数据集:大学毕业生收入
下载地址,本文以绘制直方图为主。
1. 字段描述
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| Major_code | 整型 | 专业代码。 |
| Major | 字符型 | 专业名称。 |
| Major_category | 字符型 | 专业所属目录。 |
| Total | 整型 | 总人数。 |
| Employed | 整型 | 就业人数。 |
| Employed_full_time_year_round | 整型 | 全年全职在岗人数。 |
| Unemployed | 整型 | 失业人数。 |
| Unemployment_rate | 浮点型 | 失业率。 |
| Median | 整型 | 收入的中位数。 |
| P25th | 整型 | 收入的25百分位数。 |
| P75th | 浮点型 | 收入的75百分位数。 |
2. 数据预处理
2.1 导包
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import os
import warnings
warnings.filterwarnings('ignore')
2.2 读取数据
df = pd.read_csv('大学毕业生收入数据集.csv')
3. 数据预览
3.1 预览数据
print(df.head())
结果:
Major_code Major ... P25th P75th
0 1100 GENERAL AGRICULTURE ... 34000 80000.0
1 1101 AGRICULTURE PRODUCTION AND MANAGEMENT ... 36000 80000.0
2 1102 AGRICULTURAL ECONOMICS ... 40000 98000.0
3 1103 ANIMAL SCIENCES ... 30000 72000.0
4 1104 FOOD SCIENCE ... 38500 90000.0
3.2 查看基本信息
df.info()
结果:
RangeIndex: 173 entries, 0 to 172
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Major_code 173 non-null int64
1 Major 173 non-null object
2 Major_category 173 non-null object
3 Total 173 non-null int64
4 Employed 173 non-null int64
5 Employed_full_time_year_round 173 non-null int64
6 Unemployed 173 non-null int64
7 Unemployment_rate 173 non-null float64
8 Median 173 non-null int64
9 P25th 173 non-null int64
10 P75th 173 non-null float64
dtypes: float64(2), int64(7), object(2)
3.3 查看重复值
print(df.duplicated().sum())
结果:
0
3.4 查看缺失值
print(df.isnull().sum())
结果:
Major_code 0
Major 0
Major_category 0
Total 0
Employed 0
Employed_full_time_year_round 0
Unemployed 0
Unemployment_rate 0
Median 0
P25th 0
P75th 0
dtype: int64
4. 数据集描述性信息
describe = df.describe()
print(describe)
结果:
Major_code Total ... P25th P75th
count 173.000000 1.730000e+02 ... 173.000000 173.000000
mean 3879.815029 2.302566e+05 ... 38697.109827 82506.358382
std 1687.753140 4.220685e+05 ... 9414.524761 20805.330126
min 1100.000000 2.396000e+03 ... 24900.000000 45800.000000
25% 2403.000000 2.428000e+04 ... 32000.000000 70000.000000
50% 3608.000000 7.579100e+04 ... 36000.000000 80000.000000
75% 5503.000000 2.057630e+05 ... 42000.000000 95000.000000
max 6403.000000 3.123510e+06 ... 78000.000000 210000.000000
[8 rows x 9 columns]
可在变量视图中查看
describe
5. 数据分析
5.1 各专业种类(Major_category)的专业分支个数
Major_category_counts=df['Major_category'].value_counts()
print(Major_category_counts)
rects = plt.bar(range(1,17),Major_category_counts);
for rect in rects: #rects 是三根柱子的集合
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height, str(height), size=12, ha='center', va='bottom')
interval = ['Engineering','Education','Humanities & Liberal Arts','Biology & Life Science','Business','Health','Computers & Mathematics','Agriculture & Natural Resources','Physical Sciences','Social Science','Psychology & Social Work','Arts','Industrial Arts & Consumer Services','Law & Public Policy','Communications & Journalism','Interdisciplinary']
plt.xticks(range(1,17),interval,rotation=90);
plt.title('Number of Branches by Major Category')
plt.ylabel('Counts')
plt.show()
结果:
Engineering 29
Education 16
Humanities & Liberal Arts 15
Biology & Life Science 14
Business 13
Health 12
Computers & Mathematics 11
Agriculture & Natural Resources 10
Physical Sciences 10
Social Science 9
Psychology & Social Work 9
Arts 8
Industrial Arts & Consumer Services 7
Law & Public Policy 5
Communications & Journalism 4
Interdisciplinary 1
Name: Major_category, dtype: int64
图示:
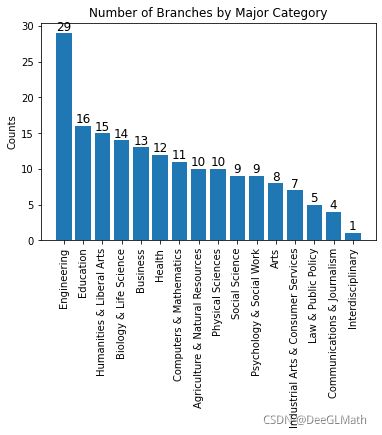
结论:
由于机械类专业发展历史悠久,故相对来说机械类专业分支数相较其他大类专业要多
5.2 各大类专业收入
averageMoney = []
for i in range(len(interval)):
sum = 0
for j in range(173):
if df['Major_category'][j] == interval[i]:
sum = sum + df['Median'][j]
averageMoney.append(sum/Major_category_counts[i])
plt.bar(range(1,17),averageMoney);
plt.xticks(range(1,17),interval,rotation=90);
plt.title('Average Annual salary by Major Category')
plt.ylabel('Moneys')
plt.show()
图示:
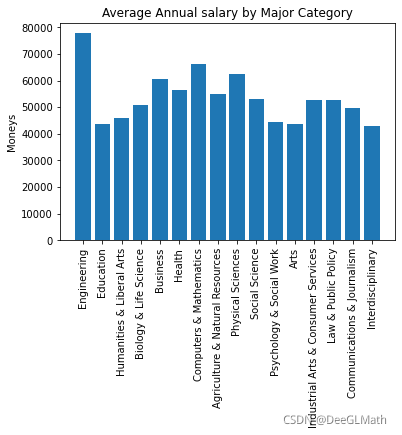
结论:
由于机械类专业与人工智能、自动化等领域相关,故平均工资比较高;计算机与数学类专业发展前景很好,但是小公司工资普遍不高,大公司工资相对来说较高。
5.3 各大类专业失业率
averageUnemployRate = []
for i in range(len(interval)):
sum = 0
for j in range(173):
if df['Major_category'][j] == interval[i]:
sum = sum + df['Unemployment_rate'][j]
averageUnemployRate.append(sum/Major_category_counts[i])
plt.bar(range(1,17),averageUnemployRate);
plt.xticks(range(1,17),interval,rotation=90);
plt.title('Average Unemployment Rate by Major Category')
plt.ylabel('Rate')
plt.show()
图示:
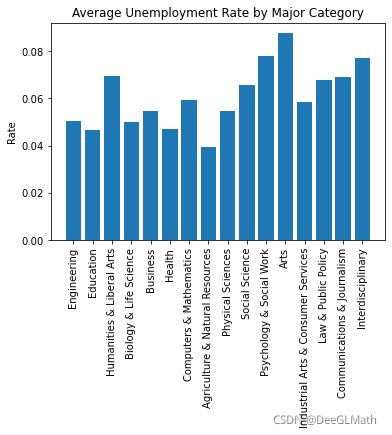
结论:
艺术类专业由于可变动性特别大,加上对人才的要求相对来说较为苛刻,故失业率较高。
5.4 各大类专业就业率
averageEmployRate = []
for i in range(len(interval)):
sum = 0
for j in range(173):
if df['Major_category'][j] == interval[i]:
sum = sum + df['Employed'][j] / df['Total'][j]
averageEmployRate.append(sum/Major_category_counts[i])
plt.bar(range(1,17),averageEmployRate);
plt.xticks(range(1,17),interval,rotation=90);
plt.title('Average Employment Rate by Major Category')
plt.ylabel('Rate')
plt.show()
图示:
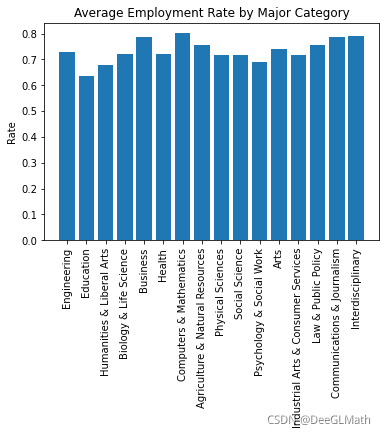
结论:
相对来说,由于计算机的发展前景,计算机与数学类的就业率较高。
5.5 各大类专业全年全职在岗率
averageFullTimeRate = []
for i in range(len(interval)):
sum = 0
for j in range(173):
if df['Major_category'][j] == interval[i]:
sum = sum + df['Employed_full_time_year_round'][j] / df['Employed'][j]
averageFullTimeRate.append(sum/Major_category_counts[i])
plt.bar(range(1,17),averageFullTimeRate);
plt.xticks(range(1,17),interval,rotation=90);
plt.title('Average Full-Time Rate by Major Category')
plt.ylabel('Rate')
plt.show()
图示:
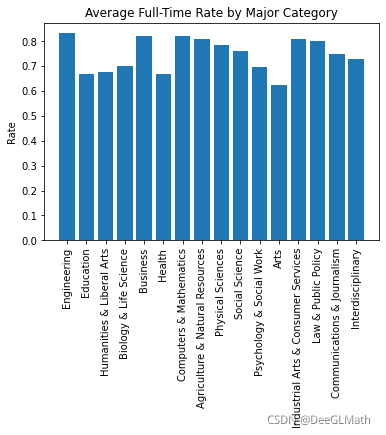
5.6 各大类专业总人数
averageNum = []
for i in range(len(interval)):
sum = 0
for j in range(173):
if df['Major_category'][j] == interval[i]:
sum = sum + df['Total'][j]
averageNum.append(sum/Major_category_counts[i])
plt.bar(range(1,17),averageNum);
plt.xticks(range(1,17),interval,rotation=90);
plt.title('Average Total Numbers by Major Category')
plt.ylabel('Counts')
plt.show()
图示:
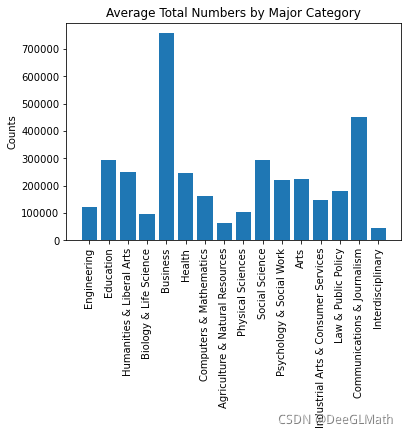
5.7 就业失业比
EUratio = []
for i in range(len(interval)):
EUratio.append(averageEmployRate[i]/averageUnemployRate[i])
plt.bar(range(1,17),EUratio);
plt.xticks(range(1,17),interval,rotation=90);
plt.title('Employment-Unemployment Ratio by Major Category')
plt.ylabel('Ratio')
plt.show()
图示:
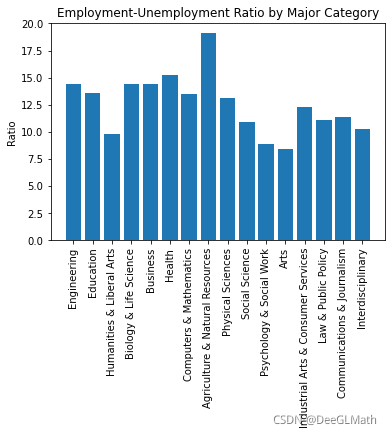
结论:
相对来说,农业就业的门槛低,就业率高的同时失业率低。
6. 完整代码
# 导包
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import os
import warnings
warnings.filterwarnings('ignore')
# 读取数据
df = pd.read_csv('大学毕业生收入数据集.csv')
# 预览数据
print(df.head())
# 规范字段名称(本数据集已经较为规范)
# 查看基本信息
df.info()
# 查看重复值
print(df.duplicated().sum())
# 查看缺失值
print(df.isnull().sum())
# 查看数据集描述性信息
describe = df.describe()
print(describe)
# 统计表中每个专业种类(Major_category)的个数
Major_category_counts=df['Major_category'].value_counts()
print(Major_category_counts)
rects = plt.bar(range(1,17),Major_category_counts);
for rect in rects: #rects 是三根柱子的集合
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height, str(height), size=12, ha='center', va='bottom')
interval = ['Engineering','Education','Humanities & Liberal Arts','Biology & Life Science','Business','Health','Computers & Mathematics','Agriculture & Natural Resources','Physical Sciences','Social Science','Psychology & Social Work','Arts','Industrial Arts & Consumer Services','Law & Public Policy','Communications & Journalism','Interdisciplinary']
plt.xticks(range(1,17),interval,rotation=90);
plt.title('Number of Branches by Major Category')
plt.ylabel('Counts')
plt.show()
# 对各大类专业收入作统计并作图
averageMoney = []
for i in range(len(interval)):
sum = 0
for j in range(173):
if df['Major_category'][j] == interval[i]:
sum = sum + df['Median'][j]
averageMoney.append(sum/Major_category_counts[i])
plt.bar(range(1,17),averageMoney);
plt.xticks(range(1,17),interval,rotation=90);
plt.title('Average Annual salary by Major Category')
plt.ylabel('Moneys')
plt.show()
# 对各大类专业失业率作统计并作图
averageUnemployRate = []
for i in range(len(interval)):
sum = 0
for j in range(173):
if df['Major_category'][j] == interval[i]:
sum = sum + df['Unemployment_rate'][j]
averageUnemployRate.append(sum/Major_category_counts[i])
plt.bar(range(1,17),averageUnemployRate);
plt.xticks(range(1,17),interval,rotation=90);
plt.title('Average Unemployment Rate by Major Category')
plt.ylabel('Rate')
plt.show()
# 对各大类专业就业率作统计并作图
averageEmployRate = []
for i in range(len(interval)):
sum = 0
for j in range(173):
if df['Major_category'][j] == interval[i]:
sum = sum + df['Employed'][j] / df['Total'][j]
averageEmployRate.append(sum/Major_category_counts[i])
plt.bar(range(1,17),averageEmployRate);
plt.xticks(range(1,17),interval,rotation=90);
plt.title('Average Employment Rate by Major Category')
plt.ylabel('Rate')
plt.show()
# 对各大类专业全年全职在岗率作统计并作图(没有早退的)
averageFullTimeRate = []
for i in range(len(interval)):
sum = 0
for j in range(173):
if df['Major_category'][j] == interval[i]:
sum = sum + df['Employed_full_time_year_round'][j] / df['Employed'][j]
averageFullTimeRate.append(sum/Major_category_counts[i])
plt.bar(range(1,17),averageFullTimeRate);
plt.xticks(range(1,17),interval,rotation=90);
plt.title('Average Full-Time Rate by Major Category')
plt.ylabel('Rate')
plt.show()
# 对各大类专业总人数作统计并作图
averageNum = []
for i in range(len(interval)):
sum = 0
for j in range(173):
if df['Major_category'][j] == interval[i]:
sum = sum + df['Total'][j]
averageNum.append(sum/Major_category_counts[i])
plt.bar(range(1,17),averageNum);
plt.xticks(range(1,17),interval,rotation=90);
plt.title('Average Total Numbers by Major Category')
plt.ylabel('Counts')
plt.show()
# 对各大类专业就业失业比作统计并作图
EUratio = []
for i in range(len(interval)):
EUratio.append(averageEmployRate[i]/averageUnemployRate[i])
plt.bar(range(1,17),EUratio);
plt.xticks(range(1,17),interval,rotation=90);
plt.title('Employment-Unemployment Ratio by Major Category')
plt.ylabel('Ratio')
plt.show()