前言
我们知道,「 顺序表 」 可以 「 快速索引 」 数据,而 「 链表 」 则可以快速的进行数据的「 插入 和 删除 」。那么,有没有一种数据结构,可以快速的实现 「 增 」「 删 」「 改 」「 查 」 呢?
本文,我们就来聊一下一种 「 树形 」 的数据结构,它既有链表的快速插入与删除的特点,又有顺序表快速查找的优势。它就是:
「 二叉搜索树 」


二叉树的查找

二叉搜索树的删除

二叉搜索树的插入
点击我跳转末尾 获取 粉丝专属 《算法和数据结构》源码。
文章目录
- 前言
- 一、二叉树的概念
- 1、二叉树的性质
- 2、特殊二叉树
- 1)斜树
- 2)满二叉树
- 3)完全二叉树
- 3、二叉树的性质
- 1)性质1
- 2)性质2
- 3)性质3
- 4)性质4
- 二、二叉树的存储
- 1、顺序表存储
- 1)完全二叉树
- 2)非完全二叉树
- 3)稀疏二叉树
- 2、链表存储
- 三、二叉树的遍历
- 1、 前序遍历
- 1)算法描述
- 2)源码详解
- 2、 中序遍历
- 1)算法描述
- 2)源码详解
- 3、 后序遍历
- 1)算法描述
- 2)源码详解
- 四、二叉搜索树的概念
- 1、定义
- 2、用途
- 3、数据结构
- 4、结点创建
- 五、二叉搜索树的操作
- 1、查找
- 1)算法原理
- 2)动图演示
- 3)源码详解
- 2、插入
- 1)算法原理
- 2)动图演示
- 3)源码详解
- 3、删除
- 1)算法原理
- 2)动图演示
- 3)源码详解
- 4、构造
- 1)算法原理
- 2)源码详解
- 六、二叉搜索树的遍历
- 1、先序遍历
- 2、中序遍历
- 3、后序遍历
- 七、二叉搜索树的总结
- 粉丝专属福利
一、二叉树的概念
在学习二叉搜索树之前,我们首先需要了解下什么是二叉树。
1、二叉树的性质
二叉树是一种树,它有如下几个特征:
1)每个结点最多 2 棵子树,即每个结点的孩子结点个数为 0、1、2;
2)这两棵子树是有顺序的,分别叫:左子树 和 右子树;
3)如果只有一棵子树的情况,也需要区分顺序,如图所示:

b
b
b 为
a
a
a 的左子树;

c
c
c 为
a
a
a 的右子树;
2、特殊二叉树
1)斜树
所有结点都只有左子树的二叉树被称为左斜树。

所有结点都只有右子树的二叉树被称为右斜树。

斜树有点类似线性表,所以线性表可以理解为一种特殊形式的树。
2)满二叉树
对于一棵二叉树,如果它的所有根结点和内部结点都存在左右子树,且所有叶子结点都在同一层,这样的树就是满二叉树。

满二叉树有如下几个特点:
1)叶子结点一定在最后一层;
2)非叶子结点的度为 2;
3)深度相同的二叉树,满二叉树的结点个数最多,为
2
h
−
1
2^h-1
2h−1(其中
h
h
h 代表深度)。
3)完全二叉树
对一棵具有
n
n
n 个结点的二叉树按照层序进行编号,如果编号
i
i
i 的结点和同样深度的满二叉树中的编号
i
i
i 的结点在二叉树中位置完全相同,则被称为 完全二叉树。

满二叉树一定是完全二叉树,而完全二叉树则不一定是满二叉树。
完全二叉树有如下几个特点:
1)叶子结点只能出现在最下面两层。
2)最下层的叶子结点一定是集中在左边的连续位置;倒数第二层如果有叶子结点,一定集中在右边的连续位置。
3)如果某个结点度为 1,则只有左子树,即 不存在只有右子树 的情况。
4)同样结点数的二叉树,完全二叉树的深度最小。
如下图所示,就不是一棵完全二叉树,因为 5 号结点没有右子树,但是 6 号结点是有左子树的,不满足上述第 2 点。

3、二叉树的性质
接下来我们来看下,二叉树有哪些重要的性质。
1)性质1
【性质1】二叉树的第 i ( i ≥ 1 ) i (i \ge 1) i(i≥1) 层上至多有 2 i − 1 2^{i-1} 2i−1 个结点。
既然是至多,就只需要考虑满二叉树的情况,对于满二叉树而言,当前层的结点数是上一层的两倍,第一层的结点数为 1,所以第 i i i 的结点数可以通过等比数列公式计算出来,为 2 i − 1 2^{i-1} 2i−1。
2)性质2
【性质2】深度为 h h h 的二叉树至多有 2 h − 1 2^{h}-1 2h−1 个结点。
对于任意一个深度为
h
h
h 的二叉树,满二叉树的结点数一定是最多的,所以我们可以拿满二叉树进行计算,它的每一层的结点数为
1
1
1、
2
2
2、
4
4
4、
8
8
8、…、
2
h
−
1
2^{h-1}
2h−1。
利用等比数列求和公式,得到总的结点数为:
1
+
2
+
4
+
.
.
.
+
2
h
−
1
=
2
h
−
1
1 + 2 + 4 + ... + 2^{h-1} = 2^h - 1
1+2+4+...+2h−1=2h−1
3)性质3
【性质3】对于任意一棵二叉树 T T T,如果叶子结点数为 x 0 x_0 x0,度为 2 的结点数为 x 2 x_2 x2,则 x 0 = x 2 + 1 x_0 = x_2 + 1 x0=x2+1
令
x
1
x_1
x1 代表度 为 1 的结点数,总的结点数为
n
n
n,则有:
n
=
x
0
+
x
1
+
x
2
n = x_0 + x_1 + x_2
n=x0+x1+x2
任意一个结点到它孩子结点的连线我们称为这棵树的一条边,对于任意一个非空树而言,边数等于结点数减一,令边数为
e
e
e,则有:
e
=
n
−
1
e = n-1
e=n−1

对于度为 1 的结点,可以提供 1 条边,如图中的黄色结点;对于度为 2 的结点,可以提供 2 条边,如图中的红色结点。所以边数又可以通过度为 1 和 2 的结点数计算得出:
e
=
x
1
+
2
x
2
e = x_1 + 2 x_2
e=x1+2x2 联立上述三个等式,得到:
e
=
n
−
1
=
x
0
+
x
1
+
x
2
−
1
=
x
1
+
2
x
2
e = n-1 = x_0+x_1+x_2 - 1 = x_1 + 2 x_2
e=n−1=x0+x1+x2−1=x1+2x2 化简后,得证:
x
0
=
x
2
+
1
x_0 = x_2 + 1
x0=x2+1
4)性质4
【性质4】具有 n n n 个结点的完全二叉树的深度为 ⌊ l o g 2 n ⌋ + 1 \lfloor log_2n \rfloor + 1 ⌊log2n⌋+1。
由【性质2】可得,深度为
h
h
h 的二叉树至多有
2
h
−
1
2^{h}-1
2h−1 个结点。所以,假设一棵树的深度为
h
h
h,它的结点数为
n
n
n,则必然满足:
n
≤
2
h
−
1
n \le 2^{h}-1
n≤2h−1 由于是完全二叉树,它一定比深度为
h
−
1
h-1
h−1 的结点数要多,即:
2
h
−
1
−
1
<
n
2^{h-1}-1 \lt n
2h−1−1<n 将上述两个不等式,稍加整理,得到:
2
h
−
1
≤
n
<
2
h
2^{h-1} \le n \lt 2^h
2h−1≤n<2h 然后,对不等式两边取以2为底的对数,得到:
h
−
1
≤
l
o
g
2
n
<
h
h-1 \le log_2n \lt h
h−1≤log2n<h 这里,由于
h
h
h 一定是整数,所以有:
h
=
⌊
l
o
g
2
n
⌋
+
1
h = \lfloor log_2n \rfloor + 1
h=⌊log2n⌋+1
二、二叉树的存储
1、顺序表存储
二叉树的顺序存储就是指利用数组对二叉树进行存储。结点的存储位置即数组下标,能够体现结点之间的逻辑关系,比如父结点和孩子结点之间的关系,左右兄弟结点之间的关系 等等。
1)完全二叉树
来看一棵完全二叉树,我们对它进行如下存储。

编号代表了数组下标的绝对位置,映射后如下:
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| d a t a data data | − - − | a a a | b b b | c c c | d d d | e e e | f f f | g g g | h h h | i i i | j j j | k k k | l l l |
这里为了方便,我们把数组下标为 0 的位置给留空了。这样一来,当知道某个结点的下标 x x x,就可以知道它左右儿子的下标分别为 2 x 2x 2x 和 2 x + 1 2x+1 2x+1;反之,当知道某个结点的下标 x x x,也能知道它父结点的下标为 ⌊ x 2 ⌋ \lfloor \frac x 2 \rfloor ⌊2x⌋。
2)非完全二叉树
对于非完全二叉树,只需要将对应不存在的结点设置为空即可。

编号代表了数组下标的绝对位置,映射后如下:
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| d a t a data data | − - − | a a a | b b b | c c c | d d d | e e e | f f f | g g g | − - − | − - − | − - − | k k k | l l l |
3)稀疏二叉树
对于较为稀疏的二叉树,就会有如下情况出现,这时候如果用这种方式进行存储,就比较浪费内存了。

编号代表了数组下标的绝对位置,映射后如下:
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| d a t a data data | − - − | a a a | b b b | c c c | d d d | − - − | − - − | g g g | h h h | − - − | − - − | − - − | − - − |
于是,我们可以采取链表进行存储。
2、链表存储
二叉树每个结点至多有两个孩子结点,所以对于每个结点,设置一个 数据域 和 两个 指针域 即可,指针域 分别指向 左孩子结点 和 右孩子结点。
typedef struct TreeNode {
DataType data;
struct TreeNode *left; // (1)
struct TreeNode *right; // (2)
}TreeNode;
-
(
1
)
(1)
(1)
left指向左孩子结点; -
(
2
)
(2)
(2)
right指向右孩子结点;

三、二叉树的遍历
二叉树的遍历是指从根结点出发,按照某种次序依次访问二叉树中的所有结点,使得每个结点访问一次且仅被访问一次。
对于线性表的遍历,要么从头到尾,要么从尾到头,遍历方式较为单纯,但是树不一样,它的每个结点都有可能有两个孩子结点,所以遍历的顺序面临着不同的选择。
二叉树的常用遍历方法有以下四种:前序遍历、中序遍历、后序遍历、层序遍历。
我们用 void visit(TreeNode *root)这个函数代表访问某个结点,这里为了简化问题,访问结点的过程就是打印对应数据域的过程。如下代码所示:
void visit(TreeNode *root) {
printf("%c", root->data);
}
1、 前序遍历
1)算法描述
【前序遍历】如果二叉树为空,则直接返回。否则,先访问根结点,再递归前序遍历左子树,再递归前序遍历右子树。
前序遍历的结果如下: a b d g h c e f i abdghcefi abdghcefi。

2)源码详解
void preorder(TreeNode *root) {
if(root == NULL) {
return ; // (1)
}
visit(root); // (2)
preorder(root->left); // (3)
preorder(root->right); // (4)
}
- ( 1 ) (1) (1) 待访问结点为空时,直接返回;
- ( 2 ) (2) (2) 先访问当前树的根;
- ( 3 ) (3) (3) 再前序遍历左子树;
- ( 4 ) (4) (4) 最后前序遍历右子树;
2、 中序遍历
1)算法描述
【中序遍历】如果二叉树为空,则直接返回。否则,先递归中序遍历左子树,再访问根结点,再递归中序遍历右子树。
中序遍历的结果如下: g d h b a e c i f gdhbaecif gdhbaecif。

2)源码详解
void inorder(TreeNode *root) {
if(root == NULL) {
return ; // (1)
}
inorder(root->left); // (2)
visit(root); // (3)
inorder(root->right); // (4)
}
- ( 1 ) (1) (1) 待访问结点为空时,直接返回;
- ( 2 ) (2) (2) 先中序遍历左子树;
- ( 3 ) (3) (3) 再访问当前树的根;
- ( 4 ) (4) (4) 最后中序遍历右子树;
3、 后序遍历
1)算法描述
【后序遍历】如果二叉树为空,则直接返回。否则,先递归后遍历左子树,再递归后序遍历右子树,再访问根结点。
后序遍历的结果如下: g h d b e i f c a ghdbeifca ghdbeifca。

2)源码详解
void postorder(TreeNode *root) {
if(root == NULL) {
return ; // (1)
}
postorder(root->left); // (2)
postorder(root->right); // (3)
visit(root); // (4)
}
- ( 1 ) (1) (1) 待访问结点为空时,直接返回;
- ( 2 ) (2) (2) 先后序遍历左子树;
- ( 3 ) (3) (3) 再后序遍历右子树;
- ( 4 ) (4) (4) 再访问当前树的根;
四、二叉搜索树的概念
1、定义
二叉搜索树,又称为二叉排序树,二叉查找树,它满足如下四点性质:
1)空树是二叉搜索树;
2)若它的左子树不为空,则左子树上所有结点的值均小于它根结点的值;
3)若它的右子树不为空,则右子树上所有结点的值均大于它根结点的值;
4)它的左右子树均为二叉搜索树;

如图所示,对于任何一棵子树而言,它的根结点的值一定大于左子树所有结点的值,且一定小于右子树所有结点的值。
2、用途
从二叉搜索树的定义可知,它的前提是二叉树,并且采用了递归的方式进行定义,它的结点间满足一个偏序关系,左子树根结点的值一定比父结点小,右子树根结点的值一定比父结点大。
正如它的名字所说,构造这样一棵树的目的是为了提高搜索的速度,如果对二叉搜索树进行中序遍历,我们可以发现,得到的序列是一个递增序列。

3、数据结构
我们用孩子表示法来定义一棵二叉搜索树的结点。如下:
struct TreeNode {
int val; // (1)
struct TreeNode *left; // (2)
struct TreeNode *right; // (3)
};
- ( 1 ) (1) (1) 二叉搜索树结点的值,注意,这里的类型其实可以是任意类型,只要这种类型支持 关系运算符 的比较即可,本文为了把问题简单话,一律采用整数进行讲解。
-
(
2
)
(2)
(2) 二叉搜索树结点的左儿子结点的指针,没有左儿子结点时,值为
NULL; -
(
3
)
(3)
(3) 二叉搜索树结点的右儿子结点的指针,没有右儿子结点时,置为
NULL;
4、结点创建
结点创建就是给结点分配一块内存,并且填充它的数据域和指针域,然后返回这个结点。C语言实现如下:
struct TreeNode* createNode(int val) {
struct TreeNode* node = (struct TreeNode*) malloc( sizeof(struct TreeNode) );
node->val = val;
node->left = NULL;
node->right = NULL;
return node;
}
五、二叉搜索树的操作
1、查找
二叉搜索树的查找指的是:在树上查找某个数是否存在,存在返回true,不存在返回false。
1)算法原理
对于要查找的数val,从根结点出发,总共四种情况依次判断:
1)若为空树,直接返回false;
2)val的值 等于 树根结点的值,则直接返回true;
3)val的值 小于 树根结点的值,说明val对应的结点不在根结点,也不在右子树上,则递归返回左子树的 查找 结果;
4)val的值 大于 树根结点的值,说明val对应的结点不在根结点,也不在左子树上,则递归返回右子树的 查找 结果;
2)动图演示
如图所示,代表的是从一个二叉搜索树中查找一个值为 3 的结点。一开始, 3 比根结点 5 小,于是递归访问左子树;还是比子树的根结点 4 小,于是继续递归访问左子树;这时候比根结点 2 大,于是递归访问右子树,正好找到值为 3 的结点,回溯结束查找。

3)源码详解
bool BSTFind(struct TreeNode* root, int val) { // (1)
if(root == NULL) {
return false; // (2)
}
if(root->val == val) {
return true; // (3)
}
if(val < root->val) {
return BSTFind(root->left, val); // (4)
}else {
return BSTFind(root->right, val); // (5)
}
}
-
(
1
)
(1)
(1)
BSTFind这个函数用于查找以now为根结点的树中是否存在值为val这个结点; -
(
2
)
(2)
(2) 空树是不可能存在值为
val的结点的,直接返回false; -
(
3
)
(3)
(3) 一旦发现有值为
val的结点,直接返回true; -
(
4
)
(4)
(4)
val的值 小于 树根结点的值,说明val对应的结点不在根结点,也不在右子树上,则递归返回左子树的 查找 结果; -
(
5
)
(5)
(5)
val的值 大于 树根结点的值,说明val对应的结点不在根结点,也不在左子树上,则递归返回右子树的 查找 结果;
2、插入
二叉搜索树的插入指的是:将给定的值生成结点后,插入到树上的某个位置,并且保持这棵树还是二叉搜索树。
1)算法原理
对于要插入的数val,从根结点出发,总共四种情况依次判断:
1)若为空树,则创建一个值为val的结点并且返回;
2)val的值 等于 树根结点的值,无须执行插入,直接返回根结点;
3)val的值 小于 树根结点的值,那么插入位置一定在 左子树,递归执行插入左子树的过程,并且返回插入结果作为新的左子树;
4)val的值 大于 树根结点的值,那么插入位置一定在 右子树,递归执行插入右子树的过程,并且返回插入结果作为新的右子树;
2)动图演示
如图所示,代表的是将一个值为 3 的结点插入到一个二叉搜索树中。一开始, 3 比根结点 5 小,于是递归插入左子树;还是比子树的根结点 4 小,于是继续递归插入左子树;这时候比根结点 2 大,于是递归插入右子树,右子树为空,则直接生成一个值为 3 的结点,回溯结束插入。

3)源码详解
struct TreeNode* BSTInsert(struct TreeNode* root, int val){ // (1)
if(root == NULL) {
return createNode(val); // (2)
}
if(val == root->val) {
return root; // (3)
}
if(val < root->val) { // (4)
root->left = BSTInsert(root->left, val);
}else { // (5)
root->right = BSTInsert(root->right, val);
}
return root;
}
-
(
1
)
(1)
(1)
BSTInsert函数用于将值为val的结点插入到以root为根结点的子树中; -
(
2
)
(2)
(2) 如果是空树,则创建一个值为
val的结点并且返回; -
(
3
)
(3)
(3)
val的值 等于 树根结点的值,无须执行插入,直接返回根结点; -
(
4
)
(4)
(4)
val的值 小于 树根结点的值,那么插入位置一定在 左子树,递归执行插入左子树的过程,并且返回插入结果作为新的左子树; -
(
5
)
(5)
(5)
val的值 大于 树根结点的值,那么插入位置一定在 右子树,递归执行插入右子树的过程,并且返回插入结果作为新的右子树;
3、删除
二叉搜索树的删除指的是:在树上删除给定值的结点。
1)算法原理
删除值为val的结点的过程,从根结点出发,总共四种情况依次判断:
1)空树,不存在结点直接返回空树;
2)val的值 小于 树根结点的值,则需要删除的结点一定不在右子树上,递归调用删除左子树的对应结点;
3)val的值 大于 树根结点的值,则需要删除的结点一定不在左子树上,递归调用删除右子树的对应结点;
4)val的值 等于 树根结点的值,相当于是要删除根结点,这时候又要分三种情况:
4.1)当前树只有左子树,则直接将左子树返回,并且释放当前树根结点的空间;
4.2)当前树只有右子树,则直接将右子树返回,并且释放当前树根结点的空间;
4.3)当左右子树都存在时,需要在右子树上找到一个值最小的结点,替换新的树根,而其它结点组成的树作为它的子树,并且在子树中删掉这个最小的结点,而这一步删除的过程正是继续递归调用结点删除的过程;
2)动图演示
如图所示,下图展示的是,从这棵树删除根结点 5 的过程。首先,由于它有左右儿子结点,所以这个过程,根结点并不是真正的删除。而是从右子树中找到最小的结点 6,替换根结点,并且从根结点为 7 的子树中删除 6 的过程。由于 6 没有子结点所以这个过程就直接结束了。

3)源码详解
3.1)接口简介
在介绍二叉搜索树的结点删除算法前,我们首先需要知道以下四个接口:
int BSTFindMin(struct TreeNode* root); // (2)
struct TreeNode* BSTDelete(struct TreeNode* root, int val); // (3)
struct TreeNode* Delete(struct TreeNode* root); // (4)
-
(
1
)
(1)
(1)
BSTFindMin:查找root为根的树中,值最小的那个结点的值,根据二叉搜索树的性质,如果左子树存在,则必然存在更小的值,递归搜索左子树;如果左子树不存在,则根结点的值必然最小,直接返回,具体实现见下文; -
(
2
)
(2)
(2)
BSTDelete:在root为根的树中,删除值为val的结点,是我们需要实现的删除接口,具体实现见下文; -
(
3
)
(3)
(3)
Delete:在root为根的树中,将根结点删除,并且使得剩下的树还是二叉搜索树,具体实现见下文;
3.2)查找最小结点
int BSTFindMin(struct TreeNode* root) {
if(root->left)
return BSTFindMin(root->left); // (1)
return root->val; // (2)
}
- ( 1 ) (1) (1) 如果左子树存在,则递归调用左子树的查找最小结点接口;
- ( 2 ) (2) (2) 如果左子树不存在,则当前根结点的值一定是最小的,直接返回接口;
3.3)删除给定结点
struct TreeNode* BSTDelete(struct TreeNode* root, int val){
if(NULL == root) {
return NULL; // (1)
}
if(val == root->val) {
return Delete(root); // (2)
}
else if(val < root->val) {
root->left = BSTDelete(root->left, val); // (3)
}else if(val > root->val) {
root->right = BSTDelete(root->right, val); // (4)
}
return root; // (5)
}
- ( 1 ) (1) (1) 如果为空树,则直接返回空结点;
-
(
2
)
(2)
(2) 如果需要删除的结点,是这棵树的根结点,则直接调用接口
Delete,下文会介绍它的实现; - ( 3 ) (3) (3) 如果需要删除的结点的值 小于 树根结点的值,则需要删除的结点必定在左子树上,递归调用左子树的删除,并且将返回值作为新的左子树的根结点;
- ( 4 ) (4) (4) 如果需要删除的结点的值 大于 树根结点的值,则需要删除的结点必定在右子树上,递归调用右子树的删除,并且将返回值作为新的右子树的根结点;
- ( 5 ) (5) (5) 最后,返回当前树的根结点;
3.4)删除给定二叉搜索树的根结点,并且返回新的树根
struct TreeNode* Delete(struct TreeNode* root) {
struct TreeNode *delNode, *retNode;
if(root->left == NULL) { // (1)
delNode = root, retNode = root->right, free(delNode);
}else if(root->right == NULL) { // (2)
delNode = root, retNode = root->left, free(delNode);
}else { // (3)
retNode = (struct TreeNode*) malloc (sizeof(struct TreeNode));
retNode->val = BSTFindMin(root->right);
retNode->right = BSTDelete(root->right, retNode->val);
retNode->left = root->left;
}
return retNode;
}
- ( 1 ) (1) (1) 如果左子树为空,则用右子树做为新的树根;
- ( 2 ) (2) (2) 如果右子树为空,则用左子树作为新的树根;
-
(
3
)
(3)
(3) 否则,当左右子树都为非空时,利用
BSTFindMin,从右子树上找出最小的结点,作为新的根,并且在右子树中删除对应的结点,删除过程就是递归调用BSTDelete的过程;
4、构造
二叉搜索树的构造就是:给定一个数组序列,构造出一个棵二叉搜索树。
1)算法原理
原理比较简单,一开始是一棵空树,然后遍历数组,对每个元素生成一个结点,不断执行插入操作,并且返回新的树根,就完成了构造的过程。
2)源码详解
struct TreeNode* BSTConstruct(int *vals, int valSize) {
int i;
struct TreeNode* root = NULL; // (1)
for(i = 0; i < valSize; ++i) {
root = BSTInsert(root, vals[i]); // (2)
}
return root;
}
- ( 1 ) (1) (1) 初始化空树;
- ( 2 ) (2) (2) 根据数组给定顺序执行插入树的操作;
插入过程需要明确一点,就是如果给定的数组是严格递增,或者严格递减,就会导致每次插入都要遍历树的所有结点,这样就使得整个插入过程的时间复杂度变成了
O
(
n
2
)
O(n^2)
O(n2),改善的方法有几种:
方法1:随机将数组打乱顺序,再执行插入;
方法2:每次插入后,变换成平衡树,对于平衡树相关内容,下篇文章会详细讲解;
六、二叉搜索树的遍历
1、先序遍历
给定一个某个二叉搜索树的先序遍历序列,构造出一棵二叉搜索树,方法如下:
1)首先,考虑先序遍历的特点:先访问根结点,再依次访问左右子树;所以,第一个结点一定是根结点;
2)然后,数组往后遍历的过程中,遇到的所有小于当前根结点的结点,都必然是左子树上的结点,后面的结点必然是右子树的(当然,如果检测到后面的结点有比这个根结点小的,则这个序列无法构造出一棵二叉搜索树);
3)遍历找到左右子树的分界点后,就可以进行左右子树递归计算了,注意递归时返回构造完的子树的根结点。
2、中序遍历
二叉搜索树的中序遍历是最常用的,一棵二叉搜索树的中序遍历是一个递增序列。
递增序列是存在单调性的,所以可以利用这个特性,在有效的时间内找出这棵树的第
k
k
k 大结点。
3、后序遍历
给定一个整数数组,判断该数组是不是某二叉搜索树的后序遍历结果,方法如下:
1)从后序遍历的定义出发,先左子树,再右子树,最后根结点。所以,这个序列的最后一个元素,一定是根结点,且所有小于它的元素作为左子树,所有大于它的元素作为右子树。
2)如果能够分成这样两部分,则递归计算左右子树;
3)否则,在出现第一个大于 最后一个元素的情况下,又出现小于 最后一个元素的情况,则表示这是一种非法情况,直接返回false。
七、二叉搜索树的总结
纵观二叉搜索树的查找、插入 和 删除。完全取决于二叉搜索树的形状,如果是完全二叉树或者接近完全二叉树,则这三个过程都是
O
(
l
o
g
2
n
)
O(log_2n)
O(log2n) 的,如果是斜树,则三个过程近似操作线性表,为
O
(
n
)
O(n)
O(n)。


有关 🌳 二叉搜索树 🌳 的的内容到这里就完全结束了,如果还有什么疑问,可以添加作者微信咨询。
有关🌳《画解数据结构》🌳 的源码均开源,链接如下:《画解数据结构》

相信看我文章的大多数都是「 大学生 」,能上大学的都是「 精英 」,那么我们自然要「 精益求精 」,如果你还是「 大一 」,那么太好了,你拥有大把时间,当然你可以选择「 刷剧 」,然而,「 学好算法 」,三年后的你自然「 不能同日而语 」。
那么这里,我整理了「 几十个基础算法 」 的分类,点击开启:
如果链接被屏蔽,或者有权限问题,可以私聊作者解决。
大致题集一览:

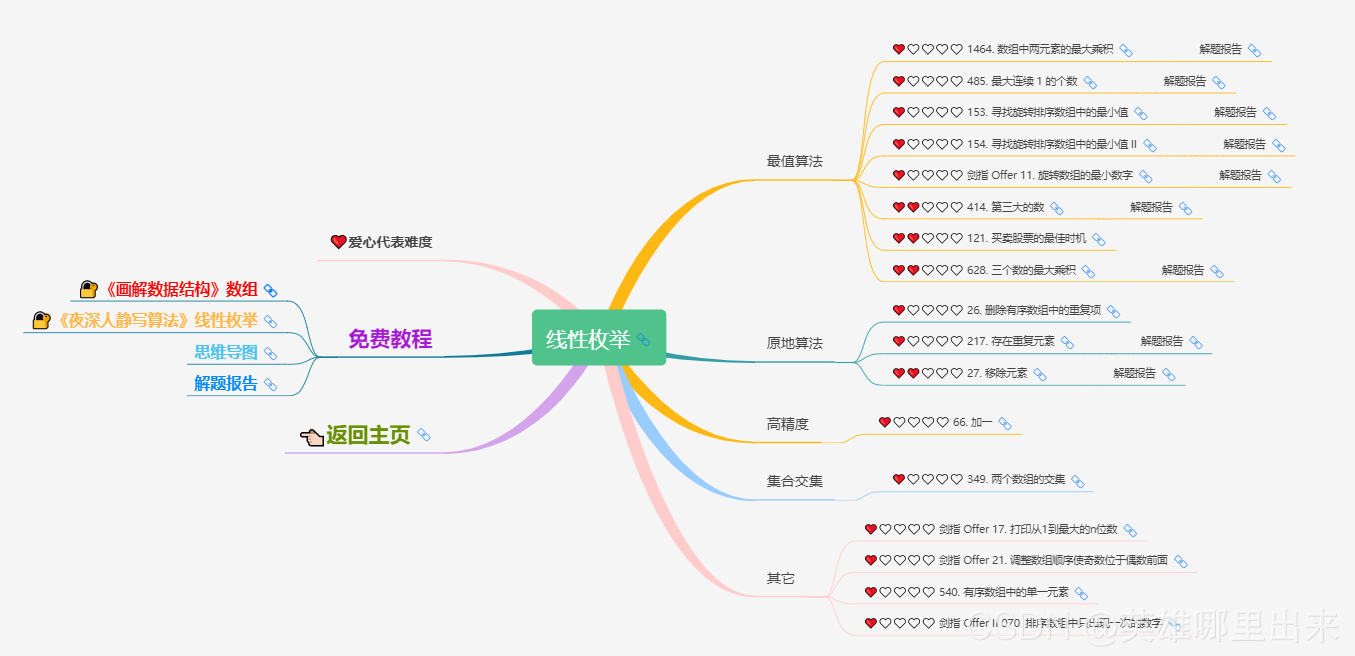
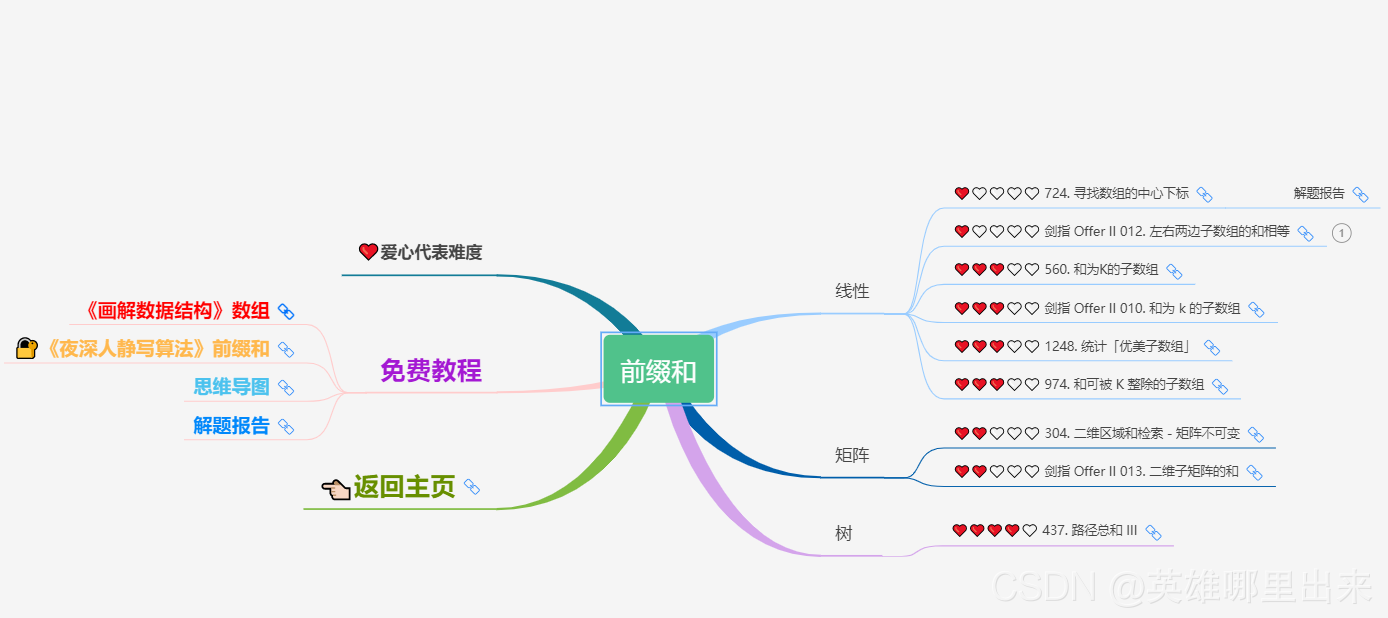
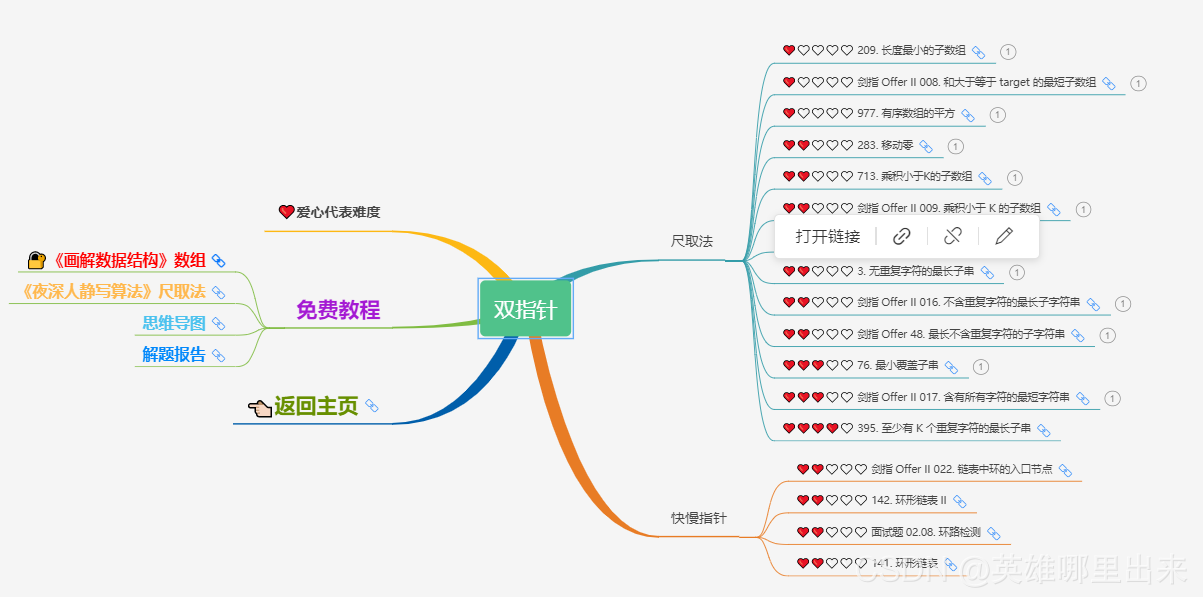
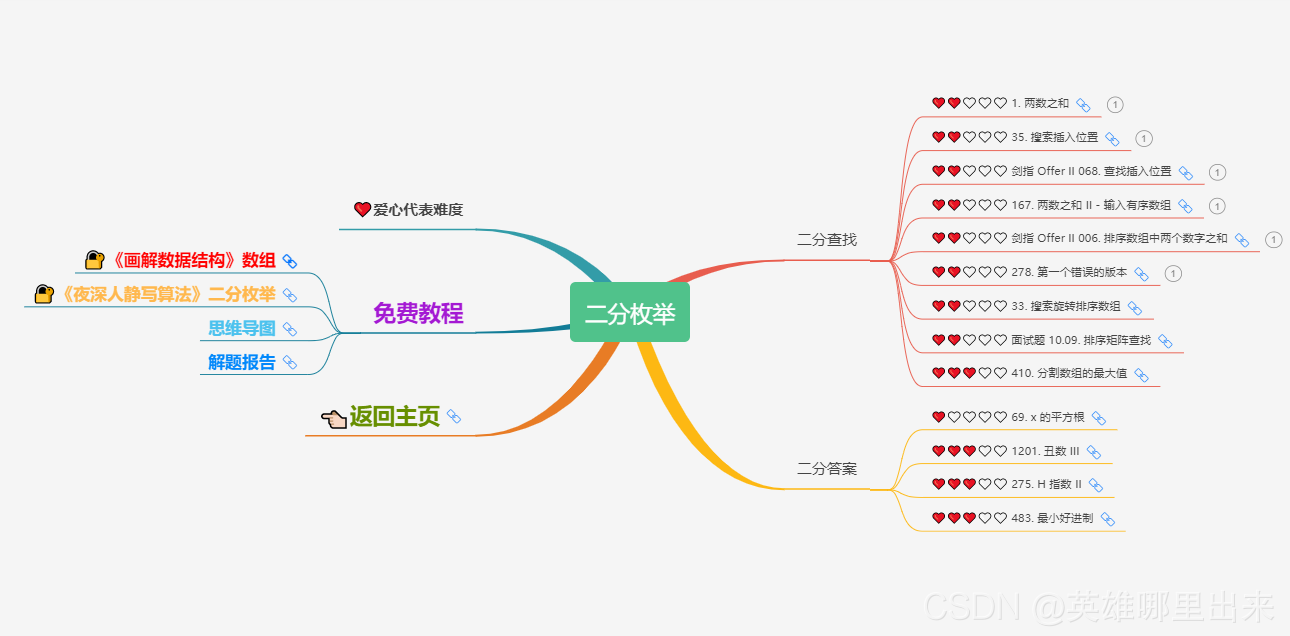


为了让这件事情变得有趣,以及「 照顾初学者 」,目前题目只开放最简单的算法 「 枚举系列 」 (包括:线性枚举、双指针、前缀和、二分枚举、三分枚举),当有 一半成员刷完 「 枚举系列 」 的所有题以后,会开放下个章节,等这套题全部刷完,你还在群里,那么你就会成为「 夜深人静写算法 」专家团 的一员。
不要小看这个专家团,三年之后,你将会是别人 望尘莫及 的存在。如果要加入,可以联系我,考虑到大家都是学生, 没有「 主要经济来源 」,在你成为神的路上,「 不会索取任何 」。
🔥让天下没有难学的算法🔥
C语言免费动漫教程,和我一起打卡! 🌞《光天化日学C语言》🌞
入门级C语言真题汇总 🧡《C语言入门100例》🧡
几张动图学会一种数据结构 🌳《画解数据结构》🌳
组团学习,抱团生长 🌌《算法入门指引》🌌
竞赛选手金典图文教程 💜《夜深人静写算法》💜 这篇文章的主要目的是讲解二叉搜索树的一些基础概念,以及和二叉搜索树相关的一些经典算法。但是实际学习过程还是需要看个人的毅力和坚持。下图代表的是 LeetCode 经典的二叉搜索树的题集,其中树是很重要的一个章节,涉及了诸多算法,希望可以供读者参考和学习。

粉丝专属福利
语言入门:《光天化日学C语言》(示例代码)
语言训练:《C语言入门100例》试用版
数据结构:《画解数据结构》源码
算法入门:《算法入门》指引
算法进阶:《夜深人静写算法》算法模板