导读
我们先来回顾一下交友平台用户表的表结构:
CREATE TABLE `user` (
`id` int(11) NOT NULL,
`user_id` int(8) DEFAULT NULL COMMENT '用户id',
`user_name` varchar(29) DEFAULT NULL COMMENT '用户名',
`user_introduction` varchar(498) DEFAULT NULL COMMENT '用户介绍',
`sex` tinyint(1) DEFAULT NULL COMMENT '性别',
`age` int(3) DEFAULT NULL COMMENT '年龄',
`birthday` date DEFAULT NULL COMMENT '生日',
PRIMARY KEY (`id`),
KEY `index_un_age_sex` (`user_name`,`age`,`sex`),
KEY `index_age_sex` (`age`,`sex`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
其中,user_introduction字段:用户介绍,里面允许用户填写非常长的内容,所以,我将这个字段的设为varchar(498),加上其他字段,单条记录的长度可能就会比较大了,这时,如果执行下面这条SQL:
select user_id, user_name, user_introduction from user where age > 20 and age < 50
假设用户表中已经存储300w条记录,执行上面的SQL,会发生什么情况呢?
对MySQL有初步了解的同学肯定知道Query Cache,它的作用就是缓存查询结果,通过首次查询时,建立SQL与结果的映射关系,相同SQL再次查询时,可以命中Query Cache,以此来提升后续相同查询的效率。
因此,对于上面的SQL查询,MySQL可以在首次执行这条SQL后,将查询结果写入Query Cache,下次相同SQL执行时,可以从Query Cache中取出结果返回。
但是,你有没有想过,如果满足查询条件的用户数超过10w,那么,这10w条记录能否完全写进Query Cache呢?
今天,我就从Query Cache的结构说起,逐步揭晓答案。
在《导读》中我提到MySQL通过建立SQL与查询结果的映射关系来实现再次查询的快速命中,那么,问题来了:为了实现这样的一个映射关系,总得有个结构承载这样的关系吧!那么,MySQL使用什么结构来承载这样的映射关系呢?
或许你已经想到了:HashMap!没错,MySQL的确使用了HashMap来表达SQL与结果集的映射关系。进而我们就很容易想到这个HashMap的Key和Value是什么了。
- Key:MySQL使用query + database + flag组成一个key。这个key的结构还是比较直观的,它表示哪个库的哪条SQL使用了Query Cache。
- Value:MySQL使用一个叫query_cache_block的结构作为Map的value,这个结构存放了一条SQL的查询结果。
Query Cache Block
那么,一条SQL的查询结果又是如何存放在query_cache_block中的呢?下面我们就结合《导读》中的SQL,来看看一个query_cache_block的结构:
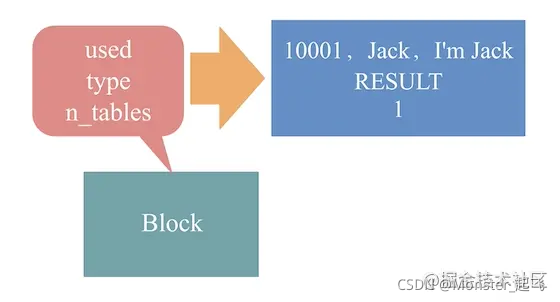
如上图所示,一个query_cache_block主要包含3个核心字段:
-
used:存放结果集的大小。MySQL通过block在内存中的偏移量 + 这个大小来获取结果集。如上图,假设《导读》中SQL查询的结果为<10001, Jack, I’m Jack>,那么,used为这个查询结果的大小。
-
type:Block的类型。包含{FREE, QUERY, RESULT, RES_CONT, RES_BEG, RES_INCOMPLETE, TABLE, INCOMPLETE}这几种类型。这里我重点讲解QUERY和RESULT,其他类型你可以自行深入了解。
-
QUERY:表示这个block中存放的是查询语句。为什么要缓存查询语句呢?
在并发场景中,会存在多个会话执行同一条查询语句,因此,为了避免重复构造《导读》中所说的HashMap的Key,MySQL缓存了查询语句的Key,保证查询Query Cache的性能。
-
RESULT:表示这个block中存放的是查询结果。如上图,《导读》中SQL的查询结果<10001, Jack, I’m Jack>放入block,所以,block类型为RESULT。
-
n_tables:查询语句使用的表的数量。那么,block又为什么要存表的数量呢?
因为MySQL会缓存table结构,一张table对应一个table结构,多个table结构组成一条链表,MySQL需要维护这条链表增删改查,所以,需要n_tables字段。
现在我们知道了一个query_cache_block的结构了,下面我简称block。
现在有这么一个场景:
已知一个block的大小是1KB,而《导读》中的查询语句得到的结果记录数有10w,它的大小有1MB,那么,显然一个block放不下1MB的结果,此时,MySQL会怎么做呢?
为了能够缓存1MB的查询结果,MySQL设计了一个双向链表,将多个block串联起来,1MB的数据分别放在链表中多个block里。于是,就有了下面的结构:逻辑块链表。
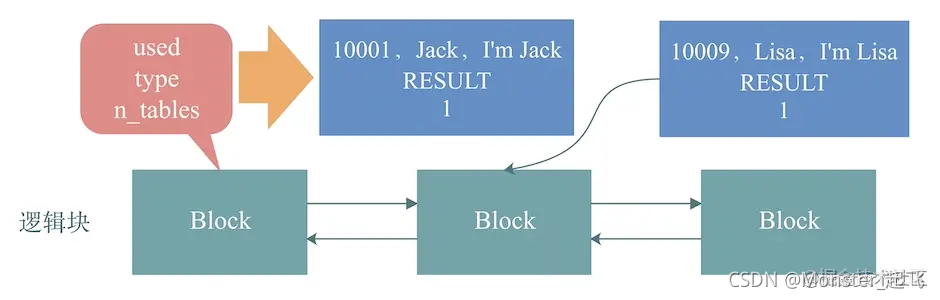
图中,MySQL将多个block通过一个双向链表串联起来,每个block就是我上面讲到的block结构。通过双向链表我们就可以将一条查询语句对应的结果集串联起来。
比如针对《导读》中SQL的查询结果,图中,前两个block分别存放了两个满足查询条件的结果:<10001,Jack,I’m Jack>和<10009,Lisa,I’m Lisa>。同时,两个block通过双向指针串联起来。
还是《导读》中的SQL案例,已知一个block的大小是1K,假设SQL的查询结果为<10001,Jack,I’m Jack>这一条记录,该记录的大小只有100Byte,那么,此时查询结果小于block大小,如果把这个查询结果放到1K的block里,就会浪费1024-100=924 字节的block空间。所以,为了避免block空间的浪费,MySQL又引入了一个新结构:
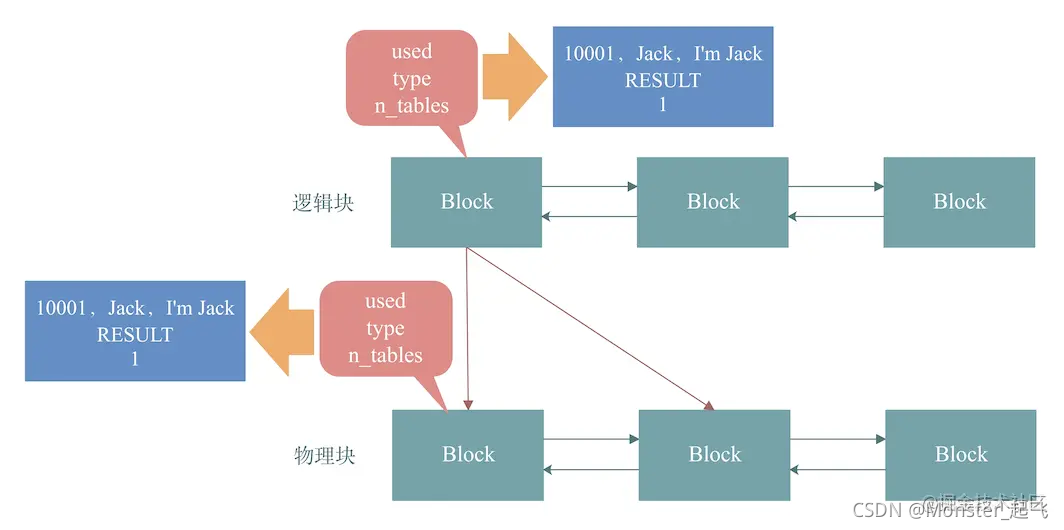
如上图,下面的物理块就是MySQL为了解决block空间浪费引入的新结构。该结构也是一个多block组成的双向链表。
以《导读》中的SQL为例,已知SQL查询的结果为<10001,Jack,I’m Jack>,那么,将逻辑块链表和物理块链表结合起来,这个结果在block中是如何表达的呢?
- 如上图,逻辑块链表的第一个block存放了<10001,Jack,I’m Jack>这个查询结果。
- 由于查询结果大小为100B,小于block的大小1K,所以,见上图,MySQL将逻辑块链表中的第一个block分裂,分裂出下面的两个物理块block,即红色箭头部分,将<10001,Jack,I’m Jack>这个结果放入第一个物理块中。其中,第一个物理块block大小为100B,第二个物理块block大小为924B。
讲完了query_cache_block,我想你应该对其有了较清晰的理解。但是,我在上面多次提到一个block的大小,那么,这个block的大小又是如何决定的呢?为什么block的大小是1K,而不是2K,或者3K呢?
要回答这个问题,就要涉及MySQL对block的内存管理了。MySQL为了管理好block,自己设计了一套内存管理机制,叫做query_cache_memory_bin。
下面我就详细讲讲这个query_cache_memory_bin。
Query Cache Memory Bin
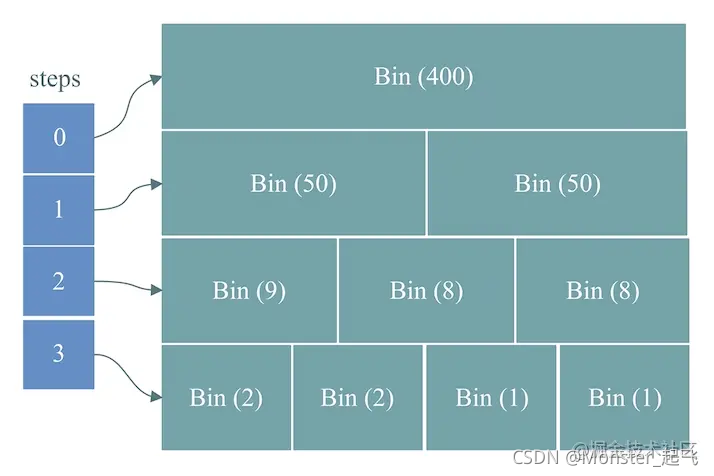
MySQL将整个Query Cache划分多层大小不同的多个query_cache_memory_bin(简称bin),如下图:
说明:
-
steps:为层号,如上图中,从上到下分为0、1、2、3这4层。
-
bin:每一层由多个bin组成。其中,bin中包含以下几个属性:
-
size:bin的大小
-
free_blocks:空闲的query_cache_block链表。每个bin包含一组query_cache_block链表,即逻辑块链表和物理块链表,也就是《Query Cache Block》中我讲到的两个链表组成一组query_cache_block。
-
每层bin的个数通过下面的公式计算得到:
bin个数 = 上一层bin数量总和 + QUERY_CACHE_MEM_BIN_PARTS_INC) * QUERY_CACHE_MEM_BIN_PARTS_MUL
其中,QUERY_CACHE_MEM_BIN_PARTS_INC = 1 ,QUERY_CACHE_MEM_BIN_PARTS_MUL = 1.2
因此,如上图,得到各层的bin个数如下:
- 第0层:bin个数为1
- 第1层:bin个数为2
- 第2层:bin个数为3
- 第3层:bin个数为4
- 每层都有其固定大小。这个大小的计算公式如下:
第0层的大小 = query_cache_size >> QUERY_CACHE_MEM_BIN_FIRST_STEP_PWR2 >> QUERY_CACHE_MEM_BIN_STEP_PWR2
其余层的大小 = 上一层的大小 >> QUERY_CACHE_MEM_BIN_STEP_PWR2
其中,QUERY_CACHE_MEM_BIN_FIRST_STEP_PWR2 = 4,QUERY_CACHE_MEM_BIN_STEP_PWR2 = 2
因此,假设query_cache_size = 25600K,那么,得到计算各层的大小如下:
- 第0层:400K
- 第1层:100K
- 第2层:25K
- 第3层:6K
- 每层中的bin也有固定大小,但最小不能小于QUERY_CACHE_MIN_ALLOCATION_UNIT。这个bin的大小的计算公式采用对数逼近法如下:
bin的大小 = 层大小 / 每一层bin个数,无法整除向上取整
其中,QUERY_CACHE_MIN_ALLOCATION_UNIT = 512B
因此,如上图,得到各层bin的大小如下:
- 第0层:400K / 1 = 400K
- 第1层:100K / 2 = 50K
- 第2层:25K / 3 = 9K,从最左边的bin开始分配大小:
- 第1个bin:9K
- 第2个bin:8K
- 第3个bin:8K
- 第3层:6K / 4 = 2K,从最左边的bin开始分配大小:
- 第1个bin:2K
- 第2个bin:2K
- 第3个bin:1K
- 第4个bin:1K
通过对MySQL管理Query Cache使用内存的讲解,我们应该猜到MySQL是如何给query_cache_block分配内存大小了。我以上图为例,简单说明一下:
由于每个bin中包含一组query_cache_block链表(逻辑块和物理块链表),如果一个block大小为1K,这时,通过遍历bin找到一个大于1K的bin,然后,把该block链接到bin中的free_blocks链表就行了。具体过程,我在下面会详细讲解。
在了解了query_cache_block、query_cache_memory_bin这两种结构之后,我想你对Query Cache在处理时用到的数据结构有了较清晰的理解。那么,结合这两种数据结构,我们再看看Query Cache的几种处理场景及实现原理。
Cache写入
我们结合《导读》中的SQL,先看一下Query Cache写入的过程:
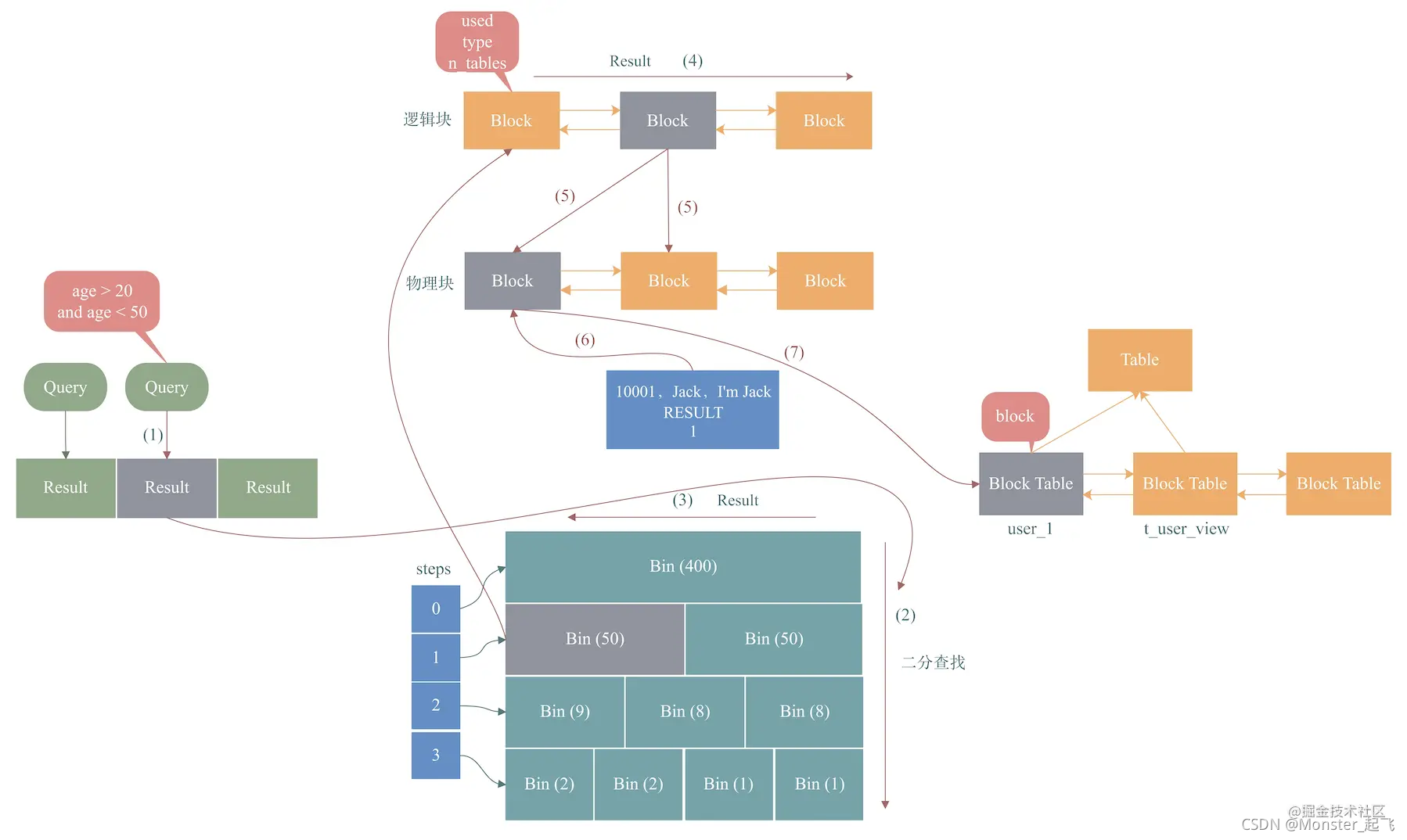
- 结合上面HashMap的Key的结构,根据查询条件age > 20 and age < 50构造HashMap的Key:age > 20 and age < 50 + user + flag,其中flag包含了查询结果,将Key写入HashMap。如上图,Result就是这个Key。
- 根据Result对query_cache_mem_bin的层进行二分查找,找到层大小大于Result大小的层。如上图,假设第1层为找到的目标层。
- 根据Result从右向左遍历第1层的bin(因为每层bin大小从左向右降序排列,MySQL从小到大开始分配),计算bin中的剩余空间大小,如果剩余空间大小大于Result大小,那么,就选择这个bin存放Result,否则,继续向左遍历,直至找到合适的bin为止。如上图灰色bin,选择了第2层的第一个bin存放Result。
- 根据Result从左向右扫描上一步得到的bin中的free_blocks链表中的逻辑块链表,找到第一个block大小大于Result大小的block。如上图,找到第2个逻辑块block。
- 假设Result大小为100B,第2个逻辑块block大小为1k,由于block大于Result大小,所以,分裂该逻辑块block为2个物理块block,其中,分裂后第一个物理块block大小为100B,第二个物理块block大小为924B。
- 将Result结果写入第1个物理块block。如上图,将<10001, Jack, I’m Jack>这个Result写入灰色的物理块block。
- 根据Result所在的block,找到对应的block_table,更新table信息到block_table中。
Cache失效
当一个表发生改变时,所有与该表相关的cached queries将失效。一个表发生变化,包含多种语句,比如 INSERT, UPDATE, DELETE, TRUNCATE TABLE,ALTER TABLE, DROP TABLE, 或者 DROP DATABASE。
Query Cache Block Table
为了能够快速定位与一张表相关的Query Cache,将这张表相关的Query Cache失效,MySQL设计一个数据结构:Query_cache_block_table。如下图:
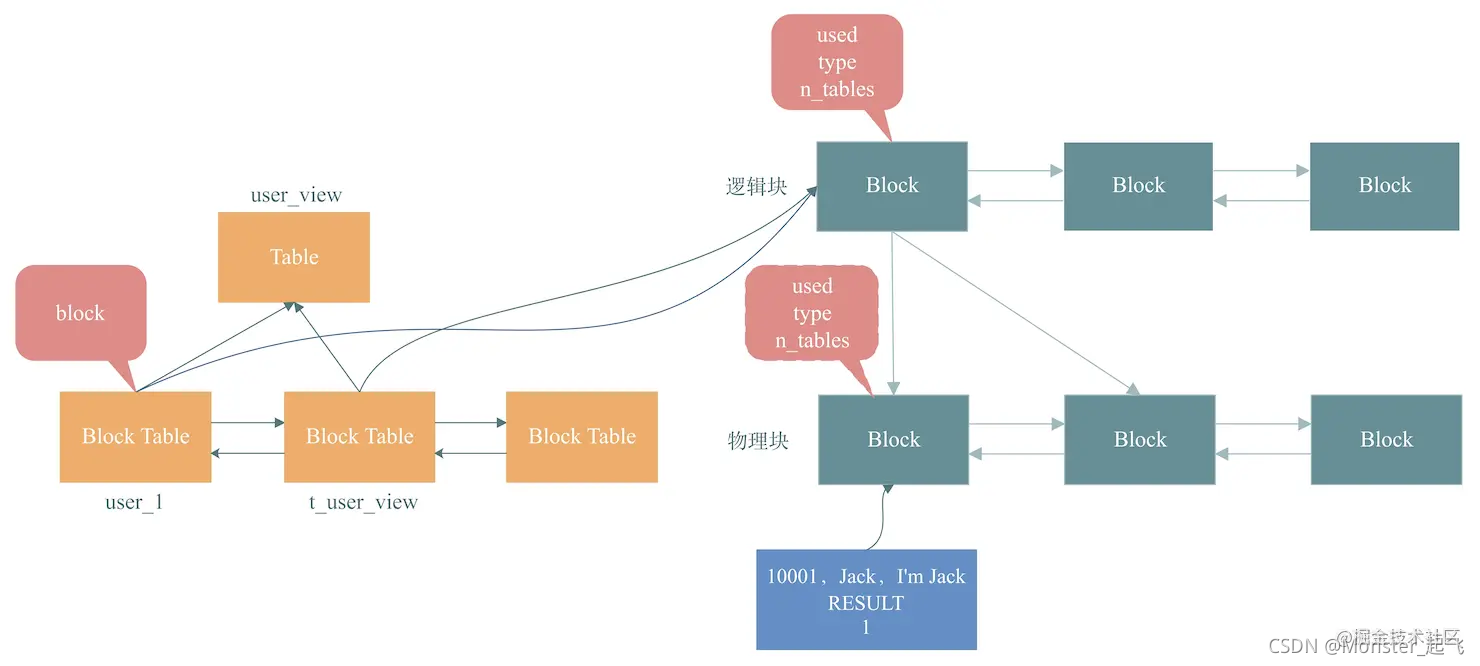
这是一个双向链表,对于一条SQL,如果包含多表联接,那么,就可以将这条SQL对应多张表链接起来,再插入这张链表,比如,我们把user和t_user_view(访客表)联接,查询用户访客信息,那么,在图中,假设逻辑块链表存放就是联表查询的结果,因此,我们就看到user表和t_user_view都指向了该逻辑块链表。
我们来看一下这个结构包含的核心属性:
-
block:与一张表相关的query_cache_block链表。如上图是user表的query_cache_block_table,该block中的block属性指向了逻辑块block链表,该链表中第1个block包含《导读》中SQL的查询结果<10001, Jack, I’m Jack>。
-
table:同样以user和t_user_view(访客表)联接,查询用户访客信息为例,这时,我对这个访客信息创建了视图,那么,MySQL如何表达表的关系呢?为了解决这个问题,MySQL引入了table,通过这个table记录视图信息,视图来源表都指向这个table来表达表的关系。如上图,user和t_user_view都指向了user_view,来表示user和t_user_view(访客表)对应的视图是user_view。
和Query Cache的HashMap结构一样,为了根据表名可以快速找到对应的query_cache_block,MySQL也设计了一个表名跟query_cache_block映射的HashMap,这样,MySQL就可以根据表名快速找到query_cache_block了。
通过上面这些内容的讲解,我想你应该猜到了一张表变更时,MySQL是如何失效Query Cache的?
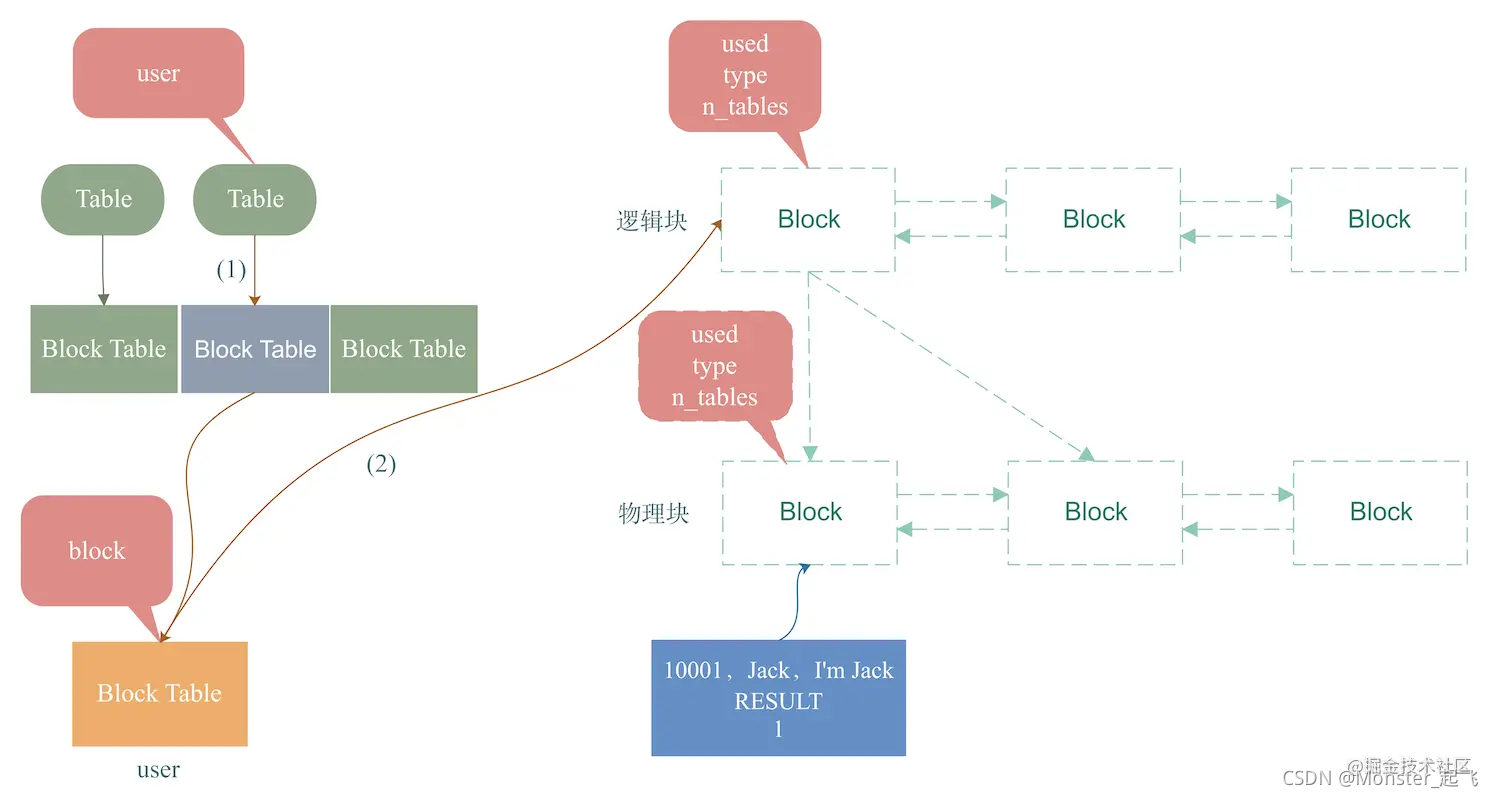
我们来看下上面这张图,关注红线部分:
- 根据user表找到其对应的query_cache_block_table。如上图,找到第2个table block。
- 根据query_cache_block_table中的block属性,找到table下的逻辑块链表。如上图,找到了右侧的逻辑块链表。
- 遍历逻辑块链表及每个逻辑块block下的物理块链表,释放所有block。
Cache淘汰
如果query_cache_mem_bin中没有足够空间的block存放Result,那么,将触发query_cache_mem_bin的内存淘汰机制。
这里我借用《Cache写入》的过程,一起来看看Query Cache的淘汰机制:
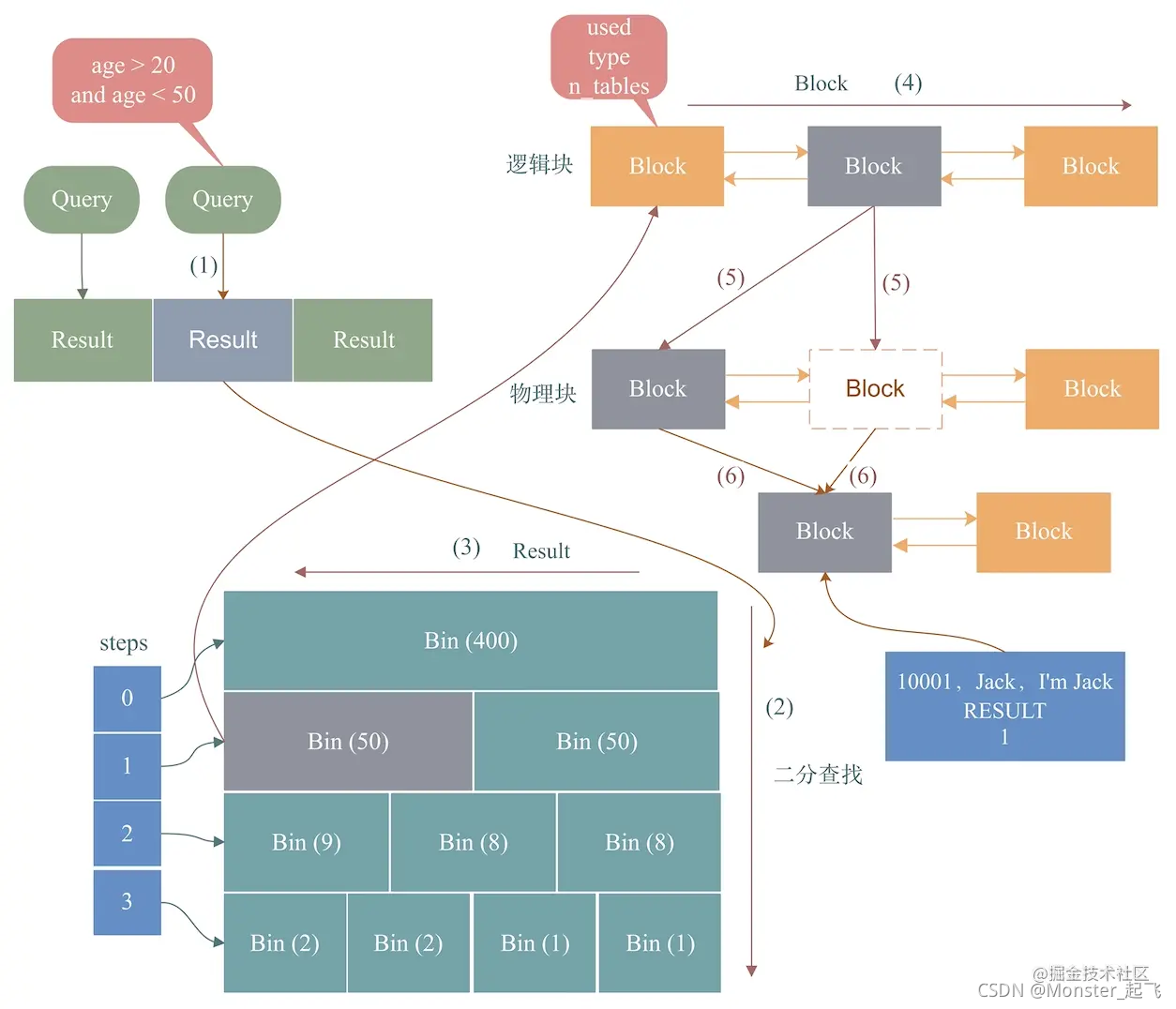
- 结合上面HashMap的Key的结构,根据查询条件age > 20 and age < 50构造HashMap的Key:age > 20 and age < 50 + user + flag,其中flag包含了查询结果,将Key写入HashMap。如上图,Result就是这个Key。
- 根据Result对query_cache_mem_bin的层进行二分查找,找到层大小大于Result大小的层。如上图,假设第1层为找到的目标层。
- 根据Result从右向左遍历第1层的bin(因为每层bin大小从左向右降序排列,MySQL从小到大开始分配),计算bin中的剩余空间大小,如果剩余空间大小大于Result大小,那么,就选择这个bin存放Result。如上图灰色bin,选择了第2层的第一个bin存放Result。
- 根据Result从左向右扫描上一步得到的bin中的block链表中的逻辑块链表,找到第一个block大小大于Result大小的block。如上图,找到第2个逻辑块block。
- 假设Result大小为100B,第2个逻辑块block大小为1k,由于block大于Result大小,所以,分裂该逻辑块block为2个物理块block,其中,分裂后第一个物理块block大小为100B,第二个物理块block大小为924B。
- 由于第1个物理块block已经被占用,所以,MySQL不得不淘汰该block,用以放入Result,淘汰过程如下:
- 发现相邻的第2个物理块block最少使用,所以,将该物理块和第1个物理块block合并成一个新block。如上图右侧灰色block和虚线block合并成下面的一个灰色block。
- 将Result结果写入合并后的物理块block。如上图,将<10001, Jack, I’m Jack>这个Result写入合并后的灰色block。
在Cache淘汰这个场景中,我们重点关注一下第6步,我们看下这个场景:
- 从第1个物理块block开始扫描,合并相邻的第2个block跟第1个block为一个新block
- 如果合并后block大小仍然不足以存放Result,继续扫描下一个block,重复第1步
- 如果合并后block大小可以存放Result,结束扫描
- 将Result写入合并后block
通过上面的场景描述,我们发现如果Result很大,那么,MySQL将不断扫描物理块block,然后,不停地合并block,这是不小的开销,因此,我们要尽量避免这样的开销,保证Query Cache查询的性能。
有什么办法避免这样的开销呢?
我在最后小结的时候回答一下这个问题。
小结
好了,这篇内容我讲了很多东西,现在,我们来总结一下今天讲解的内容:
- 数据结构:讲解了Query Cache设计的数据结构:
| 数据结构 | 说明 |
|---|---|
| Query_cache_block | 存放了一条SQL的查询结果 |
| Query_cache_mem_bin | query_cache_block的内存管理结构 |
| Query_cache_block_table | 一张表对应一个block_table,方便快速失效query cache |
- Query Cache处理的场景:Cache写入、Cache失效和Cache淘汰。
最后,我们再回头看一下文章开头的那个问题:10w条用户记录是否可以写入Query Cache?我的回答是:
-
我们先对用户表的10w记录大小做个计算:
用户表包含user_id(8),user_name(29),user_introduction(498),age(3),sex(1)这几个字段,按字段顺序累加,一条记录的长度为8+30(varchar类型长度可以多存储1或2byte)+500+3+1=542byte,那么,10w条记录最大长度为542 * 10w = 54200000byte。
如果要将10w条记录写入Query Cache,则需要将近54200K大小的Query Cache来存储这10w条记录,而Query Cache大小默认为1M,所以,如果字段user_introduction在业务上非必须出现,请在select子句中排除该字段,减少查询结果集的大小,使结果集可以完全写入Query Cache,**这也是为什么DBA建议开发不要使用select 的原因,但是如果select 取出的字段都不大,查询结果可以完全写入Query Cache,那么,后续相同查询条件的查询性能也是会提升的,😁。 -
调大query_cache_size这个MySQL配置参数,如果业务上一定要求select所有字段,而且内存足够用,那么,可以将query_cache_size调至可以容纳10w条用户记录,即54200K。
-
调大query_cache_min_res_unit这个MySQL配置参数,使MySQL在第一次执行查询并写入Query Cache时,尽可能不要发生过多的bin合并,减少物理块block链表的合并开销。那么,query_cache_min_res_unit调成多少合适呢?
这需要结合具体业务场景综合衡量,比如,在用户中心系统中,一般会有一个会员中心的功能,而这个功能中,用户查询自己的信息是一个高频的查询操作,为了保证这类操作的查询性能,我们势必会将这个查询结果,即单个用户的基本信息写入Query Cache,在我的回答的第1条中,我说过一条用户记录最大长度为542byte,结合10w条用户记录需要54200K的Query Cache,那么,设置query_cache_min_res_unit = 542byte就比较合适了。
这样,有两点好处:
- 保证查询单个用户信息,其直接可分配的bin大小大于542byte,写入单个用户信息时可以避免了bin的合并和空间浪费。
- 10w条用户记录写入Query Cache,虽然第一次分配缓存时,仍然需要合并bin,但是,综合单用户查询的场景,这个合并过程是可以接受的,毕竟,只会在第一次写缓存时发生bin合并,后续缓存失效后,再次分配时,可以直接取到合并后的那个bin分配给10w条记录,不会再产生bin的合并,所以,这个合并过程是可以接受的。
调大query_cache_limit这个MySQL配置参数,我在本章节中没有提到这个参数,它是用来控制Query Cache最大缓存结果集大小的,默认是1M,所以,10w条记录,建议调大这个参数到54200K。
思考题
最后,对比前面《Group By 深度优化,真是绝了!》这篇文章,发现MySQL特别喜欢自己实现内存的管理,而不用Linux内核的内存管理机制(比如:伙伴系统),为什么呢?
The End
如果你觉得写得不错,记得点赞哦!
作者:谦虚的小K
来源:https://juejin.cn/post/6965793803420778510