java内存模型
jmm即java memory model,即java多线程内存模型,它定义了主存、工作内存抽象概念,底层对应着cpu寄存器、缓存、硬件内存、cpu指令优化等
jMM体现在以下几个方面
- 原子性-保证指令不会受线程上下文切换的影响
- 可见性-保证指令不会受cpu缓存的影响
- 有序性-保证指令不会受cpu指令并行优化的影响
原子性
原子(atomic)就是不可分割的意思,原子操作的不可分割有两层含义:
- 访问(读,写)某个共享变量的操作从其他线程来看,该操作要么已经执行完毕,要么尚未发生,即其他线程看不到当前操作的中间结果
- 访问同一组共享变量的原子操作是不能交错的
如现实生活中从ATM机取款,对于用户来说,要么操作成功,用户拿到钱,余额减少了增加了一条交易记录,要么没拿到钱,相当于取款操作没有发生
可见性
在多线程环境中,一个线程对某个共享变量进行更新之后,后续其他的线程可能无法立即读到这个更新的结果,这就是线程安全问题的另一种形式:可见性(visibility)
如果一个线程对共享变量更新后,后续访问该变量的其他线程可以读到更新的结果,称这个线程对共享变量的更新对其他线程可见,否则称这个线程对共享变量的更新对其他线程不可见
多线程因为可见性问题可能会导致其他线程读取到了旧数据(脏数据)
重排序
在多核处理器的环境下,编写的顺序结构,这种操作执行的顺序可能是没有保障的:
- 编译器可能会改变两个操作的先后顺序
- 处理器也可能不会按照目标代码的顺序执行
这种一个处理器上执行的多个操作,在其他处理器来看它的顺序与目标代码指定的顺序可能不一样,这种现象称为重排序
重排序是对内存访问有序操作的一种优化,可以在不影响单线程正确性的情况下提升程序的性能,但有可能对多线程的正确性产生影响,即可能导致线程安全问题
重排序与可见性问题类似,不是必然出现的
与内存操作顺序有关的几个概念
- 源代码顺序,就是源码中指定的内存访问顺序
- 程序顺序,处理器上运行的目标代码所指定的内存访问顺序
- 执行顺序,处理器实际执行时的实际执行顺序
- 感知顺序,给定处理器所感知到的该处理器及其他处理器的内存访问操作的顺序
可以把重排序分为指令重排序与存储子系统重排序两种
- 指令重排序主要是由jit编译器,处理器引起的,指程序顺序与执行顺序
- 存储子系统重排序是由高速缓存,写缓冲器引起的,感知顺序和执行顺序不一致
指令重排序
在源码顺序与程序顺序不一致 或者程序顺序与执行顺序不一致的情况下,我们就说发生了指令重排序
指令重排序是一种动作,确实对指令的顺序做了调整,重排序的对象指令
javac编译器一般不会执行指令重排序,而jit编译器可能执行指令重排序(jvm的jit可能执行重排序)
处理器也可能执行指令重排序,使得执行顺序与程序顺序不一致
指令重排不会对单线程程序的结果正确性产生影响,可能导致多线程程序出现非预期的结果
存储子系统重排序
存储子系统是指写缓冲器与高速缓存
高速缓存(Cache)是cpu中为了匹配与主内存处理速度不匹配而设计的一个高速缓存
写缓冲器(store buffer,write buffer)用来提高写告诉缓存操作的效率
即使处理器严格按照程序顺序执行两个内存访问操作,在存储子系统的作用下,其他处理器对这两个操作的感知顺序与程序顺序不一致,即这两个操作的顺序看起来像是发生了变化,这种现象称为存储子系统重新排序
存储子系统重排序,没有对真正的指令顺序进行调整,而是造成一种指令执行顺序被调整的现象(不同于指令重排序,指令重排序是动作)
存储子系统重排序对象是内存操作的结果
从处理器的角度来看,都内存就是从指定的 ram地址中加载数据到寄存器称为load操作;写内存就是把数据存储到指定的地址表示的ram存储单元中,称为store操作,内存重排序有以下四种可能:
- loadload重排序,一个处理器先后执行两个读操作L1和L2,其他处理器对两个内存操作的感知顺序可能是L2->L1
- storestore重排序,一个处理器先后执行两个写操作W1和W2,其他吃力气对两个内存操作的感知顺序可能是W2->W1
- loadstore重排序,一个处理器先执行读内存操作L1在执行写内存操作W1,其他处理器对两个内存的操作的感知顺序可能是W1->L1
- storeload重排序,一个处理器先执行写内存操作W1在执行读内存操作L1,其他处理器对两个内存操作的感知顺序可能是L1->W1
内存重排序与具体的处理器微架构有关,不同架构的处理器所允许的内存重排序不同
内存重排序可能会导致线程安全问题
内存模型图
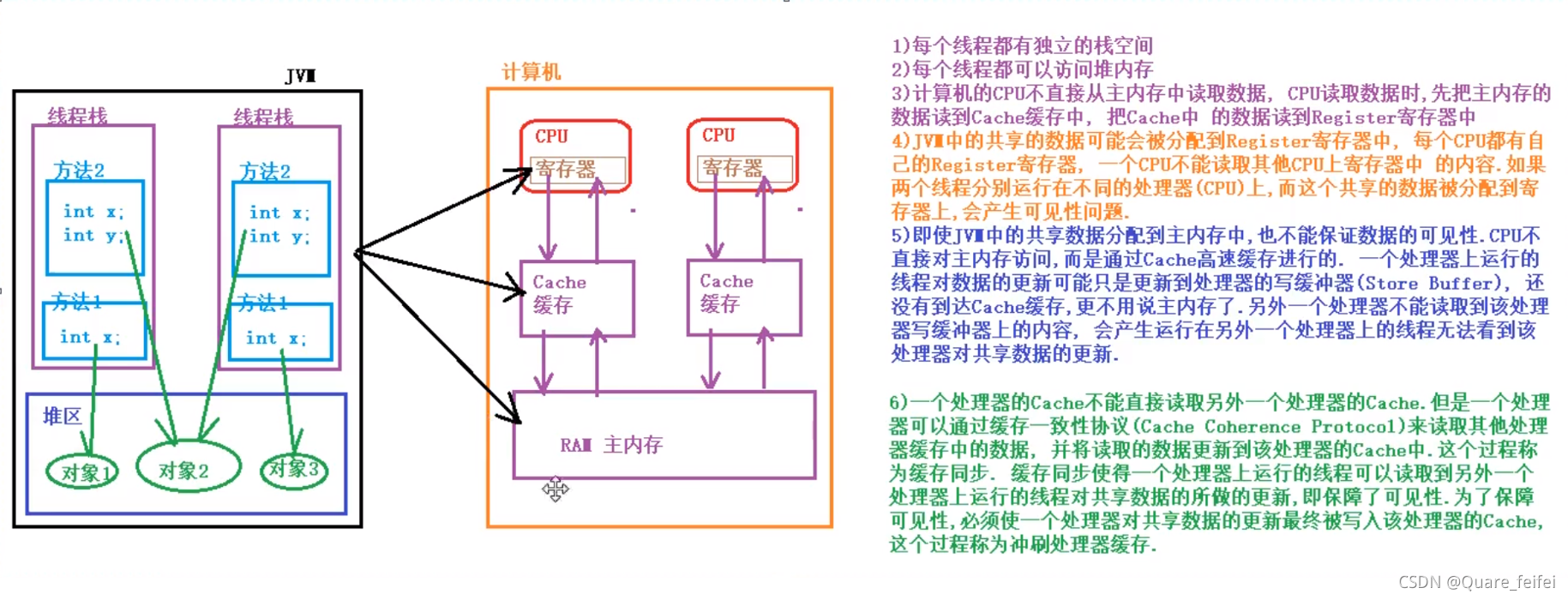

JMM数据原子操作
- read(读取):从主内存读取数据
- load(载入):将主内存读取到的数据写入工作内存
- use(使用):从工作内存读取数据来计算
- assign(赋值):将计算好的值重新赋值到工作内存中
- store(存储):将工作内存数据写入主内存
- write(写入):将store过去的变量值赋值给主内存中的变量
- lock(锁定):将主内存变量加锁,标识为线程独占状态
- unlock(解锁):将主内存变量解锁,解锁后其他线程可以锁定该变量
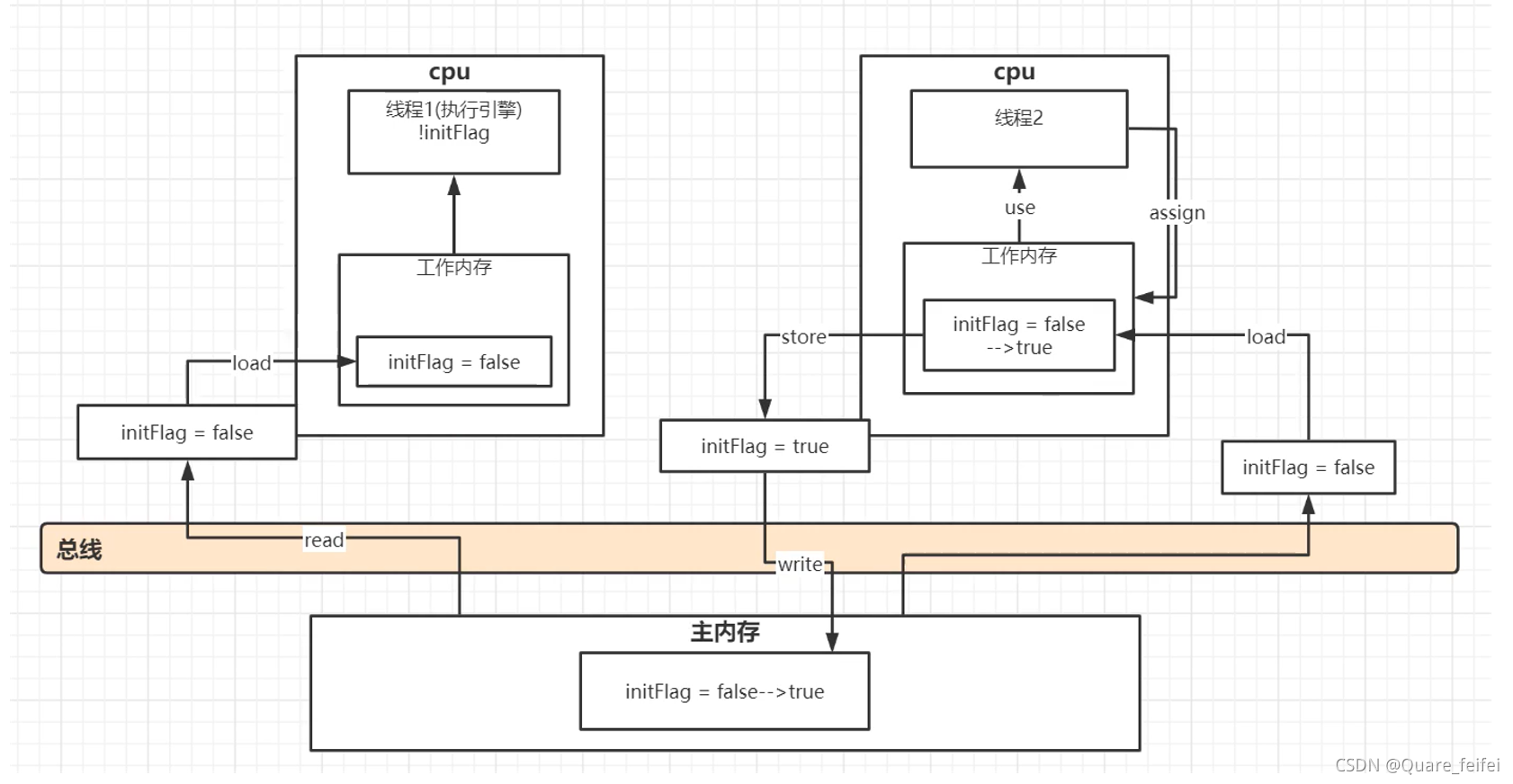
缓存一致性协议(MESI)
多个cpu从主内存读取同一个数据到各自的高速缓存,当其中某个cpu修改了缓存里的数据,该数据会立马同步回主内存,其他cpu通过总线嗅探机制可以感知数据的变化从而将自己缓存里的数据失效
volatile缓存可见性实现原理
底层实现主要是通过汇编lock前缀指令,它会锁定这块内存区域的缓存(缓存行锁定)并回写到主内存
1.会将当前处理器缓存行的数据立即写回到系统内存
2.这个写回内存的操作会引起在其他cpu里缓存了该内存地址的数据无效(mesi协议)
3.提供内存屏障功能,使lock前后指令不能重排序
- 并发编程三大特性:可见性、有序性、原子性
- vollatile保证可见性与有序性,但是不保证原子性,保证原子性需要借助synchronized这样的锁机制
- 指令重排序,在不影响单线程程序执行结果的前提下,计算机为了最大限度的发挥机器性能,会对机器指令重排序优化
- 源代码->1.编译器优化排序->2.指令级并行重排序->3.内存系统重排序->最终执行的指令序列
- 重排序会遵循as-if-serial与happens-before原则
as-if-serial语义
不管怎么重排序,单线程程序的执行结果不能被改变。编译器、runtime、处理器必须遵守as-if-serial的语义
为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果,但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序
happens-before原则

JVM规范定义的内存屏障

JVM规定volatile需要实现的内存屏障
-
对于volatile的写操作
会在前边加上storestore
会在后边加上storeload
即对于volatile的写操作在它之前,会保证在它之前的写操作已经全部结束而且已经被刷新到主存中,而且只有volatile的写操作执行结束,其后的读操作才能进行
-
对于volatile的读操作
会在后边加上loadload
会在后边加上loadstore
即对于volatile的读操作,保证读操作执行结束,才可以进行后续的读写操作
案例讲解
package com.cxf.test;
public class Singleton {
private Singleton(){}
private static volatile Singleton insetance=null;
public static Singleton getInsetance(){
if(insetance ==null){
synchronized (Singleton.class){
if(insetance==null){
insetance=new Singleton();
}
}
}
return insetance;
}
}
看了这么多来看一个比较经典的案例吧
double-check-locking实现的单例模式
相信了解过的人对于同步代码块和外边的判空操作也有一定的了解
即保证原子性和缩小锁的粒度,毕竟锁还是蛮影响速度的
那这里主要的就是volatile了为什么要有volatile呢
经过上边jmm的学习已经了解到volatile能保证可见性和有序性
而这里恰恰用到的就是volatile能禁止重排序这一特点
首先对于insetance=new Singleton();
这一操作它并不是原子性的操作
相信学过jvm的应该多少优点了解,对象的初始化大概分为这几步
- 类的检查即加载
- 分配内存空间
- 零值初始化
- 设置对象头,即mark word 、gc阈值、hashcode等的存储
- 构造器初始化并赋值
查看字节码指令也能得出
10 monitorenter
11 getstatic #2 <com/cxf/test/Singleton.insetance>
14 ifnonnull 27 (+13)
17 new #3 <com/cxf/test/Singleton>
20 dup
21 invokespecial #4 <com/cxf/test/Singleton.<init>>
24 putstatic #2 <com/cxf/test/Singleton.insetance>
27 aload_0
28 monitorexit
这里只截取了同步代码块内的内容
21是调用构造器初始化
24是赋值给instance
在实际运行时,这两个字节码指令有可能会被jit编译器进行重排序
如果是在单线程,貌似串行的执行是没有任何影响的
但是如果这两步进行了重排序,且此时同步代码块外的判空操作有线程执行,此时instance已经是一个半初始化的状态,就会直接返回instance,即返回了一个错误的实例对象
此时就需要给instance加上volatile,上边也有提过,volatile保证有序性,得益于内存屏障,此时对于instnce的赋值操作
会在前边加上storestore
会在后边加上storeload
即instance前的变量写入内存后才能开始instance的写操作
instance后的读操作要在instance的写操作执行结束后才能开始
此时构造器初始化和instance的赋值操作就不能在重排序
即dcl加volatile的原因
此问题在阿里巴巴开发规约中也有描述