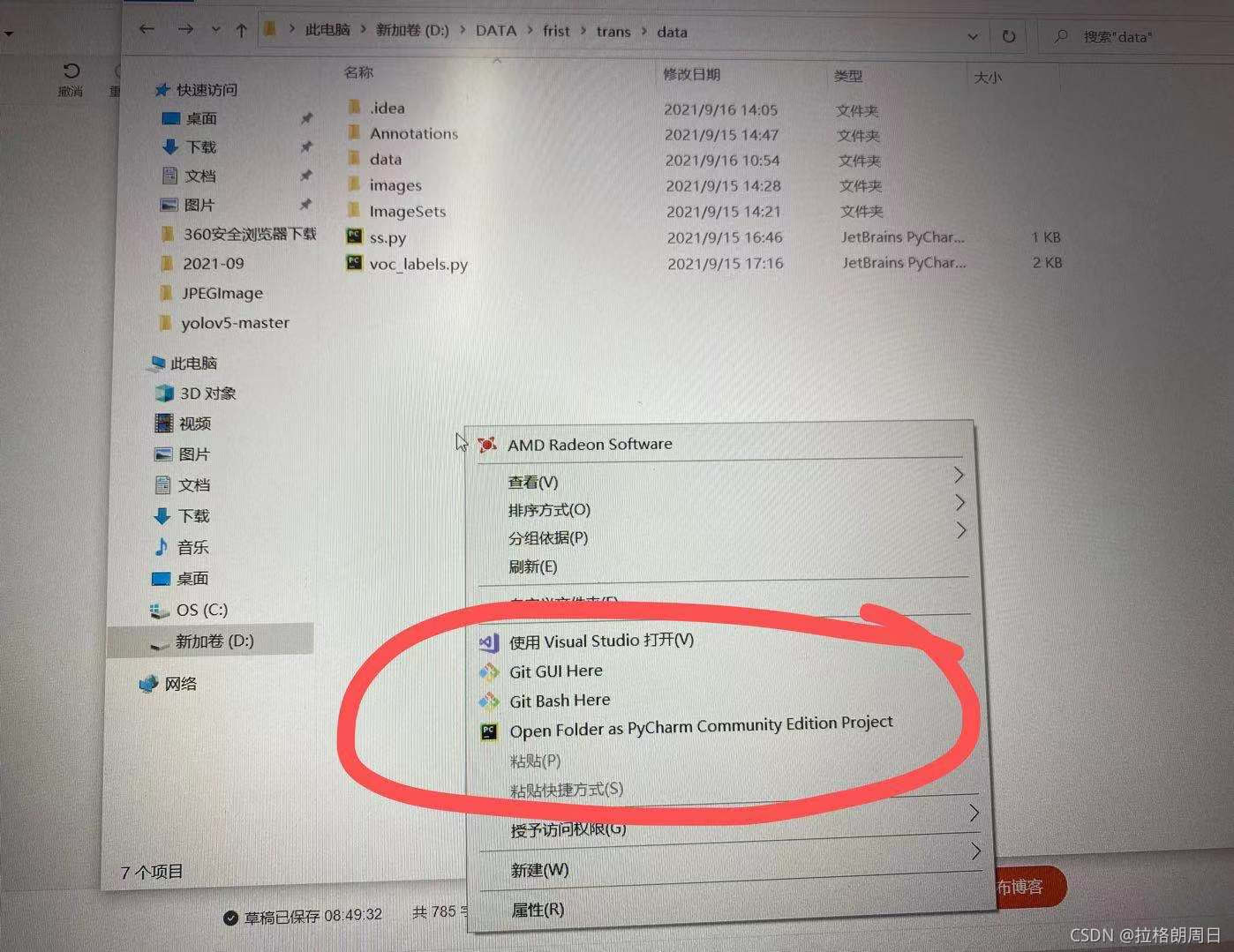
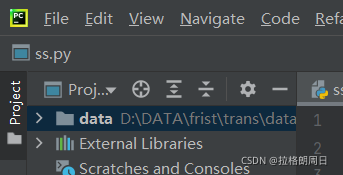
位置就在这里了,然后复制下面的代码(厉害的学妹写的 传送门)
import os
import random
trainval_percent = 0.2 # 可自行进行调节
train_percent = 1
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
# ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
# fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
# ftrainval.write(name)
if i in train:
ftest.write(name)
# else:
# fval.write(name)
else:
ftrain.write(name)
# ftrainval.close()
ftrain.close()
# fval.close()
ftest.close()
然后运行,跑完ss.py时会在Main文件夹下自动生成train.txt和test.txt,如下图
再data文件夹下建立一个data,如下图
然后还是开始的data文件夹下再建一个voc_labels.py(上面有图)
代码还是来自超级厉害的学妹,夸她!原文在这里!
这里只需改一个地方就是自己训练的类别名称,这个scallop就是绿绿的扇贝,剩下保持不动执行,就会再新建的data文件夹里生成标签文件labels。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test']
classes = ['scallop'] # 自己训练的类别
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id))
out_file = open('data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
lables里就是.txt文件了。
搞数据集
有了.txt的文件,就可以搞我们自己的数据集了。
新建一个datesets文件,位置如下图,就是那个trans的使命结束了,并排新建一个这个
在datesets下新建images 和labels两个文件夹
然后!在images下新建train和val,labels下也新建train和val,如下图
 比如说我一共有700张绿幽幽的扇贝图片,images下的train文件夹里放500张,val文件夹放200张(训练的要比val里多)
比如说我一共有700张绿幽幽的扇贝图片,images下的train文件夹里放500张,val文件夹放200张(训练的要比val里多)
对应的.txt文件放到labels里,同样的,train里放500个,val里放200个(对应的)。数据集就搞完了!!!
开始训练!
首先你得去网上下载yolov5的开源代码,如下图,yolov5有好几种,l,m,s,x,我一个小白用的是最简单的s。

1.在data文件夹下新建一个yaml文件,这个yaml文件吧,我不知道他咋来的,txt文件改后缀名吗?sorry,i dont know hhhh。所以就改别人的就行,下载下来的那个里面就有一个,coco128.yaml,应该没啥用,那我就用用。用pycharm打开
打开是这样的,找到打开是这种的就行。
改这里的train和val。改成你自己的位置(这是我的),往上翻我的那个文件夹,就可以看到我对应的很明白。

因为我的图片里只有绿幽幽的扇贝,所以类别数nc为1,名字是scallop。
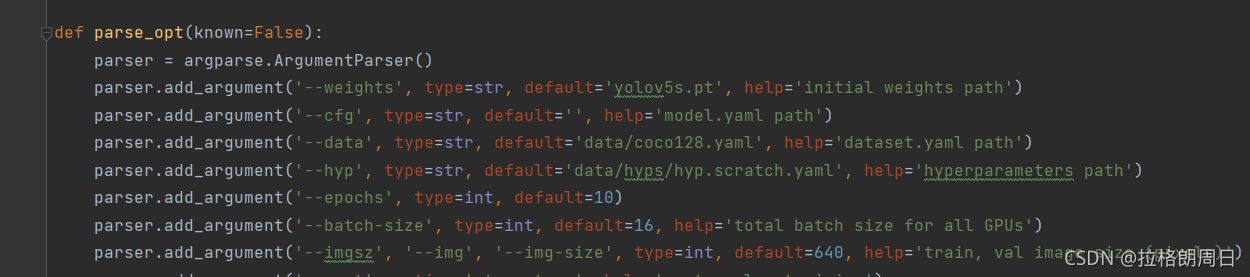
2.找到train.py文件,找到这段代码,data那行,那个yaml文件名得搞成你自己改的那个,如下图
3.执行train.py文件
跑不出来是正常现象,跑出来了才是狗屎运好吧,我的同门就跑出来了,我就...
没错,我就是跑不出来那伙的。
少环境就下环境,还是一样的anac里面下,环境下载方法就百度,安安安,安了4个环境吧,然后又错误,如下图
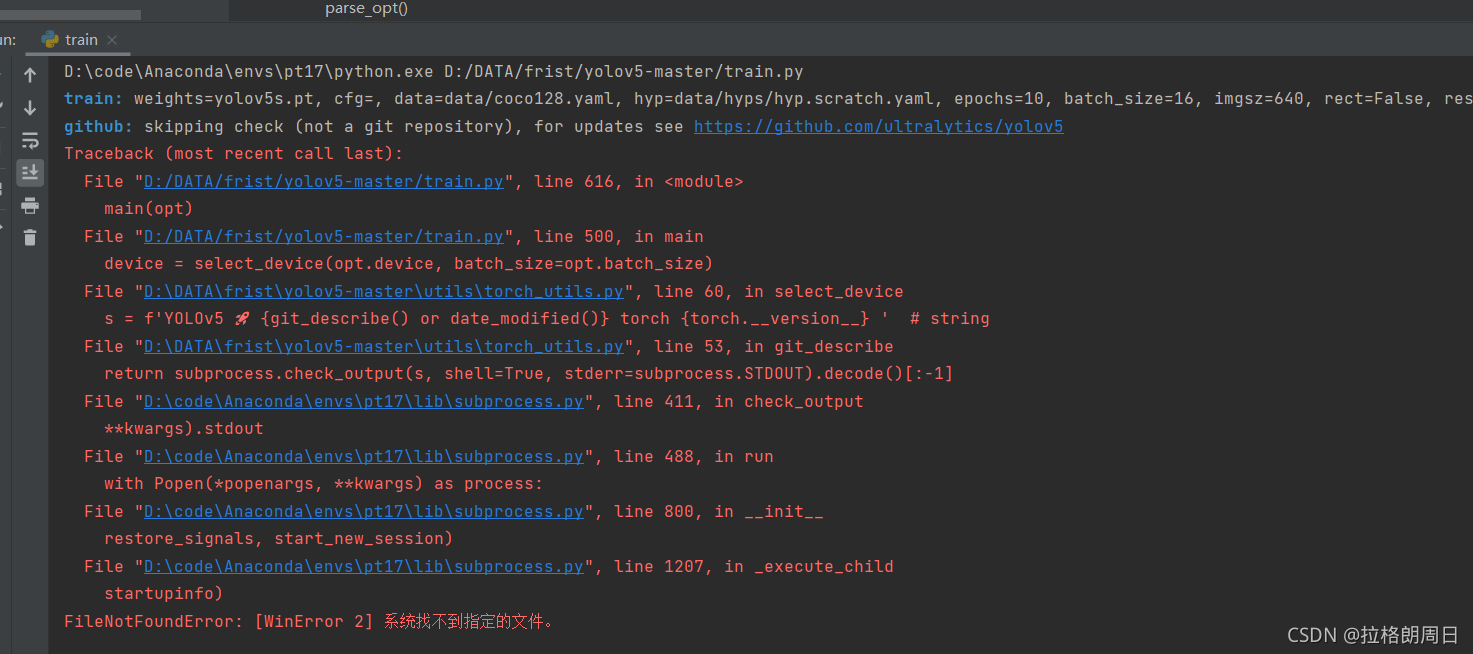
自己没搞出来,然后蔡哥分分钟搞定
因为底下四个错误都是环境里的,所以往上看,点一下,就可以看到错误来源,如图,这个git我还特意下载了,可能是不好使或者怎么样,反正yolo也没用上这个,就直接给他删掉
 这里有两行是因为我复制了,然后把原来的注释掉了,把git那玩意删掉,就可以了,如下图
这里有两行是因为我复制了,然后把原来的注释掉了,把git那玩意删掉,就可以了,如下图

再次运行,又出现了一个错误

有错误找百度,有错误找百度,然后加一段这个代码
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'变成这样
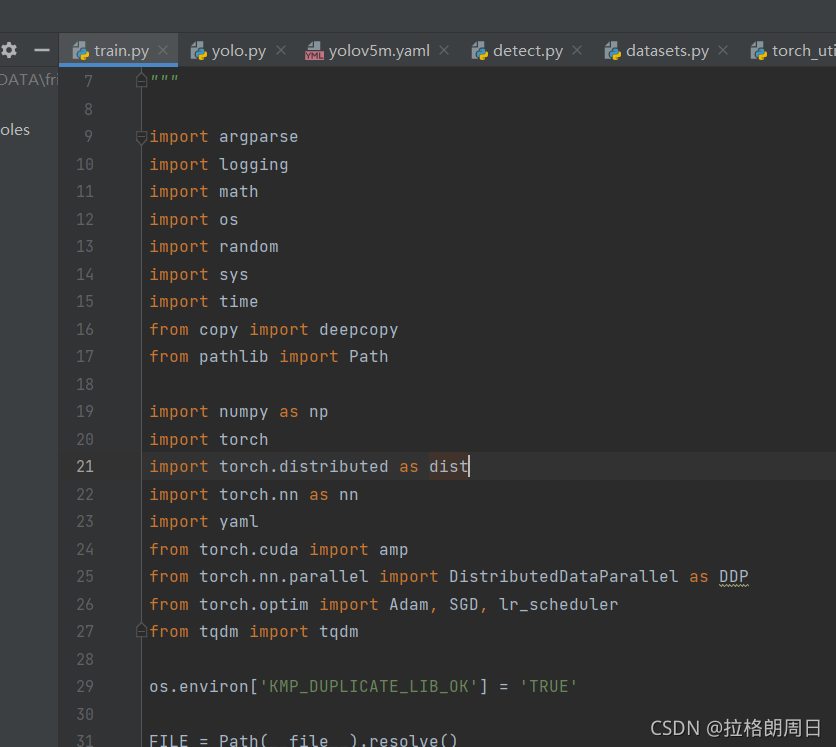
可以运行了,如图,权重就有了
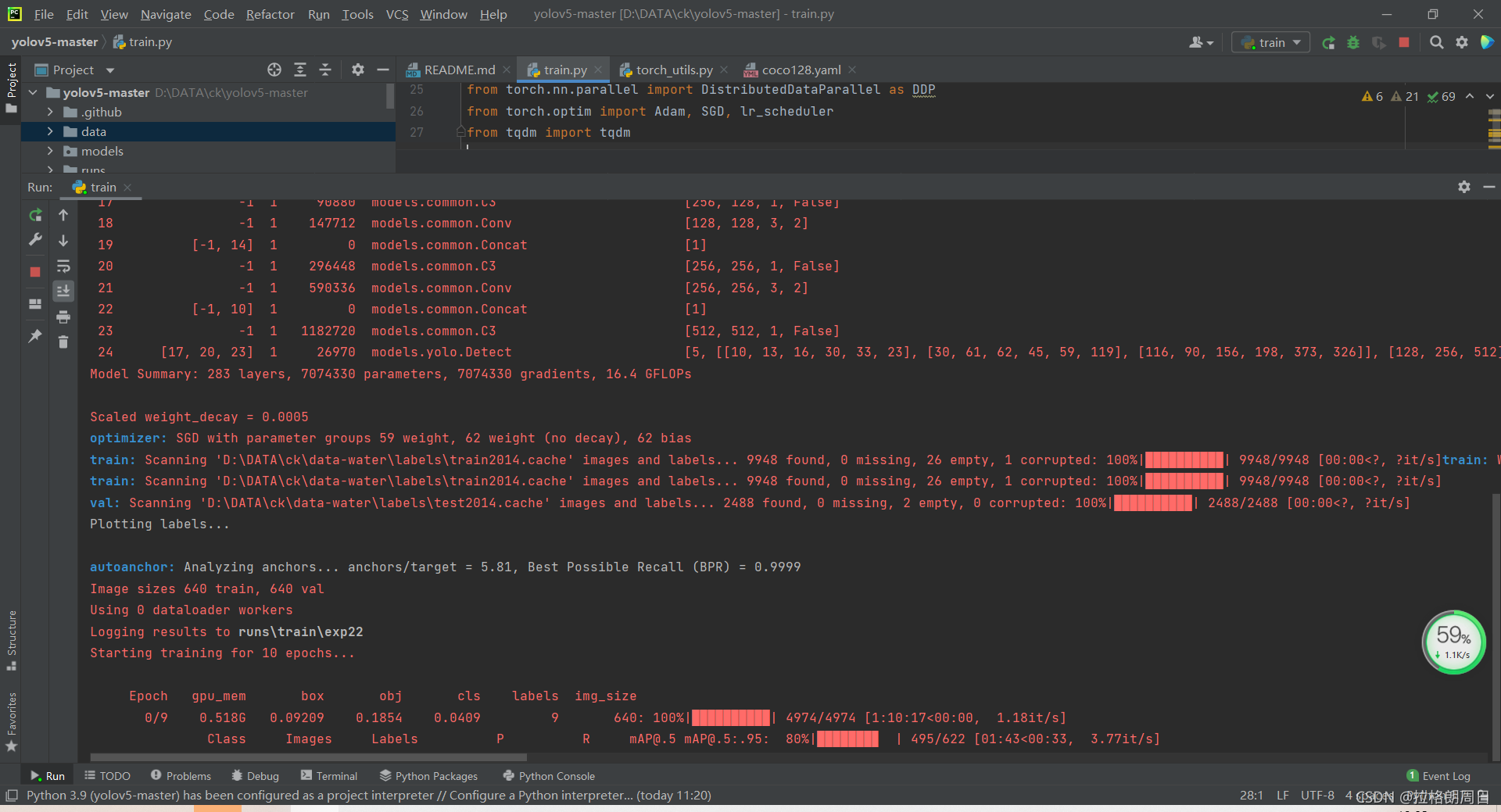
ok,very good.
剩下的下次写