Python 自动化 这一专栏,将以目的为导向,以简化或自动化完成工作任务为目标,将Python运用于实践中,解决实际问题,以激发读者对这门脚本语言的学习兴趣。在开始Python自动化相关实战的学习前,建议对 Python基础 以及 Python 爬虫 的相关知识展开一定的学习与了解。对此博客已开设相关专栏,可点击直达。
往期内容提要:
- 【Python基础】 动态HTML处理之Selenium与PhantomJS
- 【Python基础】 机器视觉与机器图像识别之Tesseract
- 【Python自动化】 selenium之验证码识别
- 【Python自动化】 selenium之网课学习自动化
- 【Python自动化】 selenium之文件批量下载(本文)
- 【Python实战】疫情期间每日健康报送任务的自动化处理
- 【Python实战】教务管理系统:成绩、课表查询接口设计及抢课、监控功能实现
“文件下载”无论是在网络爬虫,还是自动化领域,都是最为常见的需求。此前作者曾在 《教务管理系统:成绩、课表查询接口设计及抢课、监控功能实现》 一文中,在图形验证码的识别中首先就介绍了进行了实战展示。在这一篇文章中,将对文件下载作出一个相对系统的概括与总结。
一般而言,文件下载可以通过两个方式实现。其一, 发包收包解决;其二,selenium解决。
针对第一种方法,曾在 《教务管理系统:成绩、课表查询接口设计及抢课、监控功能实现》 一文中予以过展示。基本逻辑在于构造get请求,发包后储存返回结果。
url = '手动打码/Image.aspx'
def get_pic():
# 验证码请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
"cookie": "varPartNewsManage.aspx=10"
}
re_pic = requests.get(url, headers=headers)
response = re_pic.content
file = "C:\\Users\\john\\Desktop\\1\\" + ".png"
playFile = open(file, 'wb')
playFile.write(response)
playFile.close()
此外,通过selenium方式解放双手,实现文件批量下载在实战中也是较为常见的方法。接下来将以网课梦魇——“超星学习通”课程音频下载为例,介绍如何利用selenium实现网课文件批量下载。

环境所需必要模块:
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.common.exceptions import TimeoutException, WebDriverException
from datetime import datetime
from time import sleep
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
文件下载基本步骤梳理:
- 访问目标站点
- 获取下载源
- 指定存储路径
- 实现下载
一、访问目标站点
目标站点的访问方法可参见往期Python自动化文章 《【Python自动化】登陆与识别》,而文章举例站点“超星学习通”的URL作为教师分享链接,无需登陆验证。URL格式如下:
http://apps.wh.chaoxing.com/screen/vclass/view/xxxxx-xxxxx-xxxxx-xxxxx-xxxxxxxxxx
因此,仅需要简单调用webdriver,实现目标站点的访问:
chrome_options = Options()
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome()
browser = webdriver.Chrome(chrome_options=chrome_options)
url_list = [
"http://apps.wh.chaoxing.com/screen/vclass/view/xxxxx-xxxxx-xxxxx-xxxxx-xxxxxxxxxx1",
"http://apps.wh.chaoxing.com/screen/vclass/view/xxxxx-xxxxx-xxxxx-xxxxx-xxxxxxxxxx2",
"http://apps.wh.chaoxing.com/screen/vclass/view/xxxxx-xxxxx-xxxxx-xxxxx-xxxxxxxxxx3"
]
browser.get(url_list[0])
# browser.maximize_window()
wait = WebDriverWait(browser,10,0.5)
二、获取下载源
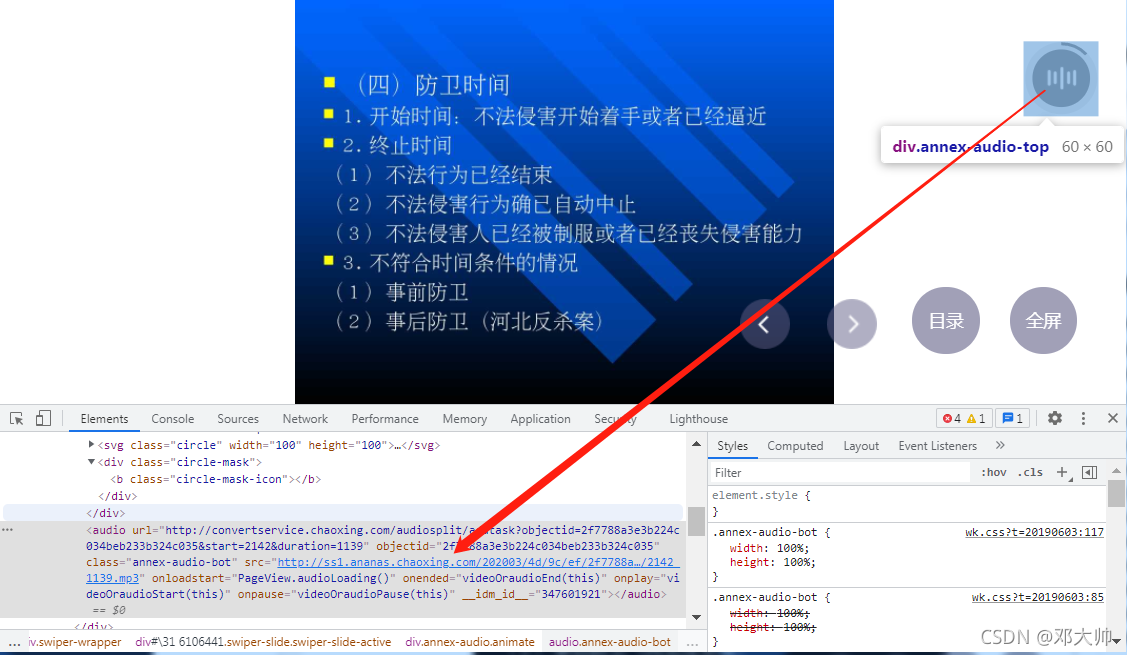
首先通过开发者模式定位音频元素,在能够获取单页音频文件直链的基础上,采用遍历的方式获取全站文件直链。
link = WebDriverWait(browser, 10).until(lambda x: x.find_elements_by_xpath("//audio"))
list=[]
list_count = 0
for i in link:
list.append(i.get_attribute('src'))
#print(list)
#print(type(list))
browser.quit()

三、指定存储路径并实现下载
z = []
for i in list:
time = datetime.now().strftime('%H-%M-%S----')
data = requests.get(i, stream=True)
z.append(time)
with open('C:\\Users\\john\\Desktop\\1\\' + time + i[-8:-5] + '.mp3', 'wb') as f:
for j in data.iter_content(chunk_size=512):
f.write(j)
print(i + '写出完毕!')
print("一共 {} 个,下载完成 {} 个 ".format(len(list),len(z)))
其中存储文件的命名方式多样,这里选择时间戳的方式为音频排序:


至此,本文也就进入尾声了。本文的撰写来自于开发中的一点心得体会,主要目的在于通过实践提高读者Python学习兴趣,解决实际问题。供对这一领域感兴趣的读者以参考借鉴。希望本文能够起到抛砖引玉之效,也欢迎大家的批评交流。
如果您有任何疑问或者好的建议,期待你的留言、评论与关注!